上个月,一位时代少年团粉丝的偶然测试,把一个学术圈讨论的技术问题推到了全网面前。
大家都知道大模型圈的「马嘉祺」事件,模型能准确说出马嘉祺的履历、综艺经历和团内角色,却始终没法正确输出马嘉祺三个字。马嘉棋、马佳琪、马琪琪,各种错别字轮番上阵。让它重复五遍,回你五个一模一样的错误。问第二个字是什么,答家。

随后的技术排查揭示了原因:大模型输出层对低频 token 的退化。嘉祺被分词器合并成了一个独立 token,预训练阶段出现得够多所以没问题,但 SFT 阶段的高质量对话数据里几乎没有偶像名字,这个 token 的参数在微调中严重偏移。模型脑子里有这个人的全部信息,嘴上就是说不出名字里那两个字。
这件事因为明星效应迅速出圈,全网热议。但其实这件事的技术原因早有端倪。低频 token 退化,并不完全是一个全新的技术发现。
早在 2025 年,一家名为脸谱心智(FaceMind)的初创公司就在顶级学术会议 EMNLP 主会上系统性地揭示了这个问题,并给出了解法。更有意思的是,就在「马嘉祺」事件前不到两周,全球最强 AI 公司之一 Anthropic 也在自家产品中悄悄落地了一次高度相关的改造 ------ 方向与脸谱心智一年前的论文几乎完全一致。
学术先驱、产业验证、公众认知,三件事发生在三个完全不同的时间点。把它们串起来看,能看到一个比「模型说不出明星名字」有趣得多的故事。
与此同时,团队已加速补齐商业和科研两块关键拼图:一位千亿市值上市公司的联创已加盟,出任商业化合伙人,将带来海量商业化资源以及下游渠道;一位发表过上千篇论文的知名教授,也将以首席科学家身份加盟,以此撬动国内外大量学界资源搭桥产学研三界。从融资节奏到核心团队搭建,脸谱心智正以资金、商业落地和技术纵深三个维度同步拉满。
四个时间节点,一条因果链
2025 年,EMNLP 主会。 脸谱心智作为第一机构,与香港中文大学联合发表论文 SLoW。这篇工作率先把大模型中的「低频词问题」系统化:在跨语言翻译中,长尾低频词往往是模型理解和生成的薄弱环节。论文提出 Dictionary-based Prompting,在推理阶段自动选择关键低频词条注入提示词,不改模型、不加训练,就能提升模型对低频词的处理能力,并适配近百种语言。
