我将会首先提出一个问题,然后基于这个问题从浅入深,深入底层讲解相关知识点,最终回到这个问题,所以问题仅仅只是一个引导,最重要的是里面的内容。
如果想要在某个模型基础上做全参数微调,究竟需要多少显存?
以下为大纲
第一部分:数据类型与静态显存基石
第二部分:训练的固定开销 梯度与优化器状态
第三部分:激活值(Activations)与上下文
第四部分:综合推演与实战计算(全景公式)
第五部分: 显存优化技术的底层工程逻辑
第一部分:数据类型与静态显存基石
在讨论微调之前,我们必须先弄清楚把一个大模型"干巴巴地请到显卡里"(只加载权重)需要多大空间。这就是静态显存。
显存的计算本质上是做小学的乘法,关键在于单位的统一。
-
Bit (位):计算机最小单位,非 0 即 1。
-
Byte (字节) :存储的基本单位,1 Byte = 8 Bits。
-
换算关系 :在 AI 显存估算中,我们通常按照
来做粗略计算(虽然严格按照
模型里的每一个参数(Parameter),都是一个浮点数。选择哪种精度的浮点数,直接决定了单个参数有多重:
-
FP32(单精度) :32 Bits = 4 Bytes。这是传统的深度学习标准精度,非常精确,但极占空间。
-
FP16 / BF16(半精度) :16 Bits = 2 Bytes。目前大模型训练和推理的绝对主流。
- 注:FP16 和 BF16 的总长度一样,都是占用 2 Bytes,只是内部表示小数和整数部分的比例不同(BF16 能表示的数值范围更大,不容易溢出,所以在训练大模型时比 FP16 更受欢迎)。
-
INT8(八位整数) :8 Bits = 1 Byte。常用于模型量化推理。
当我们说 LLaMA-7B 时,"7B"指的是 7 Billion(70亿)个参数。
在底层,大语言模型是由无数个矩阵相乘组成的。以最基础的线性层(Linear Layer)为例:
这里的 W(权重矩阵)和 B(偏置向量)里的每一个数字,就是一个参数。70亿个参数,就是 70亿个需要保存在显存里的浮点数。
现在我们要把一个拥有 70亿参数的模型加载到显卡上,准备做推理(不包括训练)。我们来算一算最低需要多少显存:
场景 A:使用传统的 FP32 加载
-
公式:显存占用 = 参数量
-
计算:
-
结论 :大约需要 28 GB 的显存。
场景 B:使用主流的 FP16 或 BF16 加载
-
计算:
-
结论 :大约需要 14 GB 的显存。
对于模型参数,你只需要记住一个极其好用的粗略心算口诀:
在半精度(FP16/BF16)下,1B 的模型参数约等于 2GB 的静态显存。
巩固习题
量化计算: 如果我们使用 INT8 量化技术来加载一个 14B(140亿参数)的模型,请严格计算仅加载模型权重需要占用多少 GB 显存?
根据BF16为1B = 2GB ,直接可以得到INT8为1B = 1GB,14B=14GB
底层矩阵: 在 Transformer 架构中,假设有一个全连接层(Linear Layer),它的输入特征维度(Input Dimension)是 4096,输出特征维度(Output Dimension)也是 4096。假设该层不使用偏置(Bias=False),请问:
-
这个层共有多少个参数?
-
如果使用 BF16 格式,这个单层的权重矩阵需要占用多少 MB 的显存?
参数量为 个。占用显存为
,除以
精确等于 32 MB。
第二部分:训练的固定开销:梯度与优化器状态
为什么很多显卡能轻松满血"运行(推理)"7B模型,却连微调它的资格都没有?因为在全参数微调中,模型本身的权重(Weights)只是显存消耗的冰山一角。
只要训练一开始,你的显存里就会立刻凭空多出两座大山:梯度(Gradients) 和 优化器状态(Optimizer States)。
1. 梯度(Gradients)
在一个深度神经网络中,输入数据经过一层层的参数计算(前向传播),最终得出一个预测值,然后与真实值对比算出"损失(海拔)"。
现在你想知道第一层某个参数 的"坡度(偏导数)"。因为中间隔了非常多的层,你无法直接看出
对最终损失的影响。
这就是微积分中链式法则 (Chain Rule) 发挥作用的地方。反向传播就像是从山顶(输出端)开始倒推:
-
先计算最后一层参数对损失的影响。
-
然后利用最后一层的计算结果,继续往倒数第二层推导。
-
一层层往回传,直到计算出最前面一层参数的偏导数。
公式表示就像齿轮传动:
在反向传播(Backpropagation)中,我们要计算损失函数对每一个参数的偏导数,这就是梯度()。
(损失对 w 的变化率 = 损失对z的变化率 × z 对 y 的变化率 × y 对 w的变化率)
在主流的大模型训练中,梯度通常和推理时的权重一样,使用 FP16 / BF16 (2 Bytes) 存储。
结论: 存储梯度所需的显存,等于模型权重的静态显存(1B 参数约占 2GB)。
2. 优化器状态(以 AdamW 为绝对核心)
这是吃显存的真正"刺客"。 如果使用最原始的随机梯度下降(SGD),优化器不需要记住任何历史信息,显存开销为 0。
在标准的随机梯度下降(SGD)中,参数更新的公式非常简单:
-
执行过程 :计算出当前这一步的梯度 g 用它更新参数
-
显存占用 :在优化器层面,SGD 是一个"没有记忆"的算法。它每次只看眼前的路,走完就忘。因此,它不需要保留任何历史信息的副本 ,优化器状态的显存开销严格为 0。
无论你用什么优化器(哪怕是最原始的 SGD),只要你想更新参数,就必须在反向传播时计算并存储每个参数的当前梯度。如果你有 70 亿个参数,你就得在反向传播的那一瞬间,腾出空间来装 70 亿个梯度值。
但是在 SGD 的视角里,梯度的生命周期非常短,通常经历以下三步(如果你熟悉 PyTorch,这刚好对应经典的训练三部曲):
-
计算梯度 (
loss.backward()):系统开辟一块显存,把计算出来的梯度存进去。这时候显存占用会突然升高。 -
更新参数 (
optimizer.step()):SGD 拿着这块显存里的梯度数据,走一步,把模型权重修改掉。 -
销毁梯度 (
optimizer.zero_grad()) :这一步走完了,刚才计算的梯度就彻底没用了。系统会立刻把存梯度的这块显存清空(或者标记为可覆盖),显存占用回落。
(注:计算过程中仍需要分配显存来临时存放这一步的梯度 g,但更新完毕后就不再长期占用了。)
但全参数微调极度依赖 AdamW 优化器,因为它能根据历史梯度动态调整每个参数的学习率,收敛既快又稳。
为了做到这一点,AdamW 需要为每一个参数记住两个额外的历史值:
-
一阶矩估计(Momentum,动量): 历史梯度的指数衰减平均值。
-
二阶矩估计(Variance,方差): 历史梯度平方的指数衰减平均值。
相比之下,AdamW 等高级优化器除了同样需要刚才说的那个"临时梯度"之外,它还要在显存里永久划出两块巨大的地盘,用来存放"一阶动量"和"二阶动量"。
这两块地盘里的数据,在整个训练的几个月时间里,永远不会被清空。不仅不清空,每走一步它还要拿着新的临时梯度去更新这两个常驻的历史状态。
精度要求: 为了防止在成千上万次迭代中累加历史信息时发生严重的精度丢失(数值下溢),一阶矩和二阶矩绝对不能 使用半精度(16 Bits),它们必须使用 FP32(4 Bytes) 来存储!
