当客户端访问 http://127.0.0.1:8080/Search?key=C++ 时,服务器解析请求行,拿到完整 URI /Search?key=C++;先从 URI 里拆分出路由路径 /Search;拿着 /Search 去匹配我们注册的路由,找到并执行 Search 业务函数;再拆分出查询参数 key=C++,在 Search 函数里使用这个业务数据。
路由路径与查询参数的关联
从本质上来说,查询参数和普通函数传入的参数是完全等价的,服务器解析完成后可以直接提取使用。在 GET 请求中,路由路径的作用是帮服务器匹配对应的业务接口,相当于确定了要调用的函数名称,而查询参数就是为这个接口传递的具体入参,客户端通过 URL 中问号后的键值对,将业务所需的数据传递给服务器。服务器解析请求报文时,会先从 URI 中拆分出路由路径完成接口匹配,再单独解析出查询参数的键值对,然后在业务函数内部就可以直接通过参数名提取对应的值,直接参与后续的业务逻辑处理,就像调用普通 C++ 函数时传递参数一样自然。需要区分的是,GET 请求的参数通过查询参数承载在 URI 中,而 POST 请求的参数会放在请求体里,但对于后端业务函数而言,两者最终都是被解析为可用的参数,只是数据承载的报文位置不同。
三、Web根目录
什么是Web根目录?
Web 根目录本质就是网站的根目录,在我们手写 HTTP 服务器的项目里,我们创建的 wwwroot 文件夹,就是服务器中定义的 Web 根目录。Web 根目录是服务器存放所有静态资源的最顶层文件夹,相当于服务器对外展示文件的 "大门",客户端通过浏览器访问时,所有静态文件的请求都会从这个目录下查找资源。
举个例子: 当客户端发起 GET 请求访问http://127.0.0.1:8080/test.txt 时,服务器解析出 URI 里的文件路径 /test.txt,会自动拼接上 Web 根目录 wwwroot,最终定位到 wwwroot/test.txt 这个文件,再将文件内容读取并返回给客户端。
