文章目录
- [1. 插入排序](#1. 插入排序)
-
- [1.1 基本思想](#1.1 基本思想)
- [1.2 直接插入排序](#1.2 直接插入排序)
-
- 1.2.1代码实现
- [1.2.2 代码讲解](#1.2.2 代码讲解)
- [1.2.3 复杂度](#1.2.3 复杂度)
- [1.2.4 直接插入排序优化:折半插入排序](#1.2.4 直接插入排序优化:折半插入排序)
- [2.2 希尔排序(插入排序的升级版,比较难理解)](#2.2 希尔排序(插入排序的升级版,比较难理解))
-
- [2.2.1 直接插入排序最大的弊端](#2.2.1 直接插入排序最大的弊端)
- [2.3 希尔排序完整代码](#2.3 希尔排序完整代码)
-
- [2.3.1 代码讲解](#2.3.1 代码讲解)
- [2.3 复杂度与稳定性详细分析](#2.3 复杂度与稳定性详细分析)
-
- [2.3.1 时间复杂度](#2.3.1 时间复杂度)
- 2.3.2**空间复杂度**
- [2.4 全文总结](#2.4 全文总结)
1. 插入排序
1.1 基本思想
直接插入排序是一种简单的插入排序法,其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。
实际中我们玩扑克牌时,就用了插入排序的思想
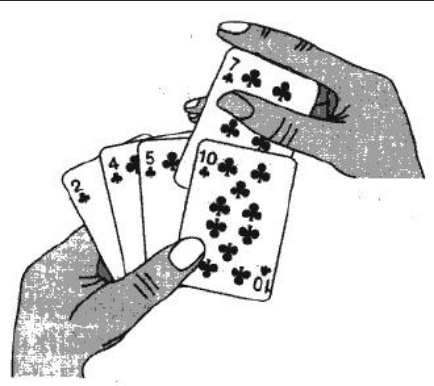
1.2 直接插入排序
当插入第i(i>=1)个元素时,前面的array0,array1,...,arrayi-1已经排好序,此时用arrayi的排序码与arrayi-1,arrayi-2,...的排序码顺序进行比较,找到插入位置即将arrayi插入,原来位置上的元素顺序后移
流程: 下一个数跟前面的一个进行比较,如果大于的话,前面一个数前移,然后继续进行比较直到找到比他小的数,然后插入。
1.2.1代码实现
以下代码以升序排序为例,包含完整的排序函数、测试用例和运行结果,可直接编译运行:
c
#include <stdio.h>
// 直接插入排序(升序)
void InsertSort(int arr[], int n) {
// 1. 外层循环:控制待插入元素(无序区间的起始位置)
// 数组第一个元素arr[0]默认是有序区间,从第二个元素arr[1]开始逐个处理
for (int i = 1; i < n; i++) {
// 2. 保存待插入元素
// 这里必须先存起来!后面元素后移时会覆盖arr[i],不保存就会丢失数据
int insertVal = arr[i];
// 3. 定义有序区间的末尾下标
int j = i - 1;
// 4. 内层循环:从有序区间末尾向前遍历,寻找插入位置
// 循环条件:j不越界,且有序区间当前元素比待插入元素大(需要继续往前找)
while (j >= 0 && arr[j] > insertVal) {
// 元素后移:把比待插入元素大的元素往后挪一位,腾出位置
arr[j + 1] = arr[j];
j--; // 继续向前比对
}
// 5. 插入元素:循环结束时,j+1就是待插入元素的正确位置
arr[j + 1] = insertVal;
}
}
// 打印数组函数
void PrintArr(int arr[], int n) {
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
// 测试主函数
int main() {
// 测试用例:包含重复元素、无序数据
int arr[] = {49, 38, 65, 97, 76, 13, 27, 49};
int n = sizeof(arr) / sizeof(arr[0]);
printf("排序前数组:");
PrintArr(arr, n);
InsertSort(arr, n);
printf("排序后数组:");
PrintArr(arr, n);
return 0;
}运行结果:
c
排序前数组:49 38 65 97 76 13 27 49
排序后数组:13 27 38 49 49 65 76 97 1.2.2 代码讲解
1. 外层循环:为什么从i=1开始
直接插入排序默认数组的第一个元素arr0是有序区间,所以我们只需要从第二个元素(下标1)开始,逐个处理无序区间的元素。
- 每一次循环,i代表无序区间的起始下标,有序区间的范围是0, i-1
- 循环结束时,i会遍历到数组末尾,整个数组都会变成有序区间
2. 保存待插入元素:为什么要定义insertVal?
