前言:为什么我要学习知识图谱
主包是做威胁情报与AI应用的研究,最开始的目的不是简单做一个"威胁情报问答工具",而是想针对威胁情报里的多跳查询问题做科研验证。
威胁情报里的很多问题,并不是查一个实体、找一段文本就能回答。它经常需要沿着多层关系往下追,比如从攻击组织追到攻击工具,再追到漏洞、基础设施、攻击目标,最后还要把这些信息组织成一条可以解释的证据链。
如果只是问:
LockBit 3.0 是什么?
这种单跳问题,普通向量 RAG 基本就能处理。只要召回到相关文本块,LLM 大概率可以总结出一个还不错的答案。
但我真正关心的是这类问题:
某个攻击组织用了哪些漏洞?这些漏洞又关联了哪些恶意软件和基础设施?
这类问题的难点不在于"有没有相关文本",而在于系统能不能把多个实体之间的关系串起来。也就是说,它不是单纯的文本相似度检索问题,而是一个多跳关系查询问题。
威胁情报里的信息天然就是关系型的:
- 攻击组织使用某个工具
- 恶意软件利用某个漏洞
- 域名解析到某个 IP
- IP 作为 C2 基础设施
- 某次攻击活动针对某个行业
这些信息如果一直停留在文本块里,系统每次回答都要临时从文本里"猜关系"。这对于科研验证不够稳定,也不方便分析多跳查询到底是在哪一步失败的。所以在 ThreatRAG 里,我把知识图谱作为核心模块接进来,用它来承载实体、关系和多跳查询路径。
一、问题背景
威胁情报不是普通文本
普通知识库文档更多是"段落解释型"的,比如产品说明、FAQ、技术文档。用户的问题通常可以在某个段落里找到答案。
但 CTI 文本不太一样。它经常长这样:
APT29 近期针对欧洲政府机构发起攻击,攻击者利用 CVE-2024-2173 漏洞植入 Cobalt Strike,并通过多个域名和 IP 作为 C2 基础设施进行通信。
这句话里真正重要的不是单个词,而是这些词之间的关系。
可以拆成:
| 类型 | 实体 |
|---|---|
| 威胁行动者 | APT29 |
| 漏洞 | CVE-2024-2173 |
| 恶意软件 / 工具 | Cobalt Strike |
| 攻击目标 | 欧洲政府机构 |
| 基础设施 | 域名、IP |
| 攻击活动 | 近期攻击活动 |
关系大概是:
- APT29 -> 利用 -> CVE-2024-2173
- APT29 -> 使用 -> Cobalt Strike
- APT29 -> 攻击 -> 欧洲政府机构
- Cobalt Strike -> 通信 -> C2 基础设施
如果只是把原文存进向量库,这些关系没有真正被结构化。后面问多跳问题时,系统还是要临时从文本里猜。
我希望系统能回答的不是"这段话像不像"
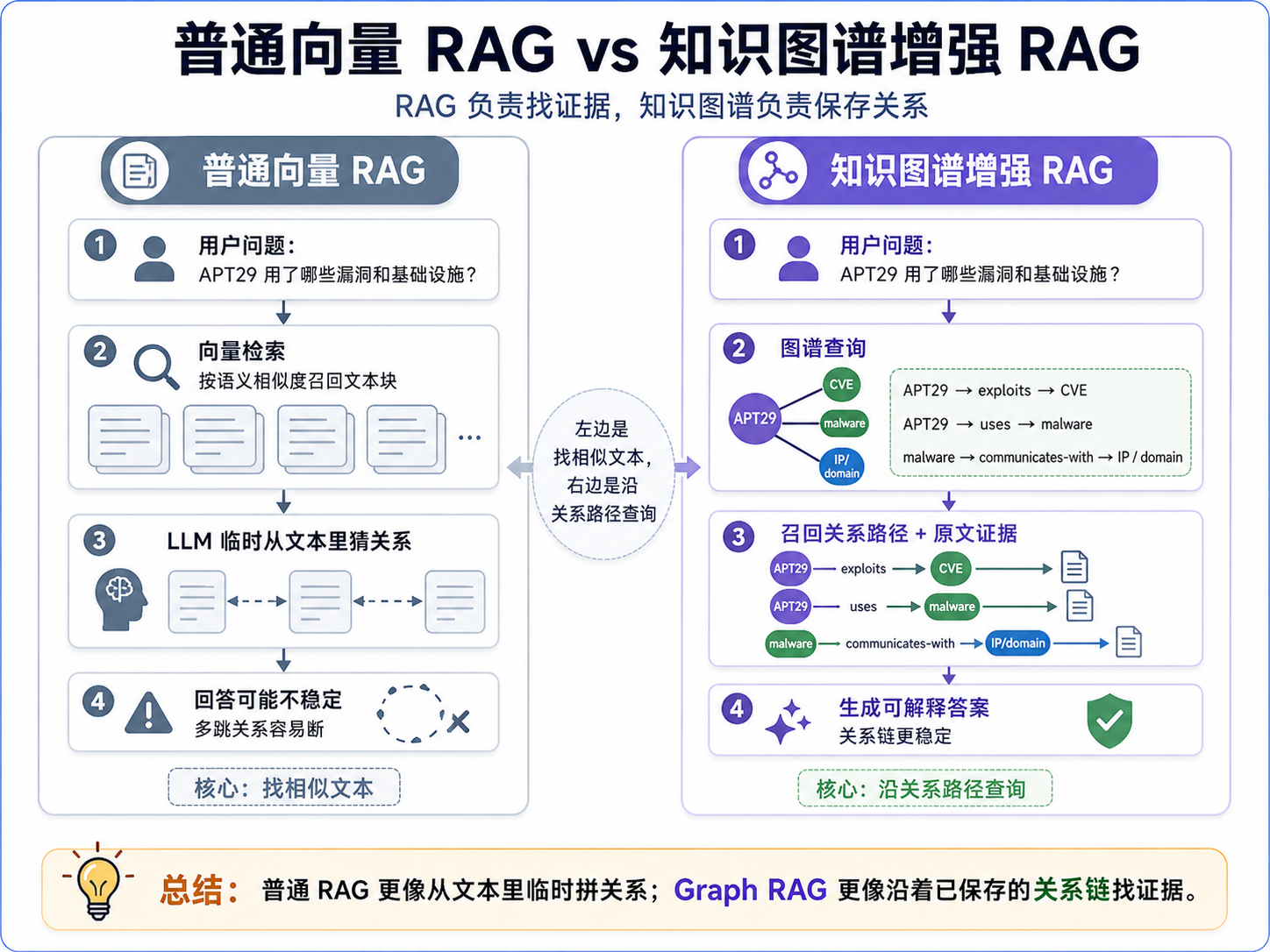
向量检索回答的是相似度问题:
哪些文本块和用户问题语义相似?
但我在 CTI 场景里更想问的是关系问题:
这个恶意软件和哪些漏洞有关?
这个 IP 被哪些攻击活动使用过?
这个攻击组织常用哪些 TTP?
某个 CVE 是否出现在多个攻击链里?
这些问题如果没有图结构,就很容易变成一堆文本片段的拼接。
我后来对这个问题的理解是:
RAG 负责找证据,知识图谱负责保存关系。
两者不是互相替代,而是互补。
二、核心概念
从文本到图谱,本质是抽三元组
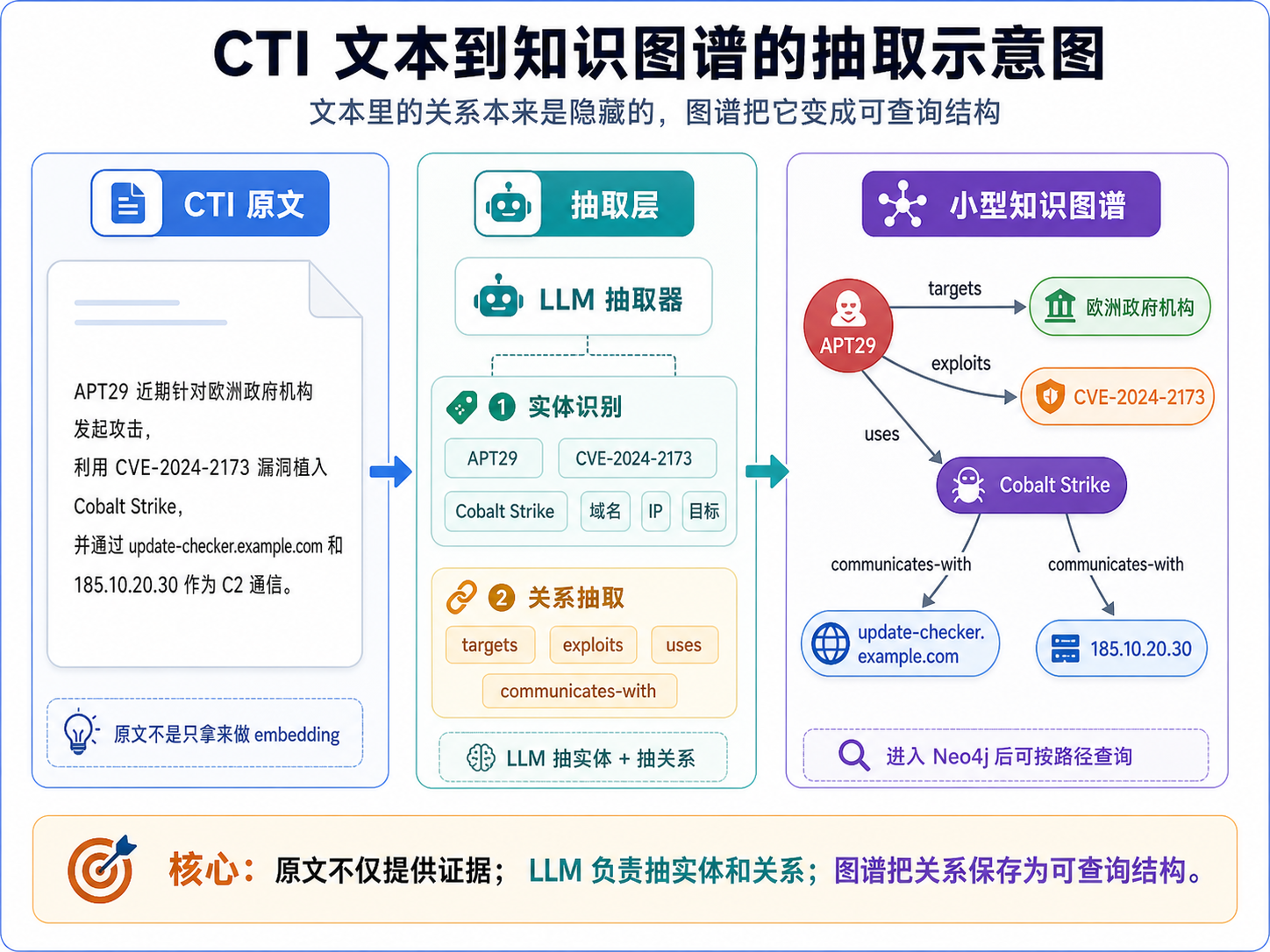
知识图谱听起来很大,但落到实现上,第一步其实就是抽三元组。
text
主体 -> 关系 -> 客体比如:
text
APT29 -> uses -> Cobalt Strike
Cobalt Strike -> exploits -> CVE-2024-2173
domain-name -> resolves-to -> ipv4-addr
malware -> communicates-with -> ipv4-addr在 ThreatRAG 里,我更倾向于先把实体统一成 STIX 风格的类型,比如:
threat-actormalwaretoolvulnerabilityindicatoripv4-addrdomain-nameattack-patterncampaign
这样做的好处是后面图谱不会太乱。否则模型今天输出"攻击者",明天输出"黑客组织",后天又输出"APT 组织",图里很快就会变成一堆同义类型。
图谱要解决的是关系可查询
整个链路可以先理解成这样:
威胁情报文本
实体识别
关系抽取
三元组
Neo4j 图数据库
图查询
RAG 回答
文本里原本隐藏的关系,被抽出来之后就可以查询了。
比如原来只能问:
text
帮我总结这篇报告有了图谱之后,可以问:
text
APT29 使用过哪些工具?
Cobalt Strike 关联了哪些攻击活动?
哪些漏洞被多个恶意软件利用过?
某个 IP 周围两跳内有哪些威胁实体?这就是知识图谱在 CTI 场景里的价值。
三、错误理解 / 常见误区
误区 1:有了向量库就不需要图谱
我一开始也有这个想法。向量库既然能召回语义相近的内容,是不是就够了?
