GitHub:github.com/web-abin/Op...
适合在 Claude Code / 类似 Agent 工具里使用。中文 / 英文项目都支持。
前言
最近 SDD(Spec-Driven Development)讨论很多,OpenSpec、Kiro 这一派工具的核心思路是:先写一份 spec,AI 按 spec 实现。
我自己跑了几个项目下来,每次都卡在同一个地方:
spec 第一周很鲜活,第三周开始过期,第二个月只能当占位符。
这不是某个工具的 bug,是流程层面的问题:spec 描述的是"打算做",code 描述的是"实际做"。只要后者还在迭代,前者就会被甩开。AI 读了一份过期 spec 写出来的代码,比没读还危险------它会基于错的"事实"做决策。
所以我开了一个反方向的口子:GDD(Geno-Driven Development),开源仓库叫 OpenGeno。这篇文章拆解一下它的设计、和 SDD 的对比、以及一些落地后才想明白的取舍。
一、SDD 的失败模式:spec 鲜活期太短
抽象一下 SDD 的工作循环:
markdown
1. 人写 spec
2. AI 读 spec → 写代码
3. (代码合入)
4. 下次任务 → AI 再读 spec → 写代码第 3 步和第 4 步之间,没有任何机制保证 spec 还和代码一致。维护 spec 这件事被默默推给了"AI 应该顺手做"或"reviewer 应该提醒"。这两个都是软约束,软约束扛不住时间。
更糟的是 spec 本身是大块文档:一份 200 行的 spec 改了 5 行,diff 看着很小,但语义上可能已经完全错了------而 AI 读它的时候不会知道这件事。
二、GDD 的赌注:把 code 当真理之源,让文档作为可验证的索引
GDD 的反向假设很简单:
- code 是唯一会被强制一致的事实(CI 跑、用户在用);
- 文档存在的意义不是"驱动开发",而是给 AI 提供加载入口和语义注解;
- 文档和代码的一致性不能靠人自觉,要靠机器对账。
落到实现就三件事:
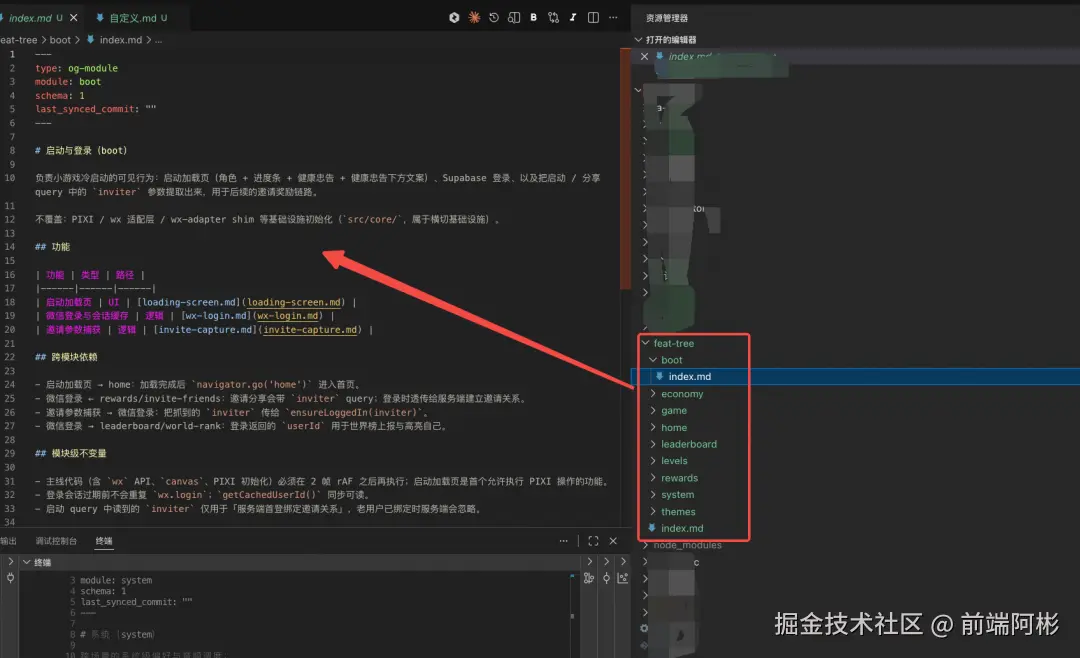
1. 三层结构,按需懒加载
r
feat-tree/
├── index.md # L1:项目根索引,列模块
├── auth/
│ ├── index.md # L2:模块索引,列 feature
│ ├── sign-in.md # L3:单个 feature 的详情
│ └── sign-out.md
└── tasks/
├── index.md
└── list-view.mdAI 改 sign-in 的时候不需要看 tasks 模块的 50 个 feature。它从 L1 看到目标在 auth/,进 auth/index.md 看到 sign-in.md,再读那一篇。改 50 个 feature 的项目和改 5 个 feature 的项目,单次任务读的 token 量几乎一样。
2. 每个 L3 都带一个"已对账"的 SHA
L3 的 frontmatter 长这样:
yaml
---
type: og-feature
kind: ui
feature: sign-in
module: auth
schema: 1
code:
- lib/features/auth/sign_in_page.dart
- lib/features/auth/sign_in_controller.dart
- lib/api/auth_service.dart
last_synced_commit: a1b2c3d
last_reviewed: 2026-05-06
---两个关键字段:
code:这个 feature 依赖哪些代码文件;last_synced_commit:这份文档上次被人/AI 真正对照代码核对过的 git SHA。
SHA 的语义不是"被编辑的时间",是"被验证的时间"。这个区分很重要:单纯改了文档不算对账,必须读了代码、确认一致才能 bump。
3. 漂移检测:把"忘记更新"变成机器能发现的事
有了 code: 和 last_synced_commit:,漂移检测就是一个简单的脚本:
bash
# 伪码
for doc in feat-tree/**/*.md:
last_sha = doc.frontmatter.last_synced_commit
for code_path in doc.frontmatter.code:
if git_log(code_path, since=last_sha) is not empty:
mark doc as DRIFT这个脚本被注册成 Claude Code 的 Stop hook------每次会话结束自动跑。两种模式:
warn(默认):打印漂移摘要,session 正常结束;block:退出码 1,session 不让结束直到漂移被处理。
软约束变成硬约束。AI 忘记更新文档不再是"下次再说",而是"现在就解决"。
三、SDD vs GDD:一张对比表
| 维度 | SDD(OpenSpec / Kiro 等) | GDD(OpenGeno) |
|---|---|---|
| 起点 | spec 先于 code | code 已存在,文档跟随 |
| 文档形态 | 单份 spec / 大块 markdown | L1 / L2 / L3 三层树 |
| AI 加载方式 | 一次性读完整 spec | 沿 L1→L2→L3 按需加载 |
| 维护机制 | 靠人/AI 自觉同步 | last_synced_commit + Stop hook 强制对账 |
| 适用阶段 | 偏新项目 | 任意阶段(含遗留代码) |
| 失败模式 | spec 腐烂、AI 读错 | 漂移会被检测,最差只是被提醒一次 |
| 介入复杂度 | 写 spec 是前置任务 | 一次 init,之后规则注入 CLAUDE.md 自传递 |
它们其实不是替代关系。SDD 解决"从零到一怎么让 AI 写对",GDD 解决"从一到正无穷怎么让 AI 一直写对"。新项目可以先 SDD 出第一版,再用 GDD 维护。
四、整体流程图
整个系统三个阶段,分开看比较清楚。
4.1 一次性初始化
text
┌─────────────────────────────────────────────────┐
│ User: /geno-init │
└────────────────────┬────────────────────────────┘
│
▼
┌────────────────────────┐
│ ① 选语言(中文 / 英文)│
└────────────┬───────────┘
▼
┌──────────────────────────────┐
│ ② 选漂移模式(warn / block) │
└──────────────┬───────────────┘
▼
┌──────────────────────────────┐
│ ③ 选生成模式(stub / full) │
└──────────────┬───────────────┘
▼
┌────────────────────────┐
│ ④ 扫描代码 → 提议模块 │
└────────────┬───────────┘
▼
┌──────────────────────────┐
│ ⑤ 写 L1 / L2 / L3 文档 │
│ 写 .feat-tree.json │
└────────────┬─────────────┘
▼
┌──────────────────────────────┐
│ ⑥ 把工作流契约注入 CLAUDE.md │
│ (此后规则自动传递) │
└──────────────────────────────┘4.2 日常改功能(不需要任何命令)
text
User: 改一下 sign-in 的逻辑
│
▼
[AI 读 CLAUDE.md] ── 已注入的规则告诉它怎么做
│
▼
[L1 index.md] ──► 看到 auth 模块
│
▼
[L2 auth/index.md] ──► 看到 sign-in feature
│
▼
[L3 auth/sign-in.md] ──► 读详情
│
▼
[AI 改代码]
│
▼
[AI 同步更新 L3 + bump last_synced_commit]
│
▼
[Stop hook 自动跑 drift-check]
│
├─► 无漂移 ──► session 正常结束
└─► 有漂移 ──► warn 提醒 / block 拒绝结束4.3 漂移发现后
text
Stop hook 报漂移
│
▼
User: /geno-sync
│
▼
列出五类问题:
├─ 红:明确漂移(code 改了,doc 没跟)
├─ 黄:可疑(提交里有 "refactor" 字样等)
├─ 灰:从未对账过(stub / 待审 full 草稿)
├─ 坏链:code 路径已经不存在
└─ 陈旧 SHA:记录的 SHA 已不在 git 历史里
│
▼
用户选择从哪类开始
│
▼
逐篇:读 diff → 改文档 → bump SHA
│
▼
最终报告:哪些已对齐、哪些跳过整个系统就两个 skill(/geno-init 和 /geno-sync)+ 两个 hook(PostToolUse 提醒、Stop 检漂移)。没有第三个。每多一个命令都是用户要记的事。
五、stub / full:两种初始化策略
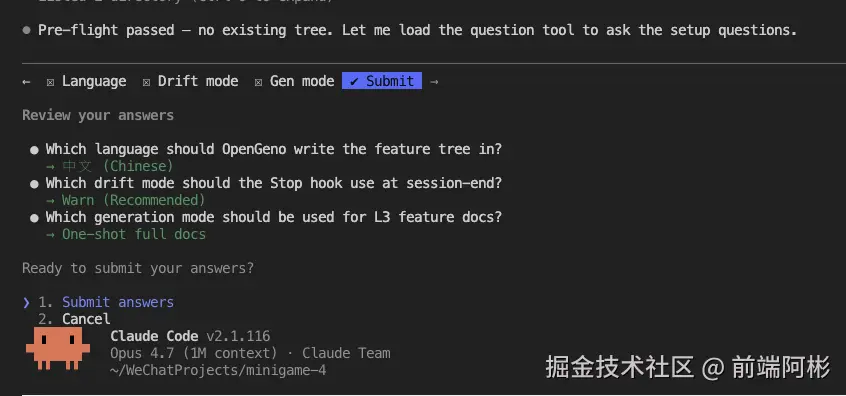
/geno-init 在 Step 3 会问一个问题:生成模式选 stub 还是 full?
stub 模式(默认)
只生成文档骨架,section body 全是 TODO / 待补充。日常改到哪个 feature 再现写哪个的内容。
yaml
---
type: og-feature
kind: ui
feature: sign-in
last_synced_commit: ""
last_reviewed: 2026-05-06
---
# Sign in
## Wireframe
TODO
## Entry points
TODO
## Interactions
TODO适合:大项目、想增量推进、不希望初始化阶段花太多 token。
full 模式
扫描更深一层,AI 一次性把所有 L3 都尽力写出来。但关键设计 :last_synced_commit: 留空。
意思是:内容有了,但没人验证过。
yaml
last_synced_commit: "" # 哪怕全文都填了,SHA 也必须是空的为什么?因为 SHA 的语义是"被验证过",full 模式只是"被生成过"。这两件事必须区分开。/geno-sync 看到 gen_mode: "full" + 空 SHA,会知道这是"待审稿"而不是"待写",给出不同的处理建议。
仓库里 examples/todo-app-full/ 有完整的 full 模式产物 demo。注意里面 AI 写的句式:
"Validates on blur. Regex used:
^[^@]+@[^@]+\.[^@]+$(literal fromsign_in_controller.dart)""Remember-me checkbox --- visible in the build method, exact placement uncertain --- confirm during review"
这种 hedged tone 是故意要求 AI 这么写的------没法确认的事就不要假装确认 。AI 拿不准的时候,不是猜一个看起来合理的值,而是直接留 待补充 让人来填。
六、.feat-tree.json:项目根的运行时配置
init 完成会在项目根写一个:
json
{
"version": 1,
"tree_path": "feat-tree",
"drift_mode": "warn",
"gen_mode": "stub"
}四个字段都是有用途的:
tree_path:树放在哪个目录(默认feat-tree/,可改);drift_mode:warn还是block,被 Stop hook 读取;gen_mode:stub还是full,被/geno-sync读取(决定空 SHA 的语义是"待写"还是"待审");version:schema 版本,未来升级用。
七、规则是怎么传递给后续 session 的
这是 GDD 真正能 work 的关键------规则不是写在 README 让用户记,是 init 时注入到项目的 CLAUDE.md。
/geno-init 最后一步会把一段规则文本追加到 CLAUDE.md(如果没有就新建),用 <!-- BEGIN OpenGeno --> / <!-- END OpenGeno --> 包起来。这段文本告诉未来每一个 session 的 AI:
- 改代码前要走 L1→L2→L3 读对应文档
- 改完代码要同步更新 L3 并 bump SHA
- bump SHA 的前提是真的读了代码------只编辑文档不算
Claude Code(包括其他读 CLAUDE.md / AGENTS.md 的工具)每次启动都会读这份文件。规则一次注入、永久生效,不需要用户每个 session 重复说。
八、上手
快速安装
csharp
npx skills add web-abin/OpenGeno手动安装
bash
# 1. 把 skill 装到 Claude Code
git clone git@github.com:web-abin/OpenGeno.git
cp -r OpenGeno/skills/geno-init ~/.claude/skills/
cp -r OpenGeno/skills/geno-sync ~/.claude/skills/
# 2. 在你的项目下运行
cd your-project
/geno-init/geno-init 会跟你交互三个问题(语言 / 漂移模式 / 生成模式),扫描代码、提议模块、确认后生成树。整个过程不会改你的代码 ,只会创建 feat-tree/、写 .feat-tree.json、追加 CLAUDE.md。
跑完之后日常使用就完全不需要再调命令了------AI 会按 CLAUDE.md 里的规则自动走流程。
九、诚实地说,GDD 不是银弹
我承认它有几个明显的限制:
- 第一次接入要花点时间梳理模块。stub 模式能减轻负担但模块边界还是要人来定。
- AI 偶尔会忘记 bump SHA。Stop hook 是兜底,但 hook 报错时仍然依赖人去修。
- 多人协作时漂移更频繁。这是好事------能暴露团队成员之间的同步问题------但接入初期会有阵痛。
- 目前只在 Claude Code 上验证过。AGENTS.md 已经准备好但未在 Cursor / Aider 等工具里打磨。
- 不能完全替代 spec。需求评审、架构设计这些"打算做"的环节,spec 还是更合适------GDD 只接管"已经做了什么"这一段。
完整的设计动机和取舍写在仓库的 docs/motivation.md,几个具体决策(为什么只两个 skill、为什么用 CLAUDE.md 注入、为什么三层)写在 docs/decisions/。
结语
把"先写 spec"换成"先看代码、再让文档跟着代码走",是个反直觉但越用越香的小转向。这种感觉有点像从"写注释"切到"写测试"------前者依赖自觉,后者由机器兜底。
如果你也被 spec 腐烂折磨过,欢迎试试 OpenGeno。
- GitHub :github.com/web-abin/Op... --- 觉得有用请点个 Star🌟🌟🌟
- Issue / PR / 讨论:都欢迎,尤其是漂移规则那块还在打磨
- 三连 :如果文章对你有启发,点赞 / 收藏 / 关注 是最大的支持
下次写一篇细的,专门聊"为什么 SHA 而不是 mtime"和"为什么三层而不是两层或四层"------这两个决策当时纠结了挺久。