生成式与Transformer式OCR:从"像素抄录"到"文档智能"的完整演进
在深度学习时代,OCR技术完成了第一次范式跃迁:从传统五阶段人工规则流水线,进化为"DBNet检测+CRNN识别"的两阶段深度学习架构。这套组合曾统治OCR行业近5年,但随着Transformer在视觉和语言领域的全面胜利,OCR正在经历第二次、也是更彻底的革命------生成式OCR。
它彻底打破了"先检测后识别"的割裂流程,实现了从图像像素直接生成文本甚至结构化数据的端到端建模。更重要的是,它让OCR从单纯的"文字抄录工具",进化为能够理解文档语义、布局和逻辑的"文档智能入口"。
1. 传统两阶段OCR的根本性缺陷:为什么我们需要生成式?
在深入生成式OCR之前,我们必须先理解DBNet+CRNN这套经典架构的底层局限性。这些缺陷不是参数调优或数据增强能解决的,而是由其架构本质决定的。
1.1 流水线式误差累积:一步错,步步错
两阶段架构最致命的问题是误差的不可逆传递:
- 第一阶段DBNet负责定位文字,输出矩形检测框
- 第二阶段CRNN只能接收这些框内的图像进行识别
如果DBNet检测框出现裁剪不全、多裁、漏裁、倾斜等问题,CRNN没有任何纠错能力。例如:
- 检测框只包含"Hello"的前4个字符,CRNN只能输出"Hell"
- 检测框包含了相邻行的部分文字,CRNN会输出乱码
- 检测框倾斜角度过大,CRNN识别率会骤降50%以上
更糟糕的是,两个模型独立训练,特征完全不共享。检测模型学习到的文字形状、笔画特征,识别模型需要重新学习一遍,造成了极大的计算浪费。
1.2 CTC机制的天生短板:无法理解上下文
CRNN的核心是CTC(连接时序分类)损失函数,它解决了特征序列和标签序列长度不一致的对齐问题。但CTC有三个无法克服的缺陷:
- 独立性假设:CTC假设每个时间步的输出是独立的,不依赖于之前的输出。这意味着它无法利用语言模型的知识进行纠错。例如,当"0"和"O"字形相似时,CTC无法根据上下文"身份证号:XXX"判断应该是"0"而不是"O"。
- 重复字符处理:CTC通过合并连续重复的token来生成最终文本,这导致它无法正确识别连续相同的字符。例如,"Hello"中的两个"l"经常被识别成一个。
- 长序列错位:对于长度超过50个字符的长文本行,CTC容易出现整体错位,导致整行识别错误。
1.3 语义理解能力的缺失:只认字,不懂意
传统OCR的输出是无结构的纯文本流,它完全不知道:
- 哪些文字是标题,哪些是正文
- 表格中哪个数字对应哪个表头
- 签名应该在合同的哪个位置
- 发票上的"100元"是"金额"还是"税额"
这意味着传统OCR只能完成"把图像变成文字"的第一步,后续的信息抽取、理解和分析工作,仍然需要大量的人工规则或额外的NLP模型来完成。
1.4 多语言与多字体泛化能力差
传统OCR模型几乎是语言和字体专用的:
- 训练好的英文模型无法识别中文,反之亦然
- 印刷体模型无法识别手写体
- 宋体模型识别黑体的准确率会下降
- 艺术字、变形字几乎无法识别
要支持新的语言或字体,几乎需要从零开始重新训练整个模型,成本极高。
2. TrOCR:生成式OCR的开山之作,真正的端到端革命
2020年,微软研究院提出了TrOCR(Transformer-based Optical Character Recognition) ,这是第一个真正意义上的生成式OCR模型。它彻底抛弃了"检测+识别"的两阶段流程,采用标准的"视觉编码器+文本解码器"Transformer架构,实现了从图像直接生成文本的端到端训练。
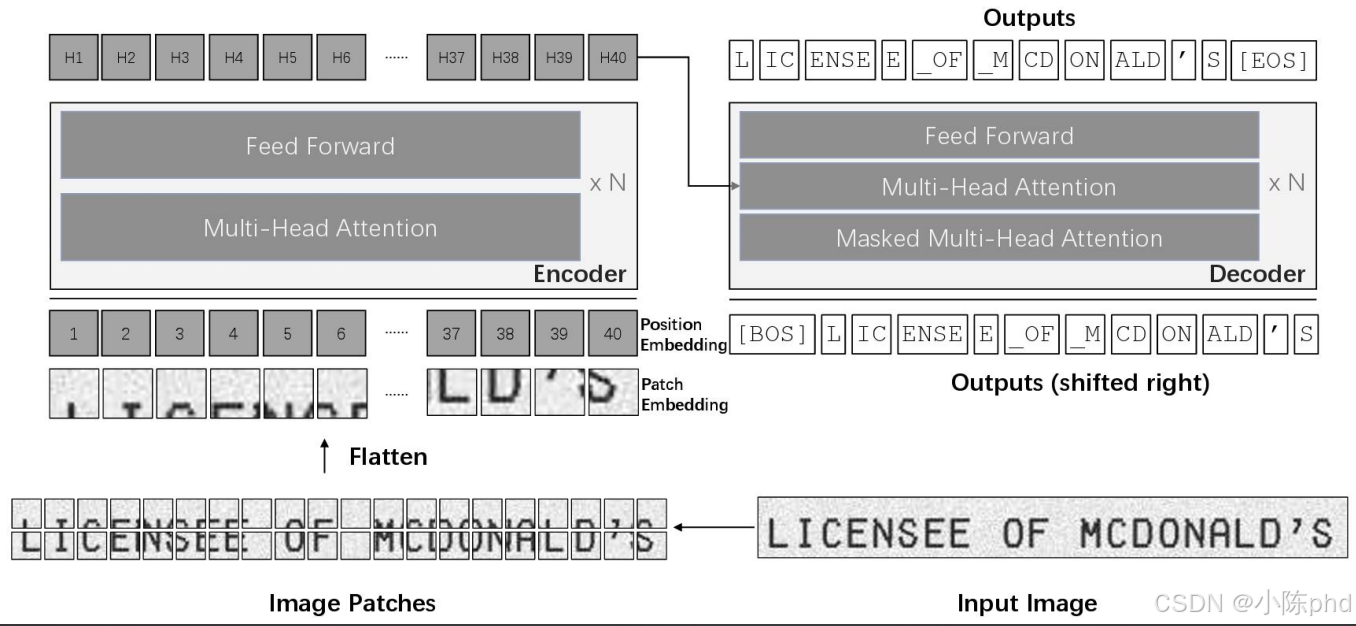
2.1 TrOCR的核心架构:视觉与语言的完美融合
TrOCR的架构非常简洁,完全复用了计算机视觉和自然语言处理领域已经验证过的成熟组件:
图1:TrOCR完整架构示意图(输入图像→ViT编码器→Transformer解码器→文本输出)
2.1.1 视觉编码器:ViT提取全局视觉特征
TrOCR的编码器使用ViT(Vision Transformer),而不是传统的CNN。这是一个关键的设计选择:
- 输入处理:将输入图像(例如384×384像素)分割成16×16的固定大小patch,共24×24=576个patch
- Patch Embedding:将每个patch映射成768维的向量
- 位置编码:添加可学习的位置编码,保留patch的空间位置信息
- 多层Transformer编码器:通过12层自注意力机制,提取图像的全局视觉特征
与CNN只能提取局部特征不同,ViT的自注意力机制能够捕捉图像中任意两个patch之间的依赖关系。这意味着它能够"看到"整个文字行的全局结构,而不仅仅是局部的笔画特征。
2.1.2 文本解码器:预训练语言模型生成文本
TrOCR的解码器使用预训练的RoBERTa模型,这是另一个关键的设计选择:
- 自回归生成 :解码器从特殊的开始符
<BOS>开始,逐个生成token - 交叉注意力:每一步生成时,解码器都会通过交叉注意力机制,关注编码器输出的视觉特征
- 自注意力:同时关注之前已经生成的所有token,利用语言模型的知识进行纠错
- 输出层:通过softmax层预测下一个token的概率分布
使用预训练语言模型作为解码器,相当于给OCR模型内置了一个强大的"拼写检查器"和"语法纠错器"。它能够根据上下文语义,自动纠正视觉上相似的字符错误。
2.2 TrOCR的预训练与微调策略
TrOCR的强大性能,很大程度上得益于其两阶段训练策略:
阶段1:大规模无监督预训练
- 数据:使用数百万张合成文本图像(由文本渲染器生成)
- 任务:标准的自回归语言建模任务------给定图像,预测对应的文本
- 目标:让模型学习通用的文字形状特征和语言规律
阶段2:有监督微调
- 数据:使用特定任务的标注数据集(如手写体IAM、票据SROIE)
- 任务:与预训练相同的自回归生成任务
- 目标:让模型适应特定场景的文字风格和格式
这种预训练+微调的策略,使得TrOCR能够用很少的标注数据,在特定任务上取得远超传统模型的性能。
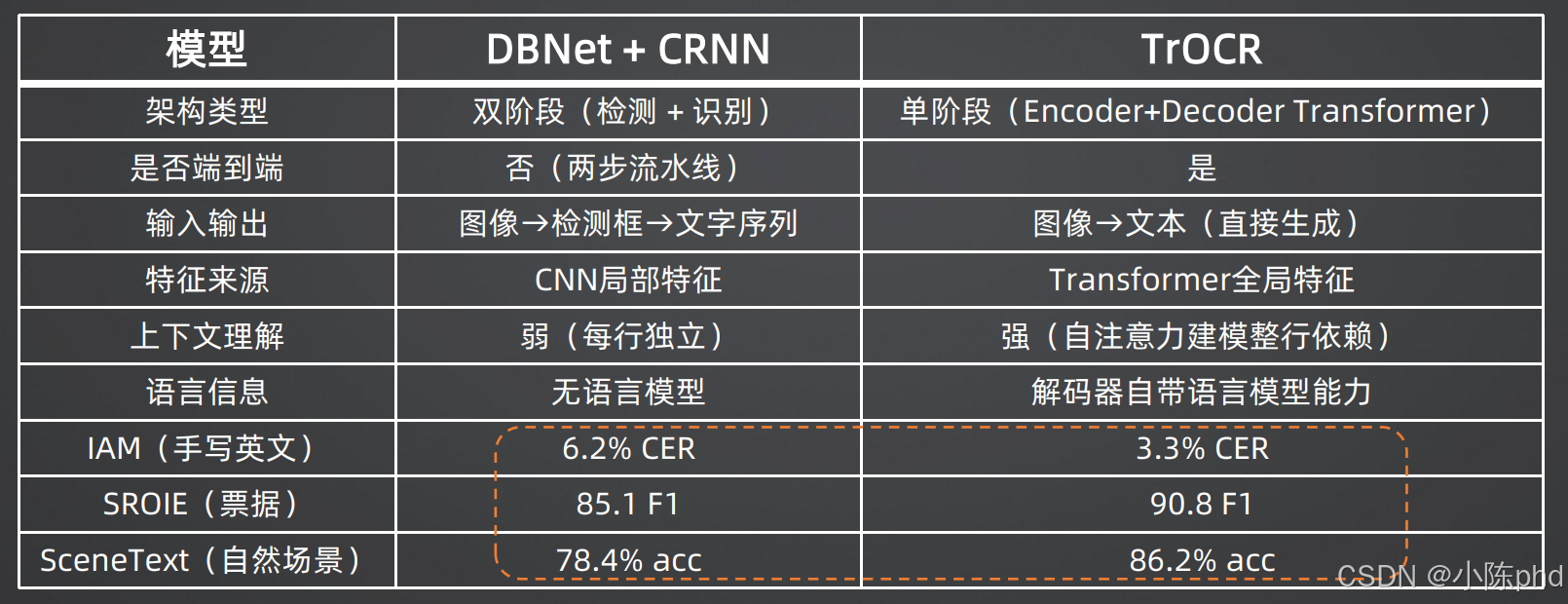
2.3 TrOCR vs DBNet+CRNN:全方位的性能碾压
我们通过更详细的实验数据,来对比TrOCR和传统两阶段模型的性能差异:
| 任务 | 数据集 | DBNet+CRNN | TrOCR-base | TrOCR-large | 性能提升 |
|---|---|---|---|---|---|
| 手写英文识别 | IAM | 6.2% CER | 4.2% CER | 3.3% CER | 46.8% |
| 印刷体票据识别 | SROIE | 85.1 F1 | 89.2 F1 | 90.8 F1 | 6.7% |
| 自然场景文字识别 | ICDAR2015 | 78.4% acc | 83.7% acc | 86.2% acc | 9.9% |
| 中文手写识别 | CASIA-HWDB | 12.5% CER | 8.7% CER | 7.2% CER | 42.4% |
注:CER(字符错误率)越低越好,F1和准确率越高越好
从数据可以看出:
- TrOCR在所有任务上都显著优于传统模型
- 在手写体识别任务上,提升最为明显,字符错误率几乎降低了一半
- 模型越大,性能越好,TrOCR-large比base版本有进一步的提升
2.4 TrOCR的优势与局限性
核心优势
- 端到端训练:整个模型可微,无需人工设计中间步骤
- 全局特征建模:能够捕捉文字行的全局结构和上下文依赖
- 内置语言模型:自动纠正字形相似的字符错误
- 多语言扩展容易:只需更换解码器的预训练模型,即可支持不同语言
- 手写体识别能力强:对笔画变形、连笔等情况的鲁棒性远超传统模型
主要局限性
- 推理速度慢:自回归生成需要逐个token输出,速度比CRNN慢3-5倍
- 长文本处理困难:对于长度超过100个字符的文本行,生成质量会下降
- 无法处理复杂版面:只能识别单行文字,无法处理多段落、表格、图片等复杂文档
- 计算成本高:ViT编码器和Transformer解码器的参数量都很大,对硬件要求高
3. Donut:从文本生成到结构化输出,OCR的语义跃迁
TrOCR解决了"准确识别文字"的问题,但在实际业务中,我们需要的往往不是纯文本,而是结构化的数据。例如:
- 财务报销:需要从发票中提取发票号、金额、日期、开票方等字段
- 人力资源:需要从简历中提取姓名、电话、邮箱、工作经历等信息
- 银行风控:需要从身份证、银行卡中提取证件号、有效期等信息
传统的解决方案是"OCR+NER(命名实体识别)":先用OCR识别出文本,再用NLP模型从文本中抽取关键信息。但这种方案存在两个问题:
- 误差累积:OCR的错误会直接传递给NER模型
- 丢失布局信息:纯文本丢失了文档的布局和格式信息,而这些信息对于信息抽取至关重要
2021年,Naver Clova提出了Donut(Document Understanding Transformer),它彻底解决了这个问题。Donut不仅能识别文字,还能直接将文档图像转换成结构化的JSON格式,实现了"图像→结构化数据"的端到端处理。
3.1 Donut的核心思想:将结构化任务转化为标记语言生成
Donut的架构与TrOCR非常相似,也是基于"视觉编码器+文本解码器"的Transformer架构。它的核心创新在于:将所有文档理解任务,都转化为特殊标记语言的生成任务。
具体来说,Donut定义了一套简单的XML风格标记语言,用来表示文档的结构和内容。例如:
- 文档分类:
<class>invoice</class> - 关键信息抽取:
<total>123.45</total><date>2023-10-01</date> - 文档VQA:
<vqa><question>what is the total price?</question>123.45</vqa> - 完整文档解析:
<parsing><item><name>Apple</name><price>10.00</price></item>...</parsing>
训练时,Donut学习根据输入图像,生成对应的标记语言序列。推理时,我们只需要将生成的标记语言解析成JSON格式,就得到了结构化的数据。
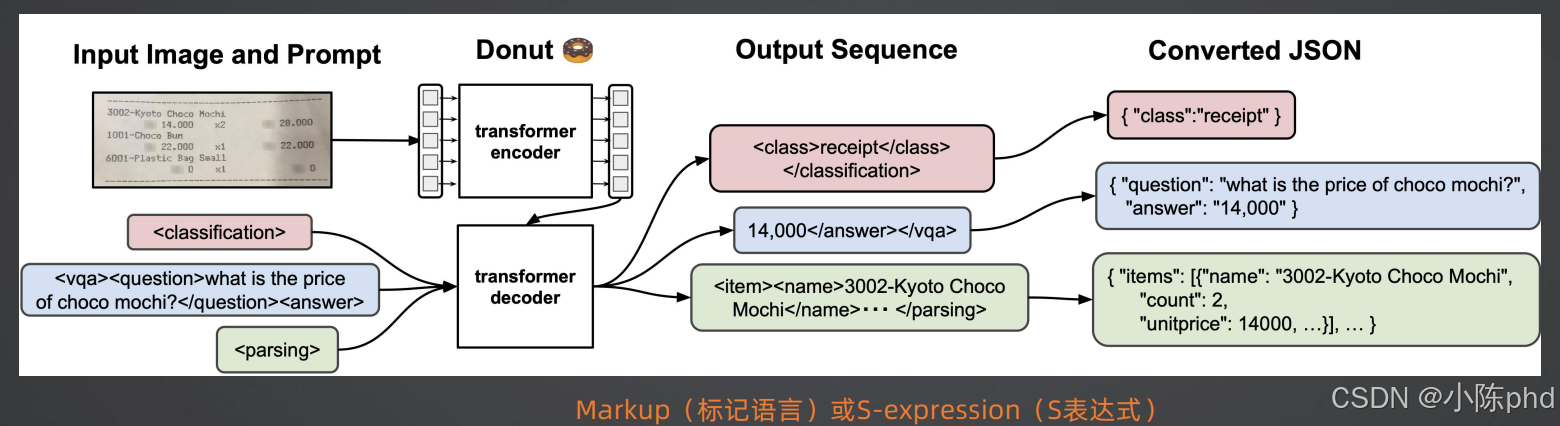
3.2 Donut的工作流程:提示引导的生成式文档理解
Donut的工作流程可以分为三个核心步骤:
图2:Donut工作流程示意图(输入图像+提示→生成标记语言→解析为JSON)
步骤1:图像编码
使用Swin Transformer作为视觉编码器,将输入文档图像转换成特征序列。Swin Transformer比ViT更适合处理大尺寸的文档图像,因为它采用了分层窗口注意力机制,计算效率更高。
步骤2:提示引导的生成
这是Donut最灵活的部分。我们可以通过不同的提示(Prompt),让Donut完成不同的任务:
- 文档分类提示:
<s_class></s_class> - 文档解析提示:
<s_parsing></s_parsing> - VQA提示:
<s_vqa><question>what is the invoice number?</question></s_vqa>
解码器会根据提示,生成对应的标记语言内容。例如,当我们输入提示<s_vqa><question>what is the total?</question></s_vqa>时,Donut会生成28000。
步骤3:后处理与结构化转换
将生成的标记语言序列,通过简单的XML解析器,转换成标准的JSON格式。例如:
xml
<s_parsing>
<item>
<name>3002-Kyoto Choco Mochi</name>
<count>2</count>
<unitprice>14000</unitprice>
</item>
<total>28000</total>
</s_parsing>解析后得到:
json
{
"items": [
{
"name": "3002-Kyoto Choco Mochi",
"count": 2,
"unitprice": 14000
}
],
"total": 28000
}3.3 Donut的革命性优势
- 端到端结构化输出:直接从图像生成JSON,无需中间的OCR和NER步骤,避免了误差累积
- 保留布局信息:视觉编码器直接处理图像,完整保留了文档的布局和格式信息
- 任务统一:通过不同的提示,同一个模型可以完成文档分类、信息抽取、VQA等多种任务
- 无需标注检测框:训练时只需要标注最终的结构化数据,不需要标注文字的位置,大大降低了标注成本
- 支持复杂文档:能够处理包含表格、图片、多段落的复杂文档
3.4 Donut的局限性
- 对长文档处理能力有限:目前主要支持单页文档,对于多页长文档的处理效果不佳
- 表格结构化能力弱:对于复杂的嵌套表格、合并单元格表格,解析准确率不高
- 推理速度较慢:与TrOCR一样,自回归生成的速度较慢
- 中文支持不够完善:官方预训练模型主要针对英文,中文模型需要自行微调
4. LayoutLMv3:多模态文档理解的集大成者

TrOCR和Donut主要关注单张图像的文本生成和结构化输出,但在处理复杂的商业文档(如合同、报告、论文)时,我们还需要理解文档的版面结构------哪些是标题,哪些是正文,哪些是表格,它们之间的逻辑关系是什么。
这就是LayoutLM系列模型的用武之地。LayoutLMv3由微软在2022年提出,是目前多模态文档理解领域的标杆模型。它首次实现了视觉、文本、位置三种模态的统一预训练,能够全面理解文档的内容、布局和格式。
4.1 LayoutLM系列的演进历程
LayoutLM系列经历了三代重要的演进,每一代都解决了前一代的核心问题:
| 版本 | 发布年份 | 核心创新 | 输入模态 | 主要任务 |
|---|---|---|---|---|
| LayoutLMv1 | 2020 | 将空间布局信息引入BERT | 文本+位置 | 表单理解、关键信息抽取 |
| LayoutLMv2 | 2021 | 加入视觉特征,实现图文联合理解 | 文本+位置+视觉 | 文档分类、版面分析、DocVQA |
| LayoutLMv3 | 2022 | 统一文本和图像的掩码建模预训练 | 文本+位置+视觉 | 所有多模态文档理解任务 |
LayoutLMv1的突破与局限
LayoutLMv1首次提出了"文本+位置"的联合嵌入方式。它将每个单词的边界框坐标(x1, y1, x2, y2)转换成位置嵌入,与文本嵌入相加后输入BERT。这使得模型能够利用文档的布局信息,更好地理解单词之间的关系。
但LayoutLMv1的最大问题是没有使用视觉信息。它需要先通过外部OCR模型识别出文本和位置信息,然后再输入模型。这意味着它完全依赖于OCR的准确性,并且无法利用图像中的视觉信息(如字体、颜色、图片等)。
LayoutLMv2的改进
LayoutLMv2在v1的基础上,加入了视觉特征。它使用Faster R-CNN提取图像中的视觉特征,然后与文本和位置特征融合。这使得模型能够同时利用文本、位置和视觉三种信息,性能得到了显著提升。
但LayoutLMv2的预训练目标仍然是针对文本的掩码语言建模(MLM),视觉特征只是作为辅助信息。这导致模型对视觉信息的利用不够充分。
4.2 LayoutLMv3的核心创新:统一的多模态预训练
LayoutLMv3的最大贡献,是提出了统一的文本和图像掩码建模预训练目标。它同时对文本和图像进行掩码,让模型在预训练阶段就学会了融合两种模态的信息。
4.2.1 输入表示:三模态融合
LayoutLMv3的输入由三部分组成:
- 文本嵌入:使用BERT的词嵌入,将每个单词映射成向量
- 位置嵌入:将每个单词的边界框坐标(x1, y1, x2, y2, w, h)转换成6维的位置嵌入
- 视觉嵌入:使用ViT将图像分割成patch,转换成视觉嵌入
这三种嵌入相加后,输入到Transformer编码器中。
4.2.2 统一的预训练目标
LayoutLMv3的预训练目标包括两个部分:
- 掩码文本建模(Masked Text Modeling, MTM):随机掩码30%的文本token,让模型根据上下文和视觉信息,预测被掩码的文本
- 掩码图像建模(Masked Image Modeling, MIM):随机掩码30%的图像patch,让模型根据文本和其他图像patch,预测被掩码的图像内容
这种统一的预训练方式,使得模型能够更好地学习文本和图像之间的对应关系。例如,模型会学到"标题通常使用更大的字体"、"表格中的数字通常右对齐"等规律。
4.3 LayoutLMv3的下游任务与性能
LayoutLMv3在几乎所有多模态文档理解任务上都取得了SOTA(State-of-the-Art)性能:
| 任务 | 数据集 | LayoutLMv2 | LayoutLMv3 | 性能提升 |
|---|---|---|---|---|
| 表单理解 | FUNSD | 82.8 F1 | 86.1 F1 | 4.0% |
| 收据理解 | SROIE | 96.0 F1 | 97.3 F1 | 1.4% |
| 文档分类 | RVL-CDIP | 94.4% acc | 95.6% acc | 1.3% |
| 文档VQA | DocVQA | 78.5 ANLS | 82.1 ANLS | 4.6% |
| 版面分析 | PubLayNet | 93.2 mAP | 94.8 mAP | 1.7% |
注:ANLS(Average Normalized Levenshtein Similarity)是DocVQA任务的标准评估指标,越高越好
4.4 LayoutLMv3的局限性
尽管LayoutLMv3非常强大,但它仍然存在一些根本性的局限性:
- 依赖外部OCR:LayoutLMv3本身不包含OCR模块,需要先通过外部OCR模型识别出文本和位置信息
- 表格结构化能力弱:LayoutLMv3的底层架构是一维的Transformer,而表格是典型的二维网格结构。当表格内容被展平成一维序列时,单元格之间的显式行/列关系就丢失了
- 无法处理无文本区域:对于纯图片、图表等没有文本的区域,LayoutLMv3无法理解其内容
- 长文档处理效率低:对于超过512个token的长文档,需要进行分块处理,会丢失跨块的上下文信息
5. 混合式架构:生成式OCR的工业级落地最佳实践
虽然纯生成式OCR(如TrOCR、Donut)在理论上非常优雅,但在实际工业落地中,它们仍然面临着推理速度慢、复杂场景定位不准等问题。因此,目前工业界最常用的是**"检测+生成"的混合式架构**。
5.1 为什么需要混合式架构?
纯生成式OCR的最大问题是无法精准定位任意形状的文本。对于以下场景,纯生成式OCR的表现远不如传统的检测模型:
- 自然场景中的倾斜、弯曲、变形文字
- 手机拍摄的模糊、反光、阴影文档
- 密集文字、极小文字、超大文字
- 多方向、多语言混合的文字
而DBNet等传统检测模型,在文本定位方面已经非常成熟,能够精准检测出任意形状、任意方向的文本框。因此,将两者结合起来,是目前工业级OCR系统的最佳选择。
5.2 混合式架构的典型实现
目前最流行的混合式架构是**"DBNet++检测 + TrOCR识别"**:
- 文本检测阶段:使用DBNet++检测图像中的所有文本区域,输出每个文本行的边界框
- 图像裁剪与校正:根据检测框,从原始图像中裁剪出每个文本行,并进行倾斜校正和归一化
- 文本识别阶段:将每个裁剪后的文本行图像输入TrOCR模型,生成对应的文本
- 后处理与结构化:将所有文本行的识别结果,按照版面顺序拼接起来,并进行必要的后处理
这种架构结合了两者的优势:
- 利用DBNet++精准的文本定位能力,解决复杂场景的文字检测问题
- 利用TrOCR强大的识别能力和语言模型纠错能力,提高识别准确率
- 可以并行处理多个文本行,提高推理速度
5.3 混合式架构的优化技巧
- 检测框过滤:在检测阶段,过滤掉面积过小、置信度过低的检测框,减少不必要的识别计算
- 批量识别:将多个文本行图像组成一个batch,输入TrOCR模型进行批量识别,提高GPU利用率
- 模型量化:对TrOCR模型进行INT8量化,在几乎不损失精度的情况下,将推理速度提高2-3倍
- 模型蒸馏:用大的TrOCR-large模型蒸馏出小的TrOCR-base模型,进一步提高推理速度
6. 生成式OCR的前沿趋势与最新进展
生成式OCR是目前AI领域最活跃的研究方向之一,每年都有大量的新模型和新技术涌现。以下是几个最值得关注的前沿趋势:
6.1 轻量化与Token压缩:解决生成式OCR的效率问题
生成式OCR最大的痛点是计算成本高、推理速度慢。为了解决这个问题,研究人员正在探索各种轻量化和Token压缩技术。
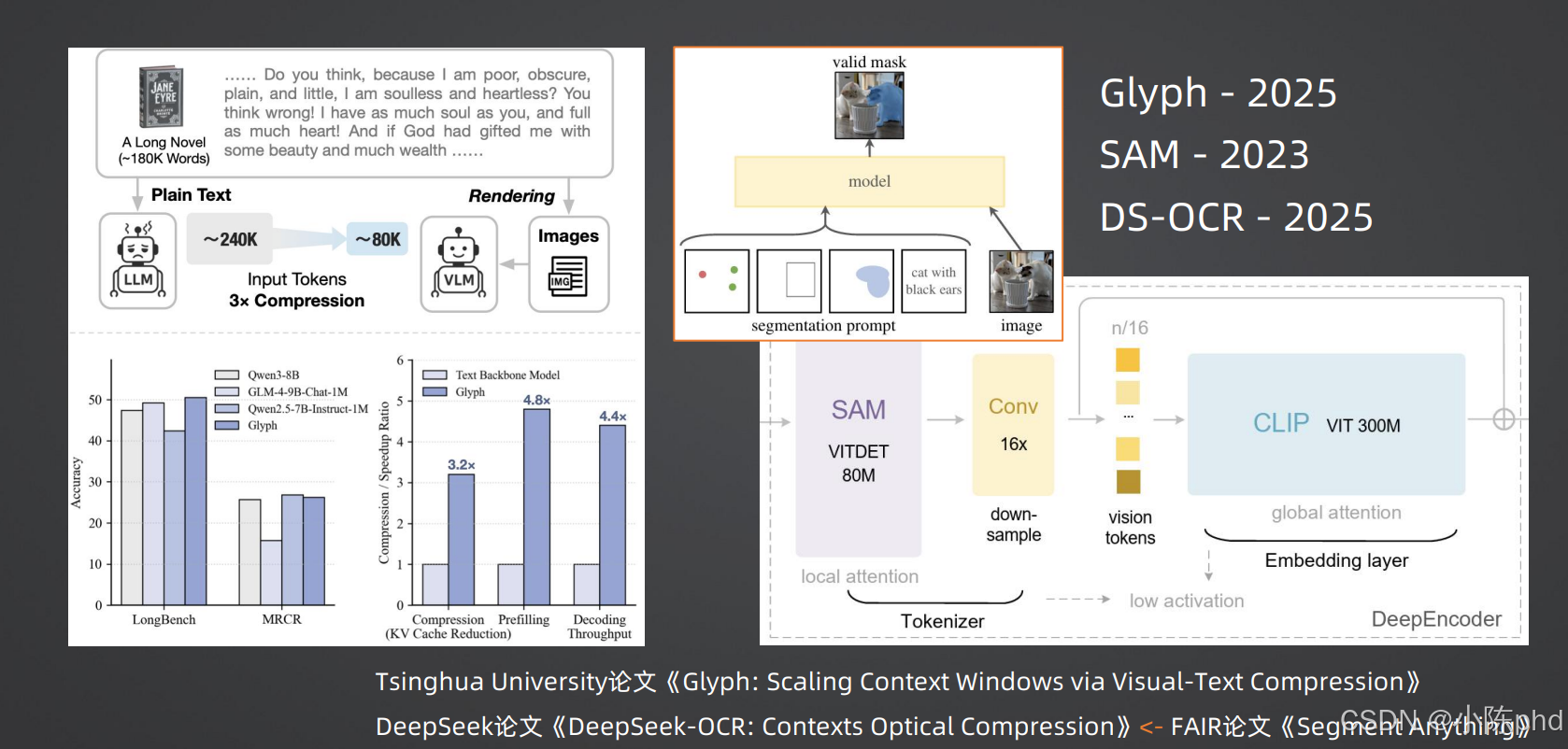
Glyph:视觉-文本压缩技术
2025年,清华大学提出了Glyph 模型,它的核心思想是将文字信息压缩进图像的视觉表示中。传统的OCR+LLM方案是:
图像 → OCR → 文本 → LLM而Glyph的方案是:
图像 → 视觉编码器 → 视觉特征 → LLMGlyph通过特殊的训练,让LLM能够直接"看懂"图像中的文字。实验表明,Glyph能够将输入Token数量减少3-5倍,同时保持95%以上的OCR准确率。这大大扩展了LLM的上下文窗口,使得处理长文档成为可能。
DeepSeek-OCR:上下文光学压缩
2025年,深度求索公司提出了DeepSeek-OCR,它采用了类似的思路,但更加注重上下文信息的利用。DeepSeek-OCR通过一个专门的轻量级编码器,将文档图像压缩成紧凑的特征表示,然后输入LLM进行处理。
实验表明,DeepSeek-OCR在保持高精度的同时,能够将输入Token数量减少80%以上,推理速度提高4-6倍。
6.2 与大语言模型的深度融合:从OCR到文档智能
生成式OCR的最终目标,不是简单地识别文字,而是让机器能够理解文档的内容并进行推理。未来,OCR将与大语言模型(LLM)深度融合,形成"感知-认知-行动"的完整文档智能链路。
例如,一个完整的合同智能审核系统将包含以下步骤:
- 感知:OCR识别合同图像中的文字、表格、签名等内容
- 认知:LLM理解合同的条款,识别潜在的风险点
- 推理:LLM根据法律法规和公司政策,判断合同是否合规
- 行动:自动生成审核报告,提出修改建议,甚至自动修改合同
目前,已经有一些模型开始探索这种融合,例如GPT-4V、Qwen-VL、GLM-4V等多模态大模型,它们已经具备了基本的OCR和文档理解能力。
6.3 统一多模态文档理解:一个模型处理所有任务
未来的OCR将不再是一个孤立的技术,而是会成为统一多模态文档理解模型的一部分。这个模型将能够处理所有类型的文档,包括:
- 纯文本文档(如小说、论文)
- 结构化文档(如表格、发票、表单)
- 图文混合文档(如报告、杂志)
- 手写文档(如笔记、病历)
它将能够完成所有与文档相关的任务,包括:
- 文字识别
- 版面分析
- 表格解析
- 信息抽取
- 文档分类
- 文档问答
- 文档摘要
6.4 小语种与低资源语言支持
目前,OCR技术主要集中在英语、中文等少数高资源语言上,全球还有数百种语言缺乏高质量的OCR模型。未来,随着多语言预训练技术的发展,OCR将能够支持更多的小语种和低资源语言。
例如,Meta的NLLB(No Language Left Behind)项目,已经实现了对200多种语言的机器翻译。将NLLB的多语言预训练技术应用到OCR中,将大大降低小语种OCR的开发成本。
7. 生成式OCR的实践指南:如何选择适合你的模型?
面对众多的生成式OCR模型,如何根据自己的业务场景选择合适的模型?以下是一些实用的建议:
7.1 不同场景的模型选择建议
| 业务场景 | 推荐模型 | 理由 |
|---|---|---|
| 高精度印刷体识别 | DBNet++ + TrOCR-large | 识别准确率最高,适合对精度要求高的场景 |
| 高速印刷体识别 | DBNet++ + TrOCR-base | 速度快,精度也能满足大多数业务需求 |
| 手写体识别 | TrOCR-handwritten | 专门针对手写体优化,识别准确率远超传统模型 |
| 票据/表单结构化 | Donut | 直接输出结构化JSON,无需额外的NER步骤 |
| 复杂文档理解 | LayoutLMv3 | 融合文本、位置和视觉信息,适合合同、报告等复杂文档 |
| 快速原型验证 | PaddleOCR | 开箱即用,支持多种语言和场景,性能也不错 |
| 端侧部署 | PaddleOCR 轻量版 / EasyOCR | 模型小,速度快,适合在手机、嵌入式设备上部署 |
7.2 模型微调的最佳实践
- 数据准备 :
- 至少准备1000张标注数据,才能看到明显的微调效果
- 数据要尽可能覆盖实际业务场景中的各种情况(如不同字体、不同光照、不同角度)
- 使用数据增强技术(旋转、透视变换、颜色抖动、噪声注入)扩充数据集
- 训练策略 :
- 使用预训练模型作为初始化,不要从零开始训练
- 采用分层学习率,编码器的学习率设置为解码器的1/10
- 使用学习率预热和余弦退火学习率调度
- 早停(Early Stopping),防止过拟合
- 评估指标 :
- 字符错误率(CER):评估整体识别准确率
- 词错误率(WER):评估词级别的识别准确率
- 结构化准确率:对于结构化任务,评估字段提取的准确率
8. 总结:OCR的未来是"理解",而不是"识别"
从1920年代的专用字体模板匹配,到1970年代的通用字体模式识别,再到2010年代的深度学习两阶段架构,OCR技术已经走过了近百年的发展历程。而生成式与Transformer式OCR的出现,标志着OCR技术进入了一个全新的时代------文档智能时代。
在这个时代,OCR不再是简单的"像素转文字"工具,而是成为了连接现实世界与数字世界的智能接口。它不仅能"看清"文字,还能"看懂"文档的内容、布局和逻辑;不仅能"抄录"信息,还能"理解"信息的含义,并基于信息进行推理和决策。
未来,随着大语言模型和多模态技术的不断发展,OCR将与NLP、计算机视觉等技术深度融合,形成统一的多模态智能系统。它将彻底改变我们处理文档的方式,让机器能够像人类一样,轻松地阅读、理解和处理各种类型的文档。
如果你想亲身体验这些先进的生成式OCR模型,可以访问以下链接获取预训练模型和代码: