文章目录
- 一、UMAP的核心思想
- 二、降维的动机与UMAP的优势
- 三、PCA与UMAP的核心区别
- 四、UMAP降维的步骤
-
- [1. 构建加权k-近邻图](#1. 构建加权k-近邻图)
- [2. 构建模糊拓扑表示](#2. 构建模糊拓扑表示)
- [3. 初始化低维嵌入](#3. 初始化低维嵌入)
- [4. 优化嵌入](#4. 优化嵌入)
- 五、使用scikit-learn实现UMAP
- 六、UMAP的核心参数详解
- 七、理解UMAP的嵌入结果
- 八、UMAP降维后效果评估
- [九、3D UMAP可视化](#九、3D UMAP可视化)
- 十、技巧:预计算k-近邻加速
- 十一、结论
- [十二、 相关文章](#十二、 相关文章)
UMAP,全称Uniform Manifold Approximation and Projection(均匀流形近似与投影),是一种基于流形学习理论的非线性降维算法。与传统的线性降维方法PCA相比,UMAP在保留数据的拓扑结构和局部邻域关系方面具有独特优势,尤其适用于单细胞测序、图像分析、自然语言处理等领域。本文将从原理、与PCA的关键区别、实现步骤、代码示例到参数调优,来介绍UMAP的使用方法与适用场景。
一、UMAP的核心思想
UMAP假设高维数据采样自一个低维流形,且该流形上的数据分布在局部是均匀的(通过自适应距离归一化实现),而不是整个流形上均匀分布。
- 流形学习:认为高维数据实际上分布在低维流形上,降维的目标是发掘这种潜在的流形结构。
- 保局部结构:UMAP优先保留数据的局部邻域关系,让原始空间中邻近的点在降维后依然靠近。
- 兼顾全局:UMAP相比 t-SNE能更好地避免将全局结构撕裂成多个孤立的簇,从而在可视化中呈现出更连贯的全局布局。
UMAP通过构建一个加权的k-近邻图来表示高维数据的拓扑结构,然后通过优化过程在低维空间中学习一个相似的图结构,最终得到降维后的表示。
二、降维的动机与UMAP的优势
在对比之前,先明确降维的通用动机:
维度灾难:高维数据中样本稀疏,模型需要更多样本才能有效训练。
可视化需求:人类无法直观理解超过3维的数据分布。
去冗余:许多特征间存在高度相关性。
在PCA的好处基础上,UMAP提供了额外的优势:
| 优势 | 说明 |
|---|---|
| 处理非线性关系 | PCA只能捕捉线性变化(如直线趋势),UMAP能发现弯曲、环形等复杂结构 |
| 保留局部拓扑 | 优先保证相似样本在降维后依然相近,适合发现子类别 |
| 计算效率高 | 相比t-SNE,UMAP速度更快,能处理百万级样本 |
| 可扩展性强 | 支持监督降维、预计算k-近邻图等高级功能 |
三、PCA与UMAP的核心区别
算法本质对比
| 方面 | PCA | UMAP |
|---|---|---|
| 数学原理 | 线性投影,最大化方差 | 流形学习,保留拓扑结构 |
| 保留关系 | 全局方差结构 | 局部邻域关系 + 部分全局结构 |
| 数据假设 | 线性关系、无强离群点 | 局部均匀分布在低维流形上 |
| 输出解释 | 各主成分是原始特征的线性组合 | 坐标无直接物理解释 |
| 可重复性 | 确定性算法,结果稳定 | 随机初始化,需设随机种子确保稳定 |
何时选择哪种算法
| 场景 | 推荐算法 | 原因 |
|---|---|---|
| 数据呈线性结构(如经济指标) | PCA | 简单高效,解释性强 |
| 需要保留全局方差结构 | PCA | 主成分贡献率明确 |
| 特征工程/预处理 | PCA | 降维后可逆,可用于重构 |
| 可视化高维聚类(如单细胞) | UMAP | 保留局部关系,簇间分离效果好 |
| 探索非线性结构 | UMAP | 发现流形结构 |
| 大规模数据(>10万样本) | UMAP | 计算效率高 |
四、UMAP降维的步骤
UMAP的核心流程分为四个阶段:
1. 构建加权k-近邻图
在高维空间中为每个点找到k个最近邻(k由n_neighbors参数指定),边的权重基于局部距离自适应调整。
2. 构建模糊拓扑表示
将k-近邻图转换为模糊单纯形集,形成对数据拓扑结构的数学表示。
3. 初始化低维嵌入
通常使用谱嵌入对低维坐标进行初始化(也可选择随机初始化或PCA初始化)。
谱嵌入是一种利用图论和线性代数(特征值分解)来寻找数据最佳低维表示的方法。
4. 优化嵌入
采用随机梯度下降(SGD)优化低维嵌入,使其模糊拓扑结构与高维表示尽可能相似。
五、使用scikit-learn实现UMAP
安装
bash
pip install umap-learn基础用法:可视化
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.preprocessing import StandardScaler
import umap
# 1. 加载数据(使用 scikit-learn 自带的 digits 数据集)
print("加载 digits 数据集...")
