一、Kafka安装
首先我们按照第七章的命令启动CM页面,然后我们开始安装Kafka服务。按照图中所示操作即可。
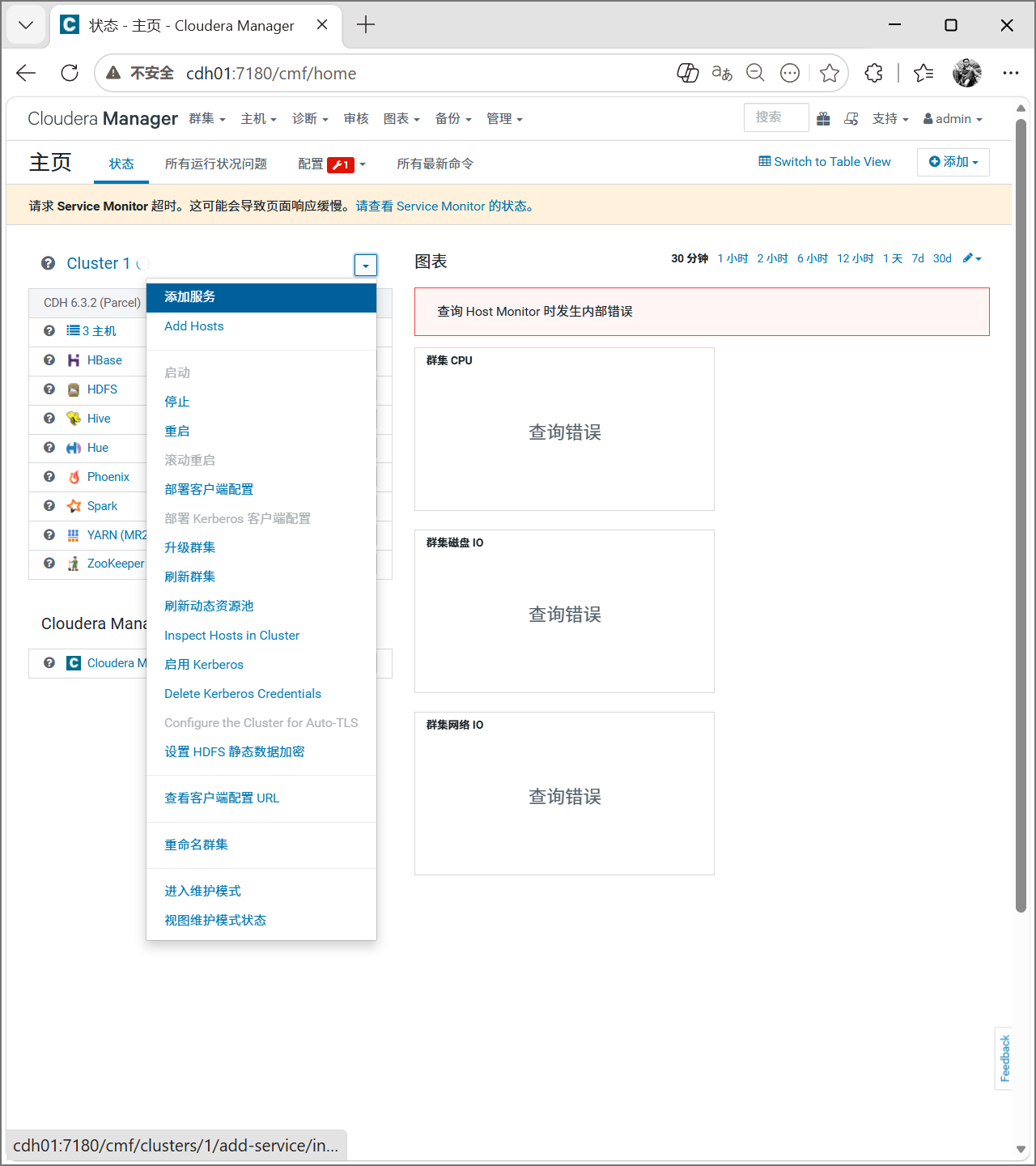
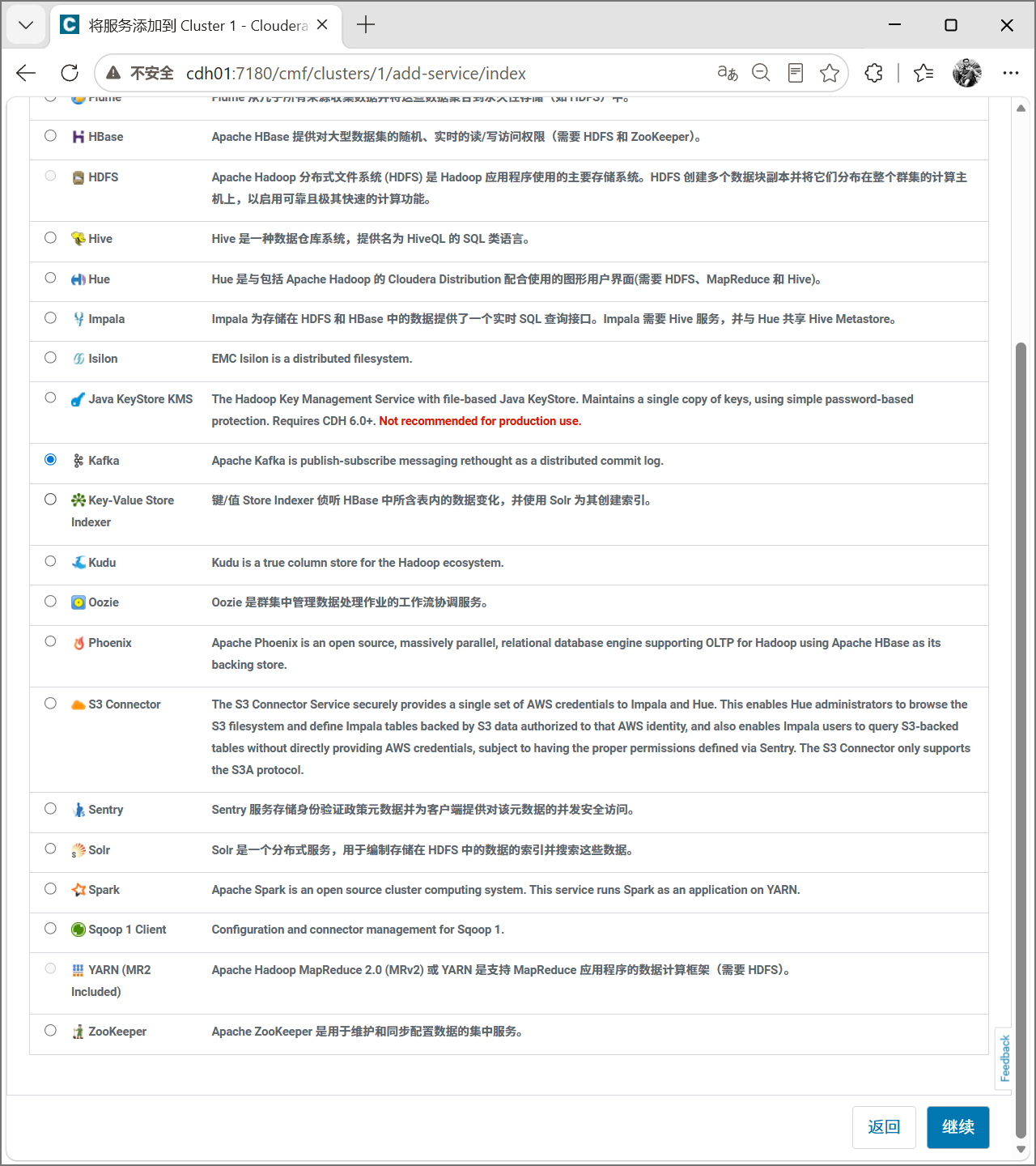
选择Kafka服务,点击继续。
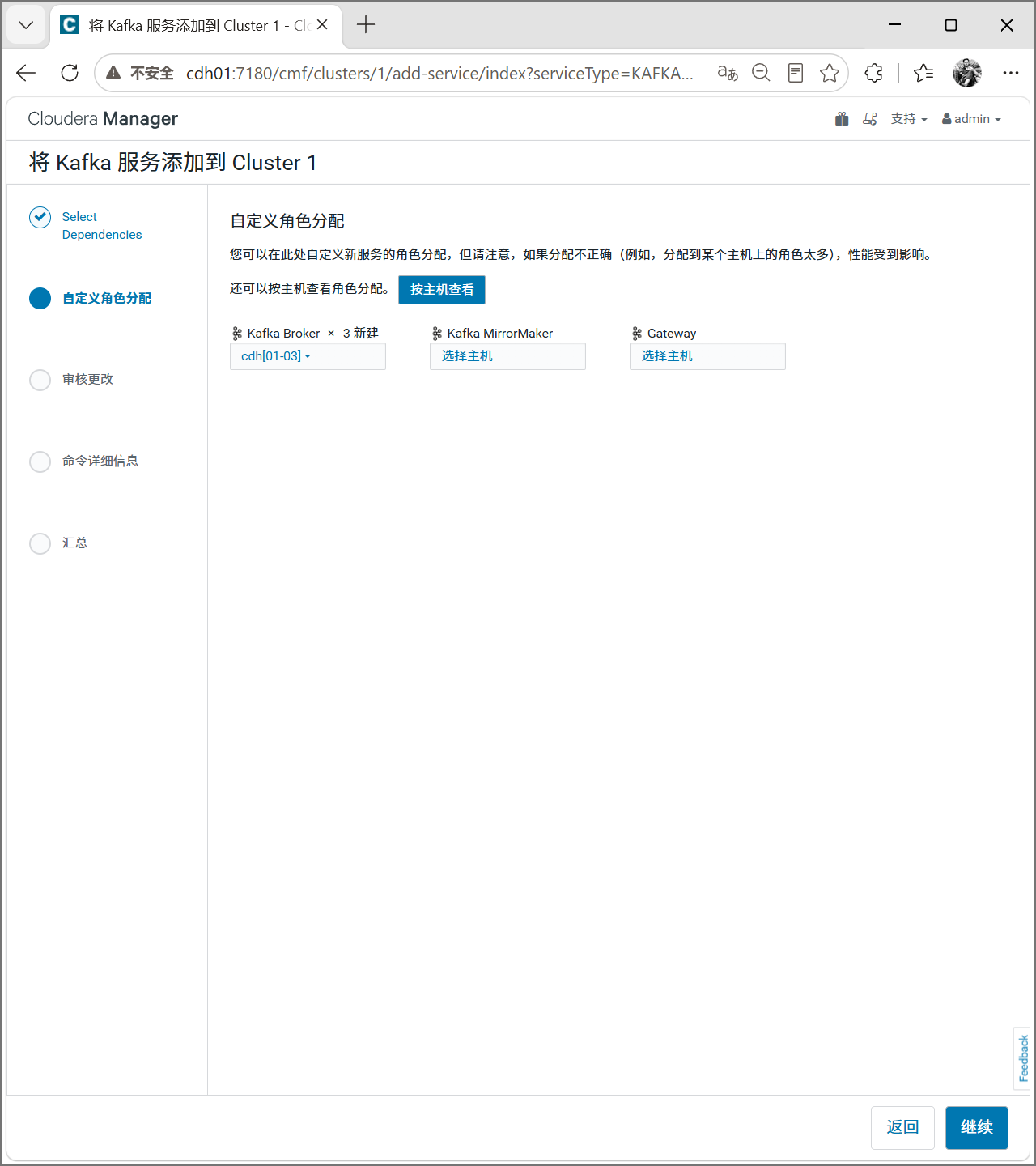
将第一个设置为3台机器。
滑倒下方将有颜色提示的那一部分改为图中所示,如果内存足够可以设置大一点。
