一、什么是 CSP?
1.1 全称与核心思想
CSP = Communicating Sequential Processes(通信顺序进程)。
这是由计算机科学家 Tony Hoare(图灵奖得主,快速排序算法的发明者)提出的一套并发编程模型。它的核心思想就一句话:
"Do not communicate by sharing memory; instead, share memory by communicating."
不要通过共享内存来通信,而要通过通信来共享内存。
1.2 传统并发 vs CSP 并发
| 模型 | 比喻 | 问题 |
|---|---|---|
| 传统多线程(Java/C++) | 多个工人(线程)围着一张桌子(共享内存)抢图纸,谁抢到谁改,改的时候得加锁 | 锁竞争激烈、死锁、数据竞争、缓存一致性开销大 |
| CSP(Go) | 每个工人有自己的工作台(独立内存),需要图纸时通过传送带(Channel)递过去 | 天然同步、无显式锁(对程序员而言)、数据所有权清晰 |
1.3 Go 的 CSP 实现
Go 语言用两个原语实现了 CSP:
-
Goroutine:轻量级线程(工人)。
-
Channel:带类型的并发安全管道(传送带)。
小白总结: 传统编程是"大家挤在一个房间里抢东西",Go 是"每个人待在自己房间,通过门口的信箱交换物品"。
二、Channel 的底层实现原理
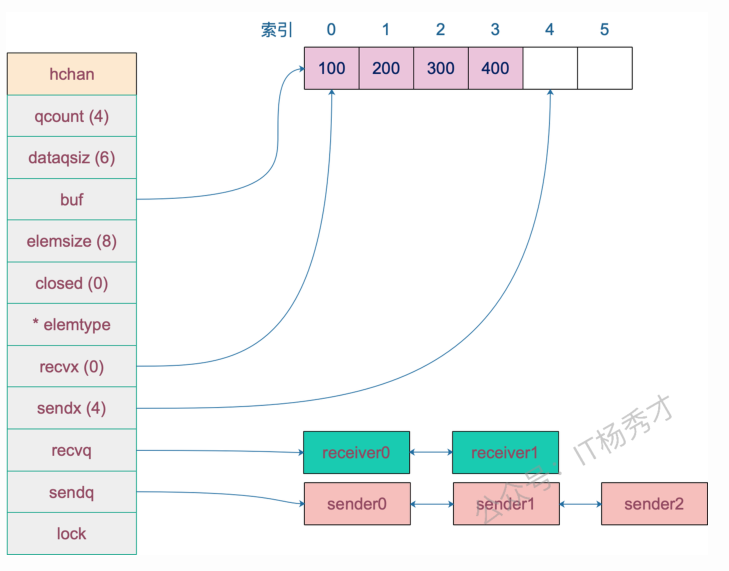
Channel 的底层是一个名为 hchan 的结构体,定义在 runtime/chan.go 中。
type hchan struct {
qcount uint // 当前缓冲区里有多少个元素
dataqsiz uint // 缓冲区总容量
buf unsafe.Pointer // 指向底层环形缓冲区的指针
elemsize uint16 // 每个元素占多少字节
closed uint32 // 是否已关闭
elemtype *_type // 元素类型信息
sendx uint // 发送索引:下一个发送位置
recvx uint // 接收索引:下一个接收位置
recvq waitq // 等待接收的 goroutine 队列
sendq waitq // 等待发送的 goroutine 队列
lock mutex // 互斥锁:保护 hchan 中所有字段
}大概的底层原理图是这样的,但是这个图里面没有体现出来环形缓冲数组:
下面这个图更形象一点,体现出来了环形缓冲数组和两个双向等待链表:
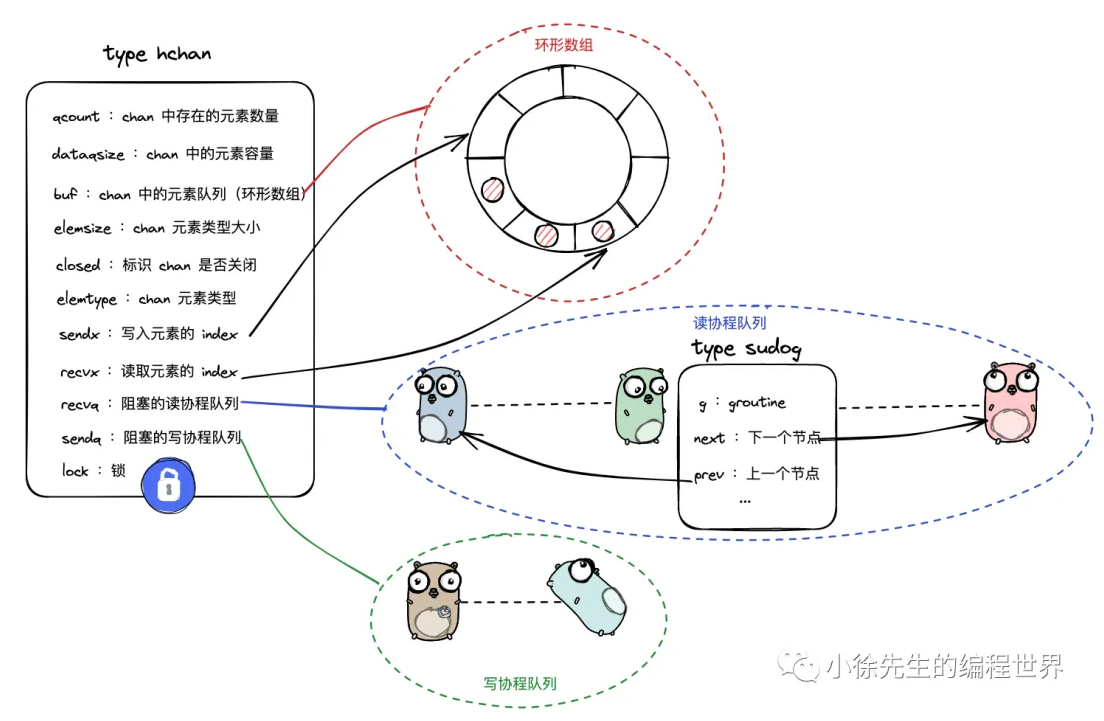
2.1 三个核心组件
① 环形缓冲区(Ring Buffer)
有缓冲 Channel 内部维护一个固定大小的环形队列:
-
buf指向缓冲区内存。 -
sendx和recvx分别记录发送和接收的位置。 -
环形设计能高效利用内存,避免数据搬移。
② 两个等待队列(sendq / recvq)
用双向链表 实现,链表里存的是 sudog 结构体(可以理解为"代表某个 goroutine 的排队号码牌")。
-
sendq:因为 Channel 满了而阻塞的发送者。 -
recvq:因为 Channel 空了而阻塞的接收者。
当条件满足时,Runtime 会唤醒对应的 goroutine。
下面是双向链表的结构体。
type waitq struct {
first *sudog
last *sudog
}waitq:阻塞的协程队列
-
first:队列头部
-
last:队列尾部
type sudog struct {
g *g
next *sudog
prev *sudog
elem unsafe.Pointer // data element (may point to stack)
isSelect bool
c *hchan
}sudog:用于包装协程的节点
-
• g:goroutine,当前协程;
-
• next:队列中的下一个节点;
-
• prev:队列中的前一个节点;
-
• elem: 读取/写入 channel 的数据的容器;
-
• isSelect:标识当前协程是否处在 select 多路复用的流程中;
-
• c:标识与当前 sudog 交互的 chan.
