文章目录
-
- 一.开篇:从生活走进程序
- 二.核心概念:栈的逻辑结构
- 三.方案选择:顺序表or链表?
- 四.代码的实现
- [五. 总结:小结与反思](#五. 总结:小结与反思)
一.开篇:从生活走进程序
想象一下你家里洗碗时摞在一起的盘子,或者你桌子上堆起来的书,如果你想把拿到最下面的那一个,是不是要把上面的一次挪开;而你新买的书也只能放在最上。
这种"后进先出 "(Last In First Out,简称 LIFO)的逻辑,便是数据结构的------"栈(Stack)"
二.核心概念:栈的逻辑结构
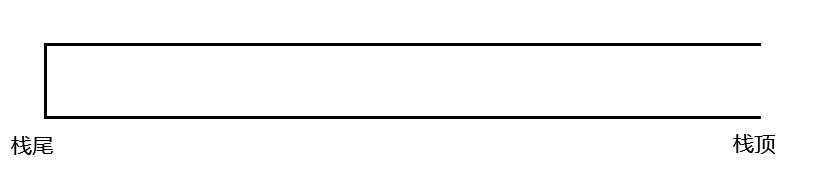
栈顶:类似于桶的开口部分,可以放入,拿出
栈底:类似于桶的底端(封闭)
入栈:从栈顶给栈添加数据
出栈:从栈顶删除数据
如图所示:
三.方案选择:顺序表or链表?
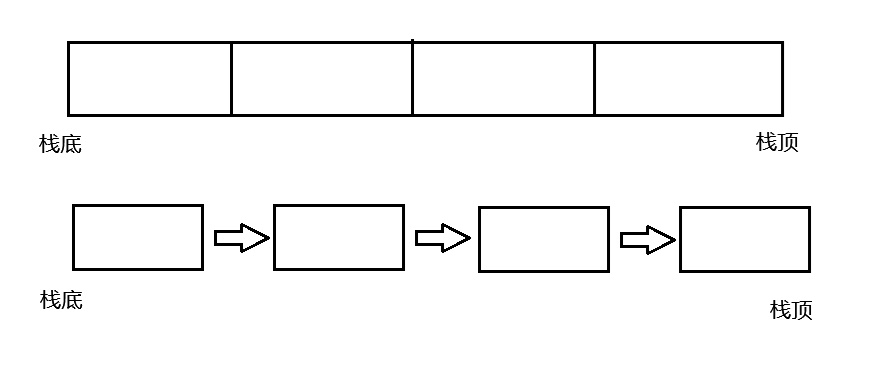
在这里不知道怎么选择的时候我们画图分析:
-
顺序表: 随机访问方便,便于快速的入栈出栈(缓存命中率高),更节省空间(只需要一个数组)
-
链表: 单链表的特殊性,随机访问需遍历 O(N), 且需要频繁的内存申请释放,但是也可以做到栈的实现
用顺序表来实现栈是典型的 " 用空间换取效率 ",虽一定程度上没被使用的空间会有浪费,但是现代计算机空间容量都很大,所以是更好的选择方案。
(补充): 缓存命中率:现代计算机体系中,数据存取通常是: CPU寄存器 >> 三级缓存(L1,L2,L3) >> 内存 >> 硬盘 从左至右速度越来越慢,容量越来越大
如果把寄存器中的数据称为现役军人的话,那么三级缓存中的数据则是预备役,为寄存器提供数据(给CPU预判并备货 ),而三级缓存的特性便是把一整块数据读取方便后续使用(假设要用a0,缓存会猜你可能要用a1 ,a2...则直接将a0到a7全部读取 ),CPU要用的数据被读取时便被称为缓存命中,而顺序表的的底层为数组,是一块连续的内存,这样的使用会非常高效,但是链表的内存是分散的,这样便会造成缓存命中率低下,故运行效率低。
"有了前面关于 CPU 缓存命中率 的铺垫,我们现在就用 C 语言来亲手构建一个基于连续内存的动态顺序栈。请注意看,我是如何处理内存申请与扩容细节的。"
四.代码的实现
我们需要创建三个文件
函数声明:Stack.h
函数定义:Stack.c
测试:Stack_test.c
1.动态栈结构的定义
(动态顺序表的结构)
c
//Stack.h
//栈结构的定义
typedef int STDataType;
//重定义方便数据类型的改变
typedef struct STack
{
STDataType* a;
int top;
int capacity;
}ST;注意包含头文件!
