文章目录
- [react native(学习笔记第三课) 英语打卡微应用(2)-从上传图片开始](#react native(学习笔记第三课) 英语打卡微应用(2)-从上传图片开始)
-
- [1. 构建手机的拍照功能](#1. 构建手机的拍照功能)
-
- [1.1 使用`react native`的`react native image picker`包](#1.1 使用
react native的react native image picker包) - [1.2 定义`takePhoto`的函数](#1.2 定义
takePhoto的函数)
- [1.1 使用`react native`的`react native image picker`包](#1.1 使用
- 2.构建手机的图片选择功能
-
- [2.1 使用`react native`的`react native image picker`库](#2.1 使用
react native的react native image picker库) - [2.2 定义`selectFromGallery`的函数](#2.2 定义
selectFromGallery的函数)
- [2.1 使用`react native`的`react native image picker`库](#2.1 使用
- [3. 界面运行效果](#3. 界面运行效果)
- [4. 创建后端(`python+web`)程序](#4. 创建后端(
python+web)程序) -
- [4.1 后端(`python+web`)程序的架构](#4.1 后端(
python+web)程序的架构) - [4.2 `python + FastAPI`构建](#4.2
python + FastAPI构建) - [4.3 `python + FastAPI`的程序入口](#4.3
python + FastAPI的程序入口) - [4.4 为英文文章的`ocr`创建`routes`](#4.4 为英文文章的
ocr创建routes) - [4.5 前端应用上传图片文件](#4.5 前端应用上传图片文件)
- [4.5 继续后端的`ocr service`之前,首先来导入`Customize LLM`](#4.5 继续后端的
ocr service之前,首先来导入Customize LLM) - [4.6 实现后端的`ocr service`](#4.6 实现后端的
ocr service)
- [4.1 后端(`python+web`)程序的架构](#4.1 后端(
- [5. 准备智谱`AI`的`api key`](#5. 准备智谱
AI的api key) -
- [5.1 为什么智谱`AI`的`api key`](#5.1 为什么智谱
AI的api key) - [5.2 在后端应用`backend`中设定智谱`AI`的`api key`](#5.2 在后端应用
backend中设定智谱AI的api key)