-
一阶矩开销:每个参数 4 Bytes
-
二阶矩开销:每个参数 4 Bytes
3. 混合精度训练(Mixed Precision)的隐藏代价
在现代大模型训练中,我们几乎都在使用"混合精度"。即:前向计算和反向传播使用 BF16/FP16 以加速计算并节省显存。
但这里有一个工程级的矛盾:如果你用 16 位的梯度去更新 16 位的权重,由于大模型微调的学习率通常极小(比如 ),"权重 - 学习率
梯度"这一步会导致微小的变化量直接被 16 位浮点数截断(变成 0),模型根本学不到东西。
系统必须在显存中悄悄克隆一份完整的、纯 FP32(4 Bytes)精度的高精度权重备份 。 每次更新时:用 32位主权重 - (学习率 32位优化器状态),更新完的高精度主权重再"降级"复制一份 16位 的版本,给下一轮的前向和反向传播用。
这就是为什么全参数微调极度消耗显存------因为你不仅要存一份用来干活的 16 位模型,还得在后台养着一份巨大无比的 32 位模型本体。
现在,我们把上述所有的底层逻辑汇总,来看看对一个包含 (1亿)个参数的 Transformer 层进行 混合精度 AdamW 全参数微调 时,单单是这些"死数据"(固定开销)需要多少显存。
我们要为这 1 亿个参数分配以下空间:
-
FP16 / BF16 模型权重 (用于前向/反向计算):2 Bytes
-
FP16 / BF16 梯度:2 Bytes
-
FP32 优化器一阶矩 (Momentum):4 Bytes
-
FP32 优化器二阶矩 (Variance):4 Bytes
-
FP32 高精度主权重备份 (Master Weights):4 Bytes
相加得出:对于每一个参数,你需要 的显存。
(请务必死记硬背这个乘数):
纯推理 :1 个参数占 2 Bytes。(除开KV CACHE)
如果加上KV Cache:
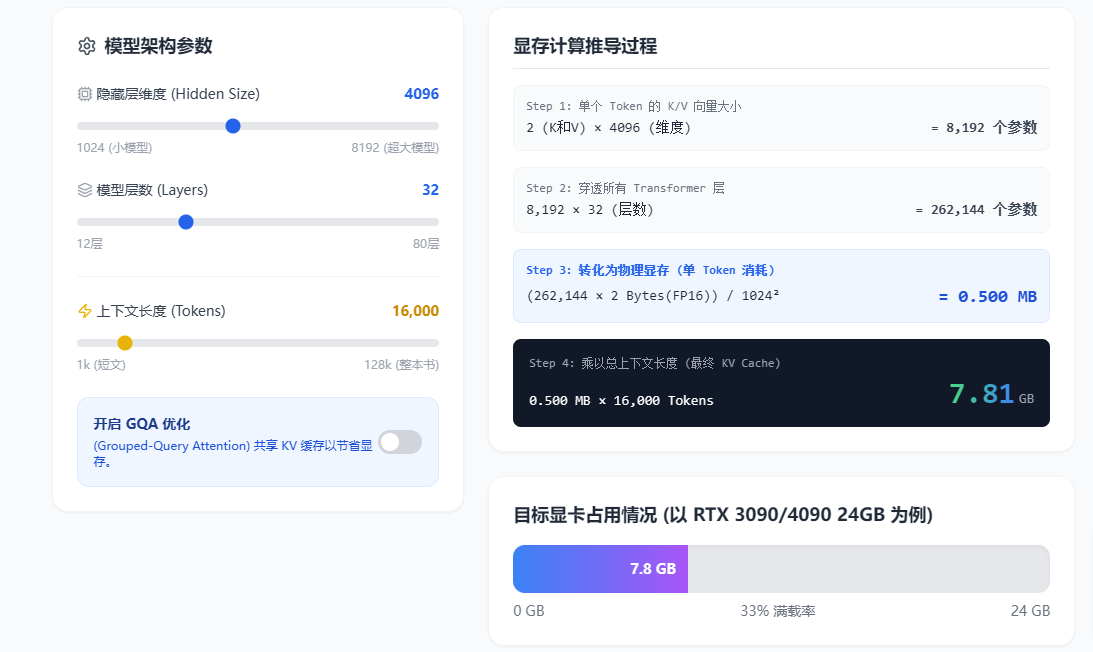
混合精度全参数微调 :1 个参数占 16 Bytes !显存需求直接翻了 8 倍!
习题巩固:
1.如果我们要对 LLaMA-7B(70亿参数)进行混合精度 AdamW 全参数微调,请问仅仅是加载上面提到的"三巨头"(模型本身、梯度、优化器状态及主权重),就已经占用了多少 GB 的显存?一张 80GB 显存的顶级 A100 显卡装得下这些"固定开销"吗?
