论文总结
-
提出融合特征解耦与特权知识蒸馏的框架(Dis2DR)
针对多模态抑郁症识别中模态缺失或降质问题,设计了一个通用框架,同时利用特征解耦和特权知识蒸馏来提高识别鲁棒性。
-
设计不完全模态交互模块(IMI)
将多模态信号解耦为同质特征(FhoFho) 、异质特征(FheFhe) 和噪声特征(FnFn),并设计对应损失函数(如DLC损失、正交损失等)约束各特征表示,抑制噪声、增强信息聚合。
-
引入特权知识蒸馏
教师模型使用完整多模态数据训练,学生模型输入随机掩码的不完整数据;通过蒸馏损失将教师模型中IMI、ES、REC层的知识迁移给学生,提升学生在模态缺失情况下的性能。
-
采用编码器-解码器进行自监督预训练
利用大规模音视频数据集(VoxCeleb2)预训练Dis2DR的编码-解码结构,缓解抑郁症数据集规模小、模态不完整的问题。
-
多数据集实验验证
在AVEC 2013、2014、2017、2019以及CMDC数据集上评估,并与现有SOTA方法对比。实验表明:
-
特权知识蒸馏显著降低了对文本模态的依赖;
-
各解耦特征中,FheFhe 贡献最大,FhoFho 次之;
-
正交损失 LorthLorth 有效提升特征区分度;
-
单模态下性能仍优于现有多模态方法(如在AVEC 2013上比AVA-DepressNet提升高达9.8%)。
-
摘要
使用面部图像、音频信号或语言文本记录的抑郁识别(DR)已经取得了显著的性能。最近,通过利用来自这些模式的组合的信息,多模式DR已经显示出比单模式方法更好的性能。然而,收集包含所有医疗模式的高质量数据是一项挑战。具体地说,当某些模式丢失或降级时,这些方法经常遇到性能下降。为了解决这个问题,我们通过聚合特征解缠和特权知识提炼,提出了一个可推广的多模态DR框架。具体地说,我们的方法旨在在抑制噪声的同时,分离多模式信号中的同质和异质特征,从而自适应地聚集最具信息量的组件,以实现高质量的DR。随后,我们利用知识蒸馏将特权知识从完整的模式传输到信息有限的观察输入,从而显著提高容忍度和兼容性。这些策略形成了我们新颖的DR功能解缠和特权知识蒸馏网络,称为Dis2DR。在avec 2013、avec 2014、avec 2017和avec 2019数据集上的实验评估证明了我们的Dis2DR方法的有效性。值得注意的是,即使只有一种模式可用,Dis2DR也能实现卓越的性能,在avec 2013数据集上超过现有最先进的多模式灾难恢复方法AVA-DepressNet高达9.8%。
引言
随着从面部图像46、语音音频65和语言语义58获得的信号的出现,抑郁症识别(DR)已经取得了重大进展。从这些模式中提取的特征已经显示出与抑郁症有关。因此,最近的研究集中在利用多模式信号的组合来改善DR的性能。在多模式DR研究中,特别强调多模式融合,这已被证明在利用来自多个模式的互补信息而不是依赖单一模式方面是有效的34,36。这一发展使得非接触式抑郁症筛查成为可能,可以通过语音过程中带有面部视频记录和语音记录的多媒体文件来实现。然而,现实世界中DR的场景通常会带来以下挑战,这些挑战阻碍了多模式DR的进一步改进:i)通道退化。