一、QAT 调优流程:
流程总览:
针对 征程 6E/M 的硬件特性,以 int8+int16 的混合精度量化为主要调优配置,可尝试少量 fp16 算子如 LayerNorm(fp16 LayerNorm 在 OE 3.5.0 及以后版本支持)。
调优原则:

如上是一个标准的对称量化公式,产生误差的地方主要有:
- round 产生的舍入误差。例如:当采用 int8 量化,scale 为 0.0078 时,浮点数值 0.0157 对应的定点值为 round(0.0157 / 0.0078) = round(2.0128) = 2,浮点数值 0.0185 对应的定点值为 round(0.0185 / 0.0078) = round(2.3718) = 2,两者均产生了舍入误差,且由于舍入误差的存在,两者的定点值一致。
- 对于舍入误差,可以使用更小的 scale,这样可以使得单个定点值对应的浮点值范围变小。由于直接减小 scale 会导致截断误差,所以常用的方法是使用更高的精度类型,比如:将 int8 换成 int16,由于定点值范围变大, scale 将减小。
- clamp 产生的截断误差。当 qmax * scale 无法覆盖需要量化的数值范围时,可能产生较大截断误差。例如:当采用 int8 量化,scale 为 0.0078 时,qmax * scale = 127 * 0.0078 = 0.9906,大于 0.9906 的值对应的定点值将被截断到 127。
- 对于截断误差,可以使用更大的 scale。scale 一般是由量化工具使用统计方法得到,scale 偏小的原因是校准数据不够全,校准方法不对,导致 scale 统计的不合理。比如:某一输入的理论范围为 -1, 1,但校准或 qat 过程中,没有观测到最大值为 1 或最小值为 -1 的样本或观测到此类样本的次数太少。应该增加此类数据或者根据数值范围,手动设置固定 scale。在截断误差不大的情况下,可以调整校准参数,通过不同的校准方法和超参缓解截断误差。
因此,QAT 量化精度调优以减少上述两种误差为基本原则,下文将针对 QAT 每个阶段做调优介绍:
1.1 浮点训练 & 评测
一般情况下,QAT 精度调优以训练好的浮点模型作为初始条件,理想情况下,浮点模型的设计和迭代应充分考虑量化风险,主要包括 2 个方面:
- 在保持浮点精度的情况下,尽可能使用量化友好的结构和算子:特征提取部分尽可能使用 CNN 结构、尽量裁剪多余的 attention 和 elementwise(add/mul/sub 等)操作、激活函数首选 ReLU、bbox 回归和位置编码常用的 sigmoid/inverse_sigmoid 等的操作避免量化(从模型移除到前后处理)、使用可被 QAT 融合的结构例如 Conv+ 普通 BN2d+ReLU、模型尾部保持 TAE 算子(GEMM/Conv/Linear/Matmul)直接输出
- 调整浮点数据流和浮点训练策略,尽可能量化友好:输入数据做-1, 1的归一化、图像训练数据建议做 bgr->yuv420->yuv444 的处理感知部署时 nv12 输入数据的颜色损失、Conv/Linear 后多增加 BN 和 LN 约束数据范围、Concat 算子多输入前添加 BN 约束数据范围避免数值范围差异过大(Concat 算子会综合多输入的数据范围重新统计 scale,存在"大数吃小数"的风险)、INF/NAN 等特殊类型的数据替换为例如 100 或 -1、极大的数值(如 float64 的掩码值)根据物理意义做手动的截断、合理选择 weight_decay 避免 weight 数值分布不均或数值极小
此外还可以参考用户手册对应章节:【构建量化友好模型】
首先需要在浮点链路上完成训练和评测整体流程的打通,需要成功复现浮点模型的精度,一方面熟悉模型结构和评测流程,为接下来的量化调优做准备;另一方面避免浮点数据流的 bug 影响量化调优
此外有条件的情况下,建议对已有的浮点模型和权重做小 lr 的 fine-tune,lr 可以复用浮点最后一个 epoch 的配置,或者参考 QAT 建议选择浮点初始学习率的 1/10~1/20,来提前排除模型过拟合相关风险
浮点模型更多算子/结构优化建议可以参考【地平线 J6 工具链进阶教程】算子优化方案集锦(
developer.horizon.auto/blog/13133) .
1.2 模型改造
QAT 校准和 QAT 训练都依赖对浮点模型代码做一定的改造,主要为在模型首尾插入量化(QuantStub)和反量化(DeQuantStub)标识算子,以及添加量化精度配置的代码。这一部分从上手到实践建议参考用户手册标准流程和配置:
- QAT 快速入门
- QConfig 详解
- 新版 qconfig 配置教程:developer.horizon.auto/blog/13112
- Prepare 详解
2.1 常见问题
1.3 模型检查
完成模型改造和量化配置后,调用 Prepare 接口时会对模型做算子支持和量化配置上的检查,这些检查一定程度上反映了模型量化存在的问题。对于不支持的算子将以报错的形式提醒用户,一般有两种情况:
- 未正确进行模型的量化改造。Prepare 过程中 QAT 量化工具会对模型进行 trace 来获取完整的计算图,在这个过程中会完成算子替换等的优化,对于这些已替换的算子,输入输出类型如果是 torch.tensor 而非经过 QuantStub 转化后的 qtensor,则会触发不支持算子的报错,表现为 xxx is not implemented for QTensor;
- 确实存在不支持的算子。工具链已支持业界大量的常用算子,但对于部分非常见算子的不支持情况,需考虑进行算子替换并且作为算子需求向工具链团队导入。
Prepare 运行成功后会在当前目录下自动保存模型检查文件 model_check_result.txt 和 fx_graph.txt,建议参考下列解读顺序:
- 算子融合检查。算子融合作为 QAT 量化工具的标准优化手段,常见的融合组合为 Conv+ReLU+BN 和 Conv+Add 等,未融合的算子会在 txt 文件中给出,未按预期融合的算子可能是因为共享没有融合成功或者是 QAT 量化工具的融合逻辑变更(针对新版 qconfig 量化模板 enable_optimize=True 情况,见《【地平线 J6 工具链入门教程】QAT 新版 qconfig 量化模板使用教程》(developer.horizon.auto/blog/13112)...