首先7B参数本体,就已经14GB了,梯度又是14GB,优化器状态一阶距和二阶矩几乎是模型本体的4倍,56GB,主权重是32精度的,又是28GB,这就是112GB了,完全不够。
2.假设你非常穷,只有一张小显存的卡。你决定放弃 AdamW,改用标准的随机梯度下降(SGD) (不需要一阶矩和二阶矩),但你依然坚持使用混合精度(FP16 前向/反向 + FP32 主权重)。请问在这种情况下,1个参数需要占用几个 Byte 的固定显存?此时微调 7B 模型需要多少 GB 的固定显存?
模型本体照样14GB,梯度必须要14GB,主权重28GB,能节省一半。一个参数 = 2+2+4 = 8byte
即便你用 SGD 把静态开销压到了 56GB,只要一跑起训练,显卡依然会瞬间 OOM。为什么?因为我们前面算的所有东西,都只是"躺在显存里的死数据"。当数据开始流动(前向传播与反向传播),第三座真正能被无限放大的大山就会拔地而起------这就是我们马上要讲的第三部分
第三部分:激活值(Activations)与上下文
在深度学习框架(如 PyTorch)中,真正让你显存爆炸的往往不是模型本身,而是被称为激活值(Activations)的动态中间变量。
从纯粹的数学和早期神经网络理论来看 "激活值(Activation)"特指数据经过"激活函数"(如 ReLU, Sigmoid, SiLU)之后输出的结果。
但是,在现代深度学习工程界 (尤其是讨论 GPU 显存、底层框架、Megatron-LM 等分布式训练时),"激活值(Activations)"这个词的含义已经被无限扩大了。
在工程领域,"激活值"已经变成了一个黑话统称。它的准确定义是:
"在整个前向传播(Forward Pass)过程中产生的,为了给反向传播(Backward Pass)算梯度而被迫临时保存在显存里的所有【中间张量】。"
1. 什么是激活值?为什么必须存着它?
狭义的激活值(理论课上的定义)
-
指代:仅仅是经过非线性激活函数(如 ReLU, GeLU, SiLU)后算出来的结果。
-
比如 :
广义的激活值(工程和显存优化里的定义)
在 PyTorch 或底层显存分析中,只要是"为了算梯度而保存的中间变量",统统叫 Activations。它甚至包括了根本没有经过激活函数的东西!比如:
-
线性层的输入 X:完全没经过激活函数,但为了算权重 W 的梯度必须保留,它被算作 Activations 显存。
-
Dropout Mask:一堆 0 和 1 的布尔值矩阵,用来决定哪些神经元被丢弃。它也被算作 Activations。
-
注意力概率矩阵 P:Softmax 算出来的结果,也被算作 Activations。
-
甚至 LayerNorm 的均值和方差:反向传播也需要它们,统统打包算作 Activations。
在前向传播(Forward Pass)中,每一层都会接收上一层的输入 X,经过矩阵乘法和激活函数后,计算出一个输出 Y。
这个过程产生的每一个中间结果 和
,就是激活值。
# 前向传播 (Forward Pass)
H = X @ W1 # 这行算完,H 就是第一层的"激活值"
Y = H @ W2 # 这行算完,Y 就是第二层的"激活值"
Loss = Y - Target底层的硬约束: 在反向传播计算梯度时,根据微积分的链式法则,当前层的梯度不仅取决于下一层传回来的梯度,还严格依赖于前向传播时这一层的输入 X 。 这意味着,在整个前向传播跑完、直到反向传播回到这一层之前,所有的中间激活值必须保存在显存里,绝对不能删, 模型有多少层,就要缓存多少层的中间结果。
2. 影响激活值的四大核心变量
激活值的大小不再是一个固定的常数,它随你喂给模型的数据量而剧烈波动。它取决于四个变量:
-
B (Batch Size, 批次大小):一次同时处理多少条数据。
-
S (Sequence Length, 序列长度):每条数据的文本长度(Token 数量)。
-
H(Hidden Size, 隐藏层维度):模型内部神经元的宽度(LLaMA-7B 的 H = 4096)。
-
A (Attention Heads, 注意力头数):多头注意力的数量(LLaMA-7B 的 A = 32)。
在普通的线性层中,激活值的显存占用是线性增长 的,复杂度为 。这部分虽然大,但尚可控。真正致命的是自注意力机制。
3. 自注意力(Self-Attention)的 灾难
Transformer 架构的灵魂是注意力机制,这也是长文本微调的显存噩梦之源。
在注意力机制中,模型需要计算序列中每一个 Token 与其他所有 Token 的相关性。
直接从 张量维度(Tensor Shapes) 和 反向传播的链式法则(Chain Rule) 来拆解这个 的红色恶魔到底是怎么来的。
在标准的 Transformer 中,自注意力机制的核心公式是:
我们把这个公式拆解成前向传播的计算图,并看看标准的深度学习框架(如 PyTorch 的 Autograd)为了计算反向传播,在显存(HBM)里"缓存"了哪些中间张量。
假设输入张量形状为:Batch大小为 B ,序列长度为 N ,注意力头数为 H ,每个头的特征维度为 。
1. 计算 Attention Scores (S)
-
计算过程 :
-
产生张量:产生了一个名为 S 的未归一化 logits 矩阵。
-
张量形状 :
-
显存动作 :为了后续计算
2. 计算 Softmax (P)
-
产生张量:产生了一个名为 P的注意力概率矩阵(Attention Probabilities)。