单个通道中的信息有时具有不同的质量。在某些情况下,某些内容可能会丢失。例如,眼睛跟踪数据可能会丢失,而其他特征保持不变。或者,内容可能会受到外部因素的影响,从而导致质量下降。例如,头部运动可能会破坏面部特征提取的准确性,而背景噪声会降低语音特征质量。这种干扰在输入信号中很常见,并且会固有地影响DR性能。Ii)情态不完整。多媒体信息经常存在通道不完备性问题,这可能是由于特征检测失败、面向帧外或无言瞬间而导致的,从而导致部分信息的存在。即使在数据收集和训练阶段,这种情况也可能发生,缺乏信息可能导致内容稀少,并在训练期间对模型的收敛产生不利影响。
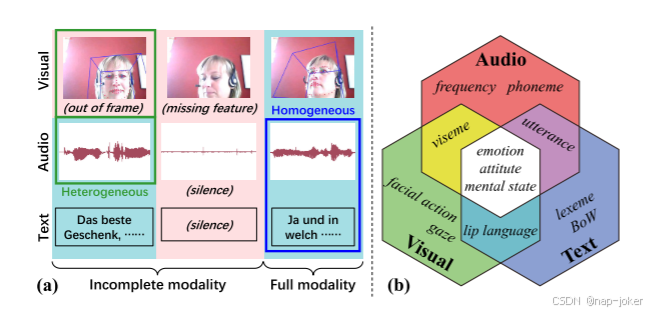
图1:(A)一个插图描述了使用不完整的多模式数据识别抑郁症的挑战。红色方块突出显示医疗设备中缺少的信息。(B)图示展示了以RGB原色表示的来自不同模式的不同内容。复合和白色代表来自组合模式的同质信息。
为了应对上述挑战,本研究引入了一种新的功能解缠和特权知识蒸馏网络DR(Dis2DR)。Dis2DR框架旨在通过有效平衡同质和异质多通道信息的利用来增强模型在不同通道之间的通用性。这种方法减少了模型对特定通道的依赖,并缓解了抑郁症识别期间通道退化的影响。在知识提炼过程中,教师模型利用完全输入作为特权知识,而学生模型则以部分输入和可学习的特权知识的完全分布为特征,从而使其能够在这样的环境中有效地学习。这种方法非常适合于解决灾难恢复设置中经常遇到的通道不完整问题。具体地说,这项工作包括以下部分:i)Dis2DR包含一个基本的解缠DR模型和用于解缠多模信息的相关约束,目的是从输入数据中分离与抑郁相关的多模同质和异质特征以及通道噪声。这种去纠缠过程增强了多模式特征的表示能力,同时减少了DR任务中不相关信息的干扰。随后,抑郁相关特征被投影到低维潜在空间,从那里预测抑郁严重程度分数。Ii)特征解缠的过程严重依赖于不同模式之间的相互依赖,如果某些模式降级,这可能会导致性能下降。Dis2DR解决这一问题的方法是,让教师模型在全通道输入下使用丰富的内容学习解缠,作为特权知识,然后将这些知识提取到学生模型,学生模型处理不完整的输入。这确保了在学习学生模型中与通道无关的表示的同时解开特征的表示,增强了通道之间的泛化表示,从而在输入通道降级或缺失的情况下产生了稳健的DR性能。Iii)实验表明,Dis2DR中的特征解缠增强了通道间抑郁相关内容的同质性,同时有效地分离了异质信息,这两者对DR都很重要。此外,利用特权知识蒸馏通过改进通道的泛化来提高DR的性能,特别是在涉及不完整通道的场景中,即使只有一个通道可用。
相关工作
抑郁症识别
在单通道输入的DR中,视觉信息通常包括面部动作单元、姿势和凝视48。面部图像67或视频帧35通常用于端到端识别。在音频分析中,基于声学特征的方法很流行32,通常与深度学习模型相结合37。对于文本输入,使用单词嵌入58或深度嵌入50来对语言特征进行预处理,其中语言特征直接反映情感倾向。对于多模式信号的DR方法通常需要组合多模式输入,利用各种手工制作的特征24,或通过深度学习模型提取的特征25。一些方法强调集成文本45和实质性融合处理62,63以实现最佳性能的重要性。然而,许多多模式方法严重依赖于人工制作的特征,往往忽略了特征检测中的潜在故障,例如面部运动模糊或语音中的无声部分。当某些内容或方式缺失时,这些疏忽可能会严重影响DR的有效性。此外,随后的研究未能探索不同通道之间的相互作用,限制了该模型对通道信息的综合利用。
特征解耦
如先前的研究6所强调的,分离表征学习的目的是约束特征以分离数据中的独立因素。设计良好的分离表示与数据的语义结构相一致。在人脸识别中,典型的解开因素包括身份、姿势和情感信息30,47。在多通道情绪识别任务中,多通道特征的分离已经被使用像图蒸馏这样的技术来探索29。通常,通道信息被分离成通道不变和通道特定的子空间60。然而,所采用的具体解缠策略因手头任务的属性而有很大差异。在DR的背景下,我们的研究首次提出了一个专为抑郁症量身定做的无纠缠表征框架。该框架同时考虑了同质性和异质性抑郁症相关的多模式特征,标志着对该领域的新贡献。
不完整多模态学习
不完全多模式学习是多模式机器学习中的一个关键研究领域,它解决了某些模式退化的场景,这在现实世界中是一个常见的问题。虽然一种有效的策略涉及识别由所有模态共享的低维子空间、最大化它们的相关性2,22,这种方法可能会忽视不同模式的互补性,有可能导致不太理想的结果。取而代之的是,更有希望的方法是使用可用的模式明确地恢复丢失的模式。例如,深度模型10,53或具有周期一致性损失的跨通道恢复策略39,可用于此目的。然而,这些方法中的许多方法需要大量的全通道数据,这在DR数据集中往往是缺乏的,因为它们的大小有限且存在缺失的通道。一些方法涉及利用特权信息进行学习的主要和补充方式3、7、20,但随后的方法侧重于将整个方式视为特权信息,要求在教师模型培训期间高度提供所需的方式。在DR的情况下,即使在训练数据中,模式也可能是不完整的,这对使用特权信息的学习的有效利用构成了挑战。我们的目标是探索特权信息在DR任务的不完全模式中的应用,标志着对该领域的新贡献。
所提出的方法
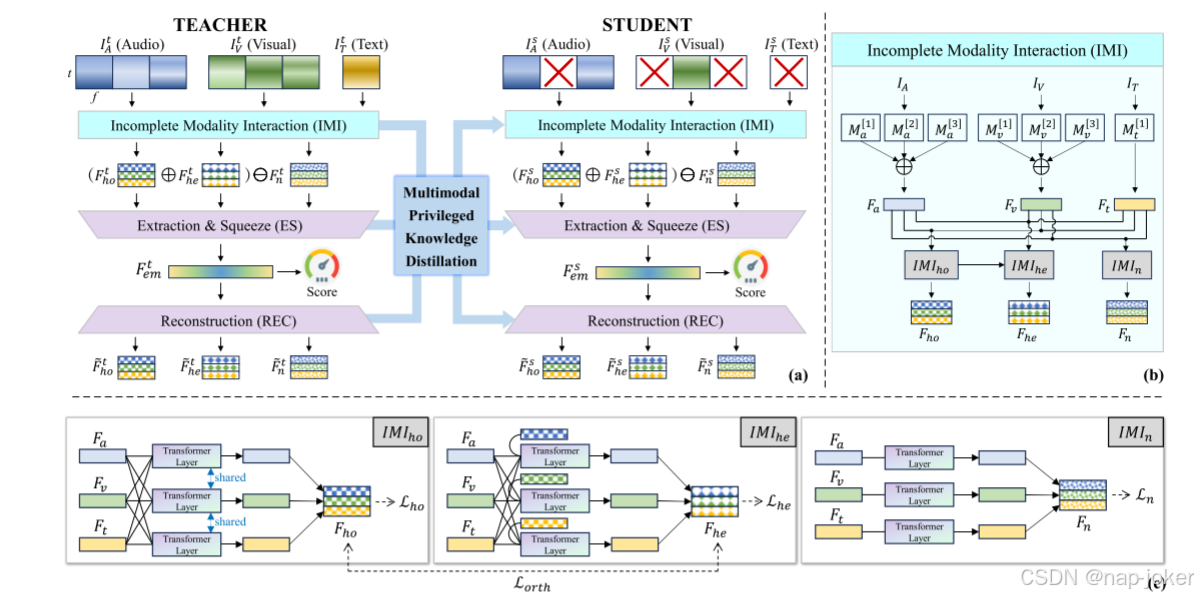
图2:Dis2DR的整体架构。(A)教师和学生模式之间的多模式特权知识升华过程。在推理过程中,学生模型仅使用部分输入。(B)IMI模型的插图。(C)特征解缠IMI子模块的流水线。
DIS2DR的总体结构如图2(A)所示,它由从事多通道特权知识提炼的教师模型和学生模型组成。在教师模型中,输入由不完全通道交互(IMI)模块进行处理,负责解开纠缠。通过该过程,通过跨通道交互并实施由设计的损失函数施加的约束来获得同质、异类和噪声多通道表示。随后,通过包括提取和压缩(ES)层和重建(REC)层的编解码器结构对表示进行压缩和重建。然后利用潜在嵌入𝐹𝑒𝑚来导出DR分数。利用编码器-解码器结构促进了使用大型多模式数据集的Dis2DR的自我监督预训练,从而减轻了小型DR数据集进行深度学习的挑战。学生模型采用与教师模型相同的体系结构,目标是最小化差异并使两个模型之间的知识保持一致。这种对齐促进了从教师到学生的无缝知识转移。随后,教师和学生模型进行多通道特权知识蒸馏,确保信息的有效传递。然后,学生模型继续学习不完整模式下的解缠表示,从而提高了模式信息的泛化。为了使学生能够从丢失或退化的多模式数据中学习,我们仔细地准备了反馈到教师网络和学生网络的数据。教师网络在数据方面进行了培训,这些数据具有更全面的多模式特征,代表特权知识。同时,学生网络暴露在信息较少的数据中,模拟真实的不完全多模式输入,并受益于教师模型提供的监督。此设置使学生能够有效地适应医疗设备缺失或降级的情况。
教师模型结构
Dis2DR中DR模型的输入由音频、视频和文本数据组成。具体地说,𝐼𝑡𝐴,𝐼𝑡𝑉,𝐼𝑡𝑇分别表示来自音频、视觉和文本的教师模型输入。同样,𝐼𝑠表示来自每种通道的学生模型输入。为了训练基本的DR模型,需要计算以下部分的损失函数:1)DR预测L𝑠的地面真实抑郁得分与预测的误差;2)潜在嵌入的损失函数L𝑣𝑎𝑒;3)特征解缠过程中IMI L𝐼𝑀𝐼的损失。在下文中,详细介绍了每种损失函数。对于L𝑠,计算地面真实标签𝑦与来自ˆ𝑦样本的预测分数𝑁之间的平均绝对误差(MAE)和均方根误差(RMSE)之和,作为DR的目标:

不完整的通道交互
在这种情况下,𝐼𝐴∈R𝑡,𝑓𝑎由几个总维度为𝑓𝑎的音频特征集组成,这些特征沿特征轴合并。这同样适用于𝐼𝑉,而𝐼𝑇仅包括作为唯一功能集的文本嵌入。IMI首先使用𝑀𝑎,𝑀𝑣和𝑀𝑡提取并标准化输入的时间序列,表示对应的特征提取层。对于𝑀𝑎和𝑀𝑣,它们具有表示为𝑀[𝑖的子层,用于处理来自通道的第𝑖个特征集,然后聚集累积结果。多峰特征可以用三个IMI子模块来处理,以分离同质分量𝐹ℎ𝑜、异质信息𝐹ℎ𝑒和噪声对应的𝐹𝑛。相应的IMI子模块分别表示为𝐼𝑀𝐼ℎ𝑜,𝐼𝑀𝐼ℎ𝑒,𝐼𝑀𝐼𝑛。为便于理解,图2(B)、(C)中示出了IMI的说明。在IMI子模块中,使用Transformer块进行特征提取。在𝐼𝑀𝐼ℎ𝑜中,所有医疗设备都使用相同的变压器。每个通道贡献其主要表示和通道令牌(使用第一时间维度)以生成多通道特征𝐹ℎ𝑜。在𝐼𝑀𝐼ℎ𝑒中,每个转换器不仅接收主要的多通道表示,还接收特定于该通道的相应𝐹ℎ𝑜。𝐼𝑀𝐼𝑛模块接收单模信息,并由相应的变压器进行预测。选择并连接𝐹ℎ𝑜,𝐹ℎ𝑒和𝐹𝑛的通道令牌,如图2(C)所示。为了约束𝐹ℎ𝑜,𝐹ℎ𝑒,𝐹𝑛,设计了具体的损耗函数。首先,我们提出了抑郁水平对比(DLC)损失,旨在确保相同抑郁水平内的一致性表征和不同水平上的不同表征。这是通过最小化相似抑郁水平的相似性和最大化每个样本中不同水平的相似性来实现的。𝑁样品之间的DLC损耗公式如下:
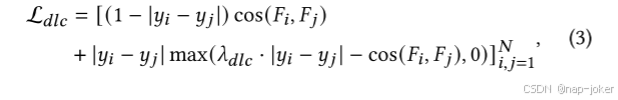
其中𝑦表示样本对应的归一化标签,𝑐𝑜𝑠(·)表示余弦相似度。边际𝜆𝑑𝑙𝑐设置为30。对于𝐹ℎ𝑜,目标是确保多通道功能包含同类信息。这需要每个样本具有反映抑郁症状的个体同质性的表示,这通过在具有样本间约束的情况下最小化来自同一样本的特征中的模式之间的相似性来实现。损失函数Lℎ𝑜将这一目标与DLC损失结合起来,公式如下:
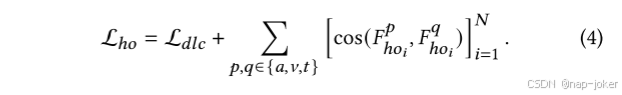
同样,𝐹ℎ𝑒应该包含抑郁症样本中不同模式之间的不同表示,突出不同模式之间的多样化信息,以表征患有抑郁症的个体。目标是从一个样本中最大化多模式特征的相似性。损失函数Lℎ𝑒可表示为:

多模态特权知识提炼
我们利用全通道信息学习的教师模型为不完全信息学习的学生模型提供特权知识。与直接微调不完全情态的教师相比,在不完全输入的情况下,对学生的蒸馏可以在学生培训过程中提供稳定、高精度的监督,防止模型被遗忘。我们选择提取模型的关键部分,包括IMI、ES和REC层。我们设计了以下损失函数来根据教师的DR表现来提取特权知识。教师模型对特定样本的误差越小,向学生提取相应知识的温度就越高。对于每一层,蒸馏函数表示为:

实验
数据集
在我们的实验中,我们使用了以下数据集:
**AVEC 201355:**在此数据集中,有150个视频片段,包含82个不同的参与者,专门为我们的研究工作的验证和测试阶段指定。
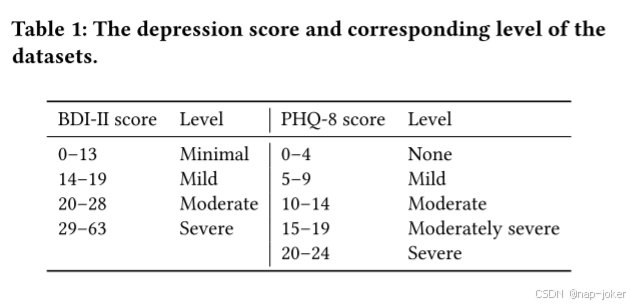
**Avec 201454:**由来自83名参与者的300个视频片段组成,avec 2013和avec 2014都捕捉了人机环境中的交互。这些评级使用Beck Depression Inventory-II(BDI)5进行评估,范围从0到63。根据官方划分,利用这些数据集中的视频进行训练、验证和测试。
AVEC 201744:在AVEC 2017,涉及来自不同个人的189个样本的收集。每个人的抑郁严重程度是基于自我报告的PHQ-8得分28来衡量的。视频帧被分解为各种特征,包括行动单位(AU)和面部地标。同时,以16 kHz的采样率捕获音频记录,avec 2017数据集包括提取的音频特征,如共振峰和基频(F0)。同时,记录每个人的对话记录。
AVEC 201943 :AVEC 2019是AVEC 2017的扩展,包含275个实例的样本大小。值得注意的是,面部标志性特征被省略,而VGG和DenseNet等新的深度特征被纳入avec 2019数据集中。**CMDC68:**该数据集包括来自健康个体的52个样本和来自抑郁症患者的26个样本。它包括文字记录、语音音频文件,在某些情况下,还包括面部视觉特征的记录。
**VoxCeleb29:**VoxCeleb2数据集是一个大规模的说话人识别数据集,包含6112位名人的100多万个话语。这些话语是从上传到YouTube的视频中提取出来的。该数据集为预培训奠定了坚实的基础。在我们的研究中,我们专注于从这个数据集中提取面部和音频特征,以便对Dis2DR进行预训练。
我们将上述所有数据集用于模型训练,而avec数据集用于我们的评估和最终测试。AVEC 2013和AVEC 2014标有BDI-II,而AVEC 2017和AVEC 2019标有PHQ-8。相应的标准分数和抑郁程度列在选项卡中。1.最初使用VoxCeleb2对编解码器进行视听任务的训练。随后,我们使用CMDC和AVEC数据集的所有训练集的联合集合,基于它们对应的问卷回答将标签归一化到0-1的范围。由于AVEC数据集提供了官方开发和测试集,所有消融研究都在其相应的开发集上进行,而与最先进方法的比较则在测试集上进行。
预处理
对于所有数据集,音频、视觉和文本数据都经过了预处理和标准化,以便输入到Dis2DR中。具体地说,使用的标准视觉特征包括定向梯度直方图(HOG)特征(如果可用)、头部姿势、凝视、AuS和具有68个点的面部地标。地标将根据中心鼻尖对齐,并沿轴范围调整到256的统一大小。所有特征由Open Face4从面部图像中提取,或者从数据集中提供的数据中重新组织。对于音频通道,提取了三组特征,包括COVAREP15特征集,以及OpenSmile17提取的Mel频率倒谱系数(MFCC)和eGeMAPS特征集。对于文本通道,从抄本中提取BERT16嵌入作为Dis2DR文本通道输入。对于avec 2013和avec 2014,首先使用多语言Whisper41从原始音频中提取说话人的文字记录,然后使用德语BERT1提取嵌入内容。对于avec 2017和avec 2019,使用的是英式BERT模型2。对于CMDC,采用中国BERT模型3。
实验配置
在我们的实验中,首先在VoxCeleb2上对教师模型进行预训练,以学习视听特征表示。在此步骤中,损失函数为

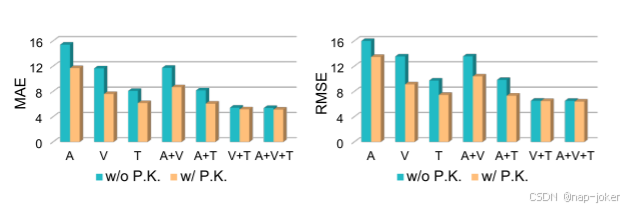
图3:使用音频(A)、视觉(V)、文本(T)及其组合作为Dis2DR w/o和w/Priviled Knowledge的输入通道的DR性能(P.K.)如图所示。性能指标在AVEC 2014数据集的开发集上进行了报告。
 继续使在Dis2DR的特权知识提炼过程中,学生模型的输入在时间轴上以随机的位置和长度被随机掩蔽。教师模式用完整的数据作为输入,可以作为学生的特权知识提供者。所有训练在2个RTX3090 GPU上使用ADAM优化器进行,学习率为0.0002,批次大小为16。输入的时间长度设置为600帧,从原始训练信号中随机采样。为了解决音频和视频信号之间的时间采样率不一致的问题,我们对片段进行了重新采样。文本嵌入利用来自样本的完整嵌入作为文本输入。在测试过程中,样本沿时间长度被分为10个大小均匀的片段,每个片段包含600个帧。这10个片段的平均得分被用作模型的预测。
继续使在Dis2DR的特权知识提炼过程中,学生模型的输入在时间轴上以随机的位置和长度被随机掩蔽。教师模式用完整的数据作为输入,可以作为学生的特权知识提供者。所有训练在2个RTX3090 GPU上使用ADAM优化器进行,学习率为0.0002,批次大小为16。输入的时间长度设置为600帧,从原始训练信号中随机采样。为了解决音频和视频信号之间的时间采样率不一致的问题,我们对片段进行了重新采样。文本嵌入利用来自样本的完整嵌入作为文本输入。在测试过程中,样本沿时间长度被分为10个大小均匀的片段,每个片段包含600个帧。这10个片段的平均得分被用作模型的预测。
特权知识蒸馏分析
我们比较了学生模型在知识提取前后的直接识别性能,体现了Dis2DR对不完全情态识别的特权知识的存在和缺失,强调了特权知识提取的必要性。比较结果如图3所示。结果表明,当不利用特权知识时,不完全通道DR的性能显著下降。与没有特权知识的模型相比,具有特权知识的模型始终显示较低的DR错误,如黄色条(具有特权知识)显示的错误低于青色条(没有特权知识)所示。此外,图3比较了使用和不使用文本通道(T、A+T、V+T、A+V+T与A、V、A+V)的结果,说明性能下降主要与不使用文本通道有关。特别是,当文本通道缺失时,下降更加明显,随后当视觉通道缺失时,性能显著下降。经过特权知识提炼后,DR对特征的依赖程度的不平衡程度有所降低。某些模式的缺失不会像在没有特殊知识的情况下观察到的那样显著地导致性能下降。这强调了知识提炼在不完全情态情景中的关键作用。它减轻了对跨医疗设备功能的严重依赖,即使在某些医疗设备降级或丢失的情况下也能确保高可用性。
解缠特征的分析
在Dis2DR中训练的学生模型用各种类型的输入进行测试,以使用t-SNE进行分析,以检查不同模式对特征的影响。如图4所示,具有不同输入的𝐹ℎ𝑜,𝐹ℎ𝑒,𝐹𝑛,𝐹𝑒𝑚成行显示。每一列对应于特定的输入模式。从结果可以推断出以下趋势:i)视觉和文字模式被认为更关键,大大有助于提高绩效。𝐹ℎ𝑜的聚类分析表明,文本通道的缺失对聚类有很大的负面影响,其次是视觉通道的影响。此外,根据t-SNE结果,特别是在仅音频形态可用的情况下,音频和文本形态表现出高度纠缠。这表明,在没有文本通道的情况下,𝐹ℎ𝑜捕获的特征可以被现有的音频通道"隐含"。Ii)𝐹ℎ𝑜可以学习不同模式之间的相同表征,表现出与抑郁程度相关的明显趋势。在𝐹ℎ𝑜的多模式情况下(图4的第一行),抑郁程度较高的样本在各模式之间形成紧密且紧密的聚集组,而轻度抑郁的样本表现出更多样化的表现,导致每种模式之间的差异。Iii)𝐹ℎ𝑒在表示不同医疗模式之间的异质信息方面一直表现良好。即使没有通道,模型仍然"记住"该特性并提供该通道的适当表示。Iv)即使在某些模式缺失的情况下,𝐹𝑛也始终表现出强烈的聚集性和清晰的边界。这表明噪声特征表示通道内的相干信息,并且在不同样本之间保持独立。V)𝐹𝑒𝑚在抑郁程度低和程度高的样本之间呈现出明显的趋势。抑郁程度较高的样本形成清晰而紧密的簇,而程度较低的样本往往表现出更分散的簇。当投入方式增加时,这一趋势尤为明显。
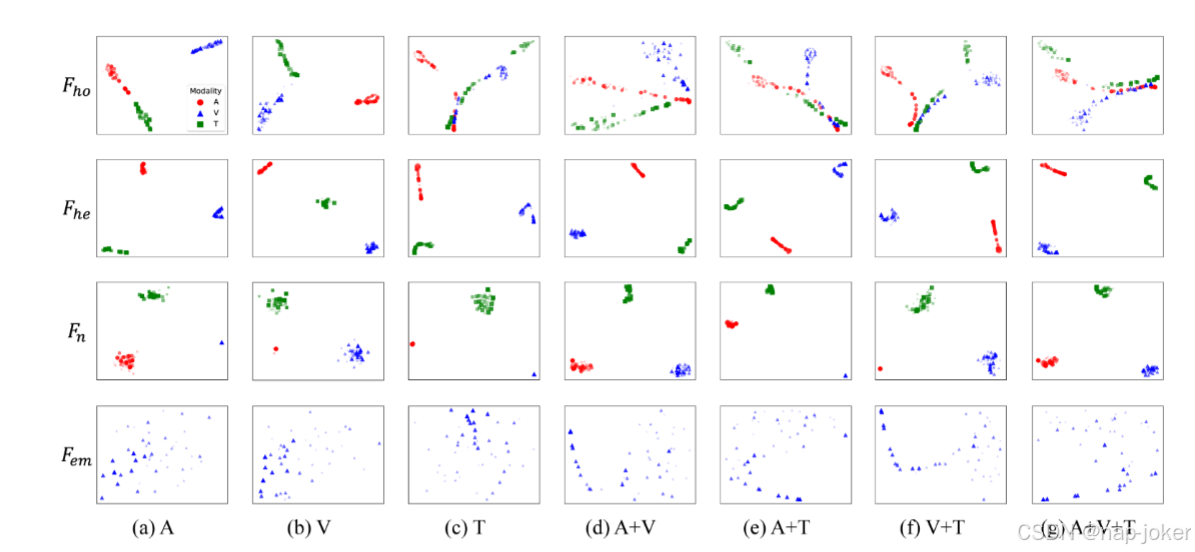
图4:t-SNE分析显示了AVEC 2017年的未纠缠多式联运功能。每一栏都提供了可视化结果,并提供了可作为输入的所注明的模式。颜色越厚的圆点越大,表示相应样本的抑郁分数越高。
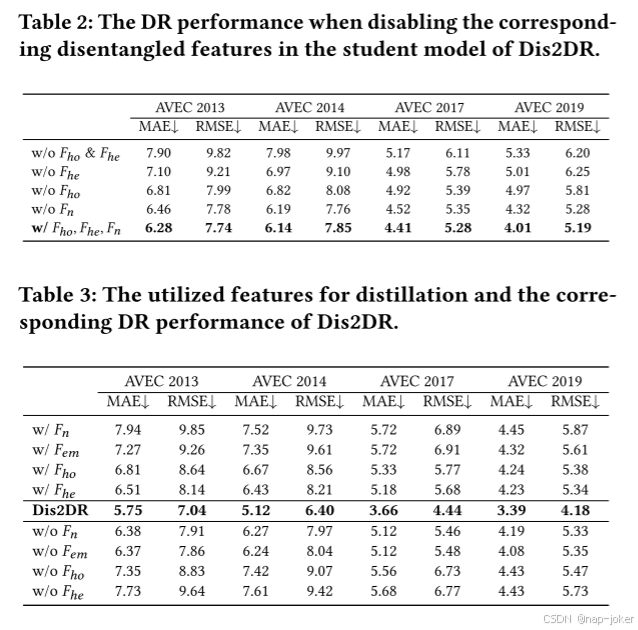
此外,我们进行了一项定量研究,以评估解缠特征对DR性能的影响。为了检查IMI中的特征不起作用时的影响,我们在训练期间禁用了相应的损失函数计算,允许特征失去其约束并降级为正常特征。结果列在选项卡中。2表明𝐹ℎ𝑒的贡献最大,其次是𝐹ℎ𝑜。此外,如果𝐹ℎ𝑜和𝐹ℎ𝑒都不可用,则会导致最显著的性能下降。
蒸馏过程的特征分析
为了评估特权知识蒸馏对Dis2DR中解缠特征的有效性,我们在训练期间进行了实验来提取或禁用这些特征的蒸馏。性能结果显示在选项卡中。3.上面的行表示Dis2DR,只提取列出的对应特征,而下面的行表示列出的相应特征在蒸馏过程中被移除。显然,蒸馏𝐹ℎ𝑒对性能的影响最大,其次是𝐹ℎ𝑜。具体地说,仅对𝐹ℎ𝑒进行蒸馏会显著提高性能,而不对𝐹ℎ𝑒进行蒸馏会导致性能显著下降。𝐹ℎ𝑜也有类似的趋势,但与𝐹ℎ𝑒相比影响较小。相比之下,对𝐹𝑛和𝐹𝑒𝑚进行蒸馏对性能的影响较小。这一结论与在Tab中观察到的趋势一致。2.这一趋势还解决了我们是否可以直接微调Dr的教师模型的问题。随着网络的精炼组成减少,代表着特权知识的减少,培训过程倾向于对不完整的模态数据进行微调。显然,与Dis2DR方法相比,DR的性能有所下降,进一步强调了特权知识提炼的重要性。
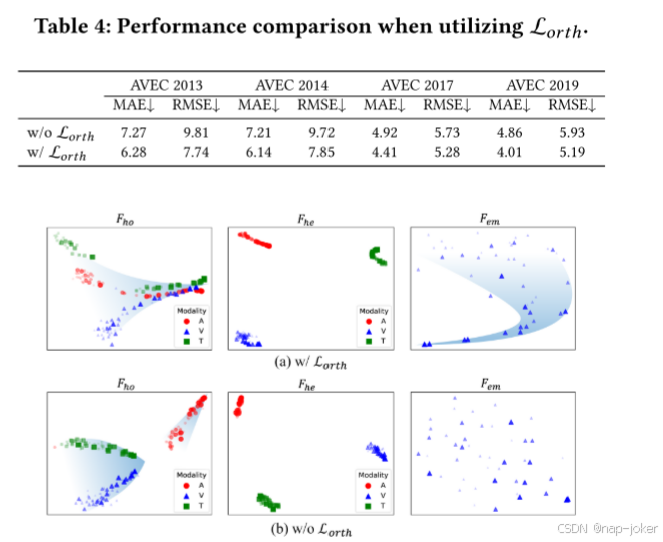
图5:采用正交性损失L𝑜𝑟𝑡ℎ对AVEC2017年的特征进行t-SNE分析。在可视化中,颜色越厚的点越大,代表相应样本的抑郁得分越高。此外,我们还使用蓝色渐变来说明特征点的聚集趋势。
特征的正交性分析
在设计𝐹ℎ𝑜和𝐹ℎ𝑒时,我们利用L𝑜𝑟𝑡ℎ来最大限度地区分这两个功能之间的信息表示。我们发现,执行L𝑜𝑟𝑡ℎ有助于提高绩效,如选项卡所示。4.此外,我们使用t-SNE检查涉及的特征,如图5所示。显然,尽管𝐹ℎ𝑜和𝐹ℎ𝑒受到对比损失Lℎ𝑜和Lℎ𝑒的约束,缺乏正交约束导致特征之间的次优区分(如第一行中的聚类所示)。如果没有L,𝑜𝑟𝑡ℎ,𝐹ℎ𝑜展示了许多不同的表示,这些表示应该描述的是同质信息,而不是异质,这从分为不同组的集群中得到了证明。此外,𝐹𝑒𝑚没有很好地聚集在一起,并且显示出与抑郁水平的弱相关性,这可归因于当不执行L𝐹ℎ𝑜时,𝐹ℎ𝑒和𝑜𝑟𝑡ℎ的次优表示。
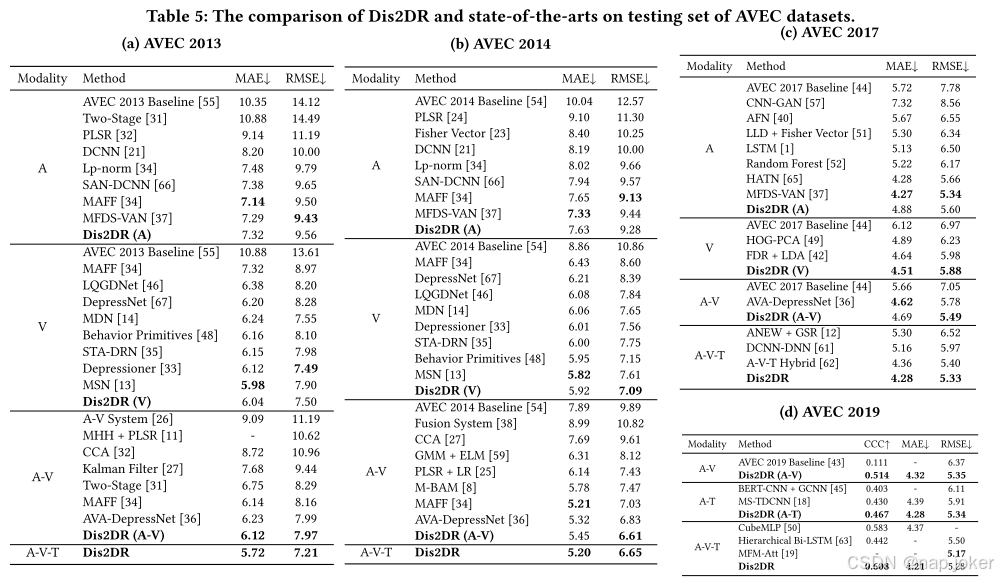
与最先进的比较
我们将我们的Dis2DR与最先进的方法在单模和多模情况下进行了比较。性能显示在选项卡中。5.在AVEC 2019中比较了一个额外的指标--和谐相关系数(CCC),它表示预测与地面事实之间的相关性。它的表述如下:
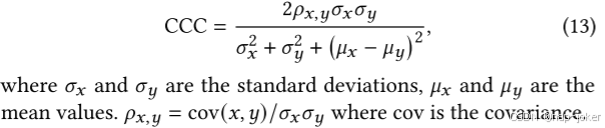
总体而言,我们的Dis2DR在几乎所有标准和所有AVEC数据集上实现了最佳的视听文本多模式灾难恢复性能。即使只使用部分医疗设备,我们的Dis2DR在Avec 2019上也表现出与视听和视听文本方法相比极具竞争力的性能。在单通道比较方面,我们的Dis2DR甚至超过了大多数单一音频或视频通道方法。在avec 2013和avec 2014数据集上,与我们的Dis2DR框架相比,视听方法MAFF34获得了具有竞争力的性能。然而,当考虑单通道方法时,MAFF在视觉通道中经历了显著的性能下降。相比之下,我们的Dis2DR框架保持了强大的性能,即使在视觉模式下也接近最先进的性能水平。
结论
在这项研究中,我们引入了Dis2DR,这是一个创新的框架,它结合了与抑郁相关的多通道特征和针对不完整多通道DR的特权知识蒸馏范例。通过将特征分离为同质、异质和噪声表示,Dis2DR有效地从通道特定和通道不变的内容中提取与抑郁相关的特征,捕获关键信息并抑制各种通道的无关内容。此外,我们的特权知识提炼方法利用缺失的内容作为特权知识,促进了通道信息的泛化,并在不完整的多通道场景中提高了性能。实验结果表明,Dis2DR在整个视听文本模式的灾难恢复中具有最先进的性能,同时即使在已建立的基准上使用单或双模式输入也保持竞争力。