✍✍计算机毕设指导师**
⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡有什么问题可以在主页上或文末下联系咨询博客~~
⚡⚡Java、Python、小程序、大数据实战项目集](https://blog.csdn.net/2301_80395604/category_12487856.html)
⚡⚡文末获取源码
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
脑卒中风险可视化分析系统-简介
本系统是一个基于Hadoop与Django框架构建的脑卒中风险可视化分析平台,旨在运用大数据技术处理和分析海量的健康数据。系统后端采用Python语言,利用Spark分布式计算框架对存储于HDFS中的脑卒中数据集进行高效清洗、转换与分析,结合Pandas与NumPy进行精细化数据处理。前端则通过Vue.js与ElementUI构建交互界面,并借助Echarts实现数据的多维度可视化。核心功能包括对整体人口特征与风险概览的宏观统计,如风险人群分布与年龄结构;深入核心人口统计学维度,探究不同性别、年龄下的风险差异与高发症状;通过临床症状深度挖掘,量化单一症状对风险的影响度,并运用Apriori算法发现高风险人群的症状组合模式,同时以热力图展示症状间的相关性。系统还聚焦于高风险人群的精准画像,并利用K-Means聚类算法对患者进行分群,结合SHAP值分析关键风险因素的贡献度,从而为脑卒中的早期预警与干预提供直观的数据支持与决策参考。
脑卒中风险可视化分析系统-技术
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
数据库:MySQL
脑卒中风险可视化分析系统-背景
选题背景
脑卒中作为一种高发病率、高致残率的脑血管疾病,对个人健康和家庭生活构成了沉重负担。疾病的预防远胜于治疗,而有效的预防依赖于对潜在风险因素的早期识别与评估。随着医疗信息化的发展,积累了大量关于患者体征、症状和病史的数据,但这些数据往往分散且形式多样,难以通过传统手段进行有效整合与深度分析。如何利用现代信息技术,从这些海量信息中提炼出有价值的健康风险模式,实现对脑卒中风险的精准评估与可视化呈现,成为了一个具有现实挑战与应用价值的课题。这便是本系统开发的出发点,希望通过技术手段辅助医疗健康领域进行更科学的风险管理。
选题意义
本课题的意义在于,它尝试将大数据分析技术应用于具体的健康风险评估场景,为脑卒中的预防工作提供一种新的思路和工具。从实际应用角度看,系统能够将复杂的数据转化为直观的图表和风险提示,帮助普通用户更好地理解自身健康状况,也为公共卫生研究者提供宏观的风险分布洞察。在技术层面,它完整地实践了从数据存储、分布式计算到Web应用开发的全过程,整合了Hadoop、Spark、Django等多种主流技术,对于计算机专业的学生而言,是一次宝贵的综合性工程训练。虽然作为一个毕业设计,其规模和精度有限,但它所探索的数据驱动决策模式,展现了信息技术在医疗健康领域的应用潜力,具有一定的参考价值。
核心功能Python代码
脑卒中风险可视化分析系统-视频展示
基于Hadoop+Django的脑卒中风险可视化分析系统
脑卒中风险可视化分析系统-图片展示
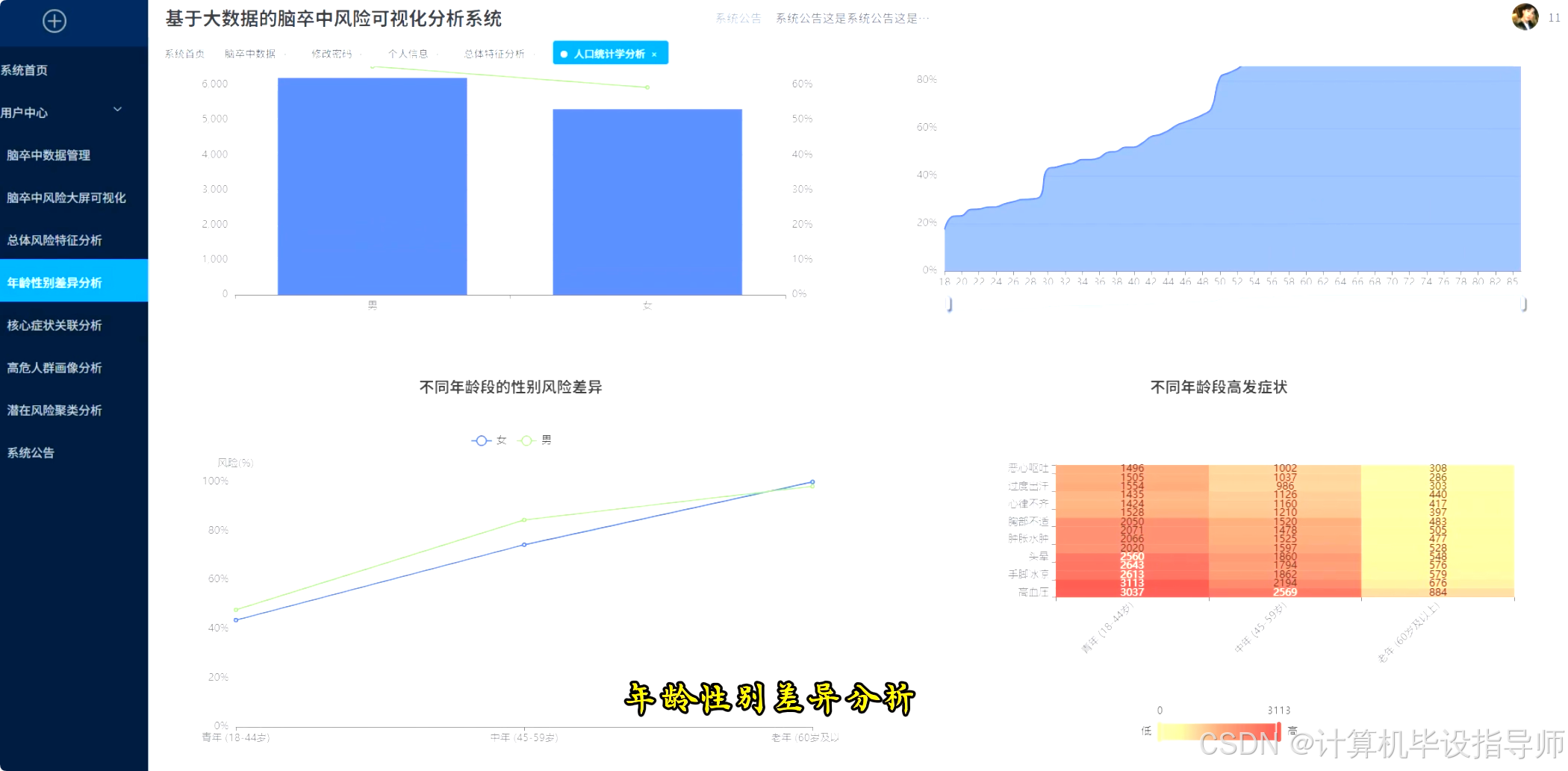

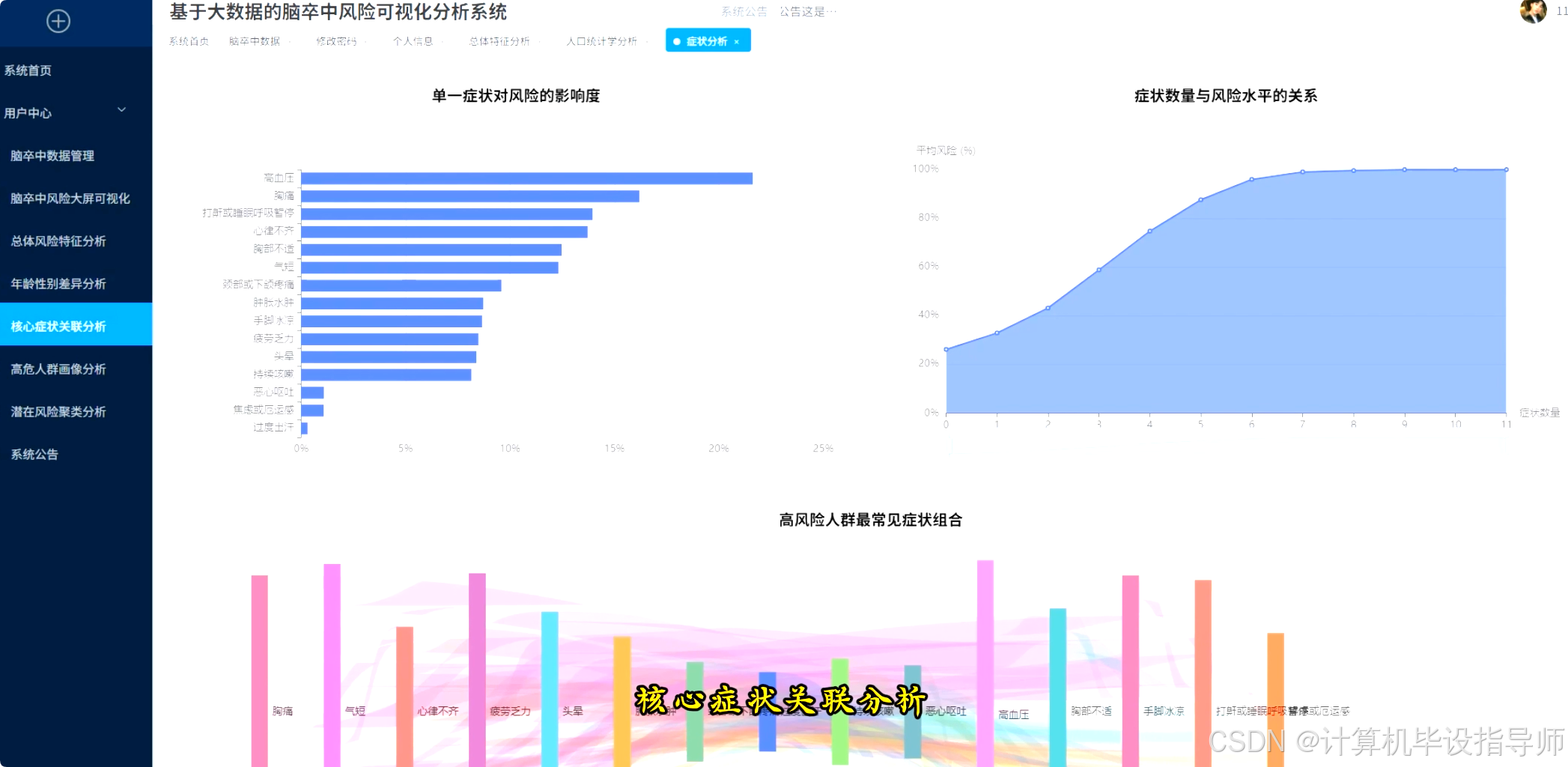
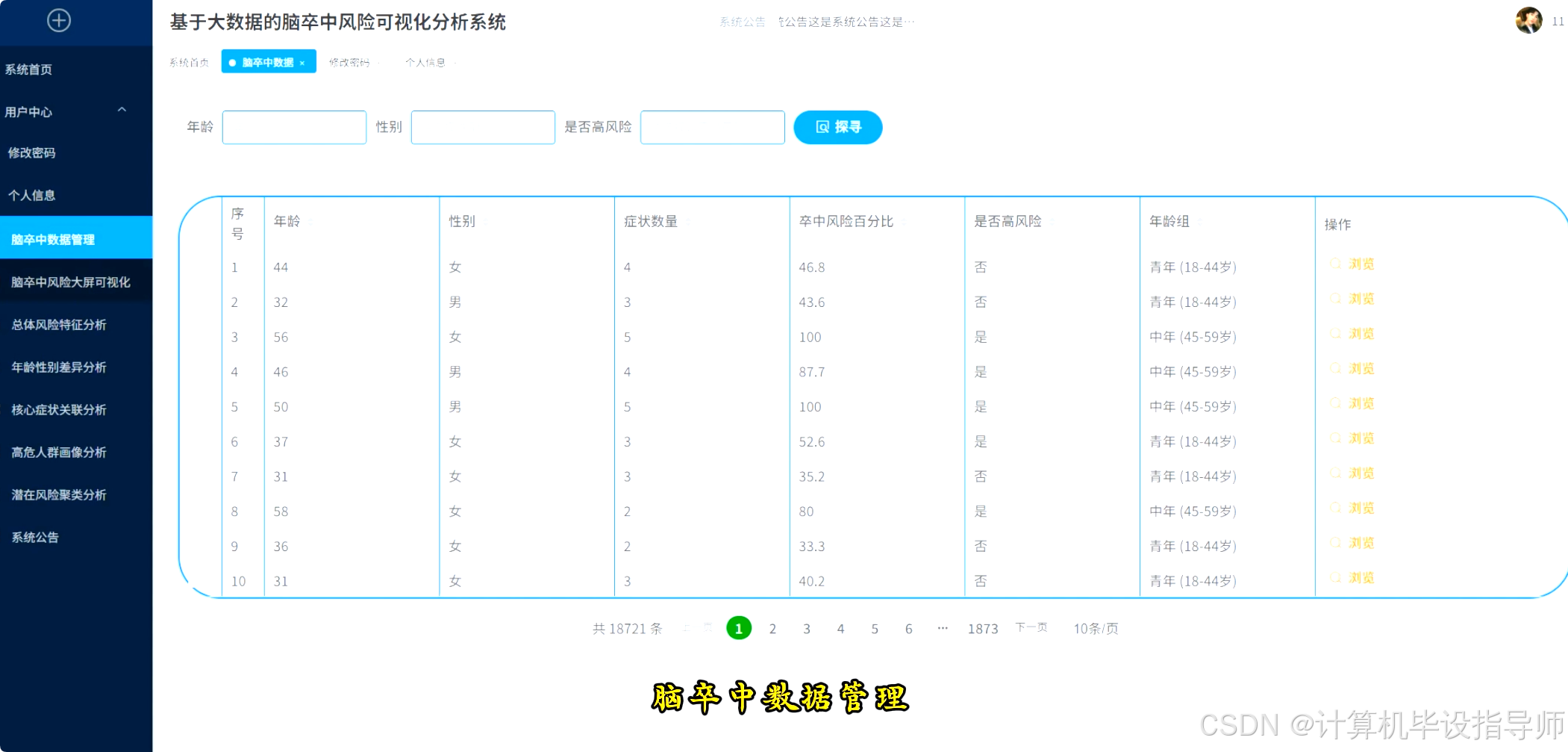
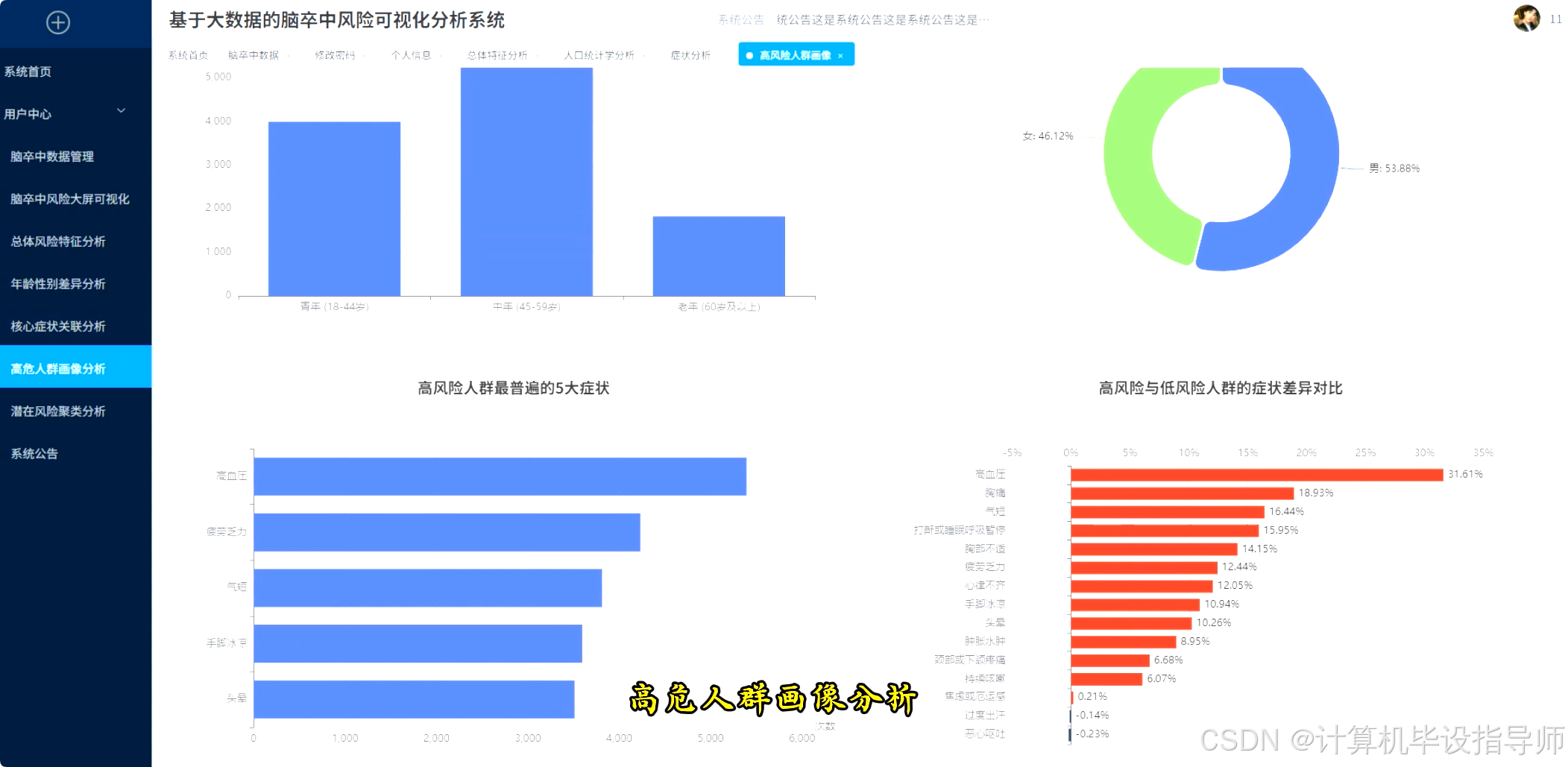

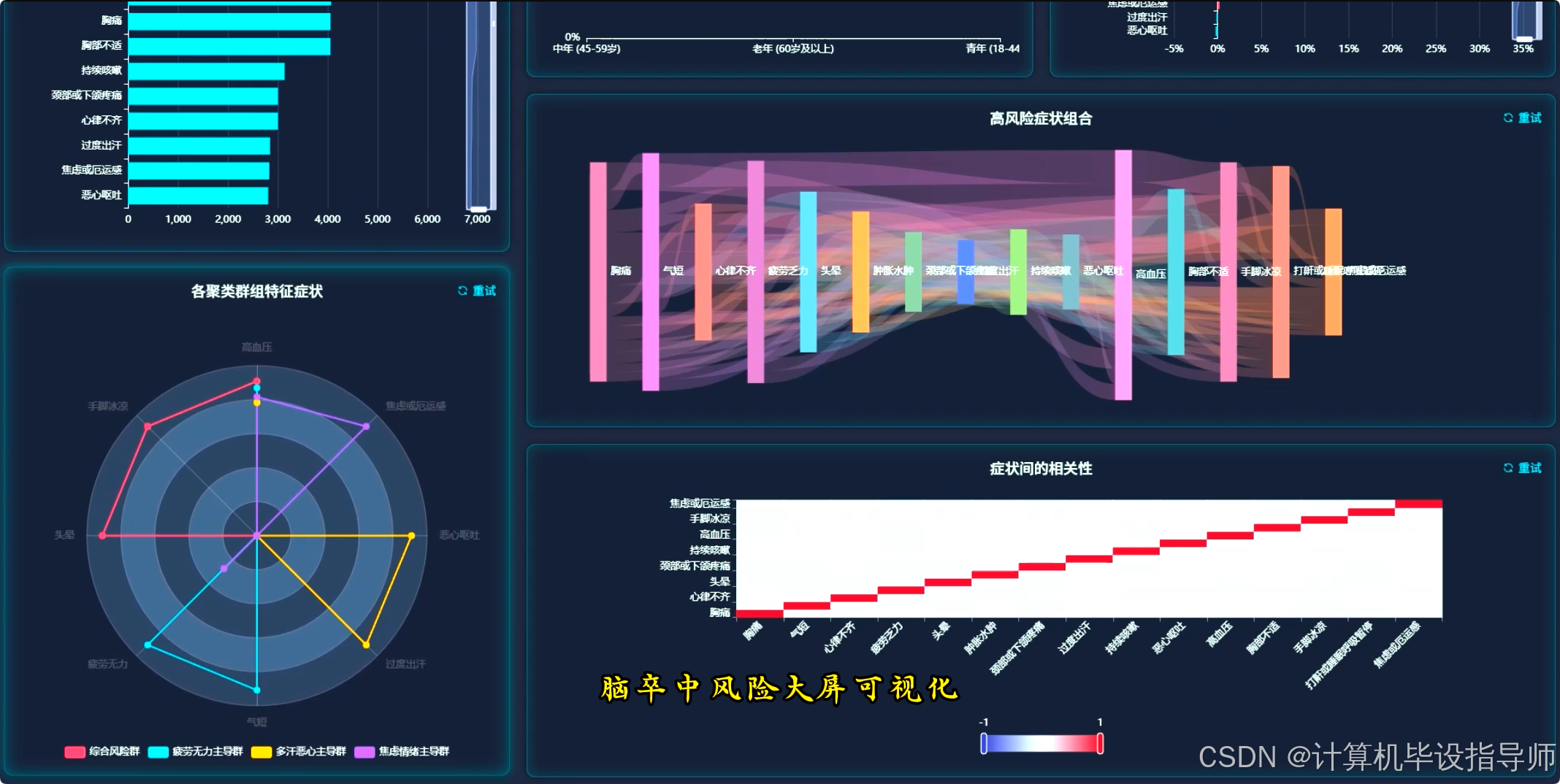
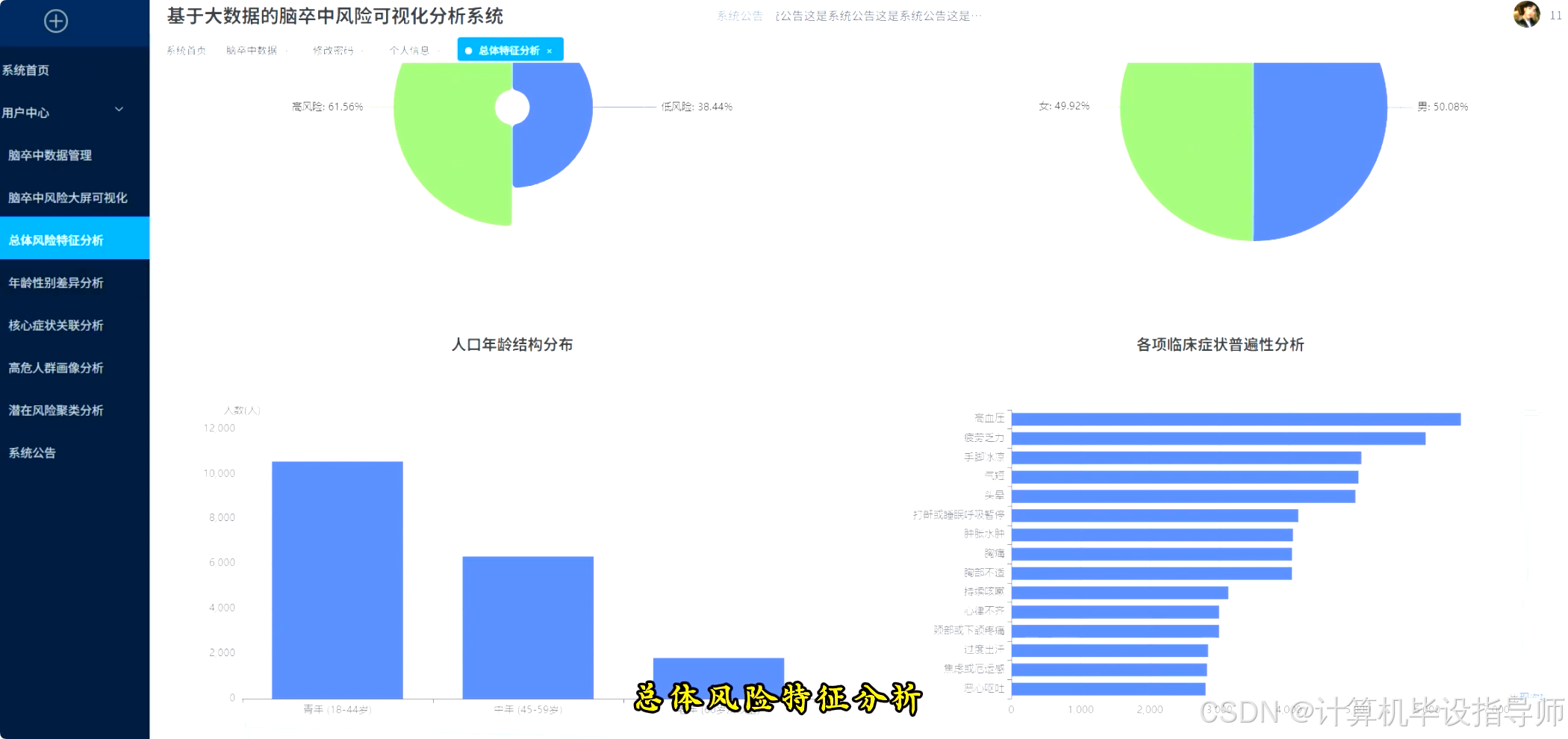
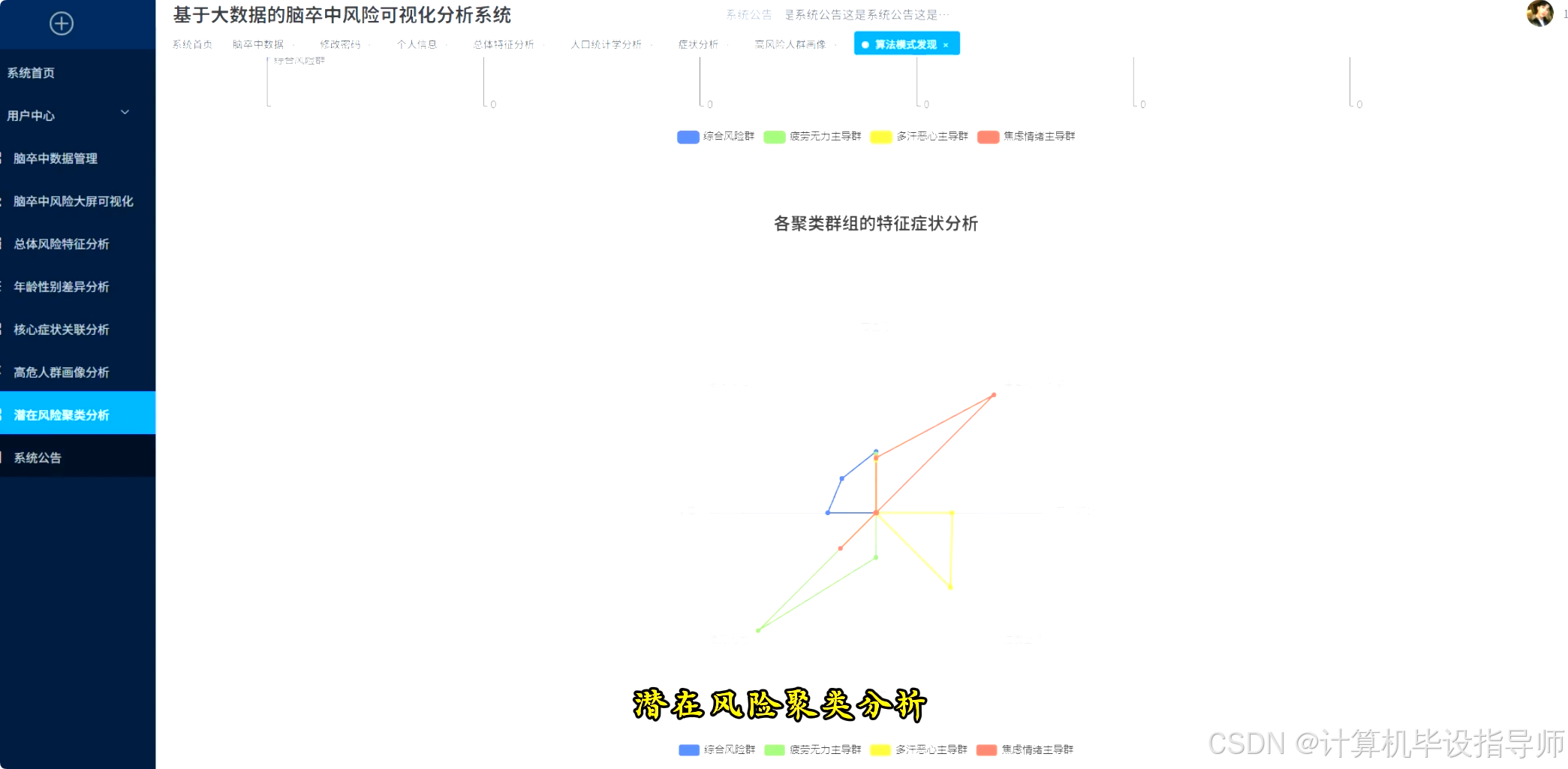
脑卒中风险可视化分析系统-代码展示
python
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.clustering import KMeans
from mlxtend.frequent_patterns import apriori
import pandas as pd
def analyze_risk_by_age_trend(spark, file_path):
df = spark.read.csv(file_path, header=True, inferSchema=True)
df.createOrReplaceTempView("stroke_data")
age_risk_df = spark.sql("SELECT age, AVG(stroke_risk_percentage) as avg_risk FROM stroke_data GROUP BY age ORDER BY age")
age_risk_pd = age_risk_df.toPandas()
return age_risk_pd.to_dict('records')
def find_symptom_combinations(spark, file_path):
df = spark.read.csv(file_path, header=True, inferSchema=True)
symptom_cols = [c for c in df.columns if c not in ['age', 'gender', 'stroke_risk_percentage', 'at_risk']]
high_risk_df = df.filter(df.at_risk == 1).select(symptom_cols)
high_risk_pd = high_risk_df.toPandas()
transactions = high_risk_pd.apply(lambda row: row[row == 1].index.tolist(), axis=1).tolist()
transaction_df = pd.get_dummies(pd.DataFrame(transactions).stack()).groupby(level=0).sum()
frequent_itemsets = apriori(transaction_df, min_support=0.2, use_colnames=True)
frequent_itemsets['length'] = frequent_itemsets['itemsets'].apply(lambda x: len(x))
results = frequent_itemsets[(frequent_itemsets['length'] >= 2) & (frequent_itemsets['support'] >= 0.25)]
return results['itemsets'].tolist()
def perform_patient_clustering(spark, file_path, k=4):
df = spark.read.csv(file_path, header=True, inferSchema=True)
symptom_cols = [c for c in df.columns if c not in ['age', 'gender', 'stroke_risk_percentage', 'at_risk']]
assembler = VectorAssembler(inputCols=symptom_cols, outputCol="features")
feature_data = assembler.transform(df)
kmeans = KMeans(featuresCol='features', k=k, seed=1)
model = kmeans.fit(feature_data)
clustered_data = model.transform(feature_data)
cluster_analysis = clustered_data.groupBy('prediction').agg(
{'age': 'avg', 'stroke_risk_percentage': 'avg', 'at_risk': 'sum'}
).orderBy('prediction')
return cluster_analysis.toPandas().to_dict('records')脑卒中风险可视化分析系统-结语
本系统基本完成了预定的设计与开发目标,成功实现了基于大数据技术的脑卒中风险可视化分析。通过整合Hadoop、Spark与Django,构建了一个从数据处理到前端展示的完整流程。当然,系统仍有可完善之处,例如数据源的多样性、模型预测精度的提升等。但总体而言,本次毕设不仅锻炼了综合运用多种技术的能力,也探索了大数据在医疗健康领域的应用路径,为未来的学习和工作打下了坚实的基础。
对这个Hadoop+Django脑卒中风险分析系统感兴趣的同学,记得来我主页看看更多毕设干货哦!如果觉得对你有帮助,别忘了给UP主一个一键三连支持一下!大家有什么关于毕设选题、技术实现的问题,都可以在评论区留言交流,我们一起讨论,共同进步,顺利毕业!
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡如果遇到具体的技术问题或其他需求,你也可以问我,我会尽力帮你分析和解决问题所在,支持我记得一键三连,再点个关注,学习不迷路!~~