我们在写 HTML 表单时,如果不写 method 属性 ,浏览器默认就会使用 GET 方法 提交表单。这是浏览器的原生默认行为,只要我们省略了 method,它就自动走 GET 请求。也就是说,默认情况下,我们填写的账号密码等表单数据,会被浏览器拼接到 URL 后面变成查询参数,明文暴露在地址栏里。正因为 GET 有安全隐患、传参量有限,所以实际开发中,凡是涉及登录、注册、提交隐私数据的表单,我们都会主动把 method 明确设置为 POST,强制让浏览器把数据放到请求体里传输,这也是为什么我们平时接触到的登录注册功能,几乎全是 POST 提交。简单说,表单默认是 GET,但业务开发里 POST 才是标准选择。
6. 那如果默认是 GET 的话,那不就暴露隐私了吗,换句话说我们是如何主动改为 POST 的呢?
首先对于普通人而言,根本不知道 GET 和 POST 是什么,他们只是在网页里填账号、输密码、点登录,对底层的请求方式一无所知。如果表单默认是 GET,那用户输入的账号密码就会直接拼在地址栏里变成明文,不仅自己能看见,还会留在浏览器历史记录里,这确实有极大的隐私泄露风险。但普通人完全不需要操心这件事,因为修改提交方式这件事,根本不是用户来做,而是开发网站的后端和前端程序员来做。程序员在写网页的登录注册页面时,会提前在 HTML 表单代码里,主动加上 method="POST" 这行代码,直接强制浏览器必须用 POST 方式提交,从根源上就避开了 GET 的安全隐患。用户在前端页面上完全感知不到这个设置,他们填完信息点提交,浏览器就会按照程序员提前写好的规则,自动把账号密码放进请求体里发送,不会暴露在地址栏。简单来说,GET 是表单的浏览器默认规则,但程序员在开发时会根据业务场景主动修改这个规则,涉及隐私、敏感数据的场景,程序员一定会手动把 method 改成 POST,普通人只管正常使用,安全防护是网站开发层面提前做好的设计,不需要用户懂任何底层原理。
具体来说,浏览器分两步处理:第一步是地址转换,如果我们输入的是普通文字,浏览器会默认调用它自带的搜索引擎,把文字解析成对应的目标网址,比如搜 "百度",浏览器就会自动定位到 "https://www.baidu.com" 这个标准网址;如果我们输入的是一个简单的域名,比如 "baidu.com",浏览器会自动补全协议,变成完整的网址。第二步是生成报文,拿到转换好的网址后,浏览器会按照我们之前聊的规则,自动拆解网址里的协议、IP、路由路径,生成标准的 GET 请求报文,然后发给对应的服务器。
这和表单提交的逻辑本质是一样的,只是触发方式不同:表单是我们填完信息点按钮,浏览器自动生成 POST 请求报文;我们搜文字是输入关键词,浏览器先转网址,再自动生成 GET 请求报文。两种情况里,我们都不用手动处理网址和报文,浏览器都在背后做了翻译和打包的工作,服务器最终收到的,永远是标准的 HTTP 请求报文,它根本不关心这个请求是我们搜文字触发的,还是点表单触发的。
8. 举一个完整的例子
当我们在浏览器地址栏输入 "西红柿炒鸡蛋怎么做" 这类纯文字搜索词时,浏览器首先会判断输入内容不是标准网址,而是搜索指令,随后会调用默认搜索引擎 (比如百度、谷歌),将我们的搜索词拼接成带查询参数的完整 URL,本质是一次 GET 请求;网址里是可以包含中文这类非英文字符的,但计算机底层只识别 ASCII 字符,所以浏览器会自动对中文进行 urlencode / urldecode 编码,把中文转换成 % XX 格式的编码字符,拼接到搜索 URL 的查询参数中,再生成标准的 HTTP GET 请求报文发给搜索引擎服务器,服务器收到数据后会自动解码还原出中文搜索词,再根据关键词返回对应的搜索结果页面。整个过程里,我们看到的中文是浏览器解码后展示的,网络中实际传输的是编码后的字符,这也是为什么我们肉眼看到的搜索网址里能显示中文,而实际传输时中文会被转换的原因,整个搜索流程本质就是浏览器自动完成拼接 URL、编码、发起 GET 请求的全过程,和我们之前讲的 GET 请求、查询参数、表单提交的底层逻辑完全相通。
五、Get和Post请求方法
GET
GET 是 HTTP 协议里最基础、最常用的请求方法,GET 的本质就是从服务器中「获取 / 查询」资源。简单说,GET 就是 "只读" 请求,我们向服务器要东西,服务器把东西给我们,整个过程不会改变服务器的状态,比如打开网页、搜索内容、加载图片、视频,底层全都是 GET 请求。
结合我们之前的例子,GET 请求的数据传递有一个铁则:所有参数都放在 URL 的查询参数里,也就是请求报文的「请求行」中。不管是我们在浏览器地址栏手动输入网址、表单默认提交,还是搜索关键词,本质都是 GET 请求:浏览器会把我们要传递的参数(比如搜索词、表单数据),拼接在 URL 的问号后面,形成URL?键1=值1&键2=值2 的格式,而这些中文、特殊符号,浏览器会自动做 URL 编码,服务器收到后再解码还原,这也是 GET 请求最标志性的特征。
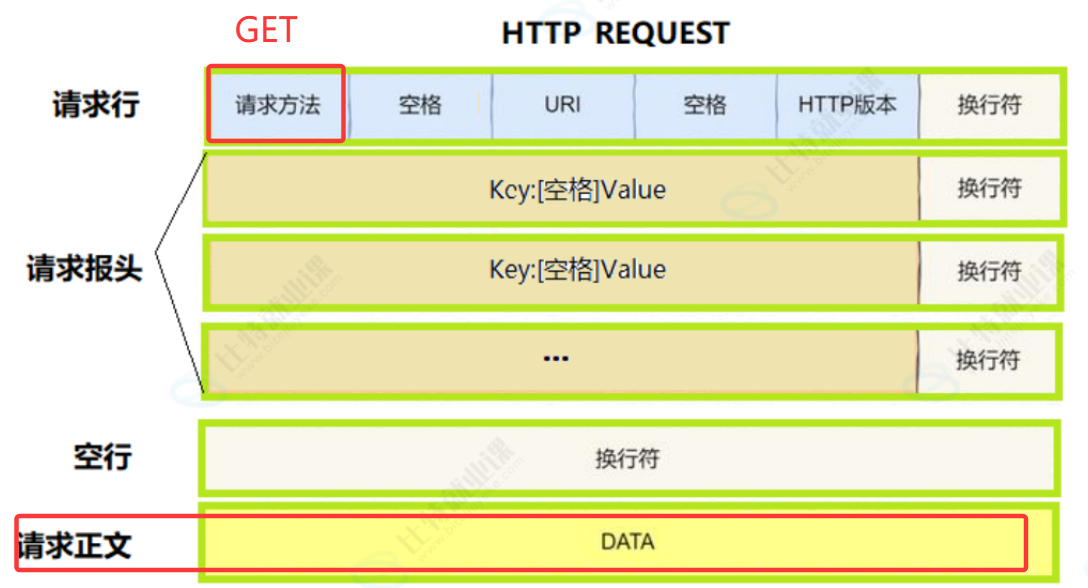
基于这个核心特征,GET 请求衍生出几个关键特点:第一,数据明文暴露,因为参数在地址栏里,所有人都能看见,还会留在浏览器历史记录里,所以绝对不能用来传输账号、密码这类敏感隐私数据,这也是为什么登录、注册表单都会手动改成 POST;第二,数据长度有限制,因为浏览器和服务器都会对 URL 的长度做限制,不能传大量数据,只适合传少量、简单的查询参数;第三,天然可缓存、可收藏,浏览器会缓存 GET 请求的结果,我们刷新页面速度更快,也能把这个带参数的网址收藏、分享,比如搜索后的页面网址,分享给别人打开就是一样的结果;第四,没有请求体,GET 请求报文只有请求行、请求头,空一行后直接结束,不需要解析请求体,服务器处理起来非常简单高效。
再结合我们手写的 HTTP 服务器,GET 请求的完整工作流程可以完美闭环:客户端发起 GET 请求时,会在请求行里带上完整的 URI(路由路径 + 查询参数),服务器收到报文后,先拆分出路由路径,匹配对应的业务接口,再拆分出查询参数,解析成键值对后直接使用,执行业务逻辑,最后把查询到的资源(HTML 页面、图片、搜索结果)返回给客户端。
