文章目录
一、归并排序🌟🌟
1.1、基本思想与分析
归并排序算法思想:
归并排序 是建立在归并操作上的一种有效的排序算法,该算法是采用分治法 的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
图解如下:
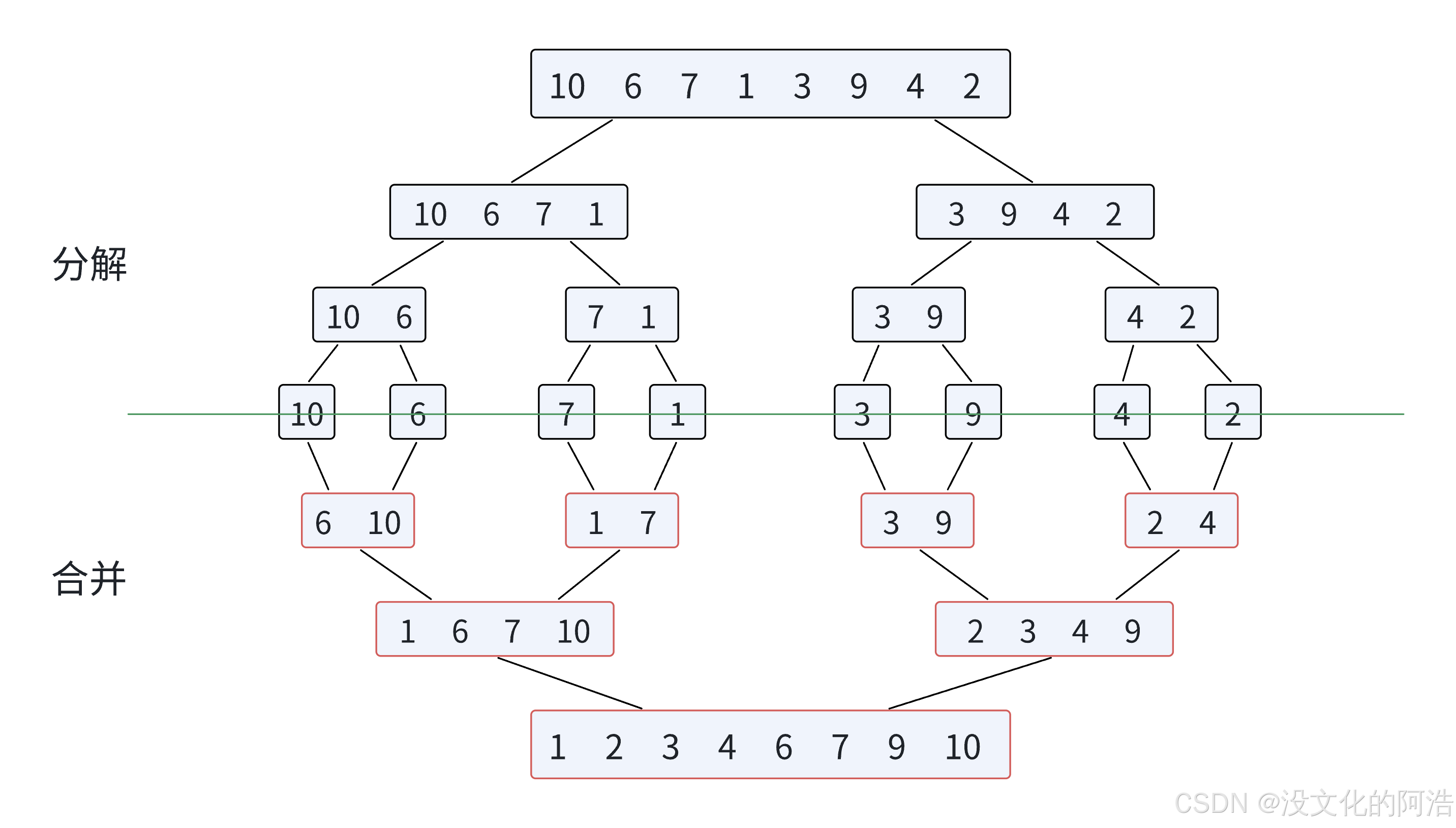
1.2、递归版归并排序
1.2.1、代码实现💻
cpp
// 归并排序
void _MergeSort(std::vector<int>& v, int left, int right, std::vector<int>& tmp)
{
if (left >= right)
{
return;
}
int mid = left + (right - left) / 2;
_MergeSort(v, left, mid, tmp);
_MergeSort(v, mid + 1, right, tmp);
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
//合并两个有序数组
int i = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (v[begin1] <= v[begin2])
{
tmp[i++] = v[begin1++];
}
else {
tmp[i++] = v[begin2++];
}
}
if (begin1 > end1)
{
while (begin2 <= end2)
{
tmp[i++] = v[begin2++];
}
}
if (begin2 > end2)
{
while (begin1 <= end1)
{
tmp[i++] = v[begin1++];
}
}
for (int i = left; i <= right; i++)
{
v[i] = tmp[i];
}
}
void MergeSort(std::vector<int>& v)
{
std::vector<int> tmp = v;
_MergeSort(v, 0, v.size() - 1, tmp);
}1.2.2、复杂度分析
归并排序的内部使用了递归,递归的时间复杂度为O(logn);而递归内部循环遍历数组,时间复杂度为O(n)。
根据递归函数的时间复杂度公式可知,归并排序的时间复杂度为O(nlogn)。
此外,我们额外开辟了O(n)的内存空间,此外,递归建立栈帧使用了O(logn)的栈空间,因此空间复杂度为O(n + logn) , 即O(n)。
1.3、非递归版归并排序
1.3.1、简单分析
非递归版本的归并排序,并没有像递归版本一样,将待排序数组不断二分,而是自底向上 式的两两一组,进行排序。
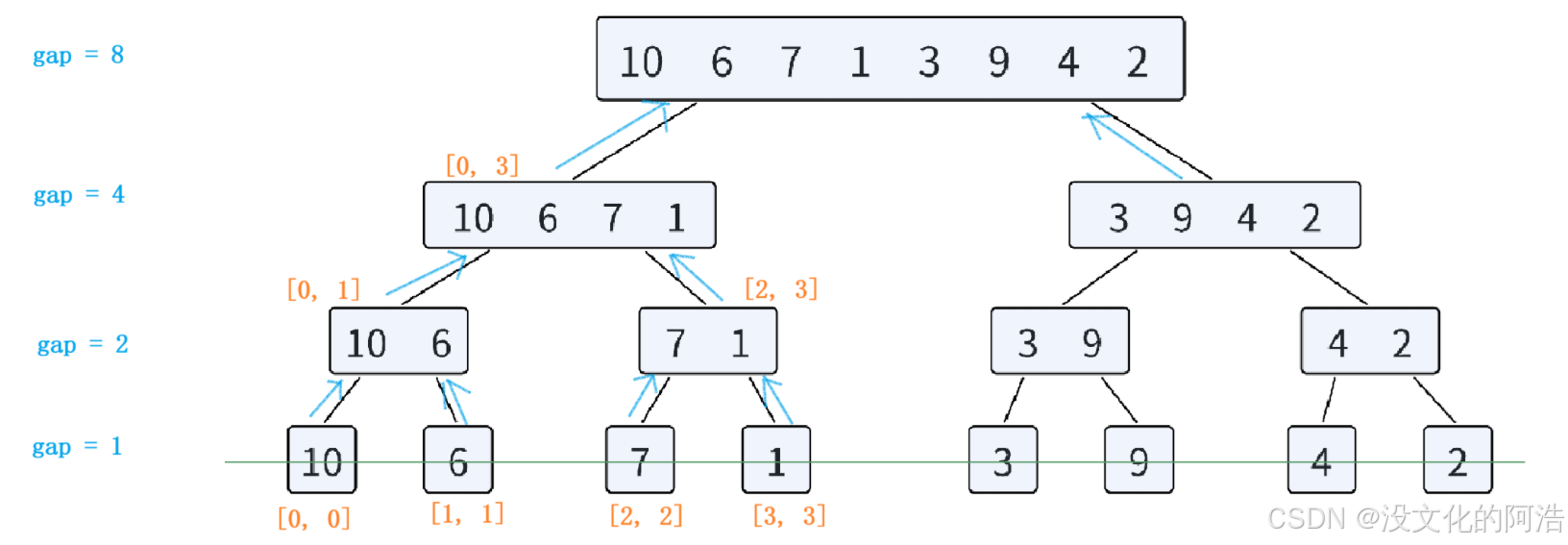
还有一些细节问题,在代码中展示。
1.3.2、代码实现💻
cpp
//非递归版
void MergeSort(std::vector<int>& v)
{
int n = v.size();
std::vector<int> tmp(n);
int gap = 1;
while (gap < n)
{
// gap == n时,表示已经排好了
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
// std::cout << end2 << std::endl;
if (begin2 >= n)
{
//跳出循环,不管【begin1, end1】部分了,即使end1也越界
break;
}
if (end2 >= n)
{
//后续的不够gap个元素
end2 = n - 1;
}
//合并两个有序数组
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (v[begin1] <= v[begin2])
{
tmp[index++] = v[begin1++];
}
else
{
tmp[index++] = v[begin2++];
}
}
if (begin1 > end1)
{
while(begin2 <= end2)
tmp[index++] = v[begin2++];
}
if (begin2 > end2)
{
while (begin1 <= end1)
tmp[index++] = v[begin1++];
}
// 将tmp放回v中
for (int k = i; k <= end2; k++)
{
v[k] = tmp[k];
}
}
gap *= 2;
}
}二、计数排序
2.1、基本思想与分析
计数排序又称为鸽巢原理 ,是对哈希直接定址法的变形应用。
鸽巢原理(抽屉原理),简单来说:如果把多于 n 个东西放进n 个抽屉里,那至少有一个抽屉里会放至少两个东西。
它与我们先前所介绍的七种排序方式有所区别,计数排序属于非比较排序 ,而先前介绍的七种排序均属于比较排序。
图解如下:
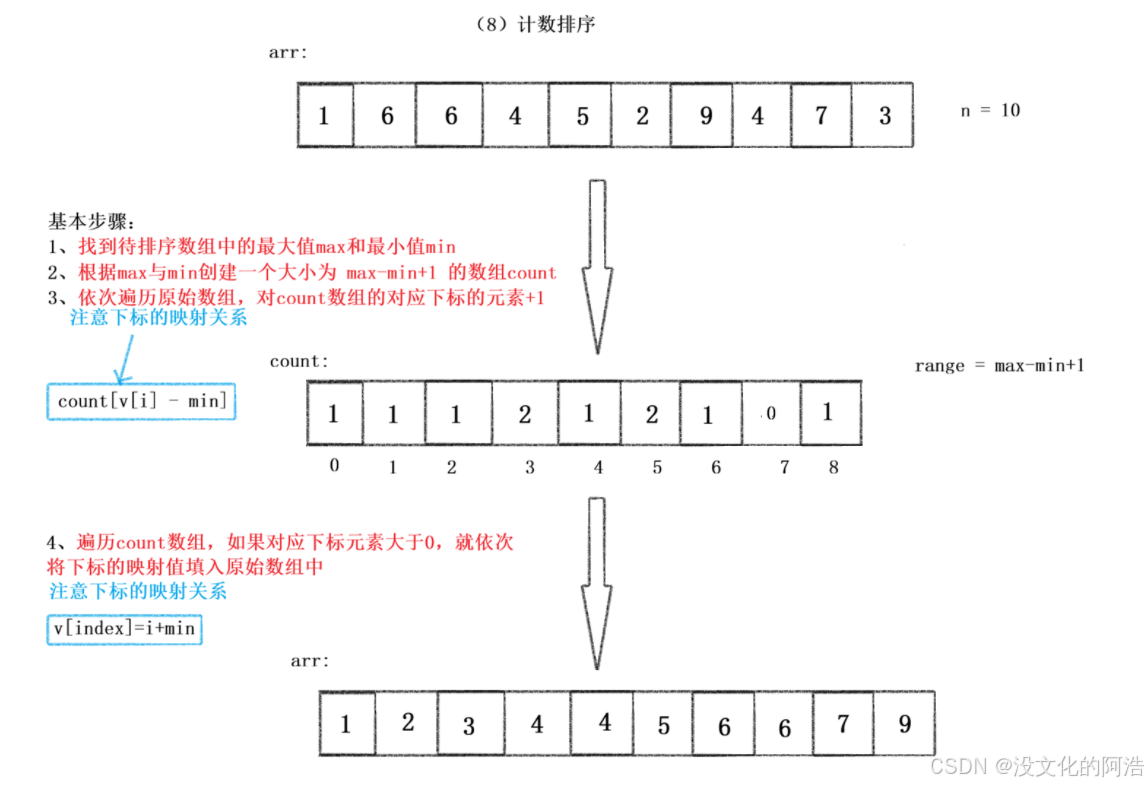
2.2、代码实现💻
cpp
// 计数排序
void CountSort(std::vector<int>& v)
{
int Max = v[0], Min = v[0];
for (int i = 1; i < v.size(); i++)
{
if (Max < v[i]) Max = v[i];
if (Min > v[i]) Min = v[i];
}
int range = Max - Min + 1;
std::vector<int> count(range);
for (int i = 0; i < v.size(); i++)
{
count[v[i] - Min]++;
}
int index = 0;
for (int i = 0; i < range; i++)
{
while (count[i] > 0)
{
count[i]--;
v[index++] = i + Min;
}
}
}2.3、复杂度分析
很显然,计数排序的时间复杂度为O(n + range), 空间复杂度为O(range)。
计数排序的应用场景十分局限,在数据范围集中的时候效率较高,当数据范围差距过大时,容易造成不不必要的空间浪费。
三、八大排序的时间复杂度和稳定性分析
至此,我们已经讲完了八大排序的所以内容🥳🥳
需要了解其余六个,可以转至:
【数据结构】排序(1)------直接插入排序&希尔排序
【数据结构】排序(2)------直接选择排序、堆排序
【数据结构】排序(3)------冒泡排序、快速排序
接下来,我们首先介绍一下:什么是稳定性。
稳定性 :假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变 ,即在原序列中,ri=rj,且ri在rj之前,而在排序后的序列中,ri仍在rj之前,则称这种排序算法是稳定的 ;否则称为不稳定的。
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 直接选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 直接插入排序 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 希尔排序 | O(n * logn) ~ O(n^2) | O(n^1.3) | O(n^2) | O(1) | 不稳定 |
| 堆排序 | O(n * logn) | O(n * logn) | O(n * logn) | O(1) | 不稳定 |
| 归并排序 | O(n * logn) | O(n * logn) | O(n * logn) | O(n) | 稳定 |
| 快速排序 | O(n * logn) | O(n * logn) | O(n^2) | O(log n) ~ O(n) | 不稳定 |
| 计数排序 | O(n) | O(n) | O(n) | O(range) | 稳定 |
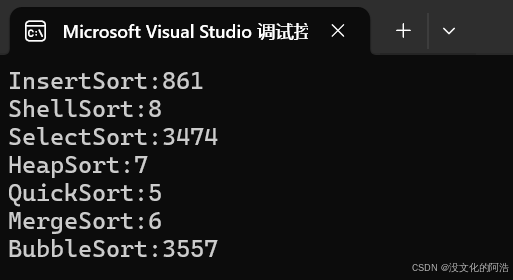
为了更加直观的看出各个排序之间的效率差异,我们可以在自己的平台上执行这样一段测试代码:
cpp
void TestOP()
{
srand(time(0));
const int N = 100000;
std::vector<int> a1(N), a2(N), a3(N), a4(N), a5(N), a6(N), a7(N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1);
int end1 = clock();
int begin2 = clock();
ShellSort(a2);
int end2 = clock();
int begin3 = clock();
SelectSort(a3);
int end3 = clock();
int begin4 = clock();
HeapSort(a4);
int end4 = clock();
int begin5 = clock();
QuickSort(a5, 0, N - 1);
int end5 = clock();
int begin6 = clock();
MergeSort(a6);
int end6 = clock();
int begin7 = clock();
BubbleSort(a7);
int end7 = clock();
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
printf("BubbleSort:%d\n", end7 - begin7);
}其中,clock()返回的是:程序执行到此语句所花费的时间。
由于数据量较大,我们在VS2022上可以将编译器改为Release模式,加快效率。
最终可以得到以下的执行结果:结果每次都可能会有些许差距,属于正常情况
完🍸🍸🍸