概念和样例
CREATE INDEX idx_name_age ON user(name, age);新建一个 B+Tree 文件(独立于原始表)---- 索引树
只存储索引字段:name + age + 主键 ID
按 name 排序组织数据
InnoDB 的二级索引(非主键索引)会自动包含主键 ID。
 、
、
二级索引需要通过主键 ID 回表查完整数据,所以自动带主键 ID
索引树
如果表结构是这样的:
ID=1, name='张三', age=25, phone='138xxx'
ID=2, name='李四', age=30, phone='139xxx'
ID=3, name='张三', age=28, phone='137xxx'索引树 (idx_name_age) 的存储结构:
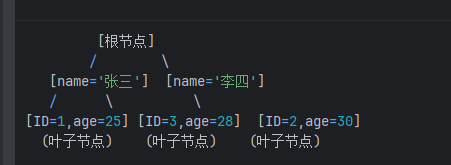
✅ 索引树里只有 name、age、主键 ID
没有 phone、address 等其他字段
✅ 按 name 字典序排列,查找极快
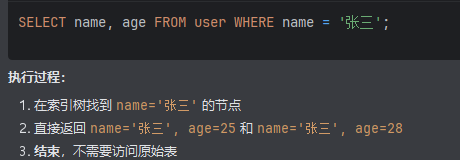
场景 1:覆盖索引(不用回表)
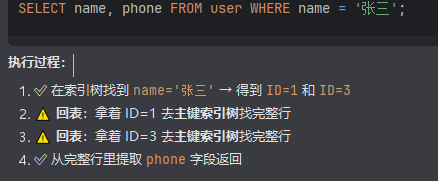
场景2:需要回表
主键索引树(聚簇索引)
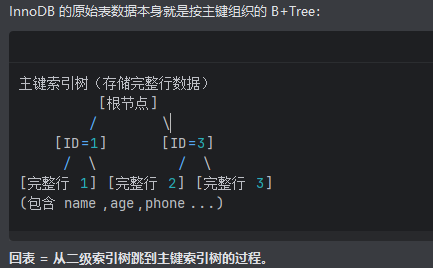
回表 = 从二级索引树跳到主键索引树的过程。
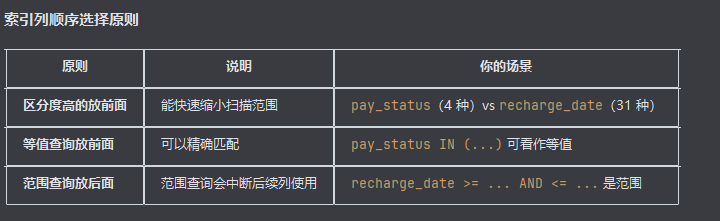
复合索引
之前创建了单个索引,进行查询的时候,没有命中索引
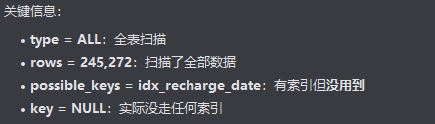
改成复合索引
ALTER TABLE a
ADD INDEX idx_recharge_pay_status (字段一, 字段二, 字段三);
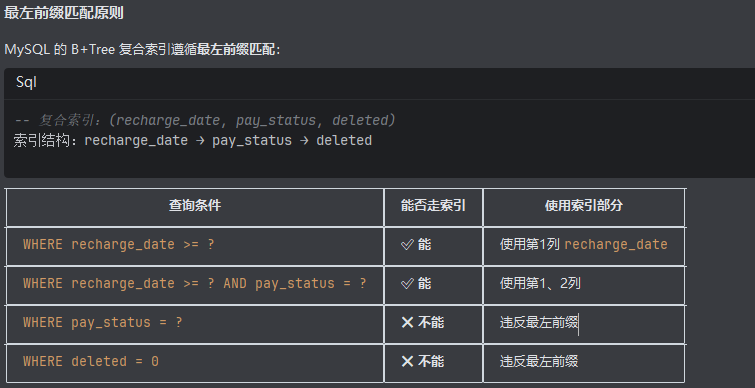
注意最左前缀匹配原则
虽然创建了 但还是有可能出现走全表查询,是因为
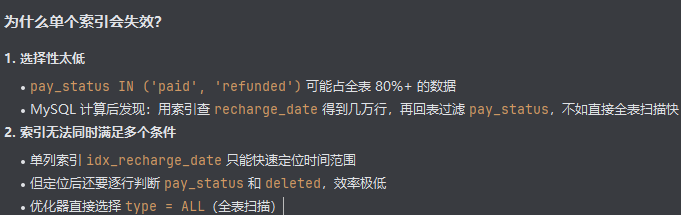
支付状态 IN ('支付', '已退款') 选择性太低
如果你的表里 80%+ 的订单都是已支付或已退款状态
MySQL 认为:走索引要回表几十万次,不如直接全表扫描
如果我的sql中的where 里面的字段顺序和创建索引的顺序不一样会怎么办
MySQL 的查询优化器会:
解析 SQL:提取所有 WHERE 条件
重新排序:按索引列顺序重新排列条件
选择执行计划:使用最优索引
但最好还是在代码层面保持一致。