PyTorch强化学习实战(4)------PyTorch基础
-
- [0. 前言](#0. 前言)
- [1. 张量 (Tensor)](#1. 张量 (Tensor))
-
- [1.1 张量的创建](#1.1 张量的创建)
- [1.2 标量张量](#1.2 标量张量)
- [1.3 张量操作](#1.3 张量操作)
- [1.4 GPU 张量](#1.4 GPU 张量)
- [2. 梯度](#2. 梯度)
- [3. 张量和梯度](#3. 张量和梯度)
- [4. 神经网络构建模块](#4. 神经网络构建模块)
- [5. 自定义层](#5. 自定义层)
- [6. 损失函数和优化器](#6. 损失函数和优化器)
-
- [6.1 损失函数](#6.1 损失函数)
- [6.2 优化器](#6.2 优化器)
- [7. 使用TensorBoard进行监控](#7. 使用TensorBoard进行监控)
-
- [7.1 TensorBoard 101](#7.1 TensorBoard 101)
- [7.2 指标可视化](#7.2 指标可视化)
- 小结
- 系列链接
0. 前言
我们已经学习了提供强化学习 (Reinforcement Learning, RL) 环境集合的开源库。RL 领域与深度学习 (Deep Learning, DL)的结合,使得解决比以往更具挑战性的问题成为可能。这部分归功于 DL 方法和工具的发展,本节介绍流行的深度学习库,PyTorch,它使我们能够通过几行 Python 代码实现复杂的深度学习模型。
1. 张量 (Tensor)
张量 (Tensor) 是所有深度学习库的基本构建块,其核心概念很简单:张量就是多维数组。单个数字如同零维的点,向量是一维的线段,矩阵是二维对象,三维的数字集合可以通过一个立方体来表示,但它们没有像矩阵那样的专有名称。对于更高维度的集合,我们可以统一使用"张量"这一术语。
需要注意的是,深度学习中所用张量与张量微积分或张量代数中的张量仅存在部分关联。在深度学习中,张量泛指任意多维数组;而在数学领域,张量是向量空间之间的映射关系------虽然有时可表示为多维数组,但其蕴含的数学语义要丰富得多。
1.1 张量的创建
在 Numpy 中,核心功能就是通用化处理多维数组。尽管 NumPy 中这类数组不称为"张量",但本质就是张量。张量作为通用数据容器广泛应用于科学计算,例如彩色图像可编码为三维张量(维度对应宽度、高度和色彩通道)。除维度外,张量还由其元素类型定义。PyTorch 支持 13 种数据类型:
- 浮点类型
4种:16位(含两种变体:float16侧重精度 /bfloat16侧重指数范围)、32位、64位 - 复数类型
3种:32位、64位、128位 - 整数类型
5种:8位有符号/无符号、16/32/64位有符号 - 布尔类型
1种
此外,还有四种"量化数字"类型,但它们使用上述类型,只是采用不同的位表示和解释。不同类型的张量由不同的类表示,其中最常用的是 torch.FloatTensor (对应 32 位浮点数)、torch.ByteTensor (8 位无符号整数)和 torch.LongTensor (64 位有符号整数)。
在 PyTorch 中创建张量的三种方法:
- 调用所需数据类型的构造函数直接实例化
- 使用
PyTorh创建具有特定数据的张量。例如,可以使用torch.zeros()函数创建一个填充为零的张量 - 将一个
NumPy数组或Python列表转换为张量。在这种情况下,自动继承原数据类型
(1) 导入 PyTorch 和 NumPy,并创建一个 3 × 2 大小的浮动数张量:
shell
$ python
>>> import torch
>>> import numpy as np
>>> a = torch.FloatTensor(3, 2)
>>> a
tensor([[7.9973e-18, 0.0000e+00],
[0.0000e+00, 0.0000e+00],
[4.0565e+31, 1.1180e-22]])可以看到,会以实际值初始化内存空间,这一行为与早期版本存在差异。先前版本仅分配内存而保持未初始化状态,虽然速度略快但安全性较低(可能引发隐蔽错误及安全隐患)。但我们不应依赖此特性,因其可能再次变更(或在不同硬件后端上表现不同),建议始终显式初始化张量内容,具体可通过两种方式实现。其一,使用张量构造运算符:
shell
>>> torch.zeros(3, 4)
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])其二,调用张量修改方法:
shell
>>> a.zero_()
tensor([[0., 0.],
[0., 0.],
[0., 0.]])张量操作可分为两种类型:
inplace(原地操作)和functional(函数式操作)。原地操作在方法名称后附加下划线(如add_),直接修改张量内容并返回对象本身;而函数式操作则会创建执行修改后的张量副本,保持原张量不变。从性能和内存角度来看,就地操作通常更高效,但直接修改现有张量(尤其是被多段代码共享时)可能导致隐蔽错误。
(2) 另一种通过构造函数创建张量的方法是传入 Python 可迭代对象(如列表或元组),其内容将作为新创建张量的内容:
shell
>>> torch.FloatTensor([[1,2,3],[3,2,1]])
tensor([[1., 2., 3.],
[3., 2., 1.]])(3) 通过 NumPy 数组创建全零张量:
shell
>>> n = np.zeros(shape=(3, 2))
>>> n
array([[0., 0.],
[0., 0.],
[0., 0.]])
