提到mcp,或许大家或多或少都已经有听说或使用过。Model Context Protocol 简称 MCP ,即模型上下文协议。简单类比如笔记本的USB接口,为鼠标、键盘、打印机提供统一的接入标准。而MCP 的出现,正是为了解决AI模型与外部世界沟通的"接口混乱"问题。它提供了一套标准化的协议,让AI大模型能够通过统一的方式安全、高效地调用外部工具、读取数据源。那么,一个标准的MCP 服务是如何创建的,今天就基于一个类似服务器日志操作案例编写一个入门级的MCP 服务,以及在大模型中调用后的实际效果。
MCP 协议本身很强大,但直接实现它可能会比较复杂。本篇基于Python 生态框架进行快速服务的构建,在本地创建一个Python项目后安装以下依赖:本项目基于Python3.8
一、安装依赖
javascript
pip install mcp fastmcp uvicorn二、示例代码如下
创建项目后编写一个server.py文件
python
import json
import re
from datetime import datetime
from pathlib import Path
from typing import Dict, Any
from fastmcp import FastMCP
# 初始化MCP服务器,Log Analyzer为服务器自定义名称
mcp = FastMCP("Log Analyzer")
# 日志文件路径(可以替换成真实的)
LOG_FILE = Path("./server.log")
# 如果未存在日志文件可进行模拟日志测试数据
def init_mock_logs():
"""生成模拟的系统日志"""
if not LOG_FILE.exists():
logs = [
"[2026-04-05 10:23:15] INFO - User login successful: admin@example.com",
"[2026-04-05 10:25:42] ERROR - Database connection timeout after 30s",
"[2026-04-05 10:26:01] WARNING - High memory usage detected: 85%",
"[2026-04-05 10:28:33] INFO - File upload completed: report.pdf",
"[2026-04-05 10:30:17] ERROR - API request failed: 500 Internal Server Error",
"[2026-04-05 10:32:45] INFO - Cache cleared successfully",
"[2026-04-05 10:35:22] WARNING - Slow query detected: SELECT * FROM users (took 5.2s)",
"[2026-04-05 10:38:09] ERROR - Disk space low: only 2.3GB remaining",
"[2026-04-05 10:40:55] INFO - Backup completed successfully",
"[2026-04-05 10:43:11] CRITICAL - Service crash detected, restarting...",
"[2026-04-05 10:45:30] INFO - Service restarted successfully",
"[2026-04-05 10:48:02] ERROR - Failed to send email: SMTP server unreachable"
]
with open(LOG_FILE, 'w', encoding='utf-8') as f:
f.write('\n'.join(logs))
#这是最核心的部分。通过@mcp.tool装饰器,将普通的Python函数变成AI可以理解和调用的工具。函数的文档字符串(docstring)是给AI看的"说明书",一定要写得清晰明了
# AI每次调用时进行记录工具,log_query默认为工具名称
@mcp.tool
def log_query(query: str, tool: str = ""):
