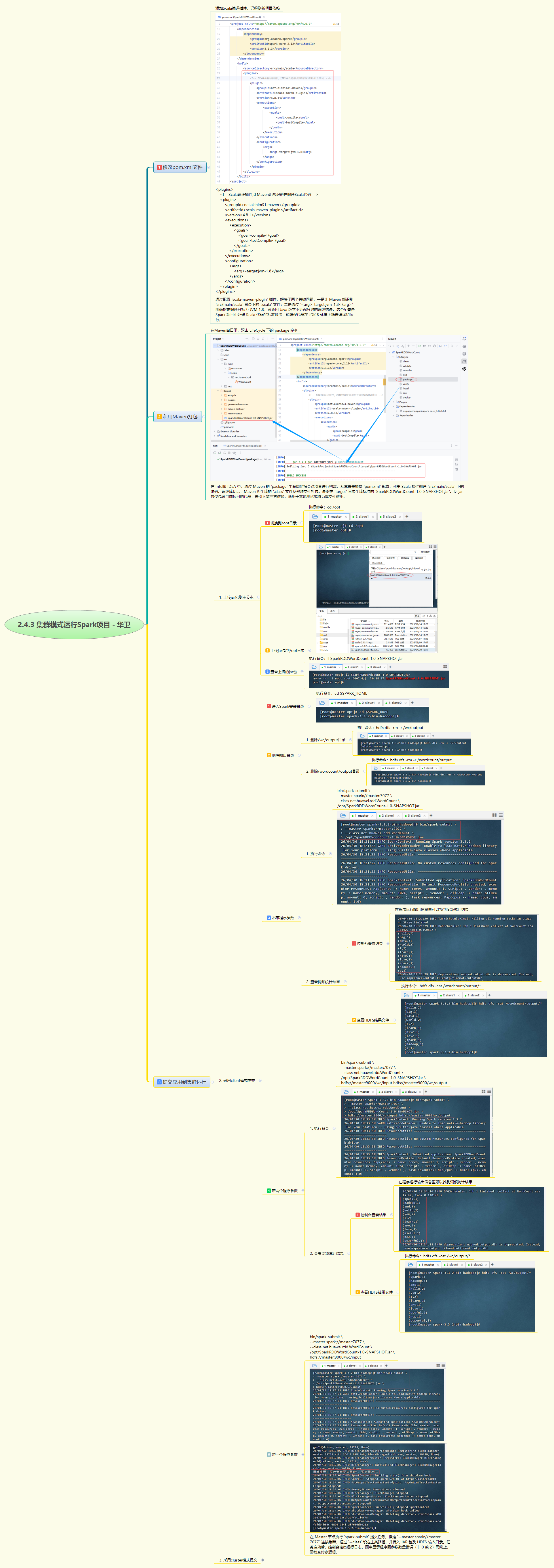
本次实战聚焦于在Spark集群环境下运行WordCount项目,完整呈现从项目构建到集群提交的全流程。首先,通过修改pom.xml文件,添加scala-maven-plugin插件并配置编译参数,解决了Maven对Scala代码的识别与编译问题,确保项目能在JDK 8环境下稳定构建。随后,利用Maven的package指令对项目进行打包,生成仅包含项目代码的JAR文件,并上传至集群主节点的/opt目录。
在集群运行阶段,分别采用client和cluster两种部署模式提交任务。client模式下,任务直接在提交端运行,便于实时查看控制台输出;cluster模式则将Driver部署在集群内部,更适合生产环境。通过不同参数组合(无参数、单参数、双参数)的提交测试,验证了程序对输入输出路径的处理逻辑。最终,通过Spark Master和Worker的Web UI页面,以及HDFS结果文件,全方位确认任务执行状态与词频统计结果,完整展示了Spark集群应用的部署与监控流程。