- [5.1 为什么智谱`AI`的`api key`](#5.1 为什么智谱
- [6. 启动后端(`backend`)程序](#6. 启动后端(
backend)程序) -
- [6.1 进入程序的根目录](#6.1 进入程序的根目录)
- [6.2 执行命令](#6.2 执行命令)
- [7. 启动前端程序进行识别成文字演示](#7. 启动前端程序进行识别成文字演示)
-
- [7.1 启动前端程序](#7.1 启动前端程序)
-
- [7.1.1 修改后端地址](#7.1.1 修改后端地址)
- [7.1.2 启动前端程序](#7.1.2 启动前端程序)
- [7.2 在前端程序中操作](#7.2 在前端程序中操作)
react native(学习笔记第三课) 英语打卡微应用(2)-从上传图片开始
- 构建手机的拍照功能
- 构建手机的图片选择功能
- 界面运行效果
- 创建后端(
python+web)程序 - 准备智谱
AI的api key - 启动后端(
backend)程序 - 使用
zhipu AI识别成文字演示
1. 构建手机的拍照功能
这里,使用react native,让手机应用具备照片拍照功能。
项目代码
使用AI,可以很快构筑想要的功能。
1.1 使用react native的react native image picker包
typescript
import {
launchCamera,
launchImageLibrary,
ImagePickerResponse,
Asset,
} from 'react-native-image-picker';引入了这个react native的包,并且导入了launchCamera,就可以进行拍照的功能开发了。
1.2 定义takePhoto的函数
typescript
// 拍照
const takePhoto = async () => {
launchCamera(
{
mediaType: 'photo',
quality: 0.8,
saveToPhotos: true,
},
(response: ImagePickerResponse) => {
if (response.didCancel) {
console.log('用户取消了拍照');
} else if (response.errorCode) {
Alert.alert('错误', `拍照失败: ${response.errorMessage}`);
} else if (response.assets && response.assets.length > 0) {
setPhoto(response.assets[0]);
setExtractedText(''); // 清空之前的文本
}
},
);
};2.构建手机的图片选择功能
除了英语文章手机的拍照,可能有对相册里面的英语文章图片进行上传的需要,同样这里,提供相册选择图片的机能。
2.1 使用react native的react native image picker库
