
文章目录
- 引言
- [1. 理解"文件"](#1. 理解“文件”)
-
- [1.1 什么是文件](#1.1 什么是文件)
-
- [1.1.1 狭义文件](#1.1.1 狭义文件)
- [1.1.2 广义文件](#1.1.2 广义文件)
- [1.2 文件的本质](#1.2 文件的本质)
- [2. 回顾 C 文件接口](#2. 回顾 C 文件接口)
-
- [2.1 fopen 打开文件](#2.1 fopen 打开文件)
- [2.2 fwrite 写文件](#2.2 fwrite 写文件)
- [2.3 fread 读文件](#2.3 fread 读文件)
- [2.4 模拟 cat 命令](#2.4 模拟 cat 命令)
- [2.5 stdin、stdout、stderr](#2.5 stdin、stdout、stderr)
- [3. 系统文件 IO](#3. 系统文件 IO)
-
- [3.1 为什么需要系统调用](#3.1 为什么需要系统调用)
- [3.2 open 打开文件](#3.2 open 打开文件)
- [3.3 write 写文件](#3.3 write 写文件)
- [3.4 read 读文件](#3.4 read 读文件)
- [4. 文件描述符 fd](#4. 文件描述符 fd)
-
- [4.1 fd 到底是什么](#4.1 fd 到底是什么)
- [4.2 fd 的本质原理](#4.2 fd 的本质原理)
- [4.3 fd 分配规则](#4.3 fd 分配规则)
- [5. 重定向](#5. 重定向)
-
- [5.1 什么是重定向](#5.1 什么是重定向)
- [5.2 重定向本质](#5.2 重定向本质)
- 输出重定向原理图
- [5.3 dup2 实现重定向](#5.3 dup2 实现重定向)
- [5.4 dup2 示例详解](#5.4 dup2 示例详解)
- [6. shell 中的重定向](#6. shell 中的重定向)
-
- [6.1 识别重定向符号](#6.1 识别重定向符号)
- [6.2 为什么重定向放在子进程](#6.2 为什么重定向放在子进程)
- [7. Linux 下一切皆文件](#7. Linux 下一切皆文件)
-
- [7.1 为什么这么设计](#7.1 为什么这么设计)
- [7.2 file 结构体](#7.2 file 结构体)
- [8. 缓冲区](#8. 缓冲区)
- [9. 系统调用与库函数关系](#9. 系统调用与库函数关系)
- [10. 基础 IO 高频面试题](#10. 基础 IO 高频面试题)
-
- [10.1 为什么 printf 比 write 慢?](#10.1 为什么 printf 比 write 慢?)
- [10.2 为什么 stderr 默认无缓冲?](#10.2 为什么 stderr 默认无缓冲?)
- [10.3 dup2 本质是什么?](#10.3 dup2 本质是什么?)
- [10.4 Linux 为什么说一切皆文件?](#10.4 Linux 为什么说一切皆文件?)
- [10.5 为什么下面代码能够实现输出重定向?](#10.5 为什么下面代码能够实现输出重定向?)
- 结语
引言
最近在学习 Linux 基础 IO 的时候,我发现自己虽然会写:fopen(), read(), write(), printf()这些函数。
但很多东西其实一直都只是:会用,但不理解
比如:
- 文件描述符 fd 到底是什么?
- 为什么 stdout 是 1?
- 为什么 close(1) 之后 printf 会输出到文件?
- dup2 到底做了什么?
- Linux 为什么说"一切皆文件"?
- printf 和 write 到底有什么区别?
- 缓冲区为什么会影响输出?
刚开始学的时候,我甚至以为:
text
printf 就是直接打印到屏幕后来才发现:
text
printf 底层最终也是 write而 write 最终还会进入 Linux 内核。
越往后学越发现:
text
Linux 中很多看起来"理所当然"的东西
其实底层都特别巧妙。尤其是在学习:
- Shell
- 网络编程
- Socket
- Pipe
- epoll
- Redis
- Nginx
这些内容之后。
我越来越感觉:
IO 真的是 Linux 的核心。
所以这篇文章我想结合自己的学习过程,整理一下 Linux 基础 IO 中最重要的一些知识点,包括:
- C 文件接口
- 系统调用
- 文件描述符 fd
- 重定向
- dup2
- 缓冲区
- Linux 一切皆文件
- minishell 重定向实现
等等。
1. 理解"文件"
1.1 什么是文件
很多同学第一次接触文件时,会下意识认为:
文件 = txt、jpg、mp4
其实这只是 "狭义文件"。
Linux 对文件的理解远比这个更广。
- 文件在磁盘中
- 磁盘属于外设
- 对文件的操作本质是 IO
- Linux 下一切皆文件
也就是说:
text
文件 ≠ 只是普通文本
文件 = 操作系统对资源的一种抽象1.1.1 狭义文件
比如:
- hello.txt
- music.mp3
- movie.mp4
- code.cpp
这些都是存储在磁盘中的数据。
磁盘属于永久存储设备,因此:文件具有持久化特征
即使程序退出,文件仍然存在。
1.1.2 广义文件
Linux 中:
- 键盘
- 显示器
- 网卡
- 管道
- socket
- 进程信息
全部都可以被当作"文件"处理。
这也是 Linux 最经典的一句话:Linux 下一切皆文件
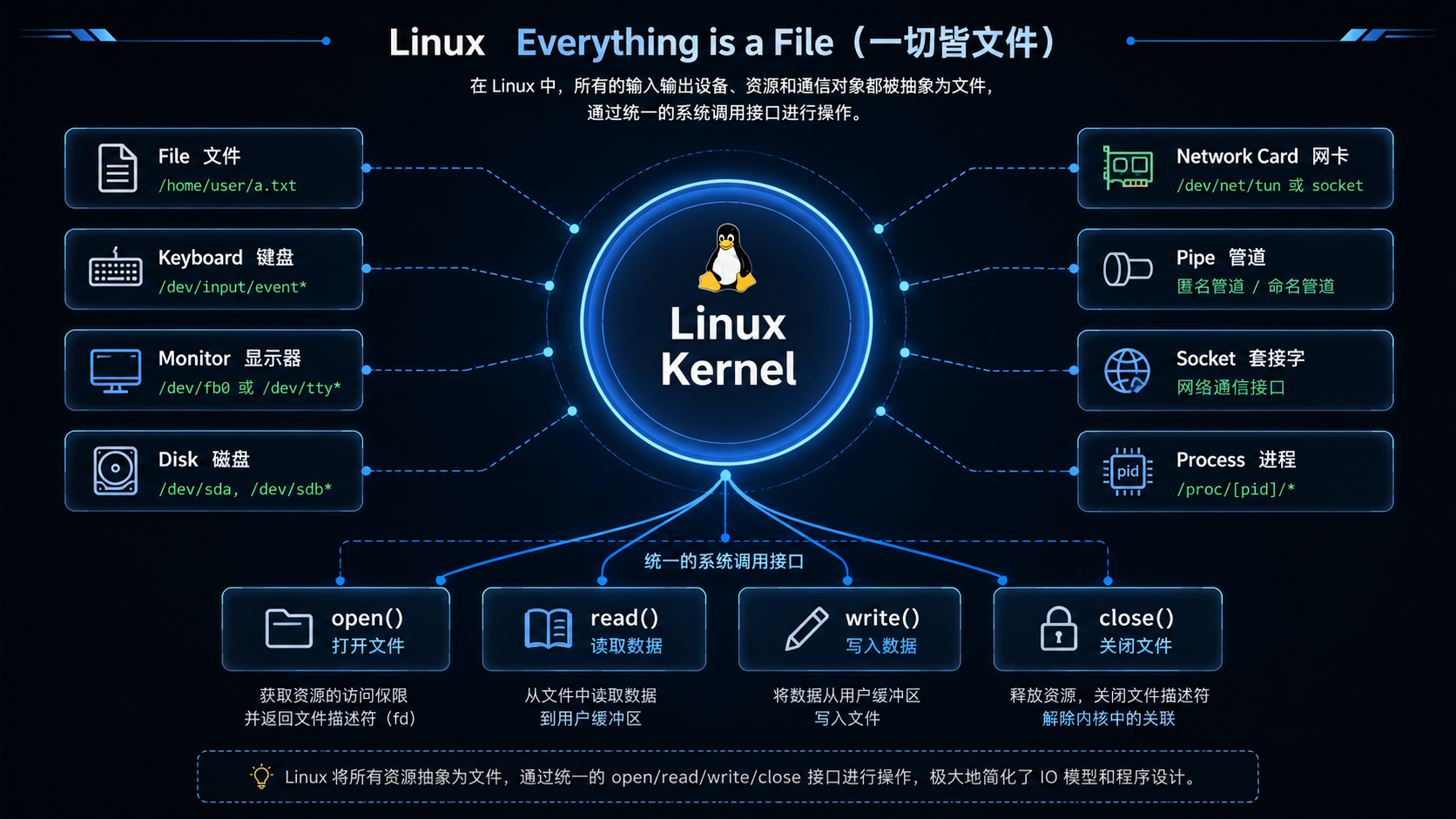
💡你可以把 Linux 理解成一个"超级统一接口系统"。
比如现实世界中:
- 遥控器控制电视
- 鼠标控制电脑
- 钥匙开门
- 方向盘控制汽车
每种设备操作方式都不一样。
但 Linux 非常聪明:
它把所有资源都抽象成"文件",于是开发者只需要掌握 read/write/open 这一套接口,就能操作绝大多数系统资源。
1.2 文件的本质
文件并不只是"内容"。
实际上:
文件 = 文件属性 + 文件内容
比如:
- 文件名
- 文件大小
- 创建时间
- 权限
- 所有者
这些都属于:元数据(metadata),而真正的数据才叫内容。
所以:
所有文件操作本质上都是:
- 对文件内容操作
- 对文件属性操作
2. 回顾 C 文件接口
2.1 fopen 打开文件
先来看最经典的栗子🌰:
cpp
#include <stdio.h>
int main()
{
FILE *fp = fopen("myfile", "w");
if(!fp){
printf("fopen error!\n");
}
while(1);
fclose(fp);
return 0;
}这里最关键的问题是:myfile 到底创建在哪?
答案是:当前进程工作目录
Linux 会通过:/proc/[pid]/cwd 找到当前运行路径。
例如:
bash
ls /proc/533463 -l你会看到:
text
cwd -> /home/hyb/io说明程序当前运行目录就在:
text
/home/hyb/io因此 myfile 就会被创建到这里。
2.2 fwrite 写文件
cpp
#include <stdio.h>
#include <string.h>
int main()
{
FILE *fp = fopen("myfile", "w");
if(!fp){
printf("fopen error!\n");
}
const char *msg = "hello bit!\n";
int count = 5;
while(count--){
fwrite(msg, strlen(msg), 1, fp);