2026 年 4 月 2 日。 脸谱心智在 arXiv 发布后续论文 Adam's Law,已被顶级学术会议 ACL 2026 以 Oral 形式接收。这篇论文把频率的影响从单词级别推进到了句子级别,提出了 Textual Frequency Law(TFL)------ 一套从 Zipf 定律出发、有完整数学证明的频率定律,以及配套的蒸馏方法和课程学习训练框架。
2026 年 4 月下旬。 Anthropic 发布 Claude Opus 4.7,官方迁移指南明确写道:Claude Opus 4.7 uses a new tokenizer, contributing to its improved performance. 社区开发者实测,同样文本的 token 消耗增加约 1.0--1.35 倍,英文和代码增幅更大(1.20--1.47 倍),CJK 文本几乎无变化(1.01 倍)。业内普遍解读:Anthropic 缩减或重组了词表,把低频、容易退化的 token 合并或去掉了。
2026 年 5 月 9 日。 「马嘉祺」事件出现,公众第一次大规模了解到低频 token 退化这个概念。

把四个节点排在一起,我们发现:脸谱心智是低频 token 退化最早的学术发现者和方案提出者,Anthropic 最早将其进行生产级落地验证,而公众认知比学术前沿晚了一整年。
这种传播时差本身就说明问题。一篇发在最顶级会议上的论文,经历了完整的同行评审,提出了系统性的发现和解法 ------ 安安静静地存在了一年。学术价值和公众注意力之间的鸿沟,在这个案例上体现得格外明显。
从单词到句子:不止一种解法
脸谱心智在低频问题上的工作分布在两个粒度 ------ 单词级别和句子级别。每个级别又各自提供了 prompting(不用训练)和 training(需要训练但效果更深入)两条路径。
单词级别:SLoW(EMNLP 2025)
这是时间最早的那篇。论文的核心洞察是:大模型对低频词汇有系统性的理解和生成劣势,而这个问题不需要动模型权重就能缓解。Dictionary-based Prompting 的做法是在提示词里塞入一层词典级别的频率辅助信息,让模型在推理时意识到哪些词是低频的、应该怎么处理。