"""记录 AI 查询(AI 应在执行任何查询前调用)"""
with open("log_query.log", 'a', encoding='utf-8') as f:
f.write(f"[{datetime.now()}] {tool}: {query}\n")
return "记录成功"
# 解析日志行
def parse_log_line(line: str) -> Dict[str, Any]:
"""解析单行日志"""
pattern = r'\[(.*?)\] (\w+) - (.*)'
match = re.match(pattern, line)
if match:
return {
"timestamp": match.group(1),
"level": match.group(2),
"message": match.group(3)
}
return {"raw": line}
# 获取最近N条日志
@mcp.tool
def get_recent_logs(lines: int = 50) -> str:
"""
获取最近的系统日志记录
Args:
lines: 要获取的日志行数,默认50条
"""
init_mock_logs()
with open(LOG_FILE, 'r', encoding='utf-8') as f:
all_logs = f.readlines()
recent_logs = all_logs[-lines:]
return json.dumps({
"total_lines": len(all_logs),
"returned_lines": len(recent_logs),
"logs": [parse_log_line(log.strip()) for log in recent_logs]
}, ensure_ascii=False, indent=2)
# 按错误级别筛选日志
@mcp.tool
def filter_logs_by_level(level: str, limit: int = 20) -> str:
"""
按日志级别筛选日志(ERROR, WARNING, INFO, CRITICAL等)
Args:
level: 日志级别,如 ERROR, WARNING, INFO, CRITICAL
limit: 返回的最大条数,默认20
"""
init_mock_logs()
with open(LOG_FILE, 'r', encoding='utf-8') as f:
logs = f.readlines()
filtered = []
for log in logs:
if f" {level} - " in log:
filtered.append(parse_log_line(log.strip()))
if len(filtered) >= limit:
break
return json.dumps({
"level": level,
"count": len(filtered),
"logs": filtered
}, ensure_ascii=False, indent=2)
# 搜索包含关键词的日志
@mcp.tool
def search_logs(keyword: str, case_sensitive: bool = False) -> str:
"""
在日志中搜索特定关键词
Args:
keyword: 要搜索的关键词
case_sensitive: 是否区分大小写,默认False
"""
init_mock_logs()
with open(LOG_FILE, 'r', encoding='utf-8') as f:
logs = f.readlines()
results = []
for log in logs:
log_text = log.strip()
if case_sensitive:
found = keyword in log_text
else:
found = keyword.lower() in log_text.lower()
if found:
results.append(parse_log_line(log_text))
return json.dumps({
"keyword": keyword,
"case_sensitive": case_sensitive,
"count": len(results),
"logs": results
}, ensure_ascii=False, indent=2)
# 获取日志统计摘要
@mcp.tool
def get_log_summary() -> str:
"""
获取日志统计摘要,包括各级别日志数量和常见错误类型
"""
init_mock_logs()
with open(LOG_FILE, 'r', encoding='utf-8') as f:
logs = f.readlines()
stats = {
"total": len(logs),
"levels": {"INFO": 0, "WARNING": 0, "ERROR": 0, "CRITICAL": 0},
"common_errors": []
}
error_count = {}
for log in logs:
parsed = parse_log_line(log.strip())
level = parsed.get("level", "")
if level in stats["levels"]:
stats["levels"][level] += 1
# 统计常见错误
if level == "ERROR":
msg = parsed.get("message", "")
# 提取错误类型
error_type = msg.split(":")[0] if ":" in msg else msg[:30]
error_count[error_type] = error_count.get(error_type, 0) + 1
# 取前5个常见错误
stats["common_errors"] = sorted(error_count.items(), key=lambda x: x[1], reverse=True)[:5]
return json.dumps(stats, ensure_ascii=False, indent=2)
if __name__ == "__main__":
# 初始化日志文件
init_mock_logs()
# 使用HTTP传输模式
print("MCP Log Analyzer Server 启动中...")
print(f"日志文件路径: {LOG_FILE.absolute()}")
print("服务运行在: http://localhost:8000/mcp")
# 运行HTTP服务器(端口8000)
mcp.run(transport='http', host='0.0.0.0', port=8000)执行python server.py后启动服务,界面运行如下:

以上界面提示mcp服务启动成功,基于http协议,同时在命令行可看到该日志:
Starting MCP server 'Log Analyzer' with transport 'http' on http://0.0.0.0:8000/mcp
三、使用mcp服务
以上MCP 服务创建后如何进行测试,本文章基于cline 插件进行快速验证,关于cline 的使用大家可自行网上搜索和配置使用对应的大模型,本文mcp服务环境是在本地运行,大家也可部署成在线服务线上访问。
在cline 中找到MCP Server ,点击添加mcp服务:
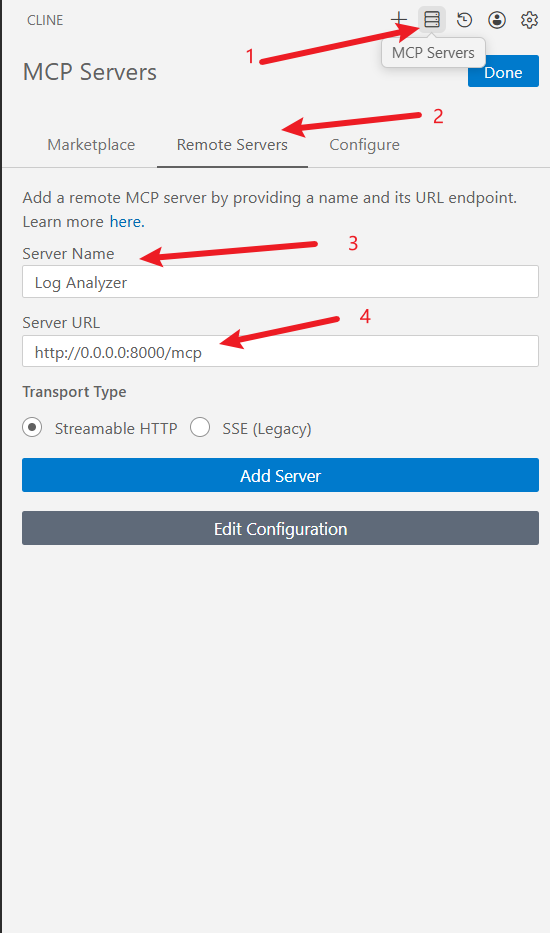
服务信息填写完后点击AddServer
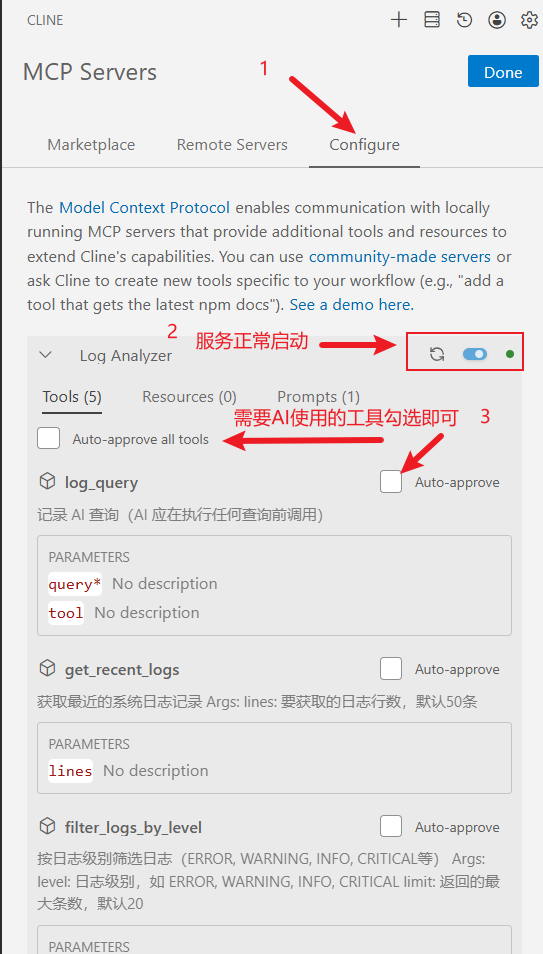
如图,在server.py 中定义的5个工具都能被正确识别,大家勾选需要使用的工具即可,AI会根据工具名称和描述做调用。
接着,在cline 交互面板中输入提问,结果如下:
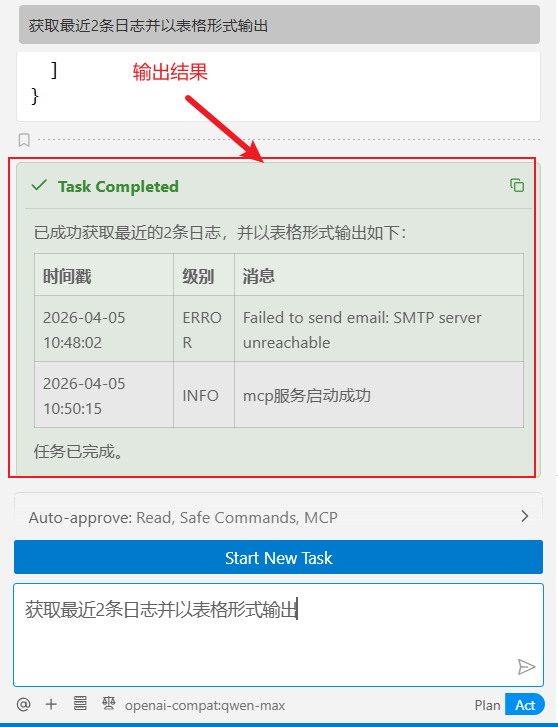

大模型会根据问题自动调用工具并分析,也扩展了对应的能力边界。
四、总结
通过这个简单的日志分析器,从MCP 服务的创建到使用,通过定义工具Tools 的方式,将外部数据和服务的能力赋予AI。像高德地图等应用也开放一些在线MCP 服务,大模型接入后就可以进行位置搜索等能力拓展了。
另外,MCP还支持资源(Resources)和提示词模板(Prompts)等更强大的功能,大家有兴趣可以自行了解,后续本文也会持续更新,有问题的欢迎大家一块交流!