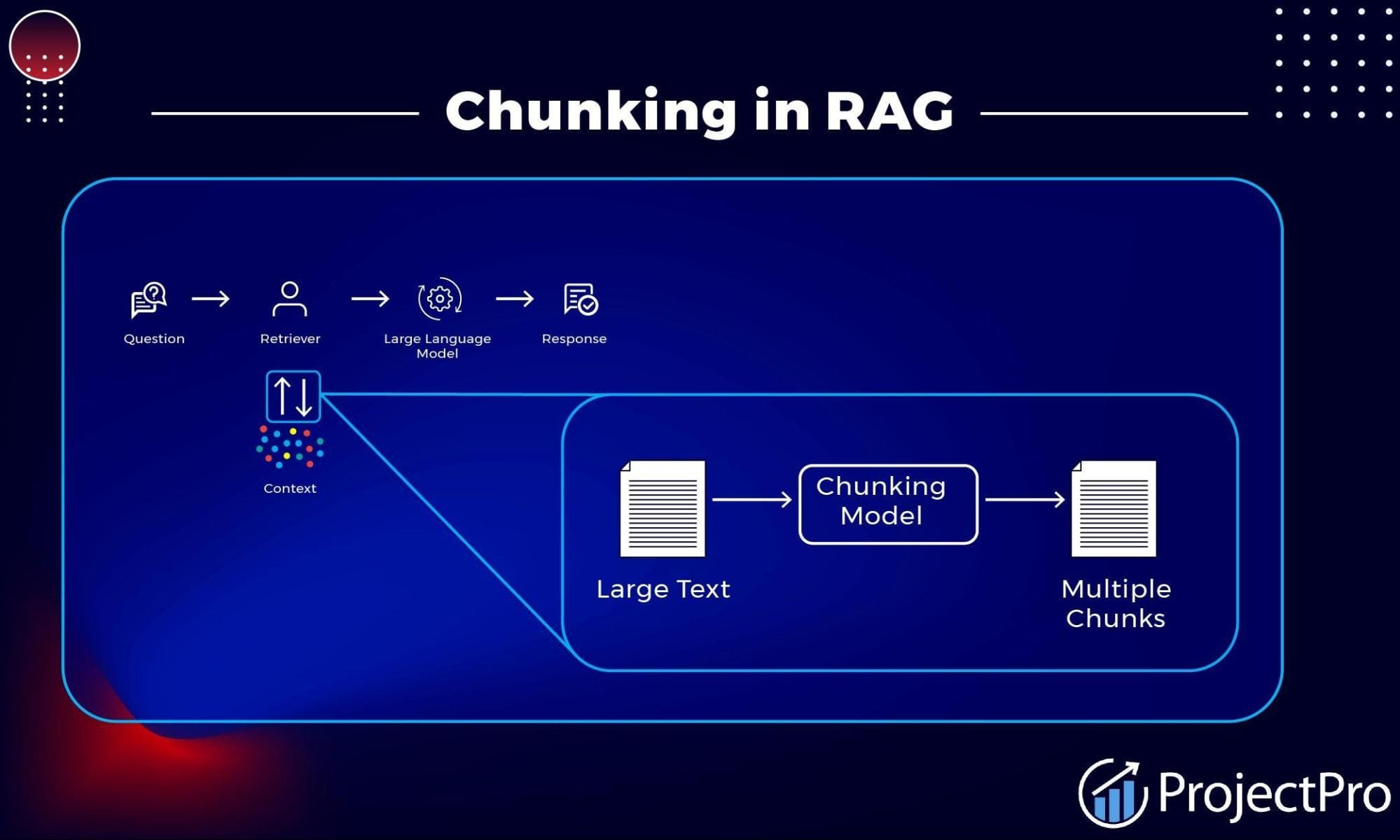
在RAG(检索增强生成)系统中,文档切分是将海量非结构化数据转化为大模型可理解知识的关键第一步。切分质量直接影响生成答案的准确性和连贯性。本文将深入解析六种主流切分算法,从简单的标点分割到复杂的语义理解,并结合LangChain实战代码和金融、法律等场景案例,为你揭示如何选择一个能真正保留"语义完整性"的切分策略。无论你是AI应用开发者还是技术决策者,都能从中找到优化检索质量的最佳实践。
引言:为什么说"切分"是RAG的灵魂?