>>> b = torch.tensor(n)
>>> b
tensor([[0., 0.],
[0., 0.],
[0., 0.]], dtype=torch.float64)(4) torch.tensor 方法可接收 NumPy 数组作为参数,并据此创建形状匹配的张量。在前例中,我们创建的 NumPy 数组默认初始化为双精度( 64 位浮点)零值数组,因此生成的张量类型为 DoubleTensor (示例中通过 dtype 值体现)。在深度学习领域,通常无需使用双精度浮点数,这种类型反而会增加额外内存和计算开销。常规做法是采用 32 位浮点类型,甚至 16 位浮点类型已完全够用。要创建此类张量,需显式指定 NumPy 数组类型:
shell
>>> n = np.zeros(shape=(3, 2), dtype=np.float32)
>>> torch.tensor(n)
tensor([[0., 0.],
[0., 0.],
[0., 0.]])(5) 另一种方案是向 torch.tensor 函数的 dtype 参数传入目标张量类型。但需要注意的是,该参数要求传入 PyTorch 类型标识而非 NumPy 类型标识。PyTorch 类型保存在 torch 包中,如 torch.float32、torch.uint8 等:
shell
>>> n = np.zeros(shape=(3,2))
>>> torch.tensor(n, dtype=torch.float32)
tensor([[0., 0.],
[0., 0.],
[0., 0.]])
torch.tensor()方法及显式PyTorch类型标注是在0.4.0版本中加入的,这一改进简化了张量的创建流程。早期版本中,推荐使用torch.from_numpy()函数转换NumPy数组,但该函数在处理Python列表与NumPy数组混合输入时存在缺陷。目前from_numpy()仍保留以维持向后兼容性,但建议改用更灵活的torch.tensor()方法。
1.2 标量张量
自 0.4.0 版本起,PyTorch 开始支持零维张量(即标量值)。这类张量可能来自某些运算结果(例如对张量所有元素求和)。旧版本会生成一个单元素一维张量(即向量)来处理这种情况,虽然可行但需要额外索引操作才能访问实际值,不够简洁。目前,零维张量已获得原生支持,相关函数会直接返回此类张量,也可通过 torch.tensor() 主动创建。要获取其实际 Python 数值,需调用专用的 item() 方法:
shell
>>> a = torch.tensor([1,2,3])
>>> a
tensor([1, 2, 3])
>>> s = a.sum()
>>> s
tensor(6)
>>> s.item()
6
>>> torch.tensor(1)
tensor(1)1.3 张量操作
PyTorch 提供了大量张量运算操作,其数量之多难以逐一列举。通常可通过 PyTorch 官方文档查询所需操作。需要注意的是,运算函数存在于两个位置:
- torch 包 :函数通常以张量作为参数传入(如
torch.sum(tensor)) - 张量类方法 :函数直接作用于调用张量(如
tensor.sum())
PyTorch 的张量运算设计大多数情况与 NumPy 保持对应关系,如 torch.stack()、torch.transpose()、torch.cat() 等。因此,只要不是 NumPy 中非常特殊的函数,大概率都能在 PyTorch 中找到功能相同的实现。这种设计极大提升了代码可读性------熟悉 NumPy 的开发者无需查阅文档即可理解 PyTorch 张量操作逻辑。
1.4 GPU 张量
PyTorch 原生支持 CUDA GPU 加速,所有运算均自动区分 CPU 和 GPU 版本,具体执行版本由参与运算的张量类型决定。
上述每种张量类型都对应 CPU 版本,同时也存在对应的 GPU 版本。唯一区别在于 GPU 张量位于 torch.cuda 包而非 torch 包中。例如 torch.FloatTensor 是存储在 CPU 内存中的 32 位浮点张量,而 torch.cuda.FloatTensor 则是其 GPU 版本。
实际上,PyTorch 不仅支持 CPU 和 CUDA,其底层采用"后端" (backend) 抽象概念------即具有内存的抽象计算设备,张量可被分配到后端内存中并执行运算。例如在苹果硬件上,PyTorch 支持将 Metal Performance Shaders (MPS) 作为名为 mps 的后端。我们主要讨论最常用的 CPU 和 GPU 后端,但 PyTorch 代码也可以在更多更高级的硬件上执行,且无需做太多修改。
通过张量的 .to(device) 方法可实现 CPU 与 GPU 间的转换,该方法会创建张量副本到指定设备( CPU 或 GPU)。若张量已在目标设备上,则直接返回原张量。设备类型可通过多种方式指定:最直接的方式是传入设备名称字符串,"cpu" 表示 CPU 内存,"cuda" 表示GPU。GPU 设备可通过冒号后添加索引编号(从 0 开始),例如系统中第二块 GPU 显卡可用 "cuda:1" 指定。
另一种更高效的设备指定方式是使用 torch.device 类,该类接受设备名称和可选索引参数。要获取张量当前所在的设备,可访问其 device 属性:
shell
>>> a = torch.FloatTensor([2,3])
>>> a
tensor([2., 3.])