typescript
import {
launchCamera,
launchImageLibrary,
ImagePickerResponse,
Asset,
} from 'react-native-image-picker';引入了这个react native的包,并且导入了launchImageLibrary,就可以进行相册的图片选择功能开发了。
2.2 定义selectFromGallery的函数
typescript
// 从相册选择
const selectFromGallery = () => {
launchImageLibrary(
{
mediaType: 'photo',
quality: 0.8,
},
(response: ImagePickerResponse) => {
if (response.didCancel) {
console.log('用户取消了选择');
} else if (response.errorCode) {
Alert.alert('错误', `选择图片失败: ${response.errorMessage}`);
} else if (response.assets && response.assets.length > 0) {
setPhoto(response.assets[0]);
setExtractedText(''); // 清空之前的文本
}
},
);
};3. 界面运行效果
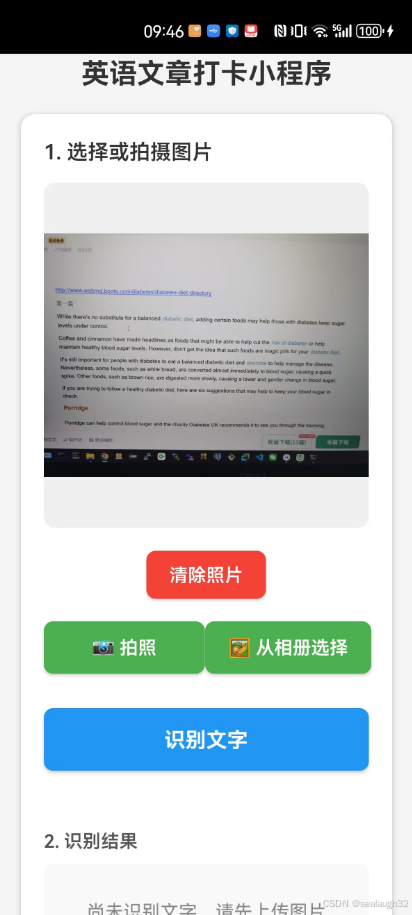
这里有两个区域:
- 第一个区域是图片选择或者拍照区域
- 第二个区域是将图片从手机上上传到后端
backend。在后端
4. 创建后端(python+web)程序
为什么要创建后端程序呢,因为需要将上传的图片上传给AI进行解析,之后会将解析之后的文字上传到数据库,以上传时间和主题进行database上的保存。所以开发前端frontend的同时,在开发一个backend的程序。
后端程序代码
4.1 后端(python+web)程序的架构
- 采用
python + FastAPI作为web的开发引擎。 - 采用
Zhupu AI进行图片的识别。->智谱AI的官网 - 采用
python + langchain进行AI的调用。
4.2 python + FastAPI构建
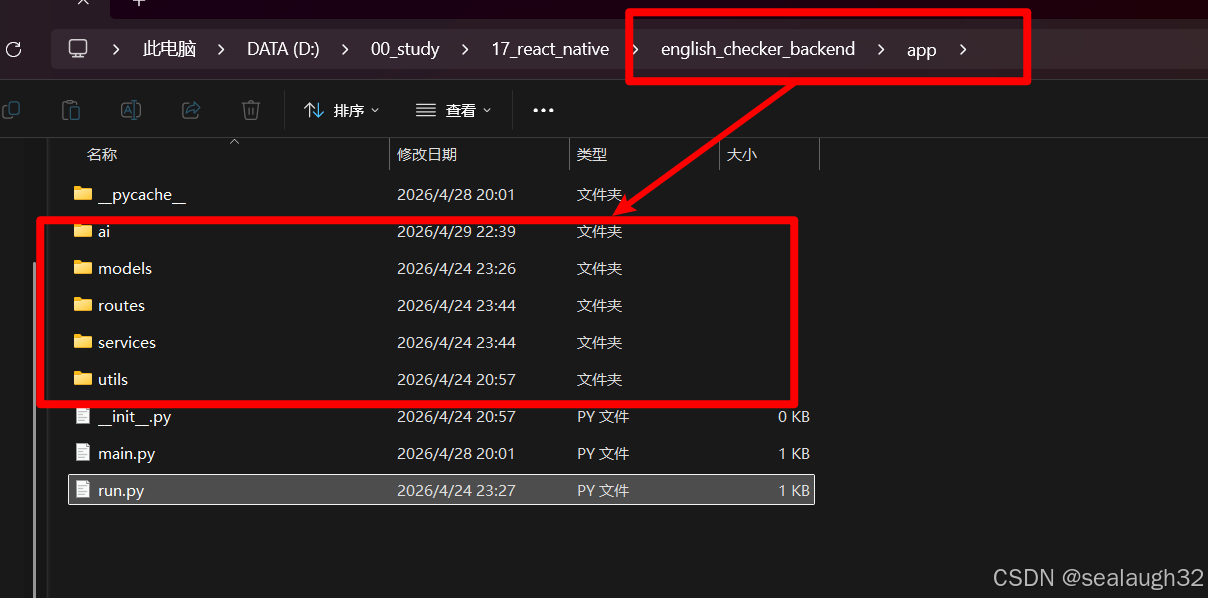
这里是整体的python + FastAPI文件夹结构,下面详细介绍每个部分。
4.3 python + FastAPI的程序入口
python
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from app.routes import ocr # 稍后创建
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 创建FastAPI应用实例
app = FastAPI(