-
张量形状 :
-
反向传播的刚需 :Softmax 的反向传播公式是
-
显存动作 :必须将整个 P 矩阵保存在显存中! 这是物理学级别的限制,没有 P,你就算不出 Softmax 的梯度。
3. Dropout (通常在 Softmax 之后)
-
产生张量:Dropout 会生成一个布尔掩码(Mask)矩阵,记录哪些元素被置零了。
-
张量形状 :
-
显存动作:必须保存这个 Mask 矩阵,反向传播时要把对应的梯度也置零。
4. 矩阵乘法 2:加权求和 (O)
-
反向传播的刚需 :根据矩阵乘法的求导法则,
-
显存动作 :为了更新 V(计算 V 的梯度),你再一次 不可避免地需要用到
假设我们用 Llama-2-70B(H=64),批次 B=1,序列长度 N=8192(8k上下文):
-
单层 Attention 里的这部分激活值大小 =
-
模型有 80 层!总占用 =
-
一张顶配 A100 才 80GB,光是存这个矩阵,就需要 21 张卡。
这就是为什么算上静态显存后,如果不加干预,照样会在长文本微调时瞬间 OOM。
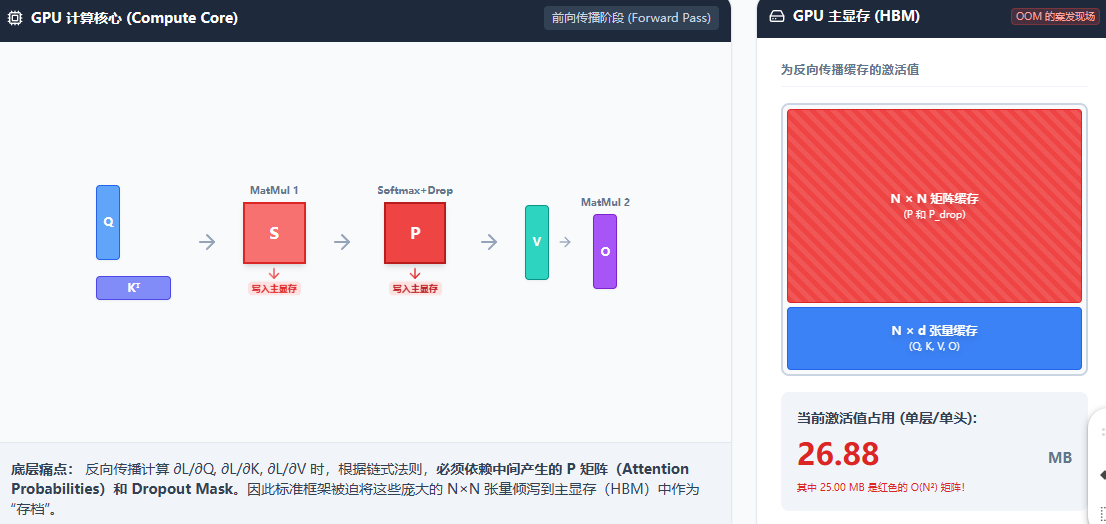
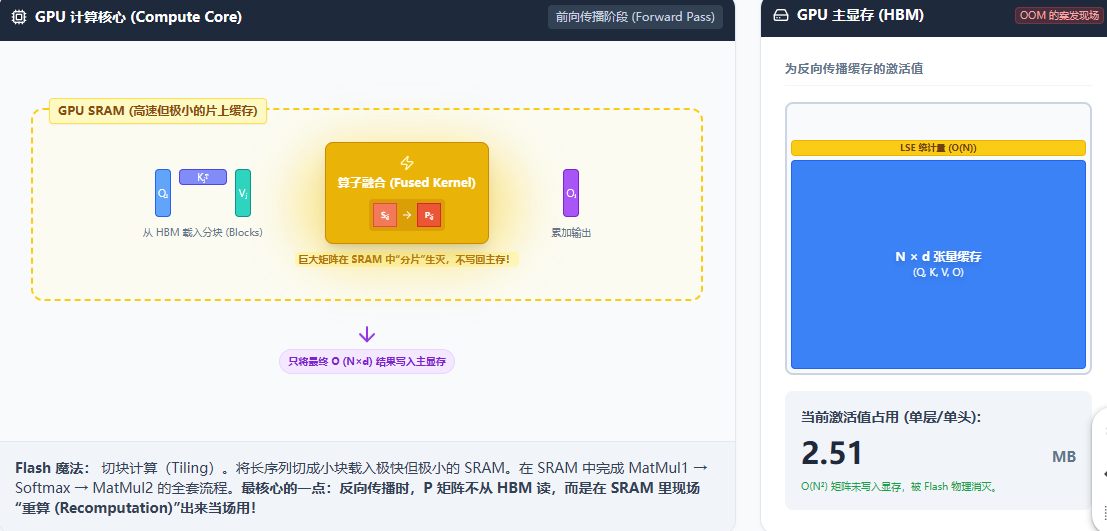
但是FlashAttention 可以解决这个问题,他写了一个底层的 CUDA Kernel,把 MatMul -> Softmax -> Dropout -> MatMul 融合成了一步。
在前向传播 时:它在 GPU 的高速缓存(SRAM)里分块(Tiling)算出 P,乘上 V 得到最终结果 O 后,直接把 SRAM 里的 P 抹掉,绝对不写回全量显存(HBM)。
在反向传播 时:它宁愿多费点算力,拿着保存下来的 Q, K, V, O,在 SRAM 里重新算一遍 P 的小分块,当场用来算梯度,算完继续抹掉。
所以,FlashAttention 的本质是:拒绝将任何 的张量写入 HBM ,从而从物理上直接干掉了模拟器里那座红色的
大山。
课后练习
理解了激活值,请思考以下两道实战问题:
1.假设你的显卡显存完全耗尽了(OOM),但在你的业务场景中,你必须 要微调长文本(序列长度 S 不能缩小)。如果不使用任何高阶优化代码,仅从上述四大变量()中挑一个来修改,你作为工程师,唯一能调整且见效最快的变量是哪一个?把它调整到多少可以最大程度救急?
明显是S,S在注意力层的复杂度为平方。
- 我们在第一部分说过,如果是单纯的推理(Inference),不需要优化器和梯度。结合刚刚讲的知识,在做纯推理时,前向传播产生的那 137GB 的"激活值"(中间层输出),还需要像训练那样死死保存在显存里不删吗?为什么?