这是代码里最关键的细节之一。
当我们执行 arrj + 1 = arrj 时,会把有序区间的元素向后移动一位,而 arri 本身就是无序区间的第一个元素,移动过程中 arri 的值会被覆盖。如果不提前保存,最后插入的时候就会丢失原本的待插入元素,导致排序结果错误。
3. 内层循环:为什么从有序区间末尾向前遍历?
- 从后往前遍历的好处是:一旦找到比待插入元素小的元素,它的下一个位置就是插入位置,不需要遍历整个有序区间,减少不必要的比较次数
- 循环条件j >= 0是为了防止数组下标越界,避免访问arr-1这种非法地址
4. 元素后移与插入位置:为什么最终插入arrj+1?
当内层循环结束时,有两种情况:
- 情况 1 :j >= 0 ,说明找到了比insertVal 小的元素,此时j指向的元素是有序区间中第一个比insertVal小的元素,j+1就是待插入的位置
- 情况 2 :j < 0 ,说明待插入元素比有序区间所有元素都小,此时j+1 = 0,正好是数组的开头位置
两种情况都满足arrj+1 = insertVal,所以这一步可以统一处理。
1.2.3 复杂度
1. 时间复杂度
最好情况(数组已有序): 时间复杂度为O(n)
此时内层循环的条件arrj > insertVal永远不成立,不会执行元素后移操作,算法只需遍历一次数组即可完成排序
最坏情况(数组逆序): 时间复杂度为O(n²)
每个元素都需要和前面所有有序区间的元素比较并移动,总比较次数为n(n-1)/2,移动次数也为n(n-1)/2
平均情况:时间复杂度为O(n²)
2. 空间复杂度
直接插入排序是原地排序算法,只使用了常数级别的额外空间(insertVal、i、j等变量),空间复杂度为O(1)。
3. 稳定性
直接插入排序是稳定排序算法。
代码中我们的比较条件是arrj > insertVal,只有当有序区间的元素严格大于待插入元素时才会后移,不会移动和待插入元素相等的元素,因此重复元素的相对位置不会改变。
比如测试用例中的两个49,排序后它们的先后顺序和原数组保持一致。
1.2.4 直接插入排序优化:折半插入排序
直接插入排序的核心耗时在「元素比较」和「元素移动」上,其中元素移动的次数无法减少,但比较次数可以优化。
我们可以用 ** 折半查找(二分查找)** 来替代顺序查找,快速找到待插入元素的位置,减少比较次数,这就是折半插入排序。
c
void BinaryInsertSort(int arr[], int n) {
for (int i = 1; i < n; i++) {
int insertVal = arr[i];
int low = 0, high = i - 1;
// 折半查找插入位置
while (low <= high) {
int mid = (low + high) / 2;
if (arr[mid] > insertVal) {
high = mid - 1;
} else {
low = mid + 1;
}
}
// 元素后移:从low到i-1的元素都需要后移一位
for (int j = i - 1; j >= low; j--) {
arr[j + 1] = arr[j];
}
// 插入元素
arr[low] = insertVal;
}
}折半插入排序的时间复杂度仍然是O(n²),但减少了比较次数,对于数据量较大的有序数组,效率会有明显提升。
2.2 希尔排序(插入排序的升级版,比较难理解)
前面我们已经完整学完了直接插入排序,它逻辑简单、代码好写、稳定性强,但有一个致命短板:
当数组无序程度很高、逆序元素多的时候,每一个元素都要往前逐个比较、一步步后移,元素移动次数极多,效率非常低。
那能不能想个办法,让大的元素快速挪到后面、小的元素快速挪到前面,不用一步一步慢慢挪?
基于这个思路,希尔排序诞生了。希尔排序本质就是对直接插入排序的极致优化,也叫缩小增量排序。
2.2.1 直接插入排序最大的弊端
直接插入排序是相邻元素逐个移动,步长只能是 1:
比如一个很小的数在数组最后面,它要一步一步往前挪,和前面每一个元素比较、逐个后移,移动次数太多、效率极低。
它只适合两种场景:
- 数据量很小
- 数组本身已经接近有序
一旦数据乱序、逆序严重,直接插入排序就会变得非常慢。
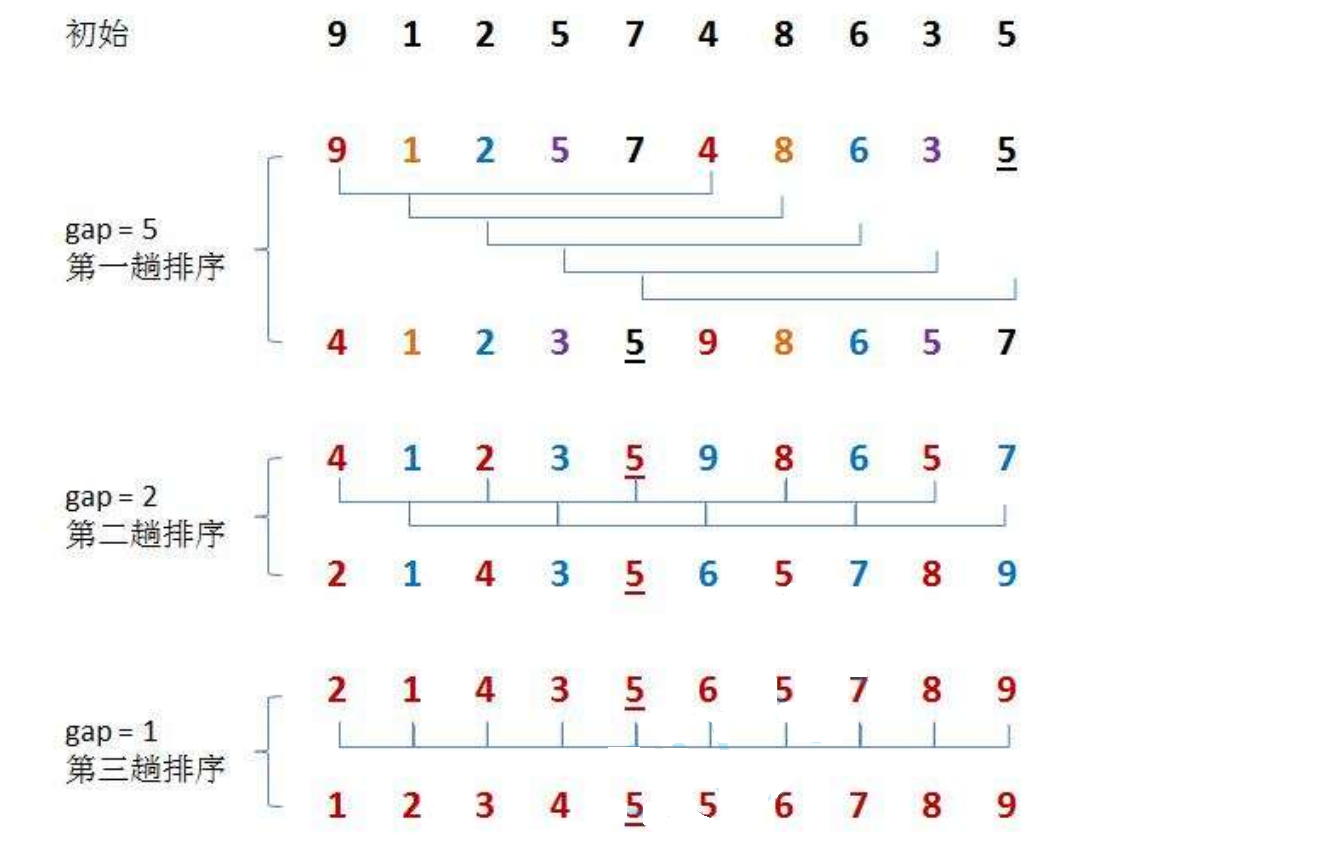
引入间隔 Gap 的核心目的 :
我们设置一个间隔增量 Gap,把相隔 Gap 距离的元素分为一组:
- 元素不再一步一步挪,而是跨越式移动
- 小元素可以直接跳到前面,大元素直接甩到后面
- 不用逐个相邻比较,一次性把远距离的逆序先调整好
一句话:设置间隔,就是为了让元素实现「跳跃式移动」,提前把数组调成基本有序,避免后期大量逐个挪动。
为什么间隔要从大到小,最后缩小到 1?
一.初始 Gap 很大
分组少、每组元素少,能快速把远距离的乱序元素调整到位,宏观上把数组捋顺。
二.逐步缩小 Gap
间隔变小,分组变多,每组元素变多,在前面宏观有序的基础上,做精细化微调。
三.最后 Gap 必须等于 1
当 Gap=1 时,就是标准的直接插入排序。
但此时数组经过前面多轮跳跃调整,已经接近有序,而直接插入排序在数组接近有序时效率是最高的。
这就是希尔排序的精髓:先粗调、后细调,大间隔宏观整理,小间隔精细收尾。
2.3 希尔排序完整代码
c
#include <stdio.h>
// 希尔排序
void ShellSort(int arr[], int n)
{
// 1. 初始增量设为数组长度一半
int gap = n / 2;
// 增量不断缩小,直到间隔为0停止
while (gap > 0)
{
// 从下标gap开始,对每个分组做直接插入排序
for (int i = gap; i < n; i++)
{
// 保存当前待插入元素,防止后移被覆盖
int temp = arr[i];
// 同组内前一个元素的下标
int j = i - gap;
// 组内向前比较,比temp大的元素向后跨越式移动
while (j >= 0 && arr[j] > temp)
{
arr[j + gap] = arr[j];
j = j - gap;
}
// 把元素放到正确位置
arr[j + gap] = temp;
}
// 增量减半,缩小间隔
gap = gap / 2;
}
}
// 打印数组
void PrintArray(int arr[], int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[] = {9, 5, 1, 8, 2, 7, 3, 6, 4};
int len = sizeof(arr) / sizeof(arr[0]);
printf("排序前:");
PrintArray(arr, len);
ShellSort(arr, len);
printf("排序后:");
PrintArray(arr, len);
return 0;
}2.3.1 代码讲解
增量循环:
c
while (gap > 0)只要间隔还大于 0,就继续分组排序,直到间隔变为 1 做完最后一轮,再缩到 0 结束。
遍历每个分组元素
c
for (int i = gap; i < n; i++)和直接插入排序 i=1 很像:
- 直插:从第 2 个元素开始,步长 1
- 希尔排序:从下标 gap 开始,步长仍是 1,但比较和移动的跨度是 gap
暂存待插入元素
c
int temp = arr[i];和直接插入排序完全一样:必须先保存元素,否则后面跨越式后移会把原值覆盖丢失。
同组前驱下标:
c
int j = i - gap;直接插入排序是 j = i - 1;
希尔排序是 j = i - gap。
唯一区别:往前找的步长从 1 变成了间隔 gap。
组内元素后移:
c
while (j >= 0 && arr[j] > temp)
{
arr[j + gap] = arr[j];
j = j - gap;
}直插:arrj+1 = arrj; j--
希尔:arrj+gap = arrj; j -= gap
逻辑一模一样,只是移动跨度从相邻 1 格,变成跳跃 Gap 格。
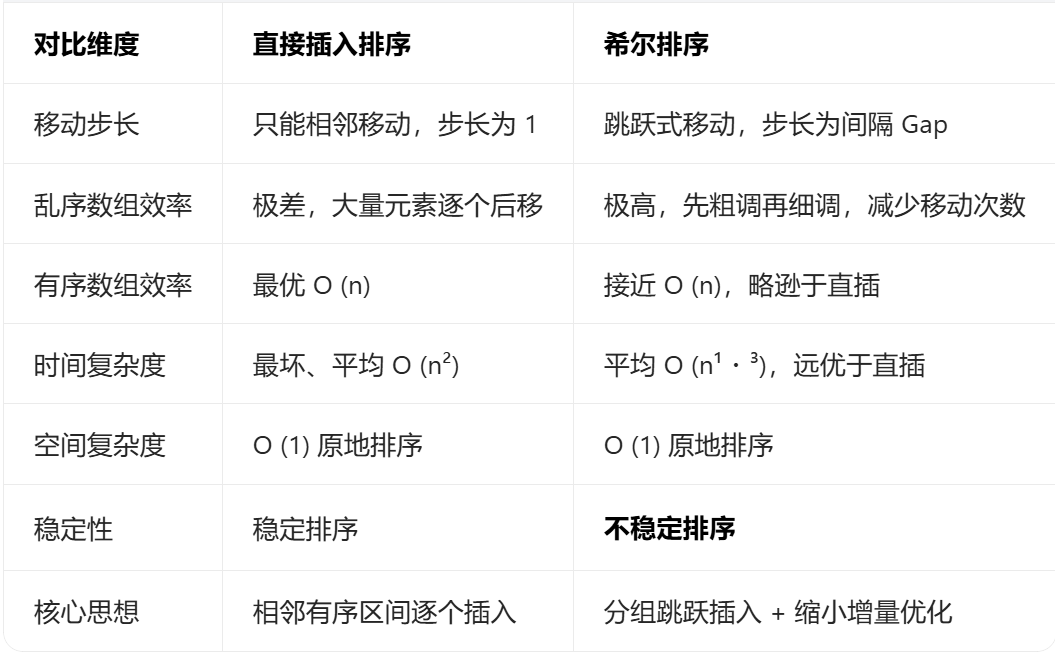
希尔排序没有改变直接插入排序的核心逻辑 ,只是加了分组 + 跳跃间隔,解决了直插在乱序数据下移动次数过多的痛点。
2.3 复杂度与稳定性详细分析
2.3.1 时间复杂度
- 采用 gap = gap/2 增量规则:平均时间复杂度 O (n¹・³)
- 最坏时间复杂度依然是 O (n²),但实际运行效率远高于直接插入排序
- 数组越接近有序,希尔排序效率越高
2.3.2空间复杂度
仅使用 gap、i、j、temp 临时变量,没有开辟额外数组,空间复杂度 O (1),属于原地排序算法。
2.4 全文总结
- 希尔排序是直接插入排序的优化升级版,专门解决直插乱序数据效率低的问题;
- 引入间隔 Gap 的目的:实现元素跳跃移动,提前宏观整理数组;
- 间隔从大到小:先粗调、后细调,最后 gap=1 回归直接插入排序收尾;
- 代码和直插高度相似,仅把步长 1 改成步长 gap,学习成本极低;
- 原地排序、效率更高,但丧失了稳定性,适合不要求保序的中等规模数据排序。