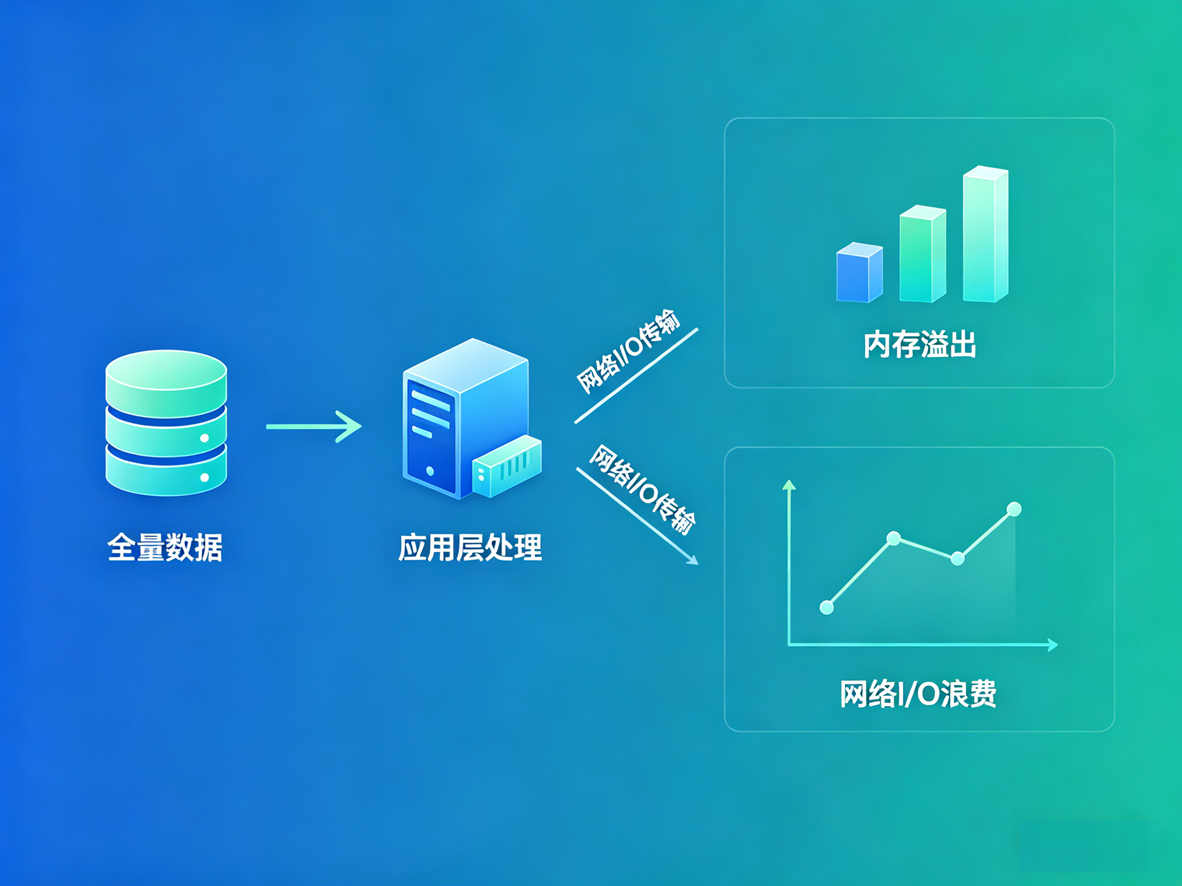
在日常的后端开发中,遇到类似"查询每个部门薪资最高的前三名员工"或"统计每个店铺的按月累计销售额"这类需求时,很多开发人员的做法是:执行一句 SELECT * 把相关数据全部拉取到 Java 或 Go 的应用层内存中,然后写双层 for 循环,或者使用类似 Stream API 的分组排序逻辑来处理。
这种做法存在两个明显的工程缺陷:一是浪费了大量的网络 I/O 传输不必要的数据(例如只需要前 3 名,却拉取了全量名单);二是极易引发应用服务器的内存溢出(OOM)。
实际上,从 MySQL 8.0 版本开始,关系型数据库原生支持了窗口函数(Window Functions)。它可以直接在数据库执行层完成复杂的分组排名和滑窗计算。本文将直接演示其实战用法。
一、 核心区别:窗口函数与传统 GROUP BY
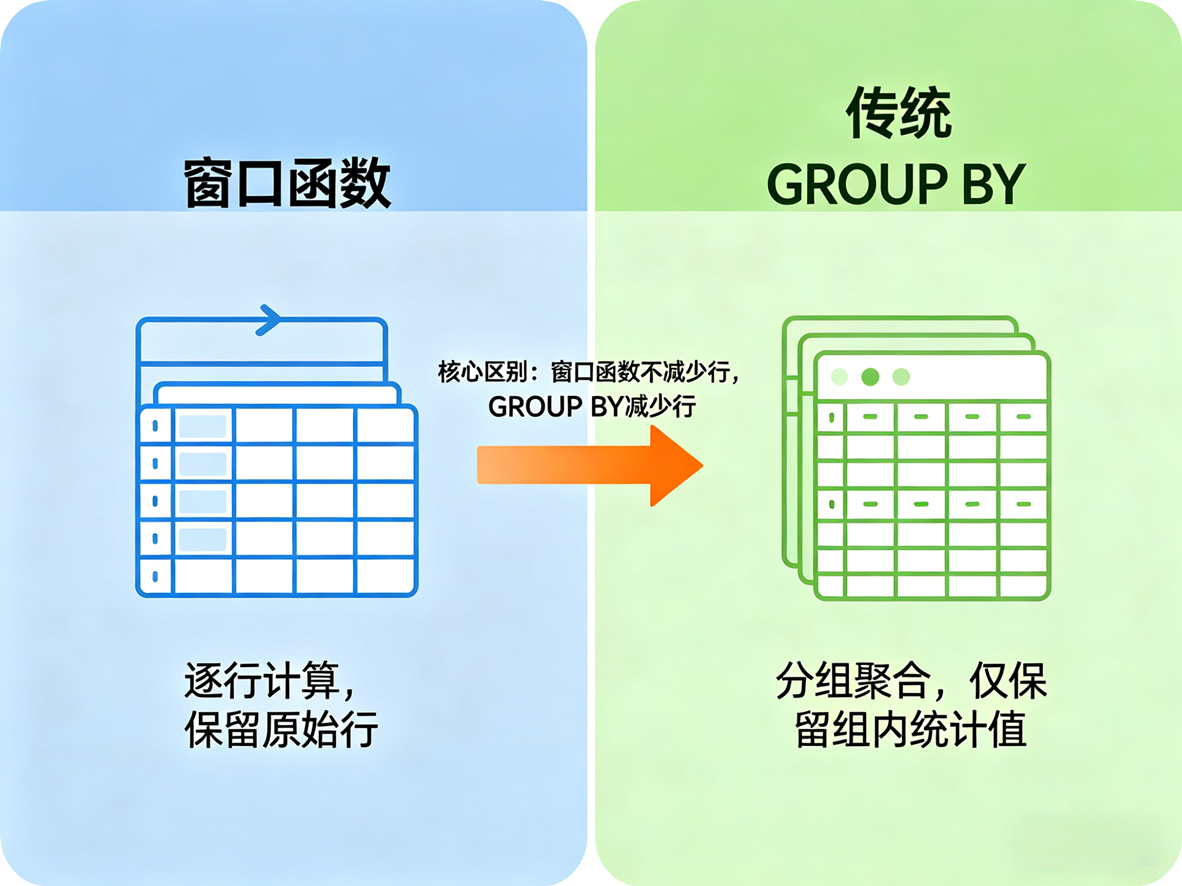
理解窗口函数,首先要区分它与常规 GROUP BY 的不同:
-
GROUP BY是聚合操作。几十行数据经过GROUP BY后,会被压缩成一行输出。 -
窗口函数是在保留原有数据行数的基础上,为每一行附加一个计算结果(如排名、累计值)。
窗口函数的基本语法结构为: 函数名() OVER (PARTITION BY 分组列 ORDER BY 排序列)
二、 实战场景 1:组内 Top N 查询
需求说明: 查询 employee_salary 表中,每个 department_id(部门)下薪水最高的前 3 名员工。
表结构参考: employee_salary (id, emp_name, department_id, salary)
传统解法极其繁琐: 在 MySQL 8.0 之前,要用纯 SQL 实现这个逻辑,通常需要写极其复杂的关联子查询。
使用窗口函数解法: 我们使用 ROW_NUMBER() 函数。它的作用是为数据生成一个连续的行号。
SELECT
department_id,
emp_name,
salary,
ranking
FROM (
-- 子查询:为每个员工生成其在所属部门内部的薪资排名
SELECT
department_id,
emp_name,
salary,
ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary DESC) AS ranking
FROM employee_salary
) AS ranked_data
WHERE ranking <= 3;原理解析:
-
PARTITION BY department_id:指示数据库按部门将数据划分成多个"窗口"(类似于代码里的按部门 Grouping)。 -
ORDER BY salary DESC:指示数据库在每个"窗口"内部,按薪资降序排列。 -
ROW_NUMBER():为排好序的每一行分配一个从 1 开始递增的序号。 -
外层查询只需加上
WHERE ranking <= 3,即可精准过滤出每个部门的前三名,没有多余数据被传输到应用层。
三、 函数对比:排名的并列处理
在实际业务中,遇到薪资相同的情况,排名的处理逻辑会有所不同。除了 ROW_NUMBER(),还有另外两个常用的排名函数:
假设一个部门有四个人,薪资分别是 20000, 20000, 15000, 10000。
-
ROW_NUMBER()(严格排序): 不管数据是否重复,序号严格递增。 结果:1, 2, 3, 4。 -
RANK()(跳跃排序): 遇到重复数据,序号相同,但后续序号会跳过对应的位数。 结果:1, 1, 3, 4。(没有第 2 名) -
DENSE_RANK()(连续排序): 遇到重复数据,序号相同,且后续序号不跳过。 结果:1, 1, 2, 3。
开发时需根据具体的产品业务规则,选择对应的函数替换上述 SQL 中的 ROW_NUMBER()。
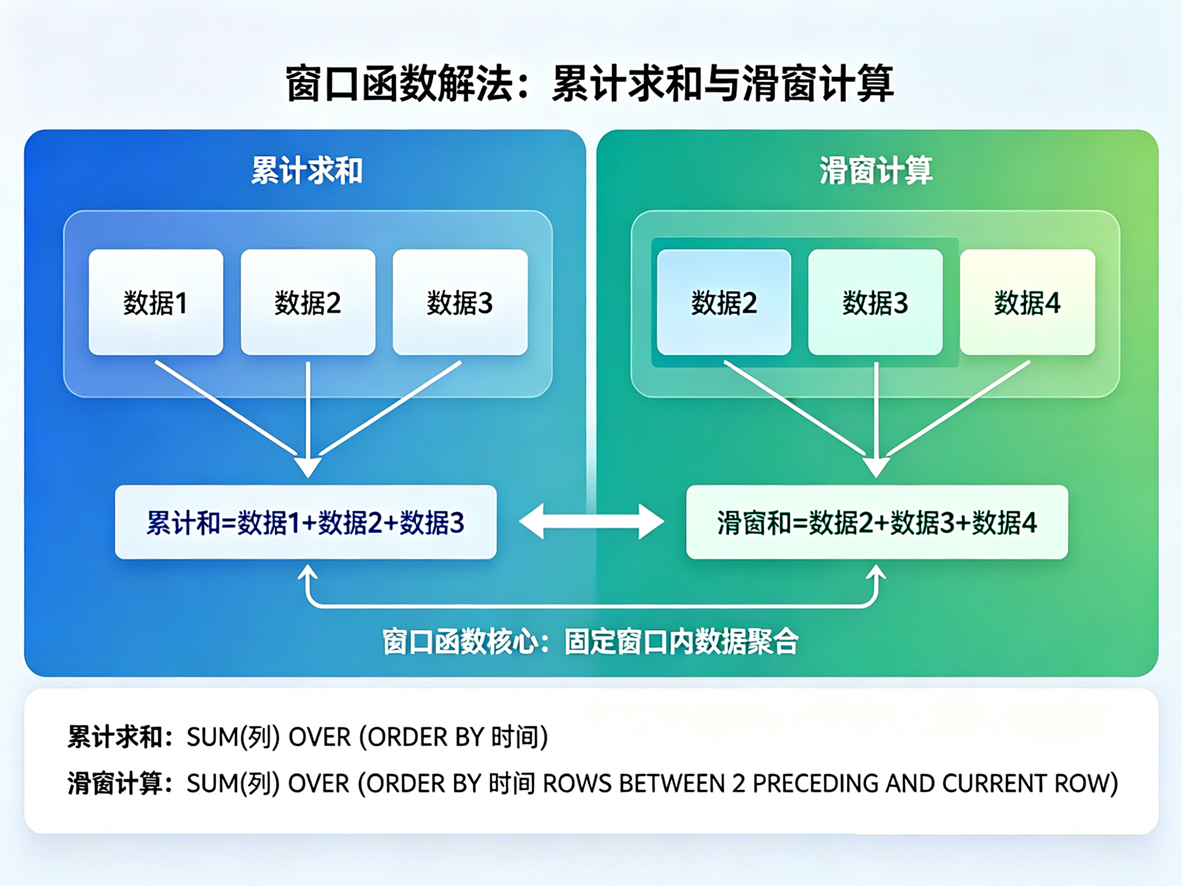
四、 实战场景 2:累计求和与滑窗计算
需求说明: 财务部门需要统计 store_sales 表中,每个店铺按月递增的"累计销售额"。(例如 2 月的数据是 1月+2月,3 月的数据是 1月+2月+3月)。
表结构参考: store_sales (store_id, sale_month, revenue)
使用窗口函数解法: 这里将标准的聚合函数 SUM() 搭配 OVER() 子句使用。
SELECT
store_id,
sale_month,
revenue AS current_month_revenue,
SUM(revenue) OVER (PARTITION BY store_id ORDER BY sale_month) AS cumulative_revenue
FROM store_sales;原理解析: 当聚合函数(如 SUM, AVG, COUNT)与带有 ORDER BY 的 OVER 子句结合时,默认会触发"累积滑窗"行为。 它不会计算整个分组的总和,而是计算从该分组的第一行到当前行的总和。这样,只用一行代码,数据库就直接吐出了计算好的按月累计数值。
五、 总结
将分组排名、累计求和等逻辑下推到数据库执行,有以下工程价值:
-
大幅精简后端代码逻辑,省去了实体类定义、集合分组、排序遍历等操作。
-
避免了全量数据的网络传输,降低了应用端 OOM 风险。
**执行前置条件:**请确保生产环境数据库版本支持窗口函数(MySQL 需 8.0 及以上版本,PostgreSQL、Oracle、SQL Server 等均原生支持)。