1. 定位导航
前面已经建立了一个基本认识:算法不是代码本身,而是一组明确、有限、可执行的求解步骤。
这一篇开始进入第一个具体算法:插入排序。
它适合用来训练三个基础能力:
- 如何把一个自然动作抽象成算法步骤;
- 如何用伪代码描述算法;
- 如何分析一个算法为什么正确、为什么有快慢差异。
插入排序虽然不是大规模排序中的最优选择,但它非常适合作为入门算法,因为它足够直观,而且能自然引出后续非常重要的概念:循环不变式。
2. 概念术语
| 术语 | 定义 | 举例 |
|---|---|---|
| 插入排序 | 每次取出一个新元素,插入到左侧有序区的正确位置 | [5,2,4] → [2,4,5] |
| 有序区 | 当前已经排好序的部分 | 数组左侧若干元素 |
| 待处理区 | 还没有被正式插入排序的部分 | 数组右侧若干元素 |
| key | 当前要插入的元素 | 当前轮拿出来的数字 |
| 向右移动 | 为 key 腾出插入位置 | 大于 key 的元素右移一格 |
| 循环不变式 | 每轮循环前后都保持成立的性质 | 左侧区间始终有序 |
| 原地排序 | 不依赖额外大数组,在原数组中完成排序 | 插入排序是原地排序 |
| 稳定排序 | 相等元素排序后相对顺序不变 | 标准插入排序是稳定的 |
关键澄清:
- 插入排序不是"交换排序"的典型代表,它更像是"移动并插入"。
- 插入排序适合小规模数据或近乎有序的数据。
- 插入排序最坏情况下很慢,但在某些场景下非常实用。
3. 插入排序的核心直觉
插入排序的思路可以这样理解:
text
左边:已经排好序
右边:还没有处理
每次从右边拿一个元素,插入到左边正确位置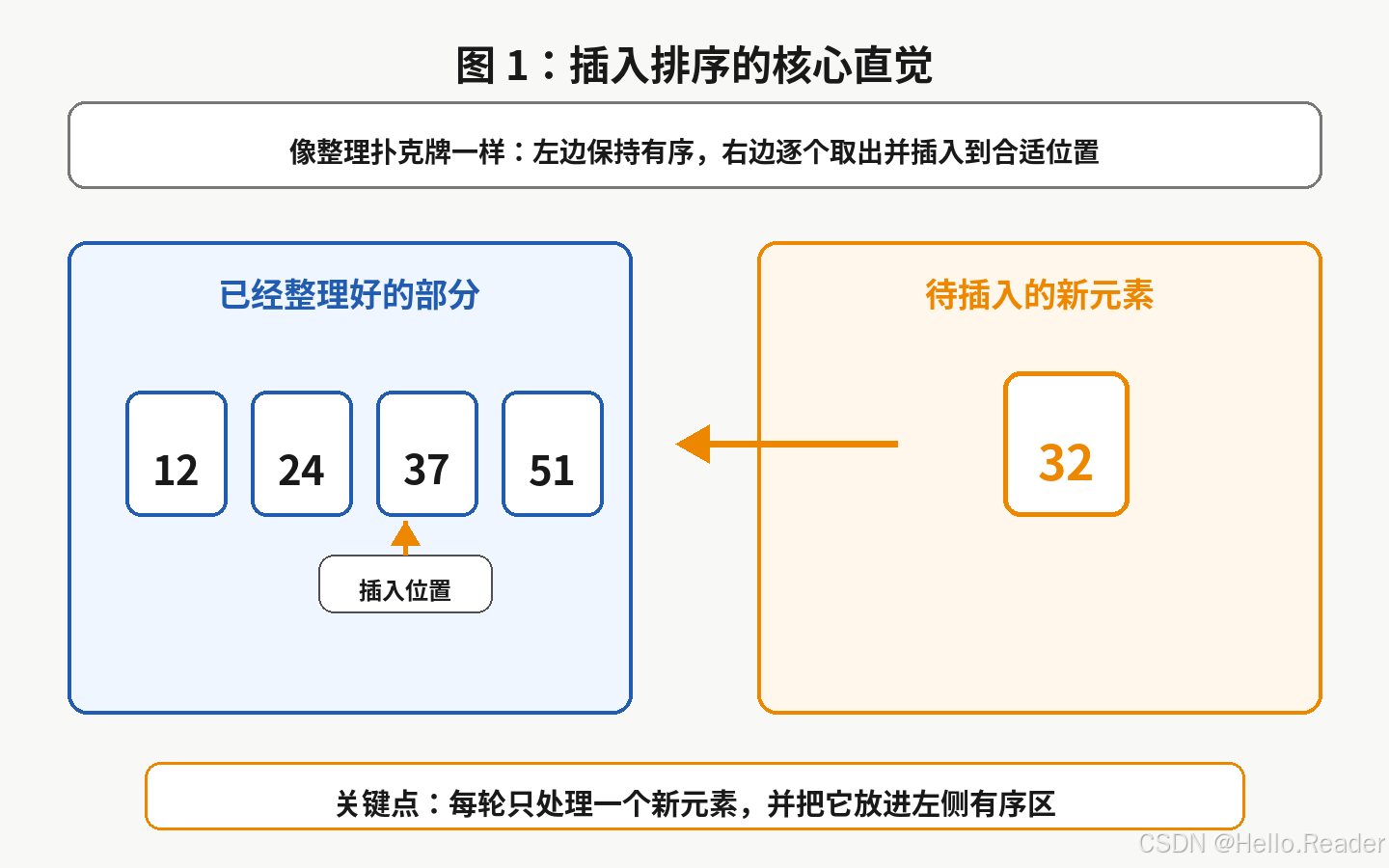
举个直观例子:
text
已经有序:12, 24, 37, 51
新元素:3232 应该插到 24 和 37 之间,插入后变成:
text
12, 24, 32, 37, 51这就是插入排序的核心动作。
4. 算法过程
假设数组为:
text
A = [5, 2, 4, 6, 1, 3]插入排序从第二个元素开始,因为只看第一个元素时,它天然是有序的。
每一轮做三件事:
- 取出当前元素
key; - 从左侧有序区的右端开始向前比较;
- 把所有比
key大的元素右移一格,最后把key放到空出来的位置。
伪代码如下:
text
INSERTION-SORT(A)
for j = 2 to A.length
key = A[j]
i = j - 1
while i > 0 and A[i] > key
A[i + 1] = A[i]
i = i - 1
A[i + 1] = key如果用从 0 开始的数组下标,可以理解成:
text
for j = 1 到 n - 1
key = A[j]
i = j - 1
while i >= 0 且 A[i] > key
A[i + 1] = A[i]
i--
A[i + 1] = key5. 动态执行过程
输入数组:
text
[5, 2, 4, 6, 1, 3]动态过程如下:
可以看到,每一轮结束后,左侧区域都会保持有序:
| 轮次 | 当前 key | 插入后左侧有序区 |
|---|---|---|
| 初始 | - | [5] |
| 第 1 轮 | 2 | [2, 5] |
| 第 2 轮 | 4 | [2, 4, 5] |
| 第 3 轮 | 6 | [2, 4, 5, 6] |
| 第 4 轮 | 1 | [1, 2, 4, 5, 6] |
| 第 5 轮 | 3 | [1, 2, 3, 4, 5, 6] |
6. 正确性理解
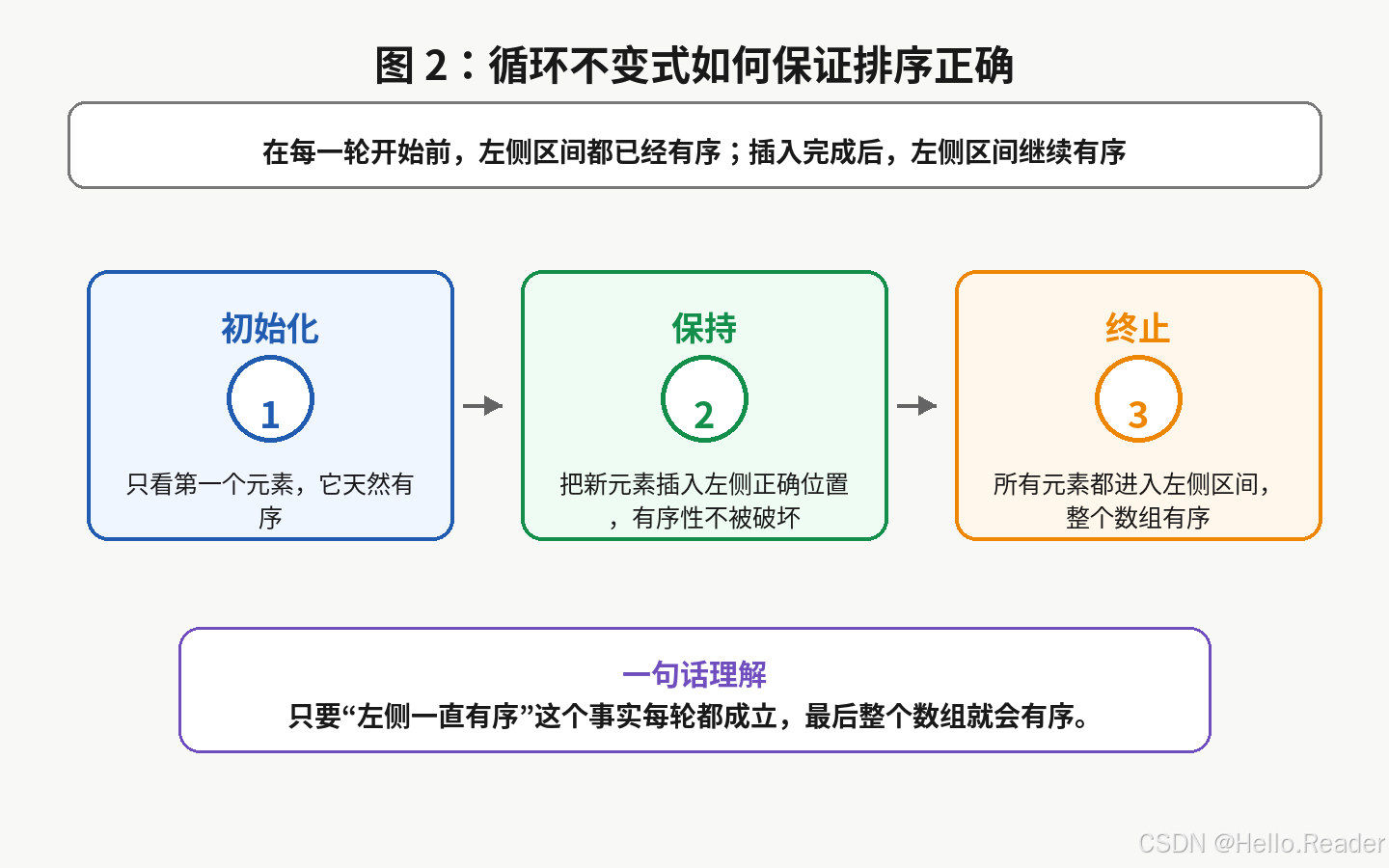
插入排序正确性的关键,是一个很重要的思想:循环不变式。
对插入排序来说,循环不变式可以说成:
每一轮外层循环开始前,当前位置左边的元素已经是有序的。

可以分三步理解:
6.1 初始化
刚开始时,只看第一个元素。一个元素当然是有序的。
6.2 保持
每一轮把 key 插入左侧有序区的正确位置。插入之后,左侧区间仍然保持有序。
6.3 终止
当所有元素都被处理完时,整个数组都属于左侧有序区,因此整个数组有序。
这就是插入排序正确性的核心逻辑。
7. 复杂度分析
插入排序的速度和输入数据的初始状态关系很大。

7.1 最好情况
如果数组本来就有序:
text
[1, 2, 3, 4, 5, 6]每一轮只需要比较一次,不需要移动大量元素。
时间复杂度:
O(n) O(n) O(n)
7.2 最坏情况
如果数组完全逆序:
text
[6, 5, 4, 3, 2, 1]每个新元素都要一路向前移动,移动次数最多。
时间复杂度:
O(n2) O(n^2) O(n2)
7.3 平均情况
随机输入时,元素通常要向前移动一段距离。
时间复杂度通常记为:
O(n2) O(n^2) O(n2)
7.4 空间复杂度
插入排序只需要一个额外变量 key,不需要额外数组。
空间复杂度:
O(1) O(1) O(1)
8. 代码实践
8.1 Python 版本
python
def insertion_sort(nums):
for j in range(1, len(nums)):
key = nums[j]
i = j - 1
while i >= 0 and nums[i] > key:
nums[i + 1] = nums[i]
i -= 1
nums[i + 1] = key
return nums
if __name__ == "__main__":
data = [5, 2, 4, 6, 1, 3]
print(insertion_sort(data))输出:
text
[1, 2, 3, 4, 5, 6]8.2 C++ 版本
cpp
#include <iostream>
#include <vector>
using namespace std;
void insertionSort(vector<int>& nums) {
for (int j = 1; j < nums.size(); j++) {
int key = nums[j];
int i = j - 1;
while (i >= 0 && nums[i] > key) {
nums[i + 1] = nums[i];
i--;
}
nums[i + 1] = key;
}
}
int main() {
vector<int> nums = {5, 2, 4, 6, 1, 3};
insertionSort(nums);
for (int x : nums) {
cout << x << " ";
}
cout << endl;
return 0;
}8.3 Go 版本
go
package main
import "fmt"
func InsertionSort(nums []int) {
for j := 1; j < len(nums); j++ {
key := nums[j]
i := j - 1
for i >= 0 && nums[i] > key {
nums[i+1] = nums[i]
i--
}
nums[i+1] = key
}
}
func main() {
nums := []int{5, 2, 4, 6, 1, 3}
InsertionSort(nums)
fmt.Println(nums)
}9. 常见误区
误区一:插入排序一定很差
不完全对。对于小数组或近乎有序的数据,插入排序表现很好,甚至很多高级排序实现会在小区间切换到插入排序。
误区二:插入排序就是不断交换
标准插入排序更准确地说是"移动元素,然后插入 key"。如果每次都交换,动作会更多。
误区三:看到两层循环就一定没价值
两层循环确实通常意味着较高复杂度,但算法是否有价值,还要看输入规模、数据分布和使用场景。
误区四:只要排序结果对,就不用理解正确性
工程里测试很重要,但测试不能替代逻辑证明。理解正确性,能帮助你在复杂算法里少踩很多坑。
10. 现代延伸
插入排序虽然简单,但它的思想在很多地方都能看到影子。
| 场景 | 体现方式 |
|---|---|
| 小规模数组排序 | 常作为高级排序算法的小数组优化策略 |
| 近乎有序数据 | 插入排序移动次数少,表现较好 |
| 在线处理 | 新数据到来时,可以插入到已有有序结构中 |
| 排序教学 | 非常适合解释循环不变式和原地排序 |
| 数据库 / 存储系统 | 局部有序维护、增量插入思想很常见 |
11. 思考题
- 为什么插入排序从第二个元素开始处理?
- 插入排序为什么在已经有序的数组上是 O(n)O(n)O(n)?
- 标准插入排序为什么是稳定排序?
- 如果把
nums[i] > key改成nums[i] >= key,稳定性会发生什么变化? - 你能否手动推演
[4, 3, 2, 1]的完整插入排序过程?
12. 本篇小结
插入排序的核心思想非常朴素:
text
维护左侧有序区,把右侧新元素逐个插进去。它的优点是:
- 思想简单;
- 原地排序;
- 稳定;
- 对小规模或近乎有序数据友好。
它的缺点是:
- 平均和最坏时间复杂度都是 O(n2)O(n^2)O(n2);
- 不适合大规模随机数据排序。
理解插入排序,不只是学会一个排序算法,更重要的是开始理解:
一个算法如何从直觉变成步骤,又如何通过不变式证明它为什么正确。