第五章:机器之眼------卷积神经网络与图像的秘密
!info
在第四章中,我们见证了 2012 年深度学习的爆炸时刻:Hinton、Krizhevsky 和 Sutskever 的三人团队用 AlexNet 在 ImageNet 竞赛上以 11 个百分点的巨大优势击溃了所有对手。我们用"三块拼图"(数据 × 算力 × 算法)解释了为什么革命偏偏在那一刻发生。但有一个问题被快速带过了:他们所使用的卷积神经网络里的"卷积",到底是一种怎样的操作?为什么偏偏是它,而不是别的什么架构,在图像识别上如此有效?
这不是偶然,其背后有一个关于图像数据本质结构的深刻洞察------而这个洞察,早在 1989 年 LeCun 还在 Bell 实验室处理邮政编码的时候就已经清晰了。那时候,他还没有 ImageNet,没有 GPU,没有 AlexNet,甚至没有多少同行相信他的方向。但他知道,关于图像,有两件事是真的------而这两件事,改变了一切。
!question
如果一个算法天生就"理解"图像的结构------知道相邻像素之间高度相关、同样的形状无论出现在画面的哪个位置都应该被同样地识别------它会比什么都不知道的通用算法强多少?卷积神经网络用一个简洁的设计回答了这个问题,也揭示了整个深度学习视觉革命最核心的秘密:在正确的地方做出正确的假设,这能产生多大的价值?
5.1、邮局里的深度学习
5.1.1 Bell 实验室的银行家需求
1987 年,美国邮政服务(USPS)正面临着一个棘手的实际工程问题。
在那个时期,每天有数亿封信件在全美流转。每封信的邮编需要被正确读取,才能路由到正确的分拣站。当时,这些邮编是靠人工来读取的------一批分拣工坐在传送带旁边,看信封,读邮编,按键输入。可想而知,这套系统不仅速度慢、成本高,而且出错率相当高。
当时的手写数字识别,是一个让所有工程团队头疼的问题。问题的核心不是"机器看不见数字"------扫描技术已经够好了,而是人类的书写风格复杂多变。邮编上的 "1",可以是一根竖线,可以是带顶划的欧式写法,可以是潦草到几乎平躺的一笔。"7" 在美国人和欧洲移民手里的写法完全不同------欧式 "7" 通常在中间加一横。一个 "4" 写得太马虎了,机器会把它认成" 9";一个 "5" 笔画连起来,又像极了 "6"。手写,从本质上就是把同样的"意义"(例如数字 2)映射到千变万化的"形状"上。当时最好的规则系统------精心手写的模板匹配程序------在理想条件下错误率超过 5%,在真实邮件上超过 10%。
而美国银行也有类似的问题。支票上的金额都是手写的,必须由人工核对。他们每年处理数十亿张支票,因此哪怕 1% 的错误率也将面临巨额的纠纷成本。
后来,AT&T Bell 实验室接了这个项目:想办法用机器自动读取手写数字?
负责这个项目的人,就是 Yann LeCun ,他刚刚完成了他在多伦多大学 Hinton 实验室的博士后研究,正在探索一种专门为图像设计的神经网络架构,因为 LeCun 知道这里存在的一个关键问题:如果将普通的全连接网络用在图像上,这将是一场灾难。
5.1.2 朴素的全连接网络
让我们先暂时抛开历史,用一组简单的数字计算来感受全连接网络处理图像的代价。
1989 年,LeCun 处理的手写数字图像是 32×3232×3232×32 像素、单通道(灰度图)。输入大小是 32×32=102432 × 32 = 102432×32=1024 个数值。如果第一个隐藏层有 1000 个神经元,那么仅这一层的参数数量就是 1024×1000=1021024 × 1000 = 1021024×1000=102 万个。这已经很多了。但如果以 ImageNet 为例,AlexNet 处理的 224×224224×224224×224 的彩色图像,情况会更糟糕:224×224×3=150528224 × 224 × 3 = 150528224×224×3=150528 个输入,第一个全连接层(1000 个神经元)需要的参数数量:150528×1000=1.5150528 × 1000 = 1.5150528×1000=1.5 亿个参数。仅仅一个全连接层,就有 1.5 亿个参数。
而整个 AlexNet 的卷积部分却只有约 2000 万参数------全连接层把参数数量放大了 7 倍以上。
这不只是"参数太多"的问题。参数多意味着:
-
内存需求爆炸:2012 年的 GPU,显存只有 3-6 GB。1.5 亿参数的仅一个全连接层,本身就要占用约 600MB(每个参数 4 字节)。而整个网络可能有多个全连接层,加上需要存储梯度和优化器状态(通常是参数量的 2-3 倍),根本塞不进 GPU 显存中。
-
过拟合几乎无法避免:1.5 亿个参数,需要远超这个数量的训练样本才能学到泛化的表示。ImageNet 有 120 万训练图片------每个参数平均只有 0.8 个训练样本。这样的比例下,网络倾向于死记硬背训练集,而不是学到真正的规律。实际上,过拟合不仅仅是模型性能下降,而是根本上无法泛化到新数据------训练集准确率接近 100%,测试集准确率只有 20-30%。
-
计算量是天文数字:1.5 亿次乘加运算,仅仅是第一层的前向传播。乘上反向传播(大约是前向传播的 3 倍),再乘上训练的 epoch 数(通常 50-100 个),再乘上 batch 中的样本数,整个训练过程的 FLOP 数会让 1990 年代的任何计算设备直接瘫痪。
所以这套方案,其背后实际上是一个根本性的设计错误:
全连接网络的假设是,图像中的每个像素,都和所有其他像素有直接的联系。
这个假设是荒谬的。而且随着所处理图片的分辨率变大,荒谬得越来越离谱------其计算代价是呈平方级增长的。
5.1.3 平移不变性的缺失
平移不变性是一个直觉上显而易见,但在技术上需要显式设计的特性。
例如,想象你正在训练一个全连接网络,教网络识别猫。在训练阶段,你给它看过一万张猫的图片,所有的猫都大致在画面中央。网络学会了认识猫这种生物------更确切地说,学会了"图像中央位置的猫样特征"。
现在,我们给它一张猫出现在画面左侧的图片。
网络会把这张图认成什么呢?大概率不是猫,或者即使识别为猫,其置信度可能也较低。
为什么?因为全连接网络的每个权重,都对应输入的某个特定位置 。图像中央的像素连接到某些权重,图像左侧的像素连接到完全不同的另一批权重。这两批权重学到的东西,完全不共享。从网络的视角看,猫在中央和猫在左侧,是两种完全不同的输入,需要分别学习。
因此要让全连接网络泛化到猫在不同位置的情况,最直接的办法就是在训练数据中包含猫在各种位置的图片------数千张、数万张。但这大幅增加了数据收集和标注的成本,而且永远无法覆盖所有可能的位置、尺度、旋转组合。
而人类的视觉系统会立刻说:那就是只猫,不管它出现在什么位置。
这种"不管物体在哪里,都能认出它"的能力,叫做平移不变性(Translation Invariance)。它是人类和大多数动物视觉的基本特性,但在全连接网络里,需要用大量数据来强行学习------效率极低。
因此 LeCun 意识到,要解决这个问题,需要一种从结构上就"知道图像是什么"的网络。
5.2、卷积计算与视觉的秘密
5.2.1 卷积计算
"卷积"(Convolution)这个词,在数学和信号处理领域有着悠久的历史,远比神经网络的历史还要古老。在信号处理里,卷积是用来描述一个信号如何通过一个系统发生变换的运算。比如:声音经过一个房间的混响、图像经过一个镜头的模糊、不同频段的无线电信号干涉。这些变换,都可以用卷积来描述。
数学中的卷积是一种对两个函数进行"叠加"运算的数学工具,例如,对于两个离散序列 fnfnfn 和 gngngn(定义在整数域上),卷积公式为: (f∗g)n=∑k=−∞∞fk⋅gn−k (f * g)n = \sum_{k=-\infty}^{\infty} fk \cdot gn - k (f∗g)n=k=−∞∑∞fk⋅gn−k其含义是将序列 ggg 反转(变为 g−kg-kg−k)、平移 nnn(变为 gn−kgn-kgn−k),再与 fkfkfk 逐点相乘后求和,得到第 nnn 个位置的卷积结果。
