在实时数仓、实时数据集成快速发展的今天,如何稳定、低延迟、低成本地把业务数据从数据库同步到下游系统,成为很多数据团队绕不开的话题。
过去,我们可能会选择 Canal + Kafka + 自研消费,或者离线同步工具 + 定时调度;如今,越来越多团队开始把目光投向一个新的选择:Flink CDC。
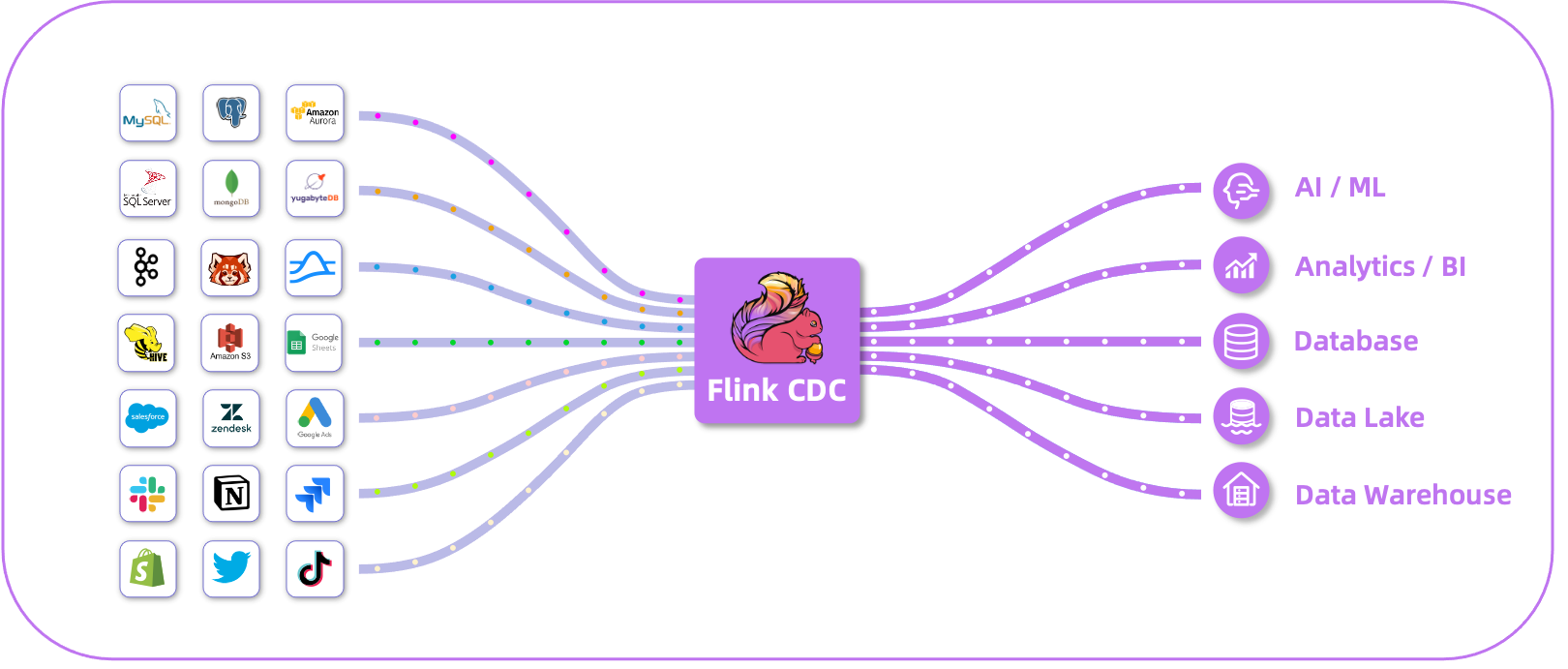
Flink CDC(Change Data Capture) 是一个基于 Apache Flink 的流式数据集成平台,用于实时捕获外部数据源中的数据变更(INSERT、UPDATE、DELETE 以及 DDL),并且将其以流的方式同步到下游系统(例如消息队列、数据库、数据仓库或数据湖)。
Flink CDC 深度集成并且由 Apache Flink 驱动,源代码托管在 GitHub:
https://github.com/apache/flink
功能特性
-
基于日志的 CDC:Flink CDC 通过解析数据库的操作日志,例如 MySQL Binlog、PostgreSQL WAL、Oracle Redo Log、MongoDB OpLog,实现低延迟(亚秒级)、低侵入、无锁的变更捕获,性能和一致性优于查询型 CDC。
-
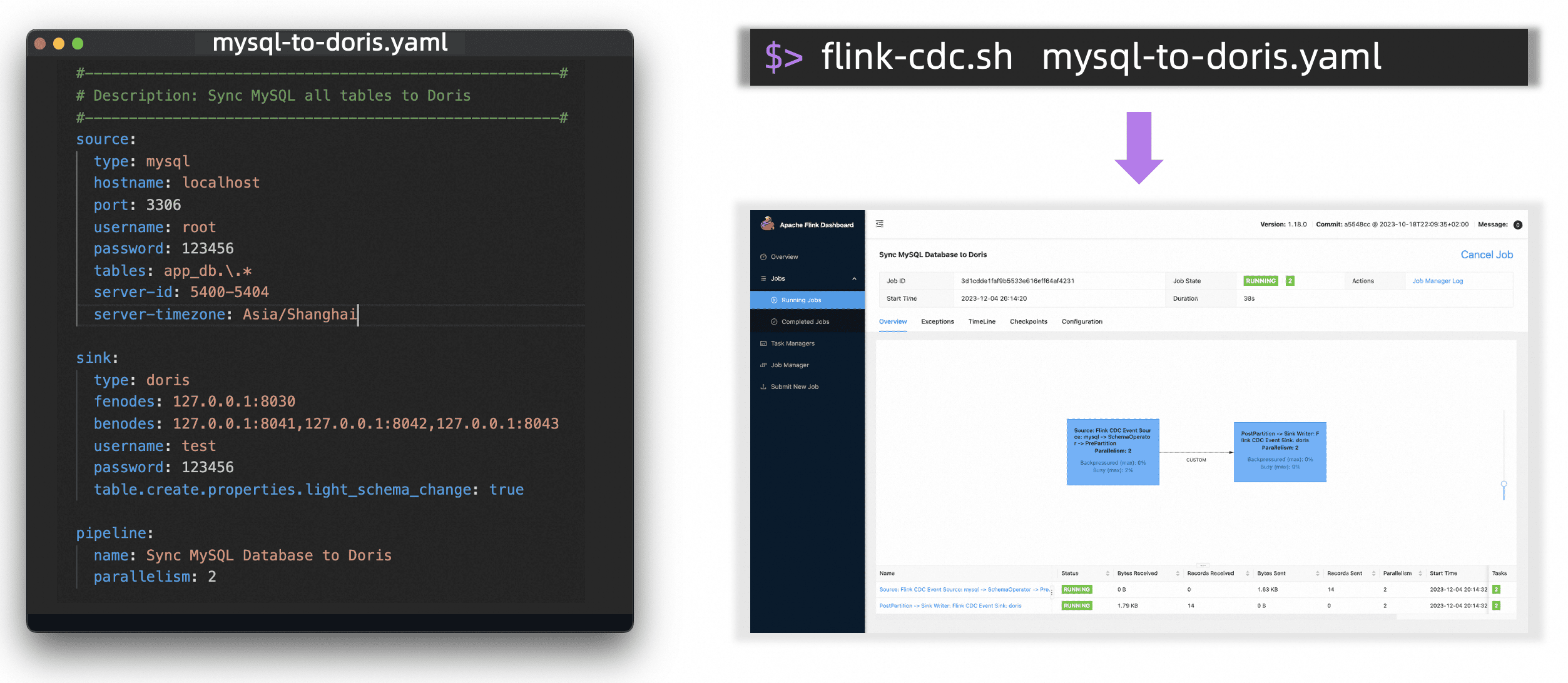
基于 YAML 的数据管道:使用基于配置文件的 Pipeline 模型自动生成并提交 Flink 作业,基本无需编写 Java 或者 SQL 代码,极大地降低了使用门槛。
-
丰富的连接器:Flink CDC 提供了丰富的连接器生态系统,用于与各种外部系统进行交互;数据源(Source)支持 MySQL、Oracle、PostgreSQL、Db2、MongoDB、SQL Server、TiDB、Vitess,目标(sink)支持 Apache Doris、Elasticsearch、Fluss、Hudi、Iceberg、Kafka、MaxCompute、OceanBase、Paimon、StarRocks。
-
表结构自动同步:Schema Evolution 功能可以用于将上游的 DDL 变更事件同步到下游,例如创建新表、添加新列、重命名列或更改列类型、删除列、截断和删除表等。
-
全量增量一体化:Flink CDC 提供增量快照框架,启动时自动做一致性全量快照,快照完成后无缝切换到增量日志。
-
精确一次语义:Exactly-Once 语义可以确保每一条数据变更在整个处理链路中一定且只被处理一次,同时只产生一次结果。
-
数据转换:Transform 模块允许用户对数据进行字段级或行级的加工处理,例如字段选择、重命名、派生字段或者函数计算。
-
路由规则:Route 代表一个路由规则,用来匹配一个或多个源表,并且映射到目标表。最常见的场景是合并子数据库和子表,将多个上游源表路由到同一个目标表。
配置示例
以下是一个 YAML 文件的示例,它定义了一个数据管道,可以从 MySQL 捕获实时变更,并且将它们同步到 Apache Doris:
yaml
source:
type: mysql
hostname: localhost
port: 3306
username: root
password: 123456
tables: app_db.\.*
server-id: 5400-5404
server-time-zone: UTC
sink:
type: doris
fenodes: 127.0.0.1:8030
username: root
password: ""
table.create.properties.light_schema_change: true
table.create.properties.replication_num: 1
pipeline:
name: Sync MySQL Database to Doris
parallelism: 2通过使用 flink-cdc.sh 提交以上 YAML 文件,一个 Flink 作业将会被编译并部署到指定的 Flink 集群。
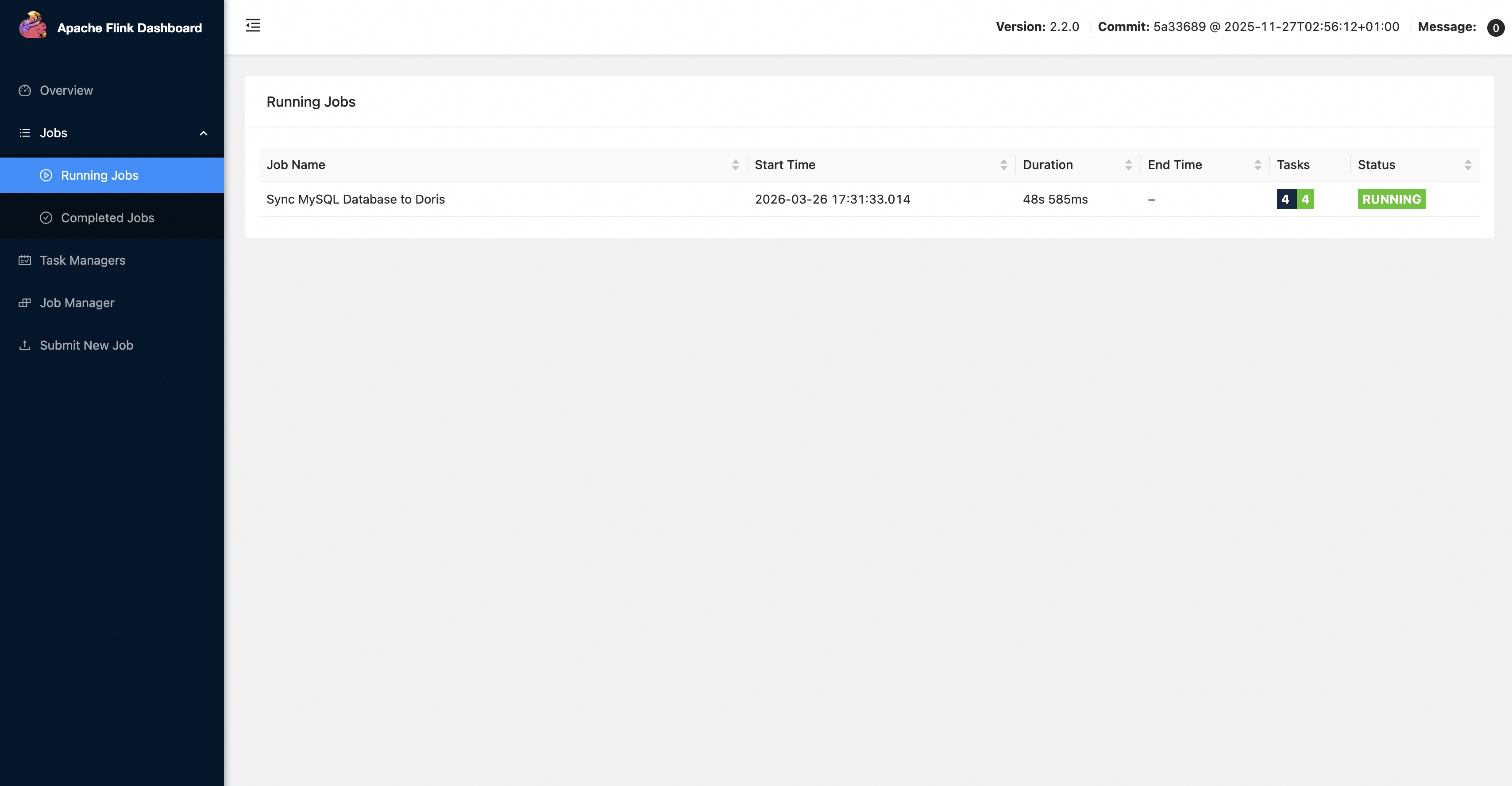
官方文档列出了常用的数据管道构建示例,参考文档:
https://nightlies.apache.org/flink/flink-cdc-docs-release-3.6/zh/docs/get-started/introduction/