>>> ca = a.to('cuda')
>>> ca
tensor([2., 3.], device='cuda:0')我们首先在 CPU 上创建了一个张量,然后将其复制到 GPU 内存中。两个副本均可用于计算,且所有 GPU 相关的底层操作对用户完全透明:
shell
>>> a+1
tensor([3., 4.])
>>> ca+1
tensor([3., 4.], device='cuda:0')
>>> ca.device
device(type='cuda', index=0)
to()方法和torch.device类是在0.4.0版本引入的。在早期版本中,CPU与GPU间的复制需要通过单独的cpu()和cuda()张量方法实现,这就要求额外编写代码来显式转换张量为CUDA版本。而现在,可以在程序开始时创建所需的torch.device对象,之后为每个新建张量调用to(device)即可。张量原有的cpu()和cuda()方法仍然保留------当需要确保张量必须位于CPU或GPU内存(无论其原始位置如何)时,这些旧方法会非常实用。
2. 梯度
即便有了无缝的 GPU 支持,若缺少自动计算梯度,那么所有的张量操作技巧也将失去价值。这一功能最初由 Caffe 工具包实现,现已成为深度学习库的实际标准。
在过去,即便是最简单的神经网络 (Neural Network, NN),手动计算梯度是非常麻烦的,其实现与调试过程令人痛苦不堪。需要为所有的函数计算导数,应用链式法则,然后实现计算的结果,且需要确保每个步骤都准确无误。虽然这种经历对理解深度学习底层原理大有裨益,但需要反复试验不同网络架构时,我们绝不会想重复这种过程。而如今,构建数百层的神经网络只需组合预置模块即可完成。即便需要实现特殊结构,最多也只需手动定义转换表达式。
所有梯度都将被精准计算、反向传播并应用于网络更新。要实现这种自动化,必须使用深度学习库的原语来定义网络架构。下图展示了优化过程中数据流与梯度流的传递方向:
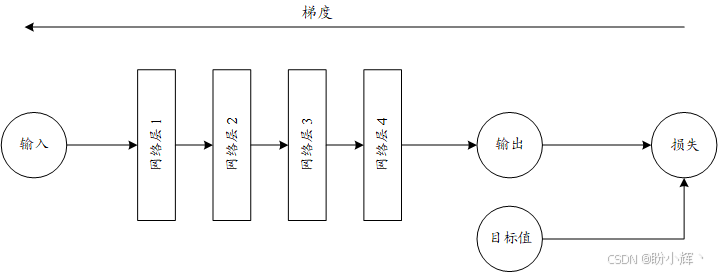
真正带来根本性差异的,在于梯度计算的方式。目前存在两种主流方法:
- 静态计算图:需预先定义完整计算流程且不可更改。深度学习库会在实际运算前对计算图进行优化处理。该模式被
TensorFlow 1.x、Theano等框架采用。其优势在于:1)通常执行速度更快,所有计算可移至GPU执行,减少数据传输开销;2)框架能自由优化计算顺序甚至删减冗余计算节点 - 动态计算图:无需预先严格定义计算图,可直接对实际数据执行所需运算操作。框架会实时记录运算顺序,在请求梯度计算时回溯操作历史并累积网络参数梯度。
PyTorch、Chainer等框架采用此模式。其优势在于:1)虽然动态图具有较高的计算开销,但赋予开发者更高自由度,例如可针对不同数据片段分别采用不同模型或重复应用网络;2)能以更自然、"Pythonic" 的方式编写转换逻辑------本质上只是调用Python库函数完成操作
值得注意的是,
PyTorch自2.0版本起引入torch.compile函数,通过JIT编译将代码转换为优化内核来提升执行效率,这实际是早期TorchScript和FX追踪编译技术的演进。从历史角度来看,
TensorFlow(静态图)和PyTorch(动态图)最初使用截然不同的设计理念,但随着时间的推移逐渐融合,PyTorch支持编译优化,而TensorFlow2.x也推出了"即时执行模式" (eager execution mode)。
3. 张量和梯度
PyTorch 张量内置了梯度计算与追踪机制,因此只需要将数据转换为张量,并使用 torch 提供的张量方法和函数执行计算。当然,如需访问底层细节仍可操作,但大多数情况下 PyTorch 都能自动实现预期行为。每个张量都包含以下与梯度相关的属性:
grad:存储与张量同形状的梯度张量is_leaf:如果该张量是由用户构建,则为True;如果该对象是函数转换的结果(即计算图中存在父节点),则为Falserequires_grad:如果该张量需要计算梯度,则为True。该属性继承自叶子张量,叶子张量在构建步骤中从张量构造时获得该值(例如torch.zeros()或torch.tensor()等)。默认情况下,requires_grad=False,若需计算梯度必须显式启用
(1) 为更好理解梯度-叶子张量机制,查看以下示例:
shell
>>> v1 = torch.tensor([1.0, 1.0], requires_grad=True)
>>> v2 = torch.tensor([2.0, 2.0])以上代码创建了两个张量:第一个需要计算梯度,而第二个不需要。