title="Book OCR API",
description="将英文书图片转换为文字的API服务",
version="1.0.0"
)
# 配置CORS(允许React Native App访问)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 生产环境应该指定具体域名
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 注册路由
app.include_router(ocr.router, prefix="/api/v1", tags=["english_checker"])
@app.get("/")
async def root():
return {
"message": "API is running",
"docs_url": "/docs",
"version": "1.0.0"
}
@app.get("/health")
async def health_check():
return {"status": "healthy"}4.4 为英文文章的ocr创建routes
python
from fastapi import APIRouter, UploadFile, File, HTTPException
from app.services.ocr_service import OCRService
import os
import logging
import base64
router = APIRouter()
ocr_service = OCRService()
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__) # 创建 logger 实例
@router.post("/ocr/extract-text")
async def extract_text_from_image(
file: UploadFile = File(..., description="上传英文书的图片")
):
"""
从上传的图片中提取文字
"""
# 验证文件类型
if not file.content_type.startswith('image/'):
raise HTTPException(
status_code=400,
detail="文件类型必须是图片"
)
# 验证文件大小(例如限制10MB)
file_size = 0
content = await file.read()
file_size = len(content)
# 转换为 Base64 字符串
base64_string = base64.b64encode(content).decode('utf-8')
decoded_start = base64.b64decode(base64_string[:12]) # 解码前 12 个 Base64 字符
print(f"文件头(十六进制): {decoded_start.hex()}")
# 根据十六进制判断文件类型
if decoded_start.startswith(b'\x89PNG\r\n\x1a\n'):
data_url = f"data:image/png;base64,{base64_string}"
elif decoded_start.startswith(b'\xff\xd8\xff'):
data_url = f"data:image/jpeg;base64,{base64_string}"
if file_size > 10 * 1024 * 1024: # 10MB
raise HTTPException(
status_code=400,
detail="文件大小不能超过10MB"
)
try:
# 调用AI进行OCR解析
extracted_text = await ocr_service.extract_text(data_url)
return {
"success": True,
"filename": file.filename,
"extracted_text": extracted_text,
"word_count": len(extracted_text.split()),
"character_count": len(extracted_text)
}
except Exception as e:
raise HTTPException(
status_code=500,
detail=f"文字提取失败: {str(e)}"
)这里,后端程序接收到了image文件,之后就进行base64的转换,最后加上先头的data:image/jpeg;base64,,转成LLM大模型需要的数据格式。
之后,进行ocr_service.extract_text(data_url)的调用,从routes层调用到service层。
4.5 前端应用上传图片文件
在进行service层的解析之前,先看看前端的代码是如何进行进行image文件上传的。
typescript
try {
// 创建 FormData
const formData = new FormData();
// 添加图片文件
formData.append('file', {
uri: photo.uri,
type: photo.type || 'image/jpeg',
name: photo.fileName || 'photo.jpg',
});
// 添加描述(如果有)
if (description) {
formData.append('description', description);
}
// 替换为你的后端API地址
const response = await fetch('http://192.168.1.107:8000/api/v1/ocr/extract-text', {
method: 'POST',
body: formData,
});
const result = await response.json();
if (response.ok) {
// 从后端响应中提取 extracted_text后端通过async def extract_text_from_image(file: UploadFile = File(..., description="上传英文书的图片"))进行前端上传文件的解析。
4.5 继续后端的ocr service之前,首先来导入Customize LLM
这里,需要导入智谱AI,这里使用前面的Customize LLM的文章来开发。
AI(学习笔记第十一课) 使用langchain的multimodality
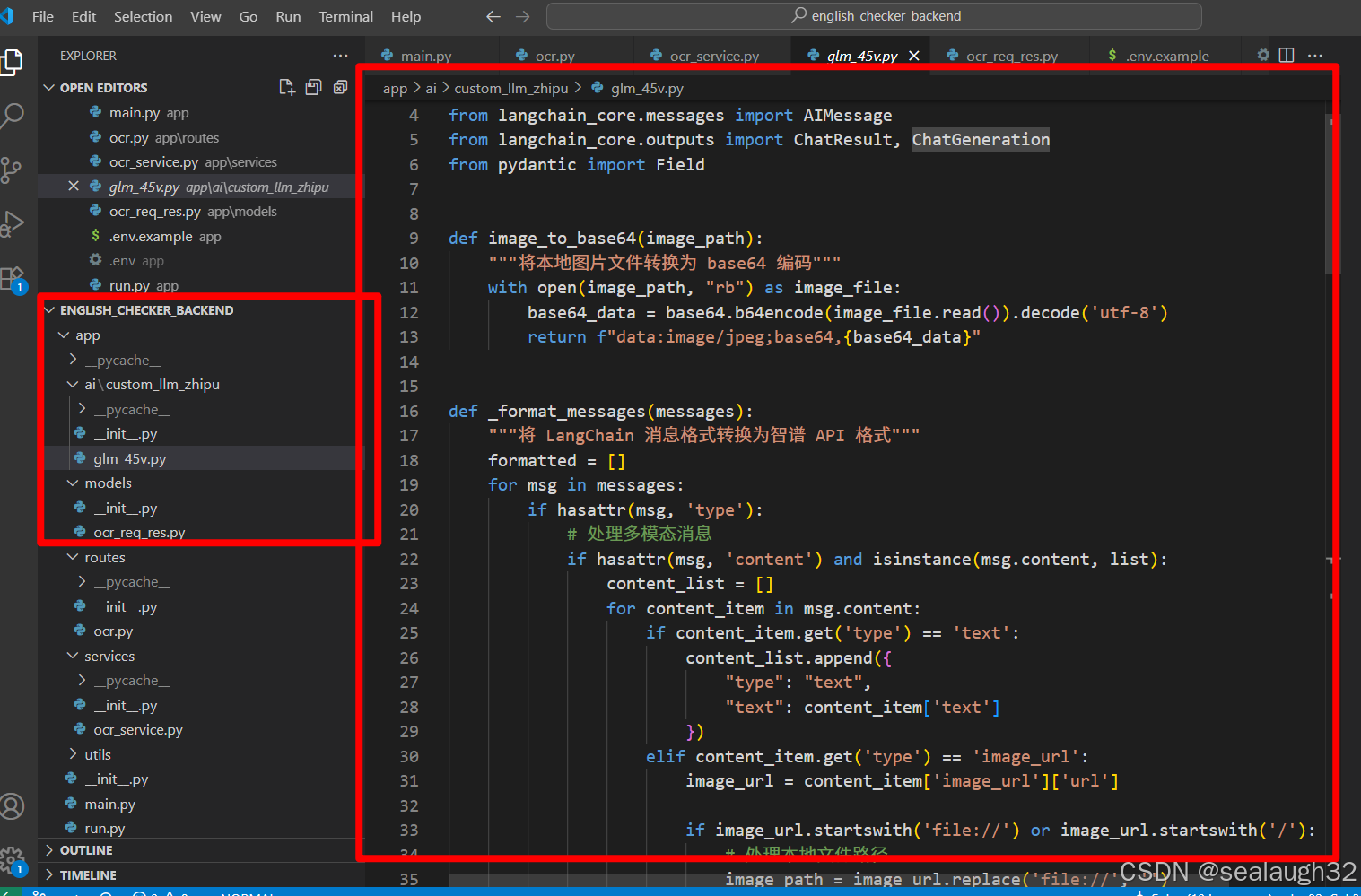
在工程的文件夹app的下面,创建了ai的子文件夹,作为LLM的目录。
这里,可以看出,作为图片解析的LLM,接受三种image输入格式:
- 本地处理路径(
file://d:/test.jpeg) base64的数据流(image bytes)这次使用的就是这种方式- 网络的
url来表示的网络图片
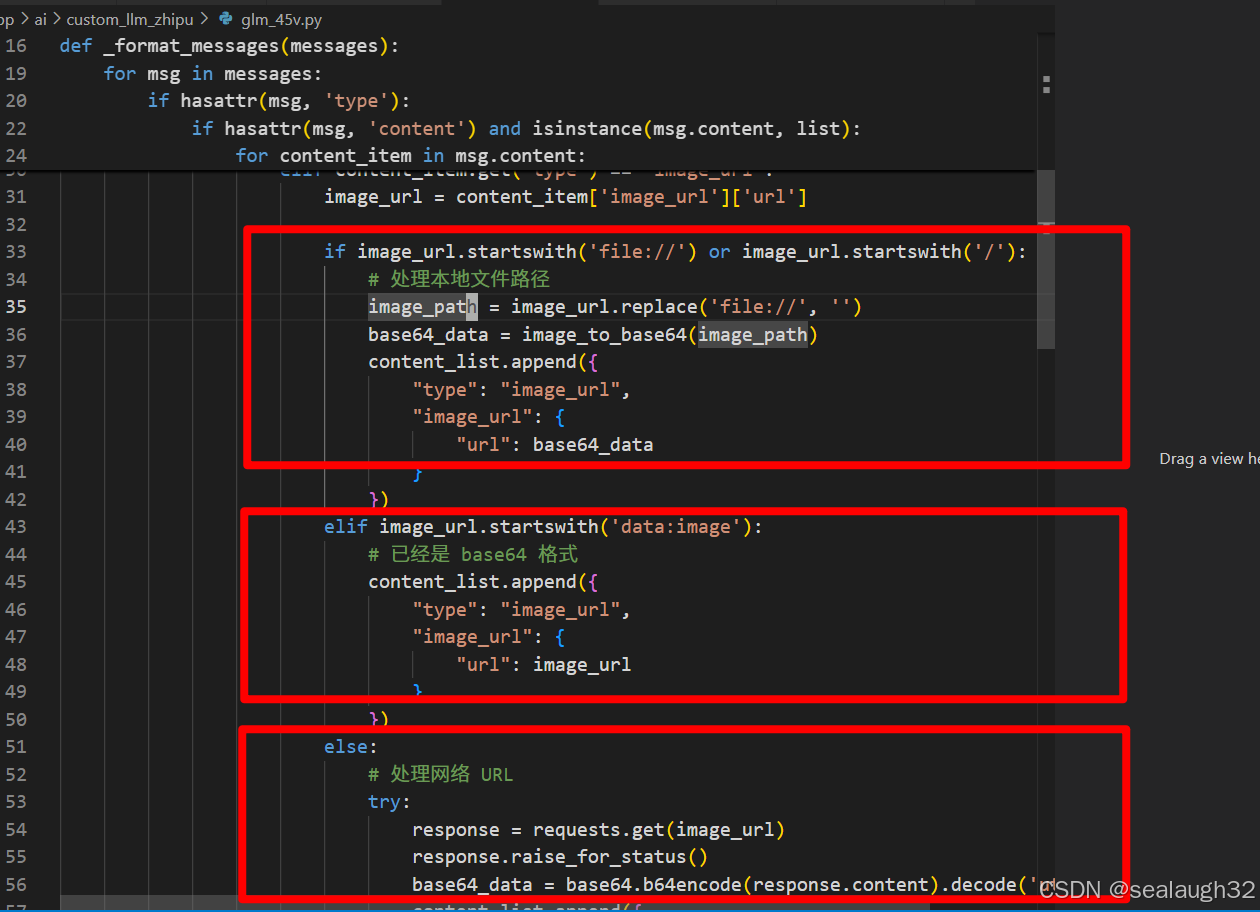
这里,主要是采用langchain的自定义customize大模型LLM,继承BaseChatModel这个父类,写出自己的_generate方法,来在应用程序和商业的LLM之前搭一个桥梁,让其他应用程序都能够自如的调用LLM,并能够增加一些customize处理。
4.6 实现后端的ocr service
从上面可以看到,/routes/ocr.py里面,已经在对接受的文件进行了base64的转换,并根据文件的形式不同加上data:image/png;base64或者data:image/jpeg;base64之后,直接就交给了/services/ocr_service.py这里处理。
python
# 转换为 Base64 字符串
base64_string = base64.b64encode(content).decode('utf-8')
decoded_start = base64.b64decode(base64_string[:12]) # 解码前 12 个 Base64 字符
print(f"文件头(十六进制): {decoded_start.hex()}")
# 根据十六进制判断文件类型
if decoded_start.startswith(b'\x89PNG\r\n\x1a\n'):
data_url = f"data:image/png;base64,{base64_string}"
elif decoded_start.startswith(b'\xff\xd8\xff'):
data_url = f"data:image/jpeg;base64,{base64_string}"
if file_size > 10 * 1024 * 1024: # 10MB
raise HTTPException(
status_code=400,
detail="文件大小不能超过10MB"
)
try:
# 调用AI进行OCR解析
extracted_text = await ocr_service.extract_text(data_url)接下来,实现ocr_service.py的这个类。很容易想到,这里的ocr_service.py主要是调用刚才的Customize LLM类GLM45V,将前端传递过来的image的base64数据传递给LLM。
pyhon
import io
from PIL import Image
import asyncio
from functools import partial
import logging
import numpy as np
import os
from langchain_core.messages import HumanMessage
from app.ai.custom_llm_zhipu import GLM45V
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__) # 创建 logger 实例
def create_image_analyzer(api_key):
llm = GLM45V(api_key=api_key)
def analyze_image(image_path, prompt_text="请将这张图片英文抽取出来"):
"""分析图片内容"""
message = HumanMessage(content=[
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": image_path
}
}
])
result = llm.generate([[message]])
return result.generations[0][0].text
return analyze_image
class OCRService:
async def extract_text(self, base64_url) -> str:
try:
# 在线程池中运行CPU密集型的OCR任务
# 这样可以避免阻塞FastAPI的异步事件循环
loop = asyncio.get_event_loop()
api_key = os.getenv("ZHIPU_AI_API_KEY")
logger.info(f"api key is :{api_key}")
analyzer = create_image_analyzer(api_key)
result = analyzer(base64_url)
print("详细分析:", result)
return result
except Exception as e:
logger.error(f"文字提取失败: {str(e)}", exc_info=True) # exc_info=True 会记录完整的堆栈跟踪
raise Exception(f"OCR处理失败: {str(e)}")5. 准备智谱AI的api key