Plain
# 示例:未融合的Conv+Add算子
Fusable modules are listed below:
name type
------------------------------------------------ --------------------------------------------------------------------------
model.view_transformation.input_proj.0.0(shared)
model.view_transformation._generated_add_0未融合的算子对模型性能会有一定影响,对于精度的影响需视量化敏感度具体分析,一般来说,Conv/Linear+ReLU+BN 未融合建议手动修改融合。
- 共享模块检查。一个 module 只有一组量化参数,多次使用将会共享同一组量化参数,多次数据分布差异较大时,会产生较大误差:
Plain
# 示例:该共享模块被调用8次
Each module called times:
name called times
--------------------------------------------------------------------------------------- --------------
...
model.map_head.sparse_head.decoder.gen_sineembed_for_position.div.reciprocal 8called times > 1 的模块可能有很多个,全部改写成非共享是一劳永逸的。对于修改简单且精度影响大的共享算子如 QuantStub,强烈建议取消共享;对于 DeQuantStub 算子,共享不会对模型精度产生影响,但是会影响 Debug 结果的分析,也建议取消共享,修改方式参考**"2.1 模型改造-常见问题"**。
例如下面的共享模块,量化表示的最大值为 128 * 0.0446799 ≈ 5.719,在第一次使用中,输出范围明显小于 -5.719, 5.719,误差较小, 第二次使用中,输出范围超出 -5.719, 5.719,数值被截断,产生了较大误差。两次数值范围的差异也造成了统计出的 scale 不准确,因此该共享模块必须修改
Plain
+------+-------------------------------------------------------------------------------+-----------------------------------------------------------------------------------+-----------------------------------------------------------------------------+--------------------------------+---------------+------------+------------------+-------------------+------------------+-------------------+
| | mod_name | base_op_type | analy_op_type | shape | quant_dtype | qscale | base_model_min | analy_model_min | base_model_max | analy_model_max |
|------+-------------------------------------------------------------------------------+-----------------------------------------------------------------------------------+-----------------------------------------------------------------------------+--------------------------------+---------------+------------+------------------+-------------------+------------------+-------------------+
...
| 1227 | model.map_head.sparse_head.decoder.gen_sineembed_for_position.div | horizon_plugin_pytorch.nn.div.Div | horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional.mul | torch.Size([1, 1600, 128]) | qint8 | 0.0446799 | 0.0002146 | 0.0000000 | 4.5935526 | 4.5567998 |
...
| 1520 | model.map_head.sparse_head.decoder.gen_sineembed_for_position.div | horizon_plugin_pytorch.nn.div.Div | horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional.mul | torch.Size([1, 1600, 128]) | qint8 | 0.0446799 | 0.0000000 | 0.0000000 | 6.2831225 | 5.7190272 |
...上面共享算子的修改方式可以参考:
Plain
class Model(nn.Module):
def __init__(self, ) -> None:
super().__init__()
...
self.steps = 2
for step in range(self.steps):
setattr(self, f'div{step}', FloatFunctional())
def forward(self, data):
...对于不带权重的 function 类算子都可以参考上面的拆分方式,但是也存在部分共享算子或模块带有权重参数拆分起来比较复杂,是否需要拆分建议先根据量化敏感度进行分析。带有权重参数算子拆分时需要复制权重,拆分方式可以参考:
Plain
class Model(nn.Module):
def __init__(self, ) -> None:
super().__init__()
...
self.steps = 2
self.conv0 = nn.Conv2d(...)
self.conv1 = nn.Conv2d(...)