(2) 接着我们对这两个向量进行逐元素相加(得到向量 [3, 3]),将所有元素翻倍后求和:
shell
>>> v_sum = v1 + v2
>>> v_sum
tensor([3., 3.], grad_fn=<AddBackward0>)
>>> v_res = (v_sum*2).sum()
>>> v_res
tensor(12., grad_fn=<SumBackward0>)最终得到一个值为 12 的零维张量。这仅是基础数学运算,接下来查看这些表达式构建的计算图:
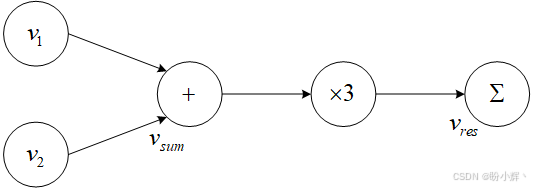
(3) 若检查各张量属性,会发现 v1 和 v2 是仅有的叶子节点,且除 v2 外所有变量均需计算梯度:
shell
>>> v1.is_leaf, v2.is_leaf
(True, True)
>>> v_sum.is_leaf, v_res.is_leaf
(False, False)
>>> v1.requires_grad
True
>>> v2.requires_grad
False
>>> v_sum.requires_grad
True
>>> v_res.requires_grad
True可以看到,requires_grad 属性有点传递性:只要参与计算的变量中有一个该属性为 True,所有后续计算节点都会继承这一特性。这种行为符合逻辑,因为通常我们需要为计算过程中的所有中间步骤保留梯度。但"计算梯度"并不意味着它们会全部保存在 .grad 字段中------出于内存效率考虑,PyTorch 默认只存储 requires_grad=True 的叶子节点的梯度。若需保留非叶子节点的梯度,必须显式调用 retain_grad() 方法:
shell
>>> v_res.backward()
>>> v1.grad
tensor([2., 2.])通过调用 backward() 函数,我们要求 PyTorch 计算 v_res 变量相对于计算图中所有变量的数值导数。具体到当前示例,v1 梯度值为 2 意味着:当 v1 的任意元素增加 1 时,v_res 的结果值将增长2。
(4) 如前所述,PyTorch 仅会为 requires_grad=True 的叶子张量计算梯度。事实上,如果我们尝试查看 v2 的梯度,将会得到空值:
shell
>>> v2.grad这样设计是出于计算效率和内存优化的考量。实际场景中,神经网络可能包含数百万待优化参数,期间会执行数百次中间运算。在梯度下降优化过程中,我们真正需要关注的并非中间矩阵乘法的梯度,而是损失函数相对于模型参数(权重)的梯度。当然,若需要计算输入数据的梯度(例如生成对抗样本干扰现有神经网络,或微调预训练词嵌入),只需在创建张量时设置 requires_grad=True 即可轻松实现。
我们已经介绍了实现自定义神经网络优化器的全部基础要素。后续内容将介绍更高级的便利函数------这些模块化组件能够提供神经网络架构的构建单元、主流优化算法及常用损失函数。需要注意的是,这些功能都可以按需重新实现,其优雅的设计与极致的灵活性正是 PyTorch 在深度学习研究领域广受推崇的原因。
张量梯度支持是
PyTorch 0.4.0的重大变革。此前版本通过独立的轻量级Variable类实现计算图追踪和梯度累积,该类作为张量包装器自动保存运算历史以支持反向传播。从实践角度看,这一变革极具价值------原先的Variable逻辑虽轻量,但仍需开发者额外处理张量包装与解包操作。如今梯度已成为张量的内置属性,使得API更加简洁统一。
4. 神经网络构建模块
在 torch.nn 包中,有大量预定义的类,它们提供了基础的神经网络功能组件。这些模块均以实践需求为设计导向,例如,支持小批量数据输入,提供合理的默认参数,自动进行正确的权重初始化。所有模块都遵循可调用规范,这意味着任何类的实例都能像函数一样处理输入参数。以 Linear 类为例,它实现了一个带可选偏置的全连接层:
shell
>>> from torch import nn
>>> l = nn.Linear(2, 5)
>>> v = torch.FloatTensor([1, 2])
>>> l(v)
tensor([ 0.2879, -1.0671, 1.5877, 0.4503, -0.8281], grad_fn=<ViewBackward0>)以上代码创建了一个随机初始化的全连接层(输入维度 2,输出维度 5),并将其应用于浮点型张量。
torch.nn 中的所有类都继承自 nn.Module 基类,可以利用它来实现自定义的高级神经网络模块。接下来,先了解所有 nn.Module 子类都具备的实用方法:
parameters():返回需要计算梯度的变量迭代器(即模块权重)zero_grad():将所有参数梯度归零to(device):将模块的所有参数移动到指定设备 (CPU/GPU)state_dict():返回包含所有模块参数的字典,常用于模型序列化load_state_dict():使用状态字典初始化模块
完整类列表可查阅官方文档。特别值得一提的是能组合多个层构建管道的 Sequential 类:
shell
>>> s = nn.Sequential(
... nn.Linear(2, 5),
... nn.ReLU(),
... nn.Linear(5, 20),
... nn.ReLU(),
... nn.Linear(20, 10),
... nn.Dropout(p=0.3),
... nn.Softmax(dim=1))
>>> s
Sequential(
(0): Linear(in_features=2, out_features=5, bias=True)
(1): ReLU()
(2): Linear(in_features=5, out_features=20, bias=True)
(3): ReLU()
(4): Linear(in_features=20, out_features=10, bias=True)
(5): Dropout(p=0.3, inplace=False)
(6): Softmax(dim=1)
)以上定义了一个三层神经网络,输出层采用沿维度 1 (维度 0 为批样本)的 softmax,包含 ReLU 非线性激活和 dropout 层。接下来,输入数据进行测试:
shell
>>> s(torch.FloatTensor([[1,2]]))
tensor([[0.0851, 0.0972, 0.0724, 0.1020, 0.0810, 0.1020, 0.1611, 0.0477, 0.1020,
0.1494]], grad_fn=<SoftmaxBackward0>)5. 自定义层
nn.Module 类不仅是 PyTorch 中所有神经网络构建模块的基类,更是实现自定义组件的关键。通过继承这个类,可以创建能够完美融入 PyTorch 生态的可堆叠、可复用的自定义模块。nn.Module 核心功能包括:
- 它子模块追踪:自动记录模块包含的所有子组件(如包含两个全连接层的复合模块),只需将子模块赋值给类属性即可完成追踪(注册)
- 参数管理:提供全套参数处理方法,包括,获取全部参数 (
parameters()),梯度清零 (zero_grads()),设备迁移 (to(device)),序列化和反序列化 (state_dict()和load_state_dict()),自定义转换 (apply()) - 数据转换规范:通过重写
forward()方法定义数据处理逻辑 - 高级功能:支持注册钩子函数来调整模块行为或梯度流向
这些特性让我们能以统一方式将子模型嵌套到更高层模型中,这对处理复杂架构非常有用。无论是单层线性变换还是包含数千层的残差网络(如 ResNet),只要遵循 nn.Module 规范,就能以相同方式处理。这种设计极大提升了代码复用性,并通过隐藏实现细节简化了开发流程。
PyTorch 通过精心设计和 Python 元编程简化了模块创建流程。通常只需完成两个步骤:注册子模块并实现 forward() 方法。
(1) 接下来,重构上一小节的 Sequential 示例,继承 nn.Module 的自定义模块类:
python
import torch
import torch.nn as nn
class OurModule(nn.Module):
def __init__(self, num_inputs, num_classes, dropout_prob=0.3):
super(OurModule, self).__init__()
self.pipe = nn.Sequential(
nn.Linear(num_inputs, 5),
nn.ReLU(),
nn.Linear(5, 20),
nn.ReLU(),
nn.Linear(20, num_classes),
nn.Dropout(p=dropout_prob),
nn.Softmax(dim=1)
)在构造函数中,传递了三个参数:输入维度、输出维度和可选的 dropout 概率。首先需要调用父类构造函数完成初始化。第二步我们创建了熟悉的 nn.Sequential 层序列,并将其赋值给名为 pipe 的类字段。由于 nn.Sequential 实例(和 nn 包中所有组件一样继承自 nn.Module )被赋值给对象字段,该模块会自动完成注册------我们无需额外调用注册方法,只需将子模块赋值给字段即可。构造函数执行完毕后,所有这些字段都会自动完成注册。若确有需要,nn.Module 也提供了 add_module() 函数用于手动注册子模块,这在需要动态创建可变数量层时特别有用。
(2) 接下来,重写 forward 函数实现数据转换逻辑:
python
def forward(self, x):
return self.pipe(x)由于我们的模块只是对 Sequential 类的简单封装,只需调用 self.pipe 来处理数据即可。需要注意的是,调用模块时应将其作为可调用对象使用(即像函数一样直接传入参数),而非直接调用 forward() 方法。这是因为 nn.Module 重载了 __call__() 方法(该方法会在实例被调用时触发),这个方法会执行一些 nn.Module 的内部逻辑,然后再调用我们实现的 forward() 方法。如果直接调用 forward(),会干扰 nn.Module 的正常流程,导致错误结果。
(3) 完成自定义模块的构建后,使用该模块:
python
if __name__ == "__main__":
net = OurModule(num_inputs=2, num_classes=3)
print(net)
v = torch.FloatTensor([[2, 3]])
out = net(v)
print(out)
print("Cuda's availability is %s" % torch.cuda.is_available())
if torch.cuda.is_available():
print("Data from cuda: %s" % out.to('cuda'))我们创建模块时传入所需的输入/输出维度,然后生成一个张量并按照调用约定(作为可调用对象)让模块处理它。接着打印网络结构 (nn.Module 已重载 __str__ 和 __repr__ 方法,能展示网络内部结构),最后输出网络处理结果。运行代码后的输出结果如下:

当然,PyTorch 动态特性的优势在此仍然适用。由于 forward() 方法会针对每个数据批次执行,这意味着可以基于待处理数据实现复杂变换------无论是分层 softmax 还是随机选择应用子网络,都不会受到任何限制。模块的参数数量同样不受约束:既可以定义需要多个必选参数的模块,也可以添加数十个可选参数,这些都能完整兼容。
接下来,我们需要熟悉 PyTorch 中两个能大幅提升效率的核心组件:损失函数与优化器。
6. 损失函数和优化器
仅实现数据转换的网络并不足以完成训练,我们还需要定义学习目标------即接受网络输出和期望输出两个参数,并返回单个标量值(表征预测结果与期望值差距)的函数。该函数称为损失函数 (loss function),其输出值即损失值 (loss value)。通过损失值计算网络参数的梯度并调整参数以降低损失值,从而推动模型持续优化。
由于损失函数和基于梯度的参数优化方法具有高度通用性且存在多种变体,PyTorch 将这两者作为核心功能提供,接下来,我们首先从损失函数开始。
6.1 损失函数
PyTorch 中的损失函数均位于 nn 模块中,它们继承自 nn.Module 类。这类函数通常接收两个参数:网络输出(预测值)和期望输出(真实值/标注数据)。PyTorch 提供了 20 余种损失函数,当然我们也可以自定义所需的优化目标函数。最常用的标准损失函数包括:
nn.MSELoss:计算均方误差 (Mean Square Error,MSE),是回归问题的标准损失函数nn.BCELoss和nn.BCEWithLogits:二元交叉熵损失,广泛应用于二分类问题。前者要求输入单个概率值(通常来自Sigmoid层输出),后者直接处理原始分数并自动应用Sigmoid,具有更好的数值稳定性和计算效率nn.CrossEntropyLoss和nn.NLLLoss:"最大似然"准则,用于多分类问题。前者接受每个类别的原始分数并在内部应用LogSoftmax,后者则需要以对数概率作为输入
PyTorch 还提供了其他损失函数,我们也可以编写自己的 Module 子类来比较输出与目标值。接下来,我们继续介绍优化过程的第二个组成部分------优化器。
6.2 优化器
优化器的核心目标是根据模型参数的梯度调整参数值,从而降低损失函数值。通过持续减小损失值,推动模型输出逐渐逼近目标值,最终提升模型性能。虽然参数调整听起来简单,但其中存在大量技术细节,目前优化算法仍是机器学习领域的热门研究方向之一。PyTorch 在 torch.optim 模块中提供了多种经典优化器实现,主要包括:
SGD:基础随机梯度下降算法,支持动量扩展RMSprop:自适应学习率算法Adagrad:自适应梯度优化器Adam:融合RMSprop与Adagrad优势的高效算法
所有优化器均提供统一接口,这使得我们可以轻松地尝试不同的优化方法(不同优化器对收敛速度和最终结果可能产生显著影响)。初始化时需传入待优化的可迭代张量集合,这些张量会在优化过程中被修改。通常的做法是传入上层 nn.Module 实例的 params() 调用结果,该方法会返回所有带梯度的叶子张量的可迭代对象。
接下来,我们讨论训练循环的通用框架:
python
for batch_x, batch_y in iterate_batches(data, batch_size=N):
batch_x_t = torch.tensor(batch_x)
batch_y_t = torch.tensor(batch_y)
out_t = net(batch_x_t)
loss_t = loss_function(out_t, batch_y_t)
loss_t.backward()
optimizer.step()
optimizer.zero_grad()通常,需要对数据进行反复迭代(对整个数据集进行一次完整遍历称为一个 epoch)。由于数据量通常过大,无法一次性载入 CPU 或 GPU 内存,因此会被分成大小相等的批次。每个批次包含数据样本及其对应目标标签,二者均需以张量形式存在(代码第 2-3 行)。
将数据样本输入网络(代码第 4 行)后,将其输出与目标标签共同传入损失函数(代码第 5 行)。损失函数的计算结果反映了网络预测结果相对于目标标签的偏差程度。由于网络输入和网络权重均为张量,网络的所有运算本质上都是由中间张量实例构成的操作图。损失函数亦然------其输出结果同样是包含单个损失值的张量。
该计算图中的每个张量都记录着其父节点信息,因此要计算整个网络的梯度,只需在损失函数结果上调用 backward() 方法(代码第 6 行)。此操作将展开已执行的计算图,并计算每个具有 require_grad=True 的叶子张量的梯度。通常,这些张量是模型参数,例如前馈网络的权重和偏置,以及卷积核等。每次计算的梯度会累加至 tensor.grad 字段,这意味着单个张量可多次参与运算,其梯度将被正确累加。例如,一个循环神经网络 (Recurrent Neural Network, RNN) 单元可以应用于多个输入项。
完成 loss.backward() 调用后,得到了累积的梯度,此时优化器开始工作------从初始化时传入的参数中提取所有梯度并进行参数更新(通过 step() 方法实现,代码第 7 行)。
训练循环的最后关键步骤是手动清零参数梯度。虽然可通过网络对象调用 zero_grad() 实现,但优化器也提供了等效方法以简化操作(代码第 8 行)。需要注意的是,梯度清零操作置于训练循环开头亦可,且通常更为常见。
上述流程提供了高度灵活的优化方案,能够满足复杂研究的需求。例如,可以使用两个优化器基于同一批数据分别调整不同模型参数,例如生成对抗网络 (Generative Adversarial Network, GAN)的训练。
我们已经学习了 PyTorch 训练神经网络的核心功能,接下来将讨论一个对神经网络实践至关重要的主题------训练过程监控。
7. 使用TensorBoard进行监控
如果不按照现成教程和示例操作(这种情况下,超参数已经经过精心调整),而是从零开始处理数据并构建模型,那么我们就会发现训练神经网络充满不确定性。即便使用深度学习工具包(这些工具已内置合适的权重初始化、优化器的 beta / gamma 等参数默认值,以及大量隐藏的自动化处理),但仍需做出大量决策,因此出错的可能性依然很高,代码几乎不可能第一次运行就成功。
当然,随着经验积累,我们会逐渐掌握问题排查的诀窍,但这需要获取网络内部运行的数据。所以,需要能够以某种方式监测训练过程并观察其动态变化。即使是小型网络,也可能涉及数十万个参数和高度非线性的训练动态。
模型训练过程中,我们通常需要监控以下数据:
- 损失值:通常由基础损失和正则化损失等部分组成,需同时监控总损失和各分项的变化
- 在训练集和测试集上的验证结果
- 梯度和权重的统计信息
- 网络输出值:如分类问题中预测类别的信息熵,回归问题中原始预测值能反映大量训练状态
- 学习率等超参数(若采用动态调整策略)
除此之外,还可扩展至领域特定指标,比如词嵌入投影、音频样本、GAN 生成图像等,以及训练速度相关指标(如单个 epoch 训练耗时)以评估优化效果或硬件问题。
