一、核心定位与专业命名
专业技术栈 :Process Monitoring / System Resource Analysis / Performance Profiling
对应角色 :Linux 系统性能分析师 (Linux System Performance Analyst)
层级:User Space Monitoring Tools (Process Scheduling & Resource Utilization)
二、引言:进程监控的基石
在 Linux 系统中,top 命令族 构成了性能监控的基石。相比于图形化监控工具,命令行工具提供了更低的系统开销、更高的实时性和更强大的自动化能力。top、htop、atop、glances 等工具共同组成了一个完整的进程监控生态系统,它们各自针对不同场景进行了优化。
【技术注记】
当系统负载异常时,top 命令能够快速揭示 CPU、内存、I/O 的瓶颈所在。
三、核心工具族解析
3.1 top:经典进程监控器
top 是最基础、最广泛使用的进程监控工具,几乎所有 Linux 发行版都预装了它。
关键特性:
- 实时显示系统资源使用情况(CPU、内存、交换空间)
- 按 CPU 或内存使用率排序进程
- 支持交互式操作(如终止进程、更改优先级)
- 可定制显示字段
深度技术参数:
# 启动 top 并仅监控特定用户进程
top -u root
# 按内存使用排序(默认按 CPU)
top -o %MEM
# 显示完整命令行(避免截断)
top -c
# 以批处理模式运行,输出到文件(适合脚本)
top -b -n 5 > top_output.txt交互式命令:
| 按键 | 功能 | 适用场景 |
|---|---|---|
P |
按 CPU 使用率排序 | 诊断 CPU 密集型问题 |
M |
按内存使用率排序 | 诊断内存泄漏 |
k |
终止进程 | 快速结束异常进程 |
r |
调整进程优先级 | 临时提升关键进程优先级 |
1 |
显示所有 CPU 核心 | 多核系统负载分析 |
h |
显示帮助 | 快速查阅交互命令 |
3.2 htop:top 的现代化增强版
htop 是 top 的增强版,提供了更友好的用户界面和更多功能。
技术优势:
- 彩色显示,视觉区分更清晰
- 水平/垂直滚动查看完整命令行
- 鼠标支持(在终端中)
- 树状视图显示进程关系
- 更直观的 CPU/内存/交换空间使用率图表
高级使用技巧:
# 启动 htop 并过滤特定进程
htop -p $(pgrep -d',' nginx)
# 以只读模式启动(防止误操作)
htop -r
# 保存当前配置
htop --save-config交互式操作:
| 操作 | 功能 |
|---|---|
F2 |
设置 |
F3 |
搜索 |
F4 |
过滤 |
F5 |
树状视图 |
F9 |
发送信号 |
F10 |
退出 |
3.3 atop:系统资源历史记录器
atop 不仅提供实时监控,还能记录系统资源使用情况的历史数据。
核心功能:
- 每 10 分钟自动记录系统状态
- 可查看历史资源使用情况
- 特别适合诊断间歇性性能问题
- 详细记录磁盘 I/O 和网络使用情况
实战应用:
# 查看昨天的系统资源使用情况
atop -r /var/log/atop/atop_20260429
# 查看特定时间段的记录(上午9点到10点)
atop -r /var/log/atop/atop_20260429 -b 09:00 -e 10:00
# 实时监控并高亮显示异常进程
atop -m # 高亮内存使用异常
atop -d # 高亮磁盘 I/O 异常关键指标解读:
| 指标 | 含义 | 异常阈值 |
|---|---|---|
MEM |
内存使用率 | >85% 持续出现 |
SWP |
交换空间使用率 | >20% 持续出现 |
DSK |
磁盘繁忙率 | >70% 持续出现 |
NET |
网络使用率 | >90% 持续出现 |
3.4 glances:跨平台系统监控工具
glances 是一个更全面的系统监控工具,支持多种输出格式和远程监控。
技术特点:
- 支持 Web 界面监控
- 可通过 API 集成到其他系统
- 支持 Docker 容器监控
- 提供历史趋势图表
高级配置:
# 启动 Web 服务器模式
glances -w
# 监控远程服务器
glances --client -s remote_server
# 以 CSV 格式输出到文件
glances -e -o csv > glances_data.csv四、核心配置与调优:top 命令族的高级应用
4.1 自定义 top 显示字段
top 允许用户自定义显示哪些进程信息字段,这对于特定场景的诊断非常有用。
# 1. 启动 top
# 2. 按 'f' 进入字段选择菜单
# 3. 使用上下键选择字段,空格键切换显示状态
# 4. 按 'd' 调整刷新间隔
# 5. 按 'W' 保存配置(会写入 ~/.toprc)推荐配置场景:
- CPU 瓶颈分析 :显示
TIME+(累计 CPU 时间)、NI(优先级) - 内存泄漏诊断 :显示
RES(常驻内存)、VIRT(虚拟内存)、SHR(共享内存) - I/O 密集型问题 :显示
SWAP(交换空间使用)、CODE(代码占用)
4.2 批处理模式与自动化监控