③ 互斥锁(lock)
hchan 内部有一个 mutex。所有对 Channel 的操作(发送、接收、关闭)都要先拿这把锁。
你可能会问:"不是说不共享内存吗?怎么还有锁?"
-
CSP 是对程序员隐藏了锁,你写代码时不用手动加锁。
-
但 Runtime 底层为了保证并发安全,确实用了一把非常轻量的锁。Go 调度器做了大量优化,锁竞争通常不激烈。
2.4 有缓冲 vs 无缓冲 Channel
| 类型 | 创建方式 | 本质 | 特点 |
|---|---|---|---|
| 无缓冲 | make(chan int) |
没有 buf,dataqsiz=0 |
同步通信:发送和接收必须同时发生,一方阻塞等待另一方 |
| 有缓冲 | make(chan int, 6) |
有 buf,dataqsiz=6 |
异步通信:发送方把数据丢进缓冲区就可以走,直到缓冲区满才阻塞 |
三、向 Channel 发送数据的过程是怎样的?
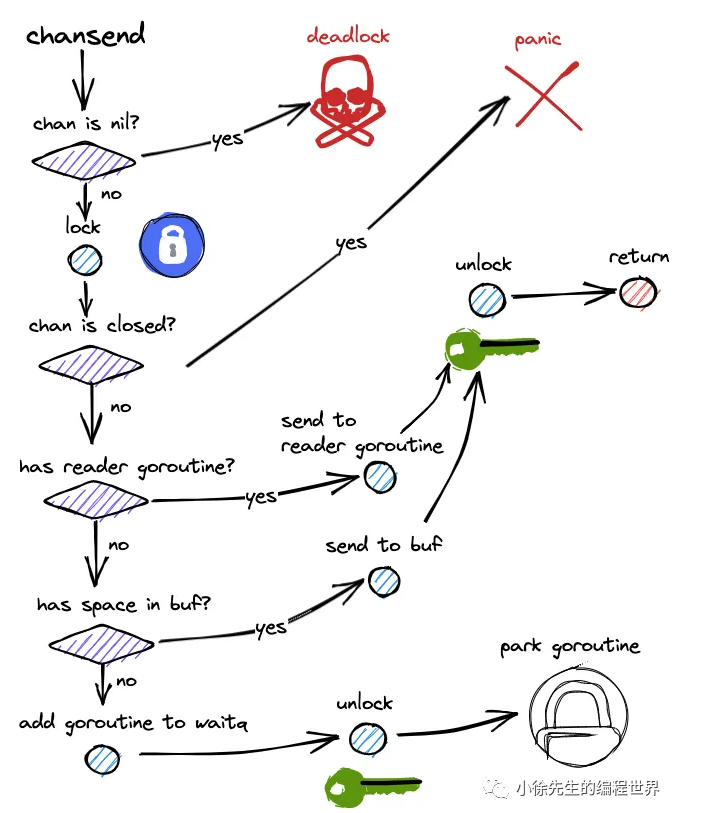
向 Channel 发送数据的整个过程都在 mutex 保护下进行。我把它展开成完整流程:
3.1 第一步:检查是否有等待的接收者(最高效路径)
if recvq 不为空 {
// 有 goroutine 在排队等着接收数据
从 recvq 出队一个 sudog(receiver)
直接把数据拷贝到 receiver 的内存地址
唤醒 receiver goroutine(goready)
return // 发送完成!
}⾸先是检查是否有等待的接收者。如果recvq队列不为空,说明有goroutine在等待接收数据,这时会直接把数据传递给等待的接收者,跳过缓冲区,这是最⾼效的路径。同时会唤醒对应的goroutine继续执⾏。
为什么这是最高效的路径? 因为数据跳过了缓冲区,直接从发送方内存拷贝到接收方内存,没有中间商赚差价。
3.2 第二步:检查缓冲区是否有空间(正常路径)
if qcount < dataqsiz { // 缓冲区没满
把数据拷贝到 buf[sendx] 位置
sendx++
if sendx == dataqsiz { sendx = 0 } // 环形回绕
qcount++
return // 发送完成!
}如果没有等待接收者,就尝试写⼊缓冲区。检查缓冲区是否还有空间,如果qcount < dataqsiz,就把数据复制到bufsendx位置,然后更新sendx索引和qcount计数。这是⽆缓冲或缓冲区未满时的正常流径。
3.3 第三步:阻塞等待(无奈之举)
// 缓冲区满了,或者无缓冲 Channel 没有接收者
把自己打包成一个 sudog
加入 sendq 等待队列
释放 lock
调用 gopark() 让自己进入阻塞状态,把 CPU 让给其他 goroutine当缓冲区满了就需要阻塞等待。创建⼀个sudog结构体包装当前goroutine和要发送的数据,加⼊到sendq等待队列中,然后调⽤gopark让当前goroutine进⼊阻塞状态,让出CPU给其他goroutine。
被唤醒后:
-
当有接收者从 Channel 读取数据后,会从
sendq中唤醒一个等待的发送者。 -
被唤醒的 goroutine 会重新获取 lock,完成数据发送,继续执行。
3.4 特殊情况:向已关闭的 Channel 发送
if closed == 1 {
panic("send on closed channel") // 直接 panic!