digits = load_digits()
X = digits.data # (1797, 64) - 8x8 图像展平
y = digits.target # (1797,) - 0-9 的数字标签
print(f"原始数据形状: {X.shape}") # (1797, 64)
print(f"样本数量: {X.shape[0]}")
print(f"特征维度: {X.shape[1]}")
print(f"类别数量: {len(np.unique(y))}")
# 2. 标准化(UMAP 对尺度敏感,建议标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. 执行 UMAP 降维
print("执行 UMAP 降维...")
reducer = umap.UMAP(
n_neighbors=15, # 局部邻域大小
n_components=2, # 降维目标维度
min_dist=0.1, # 嵌入点间最小距离
random_state=42 # 确保可重复性
)
X_umap = reducer.fit_transform(X_scaled)
print(f"降维后形状: {X_umap.shape}") # (1797, 2)
# 4. 可视化结果
plt.figure(figsize=(12, 10))
scatter = plt.scatter(X_umap[:, 0], X_umap[:, 1],
c=y, cmap='tab10', s=15, alpha=0.7)
plt.colorbar(scatter, ticks=range(10))
plt.title('UMAP visualization of Digits dataset (1,797 samples, 64-dim)', fontsize=14)
plt.xlabel('UMAP Component 1')
plt.ylabel('UMAP Component 2')
plt.tight_layout()
plt.show()
# 5. 打印一些统计信息
print(f"降维完成!")
print(f"原始维度: {X.shape[1]} → 降维后维度: {X_umap.shape[1]}")
print(f"UMAP 运行参数: n_neighbors={reducer.n_neighbors}, min_dist={reducer.min_dist}")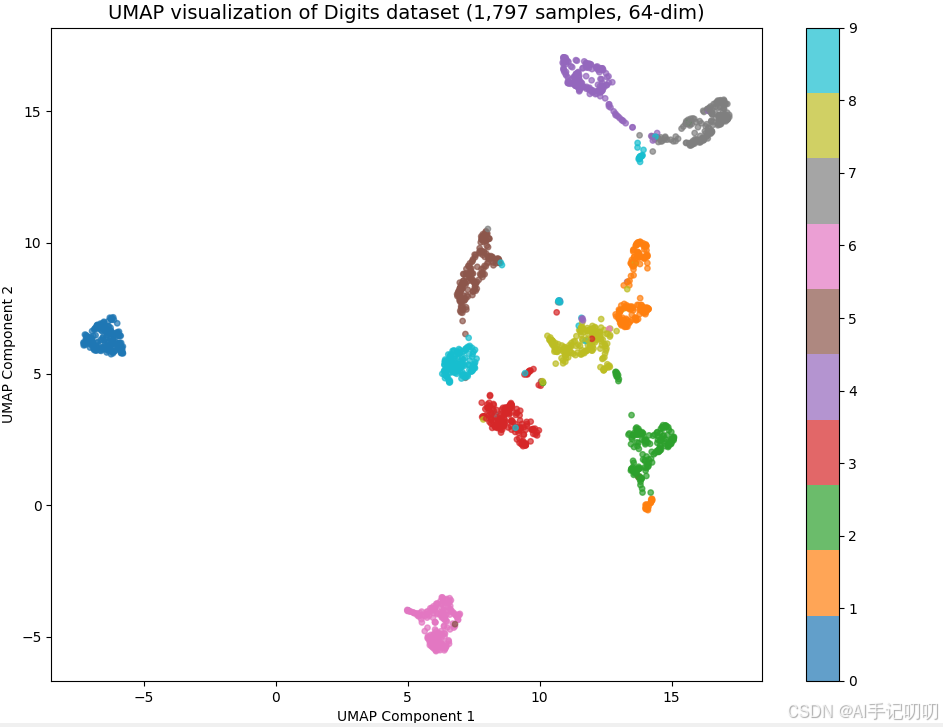
UMAP 建议进行标准化(尤其是使用欧氏距离时),除非所有特征已在可比尺度上。
在机器学习流水线中使用UMAP
与PCA类似,UMAP也可以无缝集成到scikit-learn的Pipeline中:
python
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_swiss_roll
import umap
# 1. 构造非线性数据集(瑞士卷)加上随机噪声
np.random.seed(42)
n_samples = 500
X, t = make_swiss_roll(n_samples=n_samples, noise=0.5, random_state=42)
# 添加大量随机噪声特征(100个无用特征)
X_noise = np.random.randn(n_samples, 100) * 2
X = np.hstack([X, X_noise]) # 3维结构 + 100维噪声 = 103维
