✍✍计算机毕设指导师**
⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡有什么问题可以在主页上或文末下联系咨询博客~~
⚡⚡Java、Python、小程序、大数据实战项目集](https://blog.csdn.net/2301_80395604/category_12487856.html)
⚡⚡文末获取源码
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
卵巢癌风险数据可视化分析系统-简介
本系统"基于Spark的卵巢癌风险数据可视化分析系统"的核心在于利用大数据技术处理海量的多维度医学数据。系统底层采用Hadoop的HDFS进行分布式存储,确保大规模数据集的可靠存放。计算引擎则选用Apache Spark,通过其高效的内存计算能力和Spark SQL模块,对包含人口统计学、临床医学、遗传背景及医学影像学特征的数据集进行快速聚合、关联与统计分析。后端服务采用Python语言和Django框架,负责接收前端请求、调用Spark作业执行分析任务,并将处理后的结构化结果通过API接口返回。前端界面基于Vue、ElementUI和Echarts构建,能够动态地将后端传来的数据渲染为直观的交互式图表,如风险矩阵热力图、多维度散点图和分布直方图,从而帮助用户从不同维度探索卵巢癌风险因素之间的复杂关系,整个流程实现了从海量数据到深度洞察的闭环。
卵巢癌风险数据可视化分析系统-技术
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
数据库:MySQL
卵巢癌风险数据可视化分析系统-背景
选题背景
卵巢癌作为一种严重威胁女性健康的恶性肿瘤,其早期诊断与风险评估对于提升患者生存率至关重要。随着现代医疗信息化的不断推进,医院和科研机构积累了海量的患者数据,这些数据不仅包含了常规的年龄、体重指数等基本信息,还涉及复杂的临床指标、基因检测结果和影像学特征。面对如此规模庞大且类型多样的数据,传统的数据处理方法和简单的统计分析工具显得力不从心,难以有效挖掘其中隐藏的深层次关联。因此,如何利用先进的大数据技术,对这些多源异构的医疗数据进行有效整合与深度分析,构建一个能够直观展示风险因素的可视化平台,成为了一个具有现实挑战和应用价值的研究方向。
选题意义
本课题的实际意义体现在几个层面。对于医学研究而言,系统提供了一个直观的数据探索工具,研究人员可以借助可视化交互界面,快速验证关于风险因素的假设,例如观察特定基因突变与癌症分期的关联,为后续的深入研究提供方向。对于临床应用,虽然本系统仅为毕业设计原型,但其探索的分析模式,未来有望辅助医生更全面地评估患者状况,为制定个性化的预防和筛查策略提供数据参考。从技术实践角度看,本项目完整地应用了Hadoop、Spark等主流大数据技术栈来处理真实的医学领域问题,为计算机专业的学生提供了一个将理论知识与行业需求相结合的实践案例,探索了大数据技术在智慧医疗领域的应用可能性。
卵巢癌风险数据可视化分析系统-视频展示
基于Spark的卵巢癌风险数据可视化分析系统 毕业设计
卵巢癌风险数据可视化分析系统-图片展示

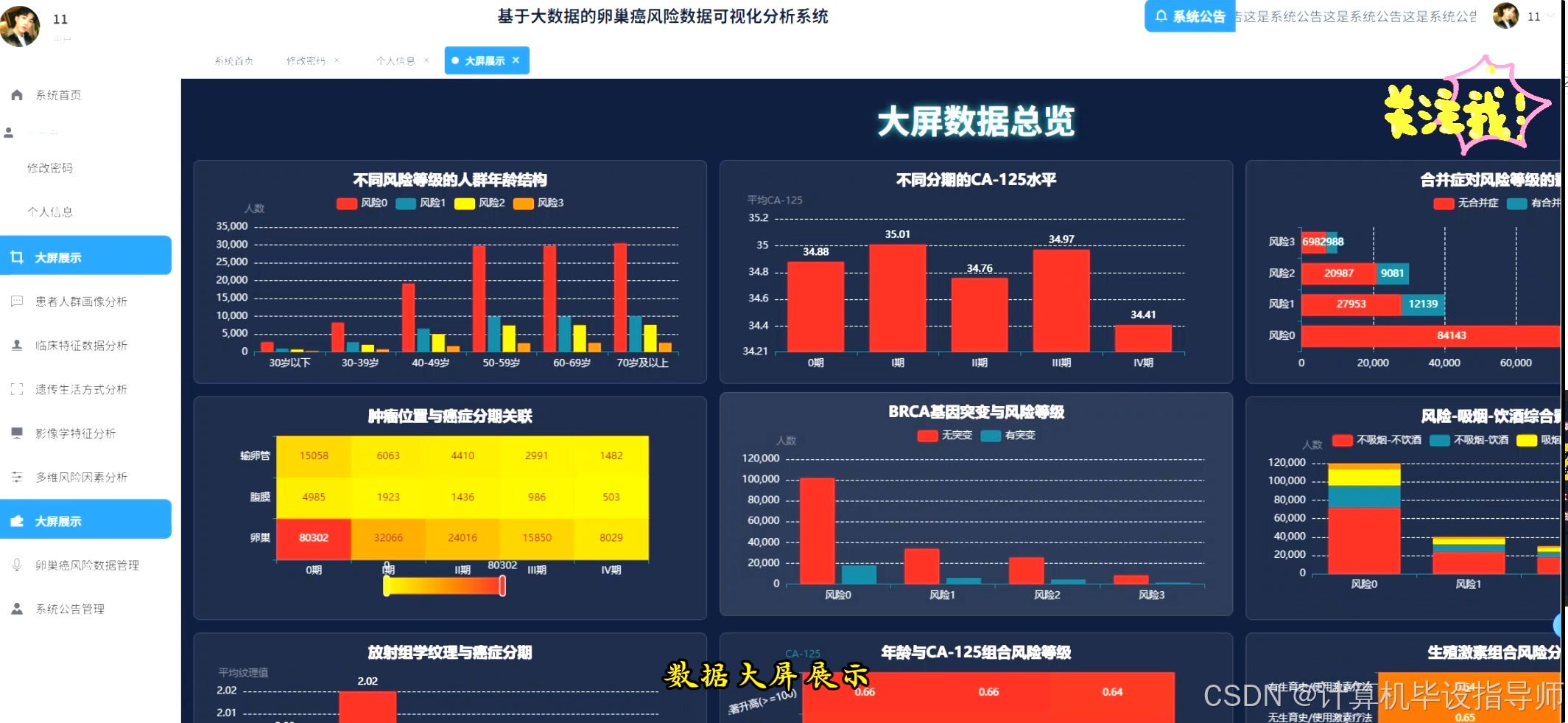
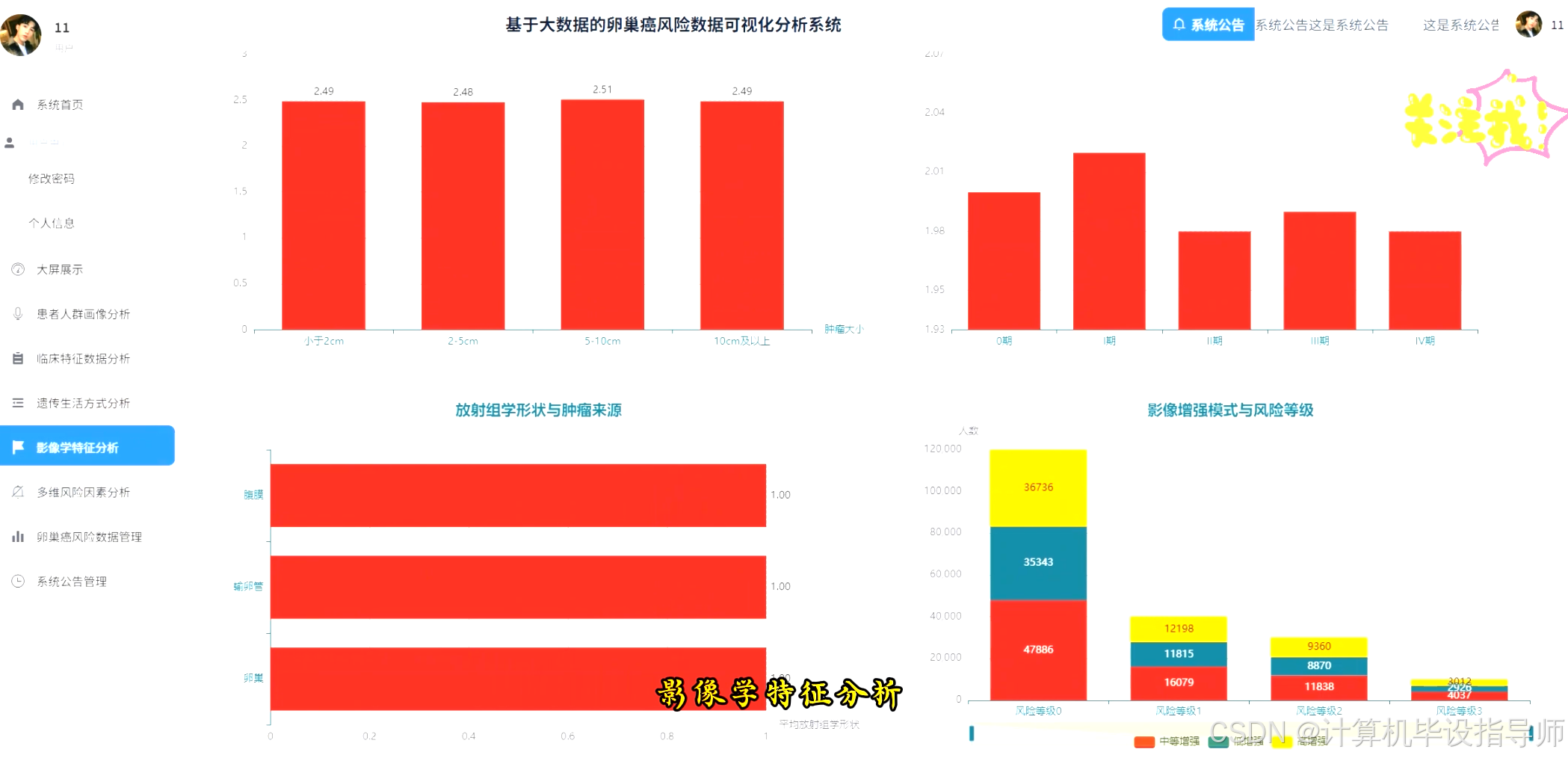
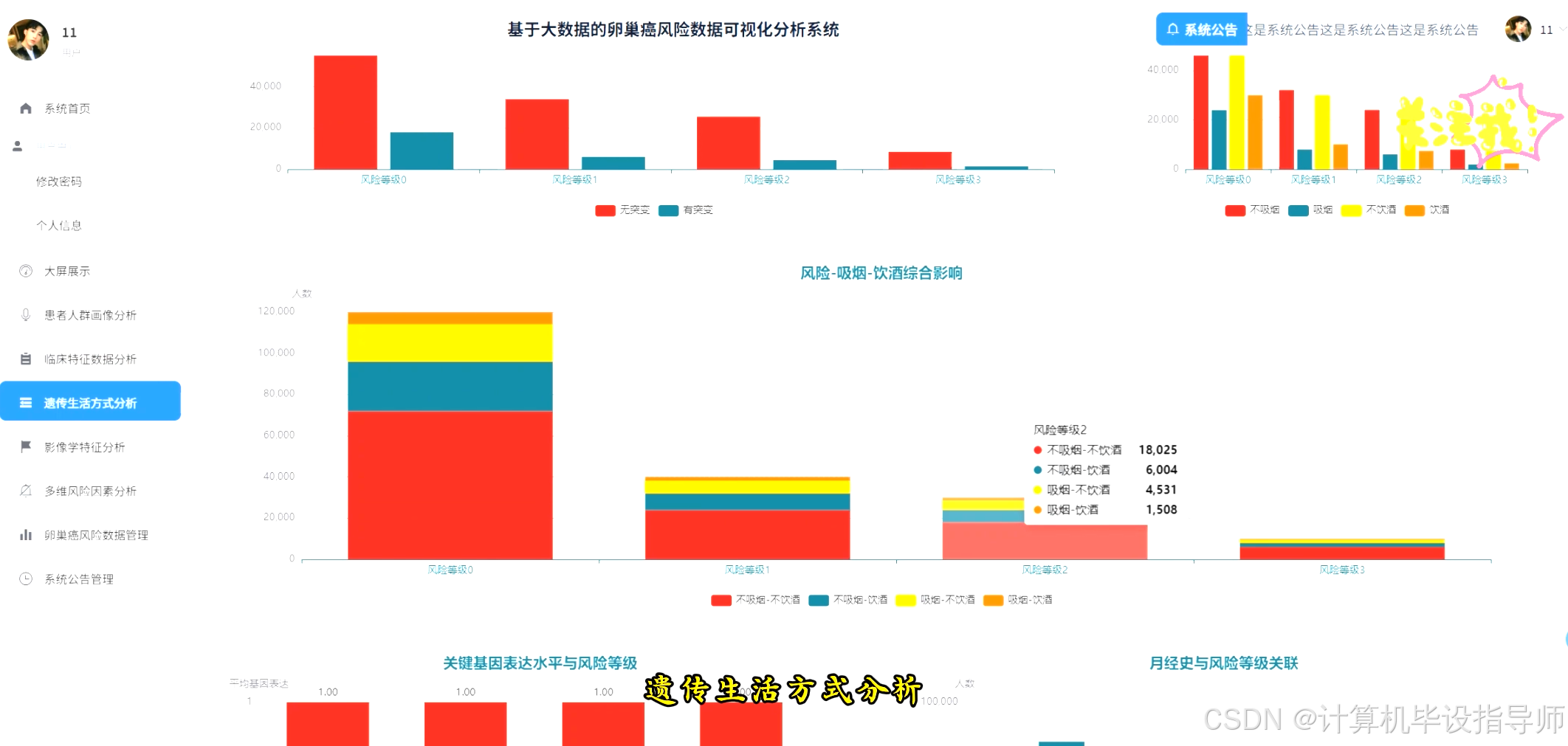

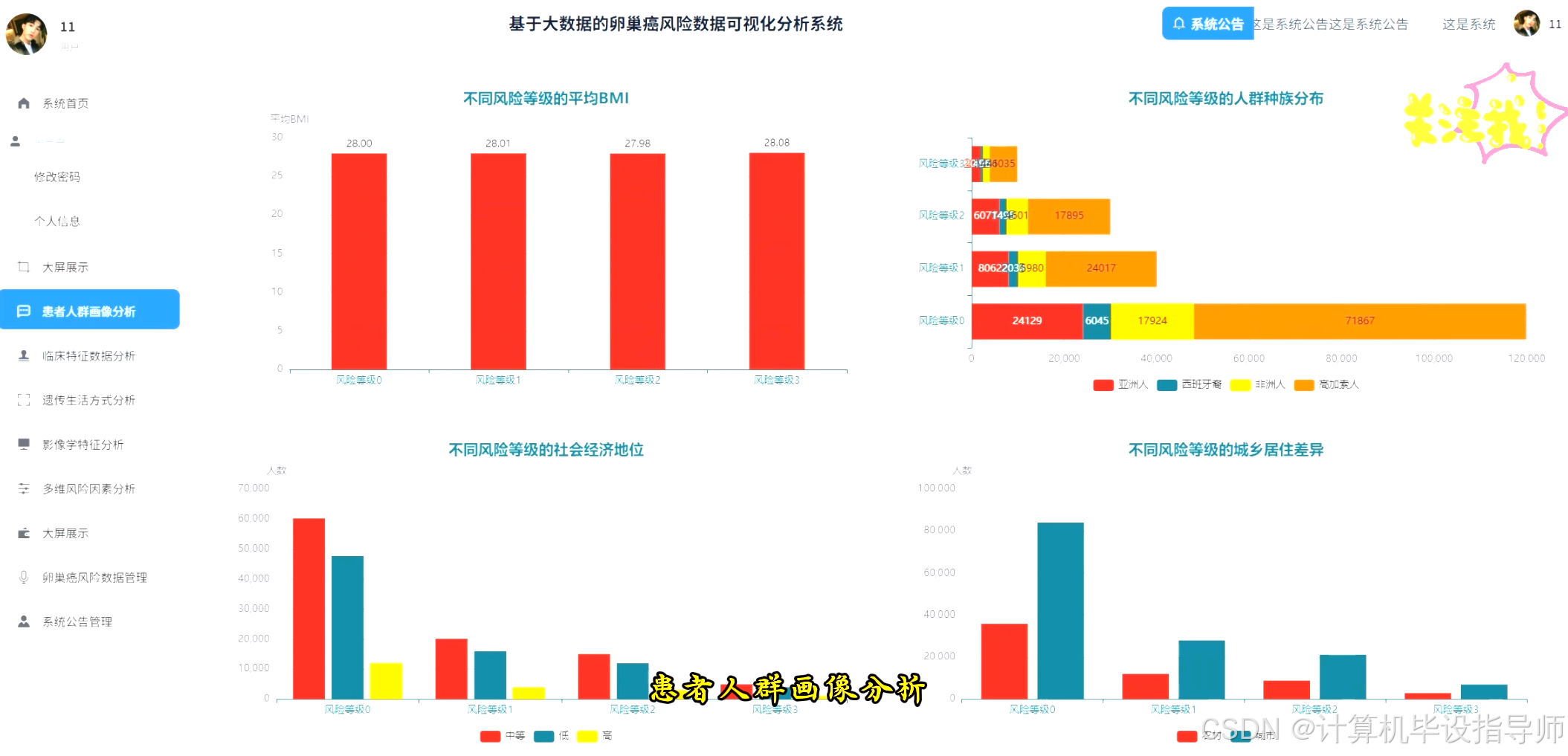


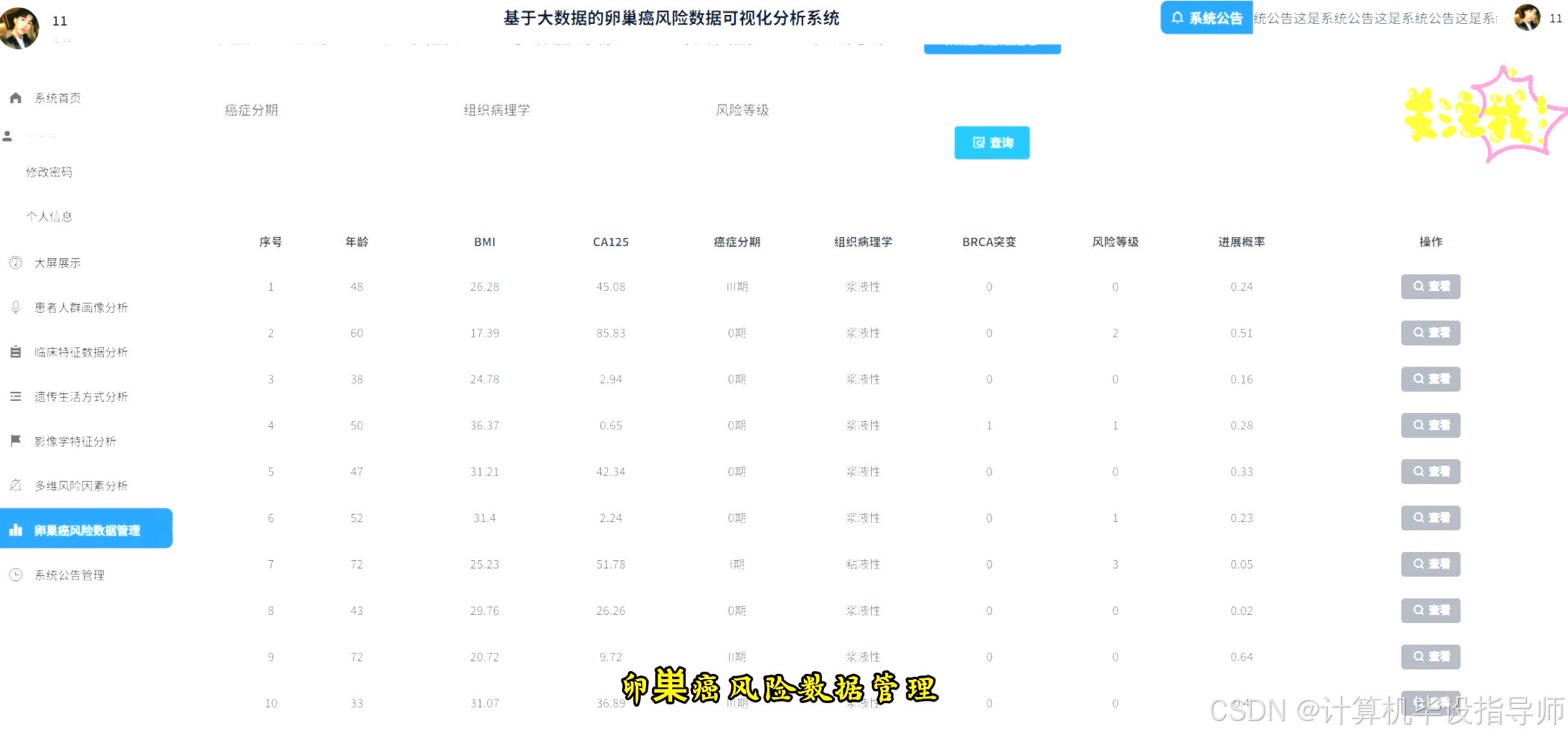
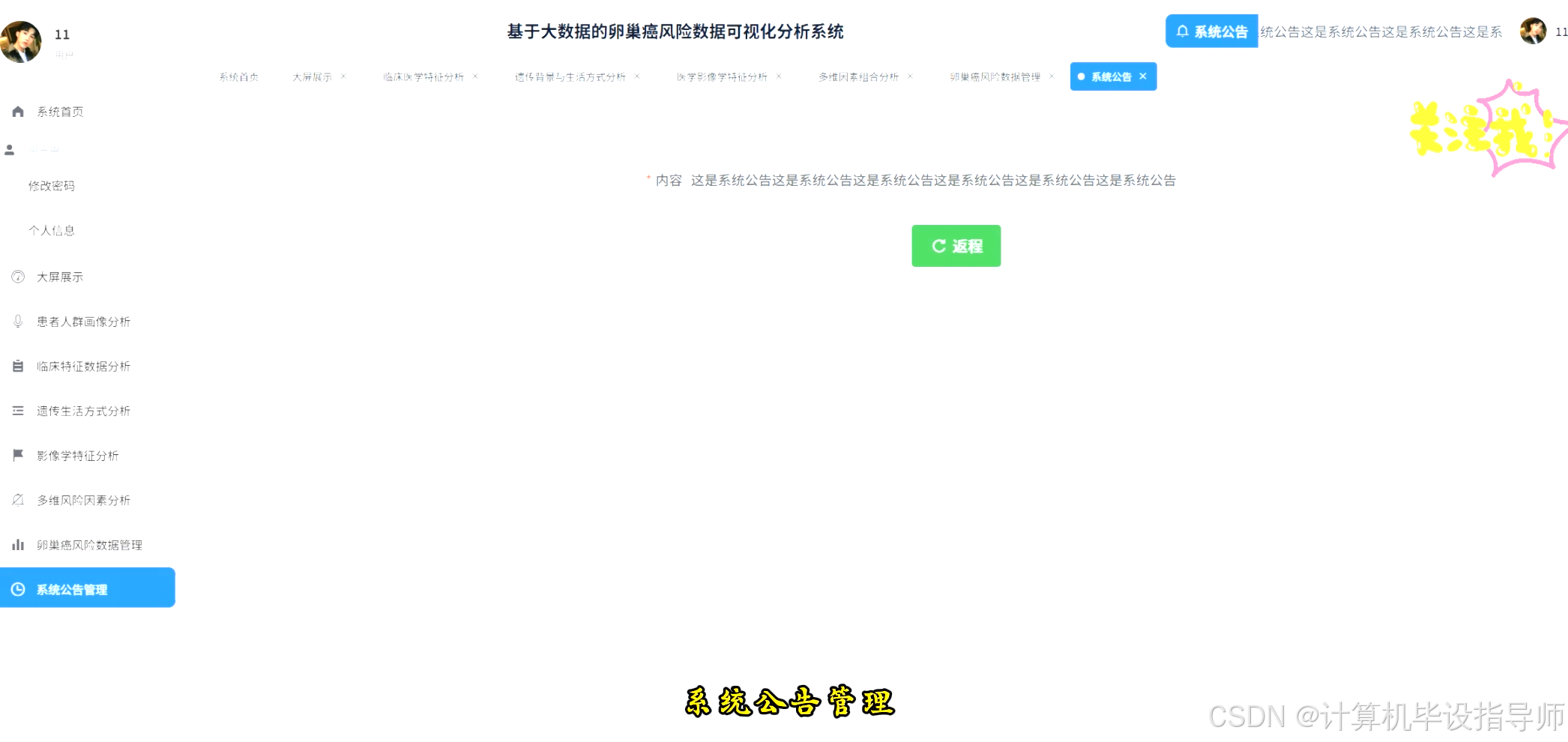
卵巢癌风险数据可视化分析系统-代码展示
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, count, when, floor
import pandas as pd
spark = SparkSession.builder.appName("OvarianCancerAnalysis").getOrCreate()
# 假设df是一个已经加载好的Spark DataFrame,包含所有字段
# df = spark.read.csv("hdfs://path/to/data", header=True, inferSchema=True)
# 核心功能1: 不同风险等级的人群年龄结构分析
def analyze_age_by_risk(df):
age_stats_by_risk = df.groupBy("RiskLabel").agg(
avg("Age").alias("平均年龄"),
count("Age").alias("人数统计")
).orderBy(col("平均年龄"))
return age_stats_by_risk
# 核心功能2: 不同癌症分期的CA-125标志物水平分析
def analyze_ca125_by_stage(df):
ca125_stats_by_stage = df.groupBy("CancerStage").agg(
avg("CA125").alias("CA125平均水平"),
count("CA125").alias("病例数")
).orderBy(col("CancerStage"))
return ca125_stats_by_stage
# 核心功能3: 年龄与CA-125水平组合下的风险矩阵分析
def create_age_ca125_risk_matrix(df):
# 将年龄和CA125水平分箱
df_binned = df.withColumn("AgeGroup",
when(col("Age") < 40, "40岁以下")
.when((col("Age") >= 40) & (col("Age") < 60), "40-59岁")
.otherwise("60岁及以上")
).withColumn("CA125Group",
when(col("CA125") < 35, "正常范围")
.when((col("CA125") >= 35) & (col("CA125") < 200), "轻度升高")
.otherwise("显著升高")
)
# 计算每个组合中的高风险人数
risk_matrix = df_binned.filter(col("RiskLabel") == "High")\
.groupBy("AgeGroup", "CA125Group")\
.agg(count("RiskLabel").alias("高风险人数"))\
.orderBy("AgeGroup", "CA125Group")
return risk_matrix卵巢癌风险数据可视化分析系统-结语
综上所述,本系统成功实现了基于Spark的卵巢癌风险数据可视化分析,完成了从数据存储、处理到前端展示的完整流程。系统能够直观地呈现多维度数据间的关联,为医学数据分析提供了有效的工具支持。当然,系统仍有可提升的空间,例如未来可引入机器学习模型进行风险预测,或接入实时数据流,以进一步增强其应用价值。
正在做大数据毕设的同学看过来!如果你对医疗数据分析感兴趣,或者正在寻找一个结合Spark、Python和可视化的完整项目,那这个"卵巢癌风险数据分析系统"或许能给你带来不少启发。从环境搭建到核心代码实现,我都整理好了。快去我主页看看完整版,别忘了点个赞、收藏加三连,有任何问题欢迎在评论区留言交流,我们一起进步!
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡如果遇到具体的技术问题或其他需求,你也可以问我,我会尽力帮你分析和解决问题所在,支持我记得一键三连,再点个关注,学习不迷路!~~