想象一下,你向一个智能法律助手提问:"这份合同里的违约金条款是什么?"如果助手只看到半句"违约金为合同总额的...",而把关键的"20%"切到了另一个片段里,它的回答就会失效。这就是文档切分在RAG中的核心作用------它决定了检索到的"知识块"是否包含足够且完整的信息来回答问题。这个过程就像考试前划重点,好的切分是保证后续检索和生成质量的生命线。
下面,我们就由浅入深,逐一剖析六种文档切分算法。
算法一:按句子切分 ------ 最自然的停顿
原理 :模拟人的阅读习惯,利用句号、问号等标点作为切分边界,将文本拆解为独立的句子。
代码逻辑(Python伪代码):
def split_by_sentence(text):
sentences = text.split('。') # 中文句号切分
return [s.strip() + '。' for s in sentences if s]适用场景与局限 :非常适合新闻快讯、散文、对话记录等每句话信息量都相对独立的文本。但它的短板也很明显,比如复杂长句或列表会被拆散,不擅长处理标点不规范的口语。
算法二:固定字符数切分 ------ 机械的"剪刀手"
原理 :设定一个固定长度(如500字符),不考虑任何语义,切到哪算哪。
代码示例:
def chunk_by_fixed_size(text, chunk_size=500):
return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]应用案例 :处理一份格式极其统一的服务器Nginx日志,每行长度和信息结构都类似,用固定切分就能快速分块,快速检索错误代码。但它最著名的缺陷是"断章取义",比如把"深度求索公司"切成"深度求"和"索公司"。
算法三:带重叠窗口的固定切分 ------ 加上"安全垫"
原理 :在机械切分的基础上,让相邻文本块之间重叠一部分内容(通常为10%-20%),防止关键信息恰好落在边界上被切断。
实战参数设置(源于微软Azure建议) :从25%的重叠率开始调优。比如chunk_size=1000字符,chunk_overlap=250字符 。
应用场景 :技术手册等上下文强关联的文档。例如文档某处写着"压紧弹簧(如上图3所示)",如果"图3"被切入上一个块,重叠窗口就能保证当前块依然能引用到它。
算法四:递归切分 ------ 最聪明的"默认选项"
原理 :这是LangChain框架的默认方法 。它按照"段落 -> 句子 -> 单词 -> 字符"的逻辑层级尝试切分,优先保持文档的自然结构。
LangChain实战代码:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", " ", ""], # 中文优化优先顺序
chunk_size=500,
chunk_overlap=50
)
chunks = text_splitter.create_documents([text])参数优化经验 :对于中文知识库的问答系统,chunk_size设为200-500字符 通常能获得最佳检索精度;而文档总结类任务则建议放宽到800-1500字符。
算法五:语义切分 ------ 真正"读懂了"再切
原理 :利用嵌入模型 将句子转为包含语义的向量,通过计算相邻句子的余弦相似度来识别话题转折点。当相似度突然下降,就在此处切分。
高级方法示例(最大最小语义分块):
- 设定一个阈值(如0.6)。
- 判断下个句子与当前块内所有句子的最低相似度是否高于阈值。
- 是,则加入;否,则创建新的块。
高价值应用 :法律合同、学术论文等需要极致语义内聚的场景。比如《民法典》条款的检索,语义切分能完美分离"权力主体"和"责任客体"的不同段落,避免混淆。
前沿探索:基于AI模型的特化算法
原理 :直接利用大模型或专用模型的注意力机制,从底层理解文档逻辑,找出隐性的语义断点。
科研新思路:
- WADSeg:分析BERT模型注意力图特征,识别主题转移点。
- QChunker :让多个AI"专家"智能体相互辩论,共同决定最优的文本边界。
应用展望:这些方法目前多处于学术前沿,有望在未来彻底解决格式混乱、逻辑复杂的跨段落语义切分难题。
一张表看懂六种算法
| 算法 | 原理 | 核心优势 | 典型应用 | 关键参数/技术 |
|---|---|---|---|---|
| 按句子切分 | 按标点符号自然断句 | 速度极快,保留语言自然单元 | 新闻、对话、博客 | 标点符号库 |
| 固定字符切分 | 机械按字符数切割 | 实现简单,分块大小绝对可控 | 日志、传感器数据 | chunk_size |
| 带重叠窗口切分 | 固定切分 + 内容重叠 | 避免信息在边界丢失 | 技术手册、大型报告 | chunk_overlap(10-25%) |
| 递归切分 | 按层级结构回溯尝试 | 平衡了结构完整与大小控制 | 通用首选,几乎所有文档 | chunk_size,分界符优先级 |
| 语义切分 | 计算句子向量相似度 | 语义内聚性极高 | 法律、医学、专业论文 | 嵌入模型,相似度阈值 |
| AI模型切分 | 模型注意力或智能体辩论 | 理解隐式、复杂逻辑结构 | 前沿研究,尚未普及 | WADSeg,QChunker |
总结:构建你的切分质量检查清单
选择切分算法没有银弹,关键在于认识你的文档并评估效果。无论采用哪种策略,最终都要回到这张质量检查清单上,确保你的"知识块"是真正可用的:
- 语义完整性检查:一个完整的观点、条款或操作步骤,不应被切成两块。尤其警惕"但是"、"除外"等转折词后跟的内容被强行分离。
- 特殊结构保全 :表格和列表必须保持结构清晰。处理表格时,一个黄金法则是:每个文本块都应复制一份完整的表头,以免脱离上下文后数据失去含义。
- 上下文关联补救 :在元数据中为每个文本块记录其前后块的ID(
prev_chunk_id,next_chunk_id),让系统在需要时能像翻书一样,随时调取上下文,而不是仅靠一个孤立的片段回答问题。