等待安装。
二、创建topic
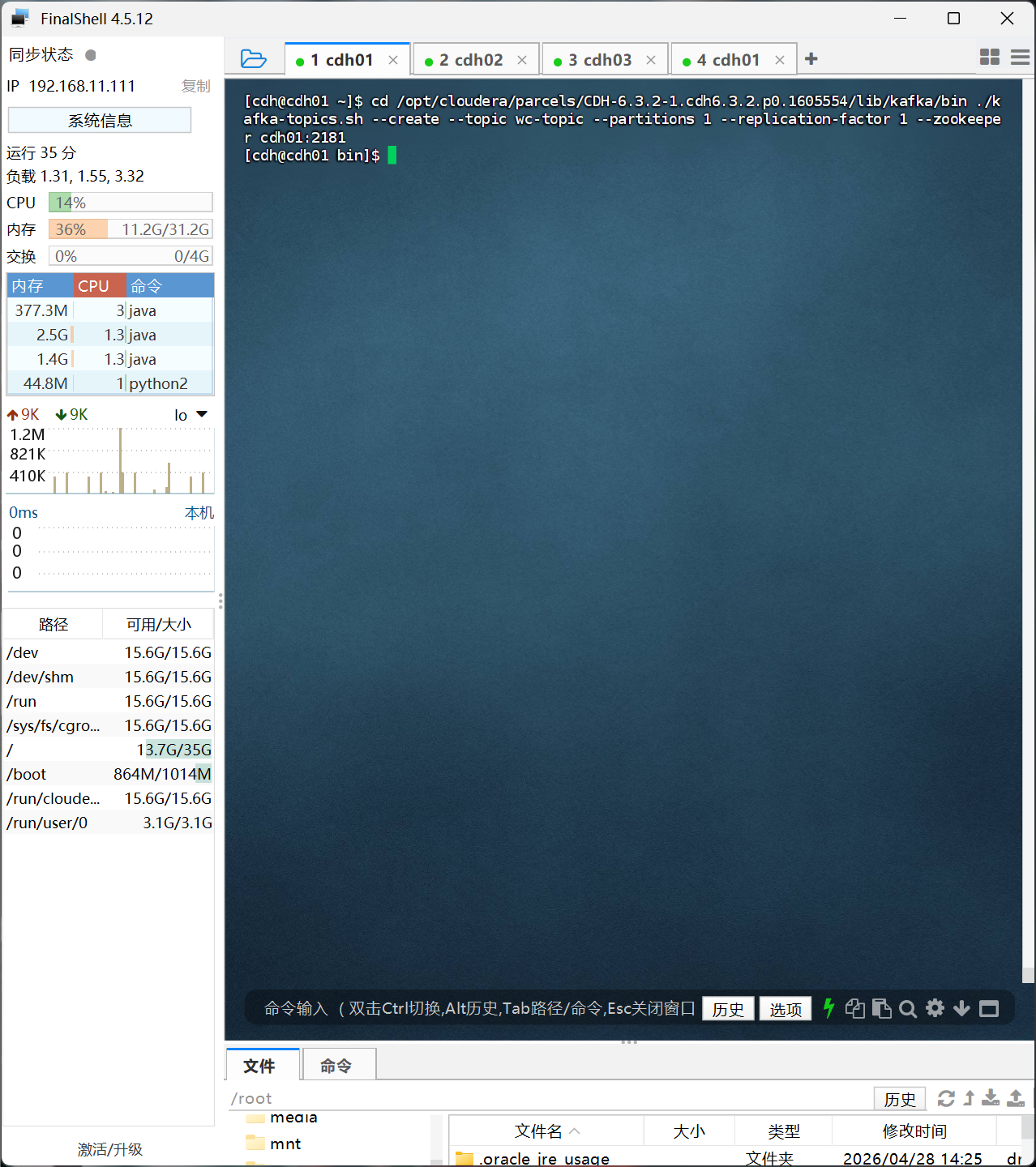
来到主机一使用cdh用户,执行以下命令创建topic
cd /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/kafka/bin ./kafka-topics.sh --create --topic wc-topic --partitions 1 --replication-factor 1 --zookeeper cdh01:2181