将 top 命令用于脚本和自动化监控是生产环境的常见做法。
# 每 5 秒采集一次 top 数据,共采集 10 次
for i in {1..10}; do
echo "=== Snapshot $(date) ===" >> top_monitor.log
top -b -n 1 >> top_monitor.log
sleep 5
done
# 使用 awk 提取特定进程的 CPU 使用率
top -b -n 1 | grep 'nginx' | awk '{print $9}'
# 将 top 数据转换为 JSON 格式(需要安装 jq)
top -b -n 1 | sed -n '/PID/,/load average/p' |
jq -R 'split("\n") | .[1:] | map(split(" ") | map(select(length > 0))) | {headers: .[0], data: [.[1:][]]}'4.3 集成到系统监控框架
将 top 命令族集成到 Prometheus/Grafana 监控体系中:
# 1. 安装 node_exporter(提供基础指标)
# 2. 使用 textfile collector 收集 top 数据
# 3. 创建收集脚本 /usr/local/bin/top_collector.sh
#!/bin/bash
top -b -n 1 | grep 'load average' | awk '{print "system_load_avg_1min", $12}' | sed 's/,//'
top -b -n 1 | grep 'Mem' | awk '{print "memory_used_percent", $4*100/$2}'
# 4. 配置 node_exporter 的 textfile collector 目录
# 5. 重启 node_exporter五、深水区:常见故障排查与"蓝屏症"对抗
在《025_Linux_EMMC相关指南》中,我们曾提及"蓝睡症";在进程监控领域,类似的"资源黑洞"与"隐形负载"同样致命。
5.1 症状一:top 显示 CPU 空闲率高,但系统响应缓慢
现象:top 显示 CPU 空闲率 (id) 高达 90%,但系统响应明显变慢。
排查路径:
# 1. 检查 I/O 等待 (wa)
top | grep 'Cpu(s)'
# 2. 使用 iostat 查看磁盘 I/O 情况
iostat -x 2 5
# 3. 检查是否有进程处于不可中断睡眠状态 (D 状态)
top -b -n 1 | grep ' D '
# 4. 使用 pidstat 查看进程 I/O 统计
pidstat -dl 2 5根治方案:
- 优化磁盘 I/O 操作,减少同步 I/O
- 考虑使用更快的存储设备或调整文件系统参数
- 对于网络文件系统,检查网络延迟和带宽
5.2 症状二:内存使用率持续上升,但无明显内存泄漏进程
现象:free 命令显示可用内存持续减少,但 top 中找不到占用大量内存的进程。
排查路径:
# 1. 检查缓存和缓冲区使用
top | grep 'Mem'
# 2. 查看 slab 分配器统计
cat /proc/slabinfo
# 3. 使用 slabtop 实时监控内核对象分配
slabtop -o
# 4. 检查内核模块是否泄漏
lsmod | sort -k2 -nr根治方案:
- 了解 Linux 内存管理机制:缓存不是问题,而是性能优化
- 如果是内核对象泄漏,更新内核或相关驱动
- 调整 vm 参数,如 vm.drop_caches
5.3 症状三:top 中显示大量僵尸进程 (Z 状态)
现象:top 显示大量状态为 Z 的进程,系统资源逐渐耗尽。
排查路径:
# 1. 统计僵尸进程数量
ps aux | grep 'Z' | wc -l
# 2. 查找僵尸进程的父进程
grep -l 'State:\sZ' /proc/[0-9]*/stat | xargs -I{} basename {} | xargs -I{} ps -o ppid= -p {}
# 3. 检查父进程是否正常处理 SIGCHLD
strace -p <父进程PID> 2>&1 | grep wait根治方案:
- 修复父进程,确保正确处理子进程退出
- 重启父进程(如果无法修改代码)
- 使用 systemd 的 Restart=always 策略自动重启服务
六、代码实战:自定义监控框架 (中势 Nerve-Rewrite)
以下展示如何实现一个基于 top 数据的自动化监控框架。我们将此框架命名为 hlth_top_monitor.c (Health Check Top Monitor)。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#define HLTH_TOP_INTERVAL 5 // 监控间隔(秒)
#define HLTH_CPU_THRESHOLD 80 // CPU 使用率阈值(百分比)
#define HLTH_MEM_THRESHOLD 90 // 内存使用率阈值(百分比)
/* 获取系统 CPU 使用率 */
float get_cpu_usage() {
FILE *fp;
char buffer[256];