后来发现不够。
向量库适合找"相关文本",但不擅长保存"明确关系"。尤其是多跳问题,向量检索经常只能召回几段相关描述,至于实体之间到底是什么关系,还得靠 LLM 临场判断。
这会带来两个问题:
- 同一个问题,每次召回内容不同,答案可能不同。
- 关系没有沉淀下来,下一次还要重新从文本里推。
知识图谱的价值就在这里:把已经抽出来的关系沉淀下来,后面可以复用。
误区 2:图谱越全越好
刚开始做图谱时,很容易想把所有东西都抽出来。实体越多越好,关系越多越好。
但实际不是这样。
CTI 里噪声很多,LLM 也会抽出一些很弱的关系。如果不控制类型和关系范围,图谱很快会变成一张"什么都有关"的大网。
这种图看起来很丰富,但查询时不一定有用。
我现在更认可的做法是:
先抽核心实体和核心关系,保证可用,再慢慢扩展。
第一版不需要追求全。先把攻击者、恶意软件、漏洞、IP、域名、攻击手法这些核心对象跑通,价值就已经很明显了。
误区 3:知识图谱只是为了可视化
很多人想到图谱,第一反应是 Neo4j Browser 里那种节点连线图。
可视化当然有用,但不是核心。
真正有用的是查询能力:
- 根据实体查邻居
- 根据关系类型查路径
- 根据相似实体扩展子图
- 把图谱结果作为 RAG 上下文
也就是说,图谱不是为了"看起来很酷",而是为了让关系可以被系统稳定使用。
四、正确实现思路
第一版先做最短闭环
我觉得知识图谱提取第一版不要做太复杂,先跑通这个闭环:
上传 CTI 文本
文本分块
LLM 抽实体和关系
解析成结构化对象
写入 Neo4j
按实体查询关系
这个闭环跑通之后,后面再考虑实体消歧、关系置信度、图谱补全、子图摘要这些能力。
ThreatRAG 里也是类似思路:
- API 接收上传文件
- 复用知识库的分块逻辑
- 调用 LLM 做实体关系抽取
- 把实体和关系写入 Neo4j
- 给节点补 embedding
- 查询时从图里召回相关关系
第一版实体类型不要太多
我会先保留这些类型:
| 实体类型 | 说明 |
|---|---|
threat-actor |
攻击组织、黑产团伙、APT |
malware |
恶意软件、木马、勒索病毒 |
tool |
攻击工具、渗透测试工具 |
vulnerability |
CVE、漏洞 |
attack-pattern |
TTP、攻击手法 |
ipv4-addr |
IP 地址 |
domain-name |
域名 |
campaign |
攻击活动 |
identity |
被攻击组织、行业、目标身份 |
关系也先控制在少数几类:
usesexploitstargetsindicatescommunicates-withresolves-torelated-to
第一版不要为了"标准完整"把 STIX 所有对象都塞进去。类型越多,Prompt 越复杂,模型越容易漂。
五、一个最小例子
原始文本:
text
APT29 近期针对欧洲政府机构发起攻击,攻击者利用 CVE-2024-2173 漏洞植入 Cobalt Strike。
Cobalt Strike 会连接 update-checker.example.com,并与 185.10.20.30 通信。希望抽取出的实体:
json
{
"entities": [
{"type": "threat-actor", "name": "APT29"},
{"type": "identity", "name": "欧洲政府机构"},
{"type": "vulnerability", "name": "CVE-2024-2173"},
{"type": "tool", "name": "Cobalt Strike"},
{"type": "domain-name", "name": "update-checker.example.com"},
{"type": "ipv4-addr", "name": "185.10.20.30"}
]
}希望抽取出的关系:
json
{
"relationships": [
{"source": "APT29", "relationship_type": "targets", "target": "欧洲政府机构"},
{"source": "APT29", "relationship_type": "exploits", "target": "CVE-2024-2173"},
{"source": "APT29", "relationship_type": "uses", "target": "Cobalt Strike"},
{"source": "Cobalt Strike", "relationship_type": "communicates-with", "target": "update-checker.example.com"},
{"source": "Cobalt Strike", "relationship_type": "communicates-with", "target": "185.10.20.30"}
]
}图上大概是这样:
这个例子很小,但已经能说明问题:一旦关系被结构化,后面查询就不再只是"找相似文本",而是可以沿着关系走。
六、总结 + 下篇预告
这一章主要记录我为什么加入知识图谱。
核心想法:
- CTI 文本天然是关系型信息,不只是普通段落
- 向量检索适合找相关文本,但不擅长沉淀明确关系
- 知识图谱的第一步不是可视化,而是把实体和关系变成可查询结构
- 第一版不要追求大而全,先跑通文本 -> 实体关系 -> Neo4j -> 查询的闭环
- 实体类型和关系类型要先收敛,否则后面图谱会很乱
下篇准备继续记录:知识图谱抽取中的实体类型应该怎么设计。重点会放在 STIX 类型、Schema 约束,以及怎么避免 LLM 把类型抽得越来越散。