1、消息(Messages)
1.1 LLM 消息结构
每条消息都有一个角色和内容,以及因 LLM 的不同而不同的附加元数据。
• 消息角色 (Role):用来区分对话中不同类型的消息,并帮助聊天模型了解如何响应给定的消息序 列。
| 角色 | 描述 |
|---|---|
| system(系统角色) | 用于告诉聊天模型如何行为并提供额外的上下文。并非所有聊天模型提供商都支持。 |
| user(用户角色) | 表示用户与模型交互的输入,通常以文本或其他交互式输入的形式。 |
| assistant(助理角色) | 表示来自模型的响应,其中可以包括文本或调用工具的请求。 |
| tool(工具角色) | 用于在检索外部数据或将工具调用的结果传递回模型的消息。与支持工具调用的聊天模型一起使用。 |
**• 消息内容 (Content):**表示多模态数据 (例如,图像、音频、视频)的消息文本或字典列表的内 容。内容的具体格式可能因底层不同的 LLM 而异。目前,大多数模型都支持文本作为主要内容类 型,对多模态数据的支持仍然有限。
• 消息其他元数据 (Additional metadata)
| 元数据 | 描述 |
|---|---|
| ID | 消息标识符。 |
| Name | 名称允许区分具有相同角色的不同实体。并非所有型号都支持此功能! |
| Metadata | 有关消息的其他信息,例如时间戳、令牌使用情况等。 |
| Tool Calls | 模型发出的一个或多个工具的调用请求。 |
OpenAI 的格式消息列表:
python
[
{
"role": "user",
"content": "Hello, how are you?",
},
{
"role": "assistant",
"content": "I'm doing well, thank you for asking.",
},
{
"role": "user",
"content": "Can you tell me a joke?",
}
]LangChain 接受下面的格式作为聊天模型的输入 :
python
chat_model.invoke([
{
"role": "user",
"content": "Hello, how are you?",
},
{
"role": "assistant",
"content": "I'm doing well, thank you for asking.",
},
{
"role": "user",
"content": "Can you tell me a joke?",
}
])1.2 LangChain 消息
LangChain 提供了一种统一的消息格式 ,可以跨聊天模型使用 ,允许用户使用不同的聊天模型,而无需担心每个模型提供商使用的消息格式的具体细节。
不同的供应商,对于其输入和输出,统一使用 LangChain 的消息格式。 LangChain 消息格式 主要分为五种,它们都是 LangChain BaseMessage 的子类 ,全部是作为 LangChain 聊天模型的输入和输出!!分别是:
| 消息类型 | 对应角色 | 描述 |
|---|---|---|
| SystemMessage | 对应 system 系统角色 | 用于启动 AI 模型的行为并提供额外的上下文 ,例如指示模型采用特定角色或设定对话的基调(例如,"你是一个后端开发的专家")。 |
| HumanMessage | 对应 user 用户角色 | 人类消息表示用户与模型交互的输入。大多数聊天模型都希望用户输入采用文本形式。 |
| AIMessage | 对应 assistant 助理角色 | 这是来自模型的响应, 其中可以包括文本或调用工具的请求。 它还可能包括**其他媒体类型,**如图像、音频或视频------尽管这目前仍然不常见。 |
| AIMessageChunk | 对应 assistant 助理角色,用于流式响应 | 通常在生成聊天模型时流式传输响应 ,因此用户可以实时看到响应,而不是等待生成整个响应后再显示。 |
| ToolMessage | 对应 tool 工具角色 | 这表示一条角色为"tool"的消息,其中包含调用工具的结果。 |
1.2.1 BaseMessage 抽象消息类
class langchain_core.messages.base.BaseMessage 是作为 LangChain 聊天模型的输 入和输出!!
BaseMessage 参数
| 参数 | 描述 |
|---|---|
content |
消息的字符串内容。 |
additional_kwargs |
与消息关联的其他有效负载数据。对于来自 AI 的消息,可能包括模型提供程序编码的工具调用。 |
response_metadata |
响应元数据。例如:响应标头、logprobs、令牌计数、模型名称。 |
type |
消息的类型。必须是消息类型唯一的字符串。此字段的目的是在对消息进行反序列化时方便地识别消息类型。 |
name |
消息名称,为消息提供一个人类可读的名称。该字段的使用是可选的,是否使用它取决于模型实现。 |
id |
消息的可选唯一标识符。理想情况下,这应该由创建消息的提供者/模型提供。 |
BaseMessage 内置方法
| 方法 | 描述 |
|---|---|
pretty_print() -> None |
打印消息的漂亮表示。 |
pretty_repr(html: bool = False) -> str |
获得消息的漂亮表示。参数 html 表示是否将消息格式化为 HTML(默认 False);返回消息的漂亮表示字符串。 |
text() -> str |
获取消息的文本内容。 |
1.2.2 对话模式
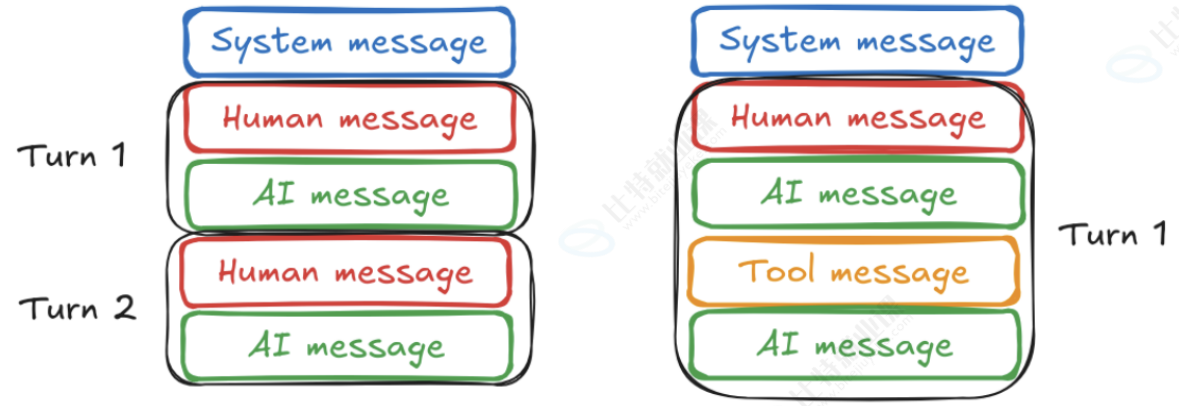
大多数对话都以设置对话上下文的系统消息开始。 接下来是包含用户输入的用户消息 ,然后是包含模型响应的助手消息。
1.3 缓存历史消息
1.3.1 多轮对话
在与大型语言模型交互的过程中,我们常常体验到与智能助手进行连贯多轮对话的便利性。但目前我们的系统还不支持此功能,不支持更多轮的对话。但是只要将历史消息,重新发送给聊天模型,那么就可以实现多轮对话的功能。
1.3.2 内存缓存
那么对于历史消息的管理就显得尤为重要。在 LangChain 老版本中,可以使用RunnableWithMessageHistory 消息历史类来包装另一个 Runnable 并为其管理聊天消息历史记录。 它将跟踪模型的输入和输出 ,并将其存储在某个数据存储中 。未来的交互将加载这些消息 ,并 将其作为输入 的一部分传递给链。
python
# 导入所需模块
from langchain_openai import ChatOpenAI # 导入 OpenAI 聊天模型
from langchain_core.messages import HumanMessage, AIMessage # 导入消息类型
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory # 聊天历史基类及内存实现
from langchain_core.runnables.history import RunnableWithMessageHistory # 带消息历史管理的可运行包装器
# 定义大模型(使用 OpenAI 的 GPT-4o-mini 模型)
model = ChatOpenAI(model="gpt-4o-mini")
# 存储不同会话的消息历史记录(字典:session_id -> 消息历史对象)
store = {}
# 根据 session_id 获取对应的消息历史对象
# 这个函数会被 RunnableWithMessageHistory 调用,用于管理每个会话的历史记录
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
# 如果该会话还没有历史记录,则创建一个新的内存消息历史对象
# InMemoryChatMessageHistory 将消息存储在内存列表中(适合测试/单次运行)
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 包装 model,使其能够自动管理聊天消息历史记录
# RunnableWithMessageHistory 会在每次调用时根据 config 中的 session_id 调用 get_session_history
with_message_history = RunnableWithMessageHistory(model, get_session_history)
# 配置信息,其中 session_id 用于区分不同的对话会话
config = {"configurable": {"session_id": "1"}}
# 第一次对话:用户发送消息 "Hi! I'm Bob"
with_message_history.invoke(
[HumanMessage(content="Hi! I'm Bob")], # 输入消息列表(这里只有一条用户消息)
config=config, # 传入配置,指定 session_id = "1"
).pretty_print() # 打印模型响应的漂亮格式
# 第二次对话:在同一会话(session_id = "1")中继续对话
with_message_history.invoke(
[HumanMessage(content="What's my name?")], # 用户询问自己的名字
config=config,
).pretty_print()class langchain_core.runnables.history.RunnableWithMessageHistory 类方法
说明:
• .invoke() 方法:此方法与其他 Runnable 实例的 .invoke() 方法相同。只不过注意其
config配置,需要配置成config={"configurable": {"session_id": ""}} ,让
RunnableWithMessageHistory 可以读取到会话id。
1.3.2.1 说明
从 LangChain 的 v0.3 版本开始,官方建议 LangChain 用户不要使用
RunnableWithMessageHistory ,而是利用 LangGraph 持久性来完成(见 LangGraph 章
节)。
原因是它们的功能有限,不太适合现实世界的对话式 AI 应用程序。这些内存抽象缺乏对多用户、多对话场景的内置支持,而这对于实际的对话式人工智能系统至关重要。这些实现中的大多数已在
LangChain 0.3.x 中被正式弃用,取而代之的是 LangGraph 持久性。LangGraph 持久性非常灵
活,可以支持比 RunnableWithMessageHistory 接口更广泛的用例。