回到「马嘉祺」场景来理解:如果问题发生在理解或翻译链路,SLoW 这种词典 prompting 可以作为低成本输入层方案;如果问题已经进入生成端,比如 lm_head 对某些 token 的后训练退化,则需要训练侧的数据覆盖或合成数据修复。也正因为如此,脸谱心智的工作价值不在于只有一种修法,而在于从输入层到训练层都给出了频率感知的方法论。

句子级别:Adam's Law(ACL 2026 Oral)
「马嘉祺」事件暴露的是单词维度的频率退化,但脸谱心智发现,频率的影响远不止于此。句子级别的文本频率同样深刻影响模型表现 ------ 这是一个此前被整个学术界忽视的维度。
Adam's Law 提出的 Textual Frequency Law 是这样说的:在语义不变的前提下,选择句子级文本频率更高的表述方式,大模型无论在 prompting 还是 fine-tuning 场景下都会表现更好。 论文从 Zipf 定律出发做了形式化推导,给出了从 token 级到句子级的完整理论证明链。
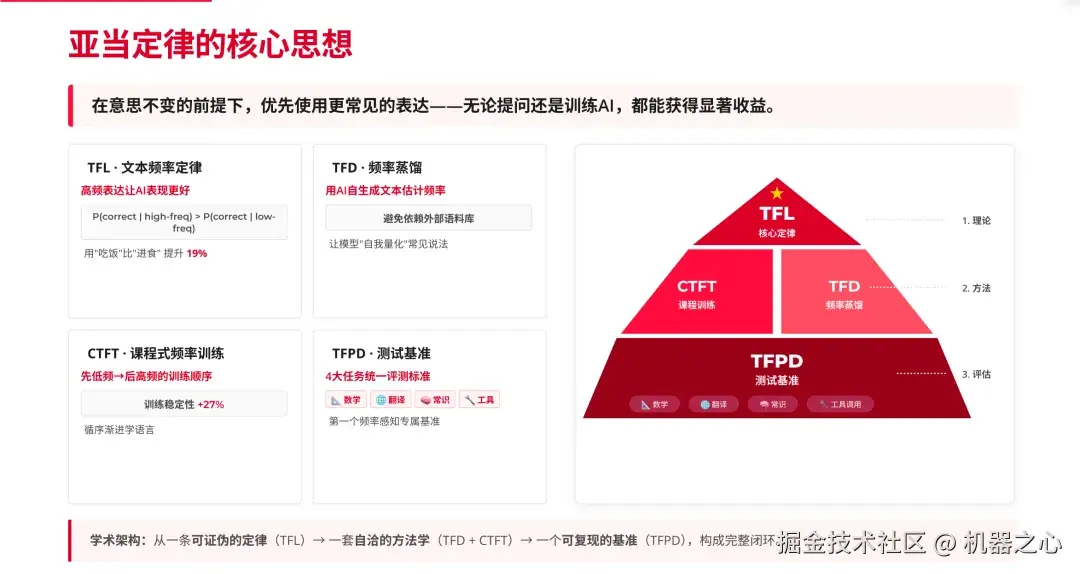
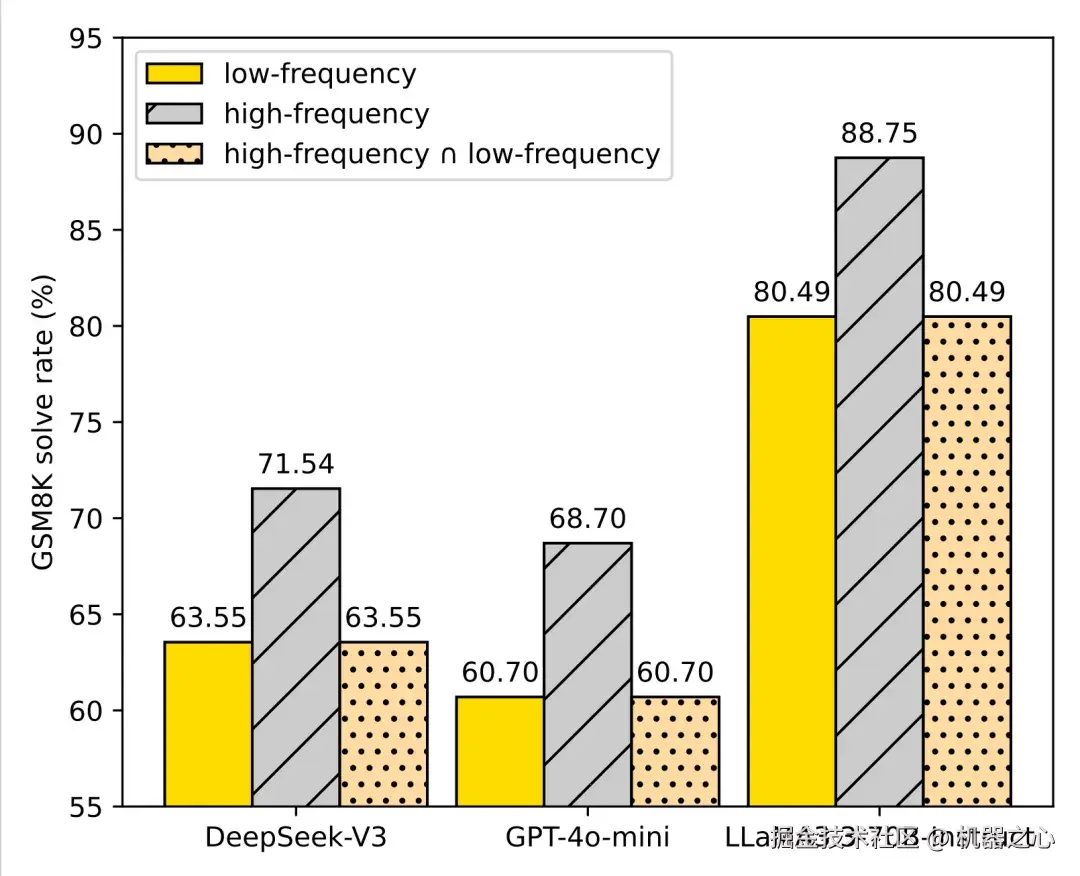
实验覆盖面非常广:
Prompting 层面:仅靠把输入改写为高频表述,DeepSeek-V3 数学推理准确率从 63.55% 涨到 71.54%,LLaMA-3.3-70B 从 80.49% 涨到 88.75%。
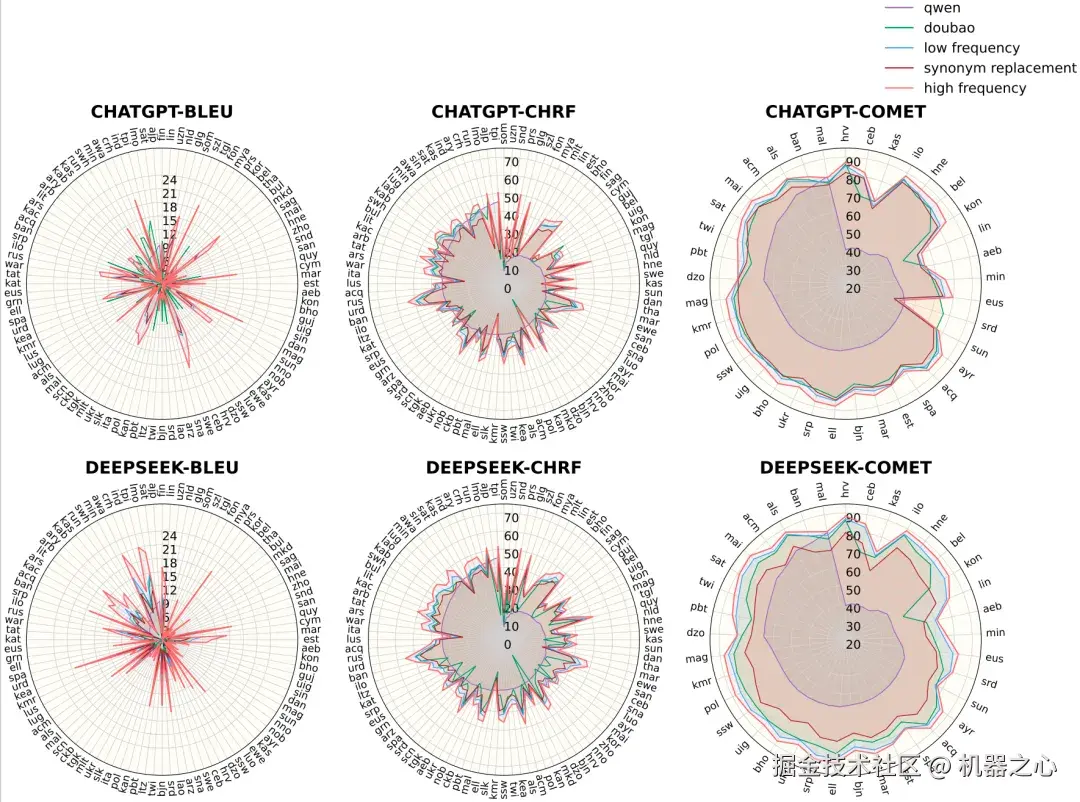
机器翻译方面,100 个语言对中 99 个 BLEU 分数获得提升,其中 63 个提升超 1 分,12 个超过 5 分。
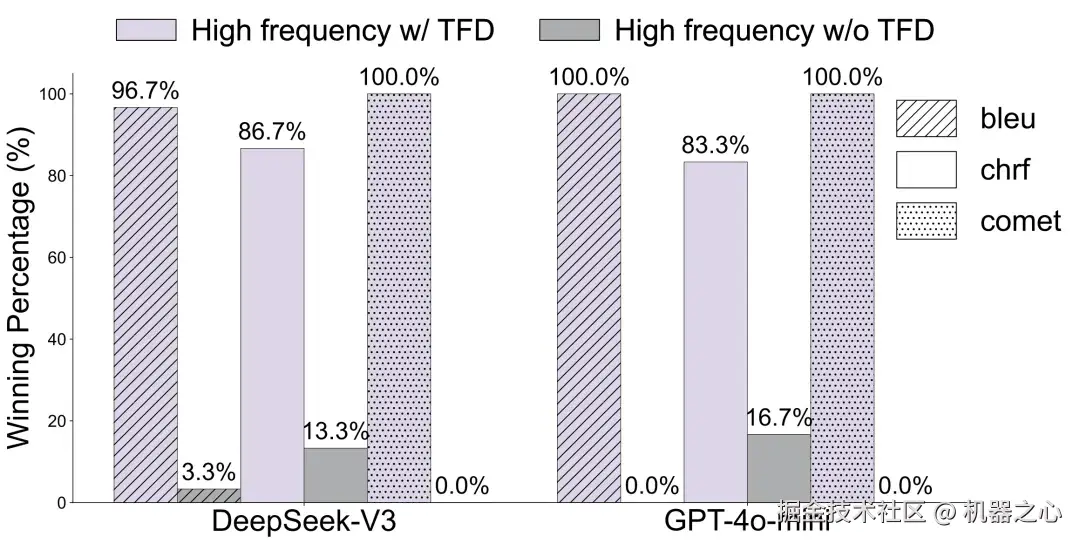
训练层面:CTFT 在低资源语言翻译的部分 BLEU 指标上带来接近 30% 的相对提升;TFD 的消融实验则进一步说明,频率估计校正本身也能带来稳定增益。
而且论文验证的任务类型远超文本生成本身:数学推理、常识推理、Agent 工具调用、近百种语言翻译任务全部涵盖在内。
两篇论文接在一起看,从单词到句子、从 prompting 到 training、从现象发现到理论证明,构成了一个完整的方法论体系。
