人工智能中的许多任务,并不是让机器只面对一批没有明确答案的数据,而是先给它一批已经标注好目标结果的样本,让它从这些样本中学习输入与输出之间的对应关系。等这种关系学到一定程度之后,再把新的输入交给模型,由模型给出预测结果。
例如,给模型一批房屋样本,每套房屋都记录了面积、房间数量、地段、房龄等信息,同时也给出了对应房价;或者给模型一批邮件样本,每封邮件都已经标明"正常邮件"或"垃圾邮件"。这时,机器要做的不是凭空思考,而是从这些"带答案的例子"中归纳规律,再把规律应用到新样本上。
这种学习方式,就是监督学习(Supervised Learning)。
监督学习是机器学习中最基础、最常见、也最容易落地的一类方法。无论是房价预测、考试成绩预测、手写数字识别,还是商品分类、疾病辅助判断、文本情感分析,其背后往往都可以归结为监督学习问题。
一、从一个任务开始:根据已知样本进行预测
假设现在有这样一个问题:我们收集了一批学生的数据,每位学生都有如下信息:
• 平时作业平均分
• 课堂测验平均分
• 出勤率
同时,我们也知道这些学生最后的考试成绩。
现在的问题是:如果再来一位新学生,我们只知道他的平时表现,能否让机器预测他的期末成绩?
这类问题的核心特征是:历史样本中已经给出了正确答案。也就是说,机器不是自己去探索"什么有趣",而是在学习"输入和答案之间是什么关系"。
例如,可以把几位学生的数据简单写成:
cs
import numpy as np
X = np.array([ [80, 78, 90], [85, 82, 95], [60, 65, 70], [90, 88, 98], [70, 72, 80]])
y = np.array([81, 86, 66, 92, 73])这里可以这样理解:
• X 表示输入数据
• y 表示对应的正确结果
• X 中每一行是一个学生样本,每一列是一个特征
• y 中每个值是该学生对应的考试成绩
这正是监督学习最基本的数据组织方式。
从直观上看,监督学习就像老师拿着一批"已经批改好的练习题"去教机器:题目是什么,答案是什么,机器通过这些成对出现的样本,逐步学会一种从题目到答案的映射关系。
二、什么是监督学习
监督学习这个名字里,"监督"二字并不是说有人实时盯着机器操作,而是说训练数据中带有明确的目标信息,可以对机器的学习过程形成指导。
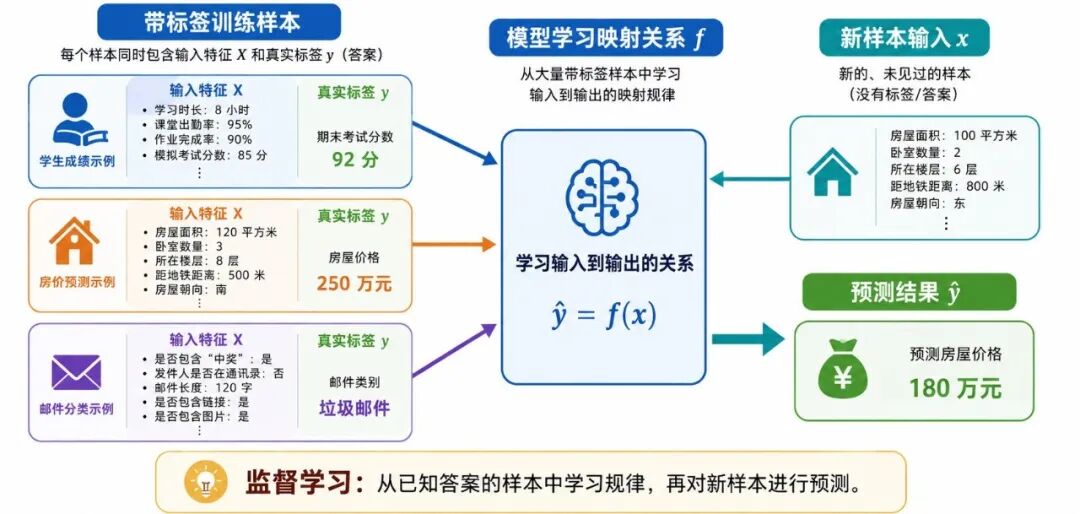
图 1:监督学习的基本思想
更准确地说,监督学习的基本结构是:
• 输入:样本的特征表示,通常记为 X
• 输出:样本对应的目标结果,通常记为 y,也常称为目标变量或标签
机器的任务,是根据大量已经配对好的 (X, y) 样本,学习一种从输入到输出的映射函数。
用数学形式可以写作:
也可以写成:
其中:
• x 表示某一个具体样本的输入
• f 表示模型学习到的映射关系
• ŷ 表示模型给出的预测结果
这里要特别注意,监督学习真正依赖的不是"数据很多"这件事本身,而是"数据中包含可用于学习的目标结果"这件事。
例如:
• 如果我们知道房屋特征,也知道真实房价,那么可以做监督学习
• 如果我们知道邮件内容,也知道每封邮件是不是垃圾邮件,那么可以做监督学习
如果只有一堆数据,却没有对应答案,那么通常不属于监督学习,而更接近无监督学习。
因此,监督学习的本质,不是让机器自己随意摸索,而是让它在已有答案的约束下学习一种预测规则。
延伸阅读:
三、监督学习中的基本对象:样本、特征与标签
要真正理解监督学习,必须先把其中最基础的三个概念分清楚:样本、特征与标签。
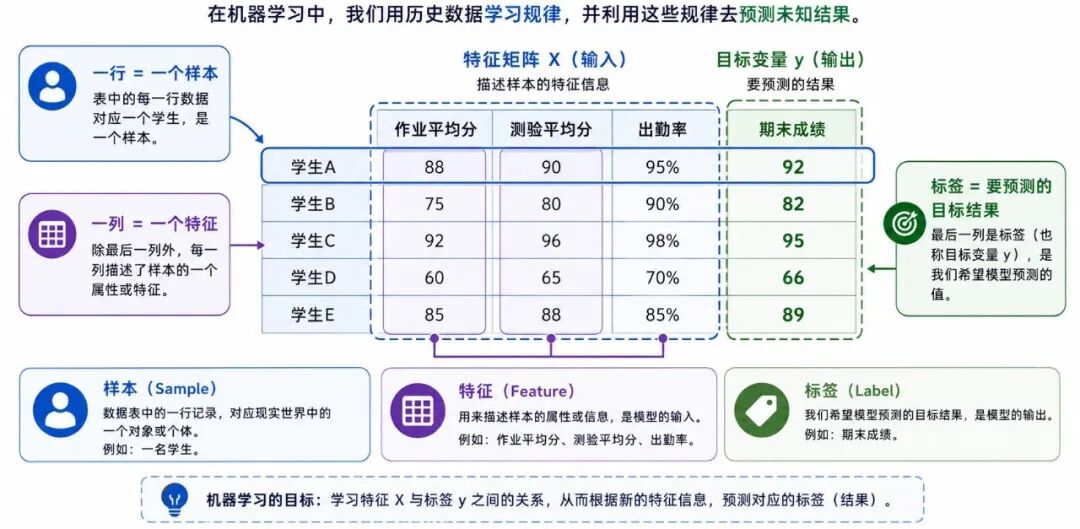
图 2:样本、特征与标签
1、样本
样本(Sample)指的是一条独立的观测记录,也就是一个具体对象在数据中的一次表示。
例如:
• 在学生成绩预测问题中,一位学生可以看作一个样本
• 在房价预测问题中,一套房屋可以看作一个样本
• 在邮件分类问题中,一封邮件可以看作一个样本
• 在手写数字识别问题中,一张手写数字图片可以看作一个样本
样本是监督学习中最基本的观察单位。模型学习规律时,并不是直接面对抽象的"学生""房屋"或"邮件",而是面对一条条已经被整理成数据形式的样本记录。
2、特征
特征(Feature)是用于描述样本的信息。机器并不直接理解现实对象本身,而是通过一组可计算的特征来认识它们。
例如,学生样本可以用以下特征表示:
• 作业平均分
• 测验平均分
• 出勤率
• 课堂参与度
• 学习时长
房屋样本也可以用以下特征表示:
• 面积
• 房间数
• 房龄
• 地段
• 到市中心的距离
因此,特征本质上是样本在计算机中的可计算表示。特征设计得是否合理,会直接影响模型能否学到有效规律。
3、标签
标签(Label)是样本对应的目标结果,也就是监督学习中"标准答案"的角色。
例如:
• 在房价预测中,标签可能是具体价格
• 在成绩预测中,标签可能是期末分数
• 在邮件分类中,标签可能是"垃圾邮件"或"正常邮件"
• 在数字识别中,标签可能是 0 到 9 之间的某个数字
从结构上看:
• 特征决定了"输入是什么"
• 标签决定了"希望预测什么"
只有当样本同时具有特征和标签时,监督学习才能建立起来。
延伸阅读:
四、监督学习在学什么
很多初学者容易把监督学习理解成"机器把数据背下来"。这种理解并不准确。
监督学习真正要做的,是从已有样本中学习一种输入与输出之间的映射关系。模型并不是去记住每个样本,而是试图总结出一种可推广到新样本上的规律。
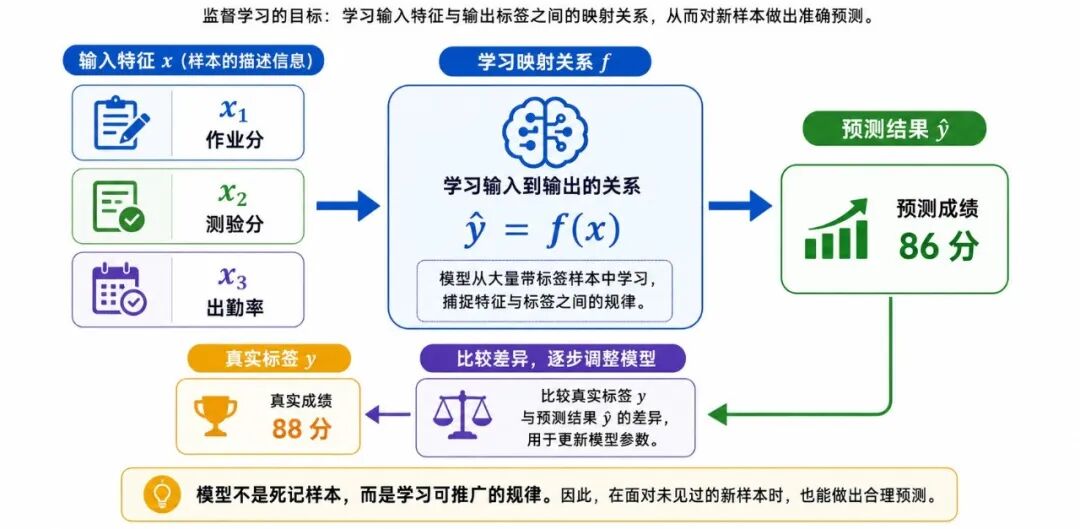
图 3:监督学习在学什么
例如,在学生成绩预测问题中,模型可能逐步学会:
• 作业分数高,期末成绩通常也偏高
• 测验成绩能够反映阶段性学习效果
• 出勤率较低时,成绩可能受到影响
多个特征共同作用,最终决定预测结果。
如果使用线性形式描述输入与输出的关系,可以写成:
其中:
• x₁, x₂, ..., xₙ 表示各个输入特征
• w₁, w₂, ..., wₙ表示对应特征的权重
• b 表示偏置项
• ŷ 表示模型预测结果
这个公式并不是说所有监督学习都必须是线性的,而是帮助我们建立一个最基础的理解:模型会根据训练数据,学习不同特征与目标结果之间的关系。
在训练过程中,模型会不断比较"预测结果"和"真实标签"之间的差异。这个差异通常由损失函数(Loss Function)刻画。模型训练的基本目标,就是让这种差异尽可能小。
对于回归任务,常见的损失函数之一是均方误差(Mean Squared Error,MSE):
其中:
• n 表示样本数量
• yᵢ 表示第 i 个样本的真实值
• ŷᵢ 表示第 i 个样本的预测值
• yᵢ − ŷᵢ 表示预测误差
更一般地说,监督学习就是在寻找一个函数,使它对已知样本的预测尽量接近真实标签,并且对新样本也具有较好的预测能力。
延伸阅读:
五、监督学习的两大任务:回归与分类
虽然监督学习任务很多,但从输出结果的性质来看,最常见的可以分成两大类:回归与分类。
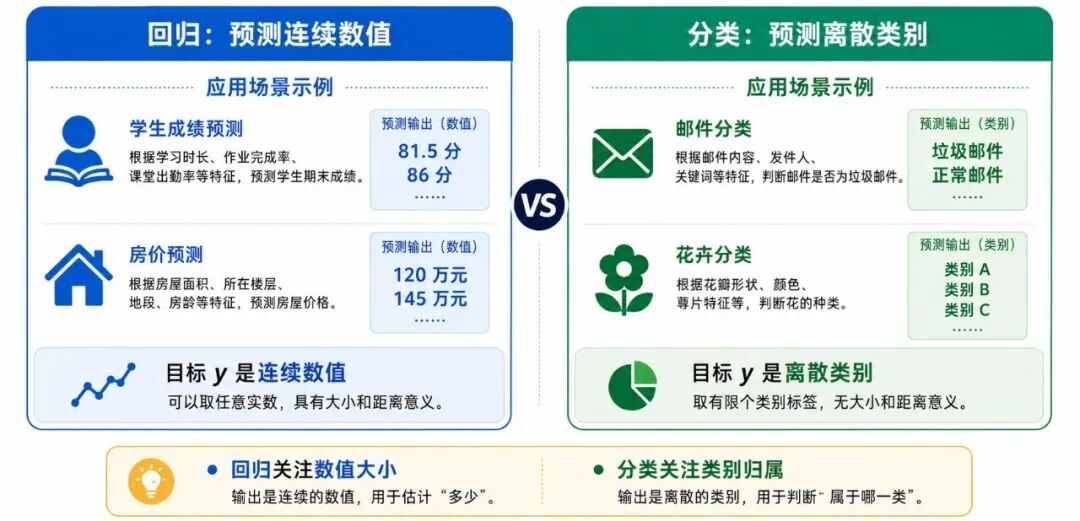
图 4:回归与分类的区别
1、回归:预测连续数值
如果标签是一个连续变化的数值,那么这类监督学习任务通常称为"回归"(Regression)。
例如:
• 预测房价
• 预测商品销量
• 预测考试成绩
• 预测气温或能耗
• 预测用户未来消费金额
这些任务的共同点在于:输出结果不是固定类别,而是可以在某个数值范围内连续变化。
例如,预测学生成绩时,输出可能是 81.5 分、86 分、73 分,而不是"优""良""中"这类有限类别。
回归任务的核心是建立特征与连续数值目标之间的关系。线性回归、多项式回归和岭回归分别代表了基础线性建模、非线性扩展和正则化控制三种常见思路。
延伸阅读:
2、分类:预测离散类别
如果标签属于有限个类别之一,那么这类监督学习任务通常称为"分类"(Classification)。
例如:
• 判断邮件是否为垃圾邮件
• 判断图像中是猫还是狗
• 判断一朵鸢尾花属于哪一种品种
• 判断一条评论是正面还是负面
• 判断用户是否会流失
这些任务的共同点在于:模型输出的不是连续数值,而是某种类别标签。
分类任务还可以继续分为二分类与多分类。
二分类(Binary Classification)只有两个类别。例如:
• 垃圾邮件 / 正常邮件
• 患病 / 未患病
• 会流失 / 不会流失
多分类(Multiclass Classification)有三个或更多类别。例如:
• 手写数字识别中的 0 到 9
• 鸢尾花分类中的不同品种
• 新闻文本分类中的不同主题
逻辑回归虽然名字中带有"回归",但常用于二分类任务,是理解分类模型的重要基础。
延伸阅读:
3、回归与分类的根本区别
回归与分类的根本区别,不在于使用的数据量多少,也不在于模型复杂不复杂,而在于预测目标的性质不同。
可以用一个简洁方式概括:
• 若目标 y 是连续数值,通常属于回归
• 若目标 y 是离散类别,通常属于分类
例如:
• "这套房大约值多少钱"是回归问题
• "这封邮件是不是垃圾邮件"是分类问题
• "这名学生期末成绩大约是多少分"是回归问题
• "这名学生属于优秀、良好还是及格"是分类问题
监督学习之所以常常先分为这两大类,是因为它们在目标形式、评价指标和常用模型上都有明显区别。
有些监督学习方法既可以用于分类,也可以用于回归,区别主要取决于目标变量 y 是离散类别还是连续数值。K 近邻、决策树、随机森林和支持向量机就是这类典型方法。
延伸阅读:
六、机器是怎样学的:训练、预测与评估
监督学习通常不是"一步得到答案",而是由几个连续环节组成。
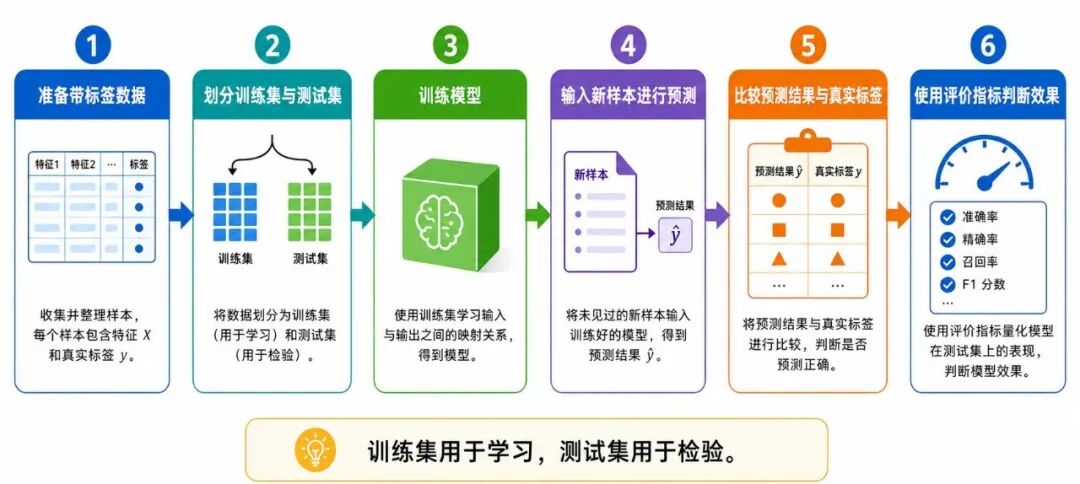
图 5:监督学习的训练、预测与评估流程
1、训练
训练(Training)就是把带标签的样本交给模型,让模型根据这些样本学习内部参数。
在这个阶段,模型看到的是"有答案的数据"。
例如,对于学生成绩预测任务,训练数据中既有学生的作业分、测验分、出勤率,也有对应的期末成绩。模型要做的,就是从这些数据中学习哪些特征与成绩之间存在关系。
2、预测
预测(Prediction)就是把新的、未见过的样本交给模型,由模型给出结果。
在这个阶段,模型不能再依赖人工给出的标签,而要用自己学到的规律进行判断。
例如,新来一位学生,我们只知道他的作业分、测验分和出勤率,并不知道他的期末成绩。模型需要根据已有经验给出一个预测分数。
3、评估
评估(Evaluation)是指把模型预测结果与真实结果进行比较,从而判断模型表现如何。
在回归任务中,可以比较预测值与真实值相差多少。
在分类任务中,除了准确率,还常用精确率、召回率、F1 值和混淆矩阵等指标,尤其适合处理类别不平衡或错误代价不同的场景。
延伸阅读:
《Scikit-learn:从问题到模型------监督学习的最小闭环》
七、泛化能力才是关键
监督学习中,一个很重要的问题是:模型在训练数据上表现好,是否就说明它真的学得好?
答案并不一定。
因为模型可能只是把训练样本记得很熟,但这种"熟悉"并不代表它面对新样本时仍然有效。机器学习真正关心的,不是模型对旧数据记得多牢,而是它对新数据是否仍能给出合理判断。
这种能力,通常称为"泛化能力"(Generalization)。
为了检验这一点,常见做法是把数据划分为:
• 训练集:用于让模型学习
• 测试集:用于检验模型在未见样本上的表现
也就是说:
• 模型在训练集上学习规律
• 模型在测试集上接受检验
只有当模型不仅在训练集上表现较好,而且在测试集上也有较合理的结果时,才更有可能说明它真正学到了一般规律,而不是只是"记住了答案"。
在更完整的建模流程中,还可能进一步划分验证集,用于模型选择、超参数调整和训练过程中的效果比较。
与泛化能力密切相关的两个概念是欠拟合与过拟合。
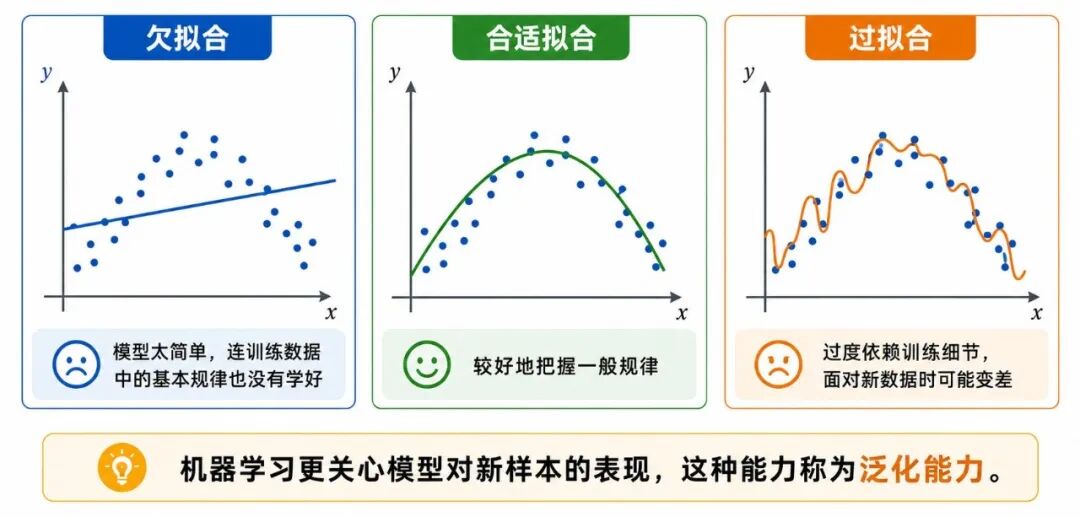
图 6:泛化能力:欠拟合、合适拟合与过拟合
欠拟合(Underfitting)是指模型过于简单,连训练数据中的基本规律也没有学好。
过拟合(Overfitting)是指模型过于依赖训练数据中的细节,导致面对新数据时表现变差。
从监督学习的角度看,泛化能力比单纯的训练准确率更重要,因为现实中的预测任务面对的往往正是"未来的新样本"。
延伸阅读:
八、综合示例:用监督学习完成一次学生成绩预测
下面用一个简单示例,把监督学习中的几个核心环节串起来。
任务是:根据学生的平时作业分、测验分和出勤率,预测其期末成绩。
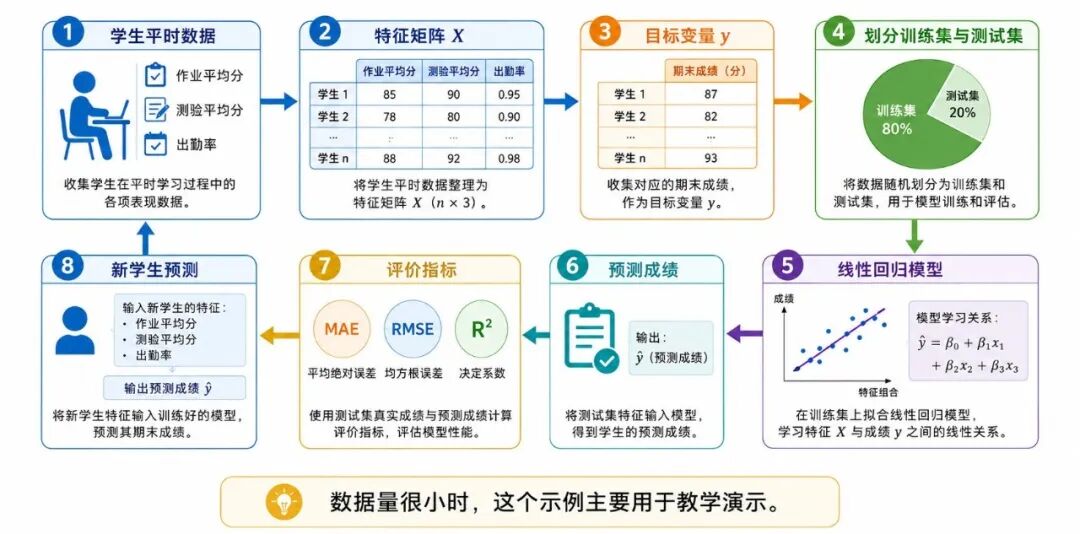
图 7:学习成绩预测中的监督学习闭环
需要注意的是,下面的数据量很小,只适合教学演示。真实建模时,通常需要更多样本、更严格的数据清洗、更合理的特征设计和更充分的评估。
cs
import numpy as np # 数值计算from sklearn.model_selection import train_test_split # 数据集划分from sklearn.linear_model import LinearRegression # 线性回归模型from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score # 评估指标
# 每一行表示一个学生样本:[作业平均分, 测验平均分, 出勤率]X = np.array([ [80, 78, 90], [85, 82, 95], [60, 65, 70], [90, 88, 98], [70, 72, 80], [88, 85, 96], [75, 74, 85], [92, 90, 99], [68, 70, 78], [95, 94, 100], [58, 62, 68], [82, 80, 92]])
# 期末成绩(目标变量)y = np.array([81, 86, 66, 92, 73, 89, 76, 94, 71, 96, 63, 84])
# 划分训练集和测试集(测试集占25%)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42)
# 创建线性回归模型model = LinearRegression()
# 训练模型(拟合训练数据)model.fit(X_train, y_train)
# 在测试集上预测y_pred = model.predict(X_test)
# 评价模型mae = mean_absolute_error(y_test, y_pred) # 平均绝对误差rmse = np.sqrt(mean_squared_error(y_test, y_pred)) # 均方根误差# 如果使用 Scikit-learn 1.4 及以上版本,也可以直接使用 root_mean_squared_error()r2 = r2_score(y_test, y_pred) # 决定系数
print("测试集真实值:", y_test)print("测试集预测值:", y_pred)print("平均绝对误差 MAE:", mae)print("均方根误差 RMSE:", rmse)print("决定系数 R²:", r2)
# 对新学生进行预测(作业86、测验84、出勤94)new_student = np.array([[86, 84, 94]])pred_score = model.predict(new_student)
print("新学生预测成绩:", pred_score[0])这个例子中已经体现出监督学习的基本结构:
• 有输入特征 X
• 有目标标签 y
• 用训练集训练模型
• 用测试集检验模型
• 用评价指标衡量预测效果
• 对新样本执行预测
其中,LinearRegression 会根据训练数据学习输入特征与期末成绩之间的线性关系;predict() 方法则根据学到的关系对测试样本或新学生进行预测。
在回归任务中,常见评价指标包括:
• MAE:平均绝对误差,表示预测值与真实值平均相差多少
• RMSE:均方根误差,对较大的预测错误更敏感
• R²:决定系数,用来衡量模型对目标变量变化的解释程度
由于本例中测试集样本很少,R² 等指标只用于理解流程,不宜作为模型性能的严肃判断依据。
如果把这个例子换成"预测房价",总体流程仍然成立;如果把它换成"判断邮件类型",任务类型会从回归变成分类,但"准备数据、训练模型、预测结果、评估效果"的基本思路仍然相通。
延伸阅读:
《人工智能通识课:Scikit-learn 机器学习工具库》
九、监督学习的意义与局限
监督学习之所以应用广泛,是因为很多现实任务本身就具有"历史数据 + 已知答案"的结构。只要样本积累到一定程度,机器就有可能从中提取出有效规律。
它的重要意义主要体现在以下几个方面:
• 能把经验判断转化为可计算模型
• 能处理规模较大的预测与分类任务
• 能在相似场景中重复使用
• 能为许多实际人工智能系统提供基础能力
• 能与数据预处理、特征工程、模型评估等方法结合成完整工作流
但监督学习也并不是没有前提。它通常依赖以下条件:
• 需要较明确的标签数据
• 样本质量会直接影响学习效果
• 特征表示会影响模型能够学到什么
• 模型学到的是数据中的统计规律,不等于真正理解现实世界
• 如果训练数据存在偏差,模型结果也可能随之偏差
• 如果应用场景发生变化,原来训练好的模型可能不再可靠
因此,监督学习虽然强大,但它并不是"万能判断器",而是一种建立在数据表示、标签质量、模型假设和评估机制之上的方法。
学习监督学习时,最重要的不是死记某个算法名称,而是理解它背后的基本问题:
• 输入是什么?
• 标签是什么?
• 模型要预测什么?
• 用什么数据训练?
• 用什么数据评估?
• 评价指标是否符合任务目标?
• 模型能否推广到新样本?
能够回答这些问题,才算真正进入了监督学习的基本思维方式。
📘 小结
监督学习是在带标签样本上学习输入与输出关系的方法。它以样本、特征、标签为基础,主要包括回归与分类两类任务,并通过训练、预测、评估和泛化检验形成完整流程。理解监督学习,是进入机器学习应用世界的重要起点。

"点赞有美意,赞赏是鼓励"