1. lifecycle作用(提供生命周期感知能力)
传统方式在生命周期回调编写代码,当组件需要感知生命周期,需要持有组件引用;
如果异步任务(如网络请求、数据库查询)在组件销毁后仍然持有其引用,可能导致内存泄漏。
传统方式需要在 onDestroy中手动取消任务,容易遗漏。
lifecycle保存组件生命周期状态,弱引用持有组件,将业务逻辑从组件生命周期回调中抽出解耦,通过 LifecycleObserver和 Lifecycle绑定,确保在适当的时机释放 LifecycleObserver,destroy时自动移除观察者,防止泄露。
通过Lifecycle通知观察者已经到达某个生命周期,观察者就可以执行对应逻辑,减少内存泄漏、空指针等问题,并且进行解耦。
2. lifecycle源码分析
lifecycle内部的类不多,主要有四个,LifeCycleOwner、LifeCycle、LifeCycleObserver、LifeCycling.
2.1 LifeCycleOwner
java
public interface LifecycleOwner {
/**
* Returns the Lifecycle of the provider.
*
* @return The lifecycle of the provider.
*/
@NonNull
Lifecycle getLifecycle();
}lifeCycleOwner是一个接口,要求实现获取LifeCycle的方法,一个组件如果要提供生命周期状态给外部,可以实现lifeCycleOwner,通过getLifeCycle返回LifeCycle的实例,LifeCycle保存了组件当前的生命周期,组件生命周期变化时会通知LifeCycle所有观察者。所以需要感知生命周期的外部组件只要观察lifecycle即可。
2.2 LifeCycle
java
public abstract class Lifecycle {
AtomicReference<Object> mInternalScopeRef = new AtomicReference<>();
@MainThread
public abstract void addObserver(@NonNull LifecycleObserver observer);
@MainThread
public abstract void removeObserver(@NonNull LifecycleObserver observer);
@MainThread
@NonNull
public abstract State getCurrentState();
@SuppressWarnings("WeakerAccess")
public enum Event {
ON_CREATE,
ON_START,
ON_RESUME,
ON_PAUSE,
ON_STOP,
ON_DESTROY,
ON_ANY;
@Nullable
public static Event downFrom(@NonNull State state) {
switch (state) {
case CREATED:
return ON_DESTROY;
case STARTED:
return ON_STOP;
case RESUMED:
return ON_PAUSE;
default:
return null;
}
}
@Nullable
public static Event downTo(@NonNull State state) {
switch (state) {
case DESTROYED:
return ON_DESTROY;
case CREATED:
return ON_STOP;
case STARTED:
return ON_PAUSE;
default:
return null;
}
}
@Nullable
public static Event upFrom(@NonNull State state) {
switch (state) {
case INITIALIZED:
return ON_CREATE;
case CREATED:
return ON_START;
case STARTED:
return ON_RESUME;
default:
return null;
}
}
@Nullable
public static Event upTo(@NonNull State state) {
switch (state) {
case CREATED:
return ON_CREATE;
case STARTED:
return ON_START;
case RESUMED:
return ON_RESUME;
default:
return null;
}
}
@NonNull
public State getTargetState() {
switch (this) {
case ON_CREATE:
case ON_STOP:
return State.CREATED;
case ON_START:
case ON_PAUSE:
return State.STARTED;
case ON_RESUME:
return State.RESUMED;
case ON_DESTROY:
return State.DESTROYED;
case ON_ANY:
break;
}
throw new IllegalArgumentException(this + " has no target state");
}
}
@SuppressWarnings("WeakerAccess")
public enum State {
DESTROYED,
INITIALIZED,
CREATED,
STARTED,
RESUMED;
public boolean isAtLeast(@NonNull State state) {
return compareTo(state) >= 0;
}
}
}lifecycle是一个抽象类,内部有个AtomicReference变量,预留用于在kotlin的实现中存储lifecycleScope;提供添加和移除观察者的函数、获取当前所在生命周期的函数;另外有两个内部枚举类Event和State。
在经历一个生命周期事件(event)后,lifecycle的状态(state)会随着变化,属于一种状态机的实现。根据以下流程图,可以了解lifecycle的状态流转过程。
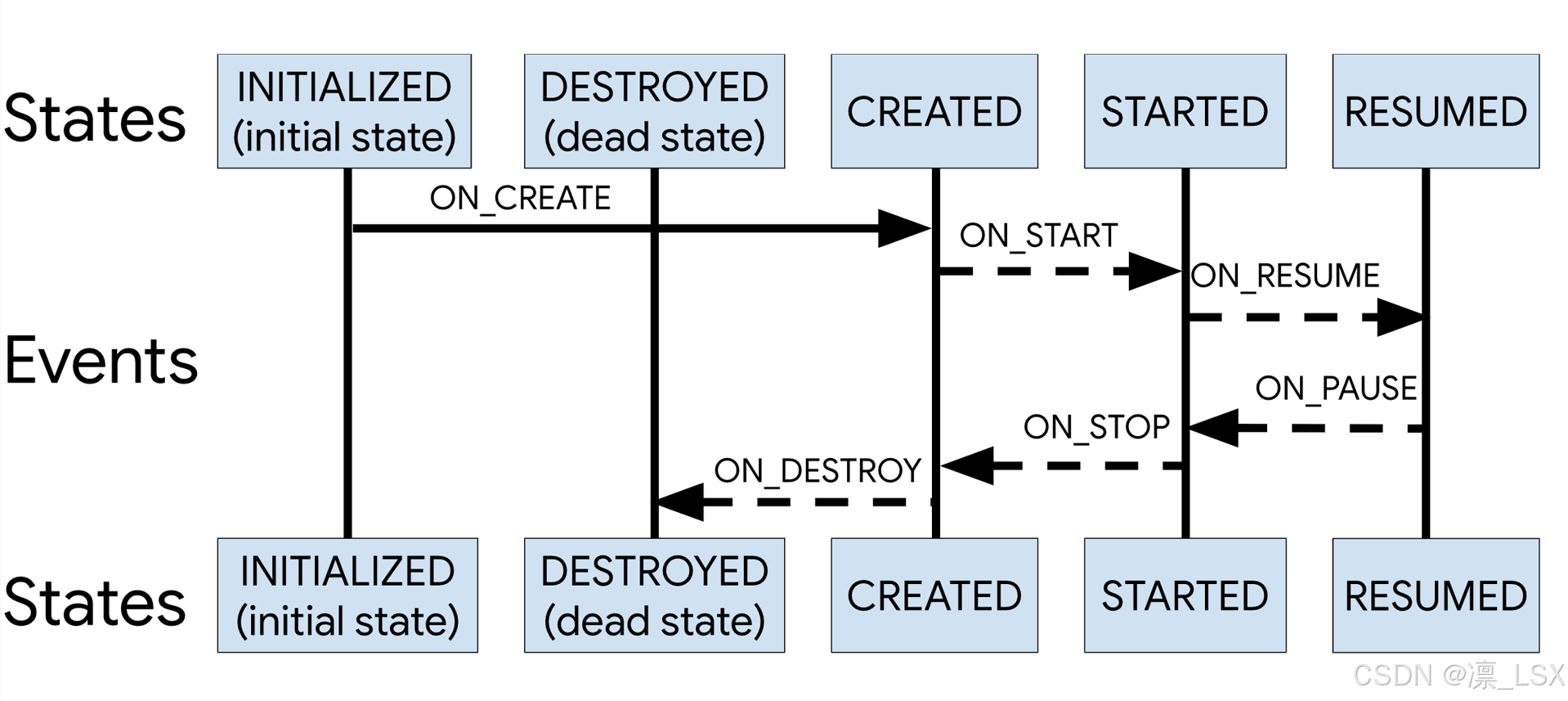
最开始是INITIALIZED状态,经过ON_CREATE事件转移到CREATED状态,经过ON_START事件转移到STARTED状态,经过ON_RESUME事件转移到RESUMED状态; (这几步状态转移属于前向转移,代表的是创建过程,在lifecycle设计中,这些流转是重点关注的,所以在这几个生命周期中添加观察者,观察者不仅可以收到后续生命周期变更信息,还可以收到之前已经历的生命周期变更,因为可能需要使用到,所以设计时都进行回调,如果不使用的话可以忽略,可以不用但是不能没有)
从RESUMED状态,经过ON_PAUSE事件回到STARTED状态,经过ON_STOP事件回到CREATED状态,经过ON_DESTROY事件回到DESTROYED状态。(这几步状态转移属于回退转移,代表的是销毁过程,在lifecycle设计中,这些流转是代表退到后台、销毁,所以不关心之前经历的生命周期事件,虽然可能会收到回调,但是没有实际意义,不应该处理)
例如:在OnResume注册观察者,最终回调会收到ON_CREATE、ON_START、ON_RESUME;如果在OnStop注册观察者,最终收到ON_CREATE,但是没有实际意义。(这里可能有些迷惑,后面解析addObserver状态流转时会说明)
2.3 LifeCycleObserver
LifeCycleObsever是一个接口,代表了一个lifecycle的观察者,在源码中有好几个相关类。
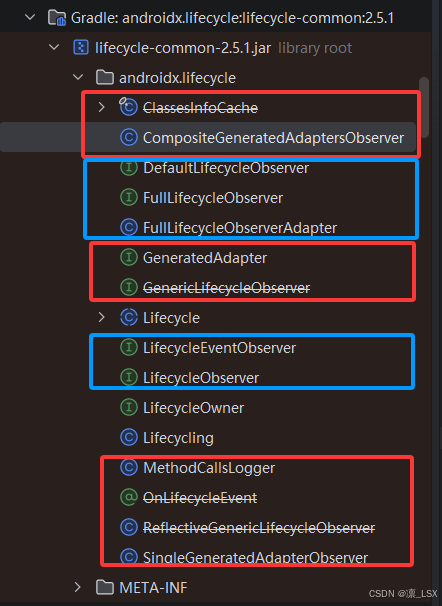
蓝框部分是目前主要使用的类,也是官方推荐的;红框部分是早期使用OnLifecycleEvent机制时用到的类,还有一些后来改进的类,以优化反射开销。
2.3.1 LifecycleObserver的子类
lifecycleObserver有两个直接子类,LifecycleEventObserver和FullLifecycleObserver.
java
public interface LifecycleEventObserver extends LifecycleObserver {
void onStateChanged(@NonNull LifecycleOwner source, @NonNull Lifecycle.Event event);
}
interface FullLifecycleObserver extends LifecycleObserver {
void onCreate(LifecycleOwner owner);
void onStart(LifecycleOwner owner);
void onResume(LifecycleOwner owner);
void onPause(LifecycleOwner owner);
void onStop(LifecycleOwner owner);
void onDestroy(LifecycleOwner owner);
}两个实现有些不同,一个是把事件event传入,自行处理,另一个是直接回调事件对应生命周期。
LifecycleEventObserver还有一个子类GenericLifecycleObserver,不过是空实现,也标注废弃,不管它。
FullLifecycleObserver也有一个子类DefaultLifecycleObserver,这个子类为每个生命周期方法添加了default实现,好处是不用像之前一样必须实现所有回调方法,某些回调如果不需要的话可以不重写,自动使用default实现。现在推荐是使用DefaultLifecycleObserver
2.3.2 OnLifecycleEvent机制
注解方式回调是 Lifecycle 早期为了降低接入成本、避免接口爆炸而采用的权宜之计;它在当时提供了更好的解耦性和开发体验,但随着 Lifecycle 演化为 State + Event 模型,接口方式(LifecycleEventObserver / FullLifecycleObserver)在性能、语义清晰度和可维护性上都明显优于注解方式,因此逐渐取代了它。
java
getLifecycle().addObserver(new LifecycleObserver() {
@OnLifecycleEvent(Lifecycle.Event.ON_ANY)
public void test(LifecycleOwner owner, Lifecycle.Event event) {
LogUtil.d(TAG, "test owner= " + owner + " event= "+ event.name());
}
@OnLifecycleEvent(Lifecycle.Event.ON_START)
public void test1(LifecycleOwner owner) {
LogUtil.d(TAG, "test1 owner= " + owner );
}
});这种使用注解的方式,在对应事件触发时回调添加注解的方法,可以只关注某个生命周期方法,但是有运行时方式开销,设计者的优化方法是使用ClassesInfoCache类进行缓存,不过从2.5.1的源码可以看到这些反射相关类都废弃了
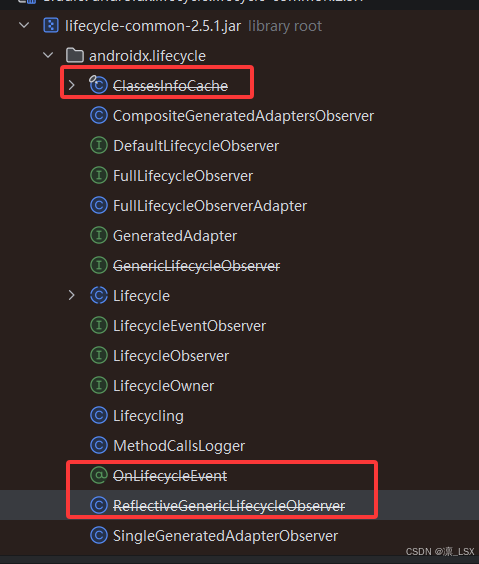
(2.4之前版本的源码)当引入androidx.lifecycle:lifecycle-compiler依赖,这种使用注解,运行时解析的方式会在编译时替换为GeneratedAdapter实现,直接进行callMethods,避免了反射开销,改为普通方法调用。(2.5.1好像不行了,不再看到有GeneratedAdapter辅助类生成)
java
public interface GeneratedAdapter {
void callMethods(LifecycleOwner source, Lifecycle.Event event, boolean onAny,
MethodCallsLogger logger);
}这部分内容了解一下即可,现在不推荐用注解的方式了。
2.4 lifeCycling
lifeCycling是Lifecycle的一个内部类。在官方推荐的Lifecycle实现->LifecycleRegistry中用到。对外提供的方法有三个-> 1.getCallback, 已经废弃,不管它; 2.getAdapterName,用于2.4之前版本源码,在引入lifecycle-compiler依赖后,OnLifecycleEvent注解生成辅助类,类名获取就用这个函数; 3.lifecycleEventObserver,重点,将各种lifecycleObserver都转换为统一的接口LifecycleEventObserver。
2.4.1 lifecycleEventObserver
不同Observer,创建相应的对象进行返回
java
static LifecycleEventObserver lifecycleEventObserver(Object object) {
//1.添加进来的是LifecycleEventObserver、FullLifecycleObserver或者它们的子类
//判断类型,是LifecycleEventObserver还是FullLifecycleObserver
boolean isLifecycleEventObserver = object instanceof LifecycleEventObserver;
boolean isFullLifecycleObserver = object instanceof FullLifecycleObserver;
//对象同时实现两个接口或者是FullLifecycleObserver,创建FullLifecycleObserverAdapter
if (isLifecycleEventObserver && isFullLifecycleObserver) {
return new FullLifecycleObserverAdapter((FullLifecycleObserver) object,
(LifecycleEventObserver) object);
}
if (isFullLifecycleObserver) {
return new FullLifecycleObserverAdapter((FullLifecycleObserver) object, null);
}
//对象只是LifecycleEventObserver,直接返回
if (isLifecycleEventObserver) {
return (LifecycleEventObserver) object;
}
//2. 添加进来的是LifecycleObserver(说明是OnLifecycleEvent注解方式)
//(OnLifecycleEvent已废弃,这部分不太重要,可以不看)
final Class<?> klass = object.getClass();
int type = getObserverConstructorType(klass);
if (type == GENERATED_CALLBACK) {
List<Constructor<? extends GeneratedAdapter>> constructors =
sClassToAdapters.get(klass);
if (constructors.size() == 1) {
GeneratedAdapter generatedAdapter = createGeneratedAdapter(
constructors.get(0), object);
return new SingleGeneratedAdapterObserver(generatedAdapter);
}
GeneratedAdapter[] adapters = new GeneratedAdapter[constructors.size()];
for (int i = 0; i < constructors.size(); i++) {
adapters[i] = createGeneratedAdapter(constructors.get(i), object);
}
return new CompositeGeneratedAdaptersObserver(adapters);
}
return new ReflectiveGenericLifecycleObserver(object);
}(这部分是OnLifecycleEvent注解方式添加Observer如何转化成统一接口lifecycleEventObserver的讲解,可选择不看)
首先是int type = getObserverConstructorType(klass); 这部分代码也是获取Observer类型,这个类型是指注解的处理方式,一种是通过反射、另一种是编译生成辅助类,改为普通方法调用。其中sCallbackCache 对已经处理过的Observer类,其属于哪种类型做了缓存,下一次遇到就可以直接返回,不需要调用resolveObserverCallbackType进行解析了。
java
//定义两种类型,通过反射处理注解(1)、通过改成编译后普通方法调用(2)
private static final int REFLECTIVE_CALLBACK = 1;
private static final int GENERATED_CALLBACK = 2;
//缓存已经解析过的Observer是属于哪种类型
private static Map<Class<?>, Integer> sCallbackCache = new HashMap<>();
//存储处理类型是GENERATED_CALLBACK的Observer,其生成的辅助类
private static Map<Class<?>, List<Constructor<? extends GeneratedAdapter>>>
sClassToAdapters = new HashMap<>();
private static int getObserverConstructorType(Class<?> klass) {
Integer callbackCache = sCallbackCache.get(klass);
if (callbackCache != null) {
return callbackCache;
}
int type = resolveObserverCallbackType(klass);
sCallbackCache.put(klass, type);
return type;
}知道属于哪种类型后,如果是需要进行反射处理的,直接返回ReflectiveGenericLifecycleObserver;如果是生成辅助类,改为普通方法调用的,进入if。会获取此Observer生成辅助类的构造器 的list。
List<Constructor<? extends GeneratedAdapter>> constructors =
sClassToAdapters.get(klass);
之前在获取类型时,会调用resolveObserverCallbackType解析类型,在这个过程中会为GENERATED_CALLBACK 类型的Observer创建辅助类构造器,放到sClassToAdapters 中,一般来说都只有一个。 但是如果Observer实现两个接口,且两个接口都有@OnLifecycleEvent注解,或者在Observer继承中,父类有@OnLifecycleEvent注解,子类也有一个新的@OnLifecycleEvent注解,那么最后生成的辅助类需要两个,构造器就会有两个。
如果辅助类只有一个,创建SingleGeneratedAdapterObserver,如果有多个,创建CompositeGeneratedAdaptersObserver。
2.5 LifecycleRegistry
说完Lifecycle源码定义的几个类,看看官方推荐的Lifecycle实现
2.5.1 LifecycleRegistry的成员
java
//持有所有的观察者对象 LifecycleObserver 以及 由该观察者对象构造的封装对象
//ObserverWithState。
private FastSafeIterableMap<LifecycleObserver, ObserverWithState> mObserverMap =
new FastSafeIterableMap<>();
//用于表示当前状态
private State mState;
//通过弱引用持有 LifecycleOwner。一般是activity或者fragment,防止内存泄漏
private final WeakReference<LifecycleOwner> mLifecycleOwner;
//记录当前有多少个 addObserver 方法正在执行中。
//每次进入 addObserver 方法时,该计数器加 1;方法退出前减 1
private int mAddingObserverCounter = 0;
//一个布尔标志位,用来标记当前 LifecycleRegistry 是否正处于分发事件的过程中
private boolean mHandlingEvent = false;
//这是一个临时的通知标志,用于在状态同步的循环过程中"打断"或"提示"当前流程
private boolean mNewEventOccurred = false;
//一个 ArrayList,充当临时状态栈,用来解决在事件分发中途动态添加新观察者时的状态对齐问题。
private ArrayList<State> mParentStates = new ArrayList<>();
//用来控制是否强制检查当前的操作是否在主线程执行。
private final boolean mEnforceMainThread;2.5.1.1 mObserverMap
一个自定义的 FastSafeIterableMap,用于存储所有注册的观察者。
为什么不用普通的 HashMap 或 ArrayList? 因为在遍历分发事件时,可能会动态地添加或移除观察者。FastSafeIterableMap 底层结合了链表和 HashMap,既保证了查找速度,又完美支持在迭代遍历时安全地进行元素的增删,避免了并发修改异常(ConcurrentModificationException)
存储的Value是一个ObserverWithState,存储了统一的观察者接口 LifecycleEventObserver和观察者目前所处的状态。
2.5.1.2 mAddingObserverCounter
记录当前有多少个 addObserver 方法正在执行中。它和 mHandlingEvent 配合使用,共同判断是否处于"重入"状态。如果该值大于 0,说明正在往集合里添加观察者。此时如果触发了状态同步,只需要在最外层的 addObserver 结束时同步一次即可,避免在递归或嵌套添加观察者时产生大量无用的重复计算。
2.5.1.3 mHandlingEvent
用来标记当前 LifecycleRegistry 是否正处于"分发事件"的过程中。
当调用 handleLifecycleEvent 准备更新状态并同步给观察者时,会先将它设为 true,分发完成后再设为 false。
如果在分发事件的过程中(mHandlingEvent = true),又收到了新的生命周期事件(例如在 onStart 的分发途中突然来了个 onResume),系统就知道现在不宜立刻处理新事件,而是会先通过 mNewEventOccurred 标记一下,等当前这一轮分发彻底结束后再进行下一轮同步。
2.5.1.4 mNewEventOccurred
这是一个临时的通知标志,用于在状态同步的循环过程中"打断"或"提示"当前流程。
当系统正在执行 sync() 同步状态时,如果中途触发了新的生命周期变化(此时 mHandlingEvent 为 true),就会把 mNewEventOccurred 设为 true。
正在执行的 sync() 循环(forwardPass 或 backwardPass)会检测到这个标志,从而提前结束当前的遍历。这样可以确保在处理完手头的状态后,能尽快重新评估最新的生命周期状态,防止旧的事件分发逻辑掩盖了最新的变化。
2.5.1.5 mParentStates
一个 ArrayList,充当"临时状态栈",用来解决在事件分发中途动态添加新观察者时的状态对齐问题。
假设宿主正在分发 ON_START 事件(意味着它即将达到 STARTED 状态)。就在这个分发过程中,某个观察者又调用了 addObserver 添加了一个全新的观察者。
这个新来的观察者初始状态是 INITIALIZED。但在计算它应该同步到哪个目标状态(targetState)时,不能只看宿主的当前状态,还得知道"我现在正卡在 ON_START 的分发路上"。此时,系统会通过 pushParentState 将当前的中间状态压入 mParentStates。
calculateTargetState 方法在计算新观察者的目标状态时,会参考 mParentStates 里的信息,从而精准地算出新观察者应该被推进到的正确状态,避免出现状态遗漏或越级。
2.5.1.6 mEnforceMainThread
用来控制是否强制检查当前的操作是否在主线程执行。在 Android 开发中,UI 组件(如 Activity、Fragment)的生命周期回调必须在主线程进行。为了保证 Lifecycle 组件的安全性和稳定性,Jetpack 默认要求所有与生命周期相关的操作(比如添加观察者 addObserver、分发事件 handleLifecycleEvent 等)都必须在主线程完成。
这个开关为了满足以下两种特殊的非 UI 场景:
JVM 单元测试:在本地跑纯 Java/Kotlin 的单元测试时,并没有 Android 的主线程(Main Looper)环境。如果不关掉这个检查,测试代码会因为无法获取主线程而直接报错崩溃。
非 UI 组件的状态管理:极少数情况下,开发者可能会在非 UI 的业务逻辑组件中复用 Lifecycle 机制来做状态分发。如果这些业务逻辑本身就在后台线程运行,强制的主线程检查反而会成为一种限制。
2.5.2 关键函数分析
向外部提供的函数有以下几个
1.markState,已经废弃了,现在用setCurrentState,作用是设置lifecycle当前的状态并同步到所有观察者。
2.handleLifecycleEvent,处理生命周期事件,改变LifecycleRegistry状态并同步到所有观察者。
3.addObserver,添加观察者,并将其同步到LifecycleRegistry当前状态。
4.removeObserver,移除观察者。
5.getObserverCount,获取目前观察者数量。
6.getCurrentState,获取LifecycleRegistry当前状态。
7.createUnsafe,创建一个不强制检查当前的操作是否在主线程执行的LifecycleRegistry。
2.5.2.1 handleLifecycleEvent
java
public void handleLifecycleEvent(@NonNull Lifecycle.Event event) {
enforceMainThreadIfNeeded("handleLifecycleEvent");
moveToState(event.getTargetState());
}
private void moveToState(State next) {
if (mState == next) {
return;
}
if (mState == INITIALIZED && next == DESTROYED) {
throw new IllegalStateException("no event down from " + mState);
}
mState = next;
if (mHandlingEvent || mAddingObserverCounter != 0) {
mNewEventOccurred = true;
// we will figure out what to do on upper level.
return;
}
mHandlingEvent = true;
sync();
mHandlingEvent = false;
if (mState == DESTROYED) {
mObserverMap = new FastSafeIterableMap<>();
}
}先检查是否在主线程,然后计算此事件处理后,lifecycle会去到哪个状态,调用moveToState进行状态转移。
moveToState中,如果已经处于目标状态直接返回,不然继续往下走,如果当前状态是刚创建(INITIALIZED),下一步直接跳到 DESTROYED,在合法的 Android 生命周期流转中是绝对不存在的 ,如果程序试图执行这一步,说明底层出现了严重的逻辑漏洞或调用错误,需要抛异常终止。
接下来将LifecycleRegistry的状态设置为转移的目标状态,然后识别重入场景:
检查 if (mHandlingEvent || mAddingObserverCounter != 0)。这两个标志位分别代表"正在分发事件"和"正在添加观察者"。 如果满足条件,说明当前正处于一次状态同步的半途中(比如在分发 ON_START 的过程中又收到了 ON_RESUME)。此时不能立刻再次触发 sync(),否则会导致递归调用甚至死循环。 系统会将 mNewEventOccurred 设为 true,相当于做一个标记,然后暂时退出。等最外层的同步流程走完后,系统会检测到这个标记并重新发起一轮同步。
如果不是重入场景,系统会将 mHandlingEvent 设为 true(锁定当前正在进行事件分发),紧接着调用核心的 sync() 方法。 sync() 会遍历所有的观察者,根据宿主最新的 mState,决定是向前推进(forwardPass)还是向后回退(backwardPass),确保所有观察者的状态都与宿主对齐。 同步完成后,将 mHandlingEvent 设回 false,解除锁定。
最后如果组件的生命周期走到终点(DESTROYED)时,意味着它即将被系统回收。此时直接把存储观察者的 Map 替换成一个新的空集合,可以迅速切断对所有观察者的引用,帮助垃圾回收器(GC)及时释放内存,有效防止内存泄漏。
接下来看一下sync做了什么
java
private void sync() {
LifecycleOwner lifecycleOwner = mLifecycleOwner.get();
if (lifecycleOwner == null) {
throw new IllegalStateException("LifecycleOwner of this LifecycleRegistry is already"
+ "garbage collected. It is too late to change lifecycle state.");
}
while (!isSynced()) {
mNewEventOccurred = false;
// no need to check eldest for nullability, because isSynced does it for us.
if (mState.compareTo(mObserverMap.eldest().getValue().mState) < 0) {
backwardPass(lifecycleOwner);
}
Map.Entry<LifecycleObserver, ObserverWithState> newest = mObserverMap.newest();
if (!mNewEventOccurred && newest != null
&& mState.compareTo(newest.getValue().mState) > 0) {
forwardPass(lifecycleOwner);
}
}
mNewEventOccurred = false;
}在开始同步之前,首先检查宿主(比如 Activity)是否已经被垃圾回收(GC)。(因为 LifecycleRegistry 内部持有的是宿主的弱引用,如果宿主已经不在了,再继续分发状态不仅没有意义,还可能导致程序出错,所以这里会直接抛出异常终止操作。)
接下来进入while循环,只要 isSynced() 返回 false(意味着还有观察者的状态没对齐),这个循环就会一直执行。它会不断地拉平宿主与观察者之间的状态差异。
while循环在处理状态前向转移或者回退转移之前,会将mNewEventOccurred设置false。
为什么每次循环开始都要设置成 false?(清零旧状态) 这相当于给当前这一轮的同步任务做一个"初始化"。 假设在上一轮 while 循环中,因为某些原因(比如在分发事件时又添加了新观察者)导致 mNewEventOccurred 被置为了 true。 进入新一轮循环时,必须先把这个标记擦掉。我们得假设"这一轮是平静的",如果在接下来的 backwardPass 或 forwardPass 过程中,真的又有新的事件插队进来,相关的代码会再次把它设为 true。如果不先清零,旧的 true 就会导致逻辑误判。
然后开始处理状态转移,取出最早加入的观察者(eldest),比较它的状态和宿主当前的 mState。如果宿主的当前状态 小于 观察者的状态,说明宿主正在经历生命周期的倒退(例如从 RESUMED 回到了 STARTED,或者正在被销毁)。 这时调用 backwardPass。这个方法会倒序遍历所有的观察者,依次向它们分发 ON_PAUSE、ON_STOP 等事件,把它们的落后状态一步步往回拉,直到与宿主对齐。
之后尝试前向转移。取出最新加入的观察者(newest)。如果!mNewEventOccurred 且宿主的当前状态 大于 它的状态,说明宿主状态正在向前转移(例如从 CREATED 到了 STARTED)。 这时调用 forwardPass。这个方法会正序遍历观察者,依次分发 ON_CREATE、ON_START 等事件,推着观察者的状态向前走。
!mNewEventOccurred 的作用:这是一个非常巧妙的防御机制。如果在执行 backwardPass 的过程中,突然插入了新的观察者或者发生了新的事件(导致 mNewEventOccurred 变成了 true),那么就先暂停 forwardPass。这样可以优先处理紧急的变动,避免在状态剧烈波动时产生混乱或死循环。拦截住 forwardPass 并不是要抛弃这个新事件,而是为了推迟处理。 当这一轮 while 循环结束后,由于状态还没完全对齐(因为有新事件插队),isSynced() 依然会返回 false。于是,while 循环会开启新一轮的同步: 在新的一轮开始时,mNewEventOccurred 会被重新清零为 false。 此时,系统会带着最新的状态(mState),重新评估是该 backwardPass 还是该 forwardPass。
看一下如何进行状态前向/回退转移,以前向forwardPass为例
java
private void forwardPass(LifecycleOwner lifecycleOwner) {
Iterator<Map.Entry<LifecycleObserver, ObserverWithState>> ascendingIterator =
mObserverMap.iteratorWithAdditions();
while (ascendingIterator.hasNext() && !mNewEventOccurred) {
Map.Entry<LifecycleObserver, ObserverWithState> entry = ascendingIterator.next();
ObserverWithState observer = entry.getValue();
while ((observer.mState.compareTo(mState) < 0 && !mNewEventOccurred
&& mObserverMap.contains(entry.getKey()))) {
pushParentState(observer.mState);
final Event event = Event.upFrom(observer.mState);
if (event == null) {
throw new IllegalStateException("no event up from " + observer.mState);
}
observer.dispatchEvent(lifecycleOwner, event);
popParentState();
}
}
}先获取一个正向迭代器,按照观察者被添加的顺序(从最早到最新)进行遍历。如果在分发过程中有新的生命周期事件发生(比如宿主突然销毁了),就会立刻停止当前的遍历,避免状态错乱。通过 !mNewEventOccurred拦截。
observer.mState 是当前观察者所处的状态,mState 是宿主当前的最新状态。 observer.mState < mState 说明该观察者落后于宿主,需要"追赶"上来(即执行生命周期前进的逻辑)。 mObserverMap.contains(entry.getKey()) 确保在遍历期间,这个观察者没有被中途移除。
接下来计算下个事件并进行分发之前,先pushParentState。pushParentState 的逻辑非常简单,就是把当前观察者的状态存入一个集合;与之对应的还有一个 popParentState() 方法,负责将刚刚存入的状态移除。它的核心作用是维护观察者(Observer)的有序性,并解决生命周期事件嵌套分发时的状态冲突问题。
例如:宿主(如 Activity)正在执行 onStart(),生命周期状态即将变为 STARTED。 系统开始按顺序通知已经注册的观察者,假设当前正在执行 观察者A 的 onStateChanged(ON_START) 回调。 在 观察者A 的这段回调代码里,业务逻辑决定动态注册一个新的 观察者B。 如果没有 pushParentState,新加入的 观察者B 会立刻尝试将自己的状态同步到宿主的最新状态(STARTED),于是 观察者B 的 onStateChanged(ON_START) 会被立即触发并执行完毕。此时,观察者A 的回调还没走完,而晚来的 观察者B 却抢先执行完了。这就打破了 Lifecycle 严格保证的"观察者按添加顺序依次接收事件"的设计原则。
通过pushParentState,系统在准备分发 ON_START 给 观察者A 之前,先调用 pushParentState(observerA.mState),把 A 当前的状态暂存起来。 接着执行 观察者A 的回调。即使此时 A 内部注册了 观察者B,系统在计算 B 应该处于什么状态时,会检测到 mParentStates 集合里还有未处理完的父级状态(即 A 的状态)。 系统会强制让 观察者B 等待,将其目标状态限制在当前父级(A)的状态之下,确保必须等 观察者A 彻底执行完回调,并调用 popParentState() 清除暂存后,才会继续推进后续所有观察者的状态。
事件分发完成后popParentState,解除对后续事件的约束。
2.5.2.2 addObserver
java
public void addObserver(@NonNull LifecycleObserver observer) {
enforceMainThreadIfNeeded("addObserver");
State initialState = mState == DESTROYED ? DESTROYED : INITIALIZED;
ObserverWithState statefulObserver = new ObserverWithState(observer, initialState);
ObserverWithState previous = mObserverMap.putIfAbsent(observer, statefulObserver);
if (previous != null) {
return;
}
LifecycleOwner lifecycleOwner = mLifecycleOwner.get();
if (lifecycleOwner == null) {
// it is null we should be destroyed. Fallback quickly
return;
}
boolean isReentrance = mAddingObserverCounter != 0 || mHandlingEvent;
State targetState = calculateTargetState(observer);
mAddingObserverCounter++;
while ((statefulObserver.mState.compareTo(targetState) < 0
&& mObserverMap.contains(observer))) {
pushParentState(statefulObserver.mState);
final Event event = Event.upFrom(statefulObserver.mState);
if (event == null) {
throw new IllegalStateException("no event up from " + statefulObserver.mState);
}
statefulObserver.dispatchEvent(lifecycleOwner, event);
popParentState();
// mState / subling may have been changed recalculate
targetState = calculateTargetState(observer);
}
if (!isReentrance) {
// we do sync only on the top level.
sync();
}
mAddingObserverCounter--;
}首先进行主线程校验,确保添加观察者的操作必须在主线程进行,保证线程安全。
接下来确定初始状态。
State initialState = mState == DESTROYED ? DESTROYED : INITIALIZED;
这里决定了新加入的观察者的起点。如果宿主(如 Activity)已经被销毁(DESTROYED),观察者直接设为销毁态;否则,统一从 INITIALIZED(初始化)状态开始。
如果是DESTRORED状态,后续不会进行事件分发。
然后添加观察者到mObserverMap,添加前会将观察者构造为ObserverWithState对象。其中包含一个统一形式的观察者接口和观察者当前状态。
java
static class ObserverWithState {
State mState;
LifecycleEventObserver mLifecycleObserver;
ObserverWithState(LifecycleObserver observer, State initialState) {
mLifecycleObserver = Lifecycling.lifecycleEventObserver(observer);
mState = initialState;
}
void dispatchEvent(LifecycleOwner owner, Event event) {
State newState = event.getTargetState();
mState = min(mState, newState);
mLifecycleObserver.onStateChanged(owner, event);
mState = newState;
}
}添加后会返回一个ObserverWithState对象,如果观察者之前已经添加过,那么ObserverWithState非空,否则为空。如果ObserverWithState非空,那么就不会往下走了。
如果观察者还未添加过,继续往下看。
先获取 LifecycleOwner(宿主),如果为 null,说明宿主已销毁,直接返回。
如果宿主还存活,继续往下完成观察者状态同步到LifeCycleRegistry的操作。
先判断此次操作是否为重入,如果不是重入,完成观察者状态同步后,最终会触发sync(),遍历所有的观察者,确保它们的状态与宿主完全一致(无论是向前推进 forwardPass 还是向后回退 backwardPass)。这保证了在多观察者场景下,所有组件的生命周期感知都是准确且同步的。
接下来要计算一个保守的目标状态,Lifecycle 必须保证所有观察者的状态推进是有序且安全的(不能跳级,也不能让后来的观察者状态超过前面的观察者)。为了做到这一点,它会综合考量三个维度的状态,并取其中的最小值(Min)作为最终的目标状态。
java
private State calculateTargetState(LifecycleObserver observer) {
// 1. 获取当前观察者前一个观察者的状态 (siblingState)
Entry<LifecycleObserver, ObserverWithState> previous = mObserverMap.ceil(observer);
State siblingState = previous != null ? previous.getValue().mState : null;
// 2. 获取嵌套分发中的父状态 (parentState)
State parentState = !mParentStates.isEmpty() ? mParentStates.get(mParentStates.size() - 1) : null;
// 3. 结合宿主当前的真实状态 (mState),取三者的最小值
return min(min(mState, siblingState), parentState);
}为什么要取这三个状态最小值?
mState(宿主的真实状态): 这是最基础的限制。新来的观察者,其状态绝对不能超过宿主(比如 Activity)当前实际所处的生命周期阶段。
siblingState(前序观察者的状态): mObserverMap 是一个有序集合。previous 代表在当前观察者之前被添加的那个观察者。 Lifecycle 规定:后添加的观察者的状态,不能超过先添加的观察者的状态。这是为了保证事件分发的严格顺序。如果前面的观察者还在 CREATED,后面的观察者就不能擅自跑到 STARTED,必须等前面的"大部队"跟上。
parentState(嵌套分发时的父状态) : 当正在给某个观察者补发历史事件时(比如在 while 循环里从 INITIALIZED 往 CREATED 走),系统会把当前的中间状态压入 mParentStates 栈中。 如果在补发事件的过程中(例如刚发了 ON_CREATE,还没发 ON_START),又突然插入了一个新的观察者,那么这个新观察者的目标状态,必须受限于当前正在处理的这个"中间状态"。它不能越过当前正在处理的事件,直接跳到更后面的状态去。
while循环进入条件是观察者当前的状态落后于宿主的目标状态,当然观察者必须在mObserver容器里,不能被移除了。
while中第一步又是先pushParentState,之前在讲forwardPass时也说过,为了确保有序性,防止后到的事件越过还未处理完。然后获取当前状态下一个要触发的事件。获取不到事件说明观察者状态有误,抛异常处理。
获取事件后就是进行分发处理,处理完成调用popParentState,取消对后续事件的限制。
while循环最末尾又重新calculateTargetState,为什么要重新计算?
- 应对"嵌套添加观察者"带来的状态限制 这是最主要的原因。
Lifecycle 有一个严格的规则:后添加的观察者的状态,不能超过先添加的观察者的状态。假设场景:宿主当前处于 RESUMED 状态。你给观察者 A 补齐事件,当 A 刚分发完 ON_START(此时 A 的状态是 STARTED)时,在 A 的 onStateChanged 回调里,突然又插队添加了新的观察者 B。 如果不重新计算,循环会继续按原计划给 A 分发 ON_RESUME。但根据规则,A 的状态不能越过刚刚新来的 B(B 初始状态通常是 INITIALIZED 或 CREATED)。如果 A 直接跳到了 RESUMED,就打破了顺序规则。
而在分发完 ON_START 后,立刻重新调用 calculateTargetState。此时该方法会检测到后面来了个"弟弟" B,于是返回一个更保守的状态(比如 CREATED)。这样,while 循环的条件 (statefulObserver.mState.compareTo(targetState) < 0) 就会变成 false,A 的爬升过程会被及时暂停,等待后续全局同步 (sync) 来统一推进。
2.配合 pushParentState 实时更新父状态栈
while 循环里有 pushParentState 和 popParentState 的操作。 在分发事件前,系统会把当前的中间状态压入 mParentStates 栈中;分发完后弹出。 calculateTargetState 内部会读取这个栈顶的状态 (parentState) 作为参考依据。因此,每分发完一个事件,栈内的情况就变了,必须重新计算才能拿到基于最新"父状态"约束下的准确目标值。
了解了观察者状态同步的逻辑后,为什么最后要在"最外层"进行全局sync()也就很清楚了。
由于内部状态同步时有嵌套现象(重入),那就在内部先别急着做全局同步,等所有嵌套的最外层方法执行完毕时,统一做一次彻底的同步就够了。因为全局同步比较耗时。
这整个处理流程就解答了为什么在某个生命周期添加观察者后会收到已经错过的生命周期回调,因为添加进来的观察者一般都是从INITIALIZED开始,之后一个个生命周期事件处理,逐步追上LifeCycleRegistry的状态。
所以在OnResume生命周期中注册观察者,最终回调会收到ON_CREATE、ON_START、ON_RESUME;因为从INITIALIZED到RESUMED状态会分发ON_CREATE、ON_START、ON_RESUME事件
如果在OnStop生命周期中注册观察者,此时状态应该是CREATED(回退转移了),最终收到ON_CREATE;因为从INITIALIZED到CREATED状态只要经历ON_CREATE。
3. Activity和Fragment如何提供LifeCycle能力
一般我们的activity继承AppCompatActivity, AppCompatActivity继承FragmentActivity,FragmentActivity继承ComponentActivity,ComponentActivity继承androidx.core.app.ComponentActivity
androidx.core.app.ComponentActivity实现了LifecycleOwner接口,
自身创建一个LifecycleRegistry mLifecycleRegistry = new LifecycleRegistry(this);
这是LifecycleOwner的具体实现,并且提供getLifeCycle进行获取。在OnCreate中调用ReportFragment.injectIfNeededIn(this); 把LifecycleOwner(activity)传入,创建了一个不可见的fragment,通过fragment的生命周期回调,就可以知道activity的生命周期变化,在fragment对应生命周期分发event事件,让activity的lifecycle进行事件处理。
api>=29时,injectIfNeededIn还会为传入的activity注册LifecycleCallbacks,这个callback
同样也能感知生命周期并进行回调。这样子的话一个生命周期会触发两次事件分发,两套机制各种触发一次,但是会在分发的函数内部进行去重。两套机制完成的任务是一样的,之所以有两套是为了兼容性和兜底,并且是双保险。
至于新增LifecycleCallbacks机制,是为了解决Android 29 以下的限制
Activity 限制:不能在生命周期回调中执行 FragmentManager 的立即操作命令;
Fragment 限制:所有 Fragment 都不能在生命周期回调中执行 FragmentManager 的立即操作命令。
注:在ReportFragment中有个ActivityInitializationListener,在onActivityCreated、onStart、onResume这些生命周期会同时回调此listener。
ActivityInitializationListener用于在 Activity 完成"初始化关键阶段"时通知外部监听器,所以只有onActivityCreated、onStart、onResume会进行回调,由于activity没有一个api可告诉已经初始化完成了,并且Fragment一定在Activity之后初始化、Fragment一定在Activity可用之后才可用,所以Fragment是Activity初始化完成的"最佳观察者"。(Fragment调用onResume时,activity必定初始化完成)
ComponentActivity继承androidx.core.app.ComponentActivity,并且也和androidx.core.app.ComponentActivity一样,自身创建一个LifecycleRegistry mLifecycleRegistry = new LifecycleRegistry(this); 并且提供getLifeCycle进行获取,覆盖基类的一个LifecycleRegistry。
目的:规避未来变更与多继承的模拟
androidx.core.app.ComponentActivity目前已处于废弃(deprecated)状态,它仅作为一个极简的兼容壳存在。
新的ComponentActivity自己持有 Registry,相当于在 Java 单继承的限制下,模拟了更纯粹的独立实现。
如果后续彻底移除或大幅修改 core 中的实现,不会直接影响到上层 activity 库的稳定性,做到解耦。
FragmentActivity继承ComponentActivity,并且创建了LifecycleRegistry mFragmentLifecycleRegistry = new LifecycleRegistry(this); 但是没有重写getLifeCycle,所以getLifeCycle获取到的是ComponentActivity的LifecycleRegistry,即FragmentActivity有两个lifeCycleRegistry。
其中从ComponentActivity继承的LifecycleRegistry用于分发activity生命周期事件给activity添加的生命周期观察者;
mFragmentLifecycleRegistry 是给 Fragment 子系统(FragmentManager 等)用的,
充当一个"中间层",让 Fragment 的生命周期观察不直接与 Activity 的 mLifecycleRegistry 耦合。
这样设计可以保持职责清晰,也便于 Fragment 子系统的独立测试和管理。
Fragment本身也实现LifecycleOwner,持有mLifecycleRegistry,这个 mLifecycleRegistry,用于通知观察此fragment生命周期变化的组件。