}
fclose(fp);
return 0;
}这里:
cpp
fwrite(msg, strlen(msg), 1, fp);参数含义:
| 参数 | 含义 |
|---|---|
| msg | 写入内容地址 |
| strlen(msg) | 每次写入大小 |
| 1 | 写入次数 |
| fp | 文件流 |
2.3 fread 读文件
cpp
while(1){
ssize_t s = fread(buf, 1, strlen(msg), fp);
if(s > 0){
buf[s] = 0;
printf("%s", buf);
}
if(feof(fp)){
break;
}
}这里有一个经典坑点:
cpp
fread 返回值
不是 bool
而是实际读取字节数很多初学者会写成:
cpp
if(fread(...))但实际上应该根据返回字节数来判断。
2.4 模拟 cat 命令
PDF 中还实现了一个简单版 cat。
cpp
FILE *fp = fopen(argv[1], "r");然后不断读取:
cpp
fread(buf, 1, sizeof(buf), fp);再输出。
其实 Linux 的:
bash
cat file.txt底层逻辑也是类似的。
💡这就像你拿着一个水杯不断从桶里舀水,fread 每次读取一部分数据,然后 printf 再把它"倒"到显示器,一直循环直到 EOF(文件结束)。
2.5 stdin、stdout、stderr
Linux 默认会打开三个流:
cpp
extern FILE *stdin;
extern FILE *stdout;
extern FILE *stderr;对应:
| 名称 | 含义 |
|---|---|
| stdin | 标准输入 |
| stdout | 标准输出 |
| stderr | 标准错误 |
对应 fd:
| fd | 含义 |
|---|---|
| 0 | stdin |
| 1 | stdout |