}这是 Go 的设计原则:禁止向已关闭的通道写入数据,防止数据混乱。
发送数据的整体流程图:
分析:
package main
import (
"fmt"
"time"
)
func goroutineA(a <-chan int) {
val := <-a
fmt.Println("goroutine A received data: ", val)
return
}
func goroutineB(b <-chan int) {
val := <-b
fmt.Println("goroutine B received data: ", val)
return
}
func main() {
ch := make(chan int)
go goroutineA(ch)
go goroutineB(ch)
ch <- 3
time.Sleep(time.Second)
ch1 := make(chan struct{})
}无缓冲 Channel 的"直接握手"机制
这段代码分析描述的是 Go Channel 里最高效、最特殊 的一条路径------无缓冲 Channel 的 sendq/recvq 直接配对 。很多人第一次看到这里都会懵,因为它涉及到了"一个 goroutine 直接写另一个 goroutine 的栈"。
ch := make(chan int) // 无缓冲!buf 大小为 0
go goroutineA(ch) // A: <-ch,阻塞,进入 recvq
go goroutineB(ch) // B: <-ch,阻塞,进入 recvq
ch <- 3 // 主协程发送执行到 ch <- 3 时,Channel 内部状态:
hchan:
buf: nil (无缓冲,没有 buf)
qcount: 0
sendx: 0
recvx: 0
recvq: [G_A] -> [G_B] (A 先排队,B 后排)
sendq: 空
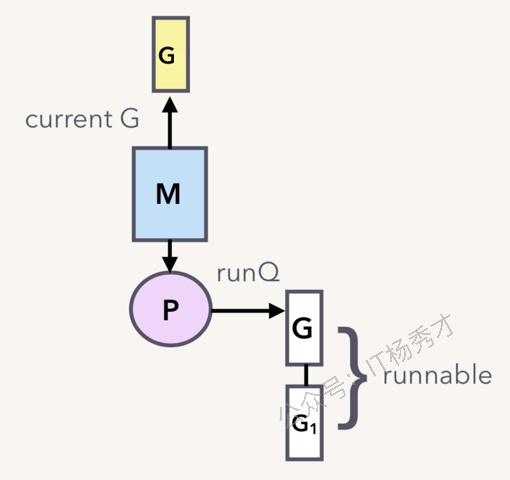
lock: mutex主协程执行 ch <- 3 时,进入 chansend 函数:
// runtime 伪代码
func chansend(ch *hchan, ep unsafe.Pointer) {
lock(&ch.lock)
// 第一步:发现 recvq 里有等待的 receiver!
if sg := ch.recvq.dequeue(); sg != nil {
// 直接拷贝!从 sender 的地址(ep)拷贝到 receiver 的栈地址(sg.elem)
memmove(sg.elem, ep, ch.elemsize)
// 把 receiver(A)加入 P 的可运行队列
goready(sg.g)
unlock(&ch.lock)
return
}
// ... 后面是写 buf 或进 sendq 的逻辑
}关键点在这里:
-
ep指向主协程栈上的3(发送源地址)。 -
sg.elem指向 goroutine A 栈上的val变量(接收目的地址)。 -
memmove(sg.elem, ep, 8)直接把3从主协程的栈 ,拷贝到了G_A 的栈!
sender 发现 ch 的 recvq ⾥有 receiver 在等待着接收,就会出队⼀个 sudog,把 recvq ⾥ first 指针的 sudo "推举"出来了,并将其加⼊到 P 的可运⾏ goroutine 队列中。然后,sender 把发送元素拷贝到 sudog 的 elem 地址处,最后会调⽤ goready 将 G1 唤醒,状态变为 runnable。
正常情况下,goroutine 的栈是私有的,别的 goroutine 不能访问。但此时:
-
两个 goroutine 都通过 Channel 的锁进入了受控状态。
-
Runtime 作为"上帝视角",知道
sg.elem是 G_A 栈上哪个位置。 -
在持有 channel 锁的前提下,Runtime 直接操作内存,完成跨栈拷贝。
这为什么高效?
-
不需要经过
buf中转(无缓冲本来就没 buf)。 -
