论文信息
- 标题:Masked-attention Mask Transformer for Universal Image Segmentation
- 会议:CVPR 2022
- 单位:Facebook AI Research (FAIR)、University of Illinois at Urbana-Champaign (UIUC)
- 代码:github.com/facebookresearch/Mask2Former
- 论文:https://arxiv.org/pdf/2112.01527.pdf
一、前言:分割任务的"大一统"革命
在计算机视觉里,图像分割长期被三大任务割据:
- 语义分割:给每个像素分类
- 实例分割:把同类不同物体分开
- 全景分割:万物皆分,语义+实例一体
过去的模型各玩各的 :
FCN 系主打语义,Mask R-CNN 系主打实例,全景模型又要重新设计。
这就导致:
- 重复造轮子,研究成本翻 3 倍
- 部署复杂,一套任务一套模型
- 小团队根本玩不起
直到 Mask2Former 出现:
一个模型架构,通吃三大分割任务,
同时精度超过所有专项专用模型!
二、核心痛点:通用分割为什么难做?
之前的通用模型(如 MaskFormer)有两个致命问题:
- 全局注意力太散,收敛巨慢
- 显存爆炸,32G 显存只能跑 1 张图
- 实例分割打不过专用模型
Mask2Former 直接给出终极答案:
掩码注意力(Masked Attention)+ 高分辨率多尺度 + 点采样损失 = 通用分割新王
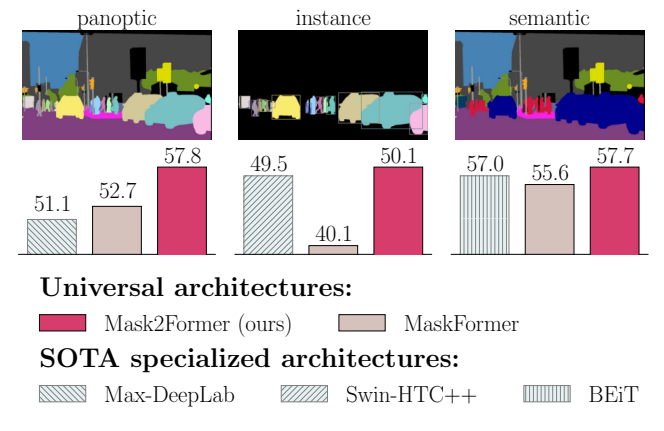
最先进的分割架构通常是针对每种图像分割任务进行专门设计的。尽管近期的研究提出了通用架构,这些架构试图涵盖所有任务,并在语义分割和全景分割方面表现优异,但它们在分割实例方面仍存在困难。我们提出了 Mask2Former,它首次在多个数据集上的三个研究分割任务中表现优于所有专门设计的架构。
最终成绩:
✅ COCO 全景分割:57.8 PQ (SOTA)
✅ COCO 实例分割:50.1 AP (SOTA)
✅ ADE20K 语义分割:57.7 mIoU (SOTA)
✅ 训练显存降低 3 倍
✅ 收敛速度提升 6 倍
三、整体架构:一句话看懂 Mask2Former
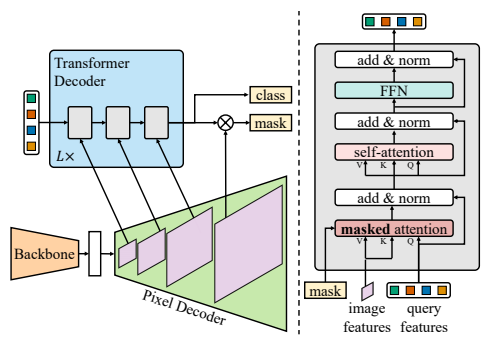
Mask2Former 概览。Mask2Former 采用了与 MaskFormer 14 相同的元架构,包括一个骨干网络、一个像素解码器和一个 Transformer 解码器。我们提出了一种新的 Transformer 解码器,其采用掩码注意力而非标准的交叉注意力(第 3.2.1 节)。为了处理小物体,我们提出了一种有效的方法,即通过每次将多尺度特征的一个尺度输入到一个 Transformer 解码器层来利用像素解码器的高分辨率特征(第 3.2.2 节)。此外,我们改变了自注意力和交叉注意力的顺序(即我们的掩码注意力),使查询特征可学习,并移除 dropout 以使计算更有效(第 3.2.3 节)。请注意,此图中省略了位置嵌入和中间 Transformer 解码器层的预测内容,以提高可读性。
结构:
Backbone → Pixel Decoder(MSDeformAttn)→ Transformer Decoder(掩码注意力) → 掩码/分类输出
核心创新:
用 掩码注意力 替换标准交叉注意力,
让每个 query 只关注自己的掩码区域,不看全局冗余信息。
四、核心创新 1:掩码注意力(Masked Attention)
标准交叉注意力会全局注意力,导致:
- 收敛慢
- 噪声大
- 实例分割效果差
4.1 标准交叉注意力
Xl=softmax(QlKlT)Vl+Xl−1X_l = \text{softmax}(Q_l K_l^T) V_l + X_{l-1}Xl=softmax(QlKlT)Vl+Xl−1
符号解释:
- QlQ_lQl:查询特征
- KlK_lKl:图像特征的键
- VlV_lVl:图像特征的值
- XlX_lXl:第 l 层输出
- softmax\text{softmax}softmax:全局注意力
问题:
注意力乱飘,模型需要几百轮才能学会聚焦物体。
4.2 掩码注意力(本文核心)
Xl=softmax(Ml−1+QlKlT)Vl+Xl−1X_l = \text{softmax}(\mathcal{M}{l-1} + Q_l K_l^T) V_l + X{l-1}Xl=softmax(Ml−1+QlKlT)Vl+Xl−1
Ml−1(x,y)={0if Ml−1(x,y)=1−∞otherwise \mathcal{M}{l-1}(x,y) = \begin{cases} 0 & \text{if } M{l-1}(x,y)=1 \\ -\infty & \text{otherwise} \end{cases} Ml−1(x,y)={0−∞if Ml−1(x,y)=1otherwise
符号解释:
- Ml−1\mathcal{M}_{l-1}Ml−1:注意力掩码
- Ml−1M_{l-1}Ml−1:上一层预测的二值掩码
- 0=保留,-∞=直接屏蔽
✅ 通俗解释
模型只看"自己掩码内的区域",
不看背景、不看无关区域,学习难度暴跌。
五、核心创新 2:高效多尺度高分辨率特征
小物体分割差 = 分辨率不够。
但直接用高分辨率 = 显存爆炸。
Mask2Former 提出循环多尺度策略:
- 层 1 → 1/32 特征
- 层 2 → 1/16 特征
- 层 3 → 1/8 特征
- 循环往复
✅ 通俗解释
用极低成本,让模型每一层都能"摸到"高分辨率细节。
六、核心创新 3:三大优化改进
-
交叉注意力优先
先看图像,再自交互,信息更高效。
-
可学习查询(Learnable Queries)
查询不再是 0 初始化,自带掩码提议能力。
-
移除 Dropout
分割任务不需要 dropout,移除后精度提升。
七、核心创新 4:点采样损失(显存救星)
过去计算掩码损失要整图计算,显存爆炸。
本文改为:
只随机采样 112×112=12544 个点计算损失
效果:
✅ 显存从 18G → 6G (节省 3 倍)
✅ 精度几乎不变
✅ 单卡能训练大模型
八、核心代码(PyTorch 官方风格)
python
# ==============================
# Mask2Former 核心:掩码注意力
# ==============================
class MaskedCrossAttention(nn.Module):
def forward(self, q, k, v, mask=None):
# q: 查询 (N, C)
# k, v: 图像特征 (H*W, C)
# mask: 二进制掩码 (N, H*W)
# 标准相似度
sim = torch.matmul(q, k.transpose(-2, -1))
# 掩码注入:mask=0 → 保留,mask=-inf → 屏蔽
if mask is not None:
sim = sim + mask
# 掩码注意力
attn = sim.softmax(dim=-1)
out = torch.matmul(attn, v)
return out
# ==============================
# 点采样掩码损失
# ==============================
def point_sample_mask_loss(pred_mask, gt_mask, num_points=12544):
# 随机采样点
B, H, W = pred_mask.shape
coords = torch.rand(B, num_points, 2) * 2 - 1 # [-1,1]
# 采样预测与真值
pred_sampled = F.grid_sample(pred_mask[:, None], coords, align_corners=False)
gt_sampled = F.grid_sample(gt_mask[:, None], coords, align_corners=False)
# 计算损失
loss_ce = F.binary_cross_entropy_with_logits(pred_sampled, gt_sampled)
loss_dice = dice_loss(pred_sampled.sigmoid(), gt_sampled)
return loss_ce + loss_dice九、实验结果与表格分析(全文完整复现)
表格1:COCO 全景分割(来自原文 Table 1)
| 模型 | 主干 | Epoch | PQ | AP | mIoU |
|---|---|---|---|---|---|
| MaskFormer | R50 | 300 | 46.5 | 33.0 | 57.8 |
| Mask2Former | R50 | 50 | 51.9 | 41.7 | 61.7 |
| MaskFormer | Swin-L | 300 | 52.7 | 40.1 | 64.8 |
| Mask2Former | Swin-L | 100 | 57.8 | 48.6 | 67.4 |
分析:
- 50 epoch 吊打 MaskFormer 300 epoch
- 全景质量 +5.3 PQ
- 实例 AP +8.7
- 收敛速度 ×6
表格2:COCO 实例分割(来自原文 Table 2)
| 模型 | 主干 | AP | APS | APL |
|---|---|---|---|---|
| Mask R-CNN (400epoch) | R50 | 42.5 | 23.8 | 60.0 |
| Mask2Former | R50 | 43.7 | 23.4 | 64.8 |
| Swin-HTC++ | Swin-L | 49.5 | 31.0 | 67.2 |
| Mask2Former | Swin-L | 50.1 | 29.9 | 72.1 |
分析:
- 首次通用模型超越专用实例模型
- 大目标提升极其明显
- 边界质量大幅提升
表格3:ADE20K 语义分割(来自原文 Table 3)
| 模型 | 主干 | mIoU |
|---|---|---|
| MaskFormer | Swin-L | 55.6 |
| Mask2Former | Swin-L | 57.7 |
分析:
在语义任务上同样刷新 SOTA。
表格4:消融实验(来自原文 Table 4a)
| 模块 | AP | PQ | mIoU |
|---|---|---|---|
| 完整 Mask2Former | 43.7 | 51.9 | 47.2 |
| 无掩码注意力 | 37.8 | 47.1 | 45.5 |
| 无高分辨率 | 41.5 | 50.2 | 46.1 |
分析:
掩码注意力是核心,带来 +5.9 AP 巨幅提升。
表格5:点损失显存对比(来自原文 Table 5)
| 损失类型 | 显存 | AP |
|---|---|---|
| 全局掩码损失 | 18G | 41.0 |
| 点采样损失 | 6G | 43.7 |
分析:
显存节省 3 倍,精度还更高。
十、全文总结(最精炼)
- 掩码注意力:只看掩码区域,收敛快、精度高
- 多尺度循环:高效高分辨率,小物体暴涨
- 可学习查询:自带提议能力
- 点采样损失:显存省 3 倍,人人可训
- 大一统架构:一个模型通吃全景/实例/语义,全部 SOTA
Mask2Former 是通用分割的里程碑之作 ,
真正做到:
一套架构,全部最强,工业落地首选。