这个公式看起来令人生畏,但实际上我们从中学阶段就一直在应用这个公式,例如多项式相乘本质上就是离散卷积。
接下来我们以 f(x)=3x3+x+5f(x) = 3x^3 + x + 5f(x)=3x3+x+5 和 g(x)=4x2+x+6g(x) = 4x^2 + x + 6g(x)=4x2+x+6 来演示卷积计算多项式乘法。按照规则,我们从最低项到最高项(x0,x1,x2,⋯ x\^0, x\^1, x\^2,\\cdotsx0,x1,x2,⋯)提取各自的系数分为为 5,1,0,35,1,0,35,1,0,3 和 6,1,46,1,46,1,4,其中 f(x)f(x)f(x) 中的 x2x^2x2 项缺失,可认为系数为 0。具体卷积计算过程如下:
5 1 0 3 第一步:f(x) 系数按顺序放置
4 1 6 g(x) 系数顺序先翻转,并挪位,尾项与 f(x) 首项对其,重叠部分相乘求和,5x6=30
----------------------
5 1 0 3 第二步:f(x) 不动
4 1 6 g(x) 滑动一位,重新计算重叠部分 5x1+1x6=11
----------------------
5 1 0 3 第三步:f(x) 不动
4 1 6 g(x) 滑动一位,重新计算重叠部分 5x4+1x1+0x6=21
----------------------
5 1 0 3 第四步:f(x) 不动
4 1 6 g(x) 滑动一位,重新计算重叠部分 1x4+0x1+3x6=22
----------------------
5 1 0 3 第五步:f(x) 不动
4 1 6 g(x) 滑动一位,重新计算重叠部分 0x4+3x1=3
----------------------
5 1 0 3 第六步:f(x) 不动
4 1 6 g(x) 滑动一位,重新计算重叠部分 3x4=12,此时如果再滑,将无重叠,计算结束
----------------------至此我们已经计算出两个多项式相乘后,各项(按 x0,x1,x2,⋯ x\^0, x\^1, x\^2,\\cdotsx0,x1,x2,⋯ 顺序)的系数大小为 30,11,21,22,3,1230,11,21,22,3,1230,11,21,22,3,12,读者不妨自己校验一下结果。
因此在离散的图像处理中,卷积计算演变成了一个非常直观的操作:用一个小矩阵(卷积核/滤波器)在图像上滑动,并在每个位置计算一个加权和。
例如,假设我们有一个 5×55×55×5 的图像,想利用一个 3×33×33×3 的卷积核处理它。我们会把 3×33×33×3 的核放在左上角,把对应的 9 个像素值和核的 9 个权重一一相乘,然后加起来,得到一个单一的输出值。然后向右滑动一步(这叫步长 或 stride),重复计算。再向右滑,直到到达右边界。然后回到左边,向下滑一行,从左到右再扫一遍。这个过程就像拿着一个小窗户在图像上滑动,每个位置都计算一次加权和。
这个操作在图像处理领域很早就有人在使用了------Sobel 边缘检测滤波器(1968 年)、Gaussian 模糊滤波器(如图片处理软件中模糊操作背后的原理)都是卷积操作的具体实例。图像处理工程师早已知道,不同的卷积核可以用来检测边缘、提取纹理、去除噪声等。每一个特定的核都是人工精心设计的,基于对图像处理的数学理解。
LeCun 的创新,是把这个古老的操作和神经网络的学习能力结合起来------让网络自己学习卷积核的权重,而不是要人工设计这些卷积核。这看起来很简单,但它的威力在于:网络可以自动发现哪些卷积核对于特定任务(比如识别猫)是有用的。用人工设计来讲,一个图像处理工程师可能花十年才能积累的卷积核知识库,一个神经网络用几周的训练就能自动学出来。
这个想法,在脑科学里也有回响。
5.2.2 视神经科学的意外发现
1958 年秋天,约翰斯·霍普金斯大学的实验室里,大卫·休伯尔 (David Hubel,1926-2013,加拿大裔美国神经生理学家)和托斯坦·维厄瑟尔(Torsten Wiesel,1924-,瑞典神经生理学家)正在做一件让他们深感沮丧的事情:他们把极细的电极插入了一只麻醉猫的大脑初级视觉皮层(V1 区),然后对着猫的眼睛打光点,试图找到能让神经元发射的刺激。
结果什么都没有。
光点打在视野的这里,神经元沉默。打在那里,还是沉默。他们用遮光板在幻灯片上打了个洞,投影出一个亮点------沉默。换了位置,还是沉默。一整个下午,那根电极的扬声器里几乎只有背景噪声的嗡嗡声。
然而,一个意外在此刻发生了。
当他们在往投影仪里插入一张新的玻璃幻灯片时,幻灯片的边缘在投影屏上划过了一条移动的阴影线------那是幻灯片边框的影子,在屏幕上从上方缓慢扫过。
这时的扬声器里突然爆发出密集的发射音:哒哒哒哒哒哒......
电极旁边的那个神经元被激活了。
Hubel 和 Wiesel 对视了一眼。他们用了几秒钟意识到发生了什么:那里的神经元对圆点并不敏感,但它对移动的边缘线是敏感的。更有意思的是,这个神经元对特定方向的边缘特别敏感。
接下来的几年,他们用一块可以旋转的遮光片系统性地进行测试:这个神经元只对某个特定角度的边缘有强响应------比如 45° 的对角线。换成 90° 的竖线,响应减弱。换成水平线,几乎没有响应。再换一个神经元,它的偏好可能是竖线;再换一个,它对 30° 的斜线特别敏感。
视觉皮层的神经元,是方向选择性的------每个神经元都有它偏好的"方向",像一个挑剔的评委。
他们随后进一步研究发现,这些神经元大致可以分为两类:
- 简单细胞(Simple Cells):只对特定位置、特定方向的边缘有响应。边缘在哪里,细胞就必须在对应的位置被激活。
- 复杂细胞(Complex Cells):对特定方向的边缘有响应,但不关心边缘在视野的哪个位置------边缘在任何地方出现,都会触发响应。
复杂细胞的这个特性,被 Hubel 和 Wiesel 解释为:它是由多个简单细胞"汇聚"而成的,汇聚了不同位置上相同方向的边缘信号。这是一种内置的位置不变性。
更重要的发现是层次性:V1 区负责检测边缘和方向;信号传入 V2 区,处理更复杂的轮廓和纹理;进入 V4 区,处理颜色和形状;最终到达下颞叶皮层,这里的神经元已经在处理具体的物体------面孔、手、工具。
整个视觉系统就是这样一条从低级特征到高级语义的处理流水线。低级就是边缘和方向,中级是形状和纹理,高级是物体类别。每一层都聚合下一层的信息,形成更抽象的表示。
Hubel 和 Wiesel 凭这项工作获得了 1981 年诺贝尔生理学或医学奖。但在当时,这项工作的计算意义被远远低估了。这种"从基础特征到高级特征的层次化处理",给了 LeCun 和他同时代的研究者重要的启发:人工神经网络也应该被这样组织------用局部的、层次化的特征提取来处理图像。
但这不是刻意的模仿,而是两套系统在解决同一个问题时自然收敛到了相似的结构。值得注意的是,LeCun 在 1989 年设计 LeNet 时,更多参考的是信号处理里的卷积操作,而不是 Hubel-Wiesel 的神经科学------神经科学给的是直觉和信心,不是推导路径。这种相似性是事后发现的,而不是从生物学反向工程出来的。这恰恰说明,自然视觉系统和人工神经网络,在面对相同的问题约束时,独立地发展出了相似的结构解决方案。
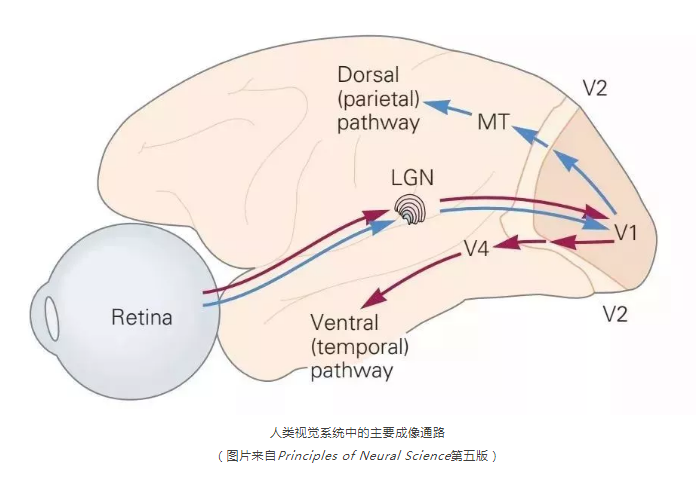
图 5.1:人类视觉皮层的层次化处理
5.3、卷积的两个核心假设
LeCun 的卷积神经网络,把关于图像的两个核心假设编码进了网络结构本身。而这两个假设,是卷积网络之所以强大的根本原因。
5.3.1 假设一:局部性
在图像中,只有相邻的像素才会高度相关,而距离较远的像素之间几乎无关。
这个直觉很简单:例如,当我们看到一张猫的照片时,猫耳朵位置的一个像素,和它旁边的像素很可能是相似的颜色(猫毛)。但这个像素和图片右下角某个随机位置的像素,则几乎没有任何关系。
想象一个实际的图像:如果你在看猫脸的细节时,你只需要关注猫脸周围 10×1010×1010×10 像素的区域。你不需要同时看脚爪或者尾巴。这个像素级别的事实对应了一个视觉学事实:图像中的信息是空间局部的。边缘、纹理、颜色渐变,这些视觉元素都是局部现象,不会跨越整张图传递。
因此,当我们要判断一个像素区域"是什么",只需要看它附近的区域即可,而不需要看整张图。这正是卷积核的工作方式------一个 3×33×33×3 的卷积核,在某个位置,只看该位置周围 3×33×33×3 像素的 9 个值。
基于这个假设,卷积网络的每个神经元只连接一个局部区域 (感受野,Receptive Field),而不是整个图像输入。例如,一个 3×33×33×3 的卷积核的感受野是 9 个像素。相比全连接层的 150000+ 个连接,每个神经元的参数数量从十几万降到了个位数。这带来的不仅是参数数量的减少,更是计算复杂度的指数级下降。
5.3.2 假设二:平移等变性
图像中的同一种特征,无论出现在图像的哪个位置,识别它的方式是一样的。
对于左上角的竖直边缘和右下角的竖直边缘,它们是同一种东西,就应该用同一种滤波器来检测。同样,对于猫耳朵的尖角形状,无论猫在画面的哪个位置,检测它的权重也应该是一样的。
基于这个假设,卷积网络会使用同一个滤波器扫过整个图像 ------这叫做权重共享 (Weight Sharing)。一个 3×33×33×3 的滤波器,在整张图片上滑动,在每个位置都做同样的操作,用完全相同的权重。
权重共享的效果是:原本需要为每个位置单独学习的权重,现在被共享了------一个 3×33×33×3 的滤波器只有 9 个参数,而这 9 个参数会通过滑窗的方式被用来处理图像中的所有位置。如果图像是 224×224224×224224×224,这个 3×33×33×3 滤波器会被应用 (224−3+1)2≈50000(224-3+1)^2 ≈ 50000(224−3+1)2≈50000 次,但始终使用的是同样的 9 个权重。
基于这两个假设,CNN 网络可以带来两个直接的好处:
参数效率极大提升 。例如,一个 3×3×33×3×33×3×3 的卷积滤波器(3 行 × 3 列 × 3 通道)只有 27 个参数,而不是数十万。如果一个卷积层有 64 个这样的滤波器,总参数数也只有 1728 个------相比全连接层的动辄数百万参数,这是一个巨大的差异。
天然的位置泛化。因为同一个滤波器处理所有位置,它学到的特征识别能力,天然就可以应用到图像的任何位置------不需要为每个位置单独学习。如果你的训练数据中,有猫在画面左侧的样本,那么网络学到的"猫脸检测器"就会自动泛化到猫在其他位置的情况。
这就是归纳偏置(Inductive Bias)的威力。
5.4、归纳偏置:正确的假设如何指数级提升学习效率
5.4.1 什么是归纳偏置
"归纳偏置"的意思是:模型对数据的结构有一定的先验假设,而这些假设决定了模型会从数据里归纳出什么样的规律。所有的模型都有归纳偏置------区别只在于这个偏置是否和数据的真实结构一致。
一个没有任何归纳偏置的模型(比如完全连接的神经网络),它的假设是:"所有东西都可能和所有其他东西有关"。这个假设过于宽泛,意味着模型必须靠数据来排除几乎所有不成立的关系。在图像上,这需要极其大量的样本------"告诉"网络猫在左边和猫在右边是同一种东西,这件对人类直觉显而易见的事情,全连接网络必须花大量数据重新发现。
因此,卷积网络的归纳偏置是:在图像里,像素只与局部像素相关,而特征与其所处的位置无关。
这个假设和图像数据的真实统计特性高度一致。自然图像的绝大多数信息都体现在局部的纹理和边缘上;同样的视觉模式(边缘、纹理、形状)无论出现在哪里都应该被同样地识别。这两个假设都是对的------所以卷积网络一旦有了足够的数据,就能快速收敛到有效的特征表示。
5.4.2 用类比理解归纳偏置的威力
我们可以把"从数据里学习"想成探案的过程。
一个没有任何先验信息的侦探,就必须排查整个城市的所有人,逐一进行背景调查、查问不在场证明、验证购买记录。这个侦探可能要花一年的时间才能锁定嫌疑人。
而一个知道案发地点在某栋写字楼的侦探,只需要排查这栋楼的访问记录、监控录像和相关人员。搜索空间缩小了 1000 倍,侦探可能花一周时间就能破案。
再进一步,一个知道案发时间、知道从监控看出嫌疑人穿着的侦探,搜索空间再缩小 100 倍。现在只需要检查那段时间出入该楼且穿着匹配的人名单。
正确的假设,就是把搜索空间从"整个城市"缩减到"某个楼"、再缩减到"那个楼的电梯记录"。
机器学习中的情况完全类似。全连接网络相当于第一个侦探,它对数据结构的假设太弱,必须用大量训练样本来补偿。CNN 相当于第二、第三个侦探,它内建了关于图像结构的假设,从而显著缩小了搜索空间。
把关于问题结构的正确假设编码进模型,可以让学习过程指数级更高效------这是归纳偏置的威力,也是 CNN 在图像任务上碾压全连接网络的根本原因。
这个洞察,后来成为整个深度学习架构设计的核心哲学:
- Transformer 的归纳偏置是"任意两个位置都可以直接交互",适合序列性模态
- 图神经网络的归纳偏置是"局部拓扑结构决定节点表示",适合图数据
- RNN 的归纳偏置是"时间维度有顺序依赖",适合时间序列
每种架构,都是一种关于数据结构的假设------选对了,事半功倍;选错了,事倍功半。
5.5、卷积操作的工程细节
5.5.1 滤波器的三个重要参数:kernel size、stride、padding
现在让我们进入卷积操作的具体工程细节。当一个工程师实现卷积层时,有三个超参数需要进行调整,这直接决定了输出的大小和计算复杂度。
Kernel Size(卷积核大小)
卷积核的大小决定了每次"看"多大的范围。最常见的是 3×33×33×3 的核,这在 VGGNet 中被证明是一个很好的选择。较大的核(如 5×55×55×5、7×77×77×7)能一次看到更大的范围,更宽的视野,但代价是参数更多、计算更重。较小的核(1×11×11×1)则几乎无法捕捉空间信息,通常用于通道维度的处理,而不是空间特征提取。
Stride(步长)
步长决定了卷积核在图像上移动时的跳跃距离。如果 stride = 1,核每次向右移动 1 个像素。如果 stride = 2,核每次向右移动 2 个像素,这样输出会变小。
具体来说,如果输入大小是 WWW,卷积核大小是 KKK,步长是 SSS,那么输出大小约为 (W−K)/S+1(W - K) / S + 1(W−K)/S+1。例如,224×224224×224224×224 的输入,3×33×33×3 的核,stride 为 1,输出就是 (224−3)/1+1=222×222(224 - 3) / 1 + 1 = 222×222(224−3)/1+1=222×222。如果 stride 为 2,输出就是 (224−3)/2+1=111×111(224 - 3) / 2 + 1 = 111×111(224−3)/2+1=111×111------通过增大步长,可以快速压缩空间分辨率,减少后续计算量。
在实际网络中,stride 通常在卷积层中设置为 1 或 2,或者使用单独的池化层来进行下采样。这是一种权衡:用 stride=2 的卷积比用单独的池化层计算量少,但用池化层可以让卷积和下采样的职责更清晰。
Padding(填充)
这里有一个问题是,卷积操作会缩小图像。一个 224×224224×224224×224 的图像,经过一个 3×33×33×3 的卷积,输出变成 222×222222×222222×222。多层卷积后,空间尺寸会快速萎缩。
为了解决这个问题,人们在输入图像周围补充 0(或其他值),这叫做 padding 。如果你在 224×224224×224224×224 的图像周围填充 1 圈 0,输入变成 226×226226×226226×226。再用 3×33×33×3 的卷积,输出变成 224×224224×224224×224------大小保持不变了。
这在网络设计中很重要。例如,在 ResNet 中,残差连接要求两个卷积块的输入和输出大小相同,这通常通过 padding 来实现。不同的 padding 策略(zero-padding、reflection-padding、replication-padding)在不同应用上有细微差异,但最常见的还是 zero-padding。
5.5.2 卷积作为特征检测器:从边缘到纹理
一个卷积滤波器,本质上就是一个模式检测器。
以边缘检测为例。图像处理领域早已知道,一个可以用来检测竖直边缘的滤波器卷积核形式为:
[-1 0 +1]
[-1 0 +1]
[-1 0 +1]把这个滤波器应用到图像的某个 3×33×33×3 区域的原理是这样的:将对应位置的像素值和滤波器权重相乘,然后加起来求和。
如果这个区域的左边是暗的(像素值小,比如 50),右边是亮的(像素值大,比如 200),那么:
- 左列的计算:-1 × 50 = -50
- 右列的计算:+1 × 200 = +200
- 两者加起来:-50 + 200 = +150
得到一个较大的正数------强响应,检测到竖直边缘。而如果这个区域整体是均匀的(没有边缘),左右像素值相差不大,比如都是 100,加权和接近于零------弱响应,没有竖直边缘。
这个原理非常直观:滤波器的权重设计得能够"响应"某种特定的视觉模式。检测水平边缘的滤波器会是:
[-1 -1 -1]
[ 0 0 0]
[+1 +1 +1]检测左上-右下对角线边缘的滤波器会是:
[-1 0 +1]
[ 0 0 0]
[+1 0 -1]在 CNN 里,这些滤波器的权重不是人工设计的 ,而是通过训练自动学出来的。在 AlexNet 的可视化(Zeiler & Fergus 2014 做了系统的可视化工作)里,第一层学到的滤波器自发地呈现出各种方向的边缘检测器、颜色渐变检测器------非常类似 Sobel、Gabor 等人工设计的滤波器,但并不完全相同。
网络并没有被告知"每个卷积核应该学什么样的边缘或者特征检测",它是从图片数据的统计规律里自己发现了这是个有用的特征。更深层的卷积层则学到了更复杂的特征------不只是边缘,而是纹理、形状、部件等。
机器之眼,看到了和人类工程师花十年才总结出来的同样的东西------但它只花了几天训练。这不只是技术进步,而是一种对人类专业知识积累方式的根本性颠覆。
5.5.3 卷积核的其他变体:为不同场景优化
除了基础的卷积之外,研究者们还开发了各种变体,以应对特定的实际需求。
分组卷积(Group Convolution)
在标准卷积中,一个卷积核会同时处理输入的所有通道。但这有时不是必要的。分组卷积把输入通道和输出通道分成若干组,每组独立进行卷积计算。比如,如果输入有 64 个通道,分成 8 组,那么每组只有 8 个通道,每组的卷积核也相应地变小。
这大幅减少了参数数量和计算量。例如,原本 3×3×64×643×3×64×643×3×64×64 的卷积有 36864 个参数;分组卷积(8 组)变成 8×(3×3×8×8)8 × (3×3×8×8)8×(3×3×8×8) = 4608 个参数------少了 87.5%。
分组卷积最著名的应用是 AlexNet 中的设计。由于 2012 年的 GPU 显存有限,AlexNet 的某些层采用分组卷积来节省显存占用。后来,MobileNet 和其他移动端网络也大量采用分组卷积来减少计算。
深度可分卷积(Depthwise Separable Convolution)
这是分组卷积的一个特殊形式,也是 MobileNet 的核心创新。它把一个普通卷积分解成两个更小的卷积:
- 逐深度卷积(Depthwise Convolution):对每个输入通道独立进行卷积,卷积核个数等于输入通道数
- 逐点卷积(Pointwise Convolution) :用 1×11×11×1 卷积进行通道之间的线性组合
例如,一个 3×33×33×3 的卷积,输入 32 通道、输出 64 通道,标准做法需要 3×3×32×64=184323×3×32×64 = 184323×3×32×64=18432 个参数。用深度可分卷积,需要 3×3×32+1×1×32×64=288+2048=23363×3×32 + 1×1×32×64 = 288 + 2048 = 23363×3×32+1×1×32×64=288+2048=2336 个参数------少了 87.3%。
计算量同样大幅减少,但精度损失很小。这是为什么 MobileNet 能在手机、平板等资源受限的设备上达到不错准确率的关键。
空洞卷积(Dilated Convolution)或膨胀卷积
在某些任务中(比如语义分割),需要在保持空间分辨率的同时扩大感受野。空洞卷积通过在卷积核的权重间插入"空洞"(即 dilation factor)来实现。
例如,一个 3×33×33×3 的标准卷积看的是相邻的 9 个像素。一个 dilation=2 的 3×33×33×3 卷积,看的是间隔为 2 的 9 个像素------有效感受野是 5×55×55×5,但参数数量仍然只有 9。这对于需要大感受野但计算资源有限的场景特别有用。
可形变卷积(Deformable Convolution)
标准卷积的感受野是固定的矩形网格。但对于复杂形状的物体(比如扭曲的文字、弯曲的道路),固定的矩形感受野可能不是最优的。可形变卷积允许卷积核的采样位置动态调整,即卷积核会"畸变"以适应图像中的非矩形结构。
这在 2017 年由何恺明等人提出,在物体检测和分割任务中显示了性能提升,但计算复杂度也相应增加,因此主要用于需要高精度的场景,而不是实时处理。
5.6、感受野的逐层扩张:从局部到全局
单个卷积层只看局部(3×33×33×3),那怎么处理整张图的信息?答案是通过堆叠。
第一层 :每个输出神经元看输入的 3×33×33×3 区域,感受野 = 3×33×33×3。
第二层 :以第一层的输出为输入。第二层的一个 3×33×33×3 卷积核,看第一层输出的 3×33×33×3 区域。而第一层输出的 3×33×33×3 区域,对应原始输入的 5×55×55×5 区域。所以第二层的感受野 = 5×55×55×5。
第三层 :同理,感受野 =7×7= 7×7=7×7。
依次类推,第四层 =9×9= 9×9=9×9,第五层 =11×11= 11×11=11×11......
如果卷积核使用步长 stride=2,感受野会扩大得更快。例如,如果每一层都用 stride=2,那么感受野会以 2 的幂速率增长:3 → 7 → 15 → 31 → 63......
在 AlexNet 的五层卷积后,实际感受野已经覆盖了整个 224×224 的输入(因为确实有步长大于 1 的卷积,感受野扩大得更快)。
这是卷积网络的深刻设计:通过局部操作的层层堆叠,把局部信息聚合成全局表示。不需要全连接的暴力连接,也能综合整张图的信息。
而且,这种层次化聚合有一个额外的好处:不同层提取了不同抽象程度的特征。
- 第一、二层:边缘、纹理、颜色渐变
- 第三、四层:形状、结构、部件(比如"圆形"、"毛发纹理")
- 第五层及全连接层:物体级别的语义特征("这是一只猫")
这种层次化表示,和 Hubel-Wiesel 发现的视觉皮层层次结构惊人地相似------不是因为 LeCun 刻意模仿,而是因为两者都在解决同一个问题:如何从低分辨率的局部信号,逐步构建高层的语义理解。
5.7、池化与下采样:在精度和效率间权衡
卷积层提取了特征,但还需要一个操作来压缩信息 ,同时提供额外的稳定性和平移容错。这就是池化(Pooling)。
5.7.1 最大池化:保留最强的声音
最常见的池化方式是最大池化(Max Pooling)。
把特征图分成不重叠的 2×2 区域,在每个区域里只保留最大值:
输入特征图:
[1 3 | 2 0] 经过 2×2 最大池化:
[2 4 | 1 5] → [4 5]
-------|------- [3 4]
[0 1 | 3 2]
[3 2 | 1 4]这个操作做了什么?
空间压缩 :224×224224×224224×224 的特征图经过 2×22×22×2 最大池化,变成 112×112112×112112×112------减少了 75% 的数据量,后续层的计算量随之下降。这意味着你的网络不需要处理那么多数据,训练速度会加快,显存占用会减少。
特征筛选 :最大值代表"该区域内,这个滤波器的最强响应"。换句话说,只要这个区域内的某个位置有这种特征,我们就认为这个区域有这种特征------不需要精确的位置信息。这是一个定位不敏感性的特征,对分类任务很有帮助。
轻微的平移容错 :假设一个特征在位置 (10, 10) 有强响应,图像轻微移动后,响应可能在 (11, 10)。但如果两个位置都在同一个 2×22×22×2 的池化窗口里,最大池化的输出不变------对小范围的平移不敏感。这给了网络一定的鲁棒性,使得网络对微小的图像变化(比如物体微微移动、微微旋转)不那么敏感。
这第三点,和我们在第四章讲残差连接时的思路类似:在设计中显式处理掉你知道会发生的变换,而不是依赖数据来学习。
5.7.2 其他池化方式
除了最大池化,还有平均池化(Average Pooling)------取区域内的平均值,而不是最大值。平均池化在某些任务上更合适,比如它对大范围特征的整体强度更敏感,对异常值更不敏感。如果一个区域里大多数值都是 3,但有一个 100 的异常值,最大池化会取 100,而平均池化会忽视这个异常值,取一个接近 3 的值。
全局平均池化 (Global Average Pooling,GAP)是另一种特殊形式:把整张特征图(比如 7×7×5127×7×5127×7×512)压缩成一个向量(512 维),每个通道取一个平均值。
这个操作有一个巨大的优势:它完全消除了空间维度,但保留了通道维度的信息。而且,它不引入任何额外参数------GAP 是一个完全无参数的操作。
GoogLeNet 大量使用全局平均池化来代替传统的全连接层。想象一下,如果有 7×7×10247×7×10247×7×1024 的特征图,接一个全连接层到 1000 类,需要 7×7×1024×1000=50007 × 7 × 1024 × 1000 = 50007×7×1024×1000=5000 多万个参数。但用 GAP,只需要平均每个通道,然后用一个 1024→1000 的全连接层(约 100 万参数)。这是一个数量级的差异。
5.7.3 1×11×11×1 卷积:通道维度的瑞士军刀
在这里值得提一个经常被忽视但极其实用的卷积操作:1×1 卷积。
顾名思义,1×11×11×1 的卷积核,感受野只有 1 个像素。这看起来毫无意义------它什么局部信息都学不到。但 1×11×11×1 卷积做的不是空间处理,而是通道处理 :把一个位置上的 CCC 个通道的值线性组合成 C′C'C′ 个通道。
这个操作有两个实际用途:
降维(减少计算量) :如果特征图是 7×7×5127×7×5127×7×512,你要接一个 3×3×5123×3×5123×3×512 的卷积(输出 256 通道),标准做法需要的参数是 3×3×512×256≈1183 × 3 × 512 × 256 ≈ 1183×3×512×256≈118 万。但如果先用 1×11×11×1 卷积把 512 通道压缩到 64 通道,再做 3×33×33×3 卷积,参数变成 1×1×512×64+3×3×64×256≈181×1×512×64 + 3×3×64×256 ≈ 181×1×512×64+3×3×64×256≈18 万------减少了约 85%。计算量相应降低,网络训练更快。
升维(增加表达能力) :在某些场景下,可以用 1×11×11×1 卷积把通道数从少扩展到多,相当于增加了特征的维度,而不需要改变空间分辨率。这在融合多尺度特征时特别有用。
通道融合 :在 Inception 模块中,不同大小的卷积并行处理,最后用 1×11×11×1 卷积融合它们的输出,选择性地组合来自不同尺度的特征。
GoogLeNet 的 Inception 模块大量使用了 1×11×11×1 卷积作为"bottleneck"(瓶颈)来控制计算量,ResNet 的深层版本(ResNet-50/101/152)也用了同样的设计------先降维、再处理、再升维,让极深的网络在可控计算代价下成为可能。
5.8、经典架构演进:从 LeNet 到 ResNet 与之后
5.8.1 LeNet-5:第一个真正落地的深度学习系统
1989 年,LeCun 在 Bell 实验室设计了第一版卷积网络,用于识别手写邮政编码。1998 年,他发表了 LeNet-5,一个更完整、更成熟的版本。
LeNet-5 的架构非常简洁:
输入(32×32) → 卷积(6个5×5核) → 池化 → 卷积(16个5×5核) → 池化 → 全连接 → 输出(10类)参数量:约 6 万个。在那个时代,这已经是一个"大"网络了。
LeNet-5 被用于美国邮政系统的支票邮编识别,最终处理了 AT&T 美国邮递服务中大约 10%-20% 的手写支票读取任务。换算一下这个规模:美国每年处理约 400 亿张支票,10% 就是 40 亿张------这不是一个实验室演示,而是每天数千万张真实支票在真实流水线上被 LeNet-5 处理。在错误率上,LeNet-5 也达到了 1% 以下的误读率,优于此前所有人工规则系统。
这是深度学习第一次真正的、有统计意义的商业化落地。 它不只是在测试集上表现好,而是在美国最大的金融基础设施之一里,日复一日地处理真实业务。
LeCun 多年后回忆,当时有人会来找他参加商务演示,他会拿出笔记本电脑,现场演示 LeNet-5 读取手写数字------总是能引起观众的震惊反应。一个机器在实时读取手写的、参差不齐的邮编,而且准确率比当时大多数人工方法更高------这在 1990 年代是令人瞠目结舌的场景。
但他也回忆了一种深刻的无奈。
尽管 LeNet-5 在商业上是真实有效的,1990 年代的主流 AI 学术社区对这个工作几乎不感兴趣。 原因不是效果不好------效果有目共睹。原因是那个时代有一个更时髦、更"有理论根基"的替代品:支持向量机(Support Vector Machine,SVM)。
SVM 在 1990 年代横扫了机器学习竞赛和学术排行榜。它有严格的数学理论------凸优化、核函数、最大化间隔------可以证明在某些条件下保证收敛到全局最优。更重要的是,它的性能好、训练数据需求量相对小,在各种基准测试上以微弱差距胜过或平手 LeNet-5。在那个时代,神经网络是"工程技巧"的代名词------你需要仔细选择架构,要调超参数,没有任何理论保证它会收敛,也无法解释为什么它有效。SVM 的理论洁净感,让神经网络显得土气。
LeCun 在这场争论中是孤独的。他坚持认为卷积网络的设计原则是正确的,是可扩展的,是未来。但当时没有足够的数据来证明"大"的神经网络比"小"的更好,也没有足够的算力来训练真正大的网络,所以他的坚持很难被检验。
在 Bell 实验室的一次内部报告里,LeCun 用 LeNet-5 在一个测试集上的结果和 SVM 做了对比,两者几乎持平。听报告的研究员转身问他的同事:"所以他们为什么不用 SVM 呢?"
LeNet-5 在那十年里,很像一颗被人忽视的珍珠。 它有实际的价值,但学术界看不到。直到 2012 年 AlexNet 的爆发,才终于证明了 LeCun 的执着。这段挫折期,从 LeNet-5 在 1998 年到 AlexNet 在 2012 年,足足等了 14 年。LeCun 在这 14 年间坚持深度学习研究,即便大多数同行都转向了 SVM。这是对信念的考验。
5.8.2 AlexNet 之后:深度的觉醒
第四章已经详细讲过了 AlexNet(2012)、VGGNet(2014)、ResNet(2015)的技术细节和历史背景。这里我们从架构设计哲学的角度再来补充一些细节。
AlexNet 的设计 是大胆的、有些杂乱的:混用 11×1111×1111×11、5×55×55×5、3×33×33×3 的卷积核,靠实验找到好的超参数。这是 2012 年的风格------没有太多理论指导,就是跑实验,看什么有效。AlexNet 成功后,后来的研究者逐渐意识到:不是所有的卷积核大小都有用,设计可以更有原则。
VGGNet 的设计哲学 是"简洁产生效率":只用 3×33×33×3 的卷积核,所有结构判断都靠这个最小单元。
为什么 3×33×33×3 是最优选择?VGG 的论文给出了一个漂亮的数学论证:
- 两个连续的 3×33×33×3 卷积,感受野等同于一个 5×55×55×5 卷积,但参数量是 2×32=182 × 3^2 = 182×32=18,远小于 52=255^2 = 2552=25
- 三个 3×33×33×3 = 一个 7×77×77×7 的感受野,参数量 3×9=273 × 9 = 273×9=27,远小于 72=497^2 = 4972=49
用更多小卷积核堆叠代替大卷积核:相同的感受野,更少的参数,同时因为有了更多非线性激活层,表达能力反而更强。而且,更多小卷积核意味着更多的非线性函数,网络的"弯曲"程度更高,可以拟合更复杂的函数。
这个设计原则,后来成了 CNN 架构设计的主流思路之一。
ResNet 的残差连接,我们在上一章详细讲过了。这里强调一个有趣的视角:
残差连接的核心是让网络学习增量 (Residual),而不是目标函数本身。这在某种程度上类似人类学习的方式------你已经会做某件事了,当你学习"做得更好"时,你学的是"在已有基础上改进什么",而不是"从零开始学怎么做"。
这个"学增量比学目标函数更容易"的直觉,在后来的 Transformer 架构中也被保留了下来------每个 Transformer 层同样有残差连接。
5.8.3 轻量化网络的时代:为移动设备而生
2012 年到 2015 年间,CNN 的发展方向主要是追求更深、更准确------ResNet 推到 152 层,网络变得越来越深。但随着深度学习应用的落地,一个新的需求出现了:
能不能在手机、平板、嵌入式设备上跑深度学习?
手机 GPU 的算力只有服务器 GPU 的千分之一,内存只有几个 GB。一个 ResNet-50 有 2500 万参数,就算用 FP16 半精度,也要占用 50MB 的内存------对手机来说是一个沉重的负担。更别提运行时的计算,ResNet-50 的一次前向传播需要 40 多亿次浮点计算,在手机 GPU 上需要好几秒。用户不可能等待。
这催生了一系列轻量化网络(Lightweight Network),目标是用尽可能少的参数和计算量,实现尽可能好的准确率。
MobileNet(2017,Howard 等,Google)
MobileNet 的核心创新是深度可分卷积,我们在前面已经详细介绍过了。通过这个技巧,MobileNet 把标准 CNN 的参数从几千万降到几百万,计算量也相应大幅下降。
例如,MobileNet v1 在 ImageNet 上的准确率达到 70.6%,参数只有 430 万------相比 ResNet-50 的 2500 万参数,只有 1/6。而且执行速度快了 10 倍以上。
MobileNet 的设计还包含了一个重要概念:宽度乘数(Width Multiplier)------通过一个超参数来统一缩放所有通道数,实现"在准确率和速度之间灵活权衡"。如果你的设备资源非常受限,就降低宽度乘数,换取更快的速度;如果资源充足,就提高宽度乘数,换取更高的准确率。
ShuffleNet(2017,Zhang 等,Face++ / Megvii)
ShuffleNet 在深度可分卷积的基础上,引入了通道混洗(Channel Shuffle)操作。在深度可分卷积中,不同通道的信息被分离处理,可能导致某些通道之间缺乏交互。通道混洗通过在某些操作后随机重排通道顺序,让不同通道之间有机会交互,从而在保持高效率的同时提升准确率。
ShuffleNet 的参数数甚至比 MobileNet 更少,但在相同的计算预算下,准确率反而更高。
EfficientNet(2019,Tan & Le,Google Brain)
EfficientNet 提出了一个更系统的思路:复合缩放(Compound Scaling)。
当要缩小一个网络以适应更小的设备时,该怎么缩呢?我们可以减少网络的深度(层数),或者减少宽度(通道数),或者降低输入分辨率。但这三个维度应该怎样平衡?
EfficientNet 通过大量实验发现,最优的平衡是这三个维度按特定的比例共同缩放。例如,如果计算预算增加 2 倍,最优的方案是深度增加 1.3 倍、宽度增加 1.2 倍、输入分辨率增加 1.2 倍。
基于这个发现,EfficientNet 推出了一个系列:从 EfficientNet-B0(最小)到 EfficientNet-B7(最大),覆盖从手机到云服务器的各种场景。EfficientNet-B0 只有 390 万参数,但准确率达到 77.1%------比 MobileNet 更轻量但识别率更准确。
5.8.4 特殊应用:超越分类
CNN 的应用远不止图像分类。在 LLM 时代到来之前,CNN 在多个领域产生了重大影响。
目标检测
仅仅知道"图里有什么"还不够,很多应用需要知道"它在哪里"。这推动了目标检测(Object Detection)的发展。
2015 年,Faster R-CNN (何恺明等)提出了一个优雅的框架:先用 CNN 提取特征,然后用一个区域建议网络(Region Proposal Network,RPN)自动生成候选的物体位置,再在这些区域上进行分类。这个框架成为了后来目标检测的标准范式。
同时,YOLO(You Only Look Once,Redmon 等)提出了完全不同的思路:不生成候选区域,而是直接用一个 CNN 预测整张图里所有物体的位置和类别。YOLO 的速度比 Faster R-CNN 快得多,更适合实时应用(比如自动驾驶、视频监控)。
这两条路线------准确率优先(Faster R-CNN)和速度优先(YOLO)------一直并行发展到今天,代表了准确性和效率的两种取舍。
语义分割
比目标检测更难的是语义分割(Semantic Segmentation):为图像中的每个像素分类。比如,在一张街道图里,把所有属于"汽车"的像素标为红色,属于"行人"的像素标为蓝色。
这个任务需要高分辨率的空间信息,但标准的 CNN 经过多层池化后,空间信息损失殆尽。FCN (Fully Convolutional Networks,Long 等,2015)的创新是:用卷积取代全连接层(所以叫"fully convolutional"),并引入上采样(Upsampling)把分辨率恢复回原图大小。
后来的 U-Net(Ronneberger 等,2015)更进一步:用跳跃连接(Skip Connection,类似 ResNet)在下采样时保留高分辨率特征,在上采样时把它们融合回来。U-Net 虽然名字里有个"U"形,但核心思想就是:往下采样提取信息,往上采样恢复分辨率,在这个过程中通过跳跃连接保留细节。
这个设计在医学图像分割(肿瘤检测)和其他需要像素级精度的任务上大放异彩。
人脸识别与验证
CNN 在人脸识别上的应用引发了一系列伦理和技术问题。从技术上,人脸识别分为两个子任务:
- 人脸检测:从图像中找出人脸的位置(和目标检测一样)
- 人脸识别/验证:判断两张人脸是同一个人
对于人脸识别,关键不在于分类准确率,而在于学到一个好的人脸特征表示 。一个常用的思路是:训练一个 CNN,让它学会把同一个人的不同照片映射到特征空间的同一个点附近,把不同人的照片映射到不同的点。这叫做人脸嵌入(Face Embedding)。
FaceNet (Schroff 等,Google,2015)用一个叫三元组损失(Triplet Loss)的技巧来实现这个目标。三元组损失的思想很简单:给定一张人脸 A(锚点)、另一张同一个人的人脸 A+(正样本)、以及不同人的人脸 B(负样本),损失函数要求 A 和 A+ 的距离尽可能小,A 和 B 的距离尽可能大。通过这个损失函数的训练,FaceNet 学到的特征在同人验证任务上达到了 99.6% 的准确率------实际上超过了人眼。
这项技术的出现也引发了关于监控、隐私、偏见的广泛讨论,这也是我们在后续章节会涉及的话题。
风格迁移
还有一个有趣的应用:用 CNN 进行风格迁移(Style Transfer)------把一张图的风格应用到另一张图上。比如,用梵高的《星月夜》的风格重绘一张现代照片。
这背后的思想是:CNN 的不同层学到不同的特征。浅层学到颜色和纹理(风格),深层学到物体形状和内容(语义)。通过分别优化"内容的相似度"和"风格的相似度",可以生成既保留原内容又应用新风格的图像。
这不仅是一个艺术应用,也验证了我们对 CNN 分层特征的理解------低层和高层确实在处理不同的东西。
5.9、迁移学习:CNN 学到的是通用的视觉语言
5.9.1 真正的验证:把 ImageNet 模型搬到任何地方
AlexNet 在 ImageNet 上的 1000 类分类竞赛只是一个起点。2013-2015 年,研究者开始做一个更重要的实验:把在 ImageNet 上训练好的 AlexNet 直接搬到完全不同的任务上,观察它的特征是否还有效。
答案让所有人惊呆了。
医学图像:把 AlexNet 预训练权重搬到皮肤癌分类任务上,只需要在最后几层做少量调整("微调",Fine-tuning),在几千张医学图像上训练------结果比从零开始训练的专用模型还要好,有时甚至接近皮肤科专科医生的水平。注意:皮肤癌图像和猫狗图像在视觉上几乎没有任何关系。
卫星遥感:把 ImageNet 预训练的 CNN 用于从卫星图片里识别建筑物、道路、农田------这类图像从拍摄角度、比例尺、色彩分布上都和 ImageNet 的自然图像完全不同。但预训练特征依然有效,显著优于从零开始训练。
艺术风格识别:CNN 能区分不同画家的风格、不同时代的艺术流派------这对人类来说需要多年艺术训练才能掌握的微妙差异,CNN 在看过 ImageNet 之后已经具备了识别这类视觉模式的基础能力。
工业检测:把 ImageNet 预训练模型微调,识别工厂流水线上的产品缺陷。缺陷检测和猫狗分类完全是两码事,但特征迁移工作得很好。
医学诊断:利用 CNN 识别 X 光片中的肺结节、乳腺钼靶中的肿瘤。这些医学应用最终拯救了生命,证明了深度学习不只是学术上的成就,而是有真实的医疗价值。
为什么会这样?
这其实就是"归纳偏置"。CNN 的局部性和权重共享假设,正好对应了自然图像中普遍存在的统计规律:局部纹理、边缘方向、颜色渐变------这些特征不只在 ImageNet 里有用,在几乎所有视觉数据里都有用。
CNN 学到的不是"如何识别 ImageNet 里的 1000 种物体",而是"如何读懂自然图像的视觉语言"。 这个视觉语言是通用的,无论具体任务是什么,这个底层语言都有帮助。
5.9.2 迁移学习:一场实践革命
这个发现在工程实践层面带来了一场革命。
2012 年以前,如果你想开发一个"识别 X"的视觉系统(X 是任意物体、场景或模式),你需要:
- 收集大量 X 的标注图片(数万甚至数十万张)
- 手工设计或选择合适的特征描述子(SIFT、HOG、Color Histograms......)
- 在这些特征上训练 SVM 或其他分类器
- 反复迭代,可能需要几个月
这个过程的瓶颈是什么?标注数据 和 特征工程。收集数万张标注图像很昂贵,而且需要领域专家手工设计特征。
2012 年之后,工程路径变成了:
- 收集数百到数千张 X 的标注图片(数量要求降低 10-100 倍)
- 下载一个在 ImageNet 上预训练好的 CNN(AlexNet、VGGNet、ResNet......)
- 把最后几层替换掉,用收集到的数据微调(通常只需要微调后面几层,前面的卷积层可以冻结)
- 几个小时到几天之内得到超过之前最好方法的结果
这种"预训练 + 微调"的范式,被称为迁移学习(Transfer Learning)。它把深度学习的能力从"顶尖研究团队的专属"变成了"任何工程师都能用的通用工具"。
当时正在斯坦福大学的 Andrej Karpathy 在 2014 年的博客里写道:
不要再从头训练 CNN 了。把 ImageNet 预训练的网络当成一个特征提取器------它提取的特征,几乎对所有视觉任务都有价值。
这个建议,在接下来几年里成了整个计算机视觉工程实践的默认出发点。它改变了一个行业的工作方式。
今天,如果你要做一个计算机视觉项目,"从 ImageNet 预训练模型开始"已经是常识,而不是"新发现"。这说明深度学习不仅改变了技术,还改变了我们做工程的思维方式。
CNN 的价值,不只是在 ImageNet 上赢了一场竞赛------它给了整个视觉领域一种通用的特征语言,一个不需要从零开始的起点。这个起点,让几乎所有视觉应用的开发成本降低了一到两个数量级。
5.10、卷积的局限:当假设与现实不符
5.10.1 归纳偏置的代价:正确的假设,错误的场景
归纳偏置是一把双刃剑。
在正确的场景里,正确的归纳偏置让学习指数级高效------这是 CNN 在图像上成功的原因。但在错误的场景里,错误的归纳偏置比没有任何偏置更糟糕:它会让模型系统性地忽略数据中真正有信息量的结构,即使提供再多的训练样本,也可能无法高效学到正确的东西。
卷积的两个假设------局部性和平移等变性------在图像上高度成立。但一旦数据的结构与这两个假设不符,卷积在大多情况下并不是一个首选的框架。
假设的边界,就是卷积的边界。
5.10.2 语言:长程依赖打破了局部性假设
自然语言是打破卷积局部性假设最典型的例子。
考虑这个句子:"这家餐厅的服务员态度很好,菜品的摆盘也很精致,只是味道......实在不敢恭维。"
这句话的情感倾向,由最后半句的"实在不敢恭维"决定,这是一个强烈的负面信号。但这个关键的否定,与整句话的开头之间隔了大约 40 个字------远远超出了任何合理的卷积窗口大小。即使你用一个 7×77×77×7 的卷积核(看周围 7 个词),也无法跨越整个句子。
对于 CNN 来说,它只能看到局部窗口的每个片段------"这家餐厅的服务员态度很好"的局部判断是正面的,"实在不敢恭维"的局部判断是负面的。但这两个局部判断如何融合成正确的整体判断?CNN 没有一个自然的机制来处理这种跨越整个序列长度的依赖关系。
更深层的问题是:语言的意义不是"空间局部"的,而是"上下文全局"的。 同一个词在不同的句子、不同的上下文里可能有完全相反的意思。"好"这个字,在"味道好"里是正面的,在"好难吃啊"里是强调词,在"你这道菜......好"(配上停顿和语气)里可能是讽刺。要理解它的意义,必须看整个上下文,而不是它旁边的几个字。
卷积的滑动窗口,从根本上无法捕捉这种结构。
2014-2016 年,研究者们确实尝试过把卷积用于文本处理------TextCNN(Kim 2014)用不同大小的卷积核(如 3、4、5)提取 n-gram 特征,在文本分类任务上效果不错。但一旦遇到机器翻译、问答、阅读理解这类需要深度语义理解的任务,TextCNN 就力不从心了。它可以提取局部的词组特征,但无法理解"这个句子里的'他'指的是第三段里的那个人物"这类跨越整个文本的指代关系。
5.10.3 时序数据:位置信息至关重要
卷积的第二个假设------平移等变性------在图像里是一个优点。一只猫在画面左边和在右边,本质上是"同一个东西",应该用同样的特征检测器。但在时序数据里,平移等变性变成了一个缺陷。
时间序列的位置信息是有意义的。 一个股价的波动模式,在三年前和现在出现,对预测的意义是完全不同的------背景、市场状态、经济环境都变了。一首音乐里,同样的旋律主题在第一小节和最终高潮前出现,承担的情感功能截然不同。"位置无关"不是时序数据的特性,而是它需要被显式建模的关键维度。
用卷积处理时序数据,等于在告诉模型"三年前的同样模式和今天的意义相同"------这个假设绝大多数情况下是不正确的。
更麻烦的是可变长度问题。卷积的核是固定大小的,处理固定输入。对于自然语言这样长度从几个字到几千字不等的序列,卷积要么用 padding 强行补齐(引入噪声),要么需要设计复杂的多尺度结构(增加工程复杂度),都是在绕开问题而不是真正解决问题。
5.10.4 图数据:局部性的定义不成立
还有一类数据,卷积不只是不擅长,而是从根本上无法适用:图数据(Graph Data)。
分子结构、社交网络、知识图谱、交通路网------这些数据里,"距离"和"局部"的定义本身就是由图的拓扑结构决定的,而不是由欧几里得空间的距离决定的。
一个分子里,两个原子之间的"距离"是化学键的数目,而不是它们在二维图示里的像素距离。一个社交网络里,两个用户之间的"关系强度"取决于他们有多少共同朋友、互动频率,而不是他们在某个矩阵里的相对位置。
CNN 处理图像时,"3×33×33×3 局部"这个概念有清晰的空间定义。但把一个分子图"铺"成一个矩阵,然后用 3×33×33×3 的卷积核处理,是没有意义的------这个操作没有物理/化学的对应解释,也无法捕捉分子的拓扑结构信息。
这催生了一个全新的研究方向:图神经网络(Graph Neural Networks,GNN)------它有自己的归纳偏置,是专门为图数据结构设计的。
5.10.5 卷积的局限:推动了什么
卷积的这些局限,并不是一种缺陷的暴露------它们是历史进程的催化剂。
正是因为 CNN 在序列数据上的局限,研究者开发了 RNN 和 LSTM ,为序列建模引入了"记忆"机制。但 RNN/LSTM 也有自己的问题(梯度消失、顺序处理慢、难以捕捉极长程依赖)。这些问题,又推动了注意力机制 (Attention)的诞生------"不假设局部性,让每个位置都可以直接关注任意其他位置"。注意力机制最终演化成了 Transformer(2017),彻底放弃了局部性假设,在语言、图像、语音等几乎所有模态上刷新了历史记录。
每一代技术的局限,都精确地描绘了下一代技术需要解决的问题。
卷积的局限,不是故事的终点,而是故事的转折点。
5.11、 LeCun 的三十年:信念与验证
2018 年,美国计算机学会(ACM)将图灵奖授予 LeCun、Hinton 和 Yoshua Bengio 三人,表彰他们在深度学习领域"从概念到关键技术"的贡献。
LeCun 在获奖感言里回顾了那漫长的三十年------从 1989 年在 Bell 实验室的第一个想法,到 1998 年 LeNet-5 的完成,再到被学术界冷落的 14 年,再到 2012 年 AlexNet 突然让所有人都看见了。他用一句极其平静的话总结了这段历程:
"我们知道它是对的,只是需要时间让世界看到。"
这不是自信,而是对科学直觉的坚守。在没有 GPU、没有大数据、没有论文接收的时代,LeCun 和少数几个信徒坚持认为卷积网络是未来。当 SVM 统治了 1990 年代的机器学习时,他们没有放弃。当审稿人拒掉他们的论文说"SVM 已经够好了"时,他们继续写代码、跑实验。
这三十年不仅仅是一个人的故事,而是深度学习作为一个学科从被否定到被认可的完整周期。它教会我们一个关于科学的真理:对的想法有时候需要等待正确的时刻------足够的数据、足够的算力、足够的生态。 但最重要的是,有人愿意坚持,直到那个时刻到来。
卷积神经网络的诞生、冷落、复兴、统治,是人工智能历史上最动人的一幕。
5.12、知识自检
读完本章,你应该能做到:
- 用具体数字说明全连接网络处理图像时参数爆炸的严重程度
- 解释"平移不变性"对图像识别的重要性,以及全连接网络为什么天然缺乏它
- 描述卷积的两个核心假设(局部性、平移等变性),以及它们对应图像数据的哪些真实特性
- 用滤波器权重矩阵的例子,解释一个卷积核如何"检测竖直边缘"
- 理解 stride、padding、kernel size 这三个参数如何影响卷积的输出大小
- 解释分组卷积、深度可分卷积、空洞卷积各自解决什么问题
- 计算两层、三层 3×3 卷积堆叠后的感受野大小
- 解释最大池化如何实现降维、特征筛选和轻微平移容错
- 用 VGG-16 的架构说明"前半段特征提取、后半段分类"的设计逻辑
- 用"侦探缩小搜索范围"的类比解释归纳偏置的威力
- 说出 LeNet-5 在 1990 年代被主流学界忽视的真实原因,以及 LeCun 坚持了多久
- 对比 LeNet、AlexNet、VGGNet、ResNet 的设计哲学
- 解释 MobileNet 和 EfficientNet 如何在有限计算预算下实现准确率和效率的平衡
- 解释迁移学习为什么能奏效------为什么在 ImageNet 上训练的特征,能迁移到医学图像或卫星遥感
- 说出目标检测(Faster R-CNN、YOLO)和语义分割(FCN、U-Net)的核心思路
- 解释卷积在什么类型的数据上会失效,以及这为什么引出了后来的 RNN 和 Transformer
5.13、常见误解
❌ "卷积好主要是因为它减少了参数数量"
✅ 实际上:减少参数只是表象。根本原因是卷积正确地编码了图像数据的结构 ------局部相关性和平移等变性。一个参数数量很少的模型,如果假设不对(比如一个随机稀疏连接的网络),也不会比全连接更好。参数少、效果好,是正确假设的结果,而不是直接原因。好的假设自动带来参数效率。
❌ "卷积提供了完全的平移不变性"✅ 实际上:卷积层本身提供的是平移等变性(equivariance),不是平移不变性(invariance)------特征的激活位置会随物体位置移动(输入移动,输出也移动)。池化层提供了一定程度的不变性,但范围很小(仅在池化窗口内)。完全的平移不变性需要全局平均池化,而这会丢失位置信息,对检测任务有害。理解这个区别,能帮你判断什么时候需要加入池化,什么时候不应该加。
❌ "更深的卷积网络一定更好"✅ 实际上:深度带来更大感受野和更强表达能力,但也带来训练困难(梯度消失)和计算代价。在 ResNet 之前,超过 50 层的网络训练误差反而更高("退化问题")。深度需要配合残差连接、批归一化等技术才能真正发挥作用。无脑加深度是行不通的。
❌ "1×1 卷积没用,感受野只有 1 个像素"✅ 实际上:1×1 卷积的妙处不在空间处理,而在通道处理和降维。它可以用大幅更少的参数实现与大卷积核类似的感受野(通过跨越多层)。在 ResNet 和 MobileNet 这样的高效网络中,1×1 卷积是设计的关键。
❌ "CNN 学到的特征是针对 ImageNet 的,迁移到其他任务会失效"✅ 实际上:CNN 学到的不是"如何识别猫狗",而是"如何读懂图像的底层结构"------纹理、边缘、色彩、轮廓。这些东西在医学图像、卫星图、手写数字、任何视觉数据里都存在。预训练特征的泛化能力,正是 CNN 最强大的地方。
❌ "卷积在 NLP 中完全无用"✅ 实际上:卷积可以用于文本(TextCNN),在文本分类任务上有不错表现。关键是:卷积擅长提取局部 n-gram 特征,适合不太需要全局上下文的任务。但对于需要长程依赖的任务(翻译、问答),卷积确实不够,需要 RNN 或 Transformer。这是架构与任务的匹配问题,不是卷积本身的缺陷。
❌ "深度学习的精髓是让模型完全自主地从数据里学规律,不需要人工注入任何先验假设"✅ 实际上:所有实用的深度学习模型都有显式的归纳偏置 ------CNN 的局部性和权重共享,RNN 的时序假设,Transformer 的全局注意力------这些都是人工设计的先验假设。深度学习减少的是人工特征工程(手工提取边缘、纹理等特征),而不是结构上的先验知识。区别在于:这些先验被编码进了架构设计,而不是特征定义。"端到端学习"不等于"没有先验"。
❌ "MobileNet 和 EfficientNet 的准确率比 ResNet 低很多"✅ 实际上:在相同的计算预算(浮点计算次数)下,MobileNet 和 EfficientNet 的准确率可以和 ResNet 相当甚至更高。关键是比较的是"等计算量"而不是"等参数量"。一个有 50M 参数的网络可能比一个有 10M 参数的网络慢得多(因为参数多不等于计算多)。轻量化网络的意义是在实际运行环境(手机、边缘设备)的约束下达到最佳精度。
本章关键词
| 词汇 | 简明定义 |
|---|---|
| 卷积(Convolution) | 用小滤波器在输入上滑动、计算加权和的操作,实现局部特征提取 |
| 卷积核(Kernel) | 卷积操作中的权重矩阵,通过与输入的逐元素相乘和求和来检测特定特征 |
| 感受野(Receptive Field) | 特征图上的某个神经元,对应到原始输入的哪个区域 |
| 权重共享(Weight Sharing) | 同一组滤波器权重,被用于输入图像的所有位置 |
| 步长(Stride) | 卷积核在图像上移动时的跳跃距离,影响输出大小 |
| 填充(Padding) | 在输入周围添加额外的像素(通常是0),防止空间大小快速缩小 |
| 平移等变性(Translation Equivariance) | 输入平移,输出特征图也平移相同距离(不改变特征本身) |
| 平移不变性(Translation Invariance) | 输入平移,输出的整体结论不变(需要额外的全局池化等机制) |
| 归纳偏置(Inductive Bias) | 模型对数据结构的先验假设,影响学习效率和泛化能力 |
| 特征图(Feature Map) | 卷积层的输出,表示某种特征在输入空间各位置的响应强度 |
| 最大池化(Max Pooling) | 取局部区域内最大值的下采样操作,实现降维和平移容错 |
| 全局平均池化(Global Average Pooling) | 把整张特征图的每个通道平均到一个值,是无参数的降维操作 |
| 批归一化(Batch Normalization) | 对 mini-batch 数据做标准化,稳定训练并支持更大学习率 |
| 内部协变量转移(ICS) | 深度网络训练中,每层输入分布随前层参数更新而持续变化 |
| 1×1 卷积 | 在通道维度做线性变换的卷积,用于升维/降维和通道融合 |
| Bottleneck 设计 | 先降维、再处理、再升维的卷积块设计,减少计算量 |
| 分组卷积(Group Convolution) | 把输入通道和输出通道分成若干组,独立进行卷积计算 |
| 深度可分卷积(Depthwise Separable) | 分解为逐深度卷积和逐点卷积两个步骤,大幅降低参数量 |
| 空洞卷积(Dilated Convolution) | 在卷积核权重间插入"空洞"来扩大感受野,同时保持参数数量 |
| 可形变卷积(Deformable Convolution) | 允许卷积核的采样位置动态调整,适应非矩形结构 |
| 迁移学习(Transfer Learning) | 预训练 + 微调范式,利用 ImageNet 等预训练模型快速适应新任务 |
| 目标检测(Object Detection) | 识别图像中物体的位置和类别(如 YOLO、Faster R-CNN) |
| 语义分割(Semantic Segmentation) | 为图像中每个像素分类(如 FCN、U-Net) |
| 人脸嵌入(Face Embedding) | 把人脸映射到特征空间,相同人的不同照片距离近,不同人距离远 |
| 梯度消失(Vanishing Gradient) | 反向传播时梯度被逐层衰减,导致深层参数无法更新 |
延伸阅读
- 必读 :LeCun, Y., Bengio, Y., & Hinton, G.(2015). "Deep Learning." Nature, 521, 436-444. 三位奠基人的综述,第一、二节讲卷积网络
- 必读 :LeCun, Y. 等(1998). "Gradient-Based Learning Applied to Document Recognition." Proceedings of the IEEE. LeNet-5 的完整论文,是深度学习实际落地的最早里程碑
- 推荐 :Krizhevsky, A., Sutskever, I., & Hinton, G. E.(2012). "ImageNet Classification with Deep Convolutional Neural Networks." NeurIPS. AlexNet 论文,开启了现代深度学习时代
- 推荐 :Simonyan, K., & Zisserman, A.(2015). "Very Deep Convolutional Networks for Large-Scale Image Recognition." ICLR 2015. VGGNet 论文,对小卷积核堆叠的深度网络有很好的分析
- 推荐 :He, K., Zhang, X., Ren, S., & Sun, J.(2016). "Deep Residual Learning for Image Recognition." CVPR. ResNet 论文,引入残差连接,彻底解决深度网络的训练问题
- 推荐 :Ioffe, S., & Szegedy, C.(2015). "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift." ICML 2015. 批归一化原论文,写得清晰且有大量实验数据
- 推荐 :Zeiler, M.D., & Fergus, R.(2014). "Visualizing and Understanding Convolutional Networks." ECCV 2014. 系统性地展示了 CNN 各层学到了什么,是理解 CNN 工作原理的最好参考
- 推荐:Howard, A. G., et al.(2017). "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications." MobileNet 论文,深度可分卷积的经典应用
- 推荐 :Tan, M., & Le, Q. V.(2019). "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." ICML 2019. 复合缩放的系统研究,轻量化网络的新思路
- 深入 :He, K., et al.(2016). "Identity Mappings in Deep Residual Networks." ECCV 2016. ResNet 的改进版本,对残差连接有更深的分析
- 深入 :Long, J., Shelhamer, E., & Darrell, T.(2015). "Fully Convolutional Networks for Semantic Segmentation." CVPR. FCN 论文,把卷积网络扩展到像素级任务
!tip
下一章预告:CNN 的卷积窗口是固定的,擅长的是局部特征和空间不变性。但文本数据完全是另一种结构------词序决定语义,前后文跨越任意距离,上下文的依赖随时可能贯穿整个句子。解决序列问题,我们需要一种能"记住历史"的网络结构。而在此之前,先让我们讨论一些工程上的问题:怎样才能高效地训练这些深度网络?优化算法、学习率调度、权重初始化、分布式训练------这套工程工具箱,是深度学习成为现实的幕后英雄。