# 二分类标签:基于瑞士卷位置
y = (t > np.median(t)).astype(int)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# 标准化(重要)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 2. 不使用UMAP(在高维噪声数据上训练)
svc = SVC(kernel='rbf', random_state=42, C=1.0)
svc.fit(X_train_scaled, y_train)
print(f"原始数据准确率: {svc.score(X_test_scaled, y_test):.3f}")
# 3. 使用UMAP降维
pipeline = Pipeline([
('scaler', StandardScaler()),
('umap', umap.UMAP(random_state=42, n_neighbors=15)),
('svc', SVC(kernel='rbf', random_state=42))
])
param_grid = {
'umap__n_components': [2, 5, 10, 20],
'svc__C': [0.1, 1, 10]
}
grid_search = GridSearchCV(pipeline, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
print(f"UMAP降维后最佳交叉验证准确率: {grid_search.best_score_:.3f}")
print(f"最佳参数: {grid_search.best_params_}")
# 在测试集上评估
test_score = grid_search.best_estimator_.score(X_test, y_test)
print(f"测试集准确率: {test_score:.3f}")在高维(103维)但样本量有限(500个)的场景下,UMAP可以作为流水线中的特征提取步骤,通过网格搜索自动选择最优的降维维度和分类器参数。
六、UMAP的核心参数详解
| 参数 | 含义 | 典型值范围 | 效果 |
|---|---|---|---|
n_neighbors |
局部邻域大小 | 5-100 | 越小越关注局部细节;越大越保留全局结构 |
n_components |
降维维度 | 2(可视化)至100 | 目标嵌入维度 |
min_dist |
嵌入点间最小距离 | 0.0-0.5 | min_dist 越小:局部结构更紧凑,但全局结构可能被拉长;min_dist 越大:嵌入更紧凑,但可能模糊簇边界。 |
metric |
距离度量 | 'euclidean', 'cosine', 'manhattan' | 根据数据类型选择 |
random_state |
随机种子 | 任意整数 | 关键:确保结果可重复 |
n_neighbors参数对结果的影响
n_components 定义了数据经由 UMAP 算法映射后的目标低维特征空间的维度数。其选择原则主要取决于下游任务的需求与数据内在流形的复杂度。
在该数据集上的实验表明:
- n_neighbors=2:嵌入完全失效,点散落成松散圆云,无法识别簇
- n_neighbors=15 :形成稳定、分离良好的簇,全局结构清晰(推荐起点)
选择n_components的一般原则
| 目标 | 推荐n_components |
说明 |
|---|---|---|
| 可视化(2D散点图) | 2 | 便于直接观察 |
| 可视化(3D交互图) | 3 | 可用plotly等库旋转查看 |
| 特征提取(替代PCA) | 10-100 | 根据下游任务交叉验证选择 |
| 保留局部结构 | 较低(2-5) | 强制压入低维 |
| 保留更多信息 | 较高(30-100) | 减少信息损失 |
七、理解UMAP的嵌入结果
与PCA不同,UMAP的低维坐标没有直接的物理解释。PCA的每个主成分是原始特征的线性组合,可以通过载荷(loadings)解释;而UMAP的坐标仅是嵌入空间中点的位置,用于显示相似性关系。
解读方式:
- 相对距离有意义:点越接近,表示原始空间中越相似
- 簇结构有意义:不同颜色的簇表示不同类型的样本
- 距离没有绝对尺度 :UMAP的
min_dist参数会压缩或分散点云
提取UMAP特征用于下游任务
python
# 将UMAP作为特征提取器
umap_featurizer = umap.UMAP(n_components=50, random_state=42)
X_umap_features = umap_featurizer.fit_transform(X_train)
# 现在X_umap_features可以替换X_train用于任何分类器
clf = RandomForestClassifier()
clf.fit(X_umap_features, y_train)这种"UMAP + 分类器"的两步法在单细胞RNA测序数据分析中尤为常见。
八、UMAP降维后效果评估
评估方法
| 方法 | 说明 |
|---|---|
| 可视化检查 | 观察簇是否分离、是否有意义 |
| k-近邻保留率 | 检查原始空间中的邻居在嵌入空间中是否仍是邻居 |
| 下游任务性能 | 用降维后的数据训练模型,比较准确率 |
| 轮廓系数 | 评估聚类分离程度 |
何时UMAP效果最佳
推荐使用UMAP的场景:
- 单细胞RNA测序数据(非线性、高噪声)
- 图像数据(像素间存在复杂非线性关系)
- 探索性数据分析,需发现非线性结构
- 样本量较大(>5000),t-SNE速度太慢
推荐使用PCA的场景:
- 需要特征解释性(理解每个主成分的含义)
- 数据确实接近线性结构(如某些物理测量)
- 降维后需要重构原始数据
- 作为线性模型的预处理步骤
准确性可能降低的原因
| 原因 | 说明 |
|---|---|
| 随机性 | UMAP的随机初始化可能导致次优嵌入,需设置random_state |
| 参数不当 | n_neighbors过小导致局部过拟合,过大则模糊簇边界 |
| 维度选择过低 | 强行压入2维可能丢失信息 |
| 数据不适合流形学习 | 如果数据完全随机分布、不构成低维流形结构,UMAP会失效 |
九、3D UMAP可视化
对于更精细的可视化需求,UMAP支持将数据降到3维,配合交互式绘图库(如plotly)可以获得更好的探索体验。
python
import plotly.express as px
import pandas as pd
from sklearn.datasets import make_classification
import umap
# 1. 构造高维分类数据集(300维,1000个样本)
X, y = make_classification(
n_samples=1000, n_features=300,
n_informative=250, n_classes=2, random_state=42
)
# 1. 降维到3维
reducer_3d = umap.UMAP(n_components=3, n_neighbors=15, random_state=42)
X_umap_3d = reducer_3d.fit_transform(X)
# 2. 构建DataFrame用于绘图
df_plot = pd.DataFrame({
'UMAP1': X_umap_3d[:, 0],