2.栈的初始化
c
//Stack.h
//声明
void STInit(ST* pst);
c
//stack.c
//定义
void STInit(ST* pst)
{
pst->a = NULL;
pst->top = pst->capacity = 0;
}在Stack_test.c中定义一个栈,测试一下功能
进入调试中观察一下,功能是否正常
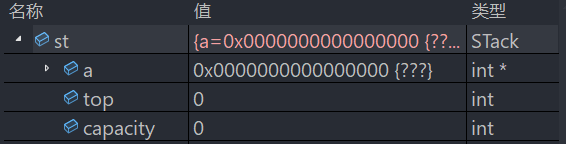
注意这里top初始化的值后面会有细节问题
完成了初始化,那么接下来我们补全另一个对立函数------销毁功能
4.栈的销毁
核心思路:释放空间,置空(防止野指针)
c
//Stack.c
//销毁
void STDestroy(ST* pst)
{
free(pst->a);
pst->a = NULL;
pst->capacity = pst->top = 0;
}测试一下:
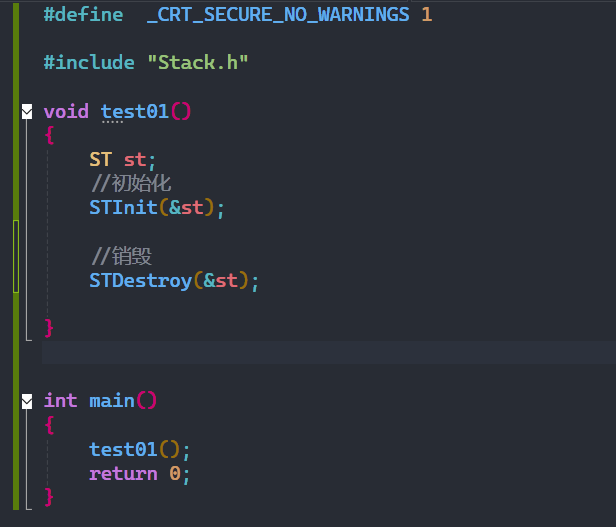
内存成功被释放并被置空
5.核心逻辑:入栈与出栈
1)入栈
(根据下标进行插入数据)
c
//Stack.c
//入栈
void STPush(ST* pst, STDataType x)
{
assert(pst);//防止传入空指针
//判断空间是否充足
if (pst->capacity == pst->top)
//前面我们将top的值初始化为0,在这里top的含义则和顺序表中size的含义相同
{
int newcapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;
STDataType* tmp = (STDataType*)realloc(pst->a,newcapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
pst->a = tmp;
pst->capacity = newcapacity;
}
pst->a[pst->top++] = x;//后置++,入栈后top向后移动
}三目操作符能更好的解决栈(顺序表)中 " 零状态 "
尽量不要直接改变参数值,应该重新定义一个中转变量进行操作,再给原参数赋值,如果realloc失败,则会直接覆盖掉pst->a的值,会造成内存泄漏数据丢失,这样用中转变量即使realloc失败,也可以保住原数据。
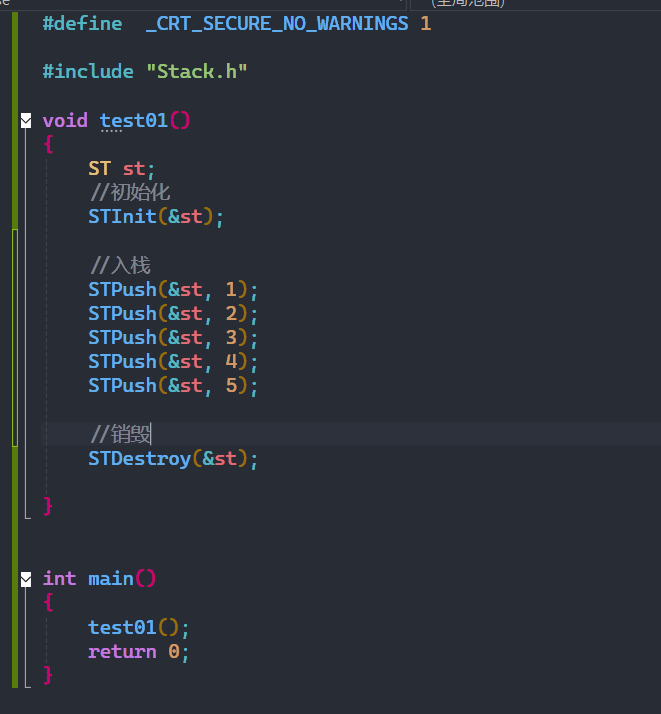
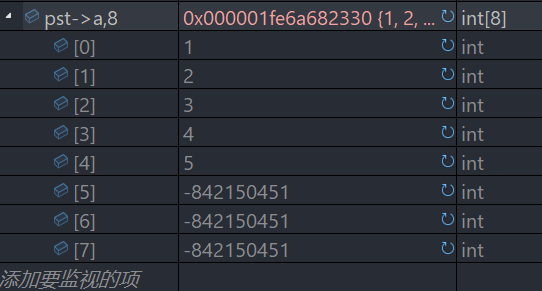
在这里我们调试的时候,需要注意如果想观察到数组内全部数据需要用 " ," ,指针,个数 的形式,这样就可以清晰的看到栈内元素了,不要弄成 " . " 了。
2)出栈
核心: 依据后进先出的规则,将可访问范围缩小即可(不是真正的物理删除)
c
//Stack.c
//出栈
void STPop(ST* pst)
{
assert(pst);//防止传入参数是空指针
assert(pst->top);//防止栈内零元素,桶中没东西还怎么拿?