最后明确 GET 的使用场景,记住一个核心原则:只要是 "查、看、获取",不用改服务器数据的操作,全用 GET。比如打开网页、搜索信息、加载静态资源、查询个人信息;反之,只要是提交隐私数据、上传文件、修改服务器数据(注册、登录、发布内容),绝对不用 GET,必须用 POST。
POST
POST 是 HTTP 协议里专门用来向服务器提交数据、修改服务器资源状态的请求方法,和 GET 完全相反:GET 是 "从服务器拿东西",POST 是 "往服务器送东西"。我们日常登录账号、注册信息、发布评论、提交表单、上传文件,底层全是 POST 请求。
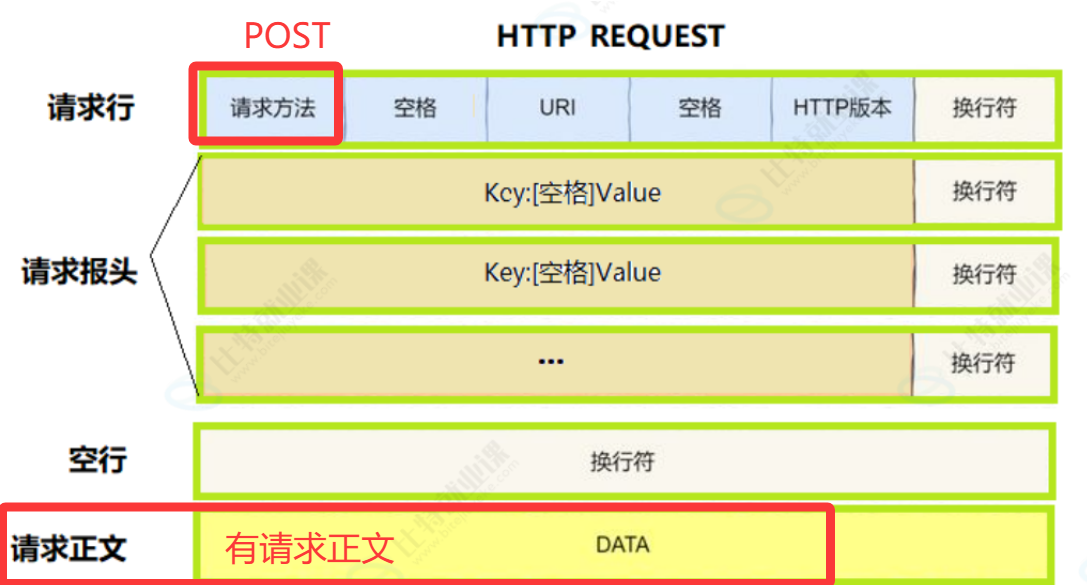
POST 最核心的特征,和 GET 有本质区别:它的参数不放在 URL 里,而是藏在 HTTP 报文的「请求体」中。我们之前讲表单时提到,只要把表单 method="POST",浏览器就不会把账号密码拼在地址栏,而是打包放在请求头后面的请求体里传输。正因为数据藏在请求体,不在地址栏暴露,所以POST 天生适合传输账号、密码、身份证这类敏感隐私数据,这也是所有登录、注册功能必用 POST 的根本原因。
基于这个核心特征,POST 衍生出和 GET 完全对立的关键特点:第一,数据隐私安全,请求体里的内容不会显示在地址栏,也不会留在浏览器历史记录里,第三方无法通过网址直接获取参数;第二,无数据长度限制,请求体理论上可以承载任意大小的数据,既能传简单的账号密码,也能传大体积的图片、文件、视频;第三,不可缓存、不可直接收藏,POST 是提交操作,每次提交都可能改变服务器数据,浏览器不会缓存 POST 结果,也无法直接收藏 POST 提交后的页面,刷新页面时浏览器还会提示 "是否重新提交表单";第四,必须解析请求体,POST 报文结构是请求行 + 请求头 + 空行 + 请求体,服务器必须读取请求体内容、解析数据格式,相比 GET,处理逻辑更复杂,我们手写服务器时遇到的粘包、拆包问题,本质就是 POST 请求体带来的。
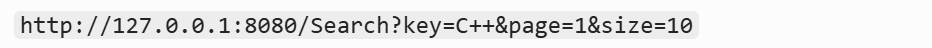

key=C++ 和 page=1 这组键值对,原封不动地存在于请求报文的请求行,是请求报文的一部分,跟着请求行一起被浏览器发送给服务器。
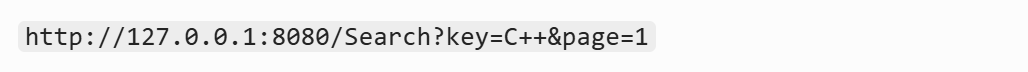
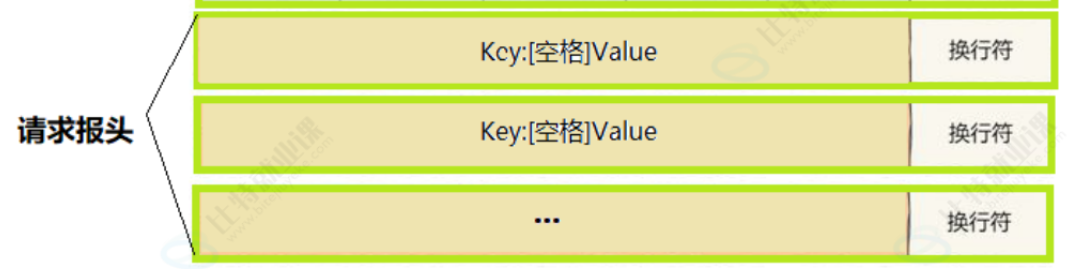

表单有 3 个核心组成:
此时数据藏在请求体,地址栏看不见;数据量无上限;服务器必须解析请求体(长连接时要拆包)。






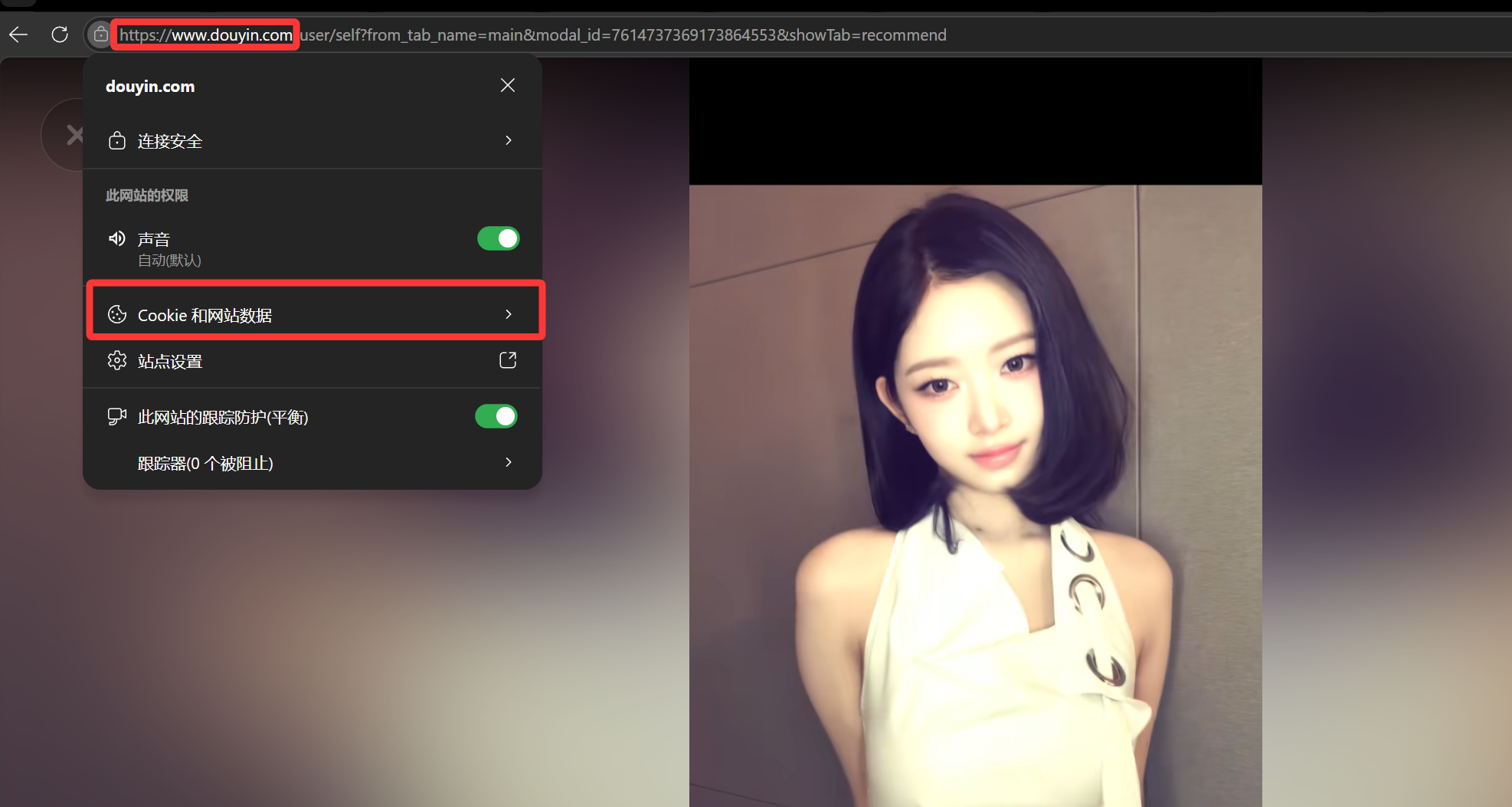 比如我们在刷抖音时,我们在抖音登录成功后,服务器会在响应报头里给浏览器发一个Set-Cookie,里面包含了登录凭证(比如sessionid这类标识)。浏览器收到后,就把这个 Cookie 存在本地,和抖音这个域名绑定。
比如我们在刷抖音时,我们在抖音登录成功后,服务器会在响应报头里给浏览器发一个Set-Cookie,里面包含了登录凭证(比如sessionid这类标识)。浏览器收到后,就把这个 Cookie 存在本地,和抖音这个域名绑定。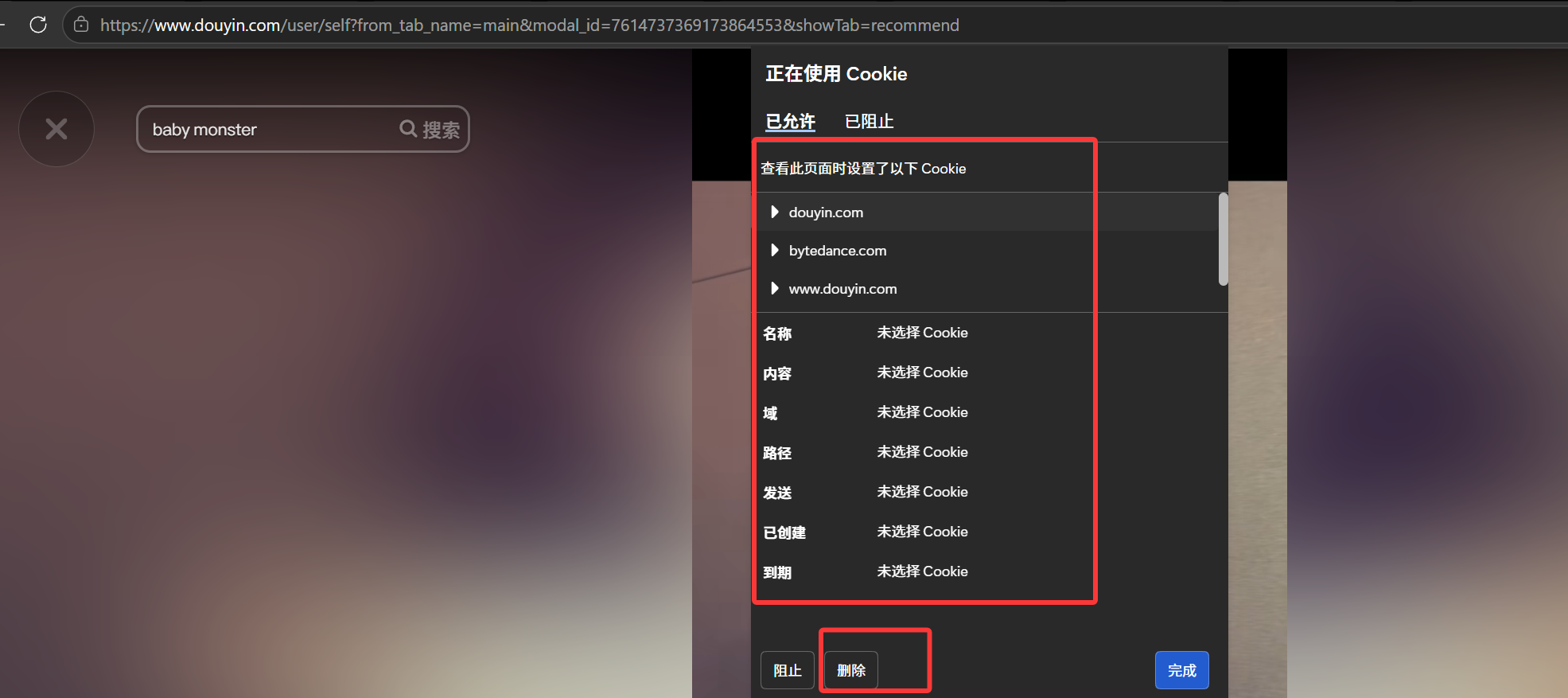 我们每次访问抖音的页面,浏览器都会自动把这个 Cookie 塞进请求头里发给服务器。服务器拿到 Cookie 里的sessionid,找到对应的 Session,就知道 "这是已登录的用户",直接返回登录状态的页面,不用我们重复登录。
我们每次访问抖音的页面,浏览器都会自动把这个 Cookie 塞进请求头里发给服务器。服务器拿到 Cookie 里的sessionid,找到对应的 Session,就知道 "这是已登录的用户",直接返回登录状态的页面,不用我们重复登录。