'UMAP2': X_umap_3d[:, 1],
'UMAP3': X_umap_3d[:, 2],
'Label': y # 将标签转换为字符串以便显示
})
# 3. 生成交互式3D图
fig = px.scatter_3d(
df_plot, x='UMAP1', y='UMAP2', z='UMAP3',
color='Label',
opacity=0.7,
title='3D UMAP Visualization'
)
fig.update_traces(marker=dict(size=2))
fig.show()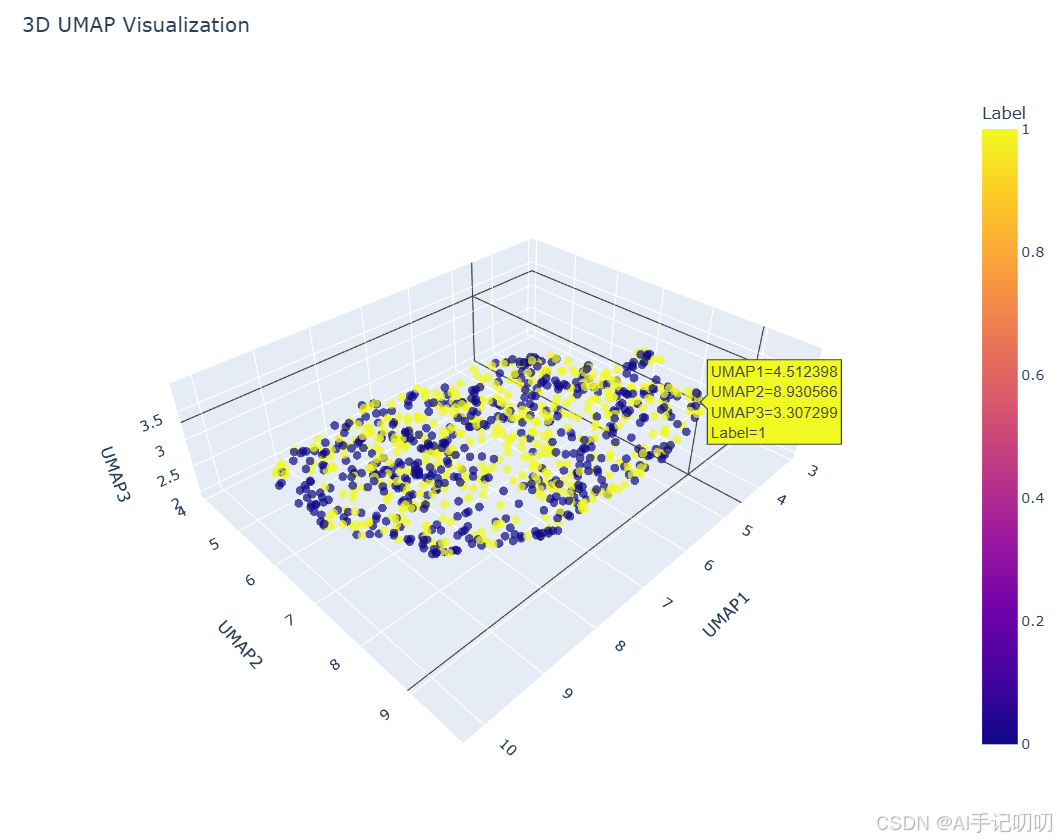
这种方式会生成的HTML文件支持鼠标拖拽旋转、缩放。
十、技巧:预计算k-近邻加速
对于需要多次尝试不同n_neighbors和min_dist参数的场景,可以预计算k-近邻图以避免重复计算:
python
from sklearn.datasets import make_classification
import umap
from umap.umap_ import nearest_neighbors
# 生成示例数据
X, y = make_classification(
n_samples=2000,
n_features=50,
n_informative=40,
random_state=42
)
print(f"原始数据形状: {X.shape}")
max_neighbors = 250
# 计算 k-近邻(返回索引和距离)
knn_indices, knn_dists, knn_search_params = nearest_neighbors(
X=X,
n_neighbors=max_neighbors,
metric='euclidean',
metric_kwds=None,
angular=False,
random_state=42,
verbose=False
)
# 使用预计算的 k-近邻图进行 UMAP 降维
umap_model = umap.UMAP(
n_neighbors=50,
n_components=2,
min_dist=0.1,
random_state=42,
precomputed_knn=(knn_indices, knn_dists)
)
X_umap = umap_model.fit_transform(X)
print(f"降维后形状: {X_umap.shape}")这种方法可以减少重复计算 k-近邻图的开销,尤其当需要多次调整 n_neighbors 参数时。
十一、结论
UMAP是目前最强大的非线性降维工具之一,在可视化质量和计算效率之间达到了优秀的平衡。
| 对比维度 | PCA | UMAP |
|---|---|---|
| 适合数据类型 | 线性 | 非线性流形 |
| 可解释性 | 高(主成分载荷) | 低 |
| 可视化质量 | 一般 | 优秀 |
| 计算效率 | 非常快 | 快(比t-SNE快) |
| 随机性 | 无 | 有(设种子可重复) |
选择建议:
- 做数据探索/可视化 :UMAP(尤其单细胞、图像、文本嵌入)
- 做标准化的特征工程 :PCA(更快、可解释、无随机性)
- 用完整流水线 :两者都可集成,用交叉验证对比
UMAP使用最佳实践:
- 始终设置
random_state以确保结果可重复 - 从
n_neighbors=15开始,根据可视化效果和下游任务调整 - 对于可视化,优先用2维;对于特征提取,用交叉验证选择
n_components - 大规模数据(>10万)建议使用预计算k-近邻加速
- 如果簇边界模糊,尝试增大
min_dist降低点之间的挤压