1.4 管理历史消息
1.4.1 前置概念
1.4.1.1 上下文窗口
管理历史消息,无非就是理解如何"管理","管理"无非也就是一些 "CRUD"。那么在了解如何
管理消息之前,需要先了解下多轮对话的核心概念:上下文窗口。
上下文窗口可以理解为模型的"短期工作记忆区",即 LLM 在**一次处理请求时,所能查看和处理的最大 Token 数量,**它包含了:
• 用户的输入
• 大模型的输出
• 有时还包括系统指令(SystemMessage)和对话历史。
Token
在自然语言处理(NLP)中,Token 是文本的基本单位。它不是完全等同于一个单词或一个汉字,而是一个更细粒度的划分。为什么用 Token?计算机无法直接理解文字,它需要将文本转换为数字(向量) 。Tokenization(令牌化)就是这个转换过程的第一步,将句子分解成模型可以理解和处理的碎片。
• 对于英文: 1个Token ~= 4个字符或0.75个单词,1000 个 Tokens 约等于 750 个英文单词。一个 Token 可以是一个单词(如 "apple" )、一个词根(如 "un" 在 "unlikely" 中),或者一个标点符号(如 "." )。例如, "ChatGPT is great!" 可能会被分成 "Chat","G", "PT", " is", " great", "!" 这 6 个 Token。
• 对于中文: 1个汉字 ~= 1.5-2个Tokens ,1000 个 Tokens 大约相当于 500-700 个汉字。常见
的词和字可能是一个 Token,生僻字或复杂词可能会被拆分成多个。
1.4.2 消息裁剪
多轮对话的实现原理,其实就是:
• 输入 = 系统消息 + 对话历史 + 最新用户问题
• 对于模型来说,并不真正"记忆",而是每次都将完整的上下文重新输入。
由于所有模型的上下文窗口大小都是有限的,这意味着作为输入的 Token 也是有限的。如果有累积了很长的消息历史记录,则需要管理传递给模型的消息的长度。trim_messages 可用于将聊天历史记录的大小减小 为指定的令牌计数或指定的消息计数。
1.4.2.1 基于输入 Token 数的修剪
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, trim_messages
# 1. 定义大模型(使用 OpenAI 的 GPT-4o-mini)
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 模拟一个包含多轮对话的历史消息列表
messages = [
SystemMessage(content="you're a good assistant"), # 系统消息:设定助手角色
HumanMessage(content="hi! I'm bob"), # 用户介绍自己
AIMessage(content="hi!"), # 助手回复
HumanMessage(content="I like vanilla ice cream"), # 用户说喜欢香草冰淇淋
AIMessage(content="nice"), # 助手回应
HumanMessage(content="whats 2 + 2"), # 用户问数学题
AIMessage(content="4"), # 助手回答 4
HumanMessage(content="thanks"), # 用户感谢
AIMessage(content="no problem!"), # 助手说不客气
HumanMessage(content="having fun?"), # 用户问是否开心
AIMessage(content="yes!"), # 助手回答是的
HumanMessage(content="What's my name?"), # 用户问自己的名字(需要上下文记忆)
]
# 3. 创建消息修剪器trim_messages,它是一个函数(方法)
#它返回一个 Runnable 对象。trimmer变量名,用来存储 trim_messages() 返回的那个 Runnable 对象。
# 作用:将消息列表修剪到不超过指定 token 数量,避免超出模型上下文长度
trimmer = trim_messages(
max_tokens=65, # 修剪后消息总 token 数的上限(可根据需要调整)
strategy="last", # 保留策略:"last" 保留最后的消息;"first" 保留最早的消息
token_counter=model, # 用于计算 token 数量的函数或模型(这里直接传入 model,它会自动使用 tokenizer)
include_system=True, # 是否始终保留系统消息(即使它不在"保留区域"内)
allow_partial=False, # 是否允许拆分消息内容(False 表示宁可多保留几条完整消息,也不截断单条消息)
start_on="human", # 确保修剪后第一条消息(不含系统消息)的类型为 "human",避免从助手消息开始
)
# 4. 应用修剪器,得到修剪后的消息列表
trimmed_messages = trimmer.invoke(messages)
# 可选:打印修剪前后的消息数量和内容,查看效果
print(f"原始消息数量: {len(messages)}")
print(f"修剪后消息数量: {len(trimmed_messages)}")
print("\n修剪后的消息内容:")
for msg in trimmed_messages:
print(f"{msg.type}: {msg.content}")
# 5. 将修剪后的消息发送给模型并获取回复
response = model.invoke(trimmed_messages)
print("\n模型回复:")
response.pretty_print()-
trim_messages是 LangChain 提供的消息修剪工具,用于在发送给 LLM 之前,自动将消息历史压缩到指定的 token 限制内,防止因对话过长而超出模型上下文窗口。 -
参数详解:
-
max_tokens:目标 token 上限,工具会尽可能使修剪后的消息总 token 数不超过该值。 -
strategy:修剪策略,"last"保留最近的消息,"first"保留最早的消息。 -
token_counter:用于计算每个消息 token 数的可调用对象,可以直接传入ChatOpenAI实例(LangChain 会调用其get_num_tokens方法)。 -