5.1 为什么智谱AI的api key
由于使用智谱AI进行一下的两个功能:
- 对于英语的文章拍照上传,之后进行
OCR文字抽取 - 对于抽取到的文字进行转语音的操作,使用智谱
AI的语音模型
所以需要开设一个智谱AI的API key。
5.2 在后端应用backend中设定智谱AI的api key
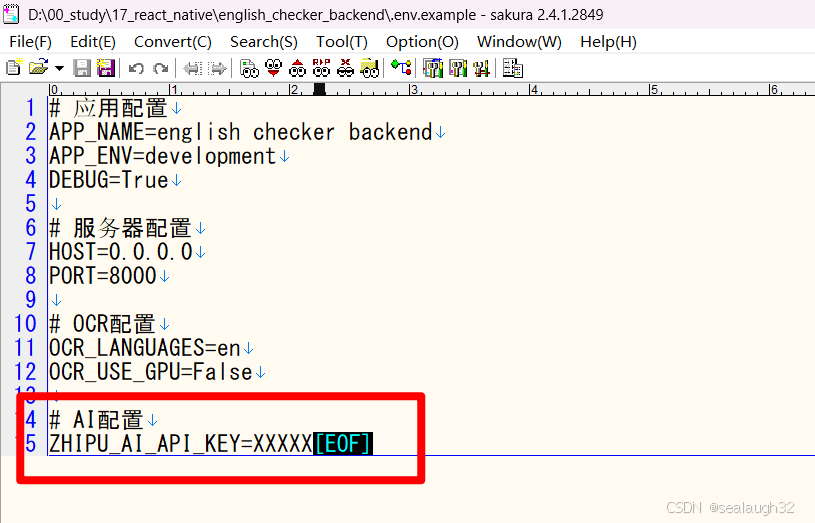
这里,.env.example文件已经给出了设定的key,在.env中设定了这个文件就可以了。
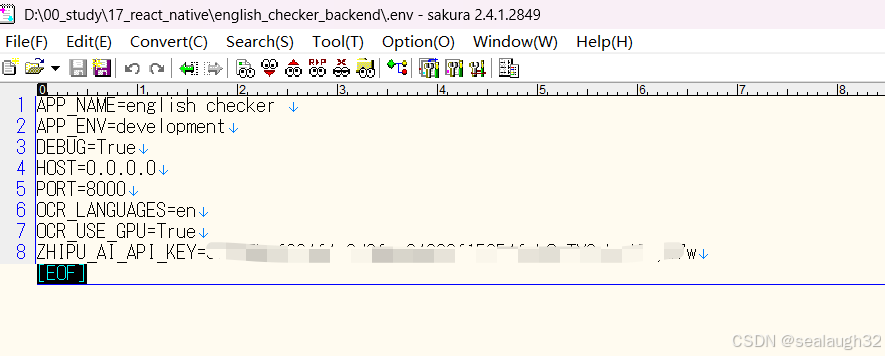
这里尝试了一下,解析一个图片,花费不到0.1元,感觉作为开发测试还是可以的。
6. 启动后端(backend)程序
6.1 进入程序的根目录
shell
cd D:\00_study\17_react_native\english_checker_backend6.2 执行命令
代码库已经将启动的命令写入了start_commands.txt文件中,可以按照这个执行
shell
# 安装python的evnv环境
python -m mvenv venv
# 激活python的venv
venv\Scripts\activate
# pip安装
pip install -r requirements.txt
# 启动backend 工程
python -m uvicorn app.main:app --reload --host=0.0.0.0 --log-level debug- 注意1:这里
--host=0.0.0.0一定要执行,否则,只有本机的localhost或者127.0.0.1好用,手机应用上到backend的访问不要用。* - 注意2:这里,一定要用家里的宽带,使手机应用和
backend应用在一个局域网里面。当然,等到开发完毕的时候正式环境,应该使用公共的域名服务DNS。
7. 启动前端程序进行识别成文字演示
7.1 启动前端程序
7.1.1 修改后端地址
这里由于是开发途中,所以暂时还是hardcoding的,最后应该问问AI,对于前端工程,后端工程的url如何进行定义(hardcoding解决方案)。
这里已经修改成了后端的地址。
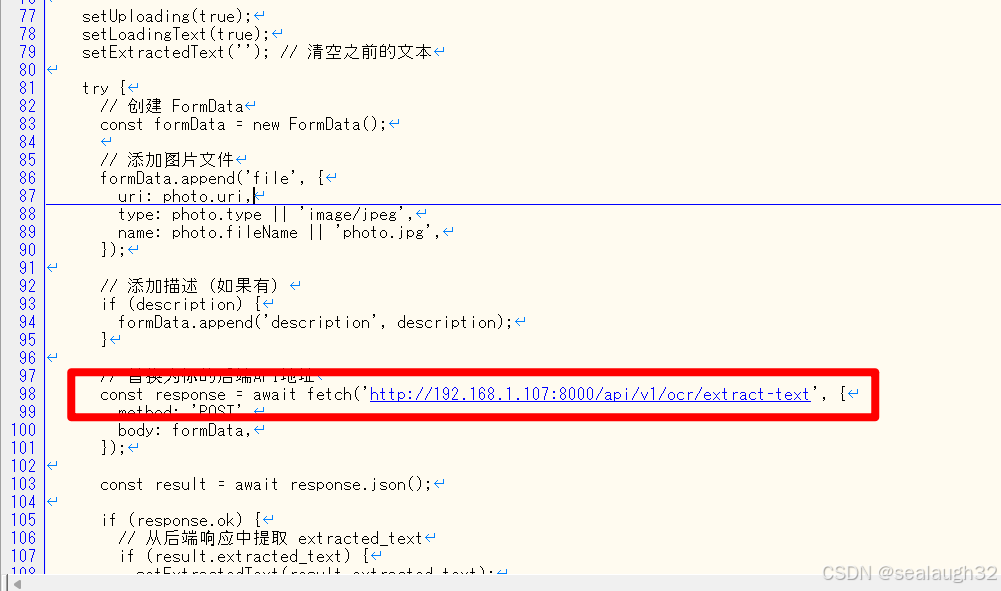
但是,如果使用手机开热点,之后PC进行连接,那么这种模式下,手机不能连接上PC。必须要使用同一局域网下才可以。
7.1.2 启动前端程序
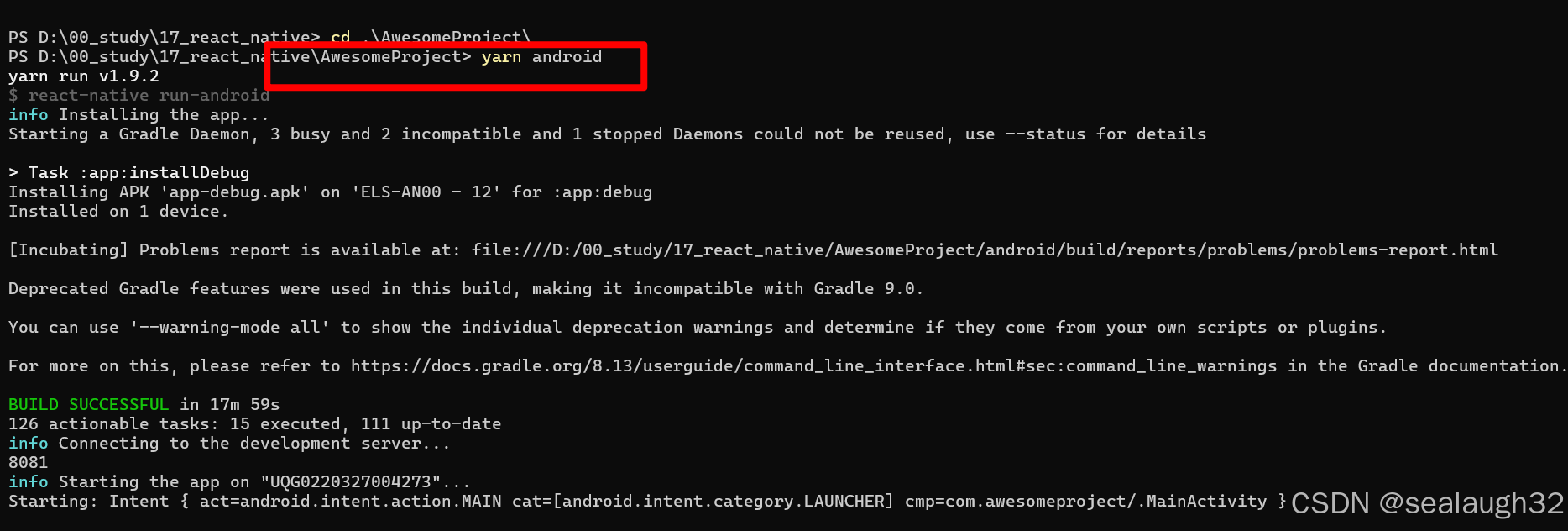
启动之后,就可以看到手机的画面,非常简单的一个画面。
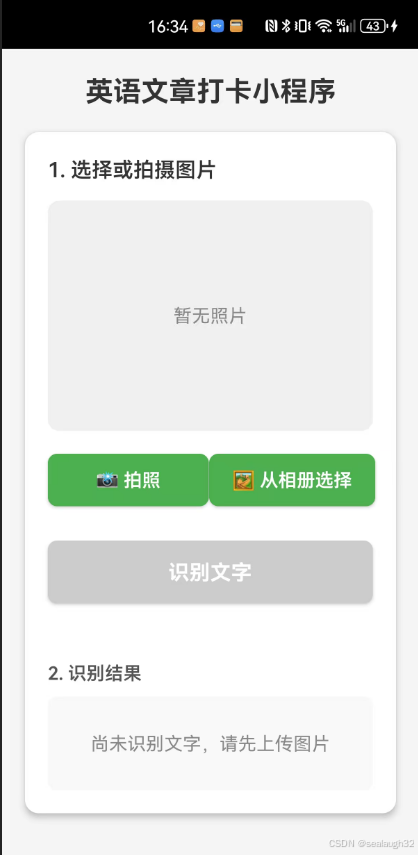
7.2 在前端程序中操作
进行拍照-> 上传,等待后端对图片image进行一会的解析之后,就会在识别结果的框内出现了识别好的英文的文字。之后,继续对文字进行转成标准英文语音的功能开发。