| 2 | stderr |
这三个非常重要。
后面的:
- 重定向
- dup2
- shell
- 管道
全部围绕它们展开。
3. 系统文件 IO
3.1 为什么需要系统调用
很多同学会误以为:fopen 就是操作系统提供的,其实不是。
fopen/fread/fwrite 属于 C 标准库函数。
而真正底层的是:
open/read/write/close
这些系统调用。
关系如下:
text
fwrite
↓
write
↓
系统调用
↓
内核
↓
磁盘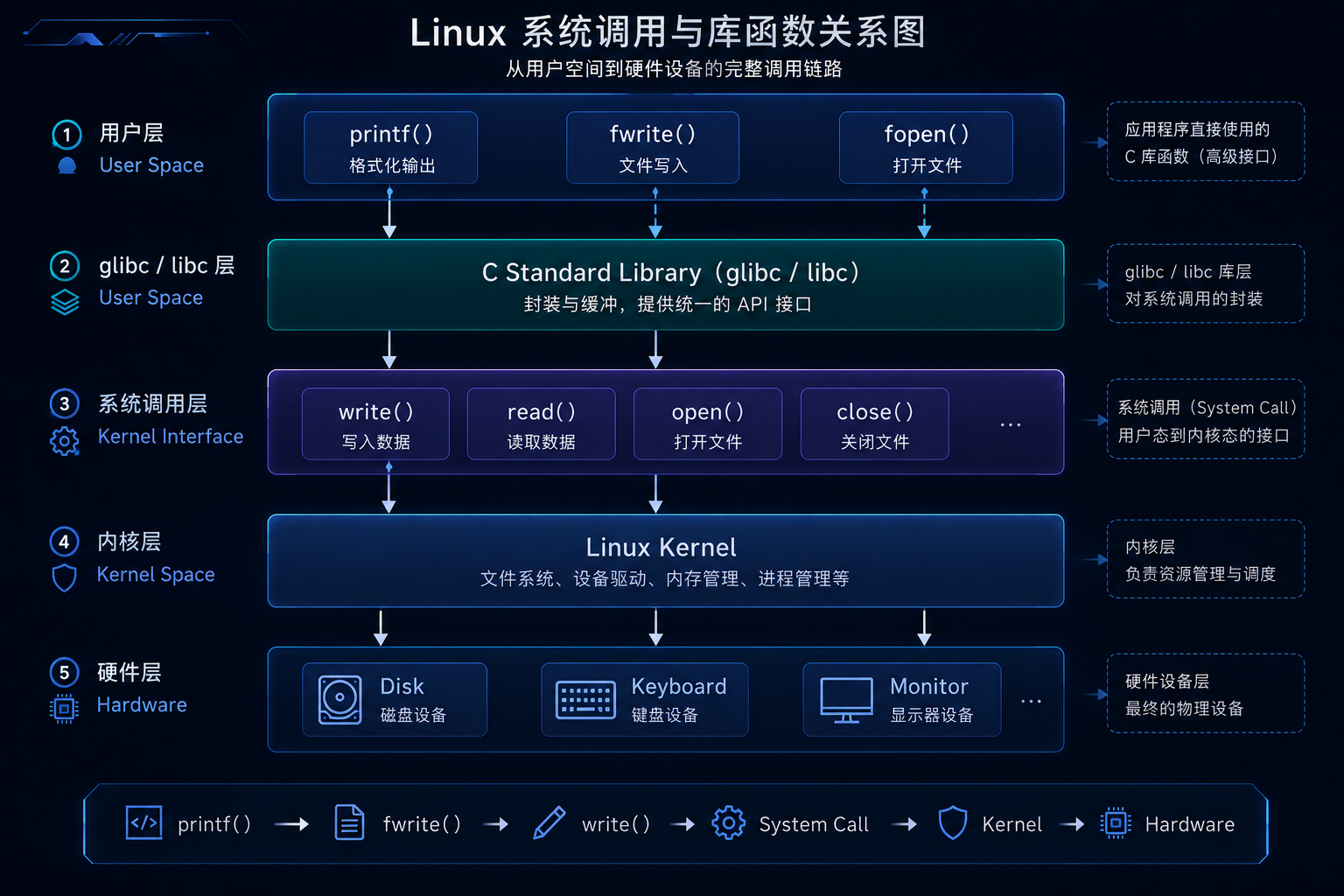
3.2 open 打开文件
cpp
int fd = open("myfile", O_WRONLY|O_CREAT, 0644);参数解析:
| 参数 | 含义 |
|---|---|
| myfile | 文件名 |
| O_WRONLY | 只写 |
| O_CREAT | 不存在则创建 |
| 0644 | 文件权限 |
这里 O_WRONLY | O_CREAT 采用的是:按位或组合标志位。
例如:
cpp
#define ONE 0001
#define TWO 0002
#define THREE 0004然后:
cpp
ONE | TWO即可同时表达多个状态。
3.3 write 写文件
cpp
write(fd, msg, len);参数:
| 参数 | 含义 |
|---|---|
| fd | 文件描述符 |
| msg | 数据地址 |
| len | 写入长度 |
返回值:实际写入字节数
注意:write 并不保证一次写完
这是高频面试点。
尤其网络编程中的短写问题特别重要。
3.4 read 读文件
cpp
ssize_t s = read(fd, buf, strlen(msg));和 write 类似:
| 参数 | 含义 |
|---|---|
| fd | 文件描述符 |
| buf | 缓冲区 |
| strlen(msg) | 读取长度 |
返回值:
| 返回值 | 含义 |
|---|---|
| >0 | 读取成功 |
| 0 | EOF |
| <0 | 出错 |
4. 文件描述符 fd
4.1 fd 到底是什么
文件描述符本质是一个小整数。
例如:
cpp
int fd = open("myfile", O_RDONLY);
printf("fd:%d\n", fd);输出:
text
fd:3为什么是 3?
因为:
text
0 -> stdin
1 -> stdout
2 -> stderr已经被占用了。
所以新的文件从3开始分配。
4.2 fd 的本质原理
Linux 内核中:
每个进程都有 files_struct,用来维护文件描述符表。
本质上fd 就是数组下标。
例如:
text
fd_table
0 -> stdin
1 -> stdout
2 -> stderr
3 -> myfilefd = 3就能找到对应文件。
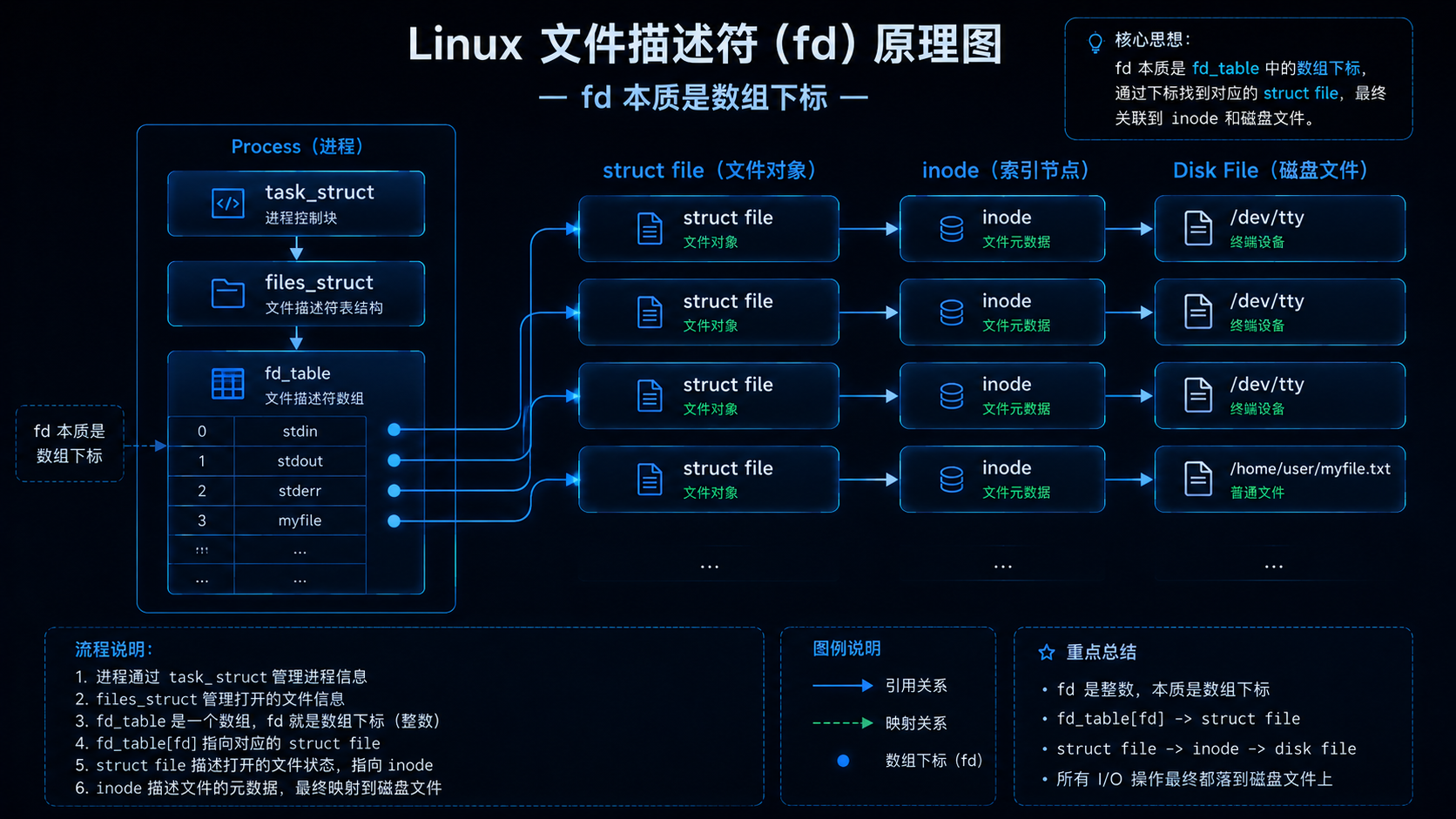
💡可以把 fd 理解成"酒店房间号",真正的房间不是数字,数字只是索引。
比如:
- 301 房间
- 302 房间
fd 就像房间号,内核通过 fd 找到真正的 file 结构体。
4.3 fd 分配规则
运行以下代码:
cpp
close(0);
int fd = open("myfile", O_RDONLY);结果:
text
fd = 0为什么?
因为 Linux 分配 fd 的规则是:寻找当前最小可用,即:谁空闲就分配谁。
5. 重定向
5.1 什么是重定向
例如:
bash
ls > log.txt这就叫输出重定向
原本输出到stdout(显示器),现在输出到文件
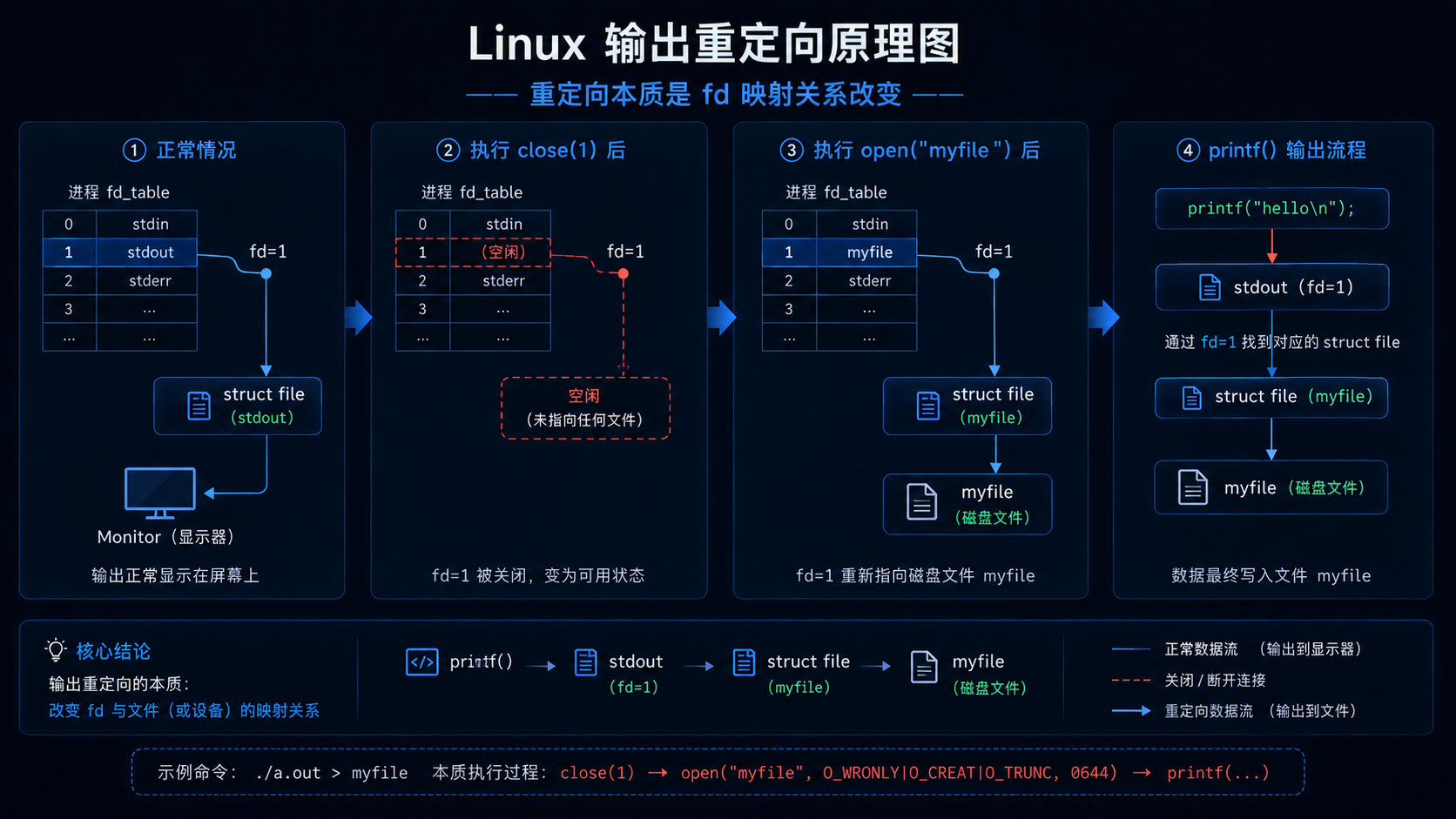
5.2 重定向本质
举一个经典栗子🌰:
cpp
close(1);
int fd = open("myfile", O_WRONLY|O_CREAT, 0644);