不需要额外的内存分配。
-
发送方把数据"塞到"接收方手里就完事了,没有二次拷贝。
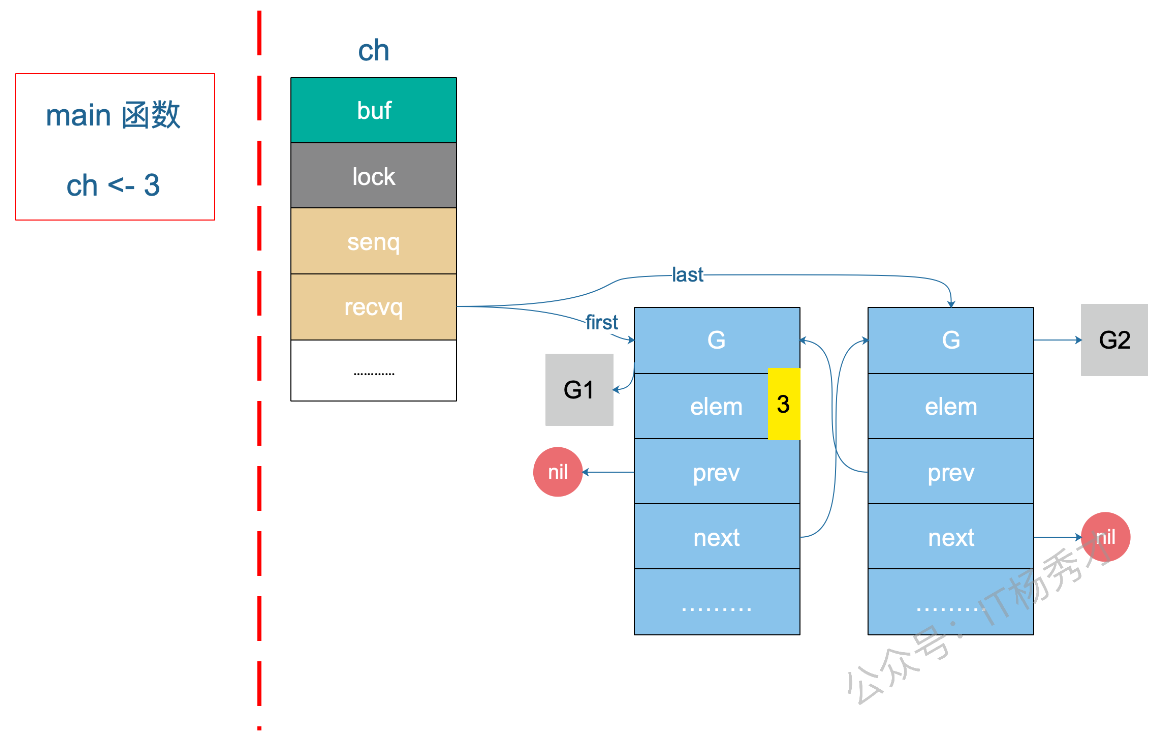
上图是⼀个⽰意图,3 会被拷贝到 G1 栈上的某个位置,也就是 val 的地址处,保存在 elem 字段。
四、从 Channel 读取数据的详细过程
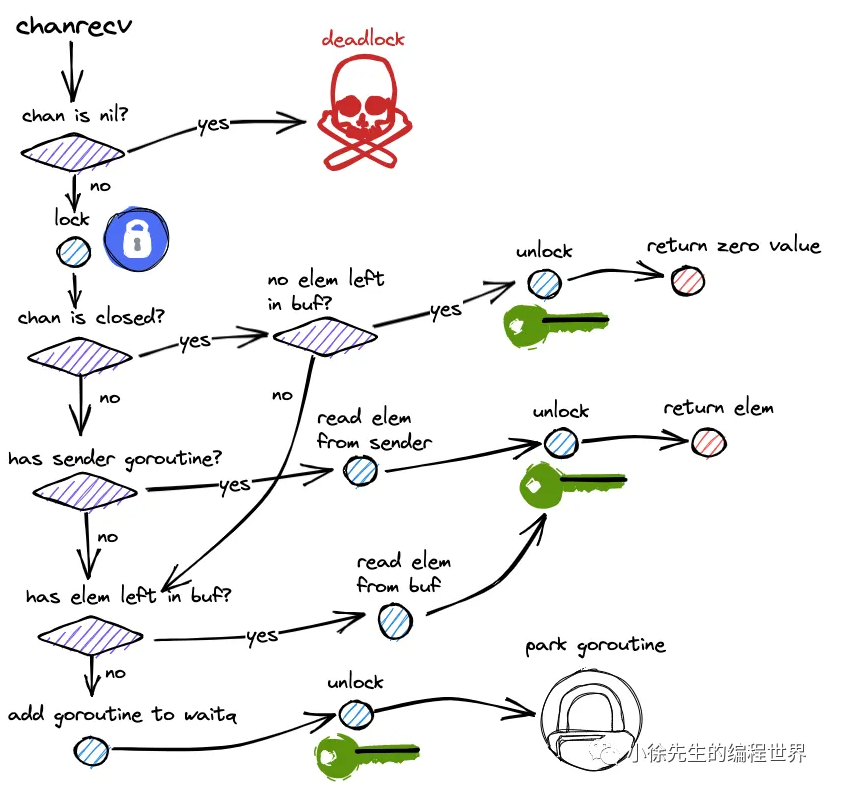
读取过程和发送过程完全对称,也分三步:
4.1 第一步:检查是否有等待的发送者(高效路径)
if sendq 不为空 && 无缓冲或缓冲区为空 {
// 有 goroutine 在排队等着发送数据
从 sendq 出队一个 sudog(sender)
直接把 sender 的数据拷贝到接收变量
唤醒 sender goroutine
return 数据, true
}⾸先检查是否有等待的发送者。如果sendq队列不为空,说明有goroutine在等待发送数据。
对于**⽆缓冲channel**,会直接从发送者那⾥接收数据。
对于有缓冲channel,会先从缓冲区取数据,然后把等待发送者的数据放⼊缓冲区,这样保持FIFO顺序。
4.2 第二步:检查缓冲区是否有数据(正常路径)
if qcount > 0 { // 缓冲区有数据
从 buf[recvx] 位置读取数据
recvx++
if recvx == dataqsiz { recvx = 0 } // 环形回绕
qcount--
return 数据, true
}如果没有等待发送者,尝试从缓冲区读取。检查qcount > 0,如果缓冲区有数据,就从bufrecvx位置取出数据,然后更新recvx索引和qcount计数。这是缓冲区有数据时的正常路径。
4.3 第三步:阻塞等待
// 缓冲区空了
把自己打包成一个 sudog
加入 recvq 等待队列
释放 lock
调用 gopark() 阻塞缓冲区为空时需要阻塞等待。创建sudog结构体包装当前goroutine,加⼊到recvq等待队列,调⽤gopark进⼊阻塞状态。当有发送者写⼊数据时会被唤醒继续执⾏。
**特殊情况:**从已关闭channel读取有特殊处理。如果channel已关闭且缓冲区为空,会返回零值和false标志;如果缓冲区还有数据,可以正常读取直到清空。这就是为什么v, ok := <-ch中的ok能判断channel状态的原因。
读取数据的整体流程图:
(注意:下面这个流程图主要针对的是无缓冲channel。如果是有缓存channel不会走has sender goroutine这一步,其他都是一样的。)
五、向一个已经关闭的 Channel 仍能读出数据吗?
5.1 结论
能! 但分两种情况:
情况 A:Channel 里还有残留数据
ch := make(chan int, 3)
ch <- 1
ch <- 2
close(ch)
v, ok := <-ch // v=1, ok=true
v, ok = <-ch // v=2, ok=true已关闭的 Channel 如果有数据,数据仍然可以正常读出,直到缓冲区被掏空。
情况 B:Channel 已空
v, ok := <-ch // v=0(零值), ok=false-
如果 Channel 已空且已关闭,读取操作不会阻塞 ,而是立刻返回该类型的零值。
-
第二个返回值
ok为false,告诉你 Channel 已经关闭且没数据了。
六、向一个关闭的 Channel 写入数据会发生什么?
6.1 结论
直接 panic!
ch := make(chan int)
close(ch)
ch <- 1 // panic: send on closed channel6.2 为什么这样设计?
如果允许向已关闭的 Channel 写数据,接收方会面临无法判断的混乱:
-
接收方读到数据,这是关闭前残留的?还是关闭后新写入的?
-
关闭语义被破坏,Channel 作为"通信终点"的约定失效。
Go 的原则:关闭 Channel 是发送方的"封笔仪式",封笔后不能再写。
七、关闭 Channel 会产生异常吗?