include_system:是否强制保留所有系统消息,即使它们在时间上较早。 -
allow_partial:若设为False,则不会截断某条消息的部分内容,而是完整保留或舍弃整条消息。 -
start_on:保证修剪后(忽略系统消息)的第一条消息类型为指定角色(如"human"),避免对话以助手消息开头。
-
-
执行流程 :先调用
trimmer.invoke(messages)获取修剪后的消息列表,再将该列表传入model.invoke()获取模型回复。
注意事项:
使用
token_counter=model需要安装tiktoken包,OpenAI 模型会自动使用它进行 token 计数。
trim_messages返回的是一个 Runnable 对象,需要调用.invoke()才能实际执行修剪。建议在实际对话场景中,每次调用模型前都动态修剪历史消息,以灵活控制上下文长度。
1.4.2.2 基于消息数的修剪
除了基于 token 的修剪,还可以通过设置 token_counter=len 根据消息数修剪聊天记录。在这
种情况下, max_tokens 将控制最大消息数。示例如下:
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, trim_messages
# 1. 定义大模型(OpenAI GPT-4o-mini)
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 历史消息记录(注意:原代码中列表定义有误,已修正为完整列表)
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
# 3. 使用 trim_messages 基于消息数进行修剪
# 设置 token_counter=len 表示按消息条数计数,此时 max_tokens 表示最大保留的消息数量
trimmer = trim_messages(
max_tokens=11, # 最大保留的消息条数(包括可能的系统消息)
strategy="last", # 保留策略:"last" 保留最后的消息;"first" 保留最早的消息
token_counter=len, # 关键:使用 len 函数按消息条数计数(而非 token 数)
include_system=True, # 是否始终保留系统消息(设为 True 时系统消息不计入 max_tokens 限制?实际上会强制保留,但仍占用条数)
allow_partial=False, # 是否允许拆分消息内容(基于条数时无效,因为不会拆分消息)
start_on="human", # 确保修剪后第一条消息(非系统消息)类型为 "human"
)
# 4. 执行修剪并打印结果
trimmed = trimmer.invoke(messages)
print(trimmed)
# 可选:打印每条消息以查看效果
print(f"\n修剪后共 {len(trimmed)} 条消息:")
for msg in trimmed:
print(f"{msg.type}: {msg.content}")-
token_counter=len:这是实现"基于消息数裁剪"的核心。trim_messages允许传入任意可调用对象来计算消息的"大小"。当传入len时,每条消息的计数就是 1,因此max_tokens就变成了最大消息数量。 -
max_tokens=11:由于原始消息列表共有 12 条消息(包含系统消息),设置max_tokens=11会从末尾保留 11 条消息,丢弃最前面的一条(本例中会丢弃系统消息吗?实际上因为include_system=True,系统消息会被强制保留,所以实际保留的消息会包含系统消息 + 最后 10 条非系统消息,总数为 11。) -
strategy="last":从末尾开始保留消息。若设为"first"则从开头保留。 -
start_on="human":确保修剪后的第一条消息(忽略系统消息后)是human类型,避免对话以assistant消息开头导致 LLM 行为异常。
1.4.3 消息过滤
在更复杂的场景下,我们可能会使用消息列表来跟踪状态 ,例如我们可能只想将这个完整消息列表的子集传递模型调用,而不是所有的历史记录。filter_messages 方法则可以轻松地按类型、ID 或名称过滤 message。下面演示相关过滤示例,首先准备消息列表:
python
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, filter_messages
# ========== 1. 准备消息列表 ==========
# 注意:SystemMessage, HumanMessage, AIMessage 的构造方法需要使用 content= 参数
messages = [
SystemMessage(content="你是一个聊天助手", id="1"), # id 用于唯一标识消息
HumanMessage(content="示例输入", id="2"),
AIMessage(content="示例输出", id="3"),
HumanMessage(content="真实输入", id="4"),
AIMessage(content="真实输出", id="5"),
]
# ========== 2. 示例一:按类型筛选 ==========
# 只保留 HumanMessage 类型的消息
filtered_by_type = filter_messages(messages, include_types="human")
# 或者使用链式写法:filter_messages(include_types="human").invoke(messages)
print("按类型筛选(只保留 human):")
for msg in filtered_by_type:
print(f"{msg.type}: {msg.content} (id={msg.id})")
# 输出示例(实际运行结果):
# human: 示例输入 (id=2)
# human: 真实输入 (id=4)
# ========== 3. 示例二:按类型 + ID 筛选 ==========
# 包含 HumanMessage 和 AIMessage,但排除 id 为 "3" 的消息(即第二条 AIMessage)
filtered_by_type_and_id = filter_messages(