因此,需要一个通用解决方案来持续追踪大量指标并进行可视化分析,接下来,介绍 TensorFlow 的 TensorBoard 作为模型监控工具。
7.1 TensorBoard 101
TensorFlow 内置了名为 TensorBoard 的专用工具,专门用于解决在训练过程中及训练结束后观察分析神经网络各项特性。作为功能强大、通用性强的解决方案,TensorBoard 不仅拥有庞大的用户社区,并且界面也相当漂亮。
从架构角度来看,TensorBoard 是一个基于 Python 的 Web 服务。启动时需指定训练过程保存分析数据的目录,随后在浏览器访问 TensorBoard 端口(通常为 6006),即可看到实时更新的交互式可视化界面(如下图所示)。这种设计非常便捷,尤其适用于云端远程训练场景。
最初 TensorBoard 作为 TensorFlow 的组件发布,后独立为 Google 维护的开源项目(但仍沿用 TensorFlow 数据格式)。虽然 PyTorch 程序需要额外处理数据格式转换,但如今已原生支持该功能(通过 torch.utils.tensorboard 包实现),不再需要第三方库。
7.2 指标可视化
为直观展示 TensorBoard 的易用性,我们以一个与神经网络无关的简单示例为例。导入所需的包、创建数据记录器,并定义待可视化的函数:
python
import math
from torch.utils.tensorboard.writer import SummaryWriter
if __name__ == "__main__":
writer = SummaryWriter()默认情况下,SummaryWriter 会在 runs 目录下为每次训练运行创建独立子目录(包含当前日期时间及主机名),以便对比不同训练轮次的效果。如需自定义,可以通过 log_dir 参数传递给 SummaryWriter 指定目录路径,也可通过 comment 参数来为目录名称添加后缀,捕捉不同实验的语义,如 dropout=0.3 或 strong_regularisation。
接下来,我们遍历角度值(以度为单位)进行数据记录:
python
funcs = {"sin": math.sin, "cos": math.cos, "tan": math.tan}
for angle in range(-360, 360):
angle_rad = angle * math.pi / 180
for name, fun in funcs.items():
val = fun(angle_rad)
writer.add_scalar(name, val, angle)
writer.close()将角度值转换为弧度并计算函数值。每个数值都通过 add_scalar 函数写入记录器,该函数接收三个参数:指标名称、数值和当前迭代次数(必须为整数)。循环结束后需手动关闭记录器。需注意的是,记录器会定期自动保存数据(默认每两分钟一次),因此即使是长时间优化过程也能实时查看数据。如果需要显式刷新 SummaryWriter 数据,可调用 flush()方法。
运行该程序时控制台不会有输出,但会在 runs 目录下生成包含数据文件的新目录。查看结果需要启动 TensorBoard 服务:
shell
$ tensorboard --logdir runs如果在远程服务器上运行 TensorBoard,需要添加 --bind_all 命令行选项,以使其能够从其他机器访问。现在,在浏览器中打开 http://localhost:6006 可以看到界面如下所示:
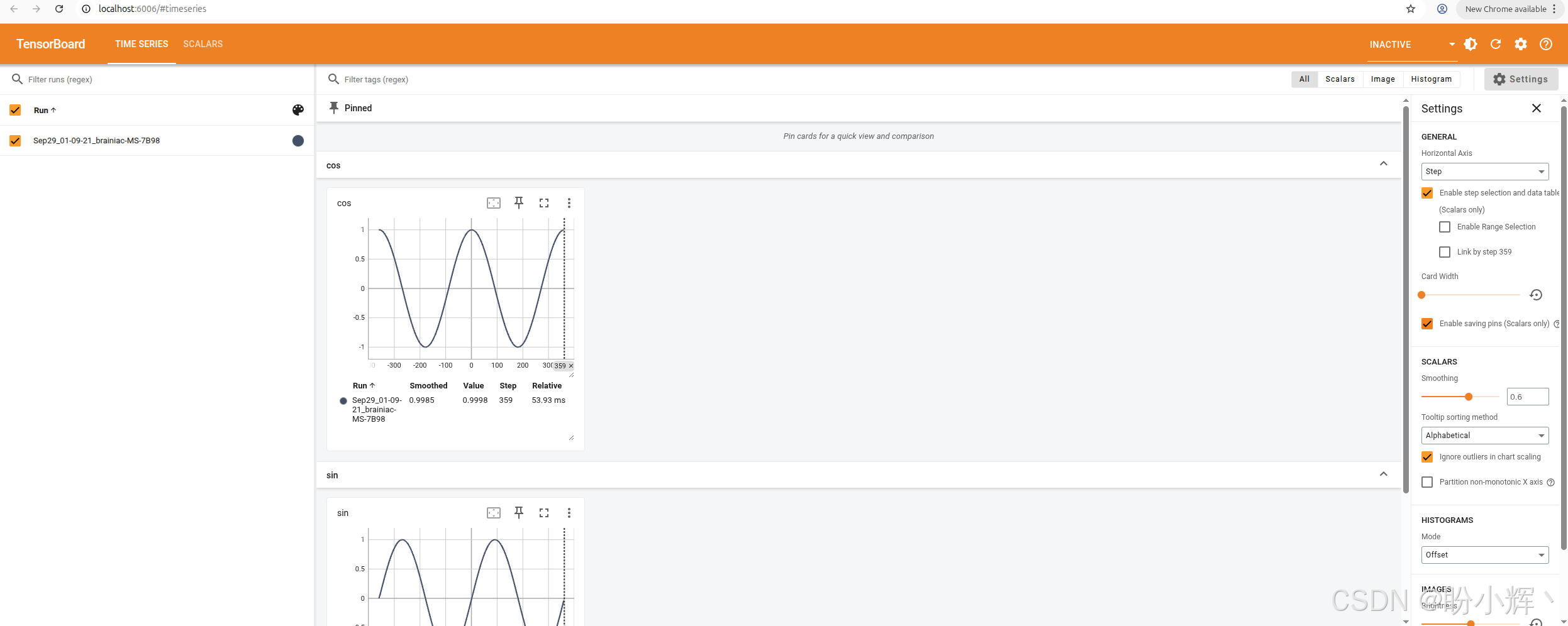
这些图表支持交互操作:鼠标悬停可查看具体数值,框选区域可放大观察细节,双击图表即可恢复原始比例。若多次运行程序,左侧 "Runs" 列表会显示多个训练记录,可任意勾选组合进行对比分析。TensorBoard 不仅能可视化标量数据,还支持图像、音频、文本、嵌入向量等多维数据分析,甚至能展示网络结构。
小结
在本节中,了解了 PyTorch 的功能和特性,涵盖张量与梯度等基础组件,演示了如何用基本模块构建神经网络,然后学习如何实现自定义模块。我们探讨了损失函数、优化器以及训练过程监控方法,为后续学习奠定 PyTorch 基础。
系列链接
PyTorch强化学习实战(1)------强化学习(Reinforcement Learning,RL)详解
PyTorch强化学习实战(2)------强化学习环境库Gymnasium
PyTorch强化学习实战(3)------Gymnasium API扩展功能