7.1 正常关闭:不会异常
close(ch) // 正常,没问题7.2 重复关闭:panic
close(ch)
close(ch) // panic: close of closed channel7.3 关闭 nil Channel:panic
var ch chan int // nil channel
close(ch) // panic: close of nil channel7.4 关闭后的行为总结
| 操作 | 未关闭 | 已关闭 |
|---|---|---|
发送 ch <- v |
正常/阻塞 | panic |
接收 <-ch |
正常/阻塞 | 有数据读数据,没数据读零值+ok=false |
close(ch) |
正常 | panic |
最佳实践:
-
谁发送,谁关闭。接收方不要关闭,发送方关闭前确保不再发送。
-
利用
sync.Once保证只关一次:
var once sync.Once
once.Do(func() { close(ch) })深入:关闭 Channel 时的 glist 机制
你问得非常准。关闭 Channel 不是简单地遍历两个队列就唤醒,这里有一个关键的解耦设计。
2.1 关闭 Channel 的完整步骤
func closechan(ch *hchan) {
// 1. 加锁
lock(&ch.lock)
// 2. 标记关闭(之后任何发送都会 panic)
ch.closed = 1
// 3. 创建一个临时链表 glist(sudog 链表)
var glist *sudog
// 4. 把 recvq 里所有等待的 goroutine 全部移到 glist
for sg := ch.recvq.first; sg != nil; sg = sg.next {
ch.recvq.dequeue()
sg.elem = nil // 标记:因为关闭而被唤醒
glist.push(sg)
}
// 5. 把 sendq 里所有等待的 goroutine 全部移到 glist
for sg := ch.sendq.first; sg != nil; sg = sg.next {
ch.sendq.dequeue()
sg.elem = nil // 标记:因为关闭而被唤醒(后续会 panic)
glist.push(sg)
}
// 6. 解锁!
unlock(&ch.lock)
// 7. 在锁外统一唤醒
for sg := glist; sg != nil; sg = sg.next {
goready(sg.g)
}
}2.2 glist 到底是什么?
glist 是一个临时的 sudog 链表 (单链表),作用是收集所有需要唤醒的 goroutine。
2.3 为什么必须先把它们收集到 glist,再统一唤醒?
这是并发设计里的黄金法则:
不要在持有自旋锁/互斥锁的时候,做可能触发调度或执行复杂逻辑的操作。
如果我们在 lock(&ch.lock) 的保护下直接调用 goready():
-
死锁风险 :
goready会修改被唤醒 goroutine 的状态。如果该 goroutine 优先级很高,调度器可能立即切换 去执行它。而这个 goroutine 醒来后可能执行select,试图再次获取同一个 channel 的锁 → 死锁。 -
性能灾难:唤醒操作涉及调度器数据结构(P 的 runqueue),这些操作本身可能很耗时。如果一直持有 channel 的锁,其他想操作这个 channel 的 goroutine 全部阻塞,并发度骤降。
-
状态一致性 :在锁内只负责"修改 channel 内部状态"(标记关闭、清空队列),在锁外再做"通知外部"的事(唤醒 goroutine)。这是典型的**"先修改状态,后通知观察者"**模式。
关闭channel的整体流程图:
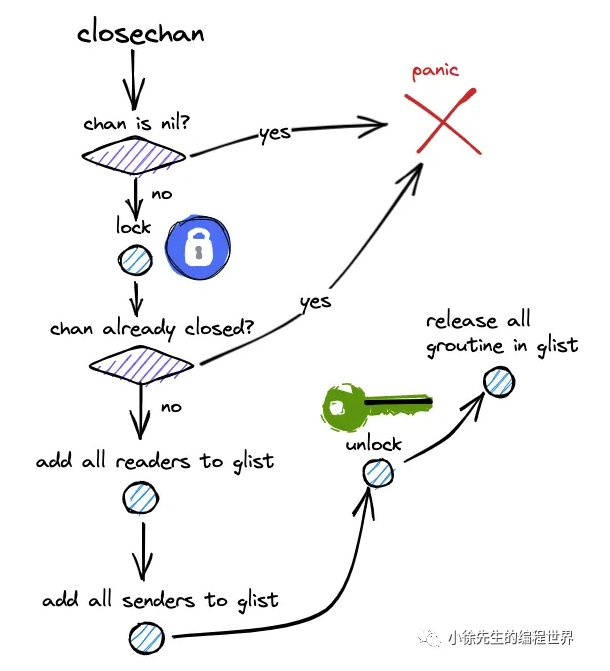
-
关闭未初始化过的 channel 会 panic;
-
加锁;
-
重复关闭 channel 会 panic;
-
将阻塞读协程队列中的协程节点统一添加到 glist;
-
将阻塞写协程队列中的协程节点统一添加到 glist;
-
唤醒 glist 当中的所有协程.
七、Channel 在什么情况下会引起内存泄漏?
Channel 本身不会泄漏,但不当使用 Channel 会导致 goroutine 永久阻塞 ,而阻塞的 goroutine 及其引用的内存无法被 GC 回收,这就是内存泄漏。
7.1 场景一:发送方无接收者
func leak() {
ch := make(chan int)
go func() {
ch <- 1 // 永远没人收,这个 goroutine 永远卡在 sendq
}()
// 函数返回,ch 不再被引用?不!goroutine 还持有 ch 的引用!
}结果: 匿名 goroutine 永远挂在 sendq 上,无法被调度执行,也无法被 GC。
7.2 场景二:接收方无发送者
func leak() {
ch := make(chan int)
go func() {
<-ch // 永远没人发,这个 goroutine 永远卡在 recvq
}()
}7.3 场景三:select 中未处理关闭
for {
select {
case v := <-ch:
// 处理 v
}
// 如果 ch 再也没数据且永不关闭,这个循环永远阻塞在 select
}7.4 如何避免?
-
确保成对出现:有发送就要有接收,有接收就要有发送。
-
使用
context或donechannel 做退出通知。 -
设置缓冲区:适当缓冲可以解耦发送和接收的时间差。
-
及时关闭 :发送方完成后主动
close(ch),让接收方感知到结束。
九、什么是 select?
9.1 一句话定义
select 是 Go 提供的 Channel 多路复用(Multiplexing) 机制,让你可以同时监听多个 Channel 操作,哪个就绪就执行哪个。
9.2 生活类比
想象你是快递站的站长,面前有 5 个不同公司的快递柜(5 个 Channel):
-
你不需要盯着某一个一直等。
-
只要任意一个 快递柜有包裹到了(有数据可读),或者任意一个快递柜有空位了(可以写入),你就去处理那个。
-
如果多个快递柜同时有动静,
select随机挑一个处理,避免总是优先某一个导致"饥饿"。
9.3 基本语法
select {
case v := <-ch1: // 尝试从 ch1 读
fmt.Println("ch1:", v)
case ch2 <- 100: // 尝试向 ch2 写
fmt.Println("sent to ch2")
case <-done: // 收到退出信号
return
default: // 非阻塞分支(可选)
fmt.Println("none ready")
}十、select 的底层实现原理是什么?
select 不是简单的语法糖,编译器会把它翻译成复杂的 Runtime 调用。核心涉及两个结构:
10.1 scase 结构体
每个 case 语句会被编译器打包成一个 scase:
type scase struct {
c *hchan // 指向哪个 channel
elem unsafe.Pointer // 数据指针(发送或接收的地址)
kind uint16 // 类型:send / recv / default
}10.2 selectgo 函数
编译器把所有 scase 收集成一个数组,调用 runtime.selectgo():
func selectgo(cases []scase, order0 []uint16, order1 []uint16) (int, bool)10.3 两个关键顺序数组
为了避免死锁 和实现随机选择 ,selectgo 会生成两个随机顺序:
| 数组 | 作用 |
|---|---|
pollorder |
遍历 case 的随机顺序(决定先检查哪个 channel) |
lockorder |
给 channel 加锁的固定顺序(从小到大排序地址,避免循环死锁) |
为什么需要 lockorder? 如果 select 同时操作多个 channel,需要给它们加锁。如果不同 goroutine 加锁顺序不同,会产生死锁。lockorder 按 channel 地址排序后依次加锁,全局统一,死锁消除。
10.4 为什么需要 pollorder 和 lockorder?
想象你要在 5 个银行窗口(channel)同时排队办业务:
| 数组 | 解决的问题 | 比喻 |
|---|---|---|
pollorder |
公平性:多个窗口同时叫号,我该先去哪个? | 你手里的"随机叫号单",决定你先看哪个窗口 |
lockorder |
死锁避免:如果多个顾客都在多个窗口排队,怎么防止大家互相卡住? | 银行规定的"必须按窗口编号从小到大依次刷卡进门"的规则 |
pollorder 详解
cases := []scase{ch1, ch2, ch3} // 3 个 case
pollorder := []uint16{2, 0, 1} // 随机打乱:先检查 ch3,再 ch1,再 ch2-
每次
select执行时,pollorder都是随机生成的。 -
在 Fast Path 中,按照这个随机顺序检查 channel 是否就绪。
-
目的 :防止
ch1总是排在数组第一个,导致它被优先选中,让ch2、ch3饥饿。
lockorder 详解
lockorder := []uint16{0, 2, 1} // 按 channel 内存地址从小到大排序-
select可能需要同时给多个 channel 加锁(Slow Path)。 -
如果 goroutine A 按
ch1→ch2顺序加锁,goroutine B 按ch2→ch1顺序加锁,可能死锁。 -
强制所有 goroutine 按channel 指针地址的全局顺序加锁,彻底消除循环等待。
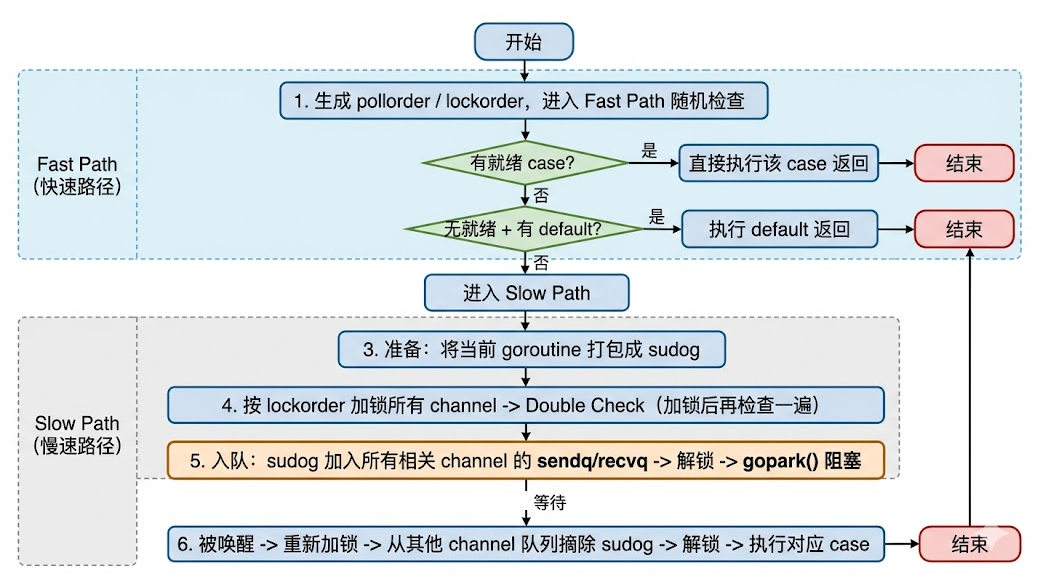
10.5 第一阶段:Fast Path(快速路径)
func selectgo(cases []scase, pollorder, lockorder []uint16) (int, bool) {
// 1. 按照 pollorder(随机顺序),逐个检查 case
for i := 0; i < len(cases); i++ {
cas := cases[pollorder[i]]
// 尝试非锁定快速检查
if cas.kind == CaseRecv && cas.c.readyToRecv() {
// ch 有数据可读了!直接执行这个 case
return cas.index, true
}
if cas.kind == CaseSend && cas.c.readyToSend() {
// ch 有空位可写了!直接执行这个 case
return cas.index, true
}
if cas.kind == CaseDefault {
// 有 default 且前面都没就绪,执行 default
return cas.index, false
}
}
// 快速路径失败,进入慢速路径...
}核心思想: 大部分 select 在执行时,其实只有一个或零个 case 就绪。Fast Path 试图在不加锁或轻量加锁的情况下快速命中,避免昂贵的全量排队逻辑。
10.6 第二阶段:Slow Path(慢速路径)
为了让你彻底理解,我用一个生活比喻贯穿全程:
你要在 3 家热门餐厅 (ch1, ch2, ch3)同时排队等位。
select就是那个帮你"同时排多家、哪家先到吃哪家"的智能助手。
阶段一:准备(在锁外面做)
第 1 步:把当前 goroutine 打包成 sudog
gp := getg() // 获取当前 goroutine
sudog := acquireSudog()
sudog.g = gp
sudog.elem = ... // 发送/接收的内存地址比喻: 你先把自己的手机号(sudog)填好,准备留给餐厅。此时你还没进任何餐厅,只是在门口整理资料。
阶段二:加锁 & Double Check(最关键!)
第 2 步:按照 lockorder 给所有涉及的 channel 加锁
// lockorder 是按 channel 内存地址从小到大排序的
for i := 0; i < ncases; i++ {
lock(&cases[lockorder[i]].c.lock)
}比喻: 你按门牌号从小到大,依次进入 3 家餐厅。这是银行家算法,防止两个顾客交叉进门导致死锁。
第 2.5 步:Double Check(再次检查)
// 加锁后,再次按 pollorder 检查所有 case
for i := 0; i < ncases; i++ {
cas := cases[pollorder[i]]
if cas.ready() { // 某个 channel 现在就有数据/空位了!
// 直接执行这个 case!
unlockAll() // 解锁所有餐厅
return cas.index, true
}
}为什么需要 Double Check? 因为在你准备 sudog 和加锁的这段时间里,其他 goroutine 可能已经往某个 channel 发了数据。如果不检查就直接去排队,你就错过了"刚好有空位"的机会,白白阻塞。
比喻: 你按顺序进了 3 家餐厅,在登记排队前,先问一句"现在有没有空位?"------可能刚好上一秒有人取消预约,你直接就能吃,不用回家等电话了。
阶段三:入队 & 阻塞
第 3 步:把 sudog 加入所有相关 channel 的等待队列
for i := 0; i < ncases; i++ {
cas := cases[i]
c := cas.c
if cas.kind == CaseRecv {
c.recvq.enqueue(sudog) // 在餐厅1留下手机号(等叫号)
} else {
c.sendq.enqueue(sudog) // 在餐厅2留下手机号
}
}
// 注意:sudog 通过链表节点,同时存在于多个 channel 的队列中!比喻: 3 家餐厅你都留下了同一个手机号。任何一家有空位了都会打这个电话。
第 4 步:释放所有锁,调用 gopark() 阻塞
unlockAll() // 依次解锁所有 channel
gopark() // 当前 goroutine 进入阻塞状态,CPU 让给别人比喻: 登记完手机号,你退出所有餐厅 (解锁),回家睡觉(gopark)。餐厅门口不再堵着你,其他顾客可以正常进出。
阶段四:唤醒 & 清理
第 5 步:当任意一个 channel 就绪时,唤醒该 goroutine
假设 ch2 来了数据,ch2 的 chanrecv 发现 recvq 里有你的 sudog:
// 在 ch2 的 channel 操作内部:
sg := ch.recvq.dequeue() // 把你的手机号从队列取出
memmove(sg.elem, ...) // 拷贝数据
goready(sg.g) // 打电话叫醒你比喻: 餐厅 2 有空位了,给你打电话。你从睡梦中醒来。
第 5.5 步:醒来后,重新按 lockorder 给所有 channel 加锁
for i := 0; i < ncases; i++ {
lock(&cases[lockorder[i]].c.lock)
}为什么醒来后还要加锁? 因为你接下来要做清理工作(告诉其他餐厅"我不排了"),而修改餐厅的排队名单(队列)必须加锁保护。
比喻: 你被餐厅 2 叫醒了,但你在餐厅 1 和 3 还留着手机号。你必须再次进入这 3 家餐厅(加锁),去注销你的预约。
第 6 步:把自己从其他所有 channel 的等待队列中摘除
for i := 0; i < ncases; i++ {
cas := cases[i]
c := cas.c
if cas.kind == CaseRecv {
c.recvq.remove(sudog) // 从其他餐厅撤掉手机号
} else {
c.sendq.remove(sudog)
}
}为什么必须摘除?
-
你同时在 3 个 channel 的队列里。
-
ch2 唤醒了你,但 ch1 和 ch3 不知道。
-
如果 ch1 之后也来数据了,它会尝试再次唤醒你(重复唤醒)。
-
或者 ch1 关闭时,会遍历
recvq唤醒所有人,你又会收到一次"假叫醒"。
比喻: 你确定去餐厅 2 吃饭了,就必须把餐厅 1 和 3 的预约全部取消。否则它们之后叫号还会打你电话,你就懵了。
第 7 步:执行对应的 case
unlockAll() // 退出所有餐厅
return chosenIndex, true // 去餐厅 2 吃饭!
select的 Slow Path 就是:先同时给所有 channel 上锁,确认真的没就绪后,把自己的号码同时塞进所有 channel 的排队系统;然后解锁回家睡觉;被叫醒后,再依次进入所有 channel 注销其他排队,最后只执行一家。
select执行的整体的流程图:
10.7 为什么 select 是"随机公平"的?
Go 故意设计为随机选择就绪的 case,防止某个 channel 总是优先被选中,导致其他 channel 的 goroutine "饿死"。
示例验证:
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
// 准备充足的弹药,确保 10 次 select 都有数据可读
ch1 := make(chan int, 20)
ch2 := make(chan int, 20)
for i := 0; i < 10; i++ {
ch1 <- 1
ch2 <- 2
}
// 设置随机种子,让 select 的随机性更明显(Go 1.20+ 已自动处理,显式设置更保险)
rand.Seed(time.Now().UnixNano())
for i := 0; i < 10; i++ {
select {
case <-ch1:
fmt.Println("ch1")
case <-ch2:
fmt.Println("ch2")
}
}
}输出不是固定的 ch1, ch2, ch1, ch2...,而是随机交错的。
十一,思考题:无缓冲 Channel 的 sendq 和 recvq,可能同时非空吗?为什么?
不可能同时非空。
11.1 证明
假设无缓冲 Channel 的 sendq 和 recvq 同时非空:
-
sendq非空 → 有 sender 在等。 -
recvq非空 → 有 receiver 在等。
但无缓冲 Channel 的核心规则是:
-
Sender 来了 ,先看
recvq。如果recvq非空,直接配对,sender 不会进入sendq。 -
Receiver 来了 ,先看
sendq。如果sendq非空,直接配对,receiver 不会进入recvq。
所以,只要对方队列有人,你就直接握手了,根本没机会进自己的队列。
11.2 补充:所有 Channel 都满足这个性质
其实不仅无缓冲 Channel,任何 Channel 的 sendq 和 recvq 都不会同时非空:
| 场景 | 结果 |
|---|---|
| 有缓冲,buf 未满 | Sender 写 buf,不进入 sendq |
| 有缓冲,buf 非空 | Receiver 读 buf,不进入 recvq |
| 有缓冲,buf 满 | Sender 进 sendq,但此时 receiver 可以直接读 buf,不会进 recvq |
| 有缓冲,buf 空 | Receiver 进 recvq,但此时 sender 可以直接写 buf,不会进 sendq |
如果真的出现同时非空(理论上不可能,除非 Runtime 有 bug),确实意味着系统卡死了,因为双方都在等对方唤醒自己。
十二,思考题:select 里有 default 分支和没 default 分支,在底层行为上有什么本质区别?
这是阻塞 vs 非阻塞的分水岭。
12.1 没有 default
select {
case v := <-ch1:
// ...
case ch2 <- 100:
// ...
}底层行为:
-
Fast Path 没找到就绪 case → 必须进入 Slow Path。
-
当前 goroutine 会阻塞(gopark)。
-
会被挂到 ch1 和 ch2 的等待队列上。
-
等待被其他 goroutine 唤醒。
本质: 这是阻塞式多路等待 ,和单独写 <-ch1 一样会阻塞,只是多了几个备选。
12.2 有 default
select {
case v := <-ch1:
// ...
case ch2 <- 100:
// ...
default:
// ...
}底层行为:
-
Fast Path 没找到就绪 case → 检查 default。
-
如果有 default,直接执行 default,函数立即返回。
-
不会进入 Slow Path,不会阻塞,不会加入任何等待队列。
本质: 这是非阻塞轮询 ,和 default 一起构成了 Go 里的 "try-send" / "try-recv" 语义。
12.3 对比表
| 特性 | 无 default | 有 default |
|---|---|---|
| 是否阻塞 | 可能阻塞 | 永不阻塞 |
| Fast Path 失败后的行为 | 进入 Slow Path,挂起 | 执行 default,返回 |
| 是否创建 sudog | 是 | 否 |
| 是否加入 channel 队列 | 是 | 否 |
| 适用场景 | 必须等到某个 channel 就绪 | 轮询,立刻做其他事 |
生活比喻:
无 default :你去 3 个窗口排队,必须等到其中一个办完业务,否则一直在那等。
有 default :你去 3 个窗口看了一眼,都没人理你,那你转身就走(default),不浪费时间等待。
十三,思考:select里面本身就会有多个channel监听,每个channel如果都没有就绪,本身可能就会进入到一个recvq或者sendq队列,这个时候当前的 goroutine进入recvq或者sendq队列,怎么保证先唤醒的一定是当前goroutine呢?
这是一个非常经典的误解。 实际上,Runtime 不需要、也不保证 "先唤醒当前 goroutine"。你的问题里隐含了一个假设:"多个 goroutine 在竞争,要确保我排在前面",但 select 的场景是反过来的:
13.1 先分清两个完全不同的场景
| 场景 | 图示 | 唤醒逻辑 |
|---|---|---|
| 场景 A:多个 goroutine 抢一个 channel | G1, G2, G3 都在 ch 的 recvq 里排队 |
channel 就绪时,唤醒队首(FIFO),G1 先被唤醒 |
| 场景 B:一个 goroutine 在多个 channel 等待(select) | 同一个 G 同时在 ch1.recvq, ch2.recvq, ch3.sendq 里 |
任意一个 channel 就绪,就唤醒这个 G |
select机制 属于 场景 B。
13.2 场景 B 的唤醒机制
假设你的 select 监听了 ch1 和 ch2:
ch1.recvq: [G_select] → nil
ch2.recvq: [G_select] → nil注意:G_select 的同一个 sudog 节点,通过链表指针,同时挂在两个队列里。
当 ch1 来了数据,执行 chanrecv 时:
// ch1 的接收逻辑内部
if sg := ch1.recvq.dequeue(); sg != nil {
// sg 就是 G_select 的 sudog
memmove(sg.elem, src, size)
goready(sg.g) // 唤醒 G_select
return
}关键点:
-
ch1不会问"你是不是在别的 channel 也排队了",它只管自己的recvq。 -
ch1的recvq是 FIFO 队列。如果G_select是队首,它就会被唤醒。 -
如果
ch1的recvq里还有其他 goroutine(比如另一个普通的<-ch1),那么G_select必须排在它们后面,按顺序唤醒。
13.3 所以"保证"的是什么?
Runtime 保证的是:
-
每个 channel 自己的队列是 FIFO:先排队的先被唤醒。
-
select 的 goroutine 只要排在某个 channel 队列的队首,且该 channel 就绪,它就会被唤醒。
-
不需要"优先权" :因为
select的设计就是"哪个 channel 先到吃哪个",不是"我一定要比别人先"。
13.4 一个可能的误区:如果两个 channel 同时就绪呢?
假设 ch1 和 ch2 同时有数据,且 G_select 在两个队列中都是队首:
-
ch1的chanrecv先执行,唤醒G_select。 -
ch1把G_select从自己的队列中移除。 -
G_select醒来后,会从ch2的队列中也摘除自己。 -
即使
ch2也想唤醒它,发现sudog已经被标记为"已唤醒",会跳过。
这就是为什么醒来后必须"从其他所有队列摘除"的原因------防止重复唤醒导致的混乱。
十四,思路:gopark() 和 goready() 做了什么?
这是 Go GMP 调度模型 的核心原语,理解它们等于拿到了调度器的钥匙。
14.1 gopark() ------ 让当前 goroutine 去"睡觉"
作用
让当前执行的 goroutine 主动放弃 CPU ,进入阻塞状态 (_Gwaiting),从所在的线程(M)上剥离。
底层发生了什么?
// 伪代码
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason) {
// 1. 获取当前 goroutine
gp := getg()
// 2. 修改状态:从 _Grunning(正在跑)变成 _Gwaiting(等待中)
casgstatus(gp, _Grunning, _Gwaiting)
// 3. 记录为什么阻塞(比如 waitReasonChanSend)
gp.waitreason = reason
// 4. 把 gp 和 M 解绑
// 这个 M(线程)可以去跑别的 goroutine 了
dropg()
// 5. 调用 unlockf(通常是释放 channel 的锁)
if unlockf != nil {
unlockf(gp, lock)
}
// 6. 调度器!请安排别的 goroutine 来这个 M 上执行
schedule()
}14.2 goready() ------ 叫醒某个 goroutine
作用
把指定的 goroutine 从等待状态 (_Gwaiting)改为可运行状态 (_Grunnable),放入调度器的运行队列,等待被调度执行。
底层发生了什么?
// 伪代码
func goready(gp *g, traceskip int) {
// 1. 修改状态:从 _Gwaiting 变成 _Grunnable
casgstatus(gp, _Gwaiting, _Grunnable)
// 2. 放到 P(Processor)的本地运行队列
runqput(_g_.m.p.ptr(), gp, next)
// 3. 如果全局队列或本地队列有空位,尝试唤醒一个空闲的 M 来执行
// (如果所有 M 都在忙,就等现有的 M 轮询到它)
wakep()
}