推理的时候当然可以不用保存激活值,但是我们需要保存KV cache矩阵
第四部分:综合推演与实战计算(全景公式)
把前三部分的知识合并,我们就得到了大模型全参数微调的单卡显存开销全景公式:
-
W(Weights, 模型权重):FP16/BF16,1B参数占 2GB。
-
G (Gradients, 梯度):FP16/BF16,1B参数占 2GB。
-
O(Optimizer States, 优化器状态+主权重):FP32,1B参数占 12GB(动量4GB + 方差4GB + 主权重4GB)。
-
A (Activations, 激活值) :受
-
假设我们有一张顶配的 80GB A100 显卡。我们想在不加任何额外优化代码的情况下,对 LLaMA-7B 跑一个极小 Batch Size (B=2),中等长度 (S=4096) 的全参数微调。
算一算你的显卡会经历什么:
-
静态开销 (
-
动态开销 (
-
CUDA 开销 (
-
总需求 :
结论:哪怕是 80GB 的卡皇,在 134 GB 的真实需求面前也会瞬间宕机(OOM)。在真实的工业界,如果不做特殊处理,单卡根本没有任何可能微调 7B 级别的模型。
第五部分:打破物理极限 ------ 显存优化技术
既然物理显存不够,工程师们只能从算法和分布式架构上"偷"空间。在全参数微调中,最核心的两个续命神技是 Gradient Checkpointing (对付激活值)和 ZeRO(对付静态开销)。
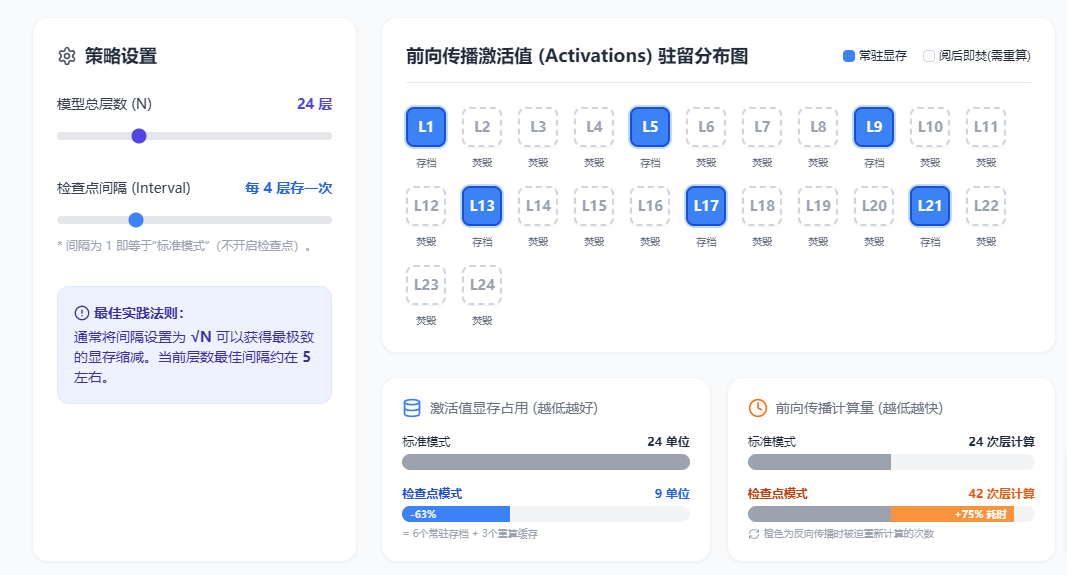
1. 梯度检查点(Gradient Checkpointing / Activation Recomputation)
-
针对目标 :
-
核心思想:用时间换空间。
我们在第三部分说过,反向传播必须依赖前向传播留下的激活值,所以要缓存好几十 GB 的中间结果。
梯度检查点的逻辑是:我不存了! 我只在每隔几层(比如每个 Transformer Block 的边界)存一个"存档点(Checkpoint)"。当反向传播计算到某一层发现没有激活值时,它就利用最近的一个"存档点",当场把这一层的前向传播重新计算一遍。
-
工程结果 :它会让微调的计算速度变慢约 20%-30%(因为多做了一部分前向传播),但能把激活值占用的显存直接砍掉 80% 到 90% (复杂度从
2. ZeRO (Zero Redundancy Optimizer) 零冗余优化器
-
针对目标 :
-
核心思想:多卡切片,按需拼接。
既然单卡装不下 112 GB,那我就用多张卡。但传统的数据并行(Data Parallel)是每张卡上都复制一份完整的模型和优化器,这并不能解决单卡装不下的问题。ZeRO 技术(由微软 DeepSpeed 提出)将其彻底切片了:
假设你有 N 张显卡:
-
ZeRO-1 (切分优化器) :模型和梯度每张卡都有,但把 12GB/B 的优化器状态切成 N块,每张卡只存
-
ZeRO-2 (切分优化器 + 梯度):把优化器状态和梯度都切成 N 块。
-
ZeRO-3 (终极形态:全切) :把模型权重、梯度、优化器全部切成 N 块!一张卡只存
测试题
这是本教程的最后两道题。
1.资源置换: 开启了 Gradient Checkpointing(梯度检查点)后,显存确实省下来了,但这会带来什么副作用?我们实际上是在用什么资源去换取显存空间?
