博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:Python语言、MySQL数据库、Flask框架、Vue框架、随机森林分类算法模型
功能模块:
- 医疗数据分析可视化实时监控大屏(包含各年龄段患病占比、疾病类型分布、医院科室分布环形图、疾病关键词云图、男女患病对比图、患病身高体重平均数图、病例列表及疾病数据概览)
- 疾病在线预测(用户输入病情描述,系统基于随机森林算法返回初步预测结果,并附温馨提示)
- 医疗数据展示(以表格形式展示患者疾病类型、性别、年龄、就诊信息、个人体征等完整病例数据,支持按类型搜索与删除)
- 后台数据管理(以表格形式集中管理病例信息,支持搜索、新增、编辑、删除操作)
项目介绍:本系统服务于医疗行业,旨在解决数据整合不畅、决策支持不足、患者信息利用率低等问题。后端采用Python与Flask框架,前端使用Vue框架,数据库选用MySQL。系统实现了医疗数据的可视化展示,包括患病占比、疾病类型分布、科室分布、关键词云图等,并提供基于随机森林算法的病情初步预测功能。同时,系统支持病例数据的表格展示与后台管理,便于用户查看、搜索、新增、编辑和删除病例信息,提升数据管理与分析效率。
2、项目界面
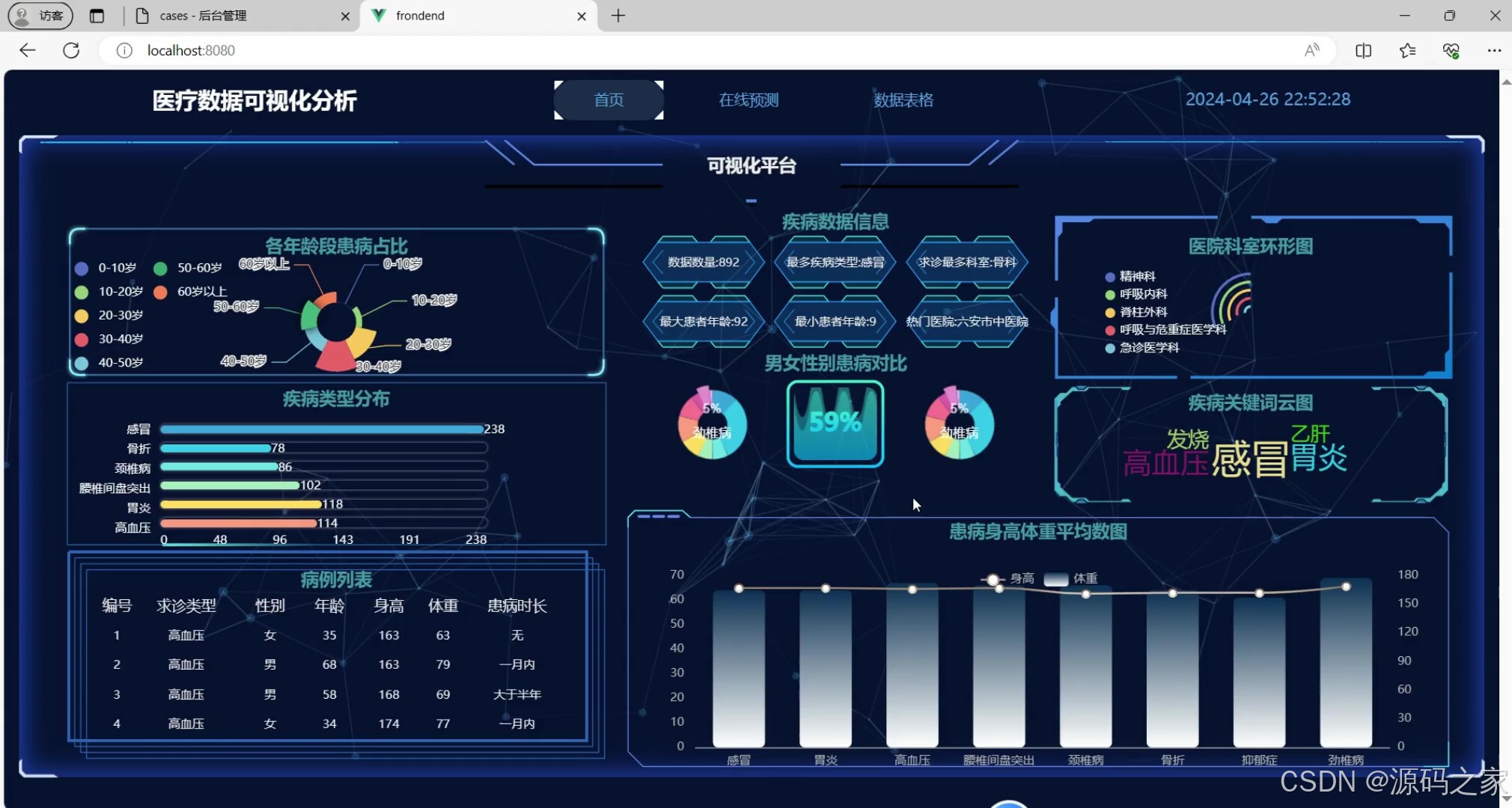
(1)医疗数据分析可视化实时监控大屏
该医疗数据可视化分析首页包含多类数据图表模块,可展示各年龄段患病占比、疾病类型分布、医院科室分布、疾病关键词、男女患病对比及患病者身高体重均值等信息,同时提供病例列表与疾病数据信息概览。
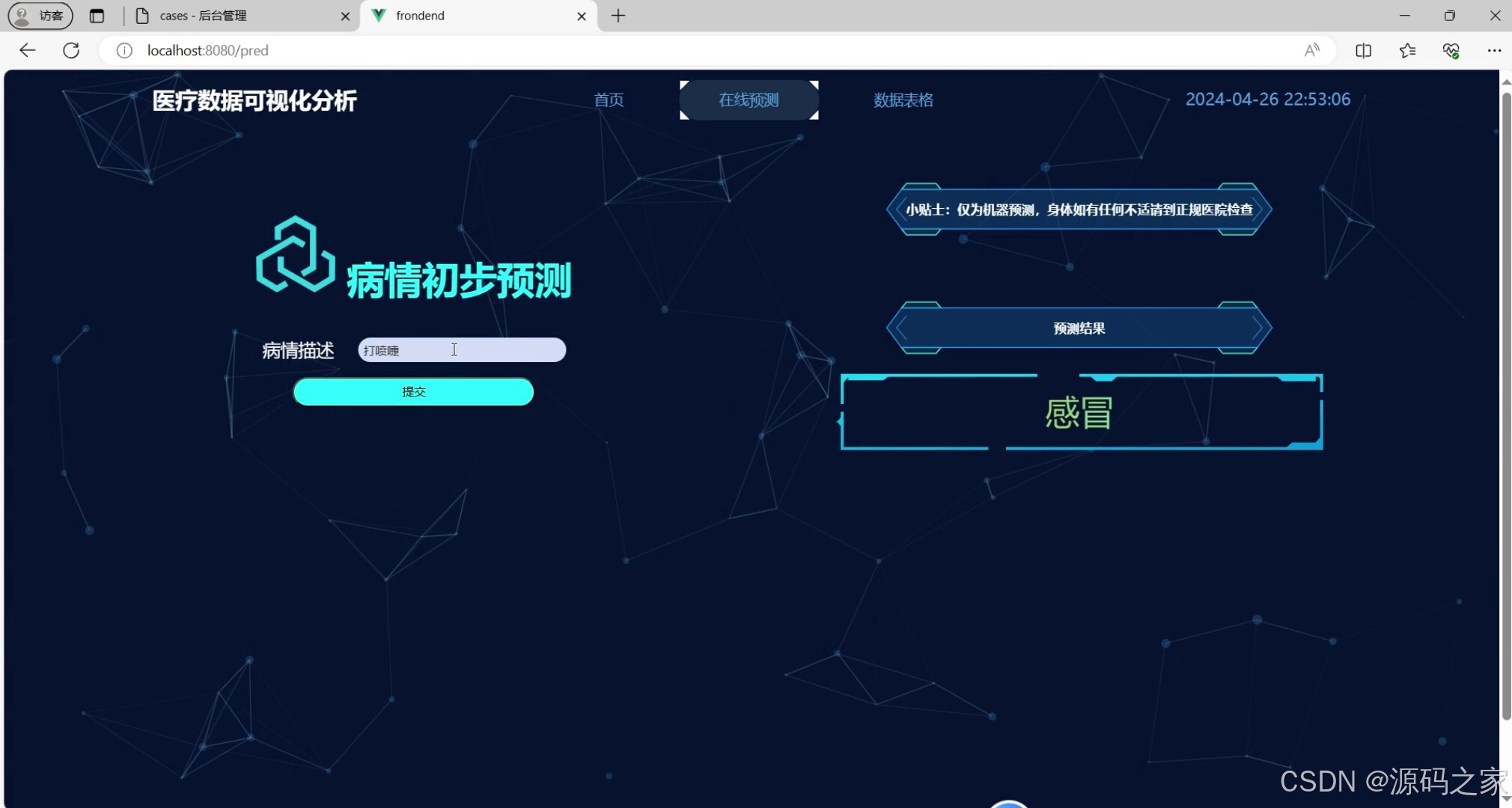
(2)疾病预测---机器学习算法
该在线预测页面为病情初步预测模块,用户可在输入框填写病情描述并提交,系统会根据输入内容给出疾病预测结果,同时页面附带温馨提示,明确说明预测仅为机器初步判断,不能替代正规医疗检查。
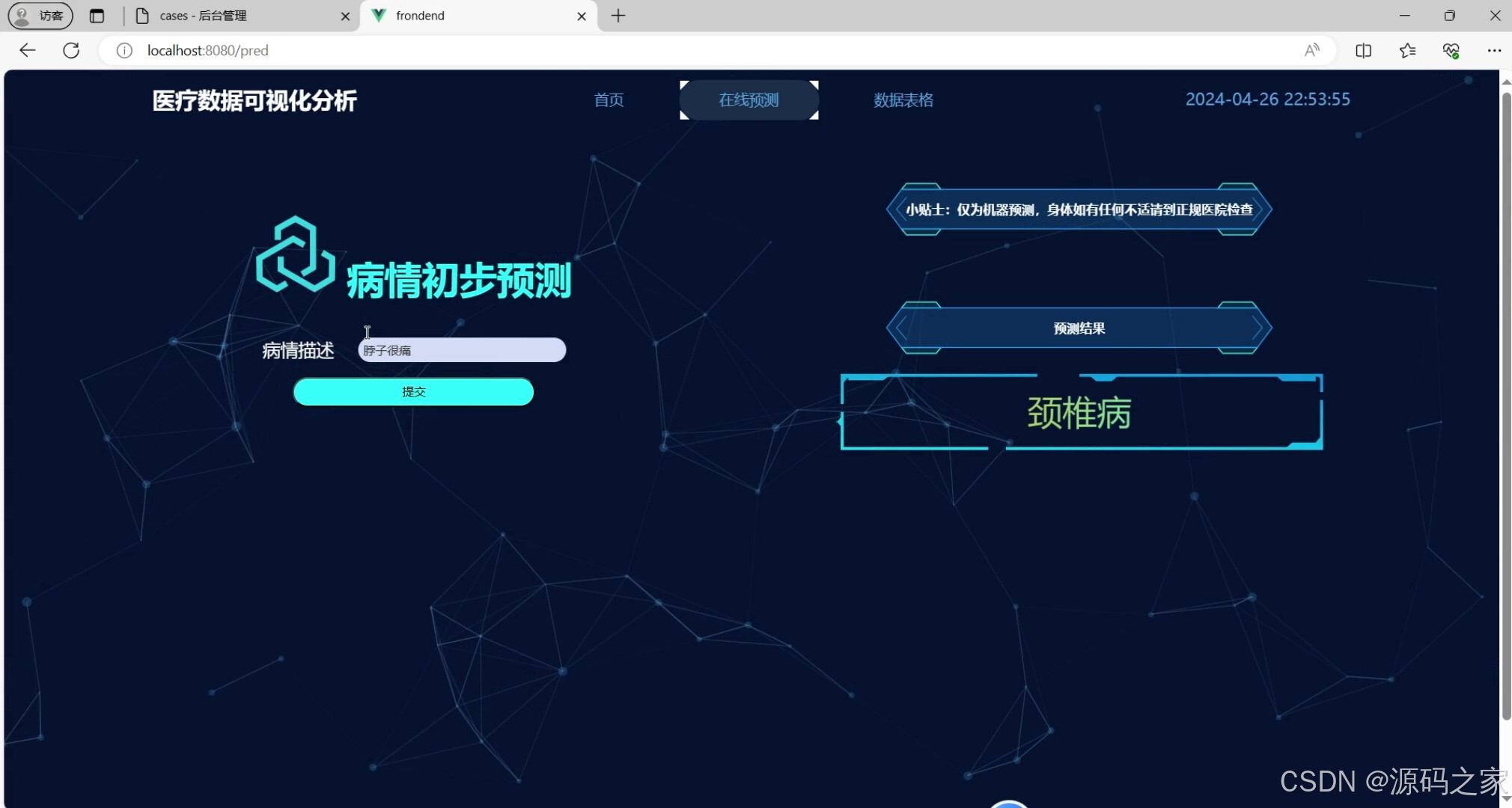
(3)疾病预测---机器学习算法
该在线预测页面为病情初步预测模块,用户可输入病情描述并提交,系统会根据内容给出疾病预测结果,同时附带温馨提示,明确说明该预测仅为机器初步判断,不能替代正规医疗检查。
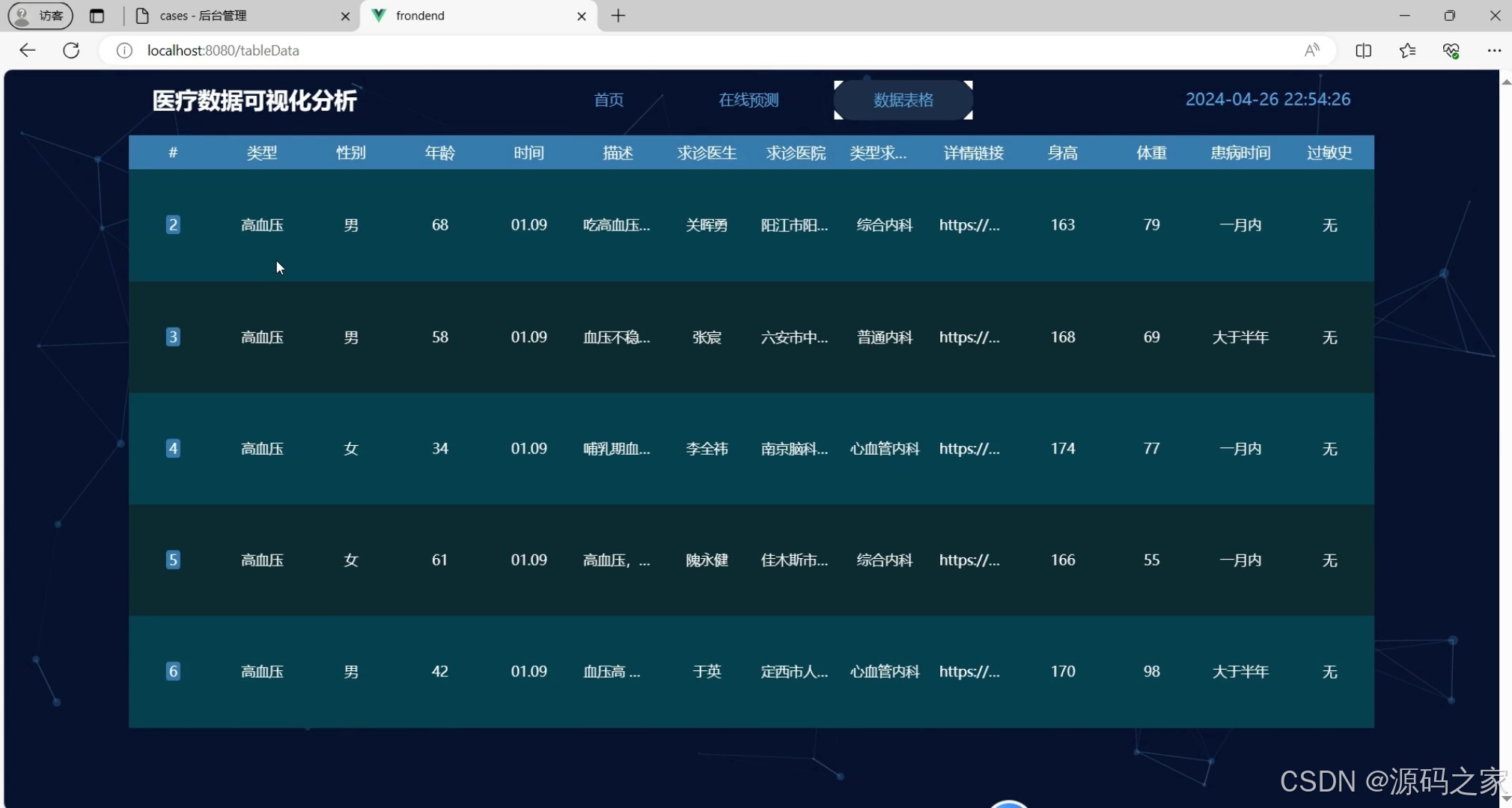
(4)医疗数据展示
该数据表格页面为医疗数据可视化分析系统的病例数据管理模块,以表格形式集中展示患者的疾病类型、性别、年龄、就诊信息、个人体征及患病相关情况,便于用户查看和管理完整的病例数据。
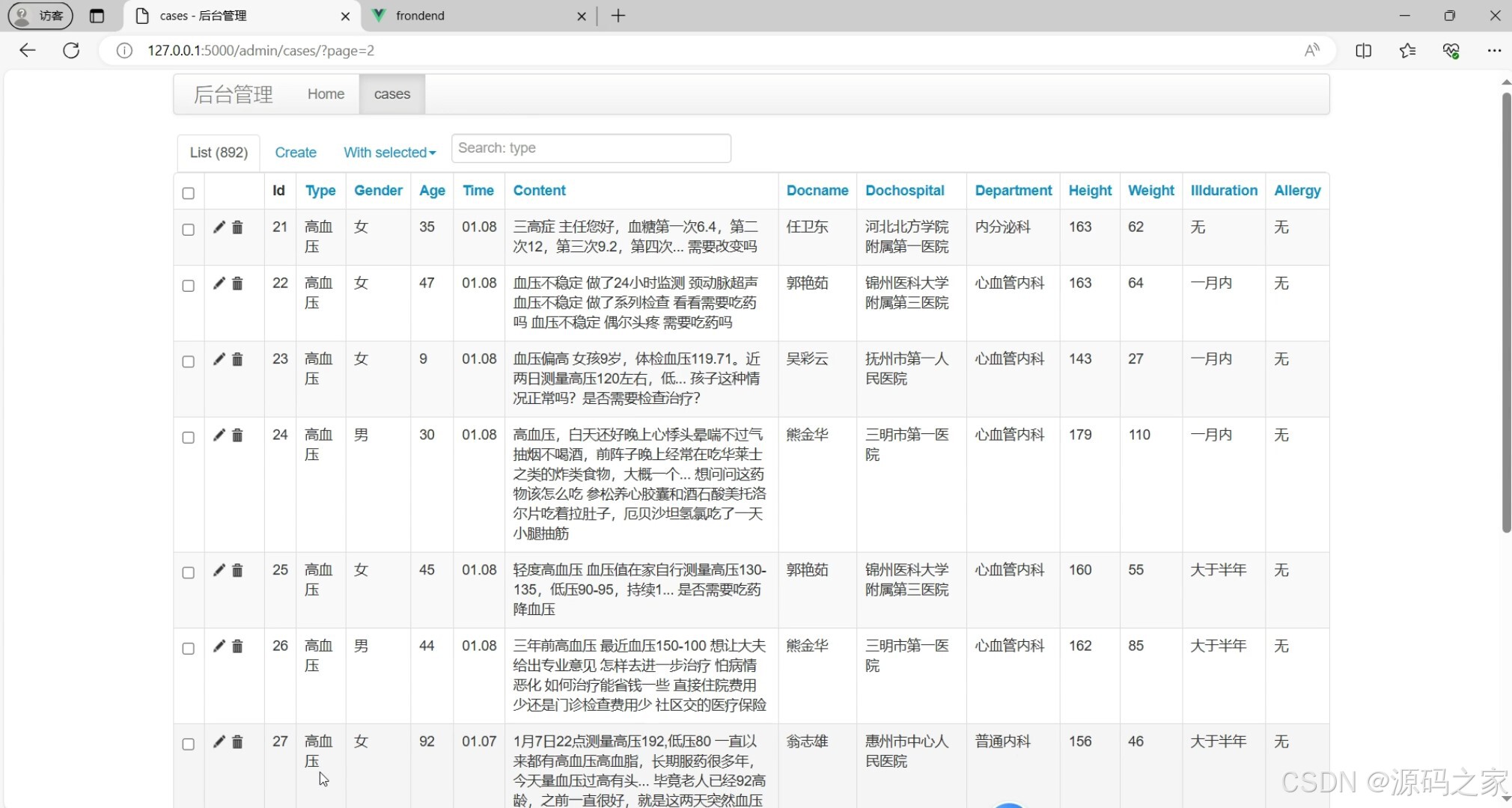
(5)后台数据管理
该后台管理页面是医疗病例数据的维护模块,以表格形式集中展示病例信息,支持对病例数据进行搜索、新增、编辑、删除操作,实现对病例数据的统一管理与维护。
3、项目说明
一、技术栈简要说明
本系统后端采用Python语言进行业务逻辑处理与算法实现,搭配Flask轻量级框架构建RESTful API接口。数据库选用MySQL存储病例数据,确保数据的完整性与查询效率。前端使用Vue框架进行页面渲染与交互体验优化,实现数据动态展示。在预测模块中,系统采用随机森林分类算法模型,基于病情描述文本进行疾病类型的初步预测。
二、功能模块详细介绍
- 医疗数据分析可视化实时监控大屏
该模块为系统首页,集成了多类数据图表组件,形成统一的监控大屏。页面展示了各年龄段患病占比统计图,帮助用户了解不同年龄段的疾病分布特征。疾病类型分布模块以图表形式呈现各类疾病的占比情况,便于快速识别高发疾病。医院科室分布采用环形图展示,直观反映各科室的病例数量比例。疾病关键词云图通过词频大小突出常见症状与疾病关联词汇。男女患病对比图用于分析性别对疾病发生的影响。患病身高体重平均数图展示不同疾病患者的平均身高与体重数据。此外,页面还提供病例列表及疾病数据信息概览,方便用户快速浏览最新病例记录。
- 疾病在线预测
该模块基于随机森林分类算法,为用户提供病情初步预测功能。用户可在输入框中填写病情描述文本,提交后系统调用训练好的机器学习模型进行分析,并返回预测的疾病类型结果。为保障用户理性使用,页面同时附带温馨提示,明确说明该预测结果仅为机器基于数据模型的初步判断,不能替代正规医疗机构的检查与医生诊断。该模块适用于辅助医生快速参考或帮助用户初步了解可能的疾病方向。
- 医疗数据展示
该模块以数据表格形式集中展示病例详细信息。表格包含患者的疾病类型、性别、年龄、就诊医生、就诊医院、就诊时间、个人体征(如身高、体重)以及患病相关情况等字段。用户可通过类型搜索功能快速筛选特定疾病类别的病例记录,也支持删除不需要的数据行。该模块便于医护人员或数据分析人员查看和管理完整的病例数据,为数据统计与病历回顾提供便利。
- 后台数据管理
该模块面向系统管理员,提供完整的病例数据维护功能。页面同样采用表格形式集中展示所有病例信息,并在此基础上增加了新增、编辑、删除等操作按钮。管理员可以搜索特定病例,新增新的病历记录,修改已有病例的字段内容,或删除错误或过时的数据。该模块实现了对病例数据的统一管理与动态维护,确保数据库中信息的准确性与及时更新,为前端可视化模块和预测模块提供可靠的数据来源。
三、项目总结
本系统针对医疗行业数据整合不畅、决策支持不足、患者信息利用率低等现实问题,设计并实现了一套完整的医疗数据分析可视化方案。系统综合运用Python、Flask、MySQL、Vue及随机森林算法,构建了从数据存储、后端处理到前端展示与智能预测的全流程架构。通过可视化大屏,用户可直观掌握疾病分布、科室情况、性别差异等多维信息;通过在线预测功能,可快速获得病情初步判断;通过数据展示与后台管理模块,可实现病例数据的高效查阅与维护。系统整体提升了医疗数据的利用效率与管理水平,为医疗工作者提供了科学、直观的辅助决策工具。
4、核心代码
python
import jieba
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score,classification_report
from sklearn.preprocessing import LabelEncoder
from sqlalchemy import create_engine,text
conn = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/medicalinfo?charset=utf8')
stopwords = set(open('./machine/stopword.txt','r',encoding='utf-8').read().splitlines())
def tokensize(text):
words = [word for word in jieba.cut(text) if word not in stopwords]
return ' '.join(words)
def getData():
query = text('select * from cases')
try:
df = pd.read_sql(query,con=conn,index_col='id') #
except Exception as e:
print(e)
data = df[['content','type']]
data['content'] = data['content'].apply(tokensize)
# print(data)
return data
vectorizer = TfidfVectorizer(max_features=10000)
def model_train(data):
x_train,x_test,y_train,y_test = train_test_split(data['content'],data['type'],test_size=0.2,random_state=42)
#文本提取
x_train_vectorizer = vectorizer.fit_transform(x_train)
x_test_vectorizer = vectorizer.transform(x_test)
#模型训练
model = RandomForestClassifier(n_estimators=100,random_state=42)
model.fit(x_train_vectorizer,y_train)
y_pred = model.predict(x_test_vectorizer)
accuracy = accuracy_score(y_test,y_pred)
return model
def pred(model,content):
content = [' '.join(jieba.cut(content))]
x_test_vectorizer = vectorizer.transform(content)
pred = model.predict(x_test_vectorizer)
return pred[0]
if __name__ == '__main__':
trainData = getData()
model = model_train(trainData)
pred(model,'腰部疼痛')