messages,
include_types=[HumanMessage, AIMessage], # 可传入类型列表
exclude_ids=["3"] # 要排除的消息 ID 列表
)
print("\n按类型(HumanMessage + AIMessage)并排除 id='3':")
for msg in filtered_by_type_and_id:
print(f"{msg.type}: {msg.content} (id={msg.id})")
# 输出示例:
# human: 示例输入 (id=2)
# human: 真实输入 (id=4)
# ai: 真实输出 (id=5)-
filter_messages的作用从消息列表中选择一个子集,支持按类型(
include_types/exclude_types)、按 ID(include_ids/exclude_ids)、按名称(include_names/exclude_names)进行筛选。返回的是满足条件的消息列表。 -
参数说明
-
include_types:需要包含的消息类型,可以是字符串(如"human")或类(如HumanMessage),也可以是它们的列表。 -
exclude_ids:需要排除的消息 ID 列表。 -
其他常用参数:
-
exclude_types:排除的消息类型 -
include_ids:只包含的 ID 列表 -
include_names/exclude_names:按消息的name属性筛选
-
-
-
调用方式
-
可以直接调用
filter_messages(messages, ...)返回筛选后的列表。 -
也可以使用 Runnable 风格:
filter_messages(...).invoke(messages),这在链式操作中更灵活。
-
1.4.4 消息合并
若我们的消息列表存在连续某种类型相同的消息,但实际上某些模型不支持传递相同类型的连续消
息。意思是:消息列表里有时会出现两个相同角色的消息连在一起 (例如连续条 HumanMessage 或连续两条 AIMessage)。
但有些大模型的 API 要求消息必须是交替的(user / assistant / user / assistant ...),不允许连续出现相同角色。为了解决这个问题,LangChain 提供了 merge_message_runs ,它会把相邻的相同角色消息拼接成一条 ,保证发给模型的消息是交替的。使用 merge_message_runs 方法轻松合并相同类型的连续消息。
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, merge_message_runs
# 1. 定义大模型(以 OpenAI 为例)
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 原始消息列表(存在连续相同类型的消息)
messages = [
SystemMessage(content="你是一个聊天助手。"),
SystemMessage(content="你总是以笑话回应。"), # 连续两条 SystemMessage
HumanMessage(content="为什么要使用 LangChain?"),
HumanMessage(content="为什么要使用 LangGraph?"), # 连续两条 HumanMessage
AIMessage(content="因为你试图让你的代码更有条理时,LangGraph 会让你感到"节点"是个好主意!"),
AIMessage(content="不过别担心,它不会"分散"你的注意力!"), # 连续两条 AIMessage
HumanMessage(content="选择 LangChain 还是 LangGraph?"),
]
# 3. 合并相同角色的连续消息
merged = merge_message_runs(messages)
print("合并后的消息列表:")
for msg in merged:
print(f"{msg.type}: {msg.content}")
# 输出示例:
# system: 你是一个聊天助手。\n你总是以笑话回应。
# human: 为什么要使用 LangChain?\n为什么要使用 LangGraph?
# ai: 因为你试图让你的代码更有条理时,LangGraph 会让你感到"节点"是个好主意!\n不过别担心,它不会"分散"你的注意力!
# human: 选择 LangChain 还是 LangGraph?
# 4. 调用大模型的两种方式
# 方式一:先合并再直接 invoke
merged_messages = merge_message_runs(messages)
response1 = model.invoke(merged_messages)
print("\n方式一 模型回复:")
response1.pretty_print()
# 方式二:将 merge_message_runs 和 model 组合成一个链(推荐写法)
merger = merge_message_runs() # 创建一个可运行的合并器
chain = merger | model # 使用管道符组合,先合并后调用模型
response2 = chain.invoke(messages) # 直接传入原始消息列表,链会自动先合并再调用
print("\n方式二 模型回复:")
response2.pretty_print()-
merge_message_runs的行为-
仅合并相邻且角色相同的消息。
-
不同角色之间的顺序保持不变。
-
系统消息(
SystemMessage)也会合并(如果连续出现)。
-
-
两种调用模型的方式
-
方式一 :手动调用
merge_message_runs得到合并后的列表,再传给model.invoke。 -
方式二 :创建一个
merge_message_runs()可运行对象,然后用|与模型组合成链。直接调用链时可以传入原始消息,链会自动完成合并 + 调用模型
-
2. 提示词模板(Prompt Template)
关于提示词模板。这里只挑拣几个简单讲解,更多的去官方文档查询使用方法即可
2.1 概念
提示词模板(Prompt Template)是 LangChain 的核心抽象之一,它被广泛应用于构建大语言模型
(LLM)应用的各个环节。
简单来说,只要是需要动态、批量、或有结构地向大语言模型【发送请求】的地方 ,几乎都会用到提示词模板。
一个简单的例子,假设我们想根据一个城市名询问 LLM 其历史,按照之前的做法,我们可以定义
HumanMessage("请介绍上海的历史") 、HumanMessage("请介绍西安的历史") 消息等等。可
以发现每次询问都会描写重复的消息内容: 请介绍xxx的历史。
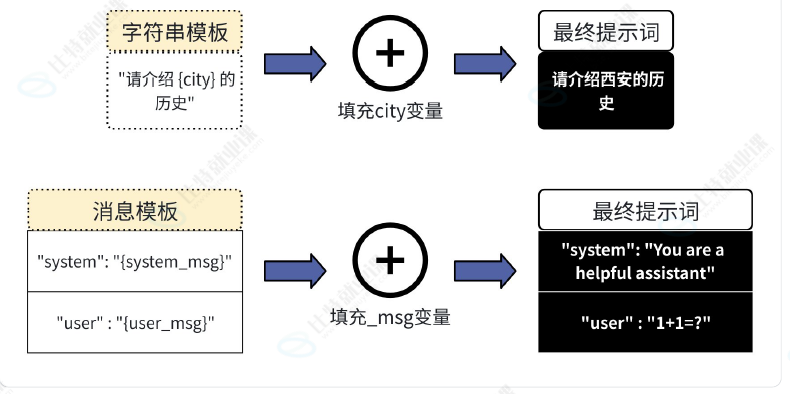
在 LangChain 中,针对这种情况,可以定义一个模板:
• 固定文本(模板): "请介绍{city}的历史。"
• 输入变量: "city"
定义好后,可以使用该模板:
• 当我们需要查询北京时,就将 city 变量赋值为 "北京"。模板引擎会生成: "请介绍北京的历
史。"
• 当我们需要查询上海时,就将 city 变量赋值为 "上海"。模板引擎会生成: "请介绍上海的历
史。"
提示词模板 就是一个可复用的提示词蓝图 ,它允许我们动态地生成提示词,而不是每次都手动编写完整的提示词。
它类似于编程中的字符串格式化功能 。你创建一个带有"占位符"的模板 ,然后在运行时,用具体的值(变量)填充这些占位符, 从而生成一个最终发送给 LLM 的完整提示词。
提示词模板解决了以下几个核心问题:
-
可复用性: 只需定义一个模板,就可以用于无数个类似的查询。
-
关注点分离: 将提示词的结构和逻辑(工程)与具体的内容和数据分离开。提示工程师可以专注于
优化模板,而应用程序则负责提供变量值。
-
一致性: 确保发送给LLM的提示词结构统一,这有助于获得更稳定、可预测的输出结果。
-
可维护性: 如果需要修改提示词的风格或结构,只需修改一个模板文件,而不用在代码的无数个地
方进行修改。
2.2 用法
2.2.1 字符串模板
LangChain 提供了 PromptTemplate 类来轻松实现这一功能。**PromptTemplate 实现了标准的
Runnable 接口。**示例如下:
python
from langchain_core.prompts import PromptTemplate
# 1. 定义模板:使用 {language} 作为占位符,运行时会被实际值替换
# from_template() 是类方法,根据模板字符串创建一个 PromptTemplate 实例
prompt_template = PromptTemplate.from_template("Translate the following into {language}")
# 2. 实例化模板:调用 invoke 方法,传入一个字典,键为占位符名称,值为要填充的内容
# 返回的是一个 PromptValue 对象,其 .text 属性或 str() 可得到最终字符串
result = prompt_template.invoke({"language": "Chinese"})
print(result) # 直接打印 PromptValue 对象会显示 text='...'
print(result.text) # 获取纯文本:Translate the following into Chinese
| 参数 | 描述 |
|---|---|
template |
提示模板字符串,包含用 {} 包裹的变量名。 |
input_variables |
模板中所有变量名的列表(通常自动从模板提取,也可手动指定)。 |
内置方法
| 方法 | 描述 |
|---|---|
from_template(template: str) |
类方法,根据模板字符串创建 PromptTemplate 实例。 |
invoke(input: dict) |
接收一个字典(变量名 -> 值),返回填充后的 PromptValue 对象。 |
更完整的示例(便于理解)
-
PromptTemplate实现了 LangChain 的 Runnable 接口,可以与模型通过|管道组合:prompt | model。 -
如果模板中使用了变量但未在
invoke传入,会抛出KeyError。
python
# 定义包含多个变量的模板
template = """
请根据以下信息回答问题:
问题:{question}
背景:{context}
"""
prompt = PromptTemplate.from_template(template)
# 填充变量
filled = prompt.invoke({
"question": "LangChain 是什么?",
"context": "LangChain 是一个用于构建 LLM 应用的框架。"
})
print(filled.text)
# 输出:
# 请根据以下信息回答问题:
# 问题:LangChain 是什么?
# 背景:LangChain 是一个用于构建 LLM 应用的框架。2.2.2 聊天消息模板
ChatPromptTemplate 模板:专为 LangChain 聊天模型设计。可以方便地构建包含
SystemMessage 、HumanMessage 、AIMessage 的消息模板。
python
# ==================== 1. 基础用法:创建包含 system 和 user 消息的模板 ====================
from langchain_core.prompts import ChatPromptTemplate
# 1.1 设置模板:使用元组列表定义消息序列,每个元组为 (角色, 内容模板)
# 支持的角色类型通常为 "system", "user", "ai"
prompt_template = ChatPromptTemplate(
[
("system", "Translate the following into {language}."), # 系统消息模板
("user", "{text}") # 用户消息模板
]
)
# 注释:在 langchain_core 0.2.24 版本后可直接使用 ChatPromptTemplate() 构造函数;
# 旧版本需要使用 ChatPromptTemplate.from_messages() 方法。
# 1.2 实例化模板:传入具体变量值,得到 PromptValue 对象
messages_value = prompt_template.invoke(
{
"language": "Chinese",
"text": "what is your name?"
}
)
# 1.3 将 PromptValue 转换为消息列表(包含 SystemMessage 和 HumanMessage 对象)
messages = messages_value.to_messages()
print(messages)
# 输出:
# [SystemMessage(content='Translate the following into Chinese.', ...),
# HumanMessage(content='what is your name?', ...)]
# ==================== 2. 进阶用法:与模型和输出解析器组合成链 ====================
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 2.1 定义大模型(以 OpenAI GPT-4o-mini 为例)
model = ChatOpenAI(model="gpt-4o-mini")
# 2.2 定义输出解析器:将模型响应转换为字符串
parser = StrOutputParser()
# 2.3 构建链:模板 -> 模型 -> 解析器
# 注意:ChatPromptTemplate 可以直接 invoke 返回消息列表,也可以直接放入链中
chain = prompt_template | model | parser
# 2.4 执行链:传入变量,自动完成模板填充 -> 模型调用 -> 解析
result = chain.invoke({"language": "Chinese", "text": "what is your name?"})
print(result) # 输出:你的名字是什么?-
ChatPromptTemplate的作用专为聊天模型设计,可以方便地定义多轮对话的消息模板(系统、用户、助手角色)。每个消息模板是一个
(role, template_string)元组。 -
两种调用方式
-
单独使用:
prompt_template.invoke(variables)→PromptValue,再调用.to_messages()得到消息列表,传递给模型。 -
链式调用:
prompt_template | model | parser,直接传入变量,自动完成模板填充、模型调用和输出解析。
-
-
输入变量的自动推断
ChatPromptTemplate会自动扫描所有模板字符串中的{variable}作为输入变量,无需手动指定input_variables。 -
常见角色类型
-
"system": 系统消息,设定模型行为。 -
"user": 用户消息。 -
"ai": 助手消息(通常用于少样本示例或对话历史)。 -
也可使用
HumanMessage,AIMessage等对象直接添加,但元组形式更简洁。
-
-
第一个
print(messages)输出的是SystemMessage和HumanMessage对象的列表,包含完整元数据。 -
链式调用最终打印的是模型翻译后的中文结果:
你的名字是什么?。
2.2.3 消息占位符
在上面的 ChatPromptTemplate 中,我们看到了如何格式化两条消息,每条消息都是一个字符串。但如果我们希望将消息插入特定位置怎么办?使用 MessagesPlaceholder :负责在特定位置添加消息列表。
python
# ==================== 方式一:使用 MessagesPlaceholder(推荐) ====================
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
# 1. 定义模板:包含系统消息和一个占位符(用于插入任意消息列表)
prompt_template = ChatPromptTemplate([
("system", "你是一个聊天助手"),
MessagesPlaceholder("msgs") # 参数为占位符变量名,运行时会将对应消息列表嵌入此处
])
# 2. 准备要插入的消息列表(通常是对话历史或动态生成的连续消息)
messages_to_pass = [
HumanMessage(content="中国首都是哪里?"),
AIMessage(content="中国首都是北京。"),
HumanMessage(content="那法国呢?")
]
# 3. 调用 invoke,将消息列表赋值给变量 "msgs",生成最终 PromptValue
formatted_prompt = prompt_template.invoke({"msgs": messages_to_pass})
# 4. 打印结果:可以看到系统消息后面依次插入了三条消息
print(formatted_prompt)
# 输出效果(简化):
# messages=[
# SystemMessage(content='你是一个聊天助手', ...),
# HumanMessage(content='中国首都是哪里?', ...),
# AIMessage(content='中国首都是北京。', ...),
# HumanMessage(content='那法国呢?', ...)
# ]
# ==================== 方式二:使用 ("placeholder", "{var}") 的缩写形式 ====================
# 不显式使用 MessagesPlaceholder 类,直接用元组 ("placeholder", 变量名) 效果相同
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import HumanMessage, AIMessage
prompt_template = ChatPromptTemplate([
("system", "You are a helpful assistant"),
("placeholder", "{msgs}") # 等价于 MessagesPlaceholder("msgs")
])
messages_to_pass = [
HumanMessage(content="中国首都是哪里?"),
AIMessage(content="中国首都是北京。"),
HumanMessage(content="那法国呢?")
]
formatted_prompt = prompt_template.invoke({"msgs": messages_to_pass})
print(formatted_prompt) # 输出结果与方式一完全一致-
什么是
MessagesPlaceholder它是一个特殊的占位符,允许你在聊天模板的任意位置嵌入一个完整的消息列表(而不是普通字符串)。通常用于:
-
插入多轮对话历史记录。
-
动态添加任意数量的上下文消息(如检索到的示例、用户的操作记录等)。
-
-
为什么需要消息占位符
普通的字符串占位符(如
{text})只能填充文本内容,而MessagesPlaceholder可以直接填充BaseMessage列表(HumanMessage、AIMessage等),保留每条消息的角色和元数据。 -
两种写法的区别与选择
-
推荐写法 :
MessagesPlaceholder("variable_name"),语义清晰,IDE 支持良好。 -
缩写写法 :
("placeholder", "{variable_name}"),更简洁,但不易发现可用的参数(如optional、n_messages等扩展参数)。
从 LangChain 0.2+ 开始,
MessagesPlaceholder还支持额外参数:optional=True(允许变量缺失而不报错)、n_messages=5(限制插入的消息数量)等,这些在缩写形式中无法使用。 -
-
与普通模板的区别
-
普通模板:
("user", "{text}")→ 填充的是纯文本,生成一条HumanMessage。 -
消息占位符:
MessagesPlaceholder("msgs")→ 将整个消息列表"展开"后嵌入,列表中的每条消息保持原样插入。
-
-
实际应用场景
python# 场景:需要将检索到的示例对话作为上下文插入到系统消息之后 prompt_template = ChatPromptTemplate([ ("system", "你是一个代码助手"), MessagesPlaceholder("few_shot_examples"), # 插入几个例子 ("user", "{user_input}") ]) examples = [ HumanMessage("如何反转列表?"), AIMessage("使用 list[::-1] 即可。"), HumanMessage("如何合并两个字典?"), AIMessage("使用 {**dict1, **dict2}。") ] final_prompt = prompt_template.invoke({ "few_shot_examples": examples, "user_input": "如何创建字典推导式?" })
扩展:MessagesPlaceholder 的更多参数(LangChain 0.3+)
python
MessagesPlaceholder(
variable_name="history",
optional=True, # 若 history 未提供,不会报错,直接忽略该占位符
n_messages=5 # 最多只取历史中的最后 5 条消息插入
)2.3 使用 LangChain Hub 的提示词模板
**LangChain Hub 是一个用于上传、浏览、拉取和管理提示词(prompts)的地方。**随着 LLM 的发展,提示变得越来越重要。LangChain 正在打造一个与像 GitHub 这样的传统平台,GitHub长期以来一直是共享和协作代码的首选平台。于是推出了 LangChain Hub 平台。
LangChain Hub 创建一个分享和发现 Prompt 的平台,使得开发者可以更容易地发现新用例和精炼提示。 这一举措使提示工程师更容易合作,重复使用现有的提示,并对其进行微调以实现特定的结果,从而加速对话代理和其他基于语言的应用程序的开发和部署。早期的时候 LangChain Hub 有Prompt、Chain、Agent,现在只有Prompt。
LangChain Hub 官网地址:中心 - LangSmith。通过登录到 Hub 来探索所有现有提示。
这里以提示词模板:hardkothari/prompt-maker 为示例,演示一下如何使用 LangChain Hub 上的提示。Prompt Maker 模板是一个【提示生成器】 ,它可以自动化优化提示的过程,从而提高语言模型在各种应用中的质量和效果。
要想使用该能力,需要先申请并配置LangSmith 环境变量 : LANGSMITH_API_KEY="你的LangSmith API Key" 。接着,需要从 hub 拉取相应的提示,并使用
python
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langsmith import Client
# ==================== 1. 设置 LangSmith API 环境变量 ====================
# 在代码中设置(不推荐生产环境使用,仅演示),或者提前在系统环境变量中配置好 LANGSMITH_API_KEY
# os.environ["LANGSMITH_API_KEY"] = "你的 LangSmith API Key"
# ==================== 2. 初始化 LangSmith 客户端 ====================
client = Client() # 自动从环境变量 LANGSMITH_API_KEY 中读取 API Key
# ==================== 3. 从 LangSmith Hub 拉取提示词模板 ====================
# 从 LangSmith Hub 拉取 hardkothari/prompt-maker 提示词模板
# include_model=False 表示只拉取提示词本身的定义,不附带关联的模型配置。
# 如果设置为 True,则会尝试同时加载模板中指定的模型配置(需要额外设置)
prompt = client.pull_prompt("hardkothari/prompt-maker", include_model=False)
# 4. 定义 LLM 模型:此处使用 OpenAI 的 GPT-4o-mini 模型
model = ChatOpenAI(model="gpt-4o-mini")
# 5. 构建处理链:提示词模板 → 大模型调用(此时模板还未"注入"用户输入)
chain = prompt | model
# 6. 交互式循环:接收用户输入的"任务"和"当前提示词",生成优化后的提示词并打印
while True:
# 6.1 获取用户当前的任务描述
task = input("\n你的任务是什么?(输入 quit 退出聊天)\n")
if task == 'quit':
break
# 6.2 获取用户当前的提示词/原始提示
lazy_prompt = input("\n你当前的提示是什么?(输入 quit 退出聊天)\n")
if lazy_prompt == 'quit':
break
# 6.3 将两个变量以字典形式传入链中调用,生成模型的回复并美化打印
print("\n Response:")
# 将 task 和 lazy_prompt 传递给链进行调用,注意字典的键名要与模板期望的变量名完全匹配
chain.invoke({'lazy_prompt': lazy_prompt, 'task': task}).pretty_print()
通过使用这个模板,可以大 减少手动调整提示所需的工作量,从而节省时间和资源。Prompt Maker通过分析初始提示的结构和内容,然后应用一组预定规则或算法来优化提示,以提高响应质量、清晰度和相关性。这在提示的质量对模型的输出有很大影响的场景中特别有用,比如客户服务机器人、对话代理或数据分析任务。