由上文可以得出其实我们牺牲了部分的训练速度,因为梯度检查点会丢弃一部分中间的激活值,然后当需要这部分梯度反向传播时再进行一次前向传播,明显的用速度换显存。
2.ZeRO 的代价: 既然 ZeRO-3 能把所有东西都切分,完美解决显存问题,那为什么我们在有 4 张 A100 的情况下,大多数工程师通常首选 ZeRO-2 ,而不是无脑开启 ZeRO-3?(提示:想象一下,当显卡 1 正在前向传播计算,但它只拥有四分之一的权重时,它需要向谁求助?这种求助会引发什么物理瓶颈?)
主要是通信延迟。现在倒是有环状的显卡连接方法,可以尽可能的缩小延迟。
最终答案:
为了保证计算的严谨性,我们先统一全局测试环境与前提假设:
-
模型 :LLaMA-7B(
-
精度:混合精度(前向/反向 FP16 或 BF16,主权重及优化器 FP32)。
-
优化器:AdamW。
-
输入数据:批次大小 B = 2,序列长度 S = 4096。
-
常数转换 :为方便工程估算,按
-
CUDA 上下文常数 (
-
激活值估算 (A) :在 B=2, S=4096 时,如果不做任何优化,7B 模型的中间激活值大约占用
场景一:理论裸跑线(约 134 GB)
配置:不使用任何显存优化技术,单卡硬扛。
1. 静态显存计算(死数据):
-
模型权重 (W) :
-
梯度 (G) :
-
优化器状态 (O):
-
主权重备份:
-
一阶矩 (动量):
-
二阶矩 (方差):
-
优化器总计 :
-
2. 动态与环境显存(活数据):
-
激活值 (A) :全量缓存,约
-
上下文 (Ctx) :
3. 总账单:
场景二:工业界标准线(约 42.5 GB / 单卡)
配置:开启 Gradient Checkpointing(GC) + DeepSpeed ZeRO-2。
假设我们使用一台 4 张显卡 (GPUs = 4) 的机器进行数据并行训练。
1. 静态显存计算(ZeRO-2 切分):
ZeRO-2 的逻辑是:每张卡保留完整的模型权重,但把梯度和优化器切成 4 份。
-
模型权重 (W) :每张卡存完整版
-
梯度 (G) :
-
优化器状态 (O) :
2. 动态与环境显存(GC 降维打击):
-
激活值 (A) :开启 GC 后,大部分中间层激活值被丢弃,仅保留边界存档点。显存占用通常会缩减到原来的十分之一左右:
-
上下文 (Ctx) :
3. 每张显卡的总账单:
场景三:极限压榨线(约 18 GB / 单卡)
配置:开启 Gradient Checkpointing(GC) + DeepSpeed ZeRO-3。
假设我们拉了一帮穷兄弟,凑了一台 8 张显卡 (GPUs = 8) 的服务器(哪怕是 24GB 的 RTX 3090/4090 拼凑机)。
1. 静态显存计算(ZeRO-3 全切分):
ZeRO-3 的逻辑是:别管什么权重、梯度还是优化器,统统切成 8 份!
-
模型权重 (W) :
-
梯度 (G) :
-
优化器状态 (O) :
2. 动态与环境显存:
-
激活值 (A) :开启 GC 续命
-
上下文 (Ctx) :
3. 每张显卡的总账单: