- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
一、前置知识
1、ResNet50V2介绍
ResNet50(V2)与ResNet50(V1)的区别:V2采用 pre-activation(BN → ReLU → Conv),V1采用 post-activation(Conv → BN → ReLU)
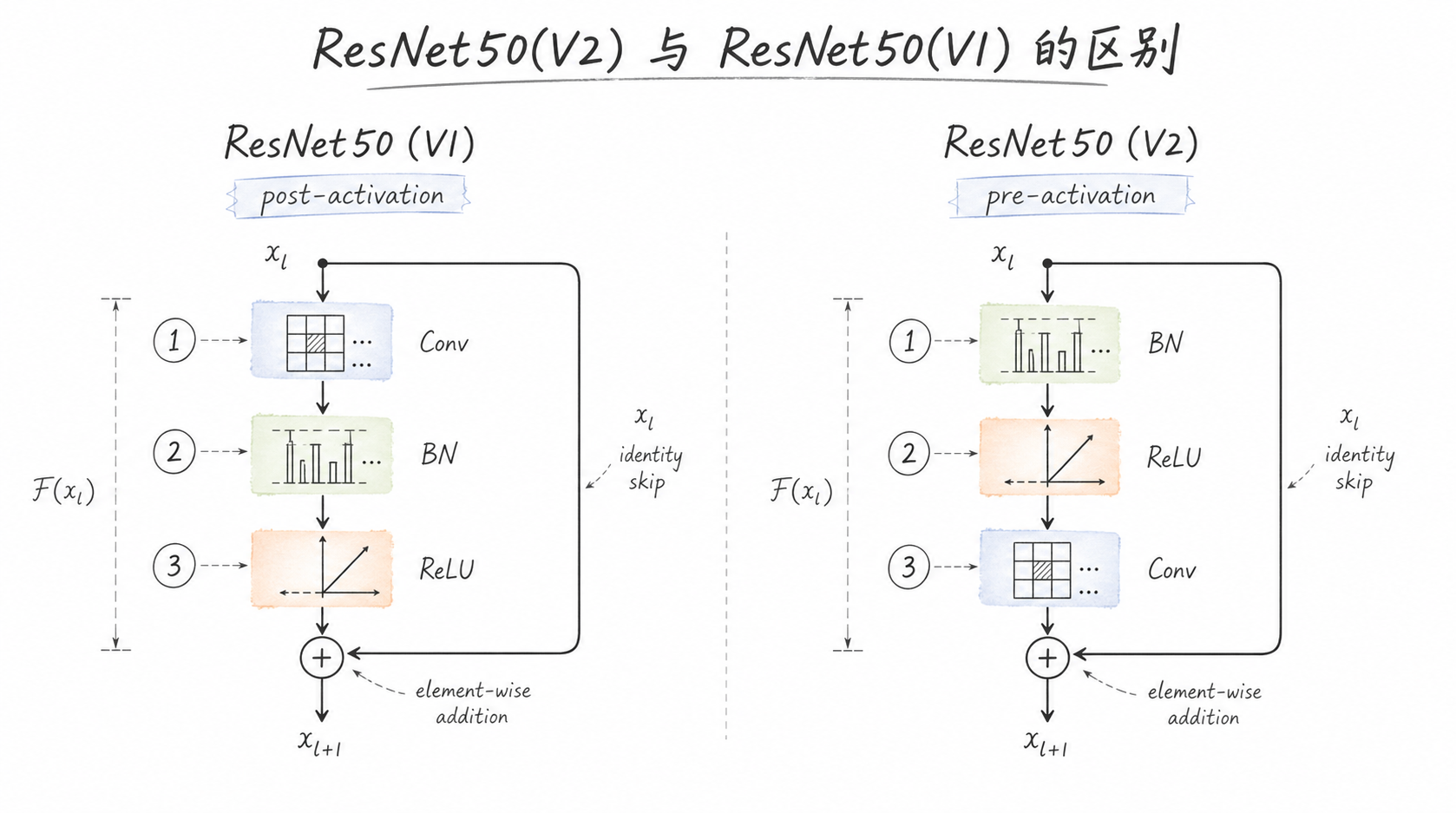
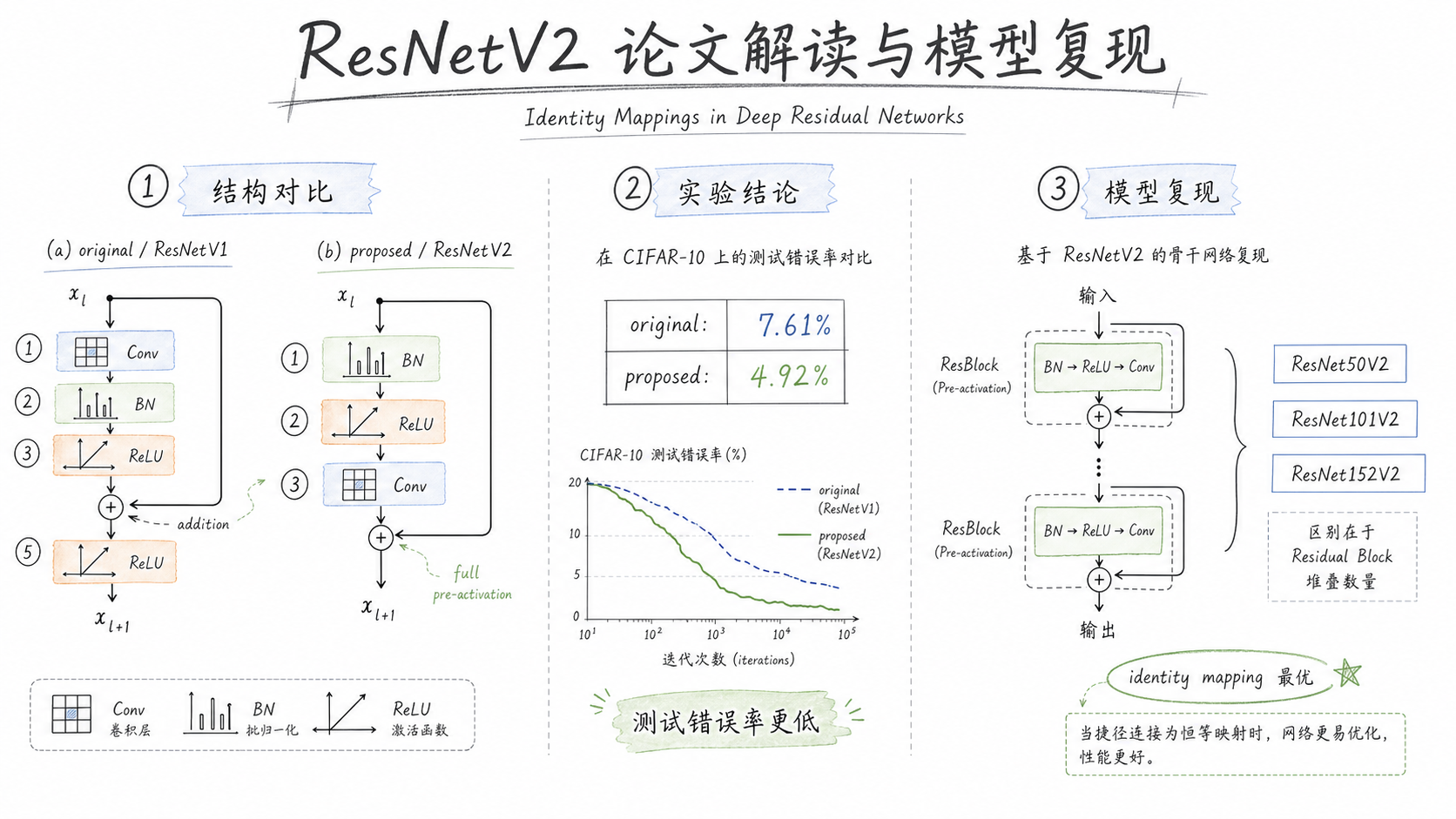
2、ResNetV2 论文解读
二、代码实现
1、准备工作
1.1 设置GPU
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import os, PIL, pathlib, warnings
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')1.2 导入数据
data_dir = './data/day01'
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
total_data = datasets.ImageFolder(data_dir, transform=train_transforms)
total_data
Dataset ImageFolder
Number of datapoints: 1661
Root location: ./data/day01
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=True)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
total_data.class_to_idx
{'0Normal': 0, '2Mild': 1, '4Severe': 2}1.3 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
Shape of X [N, C, H, W]: torch.Size([4, 3, 224, 224])
Shape of y: torch.Size([4]) torch.int642、搭建ResNet50V2模型
ResNetV2 核心区别:Pre-Activation
- V1:Conv → BN → ReLU(post-activation)
- V2:BN → ReLU → Conv(pre-activation)
即把 BN 和 ReLU 放到卷积之前,shortcut 连接变为干净的恒等映射
# Same Padding
def autopad(k, p=None):
if p is None:
if isinstance(k, int):
p = k // 2
else:
p = [x // 2 for x in k]
return p
# ResNetV2 Identity Block (Pre-Activation)
class IdentityBlockV2(nn.Module):
def __init__(self, in_channel, kernel_size, filters):
super(IdentityBlockV2, self).__init__()
filters1, filters2, filters3 = filters
# Pre-activation: BN → ReLU → Conv
self.bn1 = nn.BatchNorm2d(in_channel)
self.relu1 = nn.ReLU(True)
self.conv1 = nn.Conv2d(in_channel, filters1, 1, stride=1, bias=False)
self.bn2 = nn.BatchNorm2d(filters1)
self.relu2 = nn.ReLU(True)
self.conv2 = nn.Conv2d(filters1, filters2, kernel_size, stride=1,
padding=autopad(kernel_size), bias=False)
self.bn3 = nn.BatchNorm2d(filters2)
self.relu3 = nn.ReLU(True)
self.conv3 = nn.Conv2d(filters2, filters3, 1, stride=1, bias=False)
def forward(self, x):
# Pre-activation path
x1 = self.conv1(self.relu1(self.bn1(x)))
x1 = self.conv2(self.relu2(self.bn2(x1)))
x1 = self.conv3(self.relu3(self.bn3(x1)))
# shortcut 是干净的恒等映射(无 BN/ReLU)
out = x1 + x
return out
# ResNetV2 Conv Block (Pre-Activation, 下采样)
class ConvBlockV2(nn.Module):
def __init__(self, in_channel, kernel_size, filters, stride=2):
super(ConvBlockV2, self).__init__()
filters1, filters2, filters3 = filters
# Pre-activation: BN → ReLU → Conv
self.bn1 = nn.BatchNorm2d(in_channel)
self.relu1 = nn.ReLU(True)
self.conv1 = nn.Conv2d(in_channel, filters1, 1, stride=stride, bias=False)
self.bn2 = nn.BatchNorm2d(filters1)
self.relu2 = nn.ReLU(True)
self.conv2 = nn.Conv2d(filters1, filters2, kernel_size, stride=1,
padding=autopad(kernel_size), bias=False)
self.bn3 = nn.BatchNorm2d(filters2)
self.relu3 = nn.ReLU(True)
self.conv3 = nn.Conv2d(filters2, filters3, 1, stride=1, bias=False)
# shortcut 下采样(V2 中 shortcut 也不带 BN)
self.shortcut = nn.Conv2d(in_channel, filters3, 1, stride=stride, bias=False)
def forward(self, x):
x1 = self.conv1(self.relu1(self.bn1(x)))
x1 = self.conv2(self.relu2(self.bn2(x1)))
x1 = self.conv3(self.relu3(self.bn3(x1)))
x2 = self.shortcut(x)
out = x1 + x2
return out
''' 构建ResNet50V2 '''
class ResNet50V2(nn.Module):
def __init__(self, num_classes=1000):
super(ResNet50V2, self).__init__()
# Stem: 注意V2的stem末尾不加ReLU(交给第一个block的pre-activation做)
self.stem = nn.Sequential(
nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# Stage 2
self.stage2 = nn.Sequential(
ConvBlockV2(64, 3, [64, 64, 256], stride=1),
IdentityBlockV2(256, 3, [64, 64, 256]),
IdentityBlockV2(256, 3, [64, 64, 256])
)
# Stage 3
self.stage3 = nn.Sequential(
ConvBlockV2(256, 3, [128, 128, 512]),
IdentityBlockV2(512, 3, [128, 128, 512]),
IdentityBlockV2(512, 3, [128, 128, 512]),
IdentityBlockV2(512, 3, [128, 128, 512])
)
# Stage 4
self.stage4 = nn.Sequential(
ConvBlockV2(512, 3, [256, 256, 1024]),
IdentityBlockV2(1024, 3, [256, 256, 1024]),
IdentityBlockV2(1024, 3, [256, 256, 1024]),
IdentityBlockV2(1024, 3, [256, 256, 1024]),
IdentityBlockV2(1024, 3, [256, 256, 1024]),
IdentityBlockV2(1024, 3, [256, 256, 1024])
)
# Stage 5
self.stage5 = nn.Sequential(
ConvBlockV2(1024, 3, [512, 512, 2048]),
IdentityBlockV2(2048, 3, [512, 512, 2048]),
IdentityBlockV2(2048, 3, [512, 512, 2048])
)
# V2在全局池化前有最后一个BN+ReLU
self.post_bn = nn.BatchNorm2d(2048)
self.post_relu = nn.ReLU(True)
self.pool = nn.AvgPool2d(kernel_size=7, stride=7, padding=0)
self.fc = nn.Linear(2048, num_classes)
def forward(self, x):
x = self.stem(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.stage5(x)
x = self.post_relu(self.post_bn(x))
x = self.pool(x)
x = torch.flatten(x, start_dim=1)
x = self.fc(x)
return x
model = ResNet50V2(num_classes=3).to(device)
model
ResNet50V2(
(stem): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(stage2): Sequential(
(0): ConvBlockV2(
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(shortcut): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(1): IdentityBlockV2(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): IdentityBlockV2(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(stage3): Sequential(
(0): ConvBlockV2(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(shortcut): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
)
(1): IdentityBlockV2(
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): IdentityBlockV2(
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(3): IdentityBlockV2(
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(stage4): Sequential(
(0): ConvBlockV2(
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(shortcut): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
)
(1): IdentityBlockV2(
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): IdentityBlockV2(
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(3): IdentityBlockV2(
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(4): IdentityBlockV2(
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): IdentityBlockV2(
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(stage5): Sequential(
(0): ConvBlockV2(
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(shortcut): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
)
(1): IdentityBlockV2(
(bn1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): IdentityBlockV2(
(bn1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(post_bn): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(post_relu): ReLU(inplace=True)
(pool): AvgPool2d(kernel_size=7, stride=7, padding=0)
(fc): Linear(in_features=2048, out_features=3, bias=True)
)2.1 查看模型详情
import torchsummary as summary
summary.summary(model, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
BatchNorm2d-5 [-1, 64, 56, 56] 128
ReLU-6 [-1, 64, 56, 56] 0
Conv2d-7 [-1, 64, 56, 56] 4,096
BatchNorm2d-8 [-1, 64, 56, 56] 128
ReLU-9 [-1, 64, 56, 56] 0
Conv2d-10 [-1, 64, 56, 56] 36,864
BatchNorm2d-11 [-1, 64, 56, 56] 128
ReLU-12 [-1, 64, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 16,384
Conv2d-14 [-1, 256, 56, 56] 16,384
ConvBlockV2-15 [-1, 256, 56, 56] 0
BatchNorm2d-16 [-1, 256, 56, 56] 512
ReLU-17 [-1, 256, 56, 56] 0
Conv2d-18 [-1, 64, 56, 56] 16,384
BatchNorm2d-19 [-1, 64, 56, 56] 128
ReLU-20 [-1, 64, 56, 56] 0
Conv2d-21 [-1, 64, 56, 56] 36,864
BatchNorm2d-22 [-1, 64, 56, 56] 128
ReLU-23 [-1, 64, 56, 56] 0
Conv2d-24 [-1, 256, 56, 56] 16,384
IdentityBlockV2-25 [-1, 256, 56, 56] 0
BatchNorm2d-26 [-1, 256, 56, 56] 512
ReLU-27 [-1, 256, 56, 56] 0
Conv2d-28 [-1, 64, 56, 56] 16,384
BatchNorm2d-29 [-1, 64, 56, 56] 128
ReLU-30 [-1, 64, 56, 56] 0
Conv2d-31 [-1, 64, 56, 56] 36,864
BatchNorm2d-32 [-1, 64, 56, 56] 128
ReLU-33 [-1, 64, 56, 56] 0
Conv2d-34 [-1, 256, 56, 56] 16,384
IdentityBlockV2-35 [-1, 256, 56, 56] 0
BatchNorm2d-36 [-1, 256, 56, 56] 512
ReLU-37 [-1, 256, 56, 56] 0
Conv2d-38 [-1, 128, 28, 28] 32,768
BatchNorm2d-39 [-1, 128, 28, 28] 256
ReLU-40 [-1, 128, 28, 28] 0
Conv2d-41 [-1, 128, 28, 28] 147,456
BatchNorm2d-42 [-1, 128, 28, 28] 256
ReLU-43 [-1, 128, 28, 28] 0
Conv2d-44 [-1, 512, 28, 28] 65,536
Conv2d-45 [-1, 512, 28, 28] 131,072
ConvBlockV2-46 [-1, 512, 28, 28] 0
BatchNorm2d-47 [-1, 512, 28, 28] 1,024
ReLU-48 [-1, 512, 28, 28] 0
Conv2d-49 [-1, 128, 28, 28] 65,536
BatchNorm2d-50 [-1, 128, 28, 28] 256
ReLU-51 [-1, 128, 28, 28] 0
Conv2d-52 [-1, 128, 28, 28] 147,456
BatchNorm2d-53 [-1, 128, 28, 28] 256
ReLU-54 [-1, 128, 28, 28] 0
Conv2d-55 [-1, 512, 28, 28] 65,536
IdentityBlockV2-56 [-1, 512, 28, 28] 0
BatchNorm2d-57 [-1, 512, 28, 28] 1,024
ReLU-58 [-1, 512, 28, 28] 0
Conv2d-59 [-1, 128, 28, 28] 65,536
BatchNorm2d-60 [-1, 128, 28, 28] 256
ReLU-61 [-1, 128, 28, 28] 0
Conv2d-62 [-1, 128, 28, 28] 147,456
BatchNorm2d-63 [-1, 128, 28, 28] 256
ReLU-64 [-1, 128, 28, 28] 0
Conv2d-65 [-1, 512, 28, 28] 65,536
IdentityBlockV2-66 [-1, 512, 28, 28] 0
BatchNorm2d-67 [-1, 512, 28, 28] 1,024
ReLU-68 [-1, 512, 28, 28] 0
Conv2d-69 [-1, 128, 28, 28] 65,536
BatchNorm2d-70 [-1, 128, 28, 28] 256
ReLU-71 [-1, 128, 28, 28] 0
Conv2d-72 [-1, 128, 28, 28] 147,456
BatchNorm2d-73 [-1, 128, 28, 28] 256
ReLU-74 [-1, 128, 28, 28] 0
Conv2d-75 [-1, 512, 28, 28] 65,536
IdentityBlockV2-76 [-1, 512, 28, 28] 0
BatchNorm2d-77 [-1, 512, 28, 28] 1,024
ReLU-78 [-1, 512, 28, 28] 0
Conv2d-79 [-1, 256, 14, 14] 131,072
BatchNorm2d-80 [-1, 256, 14, 14] 512
ReLU-81 [-1, 256, 14, 14] 0
Conv2d-82 [-1, 256, 14, 14] 589,824
BatchNorm2d-83 [-1, 256, 14, 14] 512
ReLU-84 [-1, 256, 14, 14] 0
Conv2d-85 [-1, 1024, 14, 14] 262,144
Conv2d-86 [-1, 1024, 14, 14] 524,288
ConvBlockV2-87 [-1, 1024, 14, 14] 0
BatchNorm2d-88 [-1, 1024, 14, 14] 2,048
ReLU-89 [-1, 1024, 14, 14] 0
Conv2d-90 [-1, 256, 14, 14] 262,144
BatchNorm2d-91 [-1, 256, 14, 14] 512
ReLU-92 [-1, 256, 14, 14] 0
Conv2d-93 [-1, 256, 14, 14] 589,824
BatchNorm2d-94 [-1, 256, 14, 14] 512
ReLU-95 [-1, 256, 14, 14] 0
Conv2d-96 [-1, 1024, 14, 14] 262,144
IdentityBlockV2-97 [-1, 1024, 14, 14] 0
BatchNorm2d-98 [-1, 1024, 14, 14] 2,048
ReLU-99 [-1, 1024, 14, 14] 0
Conv2d-100 [-1, 256, 14, 14] 262,144
BatchNorm2d-101 [-1, 256, 14, 14] 512
ReLU-102 [-1, 256, 14, 14] 0
Conv2d-103 [-1, 256, 14, 14] 589,824
BatchNorm2d-104 [-1, 256, 14, 14] 512
ReLU-105 [-1, 256, 14, 14] 0
Conv2d-106 [-1, 1024, 14, 14] 262,144
IdentityBlockV2-107 [-1, 1024, 14, 14] 0
BatchNorm2d-108 [-1, 1024, 14, 14] 2,048
ReLU-109 [-1, 1024, 14, 14] 0
Conv2d-110 [-1, 256, 14, 14] 262,144
BatchNorm2d-111 [-1, 256, 14, 14] 512
ReLU-112 [-1, 256, 14, 14] 0
Conv2d-113 [-1, 256, 14, 14] 589,824
BatchNorm2d-114 [-1, 256, 14, 14] 512
ReLU-115 [-1, 256, 14, 14] 0
Conv2d-116 [-1, 1024, 14, 14] 262,144
IdentityBlockV2-117 [-1, 1024, 14, 14] 0
BatchNorm2d-118 [-1, 1024, 14, 14] 2,048
ReLU-119 [-1, 1024, 14, 14] 0
Conv2d-120 [-1, 256, 14, 14] 262,144