Claude Opus 4.7 换了 tokenizer,然后呢?
Anthropic 在 Claude Opus 4.7 上更换 tokenizer 这件事,在技术社区的讨论热度远不及「马嘉祺」事件。但把它放进这条时间线里审视,意义其实更大。
这个操作方向和脸谱心智 EMNLP 2025 论文中的核心判断高度吻合:低频 token 退化是大模型的结构性问题,必须主动干预。 脸谱心智走的是学术路径:发现、量化、建模、给方案;Anthropic 走的是工程路径:直接在产品中动刀,用服务全球数亿用户的系统来验证方向正确性。
两者独立工作,殊途同归。这种巧合不是巧合,它恰恰说明脸谱心智 2025 年的学术判断是准确的,方向已经被行业最头部的玩家用真金白银的产品决策所确认。
但两者之间有一个关键差异。Anthropic 目前的改造只停留在单词级别,通过 tokenizer 调整来处理低频 token。脸谱心智的框架则同时覆盖了句子级别的频率定律和配套的训练方法:Adam's Law,这部分在全球产业界还没有任何公司跟进落地。
也就是说,即使是 Anthropic,目前也只「追上」了脸谱心智 2025 年那篇论文的思路。2026 年 4 月发布的句子级方法论,整个产业界还没来得及消化。
产业界未开采的学术金矿
深入看 Adam's Law 的理论框架,会发现当前产业界对低频问题的理解和应对仍然处于初级阶段。
首先是一个被广泛忽视的基本事实。根据 Zipf 定律 ------1949 年提出,至今仍是描述自然语言频率分布的基础定律:大约 20% 的词汇承担了 80% 的使用频次。
反过来说,绝大多数词汇都落在那条长长的尾巴上,都属于低频的范畴。仅仅修改 tokenizer 是不够的。 你可以砍掉一些特别边缘的 token,但不可能把整条长尾都剪掉 ------ 那会严重损害模型处理多样化文本的能力。
这也是脸谱心智的方案比单纯改 tokenizer 更有深度的原因。他们不只做减法:Dictionary-based Prompting、tokenizer 改造,还做加法:频率蒸馏、课程学习训练框架。减法轻量快速,适合部署阶段做即时优化;加法成本更高但效果更系统,适合在训练阶段从根源上缓解问题。两条路径互补,构成了目前这个方向上最完整的工具箱。
其次是适用范围的想象空间。当前产业界对低频问题的关注几乎全部集中在文本生成,也就是「马嘉祺」三个字说不出口这类直观可感的现象。但 Adam's Law 论文已经在数学推理、常识推理、Agent 工具调用和近百种语言翻译任务上验证了频率定律的有效性。论文还进一步指出,这套理论框架不仅适用于大语言模型 ------ 传统视觉模型、VLA 模型、乃至没有显式词表的世界模型,理论上都能适配。
也就是说,频率定律可能不只是大语言模型的局部优化技巧,而是理解和提升各类深度学习模型的一个通用透镜。这个方向上能挖掘的价值,目前还远远没有触及天花板。
脸谱心智的 CEO 说过一句有意思的话:这篇论文的核心思路是他洗澡时想出来的。听着像段子,但背后的逻辑很认真。DiT 架构在提出时也只是一篇学术论文,直到 Sora 和可灵把它变成产品,人们才后知后觉地意识到那篇论文值多少钱。一篇论文如果抓住了正确的方向,它的潜在商业价值可以是数千亿甚至数万亿级别的。 这不是夸张,而是 DiT 的先例已经证明过的事。
学术社区的技术先驱
还有一件事值得一提。「马嘉祺」事件引发广泛关注后,相关技术讨论在分析低频 token 退化和数据合成方案时,几乎没能追溯到脸谱心智的工作。而从内容来看,核心论断的重合度相当高 ------ 低频 token 系统性表现差、高频 token 持续受益、训练数据需要设置频率下限 ------ 这些观点在脸谱心智的论文中都有更早的、经过同行评审的系统性阐述。
Adam's Law 在学术社区的能见度并不低。HuggingFace Papers 上有大量讨论,有研究者评价它是 Best Paper 级别的工作;Deep Learning Weekly 做了收录;YouTube、LinkedIn、Spotify、X 上都有传播痕迹。

在这一年里,产业界关于低频 token 退化的讨论很多,思路与脸谱心智的学术工作不谋而合。当一个技术方向终于被市场认可时,最早做出判断和贡献的人,理应被看见。
DiT 之于 Sora,频率定律之于什么?
脸谱心智目前正在向世界模型方向转型。从频率定律这条研究脉络来看,这家公司展现出了一个很清晰的特质:能在学术层面发现被整个行业忽视的关键问题,并且在最严格的学术评审中获得最高级别的认可。
EMNLP 2025 主会发表、ACL 2026 Oral 接收 ------ 放在自然语言处理领域,这是学术共同体能给出的顶格评价。从 SLoW 到 Adam's Law,从单词到句子,从 prompting 到 training,从现象发现到理论证明再到多任务验证,这条研究线的完整度和原创性经得起最严格的审视。
而 Anthropic 用 Claude Opus 4.7 的 tokenizer 改造,从产业侧印证了这个方向的价值 ------ 当全球最强 AI 公司之一在生产环境中做了同样的事,方向的正确性就不再需要争论。更关键的是,Anthropic 目前只跟上了单词级别的思路,句子级别的频率定律和对应的训练框架,产业界至今还没有跟上。
如果说 DiT 之于 Sora 证明了一篇论文可以撬动万亿级商业价值,那脸谱心智在频率定律上的学术积累也指向一个类似的叙事。一家掌握了关键基础理论、且研究成果已被全球头部玩家侧面验证的世界模型公司 ------ 这个定位,在当前 AI 创业公司的格局中是稀缺的。
至少在学术先发性和技术判断力这两个维度上,脸谱心智已经攒够了筹码。剩下的悬念只有一个:市场什么时候给出它应有的定价。
参考文章:
论文标题:Adam's Law: Textual Frequency Law on Large Language Models
arXiv 预印本:arxiv.org/abs/2604.02... ACL 2026 Oral 接收)
EMNLP 2025 论文(SLoW):aclanthology.org/2025.emnlp-...
GitHub:github.com/HongyuanLuk...
HuggingFace Papers:huggingface.co/papers/2604...
NUS Talk(B 站):www.bilibili.com/video/BV1Kp...
Anthropic Claude Opus 4.7 Tokenizer 分析:openrouter.ai/announcemen...
Deep Learning Weekly 报道:www.deeplearningweekly.com/p/deep-lear...