了解网络通信中为什么必须引入序列化/反序列化 ,TCP字节流带来的挑战,以及协议定制的
本质。
目录
[1.1 问题的根源:TCP是面向字节流的协议](#1.1 问题的根源:TCP是面向字节流的协议)
[1.2 字节流带来的粘包/拆包问题](#1.2 字节流带来的粘包/拆包问题)
[2.1 协议的本质是什么?](#2.1 协议的本质是什么?)
[2.2 两种约定方案对比](#2.2 两种约定方案对比)
[方案二:结构化协议 + 序列化(推荐)](#方案二:结构化协议 + 序列化(推荐))
[3.1 看似可行的方案](#3.1 看似可行的方案)
[3.2 不建议的原因分析](#3.2 不建议的原因分析)
[原因1:内存对齐问题(Memory Alignment)](#原因1:内存对齐问题(Memory Alignment))
[3.3 那为什么OS内核可以传递结构体?](#3.3 那为什么OS内核可以传递结构体?)
[4.1 核心概念](#4.1 核心概念)
[4.2 实际报文格式设计](#4.2 实际报文格式设计)
[5.1 read/write的本质是"拷贝"](#5.1 read/write的本质是"拷贝")
[5.2 TCP为什么是全双工的?](#5.2 TCP为什么是全双工的?)
[5.3 TCP自主决定:什么时候发?发多少?出错了怎么办](#5.3 TCP自主决定:什么时候发?发多少?出错了怎么办)
一、为什么read()读取TCP数据存在"Bug"?
1.1 问题的根源:TCP是面向字节流的协议
在学习应用层协议之前,我们常用这样的代码读取数据:
char buffer[1024];
ssize_t n = read(sockfd, buffer, sizeof(buffer)-1); // 读取字符串这个代码存在严重隐患! 因为TCP是面向字节流的协议,它只保证:
-
数据按发送顺序到达
-
数据不会丢失(在连接正常的情况下)
-
但不保证:一次read就能读完一个完整的"报文"
1.2 字节流带来的粘包/拆包问题
假设客户端连续发送两条消息:
-
消息A:"你好啊 2024-05-09 10:30:00 张三"
-
消息B:"吃了吗 2024-05-09 10:30:01 李四"
由于TCP的字节流特性,接收方的缓冲区可能出现以下情况:
| 场景 | 接收到的数据 |
|---|---|
| 粘包 | "你好啊 2024-05-09 10:30:00 张三吃了吗 2024-05-09 10:30:01 李四" |
| 拆包(半包) | 第一次read:"你好啊 2024-05-09 10";第二次read:"30:00 张三" |
| 完整包 | "你好啊 2024-05-09 10:30:00 张三" |
关键问题:接收方如何知道一个完整报文的边界在哪里?
结论 :在TCP中,要读到完整的报文,必须由接收方的应用层自己确定报文边界 !这是TCP协议设计的基本原则------传输层只负责可靠传输,报文语义由应用层定义。
二、重新认识"协议":从字符串到结构化数据
2.1 协议的本质是什么?
协议是一种"约定" 。在Socket编程中,read/write收发的是字节流(字符串),但我们要传输的往往是结构化的数据:
// 一条聊天消息的构成
struct Message {
std::string path; // 头像 -> 图片的路径
std::string nick_name; // 昵称 -> string
std::string msg; // 消息内容 -> 字符串
};协议定制的本质 :就是在定制双方都能认识的、符合通信和业务需要的结构化数据 。所谓的结构化数据,其实就是struct或者class。
2.2 两种约定方案对比
方案一:纯文本协议(如"1+1")
-
客户端发送形如
"1+1"的字符串 -
双方约定:两个操作数都是整数,中间用
+连接,无空格 -
缺点:扩展性差,解析复杂,容易出错
方案二:结构化协议 + 序列化(推荐)
-
定义结构体/类来表示交互信息
-
发送时 :将结构体按照规则转换成字符串 → 序列化
-
接收时 :将字符串按照相同规则转回结构体 → 反序列化
-
优点:扩展性好,类型安全,便于维护
从今天开始:如果我们要进行网络协议式的通信,在应用层强烈建议使用序列化和反序列化方案。至于直接传递结构体的方案,除非场景特殊,否则不建议。
三、为什么不建议直接发送结构体?
3.1 看似可行的方案
既然双方都用C/C++,为什么不直接这样?
struct Request {
int x;
int y;
char oper; // + - * / %
};
struct Request req = {10, 20, '+'};
write(sockfd, &req, sizeof(req)); // 直接发送二进制结构体疑问:可以直接发送二进制对象吗?因为CS双方都能认识这个结构体啊!!
答案:可以,但是不建议!!
3.2 不建议的原因分析
原因1:内存对齐问题(Memory Alignment)
struct Request {
int x; // 4字节
int y; // 4字节
char oper; // 1字节
// 编译器可能在这里填充3字节,使总大小为12字节而非9字节!
};-
不同编译器、不同平台(x86 vs ARM)、不同编译选项的对齐策略不同
-
发送方用GCC编译,接收方用Clang编译,结构体内存布局可能不同
-
结果 :接收方解析出的
x、y、oper值完全错乱
原因2:跨语言兼容性
| 发送方 | 接收方 | 能否直接传递结构体? |
|---|---|---|
| C | C++ | 可能可以(但内存对齐需完全一致) |
| C++ | Python | ❌ 不可行 |
| C++ | Java | ❌ 不可行 |
| Java | Go | ❌ 不可行 |
-
C/C++的结构体内存布局与Java的对象内存布局完全不同
-
Python没有真正的"结构体"概念
-
网络通信需要跨平台、跨语言!
原因3:大小端问题(Endianness)
int x = 0x12345678;
// 大端存储:12 34 56 78
// 小端存储:78 56 34 12-
x86架构是小端,网络协议规定大端(字节序转换)
-
直接发送结构体不做转换,在不同架构机器间通信会出错
3.3 那为什么OS内核可以传递结构体?
关键区别:
-
OS内部 :协议栈全部用C语言编写,运行在同一台机器上,编译器相同,内存对齐一致
-
网络通信:跨越不同机器、不同OS、不同编译器、可能不同语言
OS内部传递结构体对象可以,是因为环境完全可控;网络通信环境不可控,必须采用通用的文本/字节序列化方案。
四、序列化与反序列化详解
4.1 核心概念
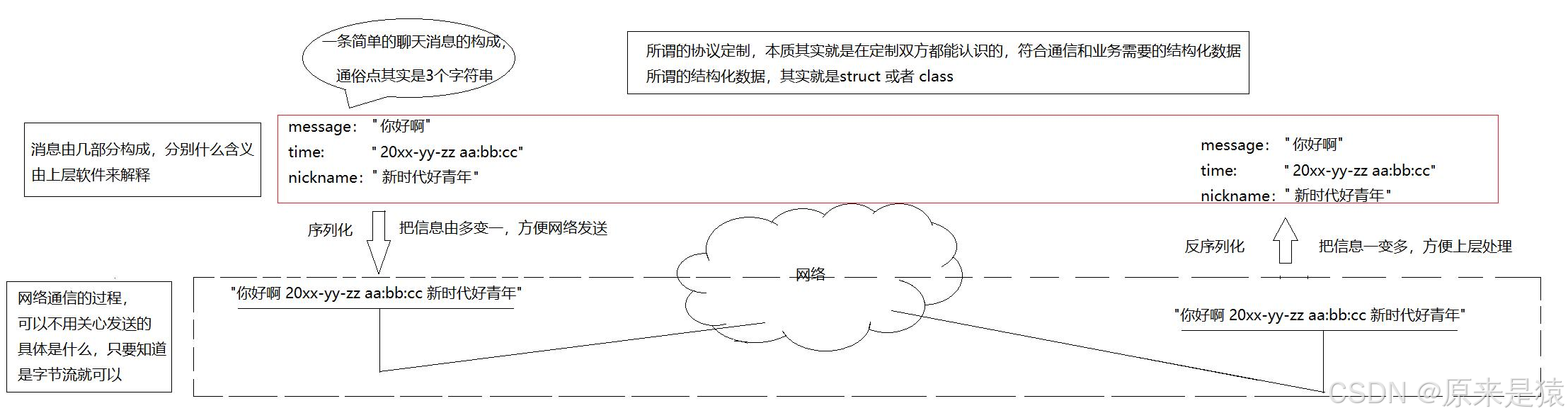
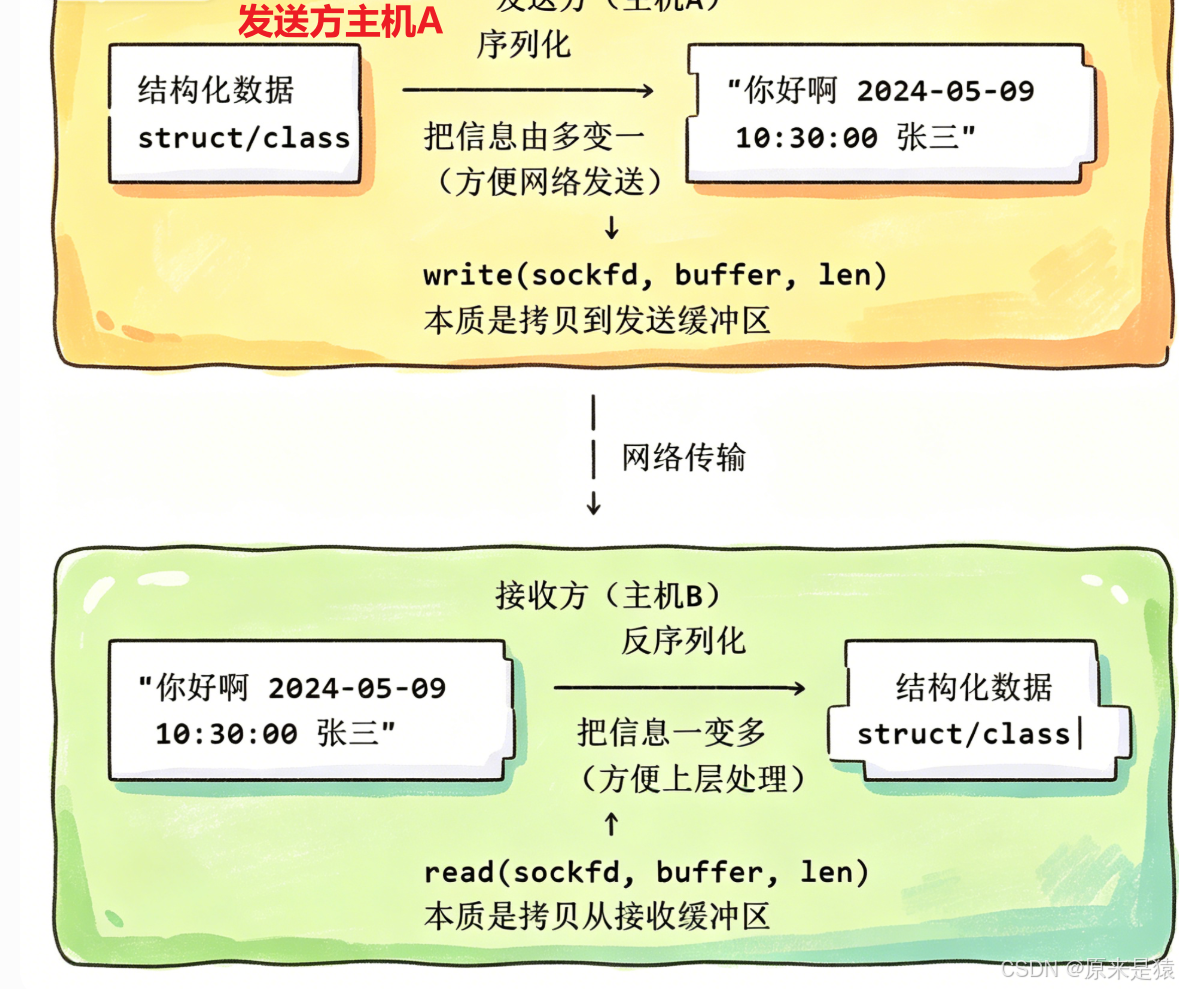
序列化(Serialization):把信息由多变一,方便网络发送
-
将结构化的
struct/class转换为字节流/字符串 -
例如:
{"datax":10,"datay":20,"oper":"+"}
反序列化(Deserialization):把信息一变多,方便上层处理
-
将字节流/字符串还原为结构化的
struct/class -
上层业务代码直接操作对象属性,无需关心字符串解析
4.2 实际报文格式设计
为了处理TCP字节流的边界问题,我们设计如下报文格式:

五、重新理解read、write与网络通信本质
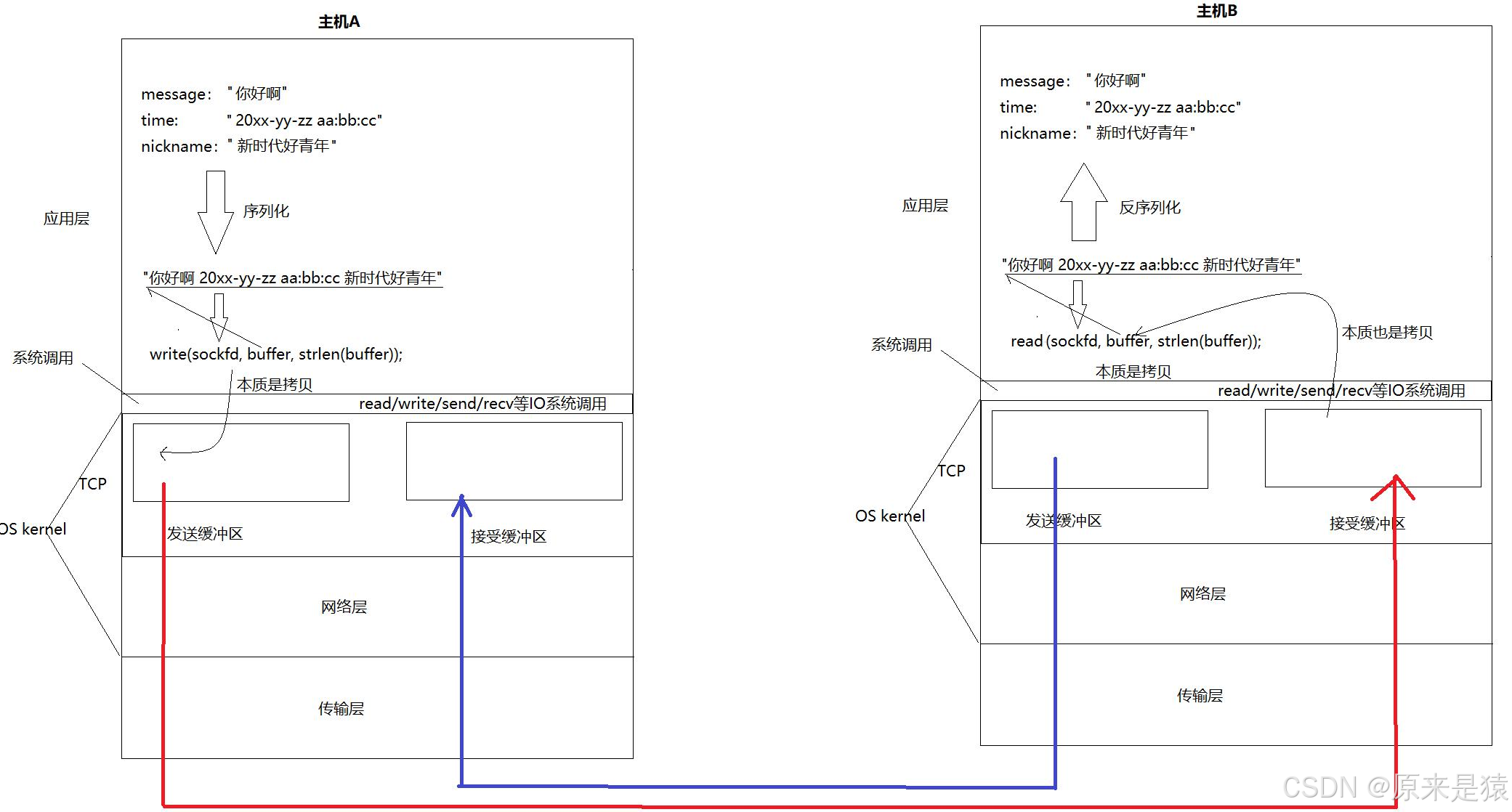
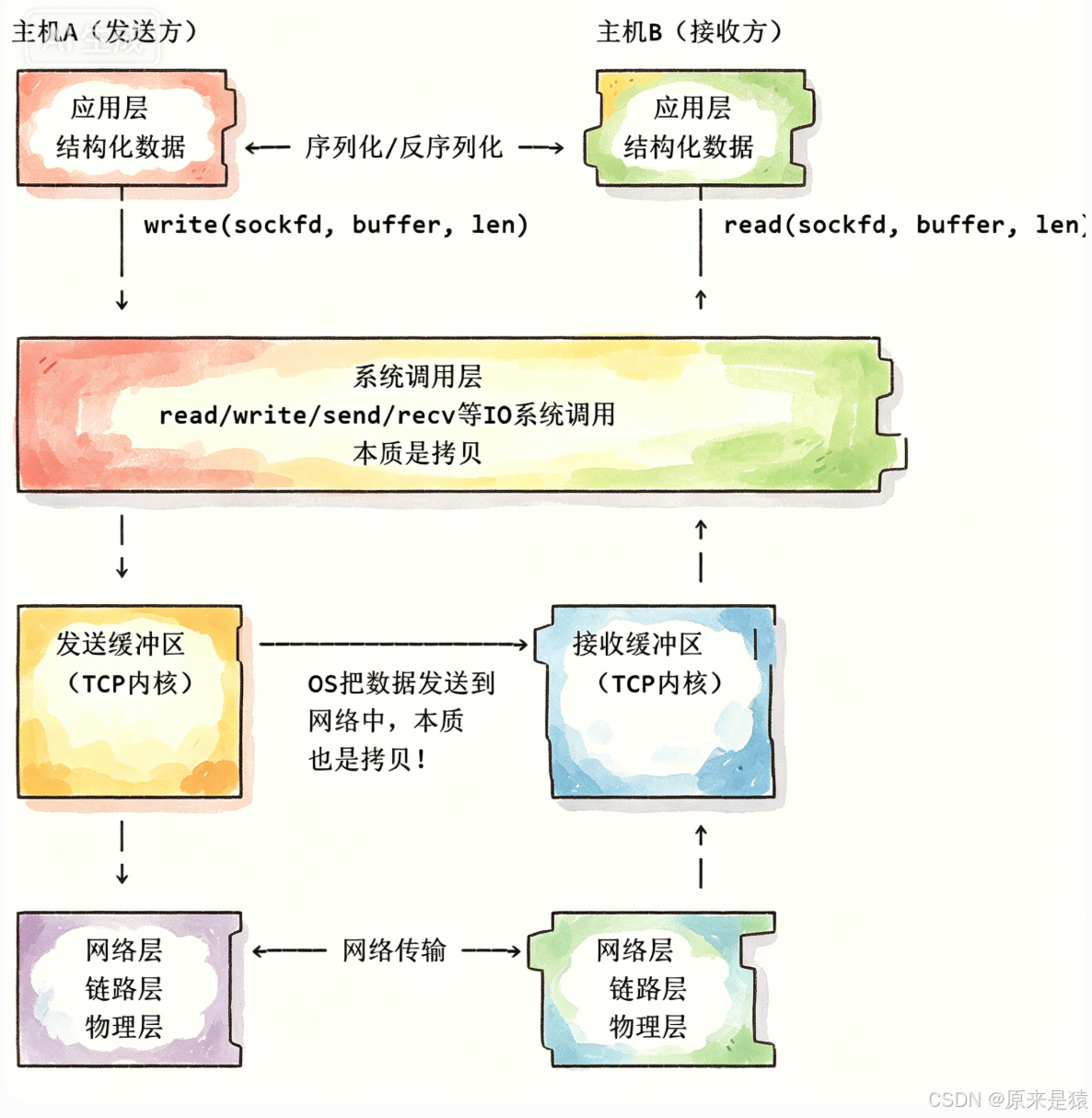
5.1 read/write的本质是"拷贝"
核心认知:
write/read就是收发消息 ------但write和read不是直接把数据发送到网络中!
主机间通信的本质:把发送方的发送缓冲区内部的数据,拷贝到对端的接收缓冲区!
计算机世界:通信即拷贝!
5.2 TCP为什么是全双工的?
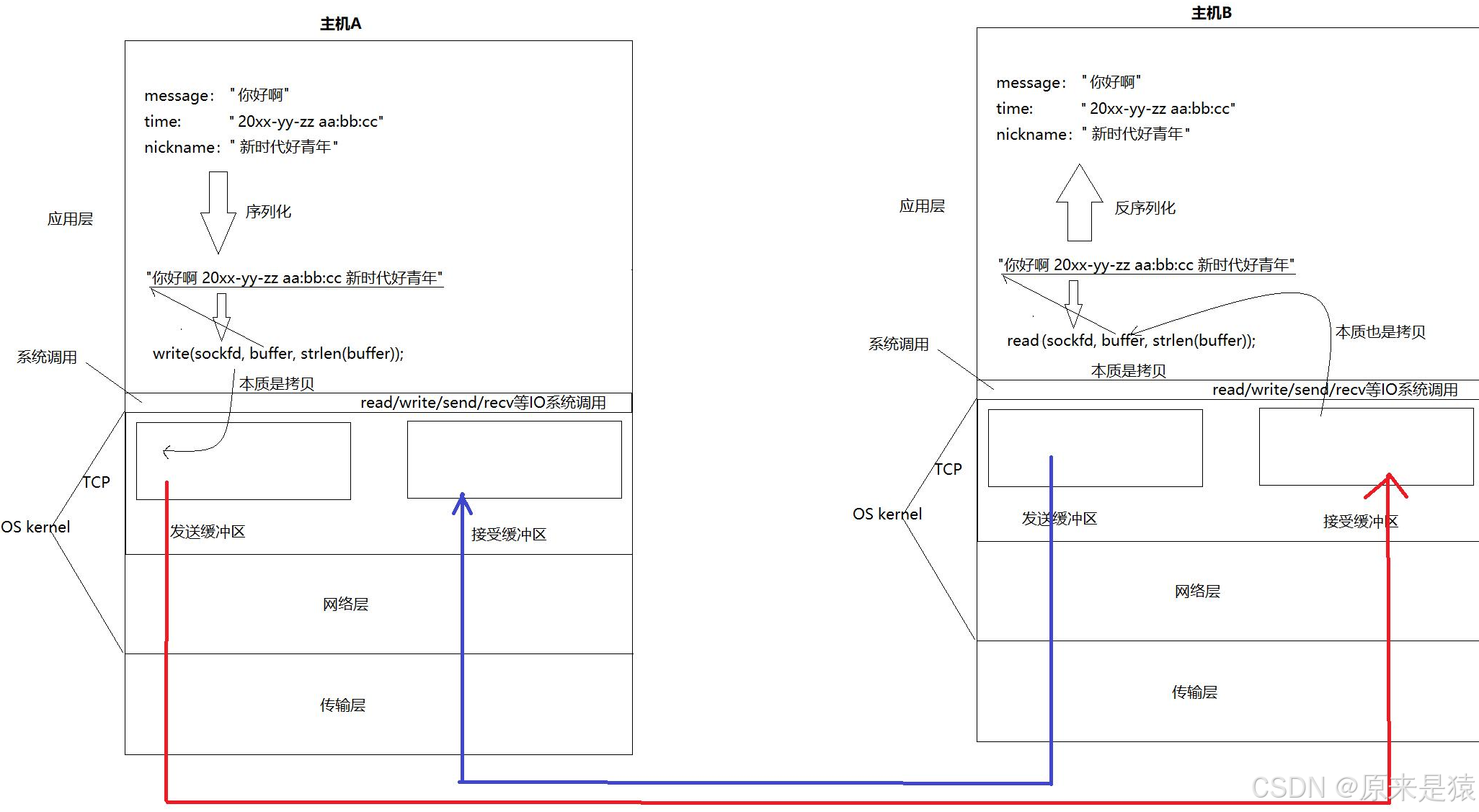
原因 :在任何一台主机上,TCP连接既有发送缓冲区,又有接收缓冲区:
-
主机A可以同时:向自己的发送缓冲区写数据(发消息)+ 从自己的接收缓冲区读数据(收消息)
-
主机B同理
-
因此,内核中可以在发消息的同时,也可以收消息
这就是为什么一个TCP sockfd读写都是它的原因! 两个缓冲区独立工作,互不影响,形成了全双工通信。
5.3 TCP自主决定:什么时候发?发多少?出错了怎么办?
write(sockfd, buffer, strlen(buffer)); // 数据拷贝到发送缓冲区
// 注意:此时数据可能还没真正发送到网络!-
什么时候发:由TCP的Nagle算法、拥塞控制等决定
-
发多少:由滑动窗口、MSS(最大报文段长度)决定
-
出错了怎么办:TCP重传机制、超时处理
这就是为什么TCP叫做"传输控制协议"(Transmission Control Protocol)------它控制了一切传输细节,应用层只需调用write/read即可。