三、启动spark
继续在第一台机器使用cdh用户执行以下命令启动spark,如果内存够用可以直接spark-shell启动,内存有限采取以下方式:
spark-shell \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--conf spark.executor.memoryOverhead=128m \
--packages org.apache.spark:spark-streaming-kafka-0-10_2.11:2.4.0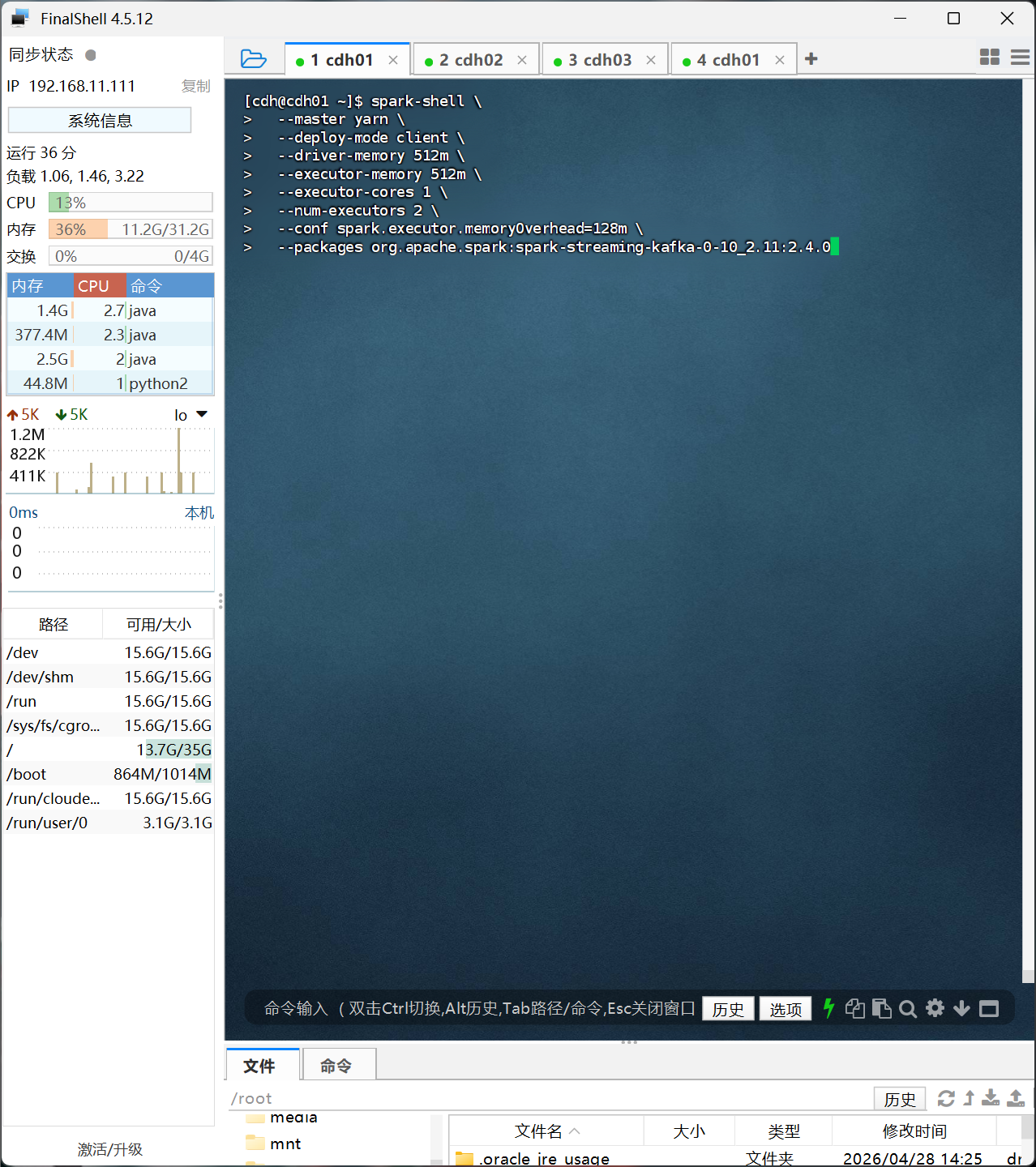
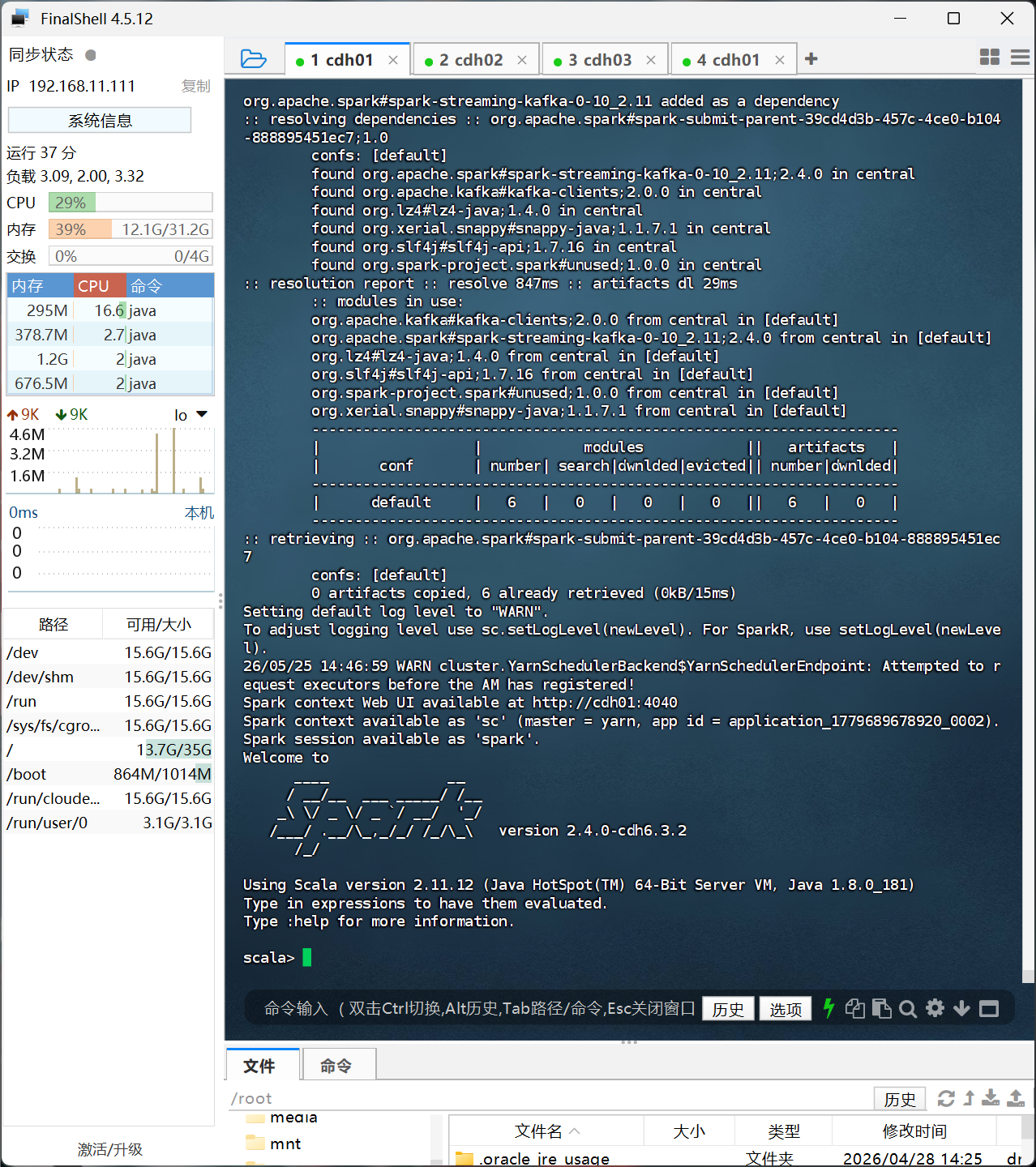
成功看到scale后,就进入Spark了,然后我们一次性复制以下内容并运行:
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
// 使用已有的 SparkContext (sc) 创建 StreamingContext,批次间隔 3 秒
val ssc = new StreamingContext(sc, Seconds(3))
// Kafka 消费者配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "cdh01:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "spark-group",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Set("wc-topic") // 与第 1 步创建的 topic 名称一致
// 创建 Kafka Direct Stream
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
// 词频统计并打印
stream.map(_.value())
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print()
// 启动流计算
ssc.start()
ssc.awaitTermination()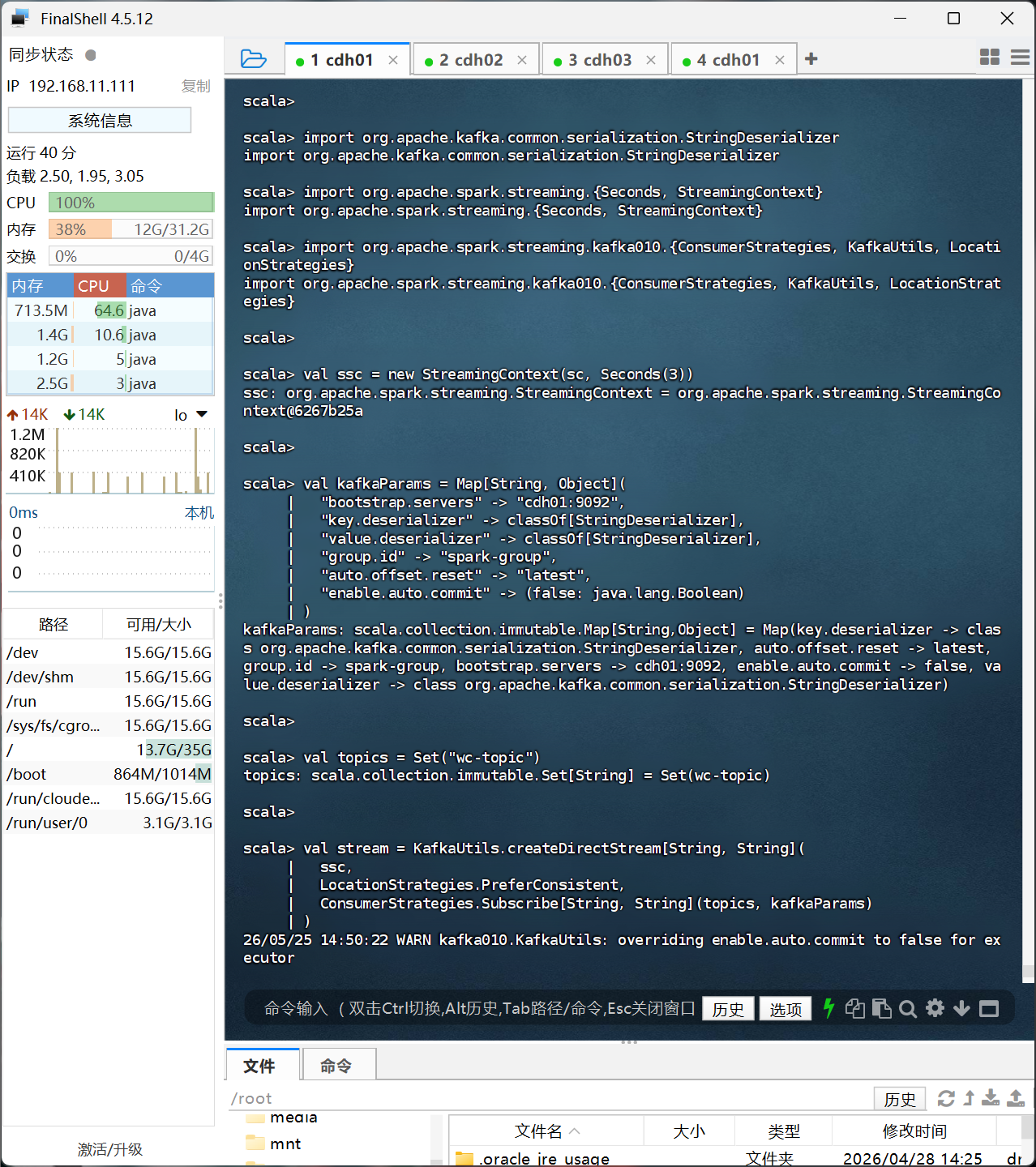
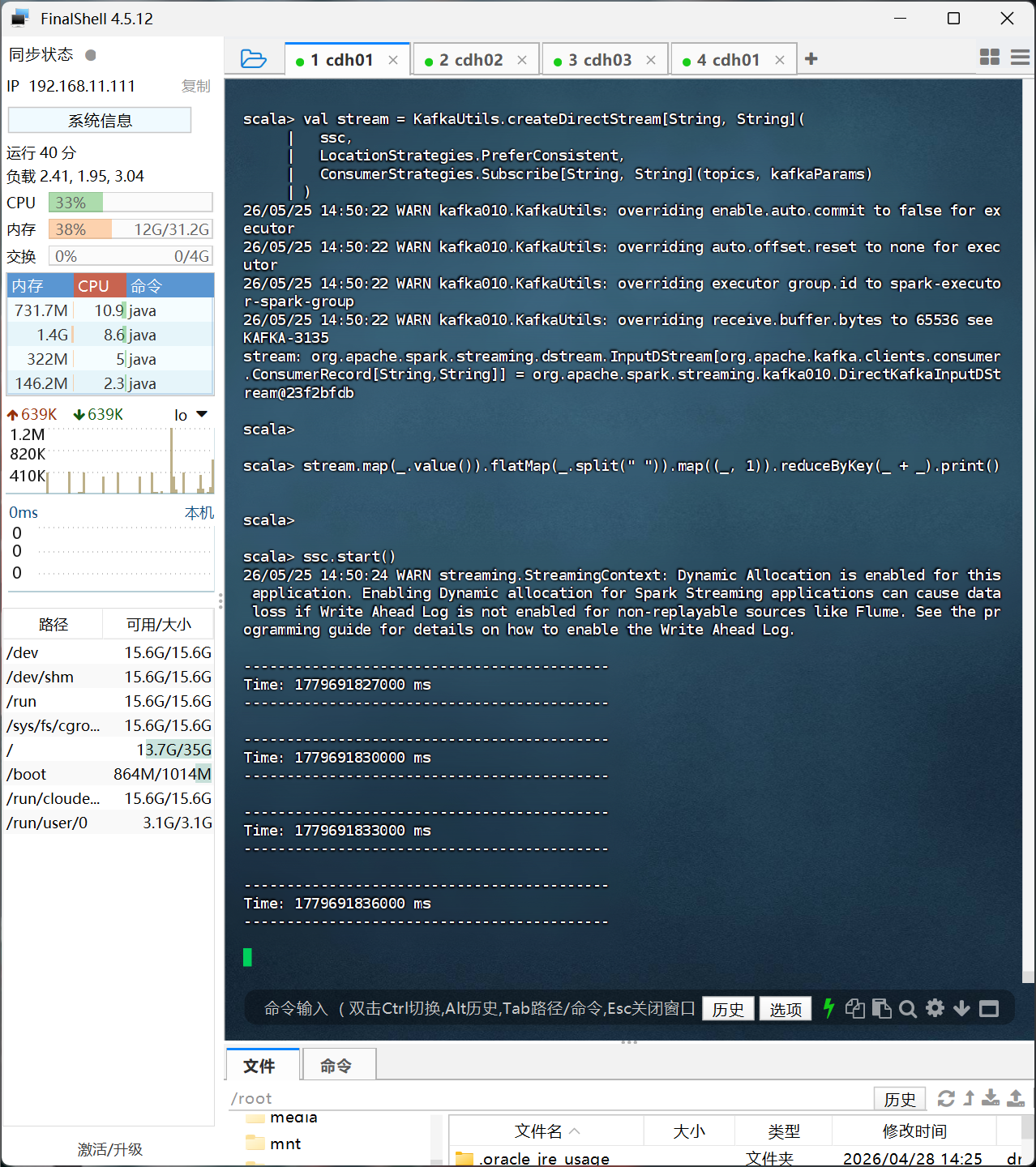
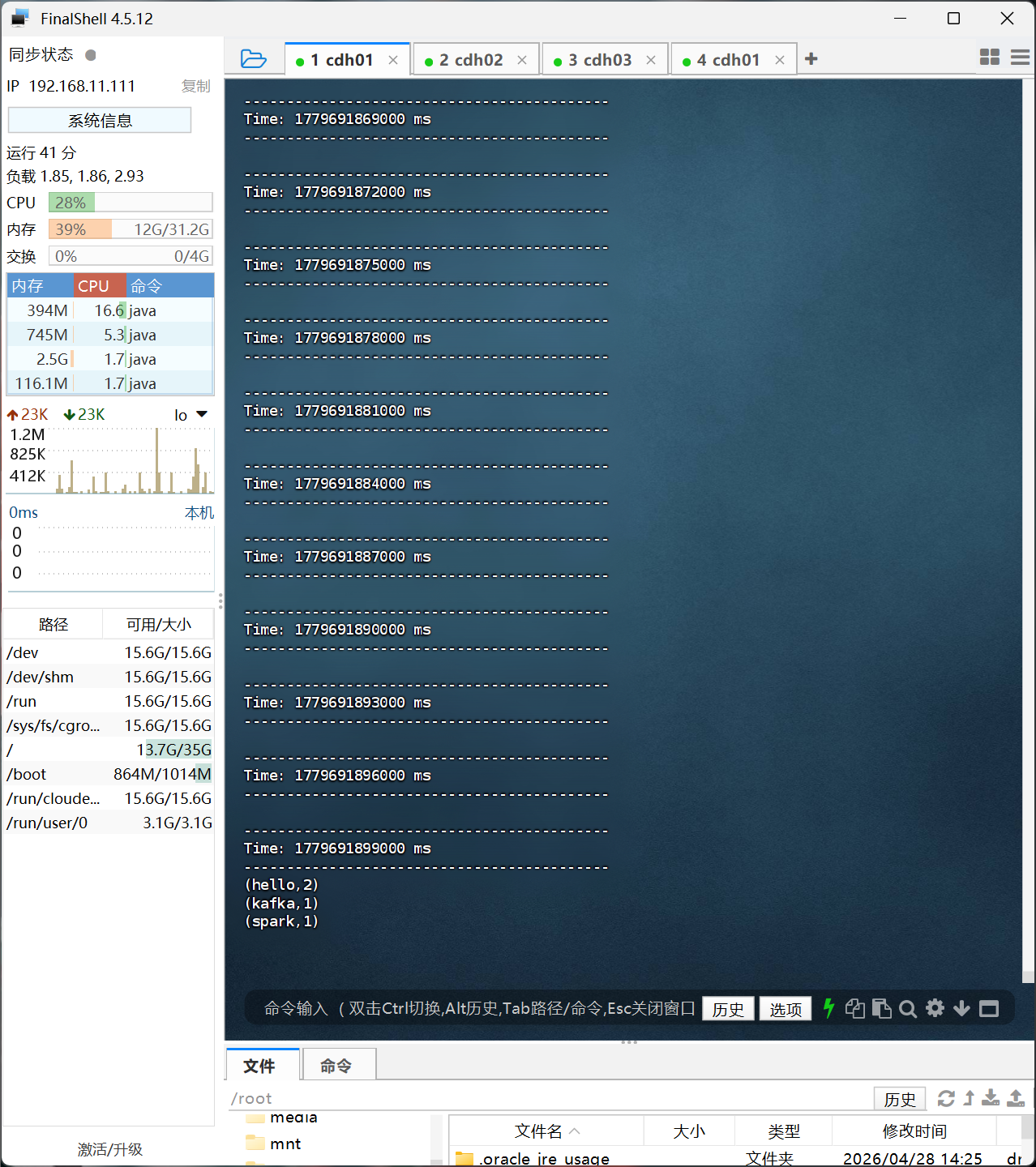
成功运行后我们会看到Time一直在输出,这是正常的,接下来我们在用Fineshell连接cdh01机器,在这一上面执行
cd /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/kafka/bin/
./kafka-console-producer.sh --broker-list cdh01:9092 --topic test_topic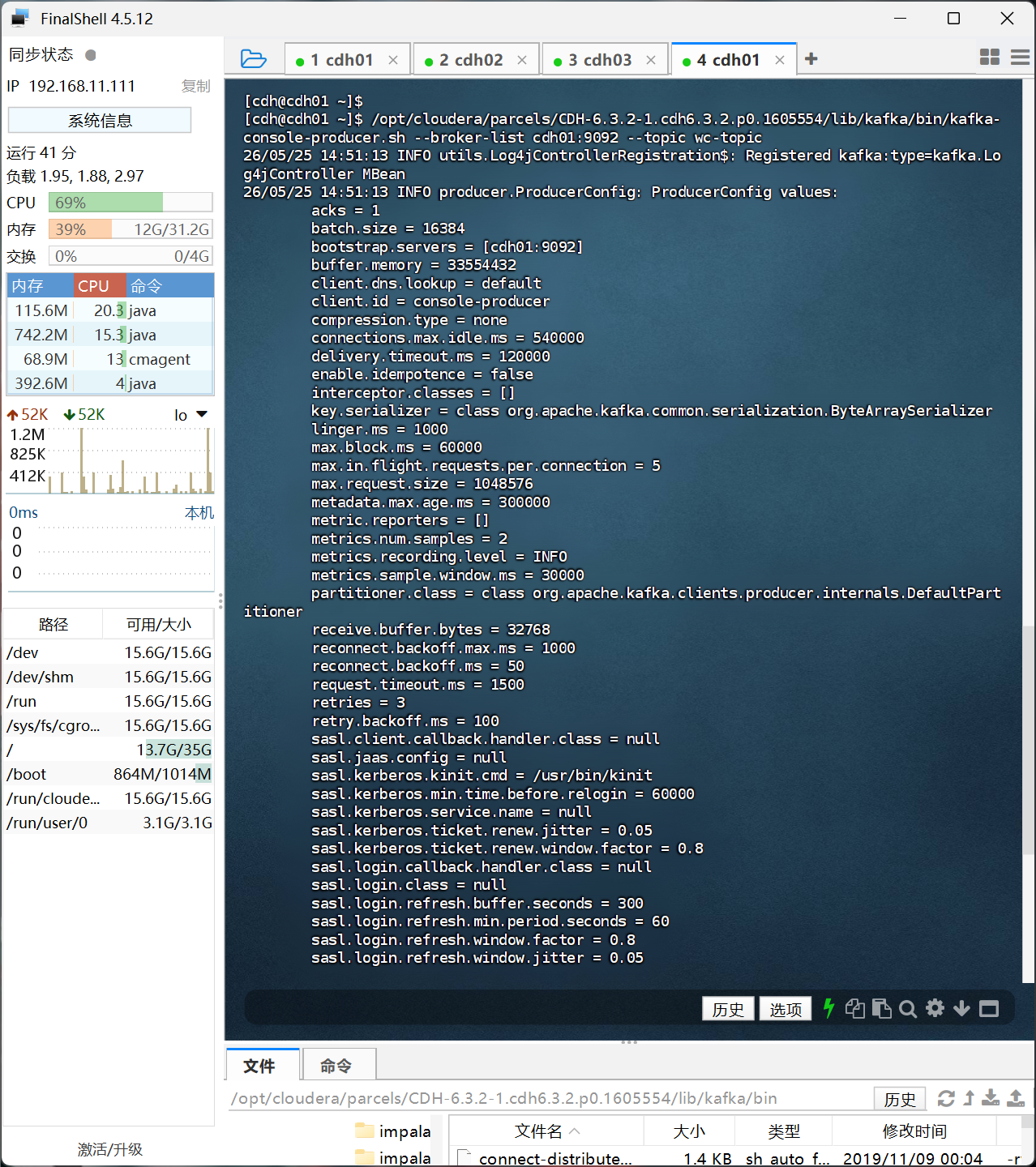
出现命令行可以输入后我们输入
hello spark kafka hello进行自动统计单词。
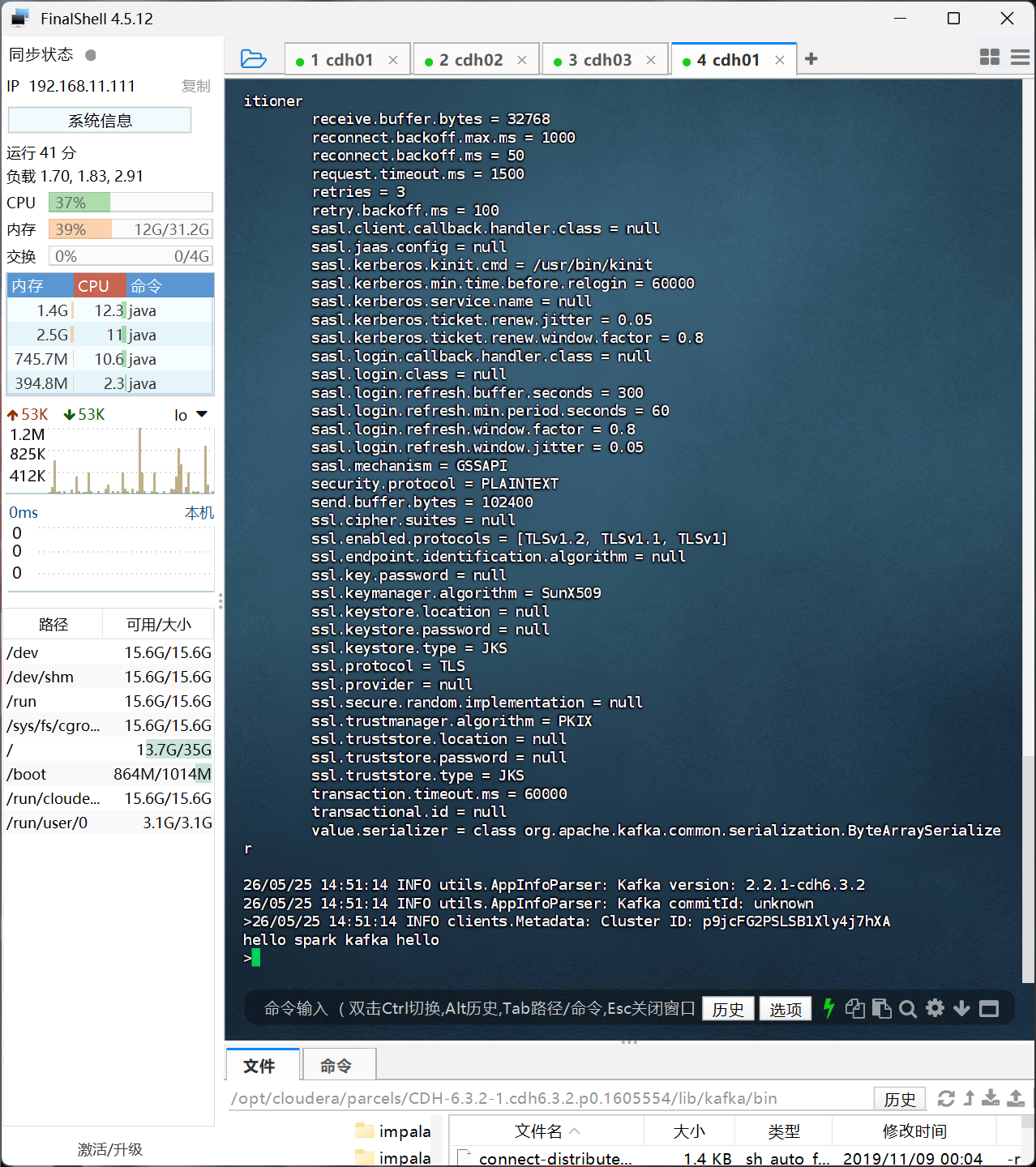
回车后我们回到一开始的主机,就可以看到打印的统计数据了