****论文题目:****Aeroengine Blades Damage Detection and Measurement Based on Multimodality Fusion Learning(基于多模态融合学习的航空发动机叶片损伤检测与测量)
****期刊:****IEEE TRANSACTIONS ON INSTRUMENTATION AND MEASUREMENT
****摘要:****航空发动机经常工作在高负荷、高速旋转、强腐蚀等恶劣条件下,在这些条件下,航空发动机叶片容易受到外界物体的冲击而损坏,严重影响航空发动机的性能和飞行安全。因此,开展航空发动机叶片损伤检测与测量研究是非常有必要的。提出了一种基于视觉图像和深度图的多模态智能损伤检测方法和一种航空发动机叶片损伤自动测量方法。建立了航空发动机叶片损伤视觉深度多模态数据集(ABDM)。该数据集包含四种常见的发动机叶片损伤类型,即划伤、撕裂、弯曲和倒角。根据不同的融合阶段,设计了三种融合网络:视觉深度数据级融合网络(VDFNet-data)、视觉深度特征级融合网络(VDFNet-feature)和视觉深度决策级融合网络(VDFNet-decision)。其中,VDFNetfeature的损伤检测性能最好,平均精度(mAP)为85.60%,推理速度为37.48帧/秒(fps)。在主干网中,设计了多分支串联块(Multi-Concat-Block)、平行下行采样块(parallel - down - block)和跨级部分空间金字塔池(CSPSPP)块,解决了检测环境光线暗淡造成的损伤智能检测难题;伤害大小的大变化和一些伤害的小变化。此外,设计了堆叠对称网络(SSNet)来提取损伤特征点,然后根据特征点在深度图上的空间坐标计算损伤大小。本文提出的测量方法的正确键率(PCKs)和尺寸误差(SE)分别为93.28%和0.12 mm。
航空发动机叶片损伤检测新突破:基于多模态融合学习的智能检测与自动测量
一、研究背景:为什么叶片损伤检测这么难?
航空发动机被誉为现代工业的"皇冠",其叶片是核心气动部件,直接决定发动机性能与飞行安全。在飞机起降过程中,发动机不可避免地会吸入沙粒、金属颗粒、鸟类等外来物,在叶片局部形成复杂应力场,导致以下四种典型损伤:
- 缺口(Nick):叶片边缘的局部缺损
- 撕裂(Tear):叶片材料的撕裂型损伤
- 弯曲(Bent):叶片的塑性弯曲变形
- 倒角(Chamfer):叶片尖端的斜角磨损
这些损伤在载荷下极易扩展,严重危及发动机运行安全。因此,高效准确的损伤检测与测量研究具有重大意义。
现有方法的三大痛点
痛点一:振动检测方法局限性大 传统基于振动响应的损伤识别方法操作流程复杂、检测成本高、效率低,且无法准确识别损伤类型与具体位置。
痛点二:人工目视检测误差多 目前主流的人工目视检测方式受环境光线、检测角度、损伤尺度差异大、部分损伤尺寸极小等因素影响,极易出现漏检和误检,且高度依赖经验丰富的检查人员。研究表明,结合触觉感知(即感知三维空间信息)的检测准确率高于纯视觉检测,这启发了引入深度图的思路。
痛点三:现有深度学习方法仅用视觉图像 已有基于深度学习的叶片损伤检测研究均依赖二维视觉图像,只能捕捉颜色、纹理、轮廓等二维特征,在光线昏暗或损伤特征不明显时容易失效,且无法获取损伤的真实三维空间信息,限制了检测精度的进一步提升。
损伤测量方面:现有方法主要依赖传统图像处理(如样条插值、曲线斜率拟合)提取单一类型损伤的特征点,鲁棒性差、泛化能力弱,且均基于二维图像,缺乏三维空间信息支撑,测量精度无法保证。
二、核心创新:本文提出了什么?
本文提出了一套完整的多模态智能检测与自动测量框架,主要创新包括以下三个层面:
创新一:ABDM多模态数据集的构建
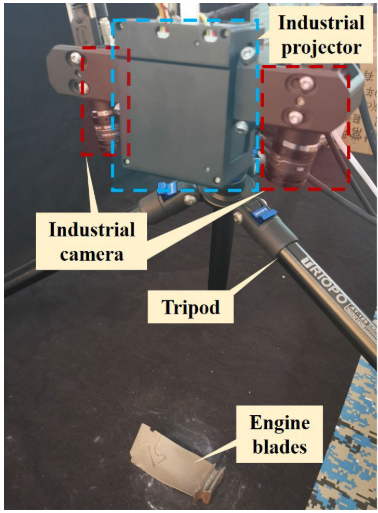
【此处配图:Fig. 1 双目结构光三维重建系统实物图】
研究团队自主搭建了一套双目结构光三维重建系统 ,该系统由工业结构光发生器、两台工业相机(海康威视500万像素,分辨率2448×2048,焦距12mm)和三脚架组成。系统采用相移法 与多频外差法 结合实现相位展开,通过极线矫正和三角测量完成三维重建,重建精度达0.005mm。
利用该系统采集视觉图像与深度图,构建了ABDM(Aeroengine Blade Damage Multimodality)数据集:

【此处配图:Fig. 2 ABDM数据集示例(第一行:视觉图像,第二行:深度图)】
| 损伤类型 | 总数量 | 训练集 | 测试集 |
|---|---|---|---|
| 缺口 Nick | 1710 | 1538 | 172 |
| 撕裂 Tear | 924 | 835 | 89 |
| 弯曲 Bent | 750 | 671 | 79 |
| 倒角 Chamfer | 480 | 435 | 45 |
| 合计 | 3864(视觉+深度各2272) | --- | --- |
数据集按9:1比例随机划分训练集与测试集,使用开源软件LabelImg对视觉图像进行标注,由于深度图与视觉图像天然对齐,无需额外标注。
为扩充数据集,采用了几何畸变 (随机缩放、裁剪、旋转、翻转)和马赛克数据增强 (Mosaic,将四张图像拼合以引入多样化上下文)两类增强策略。值得注意的是,光度畸变仅用于视觉图像,因为深度图中的颜色信息具有物理含义(代表三维空间距离),不能随意改变。
创新二:三种多模态损伤检测网络
根据融合阶段的不同,作者设计了三种网络架构:
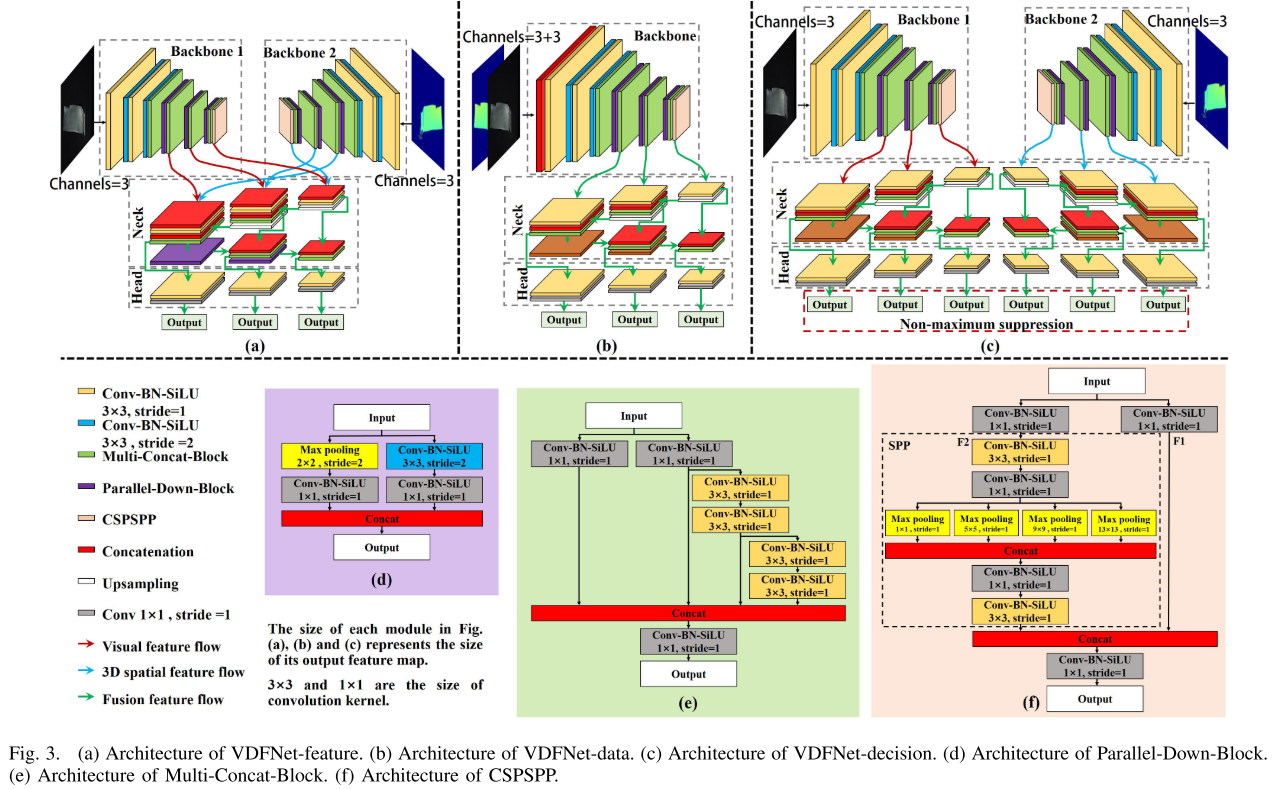
【此处配图:Fig. 3(a)(b)(c) 三种融合网络架构图,以及 (d)(e)(f) 三个专用模块结构图】
2.1 VDFNet-feature(特征级融合,性能最优)
这是本文最核心的网络。其架构由两个相同的骨干网络 + 颈部网络(PANet)+ 头部网络构成:
- 两个骨干网络分别独立提取视觉特征与三维空间特征
- 颈部网络将两种模态的多尺度特征进行融合(PANet结构)
- 头部网络输出三种尺度(20×20、40×40、80×80)的检测结果,覆盖不同大小的损伤
核心公式为:
骨干网络的三个专用模块:
① Multi-Concat-Block(多分支拼接块) 针对叶片损伤特征提取困难的问题设计。该模块采用四条并行分支,前两条分支分别用单层卷积提取浅层特征,后两条分支用3~5层卷积提取深层特征,最终通过Concat融合所有分支输出,生成语义信息更丰富的特征。核心思想是拓宽网络宽度、融合不同层次特征,同时可替代残差块,避免梯度爆炸问题。
② Parallel-Down-Block(并行下采样块) 针对小尺寸损伤漏检问题设计。传统最大池化下采样会导致小尺寸损伤特征丢失。该模块设计了两条并行路径:一条包含最大池化+1×1卷积,另一条包含步长为2的3×3卷积+1×1卷积,最终将两路特征在通道维度拼接,在保留小尺寸损伤特征的同时完成下采样。
③ CSPSPP(跨阶段部分空间金字塔池化) 结合SPP和CSPNet的思想设计,通过1×1、5×5、9×9、13×13四种不同尺寸的并行最大池化,使模型在特征提取过程中同时具备多种感受野,从而能够识别不同尺寸的损伤,有效应对损伤大小变化剧烈的挑战。同时CSP结构减少了梯度的重复计算,提升推理速度。
2.2 VDFNet-data(数据级融合)
在骨干网络入口处直接将视觉图像与深度图在通道维度拼接,使用单一骨干提取融合特征。结构最简单,参数量最少,推理速度最快(61.72 fps),但精度较低。
2.3 VDFNet-decision(决策级融合)
两路完全独立的网络分别处理视觉图像和深度图,最终通过非极大值抑制(NMS)融合两路检测结果。属于晚期融合,网络内部无特征交互,不适合视觉图像与深度图相关性强的本任务,精度介于VDFNet-data和VDFNet-feature之间。
创新三:基于SSNet的自动损伤测量方法
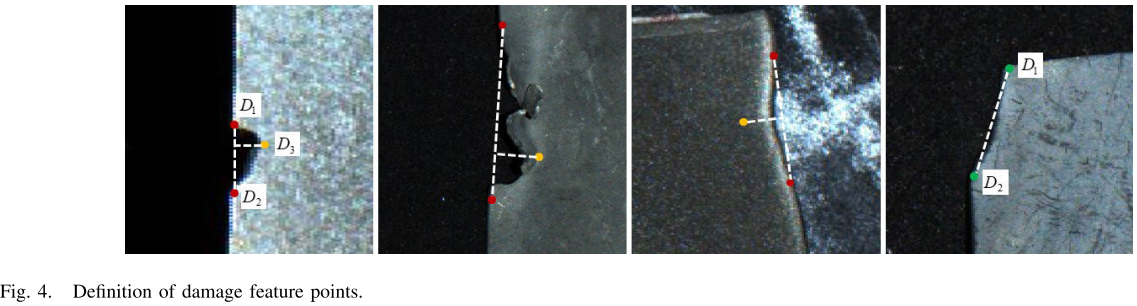
【此处配图:Fig. 4 损伤特征点定义示意图】
对于每种损伤类型,首先定义其特征点:
- 缺口、撕裂、弯曲:叶片边缘的两个端点(表征损伤长度)+ 叶片表面距边缘最远的点(表征损伤深度),共3个特征点
- 倒角:叶片边缘一点 + 叶片尖端一点(表征倒角对角线长度),共2个特征点
测量流程:
- 由第四节检测到的损伤区域作为输入
- SSNet提取特征点在图像中的位置(热图形式输出)
- 在深度图上获取特征点的三维坐标
- 根据三维坐标计算真实损伤尺寸(欧氏距离)
对于缺口/撕裂/弯曲,损伤长度 和深度
的计算公式为:
SSNet网络设计:

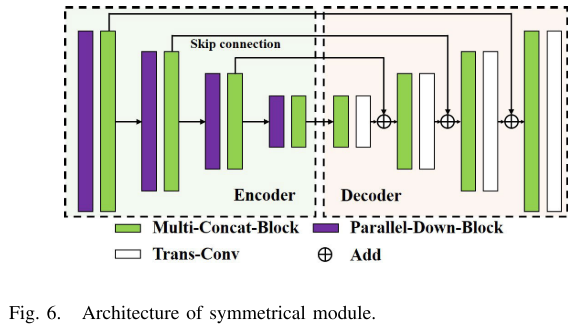
【此处配图:Fig. 5 SSNet整体架构图 | Fig. 6 对称模块结构图 | Fig. 7 转置卷积计算过程】
SSNet由8个对称模块 和9个步长为1的Conv-BN-SiLU构成。每个对称模块包含编码器(高分辨率→低分辨率)和解码器(低分辨率→高分辨率),形成类似U-Net的沙漏结构,并使用跳跃连接融合对称位置的特征图。模块中以Multi-Concat-Block为核心特征提取单元,使用Parallel-Down-Block下采样,使用转置卷积(Trans-Conv)上采样。网络输入为视觉图像与深度图的拼合,输出与输入等尺寸的热图,热图每个像素值代表该像素为损伤特征点的置信度。
三、实验结果:数据说话
实验配置
- 框架:PyTorch
- 硬件:单张 NVIDIA GeForce RTX 3090
- 操作系统:Ubuntu 20.04
- 训练轮数:1000 epochs
- 优化器:Adam,余弦退火学习率调度(初始 10\^{-2},最小 10\^{-4})
- 预训练权重来源:PASCAL VOC 2007 数据集
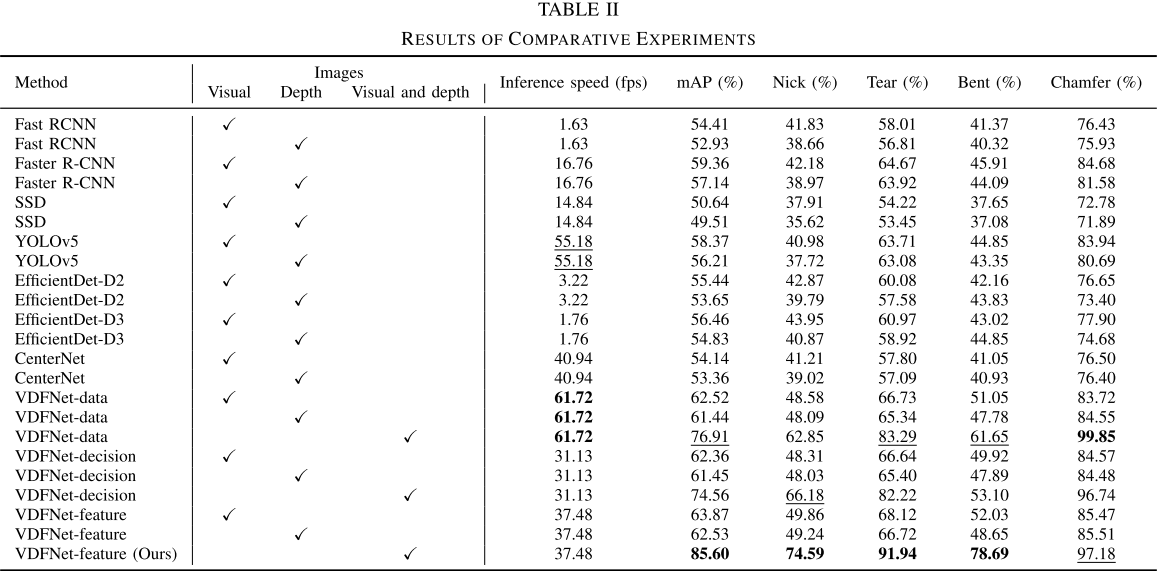
结果一:损伤检测对比实验
【此处配图:Table II 对比实验结果表】
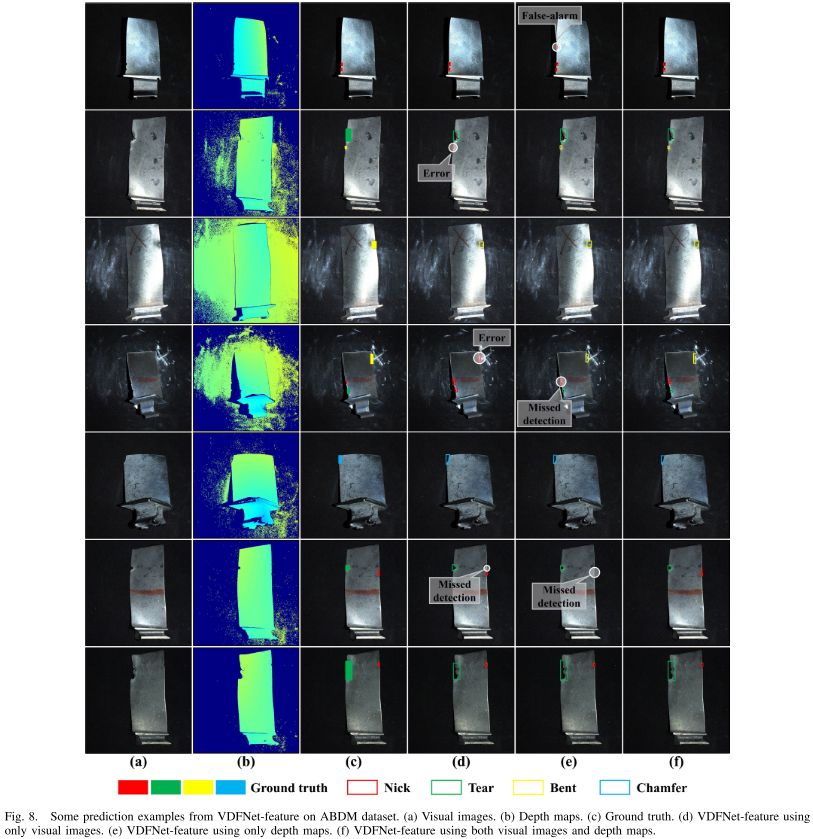
【此处配图:Fig. 8 VDFNet-feature预测结果可视化(含仅视觉、仅深度、融合三种对比)】
核心结论如下:
① 融合网络 vs. 通用检测网络:三种融合网络的mAP均远超Fast RCNN、Faster RCNN、SSD、YOLOv5、EfficientDet、CenterNet等通用目标检测网络,充分验证了专门为叶片损伤设计的网络的必要性。
② 三种融合策略对比:
| 方法 | 推理速度 (fps) | mAP (%) | Nick (%) | Tear (%) | Bent (%) | Chamfer (%) |
|---|---|---|---|---|---|---|
| VDFNet-data(视觉+深度) | 61.72 | 76.91 | 62.85 | 83.29 | 61.65 | 99.85 |
| VDFNet-decision(视觉+深度) | 31.13 | 74.56 | 66.18 | 82.22 | 53.10 | 96.74 |
| VDFNet-feature(视觉+深度) | 37.48 | 85.60 | 74.59 | 91.94 | 78.69 | 97.18 |
- VDFNet-feature综合性能最优,mAP达85.60%,推理速度37.48fps,满足实时检测要求
- VDFNet-data速度最快(61.72fps),但精度最低,因为两种模态特征被混合提取,相互干扰
- VDFNet-decision属于晚期融合,网络内无特征交互,不适合视觉图与深度图高度相关的本任务,精度最差
③ 单模态 vs. 双模态(以VDFNet-feature为例):
| 输入模式 | mAP (%) |
|---|---|
| 仅视觉图像 | 63.87 |
| 仅深度图 | 62.53 |
| 视觉+深度(本文方法) | 85.60 |
双模态融合比仅用视觉图像提升了约21.7个百分点,说明深度图提供的三维空间信息对损伤检测至关重要。

【此处配图:Fig. 9 不同模型的损伤特征热力图对比(说明本文模型注意力更集中于损伤区域)】
结果二:消融实验
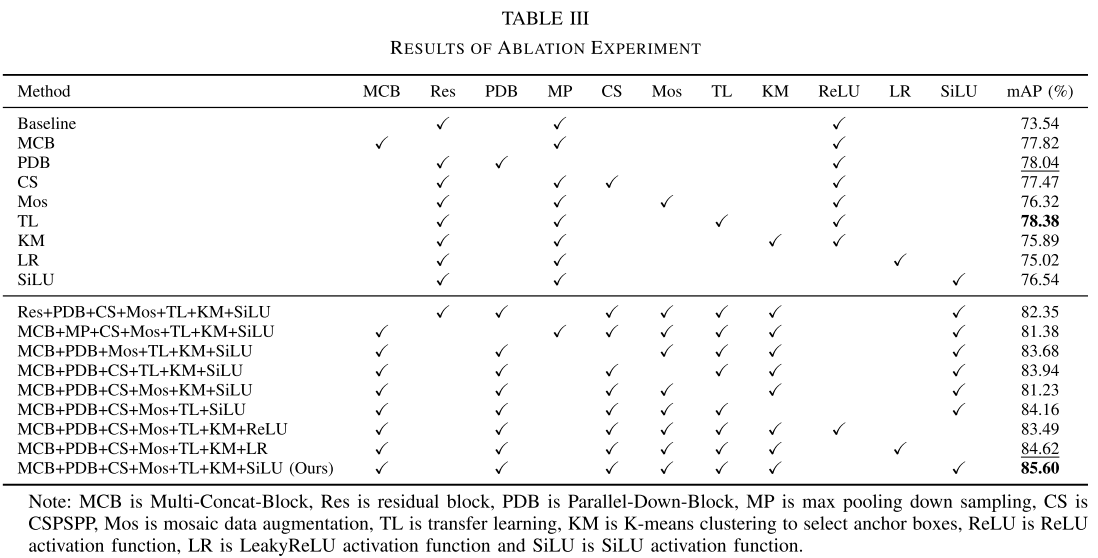
【此处配图:Table III 消融实验结果表】

【此处配图:Fig. 10 最大池化下采样 vs. Parallel-Down-Block检测结果对比(小损伤漏检问题)】
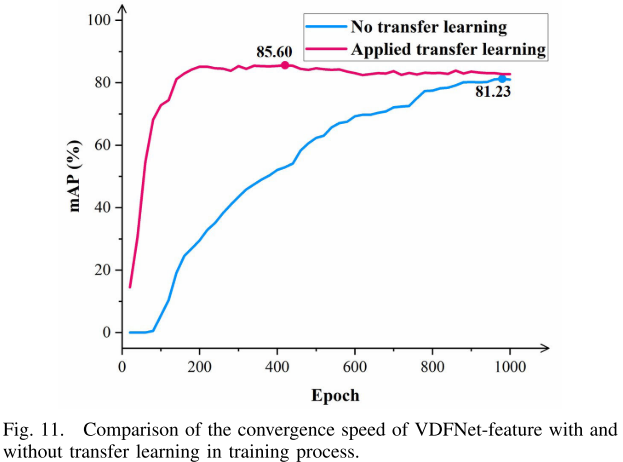
【此处配图:Fig. 11 使用/不使用迁移学习的收敛速度对比曲线】
| 组件/策略 | mAP提升 | 说明 |
|---|---|---|
| Multi-Concat-Block(vs.残差块) | +约4% | 多层次特征融合,提升特征提取能力 |
| Parallel-Down-Block(vs.最大池化) | +4.50% | 消融实验中提升最大,有效解决小损伤漏检 |
| CSPSPP(vs.SPP) | 有提升 | 多感受野,适应不同尺寸损伤 |
| 迁移学习 | +4.84% | 消融实验中提升最大的训练策略,同时将收敛从epoch 968缩短至epoch 404 |
| Mosaic数据增强 | 有提升 | 增加样本多样性 |
| K-means聚类选锚框 | 有提升 | 自适应锚框尺寸 |
| SiLU激活函数(vs. ReLU/LeakyReLU) | 有提升 | 平滑、非单调,信息流动更充分 |
| 完整方法(全部组件) | --- | mAP = 85.60% |
结果三:损伤测量实验

【此处配图:Fig. 12 SSNet测量结果可视化示例】
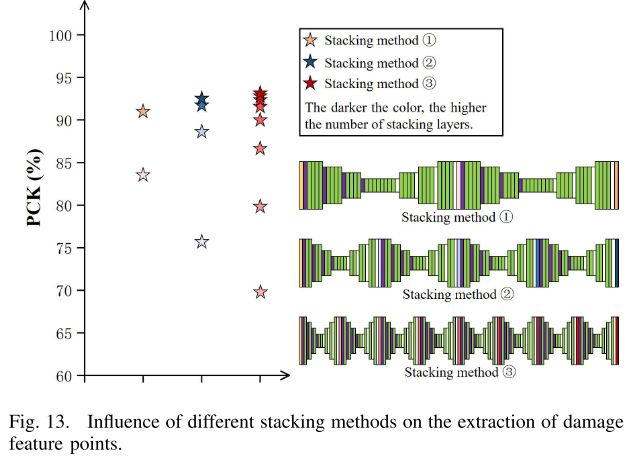
【此处配图:Fig. 13 不同堆叠方式对特征点提取效果的影响曲线】
| 方法 | 平均PCK (%) | 平均SE (mm) |
|---|---|---|
| 三次样条插值 | 83.12 | 0.47 |
| 曲线斜率拟合 | 85.96 | 0.35 |
| 本文方法(SSNet) | 93.28 | 0.12 |
注:三次样条插值和曲线斜率拟合均无法测量弯曲(Bent)类损伤。
本文方法在PCK上提升约7个百分点,SE缩小到竞争方法的1/3到1/4,且能统一处理四种损伤类型,鲁棒性与泛化能力显著优于传统方法。
各类损伤测量结果:
| 损伤类型 | PCK (%) | SE (mm) |
|---|---|---|
| Nick(缺口) | 95.22 | 0.10 |
| Tear(撕裂) | 91.46 | 0.13 |
| Bent(弯曲) | 89.29 | 0.17 |
| Chamfer(倒角) | 97.15 | 0.08 |
| 平均 | 93.28 | 0.12 |
值得注意的是,Bent类损伤的PCK(89.29%)相对较低,作者指出这是因为弯曲损伤特征不明显,即便是人工标注也难以精确定位特征点。
四、总结与意义
本文的工作可以归纳为三个层面的贡献:
方法层面:首次将视觉特征与三维空间特征融合用于发动机叶片损伤智能检测,突破了现有方法仅依赖二维视觉信息的局限。特征级融合(VDFNet-feature)被证明是三种融合策略中效果最好的,mAP达到85.60%。
工程层面:专门针对叶片损伤检测的挑战(昏暗环境、损伤尺寸变化大、小尺寸损伤)设计了三个定制化深度学习模块,显著提升了检测精度和小目标检测能力。同时提出的SSNet自动测量方法将测量误差控制在0.12mm以内,且可适用于四种不同类型损伤,解决了传统方法泛化性差的问题。
数据层面:构建了ABDM多模态数据集,包含2272对视觉-深度图像,将作为开源数据集供研究社区使用,有望推动该领域的研究发展。
从实际意义来看,本文的方法有潜力显著提升航空发动机维护检修的效率,减少对经验丰富专业人员的依赖,为实现发动机损伤的自动化、智能化检测维护提供了重要的技术基础。