
随着AI Agent的发展,AI Agent从问答查询工具向长期助手持续演进,持久记忆成为AI Agent的核心技术之一。当前行业普遍将向量数据库、Embeddings模型视为Agent记忆的标配模块,但多数开发者对"记忆存储的本质"存在理解不深------总是觉得向量数据库是唯一选择。谷歌云开源的Google Always On Memory Agent,以"去EMBEDDINGS化"SQLite替代向量数据库的极简方案,打破了这一认知惯性,这篇文章希望能让开发者们重新深入理解AI Agent记忆的本质。
第一部分:几个核心名词的解释
Google Always On Memory Agent是由谷歌云发布的开源AI Agent持久化记忆层,核心定位是让Agent可以简单的、持续的、随时的检索记忆存储。本质特征是通过三层Agent架构(Ingestion Agent多格式数据摄取、Consolidation Agent定时整合记忆、Query Agent语义化响应查询),让LLM直接担任记忆管理器,而非依赖中间存储工具。并且外延可以覆盖个人助手、小团队Copilot等领域场景,同时支持文本、图片、PDF等多格式数据输入与结构化文本存储。
去EMBEDDINGS化是指摒弃传统RAG流程中"文本→Embeddings向量→向量检索"的链路,直接让LLM理解原始信息并生成结构化的记忆记录。本质是将记忆的筛选、整理、检索逻辑从数学向量计算转移到LLM的语义理解上,核心改变是无需额外的Embedding模型与向量索引,以自然语言结构化存储替代高维向量。可以直观的理解为编译语言和脚本语言的区别。
SQLite替代向量数据库是指用轻量级关系型数据库SQLite替代专业向量数据库(如Pinecone、Milvus)作为Agent记忆存储载体。本质特征是依托SQLite的本地文件存储、低运维成本特性,将记忆以可编辑的结构化表形式存储,让LLM直接通过语义逻辑召回记忆,而非依赖向量相似度计算。
三个概念相互支撑,共同构成了Always On Memory Agent的极简架构:SQLite提供轻量化存储基础,去EMBEDDINGS化简化记忆链路,最终实现LLM主导的持久记忆管理。
第二部分:主流AI记忆系统横向对比
为让大家更直观的理解,这里将Google Always On Memory Agent与传统向量数据库方案、主流竞品Mem0(向量+知识图谱双存储)进行多维度的对比:
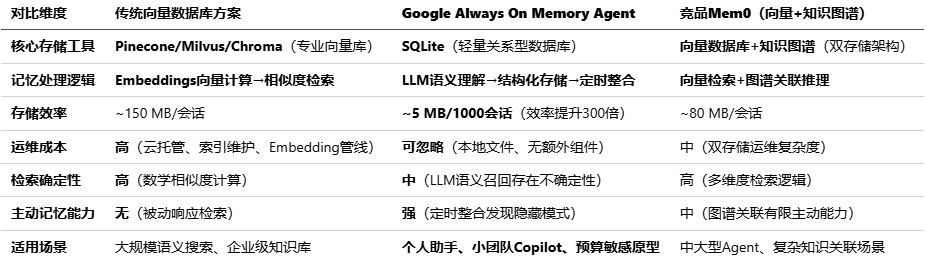
从对比可见,Always On Memory Agent的核心突破在于移除了中间层,从而将Agent记忆架构的复杂度降到最低;传统方案与竞品则更侧重规模化与检索精度,适用于对记忆召回确定性要求更高的场景。这三者之间并非替代关系,而是为了满足不同需求场景,增加了差异化选择的可能性。
第三部分:适用场景分析
核心差异分析
Always On Memory Agent与传统方案的核心差异是记忆管理主体的转移。传统方案是以向量数据库为核心,依赖数学计算实现记忆的存储与检索;Always On Memory Agent以LLM为核心,通过语义理解完成记忆的摄取、整合与召回,将"数据驱动的被动存储"转向"智能驱动的主动管理"。
适用场景
-
推荐场景:个人助手、小团队内部Copilot、隐私优先场景(数据本地存储)、预算敏感的原型验证、特定垂直领域的有界Agent。这类场景对记忆规模要求不高,更看重成本、简洁性与隐私性。
-
暂不推荐场景:大规模企业知识库(需精确召回)、强合规审计场景、对数据确定性要求极高的系统、跨平台共享记忆场景。此类场景下,传统向量数据库的规模化能力与检索确定性更具优势。
优劣势权衡
优势在于极简架构(无额外组件)、成本低廉(存储成本降低300倍,推理成本仅为高端模型的1/8)、可解释性强(结构化文本易人工检查)、隐私友好(本地SQLite存储);
劣势则体现在LLM驱动的不确定性(同一输入可能生成不同记忆)、规模化挑战(记忆量增大后依赖LLM上下文窗口,性能可能下降)、合规治理缺失(缺乏审计追踪与访问控制机制)。
写在最后
Google Always On Memory Agent并非向量数据库的对手
,而是AI Agent记忆架构的轻量化补充选项。不过它重新定义了Agent记忆的核心逻辑------从依赖技术工具的被动存储转向依托LLM智能的主动管理,印证了轻量化是技术一个永恒的方向的立场。
对于开发者而言,应跳出向量数据库=Agent记忆的思维定式,根据场景需求选择架构:小规模、成本敏感场景优先考虑轻量化方案,以减少运维负担;大规模、高确定性需求仍需传统向量数据库支撑。平衡技术简单性与业务需求,才是架构选择的核心原则。