一、Linux
不解压,直接查看压缩包内文件内容
递归统计当前目录下所有文件总行数
查看服务器开机运行时长
bash
zcat app.log.gz
find . -type f -exec cat {} \; | wc -l
uptime二、SQL
610. 判断三角形

sql
SELECT
x, y, z,
CASE
WHEN x + y > z AND x + z > y AND y + z > x
THEN 'Yes'
ELSE 'No'
END AS triangle
FROM Triangle;CASE 多条件分支 自定义字段
三角形判定核心:任意两边之和大于第三边
单列衍生标签,数仓打标签通用写法
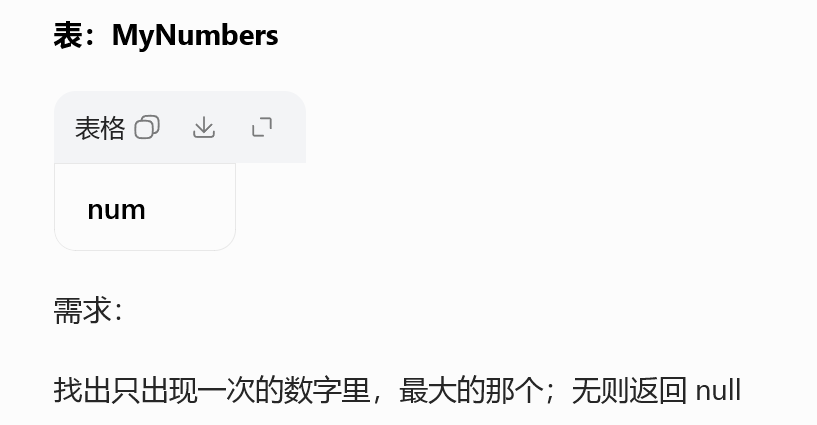
619. 只出现一次的最大数字
sql
SELECT MAX(num) AS num
FROM (
SELECT num
FROM MyNumbers
GROUP BY num
HAVING COUNT(*) = 1
) t;内层分组筛选单次数据
外层聚合取最大值
子查询嵌套、极值统计经典模板
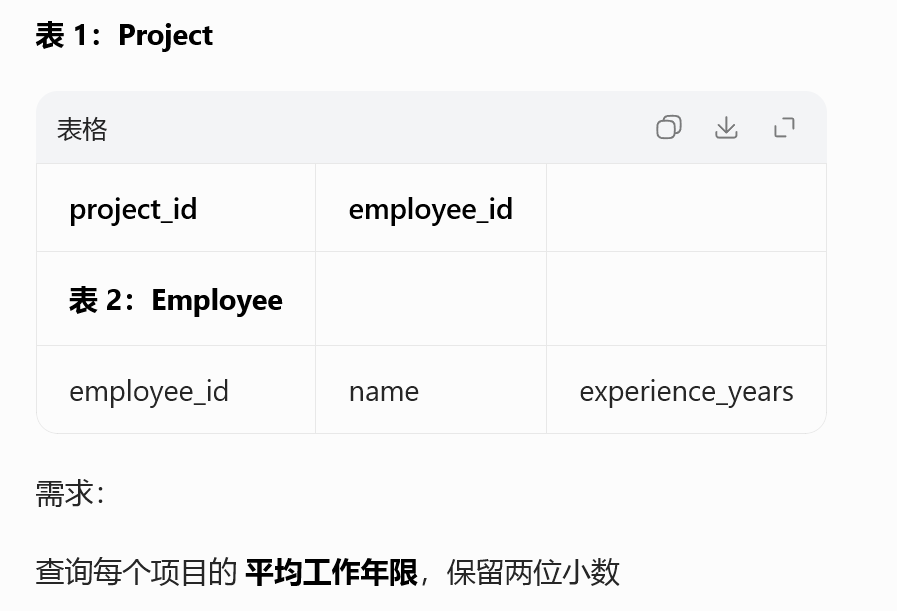
1075. 项目员工 I
sql
SELECT
p.project_id,
ROUND(AVG(e.experience_years), 2) AS average_years
FROM Project p
LEFT JOIN Employee e
ON p.employee_id = e.employee_id
GROUP BY p.project_id;多表 LEFT JOIN 关联维度表
AVG + ROUND 保留小数
项目 / 团队维度指标统计,贴合业务报表
三、Pyspark
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, round, count
spark = SparkSession.builder.master("local[*]").appName("Day23").getOrCreate()
# 1. 条件打标签 对应 LC610
tri = spark.createDataFrame([(3,4,5),(1,2,3)],["x","y","z"])
tri.createOrReplaceTempView("triangle")
spark.sql("""
SELECT x,y,z,
CASE WHEN x+y>z AND x+z>y AND y+z>x THEN 'Yes' ELSE 'No' END AS triangle
FROM triangle
""").show()
# 2. 分组筛选+求最大 对应 LC619
num_df = spark.createDataFrame([(1,),(2,),(2,)],["num"])
num_df.groupBy("num").count().filter(col("count")==1)\
.selectExpr("max(num) as num").show()
# 3. 多表关联+平均值保留2位 对应 LC1075
proj = spark.createDataFrame([(1,101),(1,102)],["project_id","employee_id"])
emp = spark.createDataFrame([(101,"A",3),(102,"B",5)],["employee_id","name","exp"])
proj.join(emp,on="employee_id")\
.groupBy("project_id")\
.agg(round(avg("exp"),2).alias("avg_year"))\
.show()
spark.stop()SparkSQL 直接复用 SQL 逻辑,快速迁移
分组过滤、聚合求值、小数保留
事实表 + 维度表关联,数仓日常开发标配
四、算法
python
class ListNode:
def __init__(self,val=0,next=None):
self.val = val
self.next = next
def reverseList(head):
pre = None
cur = head
while cur:
nxt = cur.next
cur.next = pre
pre = cur
cur = nxt
return pre