unsigned long user, nice, system, idle, iowait, irq, softirq, steal;
static unsigned long prev_user = 0, prev_nice = 0, prev_system = 0, prev_idle = 0;
fp = fopen("/proc/stat", "r");
if (!fp) return -1.0;
fgets(buffer, sizeof(buffer), fp);
sscanf(buffer, "cpu %lu %lu %lu %lu %lu %lu %lu %lu",
&user, &nice, &system, &idle, &iowait, &irq, &softirq, &steal);
fclose(fp);
unsigned long total = user + nice + system + idle + iowait + irq + softirq + steal;
unsigned long prev_total = prev_user + prev_nice + prev_system + prev_idle;
float idle_diff = idle - prev_idle;
float total_diff = total - prev_total;
prev_user = user;
prev_nice = nice;
prev_system = system;
prev_idle = idle;
if (total_diff == 0) return 0.0;
return 100.0 * (total_diff - idle_diff) / total_diff;
}
/* 获取系统内存使用率 */
float get_mem_usage() {
FILE *fp;
char buffer[256];
unsigned long total, free, available;
fp = fopen("/proc/meminfo", "r");
if (!fp) return -1.0;
while (fgets(buffer, sizeof(buffer), fp)) {
if (sscanf(buffer, "MemTotal: %lu kB", &total) == 1) continue;
if (sscanf(buffer, "MemAvailable: %lu kB", &available) == 1) break;
}
fclose(fp);
if (total == 0) return -1.0;
return 100.0 * (total - available) / total;
}
/* 检查并报告异常 */
void check_and_report() {
float cpu = get_cpu_usage();
float mem = get_mem_usage();
if (cpu < 0 || mem < 0) {
fprintf(stderr, "[ERROR] Failed to get system metrics\n");
return;
}
printf("[METRIC] CPU: %.2f%%, Memory: %.2f%%\n", cpu, mem);
if (cpu > HLTH_CPU_THRESHOLD) {
printf("[ALERT] High CPU usage detected: %.2f%% > %d%%\n", cpu, HLTH_CPU_THRESHOLD);
// 这里可以添加自动处理逻辑,如记录 top 输出
system("top -b -n 1 > /var/log/hlth_top_cpu.log");
}
if (mem > HLTH_MEM_THRESHOLD) {
printf("[ALERT] High memory usage detected: %.2f%% > %d%%\n", mem, HLTH_MEM_THRESHOLD);
// 这里可以添加自动处理逻辑,如记录内存详细信息
system("free -h > /var/log/hlth_top_mem.log");
}
}
int main() {
printf("HLTH Top Monitor started. Checking every %d seconds...\n", HLTH_TOP_INTERVAL);
while (1) {
check_and_report();
sleep(HLTH_TOP_INTERVAL);
}
return 0;
}【技术注记】
该监控框架直接读取
/proc文件系统,避免了调用外部命令的开销。在生产环境中,可以将其集成到 systemd 服务中,并配置邮件或短信告警。
七、Gauging 框架连通性与状态机描述
7.1 监控状态机定义 (FSM)
Linux Top 命令族深度解析与实战指南
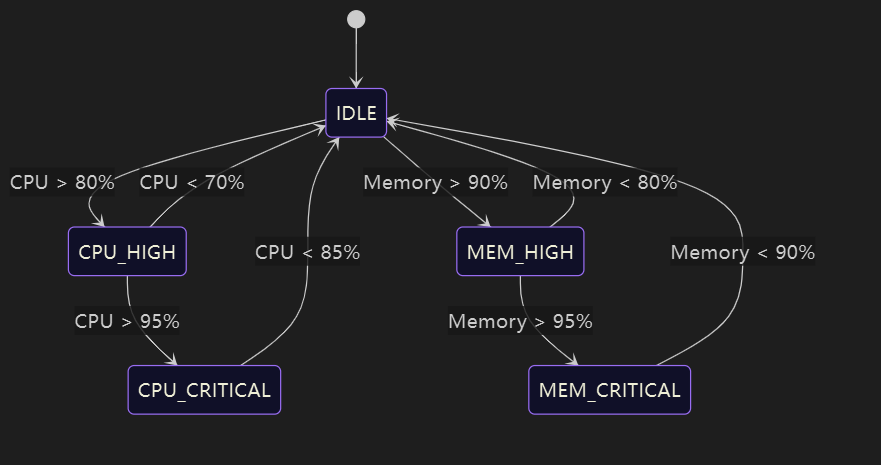
7.2 连接性检测脚本
#!/bin/bash
# gauging_top_connectivity.sh
# 描述:实时绘制 top 命令族的连通性与状态
while true; do
clear
echo "=== [GAUGING] Top Command Family Status ==="
# 检查 top 命令是否存在
if command -v top &> /dev/null; then
echo "[OK] top command available"
echo "Top version: $(top -v | head -1)"
else
echo "[ERROR] top command not found"
fi
# 检查 htop 命令是否存在
if command -v htop &> /dev/null; then
echo "[OK] htop command available"
echo "Htop version: $(htop -v | head -1 | awk '{print $2}')"
else
echo "[WARNING] htop command not found (recommended for enhanced monitoring)"
fi
# 检查 atop 命令是否存在
if command -v atop &> /dev/null; then
echo "[OK] atop command available"
echo "Atop version: $(atop -v | head -1 | awk '{print $2}')"
else
echo "[WARNING] atop command not found (recommended for historical analysis)"
fi
# 检查 glances 命令是否存在
if command -v glances &> /dev/null; then
echo "[OK] glances command available"
echo "Glances version: $(glances -v | head -1 | awk '{print $2}')"
else
echo "[WARNING] glances command not found (recommended for web-based monitoring)"
fi
echo "\n=== [METRIC] Current System Status ==="
top -b -n 1 | grep 'load average' | sed 's/^/Load Average: /'
free -h | grep 'Mem:' | awk '{print "Memory: " $3 "/" $2 " (" $3*100/$2 "%)"}'
sleep 5
done八、附录:高级技巧与配置速查表
8.1 top 命令配置文件
top 的配置保存在 ~/.toprc 文件中,可以手动编辑或通过 top 的交互界面保存。
# 示例 ~/.toprc 配置
RCfile for "top with windows" # site-specific settings here
Id:a, Mode_id:0, Delay:3.0, Curwin:0
Def fieldscur=AEHIOQTWKNMbcdfgjplrsuvyzX
winflags=24577, sortindx=10, maxtasks=0
summclr=1, msgsclr=1, headclr=3, taskclr=1
Job fieldscur=ABcefgjlrstuvyzMKNHIWOPQDX
winflags=62777, sortindx=0, maxtasks=0
summclr=6, msgsclr=6, headclr=7, taskclr=68.2 常用组合命令速查
| 场景 | 命令 | 说明 |
|---|---|---|
| 查看最耗 CPU 的进程 | top -o %CPU |
按 CPU 使用率排序 |
| 查看最耗内存的进程 | top -o %MEM |
按内存使用率排序 |
| 监控特定用户进程 | top -u username |
只显示指定用户的进程 |
| 监控特定进程ID | top -p 1234,5678 |
只显示指定PID的进程 |
| 诊断 I/O 问题 | iotop -o |
显示实际进行 I/O 的进程 |
| 分析内存使用 | smem -t -k |
显示 PSS(比例集大小)内存指标 |
hi,《嵌入式C语言最隐蔽的100个错误,第3个连10年老手都踩过》,我整理了10年嵌入式开发用C语言的 '坑',多年积累的100个高频致命错误,附赠10个面试加分项,整理成PDF手册, 每个案例附错误代码+正确代码+编译器表现+AI排查Prompt。如果你也想用AI辅助排查C语言Bug,希望这本手册可以帮上你的忙。
📌 手册获取:闲鱼搜「球场上的23号小帅哥」,9.9元 拍下秒发。
🔧 限量特价,满100单恢复19.9元原价。
------嵌入式AI实战-chen
九、参考文献与延伸阅读
- Linux Performance, Brendan Gregg. (系统性能分析圣经)
- Linux /proc Filesystem Documentation (/proc 文件系统官方文档)
- Understanding Linux CPU Load (理解 Linux 负载平均值)
Source References: