
点赞 * 关注 * 不迷路 如果结果不如你所愿,就在尘埃落定前奋力一搏。------《夏目友人帐》
有些事不是看到了希望才去坚持,而是因为坚持才会看到希望。------《十宗罪》
维持现状意味着空耗你的努力和生命。------纪伯伦
RAG 技术手册 * 第一章 认识RAG
第二节 RAG的技术原理
一. RAG的原理介绍
RAG 通过让大模型在回答问题前,先从指定的外部知识库中查找资料,从而确保答案的准确性和时效性。 来看下面的图:
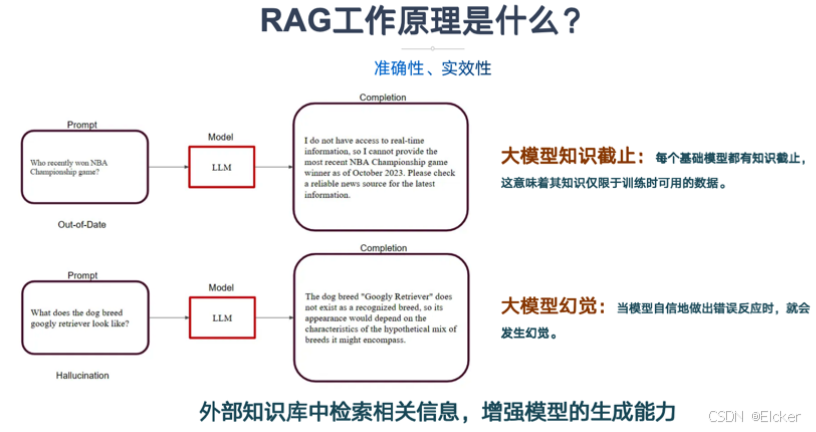
简单的理解就是在LLM模型回答问题前,先给他清晰的"答案",让他按照参考答案会大客户的问题。
二. RAG的工作流程
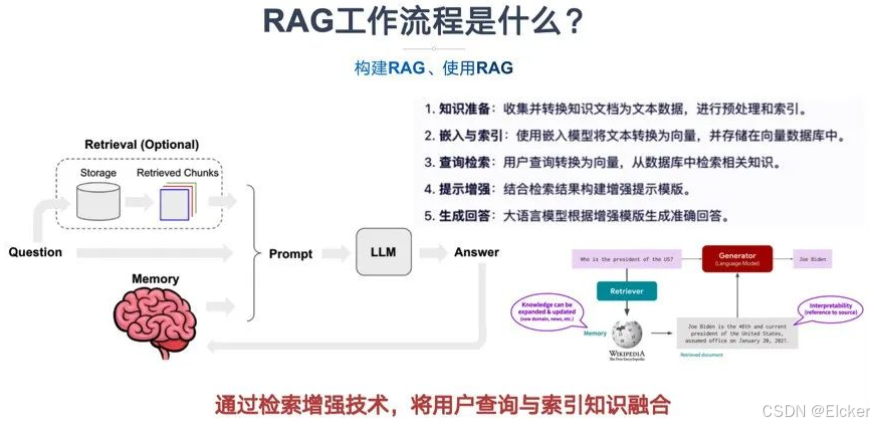
一个标准的 RAG 系统工作流程可分为两大阶段:离线数据预处理 和在线问答推理,详细的步骤可以归结为以下内容:
- 知识准备:收集并转换知识文档为文本数据,进行预处理和索引。(这个阶段是重点)
- 嵌入与索引:使用嵌入模型将文本转换为向量,并存储在向量数据库中。(本阶段涉及技术问题,使用向量在海量数据中检索,不是重点)
- 查询检索:用户查询转换为向量,从数据库中检索相关知识。(这各阶段是重点,用户的口语化严重,如何处理?)
- 提示增强:结合检索结果构建增强提示模版。(这个阶段技术重点,目前考虑更多的是成本问题)
- 生成回答:大语言模型根据增强模版生成准确回答。(输出格式问题,非重点)
来看下面的这张图:
下面我们重点介绍一些阶段的主要工作内容:
2.1 知识准备阶段 (构建知识库)
该阶段的目标是将海量的、非结构化的外部数据(如 PDF、Word、网页等)转化为模型可以快速检索的格式。
- 文档加载与清洗 (Loading & Cleaning): 从各种数据源加载文档,并进行清洗,去除乱码、页眉页脚、特殊符号等无效内容。
- 文本分块 (Chunking): 将长文档切分成固定长度、语义相对完整的短文本片段(Chunks)。这是必要的,因为 Embedding 模型有输入长度限制,且细粒度的片段能提升检索精度。
- 向量化 (Embedding): 使用 Embedding 模型将每个文本块转换为一个高维的稠密向量。这个过程将文本的语义信息编码成机器可以计算的数字形式,语义相似的文本,其向量在空间中的距离也更近。
- 向量入库 (Indexing): 将生成的向量和对应的原始文本块存入向量数据库中,并建立索引,以便后续进行高效的相似度搜索。
2.2 检索与生成阶段
当用户发出问题时,系统会实时地检索相关信息并生成答案。
- 用户提问 (User Query): 用户输入自然语言问题。
- 问题向量化 (Query Embedding): 使用与预处理阶段相同的 Embedding 模型,将用户的问题也转换为向量。
- 向量检索 (Vector Retrieval): 在向量数据库中,计算问题向量与所有文档块向量的相似度(通常使用余弦相似度),并召回最相关的 Top-K 个文本块。
- 重排序 (Reranking): (可选但推荐)对召回的文本块进行更精细的语义匹配打分,过滤掉弱相关内容,确保提供给大模型的上下文质量最高。
- 提示词拼接 (Prompt Augmentation): 将检索到的相关文本块、系统指令和用户原始问题,按照特定模板组合成一个新的、信息丰富的提示词(Prompt)。
- LLM 生成 (LLM Generation): 大模型接收到增强后的提示词,基于提供的上下文信息,生成最终准确、连贯的答案。
三. RAG的技术架构
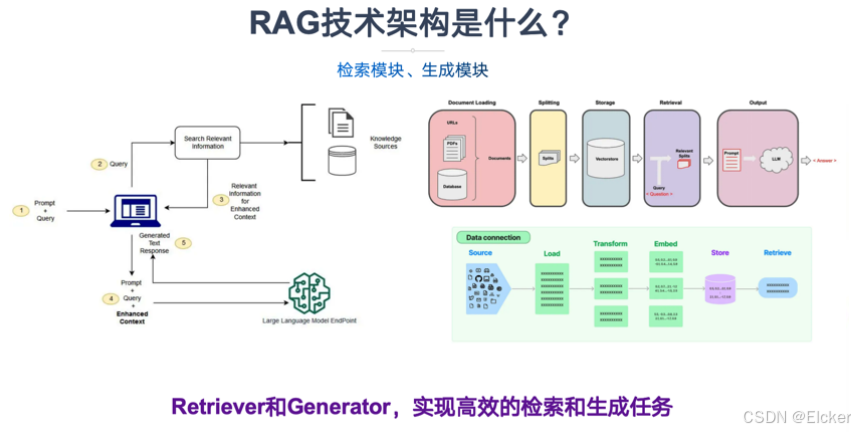
RAG(检索增强生成)的技术架构是一个精密的系统工程,旨在解决大模型"幻觉"、知识滞后和私有数据缺失的问题。我们一般将 RAG 的架构概括为:两大阶段与三大组件
3.1 阶段一 :索引构建
这是 RAG 的地基,通常在用户提问之前就已经完成。目标是:将海量的、非结构化的外部数据(如 PDF、Word、网页)转化为机器可以快速检索的格式。
3.2 阶段二:检索与生成
这是用户感知的实时交互过程。目标是:根据用户的问题,动态地从知识库中调取信息并生成答案。
3.3 三大组件
- 索引
- 检索器
- 生成器
3.4 架构图
3.5 RAG 系统的常见分层
一个成熟的RAG 系统通常包含以下核心组件:
| 核心层级 | 组件模块 | 关键技术/工具 | 作用 |
|---|---|---|---|
| 数据层 | 非结构化数据源 | PDF, Word, HTML, SQL | 知识的原始载体 |
| 向量数据库 | Milvus, Pinecone, Weaviate, Qdrant | 存储高维向量,支持毫秒级检索 | |
| 处理层 | 数据清洗与分块 | LangChain, Unstructured | 去除噪声,将长文切分为语义块 (Chunks) |
| 嵌入模型 | BGE, OpenAI Embedding, Text2Vec | 将文本转化为机器理解的向量 | |
| 服务层 | 检索引擎 | Hybrid Search (BM25 + Vector) | 结合关键词与语义检索,提高召回率 |
| 重排序模型 | Cross-Encoder, Cohere Rerank | 对初步检索结果进行精细化打分 | |
| 应用层 | 大语言模型 | GPT-4, Llama 3, Qwen | 理解上下文并生成最终答案 |
3.6 度量因素
-
混合检索架构 (Hybrid Search) :单纯依赖向量检索可能会丢失专有名词的精确匹配,单纯依赖关键词又无法理解语义。现代架构通常采用加权融合的方式,结合两者优势。
-
安全与权限 (Security) :架构中必须包含访问控制层 。例如,员工 A 只能检索到他有权访问的 HR 文档,这通常通过在向量数据库中存储元数据(如
department: "HR")并在检索时进行过滤来实现。 -
实时性 (Real-time) :架构中会引入 CDC (Change Data Capture) 技术,一旦源数据更新,立刻触发向量化和入库,实现知识库的秒级同步。
-
**数据安全:**数据的加密,脱密,日志记录;
-
**评估指标:**RAG的秩序迭代和优化参数的获取。
RAG 的技术架构本质上是一个**"搜索引擎 + 大模型"**的组合体,通过精细化的工程手段(分块、重排序、混合检索)来弥补大模型在记忆和推理上的短板。