BatchNorm2d-121 [-1, 256, 14, 14] 512
ReLU-122 [-1, 256, 14, 14] 0
Conv2d-123 [-1, 256, 14, 14] 589,824
BatchNorm2d-124 [-1, 256, 14, 14] 512
ReLU-125 [-1, 256, 14, 14] 0
Conv2d-126 [-1, 1024, 14, 14] 262,144
IdentityBlockV2-127 [-1, 1024, 14, 14] 0
BatchNorm2d-128 [-1, 1024, 14, 14] 2,048
ReLU-129 [-1, 1024, 14, 14] 0
Conv2d-130 [-1, 256, 14, 14] 262,144
BatchNorm2d-131 [-1, 256, 14, 14] 512
ReLU-132 [-1, 256, 14, 14] 0
Conv2d-133 [-1, 256, 14, 14] 589,824
BatchNorm2d-134 [-1, 256, 14, 14] 512
ReLU-135 [-1, 256, 14, 14] 0
Conv2d-136 [-1, 1024, 14, 14] 262,144
IdentityBlockV2-137 [-1, 1024, 14, 14] 0
BatchNorm2d-138 [-1, 1024, 14, 14] 2,048
ReLU-139 [-1, 1024, 14, 14] 0
Conv2d-140 [-1, 512, 7, 7] 524,288
BatchNorm2d-141 [-1, 512, 7, 7] 1,024
ReLU-142 [-1, 512, 7, 7] 0
Conv2d-143 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-144 [-1, 512, 7, 7] 1,024
ReLU-145 [-1, 512, 7, 7] 0
Conv2d-146 [-1, 2048, 7, 7] 1,048,576
Conv2d-147 [-1, 2048, 7, 7] 2,097,152
ConvBlockV2-148 [-1, 2048, 7, 7] 0
BatchNorm2d-149 [-1, 2048, 7, 7] 4,096
ReLU-150 [-1, 2048, 7, 7] 0
Conv2d-151 [-1, 512, 7, 7] 1,048,576
BatchNorm2d-152 [-1, 512, 7, 7] 1,024
ReLU-153 [-1, 512, 7, 7] 0
Conv2d-154 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-155 [-1, 512, 7, 7] 1,024
ReLU-156 [-1, 512, 7, 7] 0
Conv2d-157 [-1, 2048, 7, 7] 1,048,576
IdentityBlockV2-158 [-1, 2048, 7, 7] 0
BatchNorm2d-159 [-1, 2048, 7, 7] 4,096
ReLU-160 [-1, 2048, 7, 7] 0
Conv2d-161 [-1, 512, 7, 7] 1,048,576
BatchNorm2d-162 [-1, 512, 7, 7] 1,024
ReLU-163 [-1, 512, 7, 7] 0
Conv2d-164 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-165 [-1, 512, 7, 7] 1,024
ReLU-166 [-1, 512, 7, 7] 0
Conv2d-167 [-1, 2048, 7, 7] 1,048,576
IdentityBlockV2-168 [-1, 2048, 7, 7] 0
BatchNorm2d-169 [-1, 2048, 7, 7] 4,096
ReLU-170 [-1, 2048, 7, 7] 0
AvgPool2d-171 [-1, 2048, 1, 1] 0
Linear-172 [-1, 3] 6,147
================================================================
Total params: 23,506,627
Trainable params: 23,506,627
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 266.07
Params size (MB): 89.67
Estimated Total Size (MB): 356.32
----------------------------------------------------------------3、训练模型
3.1 编写训练函数
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss3.2 编写测试函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss3.3 正式训练
import copy
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
loss_fn = nn.CrossEntropyLoss()
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
# 保存最佳模型
PATH = './model/resnet50v2_best_model.pth'
os.makedirs(os.path.dirname(PATH), exist_ok=True)
torch.save(best_model.state_dict(), PATH)
print('Done')
Epoch: 1, Train_acc:66.0%, Train_loss:0.844, Test_acc:73.0%, Test_loss:1.060, Lr:1.00E-04
Epoch: 2, Train_acc:74.5%, Train_loss:0.672, Test_acc:79.0%, Test_loss:0.518, Lr:1.00E-04
Epoch: 3, Train_acc:78.3%, Train_loss:0.590, Test_acc:82.0%, Test_loss:0.469, Lr:1.00E-04
Epoch: 4, Train_acc:79.4%, Train_loss:0.540, Test_acc:82.3%, Test_loss:0.462, Lr:1.00E-04
Epoch: 5, Train_acc:84.4%, Train_loss:0.459, Test_acc:80.2%, Test_loss:0.525, Lr:1.00E-04
Epoch: 6, Train_acc:85.1%, Train_loss:0.431, Test_acc:83.8%, Test_loss:0.446, Lr:1.00E-04
Epoch: 7, Train_acc:85.8%, Train_loss:0.393, Test_acc:84.1%, Test_loss:0.459, Lr:1.00E-04
Epoch: 8, Train_acc:87.1%, Train_loss:0.366, Test_acc:81.1%, Test_loss:0.554, Lr:1.00E-04
Epoch: 9, Train_acc:88.4%, Train_loss:0.334, Test_acc:87.7%, Test_loss:0.343, Lr:1.00E-04
Epoch:10, Train_acc:89.2%, Train_loss:0.283, Test_acc:82.3%, Test_loss:0.441, Lr:1.00E-04
Done4、结果可视化
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
from datetime import datetime
current_time = datetime.now()
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('ResNet50V2 - Training and Validation Accuracy')
plt.xlabel(current_time)
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('ResNet50V2 - Training and Validation Loss')
plt.show()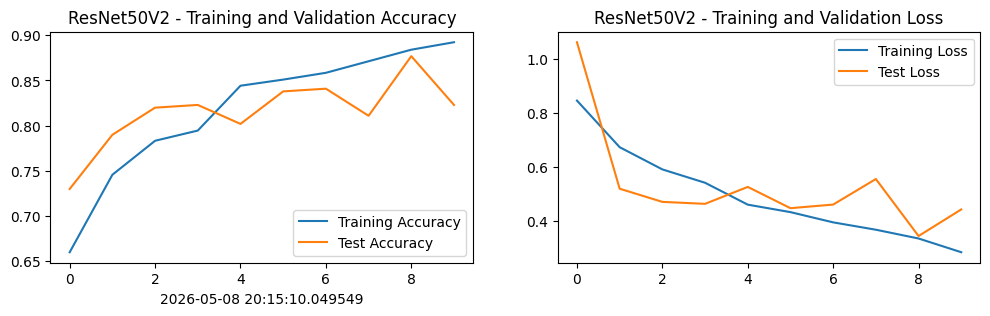
5、模型评估
best_model.load_state_dict(torch.load(PATH, map_location=device))
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
print(f'ResNet50V2 Best Test Accuracy: {epoch_test_acc*100:.1f}%')
print(f'ResNet50V2 Best Test Loss: {epoch_test_loss:.4f}')
ResNet50V2 Best Test Accuracy: 87.7%
ResNet50V2 Best Test Loss: 0.3429