printf("hello\n");结果:
text
printf 内容写入文件为什么?
因为:
text
open 得到的 fd = 1于是:
text
stdout 被替换成了文件所以:
text
printf
↓
stdout
↓
fd=1
↓
myfile这就是重定向本质。
5.3 dup2 实现重定向
函数原型:
cpp
int dup2(int oldfd, int newfd);作用:让 newfd 指向 oldfd 对应文件
例如:
cpp
dup2(fd, 1);即:让 stdout 指向 fd 对应文件
于是 printf 全部写入文件。
5.4 dup2 示例详解
cpp
int fd = open("./log", O_CREAT | O_RDWR);
close(1);
dup2(fd, 1);流程:
text
1. 打开 log 文件
2. 得到 fd
3. 关闭 stdout
4. 让 1 指向 log于是:
text
printf → log完成输出重定向。
6. shell 中的重定向
PDF 中还实现了 minishell 的重定向功能。fileciteturn0file0
这一部分非常有含金量。
6.1 识别重定向符号
cpp
if(command_buffer[end] == '<')< 表示输入重定向 ,而 > 表示输出重定向 ,>> 表示追加重定向。
cpp
if(redir == InputRedir)
{
int fd = open(filename, O_RDONLY);
dup2(fd, 0);
}输入重定向:文件 → stdin
输出重定向:dup2(fd, 1);,即:stdout → 文件
追加模式:O_APPEND 即可。
6.2 为什么重定向放在子进程
重定向应该由子进程完成
为什么?
因为shell 自己不能被污染
如果父进程 shell 自己 stdout 被改掉,那么:整个终端都会失控.
所以:
text
fork 子进程
↓
子进程重定向
↓
exec 执行命令这才是正确流程。
💡这就像公司派员工出差,你不可能让老板永久搬去外地,应该让"子员工"去执行特殊任务,子进程就是那个临时员工。
7. Linux 下一切皆文件
7.1 为什么这么设计
Linux 最伟大的设计之一:统一 IO 接口
例如:resd(),write()
可以实现:
- 读文件
- 读键盘
- 读 socket
- 读 pipe
- 读设备
的全部统一,这极大降低了开发复杂度。
7.2 file 结构体
Linux 内核 file 结构的核心字段如下:
cpp
struct file {
struct inode *f_inode;
const struct file_operations *f_op;
unsigned int f_flags;
loff_t f_pos;
};重点:f_op,即:文件操作函数表
里面包含:read, write, open, mmap, ioctl 等函数指针。
其中,不同设备实现不同 read/write,但用户层统一调用 read/write,这就是 Linux 抽象哲学。

8. 缓冲区
8.1 什么是缓冲区
缓冲区是内存中的一块区域,用于临时缓存 IO 数据
例如:
text
磁盘 → 缓冲区 → 程序而不是:
text
磁盘 → 程序直接读取。
8.2 为什么需要缓冲区
因为:系统调用非常昂贵
涉及:
- 用户态
- 内核态
- 上下文切换
频繁调用会严重降低性能。
一次读大块数据,放入缓冲区,后续直接从内存读取,速度极快。
💡这就像去超市买矿泉水,你不可能每喝一口就跑一次超市。正确做法是一次买一箱,缓冲区就是这一整箱水。
8.3 三种缓冲区
一共有三种缓冲模式:全缓冲、行缓冲、无缓冲。
1)全缓冲
缓冲区满了才刷新,适合磁盘文件。
2)行缓冲
遇到 \n 才刷新,适合终端输出。
例如:
cpp
printf("hello\n");立刻显示。
3)无缓冲
直接系统调用
典型:stderr 因为错误信息必须立刻输出。
9. 系统调用与库函数关系
核心理解:库函数 ≠ 系统调用
而是:库函数 = 对系统调用的封装
例如:
text
printf
↓
fprintf
↓
fwrite
↓
write
↓
系统调用这也是为什么:printf 最终也会进入内核
10. 基础 IO 高频面试题
10.1 为什么 printf 比 write 慢?
text
printf 需要格式化,并且存在缓冲区,而write 更接近底层10.2 为什么 stderr 默认无缓冲?
text
因为错误信息必须立即显示,否则程序崩了,错误日志还没刷新,就会非常难排查。10.3 dup2 本质是什么?
text
修改文件描述符映射关系,而不是复制文件内容。10.4 Linux 为什么说一切皆文件?
text
因为Linux 使用统一 file 抽象,开发者只需要 read/write/open 即可操作绝大多数资源。10.5 为什么下面代码能够实现输出重定向?
cpp
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT, 0644);
printf("hello\n");答:
Linux 分配文件描述符时,总是分配当前最小可用 fd,由于 close(1) 关闭了 stdout,因此 open() 返回的 fd 为1,于是 stdout 被替换为 log.txt,而 printf 底层最终仍然使用 fd=1,因此输出进入文件。
结语
基础 IO 是 Linux 最核心的知识之一。
很多同学学习 Linux 时:
- 会写 fopen
- 会写 printf
- 会写 read/write
但并不真正理解:
- fd 是什么
- 文件如何管理
- 重定向如何实现
- dup2 为什么有效
- Linux 为什么"一切皆文件"
- 缓冲区为什么能提高性能
而这些,恰恰是:
- 操作系统
- Linux 后端
- 网络编程
- Redis/Nginx/MySQL
- 高性能服务器
的核心基础。
真正厉害的程序员,往往不是"API 记得多",而是:理解系统底层抽象.
当你真正理解:
text
文件描述符
↓
file结构
↓
系统调用
↓
file_operations
↓
驱动层这一整条链路时,就会发现:Linux 世界 suddenly clear.
后续再学习:
- epoll
- socket
- pipe
- mmap
- reactor
- nginx
- redis
都会轻松很多。
因为它们底层本质都是 IO。