pst->top--;
}这一步虽然简单我们也需要进行函数封装,以便接口的完整性和代码的可读性,切不可放在主函数中直接进行top - -;
top的范围已经被缩小,即顺序表可访问的元素范围也被缩小,即做到了出栈的功能
" 我的代码里只是执行了 top--。其实那个旧数据还静静地躺在内存里,并没有被物理删除,但在逻辑上它已经出栈了。这种处理方式极大地提高了出栈的效率,这就是顺序栈的魅力!"
6.逻辑的补充
1) 判空
c
//Stack.c
//判空
bool STEmpty(ST* pst)
{
assert(pst);
if (pst->top == 0)
{
return true;
}
else
{
return false;
}
}2) 获得栈顶元素
c
//Stack.c
//获得栈顶元素
STDataType STTop(ST* pst)
{
assert(pst);
assert(pst->top);
return pst->a[pst->top - 1];
}在这里有个小细节问题,便是我之前谈到的top初始化值的问题
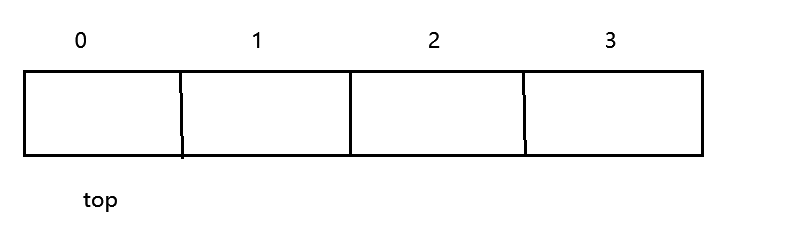
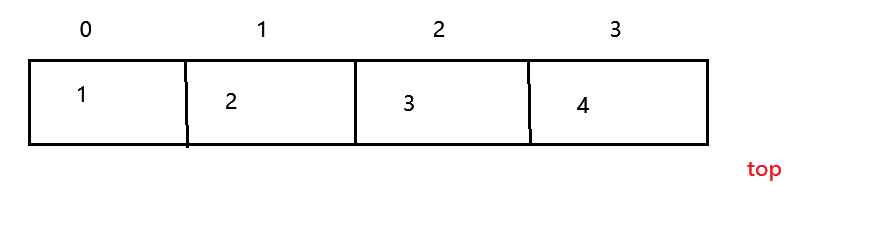
当top值初始化为1时,每次添加完数据top都要自增一次,这就导致入栈完成之后top的值处于最后一个值下标的后一位,所以在取栈顶元素时,我们的下标需要 - 1。
当然如果觉得麻烦,我们也可以在初始化赋值时,就将top的值赋值为-1,这样就可以解决掉下标问题了
3) 栈的打印
通过打印函数我们便可以更直观的观察到栈内数据的变化,无需在调试内通过监视器进行数据观察。
这时候我们的判空功能则派上了用场,STEmpty函数判断结果如果为空则返回true(即非零值,为真),所以在循环条件上我们需要用 ! 来让空为0值(循环结束情况)
c
//Stack_test.c
//栈的打印
while (!STEmpty(&st))
{
printf("%d ", st.a[st.top - 1]);
STPop(&st);
}
在这里还有一个细节问题,当打印一个值之后,需要进行出栈操作,否则无法取到下一个值,毕竟后进先出嘛。
测试一下:

五. 总结:小结与反思
通过本篇对 栈(Stack) 的手写实现,我们不仅复习了 C 语言中动态内存管理(realloc、free)的核心用法,更深入理解了顺序表实现栈的底层逻辑。
1. 为什么选择顺序表?
我们在文中讨论过,虽然链表也能实现栈,但顺序表凭借连续内存的优势,大大提高了 CPU 缓存命中率。这种"空间换效率"的思想,是每个程序猿在进阶路上必须掌握的权衡术。
2. 细节定成败
Top 的初始化:初始化为 0 还是 -1,决定了你取栈顶元素时是否需要 top - 1。
扩容陷阱:使用 tmp 中转指针,防止 realloc 失败导致原数据丢失(内存泄漏)。
逻辑删除:STPop 只是移动了 top 指针,旧数据虽在,但已"出局"。
下期预告: 栈的"双胞胎兄弟"------队列(Queue),你准备好了吗!
源码仓库:
本文实现的代码已同步上传至我的 Gitee 仓库,欢迎自取或 Star ⭐️: