摘要
本文以手写数字识别任务,展示了使用K近邻(KNN)算法对灰度图像进行分类的完整流程。文章首先介绍了数据集构成(42000张28×28像素的手写数字图像,含784个特征及对应标签),并通过代码演示了数据读取、图像可视化及标签分布统计。随后,对特征进行归一化处理,采用分层采样划分训练集与测试集以避免标签分布失衡,使用KNN分类器进行模型训练与评估,最终准确率达到约96.57%。此外,文章还演示了如何保存训练好的模型并用于识别外部手写数字图片,为KNN算法在图像识别领域的应用提供了可复用的实践范例。
Abstract
This article demonstrates the complete process of using the K-Nearest Neighbors (KNN) algorithm for grayscale image classification through the task of handwritten digit recognition. It first introduces the dataset composition (42,000 grayscale images of handwritten digits, each 28×28 pixels with 784 features and corresponding labels), and shows data loading, image visualization, and label distribution statistics through code examples. Subsequently, features are normalized, and stratified sampling is applied to split training and test sets to avoid label imbalance. A KNN classifier is used for model training and evaluation, achieving an accuracy of approximately 96.57%. Furthermore, the article demonstrates how to save the trained model and use it to recognize external handwritten digit images, providing a reusable practical example for applying the KNN algorithm in image recognition.
一.了解数据集
数据文件train.csv和test.csv包含从0到9的手绘数字的灰度图像。当前一共准备了42000组数据,每组数据有一个标签以及784个特征,这是因为每个图像高28像素,宽28像素,所以一共784个像素。每个像素点的取值范围0,255,取值越大就意味着颜色越深。
在实现手写数字识别时,先看看数据中的灰度图像。首先读取数据获取到源数据,接着由于数据量有限的所以要进行越界判断,然后对于获取到的数据进行处理分离得到标签和特征,再将特征转成28*28的形式,最后将索引对应的数字绘制出来,具体代码如下:
python
# 定义函数,接收用户传入的索引, 展示 该索引对应的图片
def show_digit(idx):
# 1.1读取数据集
df = pd.read_csv('./data/手写数字识别.csv')
# 1.2判断传入的索引是否越界
if idx < 0 or idx > len(df) - 1:
print("索引越界!")
return
# 1.3获取数据
x = df.iloc[:, 1:]
y = df.iloc[:, 0]
# 1.4查看用户传入的索引对应的图片 是数字几
print(f'该图片对应的数字是:{y.iloc[idx]}')
print(f'查看所有标签的分布情况:{Counter(y)}')
# 1.5查看 用户传入的索引对应的图片 的形状
# 1.6 将(784,)转换为(28,28),其中x.iloc[idx].values是获取这个784个像素的值
x = x.iloc[idx].values.reshape(28, 28)
# 1.7 具体灰度图的绘制
plt.imshow(x, cmap='gray') # 灰度图
plt.axis('off')
plt.show()当调用函数show_digit(9)时,得到的结果如下:
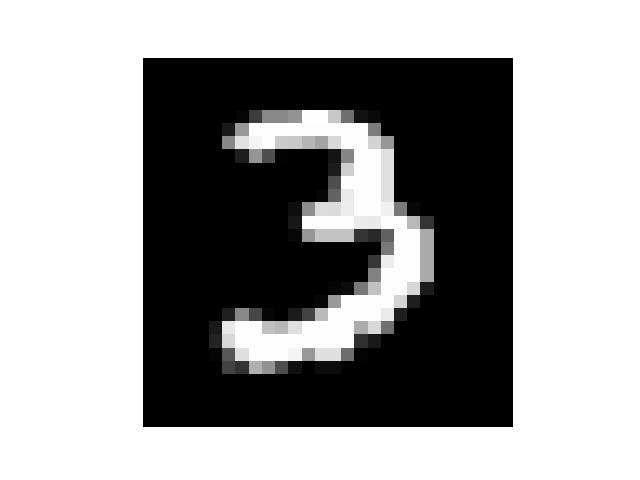
该图片对应的数字是:3
查看所有标签的分布情况:Counter({1: 4684, 7: 4401, 3: 4351, 9: 4188, 2: 4177, 6: 4137, 0: 4132, 4: 4072, 8: 4063, 5: 3795})
二.训练模型
在训练模型是也是先加载手写数字数据集,然后对数据进行预处理(归一化),然后参照y中各个数据的分布同等比例分割数据集,避免分割数据集后数据分布失衡(如分割后训练集中可能全是0、1、3、7),接着就是模型训练与模型评估,最后我们将模型经行保存。具体代码如下:
python
#定义函数,训练模型,并保存训练好的模型
def train_model():
# 1. 加载数据集
df = pd.read_csv('./data/手写数字识别.csv')
# 2.数据的预处理
# 2.1 拆出特征列
x = df.iloc[:, 1:] # 特征列
# 2.2 拆出标签列
y = df.iloc[:, 0]
# 2.3 打印特征与标签的形状
print(f'x的形状:{x.shape}') # (42000,784)
print(f'y的形状:{y.shape}') # (42000,)
# 2.4 对特征列进行归一化
x = x / 255
# 2.5 拆分训练集与测试集(参5:参考y值的比例,保持标签的比例均衡,也就是0到9都要有,量和y中等比)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=21, stratify=y)
# 3.模型训练
# 3.1 创建模型对象
estimator = KNeighborsClassifier(n_neighbors=3)
# 3.2 训练模型
estimator.fit(x_train, y_train)
# 4.模型评估
print(f'准确率:{estimator.score(x_test, y_test)}')
print(f'准确率:{accuracy_score(y_test, estimator.predict(x_test))}')
# 5.保存模型
joblib.dump(estimator, './my_model/手写数字识别.pkl') # pickle文件: Python(Pandas)独有的文件类型
print('模型保存成功')得到结果如下:
x的形状:(42000, 784)
y的形状:(42000,)
准确率:0.9657142857142857
准确率:0.9657142857142857
模型保存成功
三.手写数字识别的实现
前面已经将训练好的模型保存好了,现在将要识别的图片导入如下:

得到要识别的数据后,就加载模型,同时将这个28*28的灰度图像转成1*784的形式。最后输入到模型进行预测。具体代码如下:
python
def use_model():
# 1.加载图片
x = plt.imread('./data/demo.png') # 28 * 28像素
# 2.加载模型
estimator = joblib.load('./my_model/手写数字识别.pkl')
# 4.模型预测
# 4.1查看数据集转换
# print(x.reshape(1, -1).shape) # 语法糖 效果等同(1, 784)
# 4.2 数据集转换的动作,记得数据要归一化处理
x = x.reshape(1, -1)
# 4.3模型的预测
y_pre = estimator.predict(x)
# 5.打印预测结果
print(f'预测值为:{y_pre}')得到的结果为:
预测值为:2
总结
本文通过手写数字识别案例,系统展示了KNN算法在图像分类任务中的完整应用。文章强调了数据预处理的重要性,包括归一化(将像素值缩放到0,1区间)和分层采样(保证训练集与测试集中各类别比例与原始数据一致)。模型采用KNN(k=3)进行训练,在测试集上取得了96.57%的准确率。同时,文章演示了模型持久化保存与加载,并对新外部图片进行预测,形成了从数据探索、模型训练到部署应用的全流程实践。该案例帮助读者将KNN算法迁移到更复杂的图像识别场景,为后续学习其他分类算法奠定了实践基础。