self.conv1.weight = self.conv0.weight
self.conv1.bias = self.conv0.bias此外,未调用的模块也会在文件中体现,called times 为 0,当 Calibration/QAT/模型导出出现 miss_key 时,可以检查模型中是否有模块未被 trace。
- 量化配置检查。txt 文件中会给出模型量化精度的统计信息:
Plain
# 算子输入量化精度统计
input dtype statistics:
+----------------------------------------------------------------------------+-----------------+---------+----------+
| module type | torch.float32 | qint8 | qint16 |
|----------------------------------------------------------------------------+-----------------+---------+----------+
| | 290 | 15 | 0 |
| | 5 | 117 | 9 |
| | 0 | 8 | 0 |
...重点检查的信息有:
- 的 input dtype 应为 torch.float32,对于 qint8 或者 qint16 的 input dtype,一般是冗余的 QuantStub 算子可以改掉,不会对精度产生影响但可能会对部署模型性能有影响(算子数量)
- 如果没有配置浮点精度,模型中的算子不应出现 torch.float32 的输入精度,如上图的,需要检查是否漏插 QuantStub 未转定点,未转定点的算子在导出部署模型时会 cpu 计算从而影响模型性能。对于模型中的一些浮点常量 tensor,工具已支持自动插入 QuantStub 转定点,建议获取最新版本
- 对于 GEMM 类算子(Conv/Matmul/Linear)作为模型输出时支持高精度输出(征程 6E/M 支持 int32 输出),体现到这里则是的 input dtype 应为 torch.float32,对于 qint8 或 qint16 输入的 DeQuantStub 需要检查是否符合高精度输出的条件,符合条件但未高精度输出的需修改。此外对于下面左图的结构,也建议优化为右图结构来保证高精度输出的优化
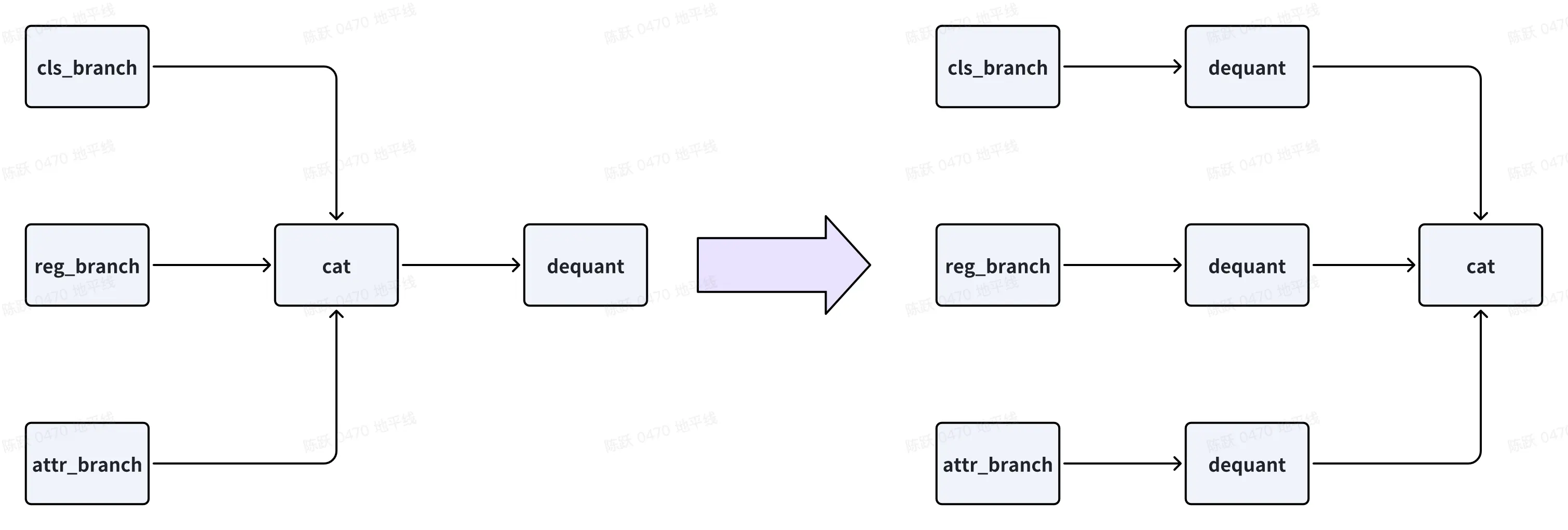
- qint8 和 qint16 算子的占比,可以协助判断是否配置全 int16 生效
txt 文件同时会给出逐层的量化配置信息:
Plain
# 激活逐层qconfig
Each layer out qconfig:
+---------------------------------------------+----------------------------------------------------------------------------+----------------------+-----------------+------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+
| Module Name | Module Type | Input dtype | out dtype | ch_axis | observer |
|---------------------------------------------+----------------------------------------------------------------------------+----------------------+-----------------+------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------|
# 固定scale
| quant | | [torch.float32] | ['qint16'] | -1 | FixedScaleObserver(scale=tensor([3.0518e-05], device='cuda:0'),zero_point=tensor([0], device='cuda:0')) |
# QAT训练激活scale更新
| mod2.1.attn.q | | ['qint16'] | ['qint16'] | -1 | MinMaxObserver(averaging_constant=0.01) |
# QAT训练激活scale不更新重点检查的信息有:
- 每层算子的输入输出 dtype、权重的 dtype,是否符合量化配置;若和量化配置不符合,比如配置了 int16,但是算子显示为 int8,则需要关注下算子回退信息,例如 Conv+Add 的融合,Conv 不支持 int16 输入则会导致前序算子的输出回退到 int8。新的 qconfig 量化配置模板下算子回退过程需查看 qconfig_changelogs.txt**,详细参考:developer.horizon.auto/blog/13112**
- 配置了 fix scale 的算子,是否正确显示 FixedScaleObserver 信息,scale 值是否正确
- 逐层算子的 observer 是否正确:权重默认 MinMaxObserver,QAT 校准时激活默认 MSEObserver,QAT 训练时激活默认 MinMaxObserver
- 若为 QAT 训练阶段且配置了固定校准的激活 scale,查看 averaging_constant,判断是否生效,生效为 averaging_constant=0(即不更新 scale),默认为 0.01(更新 scale)
对于 fx_graph.txt,可以从中获取到模型中 op/module 的上下游调用关系,例如当存在算子 called times 为 0 未被调用的情况,可以通过 Graph 定位到上下文算子从而定位未被调用的原因(通常因为存在逻辑判断或循环次数变化);此外当出现导出的部署模型(bc 模型)精度异常,也可以通过 Graph 信息来排查是否是导出计算图改变导致的。
Plain
# 模型Graph图结构信息
Graph:
opcode name target args kwargs
------------- --------------------------------------------- ------------------------------------------------------------------------ --------------------------------------------------------------------------------------------- -----------------------------
placeholder input_0 input_0 () {}
call_module quant quant (input_0,) {}
call_module traj_decoder_src_proj_0_0 traj_decoder_src_proj.0.0 (quant,) {}
call_function scope_end ('traj_decoder_src_proj.0',) {}
call_function __get__ (traj_decoder_src_proj_0_0,) {}
call_function __getitem__ (__get__, 0) {}重点关注的 Graph 信息:
- opcode 为算子调用类型
- name 为当前算子名称,需注意和 model_check_result.txt 中的 module.submodule 名称区别
- target 为算子输出
- args 为算子输入
1.4 QAT 校准
1.4.1 int8+int16 混合精度调优
QAT 校准是 QAT 精度调优流程中的一个关键环节,校准不涉及繁重的训练,只需要从训练集中选取分布均衡的校准数据校准就可以快速获取模型逐层的量化阈值。此外因为校准不改变模型的原始权重,可以帮助用户快速地排查影响精度的 QAT 链路问题,以及定位模型存在的量化参数配置问题。建议用户预估当前模型调优难度来选取合适的校准策略:
- 较易量化的模型:模型曾完成 QAT 并且当前仅迭代数据和权重、模型结构简单(例如以 CNN 结构为主的检测/分类模型)等。这一类模型可以选择全 int8 的量化精度进行校准,或者延用之前调优的混合精度(int8+int16)配置,具体的量化配置请参考"2。 模型改造"章节;
- 较难量化的模型:模型第一次适配 QAT、模型存在较大结构迭代、模型结构复杂(BEV 多任务、Transformer 结构、Sparse4D 等)。这一类模型可以选择全 int16 的量化精度进行校准,具体的量化配置请参考"2。 模型改造"章节。
对于全 int16 配置下的模型量化精度不达标或者很差,建议运行 QAT Debug 工具来进行量化敏感度分析,Debug 工具运行和产出物的分析方式请参考"4.2 Debug 产出物解读"章节,请结合 Debug 结果做精准分析,一般来说全 int16 下精度不达标的可能原因有:
- QAT 链路适配存在问题,模型在校准和评测下伪量化节点(fake_quant)和统计观测节点(observer)的状态异常、模型校准参数异常未更新等;
- 模型存在异常的数据,例如 INF 或者 NAN,这些值很大程度上影响量化效果,需进行修改;
- 模型部分层/模块有很大的截断误差,一方面可能由于校准数据选择到了极端的数据,无法获取合理的量化阈值;另一方面一些带有物理意义的数据(例如距离、速度),仅通过统计无法获取合适的量化阈值,需要在充分考虑应用场景下手动指定固定的量化阈值。
全 int16 配置下的模型通常性能无法满足部署要求,除了只看精度上限的场景,在完成全 int16 调优后,模型最终都要回到全 int8 和混合精度调优上,以期望得到一个部署精度和部署性能平衡的量化模型。
对于全 int8 或者混合精度配置下的模型,针对不同的精度表现采用不同的调优策略:
- 精度表现很差甚至无精度,且未尝试全 int16 调优,优先尝试全 int16 调优,参考前文;
- 精度表现距离浮点差距较大(量化精度/浮点精度 ,经验值),建议运行 QAT Debug 工具来进行量化敏感度分析,结合 Debug 结果做精准分析,一般的优化手段有:增加 int16 的配置、对有物理意义的数据手动指定固定的量化阈值。此外需注意 int16 算子的比例,int16 算子过多会影响部署性能,如果 int16 算子比例已超出部署预期,则可以考虑回退部分 int16 算子后尝试 QAT 训练
- 精度表现距离浮点差距较小(量化精度/浮点精度 > 90%,经验值),直接尝试 QAT 训练,在量化精度/浮点精度 >= 95%(经验值)的情况下,建议优先尝试固定校准激活 scale 的 QAT 训练(仅调整权重感知量化误差)
对于不同精度配置下的 QAT 校准,都有一些校准超参可以调整,需要用户结合具体模型去做调参优化,其中主要的参数有校准数据的 batch size、校准的 steps,详细的参数参考:
总结
int8+int16 混合精度调优的重点应放在全 int16 调优,这里需要把使用问题,量化不友好模块等等各种千奇百怪的问题都解决,务必要把全 int16 的精度调优做扎实,看到模型的精度上限,然后根据模型部署的性能要求进行 int8 和 int16 混合精度的调优,达成部署精度和部署性能的平衡。
1.4.2 Debug 产出物解读
Debug 工具比对的对象是 QAT 校准模型和浮点模型,由于模型权重在 QAT 训练过程中已经发生了改变,不建议对比 QAT 训练后的模型和浮点模型。工具使用和运行请参考:【手册引用:docs.oe.horizon.auto/guide/plugi...】,整个过程是工具自动在传入的数据集中查找 badcase 或者用户手动设置 badcase -> 运行 badcase -> 逐层比较 -> 计算敏感度。
工具运行完成后会在指定目录下生成如下一些关键的文件,按照用到的文件重要性和使用频率分成:
P0-调优重点参考
P1-调优辅助分析
P2-用户不必关注,需要时可提供研发分析
Plain
floatvscalib
├── abnormal_layer_advisor.txt # P1,异常层信息和修改建议:异常的数值范围和异常scale等
├── ...
├── analysis_model # QAT校准模型
│ ├── op_infos # P2,保存的逐层输出/权重值
│ ├── statistic.csv
│ └── statistic.txt # P1,逐层统计量
├── ...
├── baseline_model # 浮点模型
│ ├── op_infos建议分析流程为:
- 结合模型精度情况,找到和掉点精度相关的输出敏感度文件,举个例子,量化后模型 3D 检测框的朝向误差大,精度低,则找到 rot/angle 输出对应的敏感度文件 pt 和 txt。如果相关输出较多,则需要综合分析
- 分析敏感度 txt 文件
Plain
# 示例:量化敏感度
op_name sensitive_type op_type L1 quant_dtype flops
----------------------------------------------------- ---------------- -------------------------------------------------------------------------- --------- ------------- -----------------
head.head.reg_convs_list.1.1.0.0 activation 0.363303 qint8 13271040(0.07%)
backbone.mod1.0 activation 0.308664 qint8 79626240(0.41%)
backbone.mod2.0.head_layer.conv.1.0 activation 0.226762 qint8 188743680(0.97%)总结
- Debug 工具会提供逐层的误差衡量指标,但最终的调优目标仍是模型整体精度,而非单算子或单层误差指标,原因是部分算子对量化误差并不敏感(如 sigmoid 和 softmax 等)且模型整体具有噪声鲁棒性和泛化性;
- 优先查看敏感度(与精度掉点相关的输出),看完敏感度再看逐层比较。确定某一算子敏感后,先通过逐层比较或统计量确认造成的误差是舍入误差还是截断误差,然后再针对性地调整量化配置或修改模型结构。
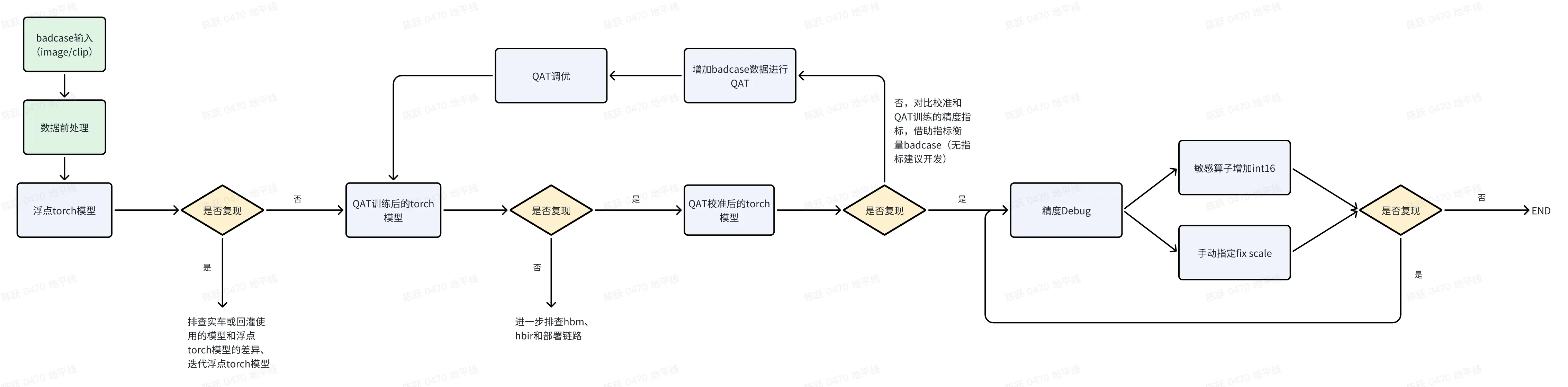
1.4.2.1 Badcase 调优
对于实车或回灌反馈的可视化 badcase,利用 Debug 工具的调优流程为:
1.5 QAT 训练
大部分模型仅通过 QAT 校准就可以获得较好的量化精度,对于部分较难调优的模型,以及还需要继续优化误差类指标的模型,通常校准设置的高精度比例导致延时超过部署上限,但精度仍无法达标,这种情况可以尝试 QAT 训练来获得满足预期性能-精度平衡的量化模型。
根据前文所述,在 QAT 校准量化精度/浮点精度 >= 95%(经验值)的情况下,充分利用校准阶段较好的激活量化参数,优先尝试固定校准激活 scale 的 QAT 训练(仅调整权重感知量化误差),设置方式具体参考**"模型改造-QConfig 详解"**
参考浮点训练,QAT 训练在大部分配置保持和浮点训练一致的基础上,也涉及到部分超参的调整来提升量化训练的精度,例如 QAT 的学习率、weight_decay、迭代次数等,详细的参数调整策略参考:
浮点和 QAT 训练中都涉及到对 BN 的状态控制,在浮点训练中可能会采用 FreezeBN fine-tune 的方式来提升模型精度,在多任务训练中也会采用 FreezeBN 的技巧。因此在 QAT 训练中,提供了 FuseBN 和 WithBN 两种训练方式:
- FuseBN 即在 Prepare 后,QAT 训练前将 BN 的 weight 和 bias 吸收到 Conv 的 weight 和 bias 中,在训练过程中不再单独更新,这一吸收过程是无损的。FuseBN 也是 QAT 默认的训练方式。
- WithBN 则是在 QAT 训练阶段保持 Conv+BN 不融合,带着 BN 进行训练,BN 的参数单独更新,在训练结束后转成部署模型时再做融合。浮点训练阶段如果采用了 FreezeBN 的训练方式,QAT 训练时需设置 WithBN,设置方式如下:
Plain
from horizon_plugin_pytorch.qat_mode import QATMode, set_qat_mode
set_qat_mode(QATMode.WithBN)通过观察 QAT 训练过程的 Loss 变化来初步判断 QAT 训练的量化效果,一般来说和浮点最后的 Loss 结果越接近越好,Loss 过大可能难以收敛,Loss 过小可能影响泛化性,对于异常的 Loss 建议的优化手段:
- 异常 INF 和 NAN 的 Loss 值,或者初始 Loss 极大且无收敛迹象,按如下顺序排查: 1. 2. 去掉 prepare 模型的步骤,用 qat pipeline finetune 浮点模型,排除训练 pipeline 的问题,Loss 如果仍异常,需要检查训练链路的配置如优化器 optimizer 和 lr_updater 等 3. 保持当前 QAT 训练配置,只关闭伪量化节点后观察训练的 Loss 现象,理论上和浮点无差异
Plain
from horizon_plugin_pytorch.quantization import set_fake_quantize, FakeQuantState
...
set_fake_quantize(qat_model, FakeQuantState._FLOAT)
train(qat_model, qat_dataloader)- 在排查完链路问题后出现初始 Loss 较大,有收敛迹象但收敛较慢,这种情况可以尝试调整学习率,延长 QAT 迭代次数,因为 QAT 训练本质上是对已收敛浮点模型的 fine-tune,本身存在一定的随机性,用较大的学习率可以快速波动到一个理想精度(依赖一些中间权重的评测)
- 对于少数模型,QAT 训练以及尝试了多次超参调整后精度仍无法达标,建议回归 QAT 校准阶段增加少量高精度算子(int16 或者尝试对 Layernorm 层配置少量 fp16 高精度)、回归浮点结构检查是否还存在量化不友好的结构如使用了大量 GeLU 等(参考"浮点训练 & 评测")
1.5.1 QAT 训练效率
由于 QAT 训练过程需要感知模型量化所带来的损失,因此模型中会被插入必要的量化相关的节点:数据观测节点 Observer 和伪量化节点 FakeQuant。数据观测节点会不断统计模型中数据的数值范围,伪量化节点会根据量化公式对数据做模拟量化和反量化,两者都会存在开销,此外就是 QAT 工具内部会对部分算子例如 LN 层做拆分算子的实现,因此相同配置下的 QAT 训练效率是会略低于浮点训练效率,具体还和模型参数规模、算子数量等有关。
对于用户可明显感知到的 QAT 训练效率降低,建议的优化手段有:
- 使用 QAT 工具提供的算子,这些算子优化了训练效率,例如 MultiScaleDeformableAttention(参考手册:MultiScaleDeformableAttention )
- 更新到最新的 horizon-plugin-pytorch 版本,新版本会有持续的 bug fix 和新特性优化,如模型中某些结构或者算子训练耗时增加明显,可以向工具链团队导入
1.6 模型导出部署
完成 QAT 精度调优后得到的模型仍是 PyTorch 模型,需要使用简单易用的接口来一步步导出编译成部署模型:
PyTorch 模型 -> export -> convert-> compile
export 得到 qat.bc;
convert 得到 quantized.bc;
compile 得到 hbm
由于导出生成物中计算差异的存在,对于每个生成物需简单验证其精度,可通过单张可视化或 mini 数据集,过程中如存在精度掉点,请参考后续一致性问题定位与解决的文章。
二、 征程 6E/M 调优案例集锦:
2.1 RT-DETR:
开源算法 QAT 调优流程示例,repo:github.com/lyuwenyu/RT...
2.1.1 浮点复现
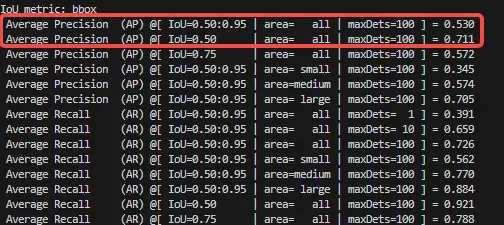
浮点公版精度:
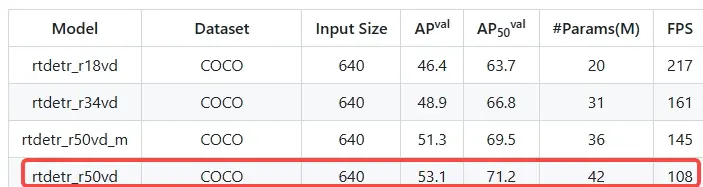
浮点复现精度(一致):
2.1.2 浮点模型改造 & Prepare
QAT 选择建议的 JIT_STRIP 模式,因此浮点改造只需插入 QuantStub/DeQuantStub,其次就是明确模型量化部署范围,一个快速的方式是参考公版 export_onnx 脚本
Plain
class Model(nn.Module):
def __init__(self, ) -> None:
super().__init__()
self.model = cfg.model.deploy()
self.postprocessor = cfg.postprocessor.deploy()
def forward(self, images, orig_target_sizes):
outputs = self.model(images)
outputs = self.postprocessor(outputs, orig_target_sizes) # 无需部署
return outputs对浮点模型进行 QAT 校准阶段的 prepare
Plain
cfg.model.load_state_dict(checkpoint, strict=True) # 先加载浮点权重
class Model(nn.Module):
def __init__(self, ) -> None:
super().__init__()
self.quant = QuantStub()
self.model = cfg.model
def forward(self, images):
images = self.quant(images) # 对输入插入QuantStub
outputs = self.model(images)2.1.3 分析 model_check_result
在默认全 int16 模板下分析 model_check_result 信息,检查模型不合理结构:
- 取消 Bbox head 的 relu 复用:src/zoo/rtdetr/rtdetr_decoder.py
无权重的简单算子复用,建议改掉;对于带权重的算子或整个 module 复用,视敏感度列表酌情改

- encoder 输入的 pos_embed 需要手动量化:src/zoo/rtdetr/hybrid_encoder.py
model_check_result 会提示存在 mix precision input 信息

- decoder 输入的 anchors 需要手动量化:src/zoo/rtdetr/rtdetr_decoder.py
model_check_result 会提示存在 mix precision input 信息
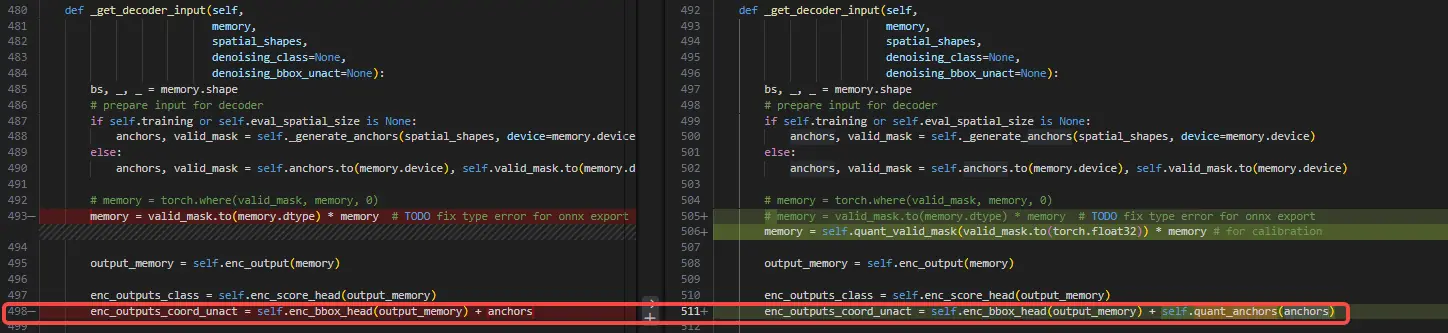
- 替换 backbone 自定义的 FrozenBatchNorm2d 为 nn.BatchNorm2d(否则不会和 conv 融合且出现单独的 mul 和 add):configs/rtdetr/include/rtdetr_r50vd.yml
BN 没有融合,model_check_result 会提示存在 mix precision input 信息

2.1.4 Calibration
开始 Calibration 前先导出部署模型,验证算子后端和模型性能,见**"1.5 部署导出"**。该模型仅通过 Calibration 就可以获得较好的量化精度
全 int16
小成本 bs 16,10 steps 校准下模型精度为 0:
- 首先排查链路问题,取消伪量化后精度和浮点一致,排除链路问题
Plain
calib_checkpoint = torch.load(os.path.join("checkpoints", f"calib-checkpoint-{args.steps}.ckpt"), map_location=args.device)
calib_model.load_state_dict(calib_checkpoint, strict=True)
# set_fake_quantize(calib_model, FakeQuantState.VALIDATION)
set_fake_quantize(calib_model, FakeQuantState._FLOAT)
evaluate_calib(calib_model.to(torch.device(args.device)), cfg, args, val_dataloader)- 适配 Debug 工具,分析敏感算子
A. encoder 输入的 pos_embed 需要手动量化:src/zoo/rtdetr/hybrid_encoder.py
值域-1, 1,给定 fix_scale,统计量也可反映

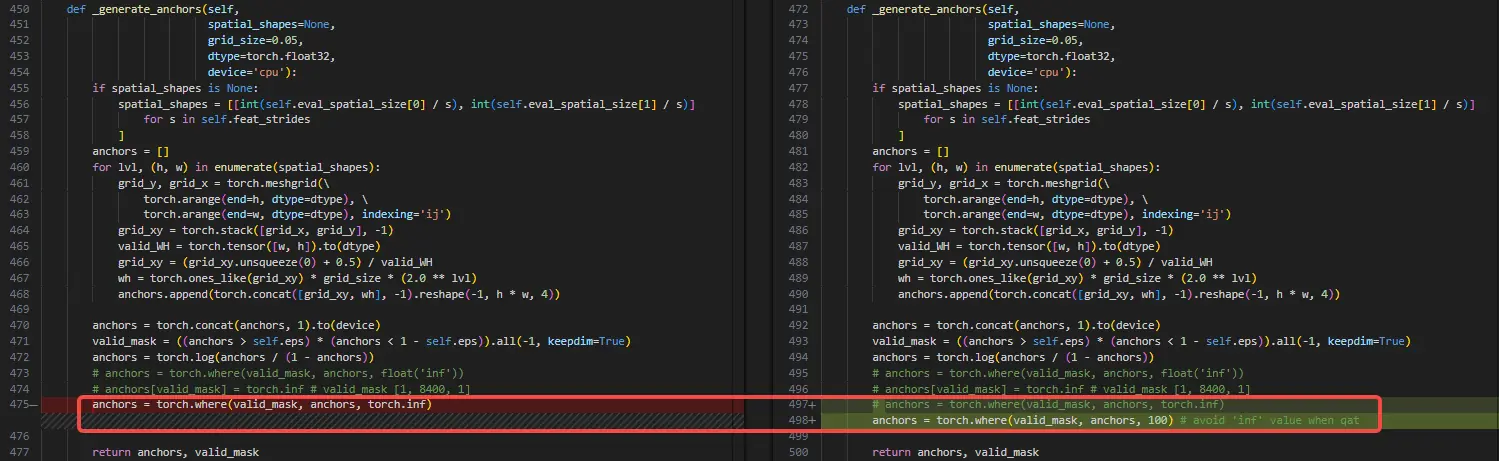
B. decoder 输入的 anchors 需要手动量化(anchors 前处理放在模型外):src/zoo/rtdetr/rtdetr_decoder.py
避免 anchors 计算中的 inf 值,mask 掉的无效锚点替换 inf 为 100:
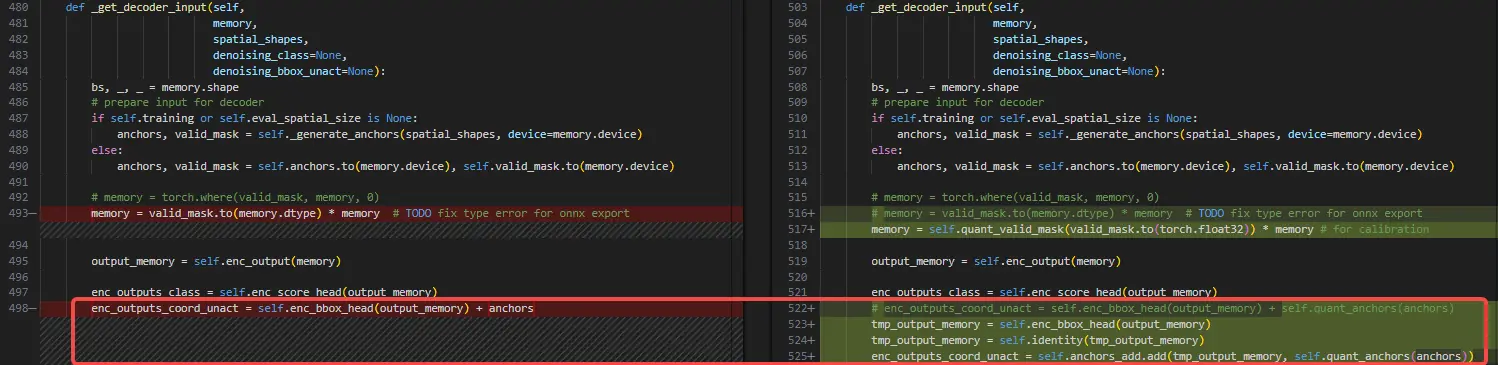
同时指定 quant_anchors 和 anchors_add 为 int16 的 fix_scale(需要通过插入 identity 解决 Conv+Add 结构回退 int8):
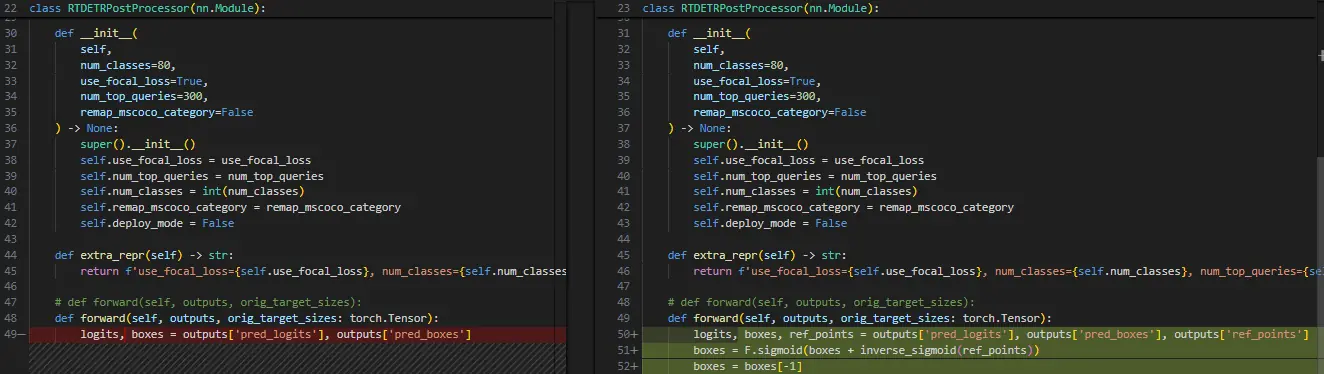
C. bbox 输出的 sigmoid 相关操作放到后处理(linear 层高精度输出),进行精度 debug 时带上:src/zoo/rtdetr/rtdetr_decoder.py
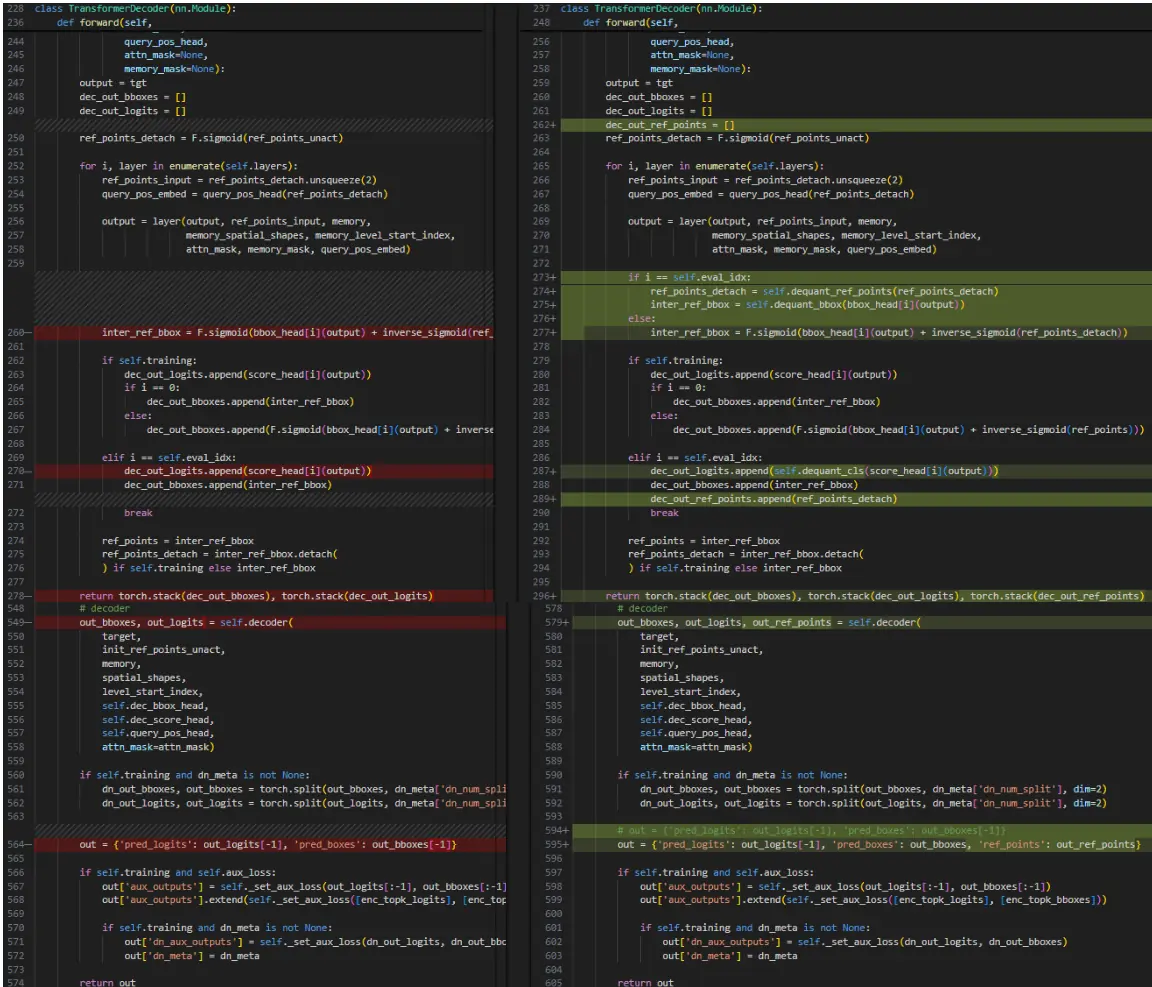
src/zoo/rtdetr/rtdetr_postprocessor.py
D. 将敏感度 top2 的 model.backbone.conv1.conv1_1.conv 和 model.backbone.conv1.conv1_2.conv 由激活 int16 改为权重 int16,指标有微小提升,进一步可修改为权重激活双 int16

全 int16 量化配置:
Plain
module_name_qconfig = {
"quant": QConfig(
output=FakeQuantize.with_args(
observer=FixedScaleObserver,
dtype=qint8,
scale=1 / QINT8_MAX,
)
),
"model.backbone.conv1.conv1_1.conv": QConfig(
weight=FakeQuantize.with_args(混合精度
基于全 int16 配置,仅将全 int16 模板改为全 int8 模板,精度为 0,通过 Debug 工具继续分析敏感度算子,将新增的敏感算子配置 int16,最简混合精度量化配置:
Plain
module_name_qconfig = {
"quant": QConfig(
output=FakeQuantize.with_args(
observer=FixedScaleObserver,
dtype=qint8,
scale=1 / QINT8_MAX,
)
),
"model.backbone.conv1.conv1_1.conv": QConfig(
weight=FakeQuantize.with_args(2.1.5 部署导出
提前导出验证发现模型存在 cast、linear、mul、topk 算子在 cpu 上,修改 src/zoo/rtdetr/rtdetr_decoder.py:
- bool 类型 tensor 转浮点并量化

- topk 后的 int64 索引接 gather,需手动 cast

修改后算子统计如下(topk 可以被 bpu 吸收、qdq 可删除):
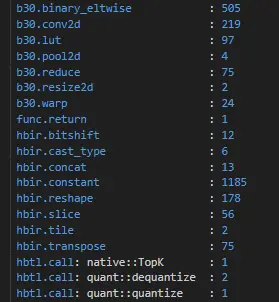
2.2 静态感知模型:
2.2.1 车道线弯折和偏移
Calibration 和 QAT 均出现车道线可视化弯折现象,浮点无此现象,且现有量化指标良好无法反映此现象

2.1.1 Badcase 调优
Step1:定位 Calibration 阶段复现问题,出问题的可视化直接跑 Debug 工具,对应修改
- 使用精度上限双 int16 模板
- decoder 中 linear 层改写 wx+b 实现权重 int16(在 OE 3.5.0 以及之后版本已直接支持配置权重 int16)
- head 中 mul 和 sum 使用 fix_scale
解决弯折问题,出现新问题:车道线横向偏移
Step2: QAT 训练解决车道线横向偏移过程中重新出现弯折问题,对 QAT 模型分段量化定位到辅助头量化引入较大量化误差,取消辅助头量化后同时解决车道线弯折和横向偏移问题
Step3:量化精度风险点解除,根据性能要求进行回退
- 量化精度上回退 int16 比例
- 结构上回退回原 linear 层
2.2.1.2 总结
- 精度 debug 工具,定位到敏感算子,高精度无法解决的问题,往往需要对敏感算子进行 fix_scale 配置或者改写调整
- 对于实际部署没有使用的结构,量化上需要谨慎(例如此案例的辅助头);算子选择上,选择 BPU 支持的算子以保证模型可导出部署
- 针对 Badcase 现象,设计增加评价指标
2.2.2 车道线朝向
2.2.2.1 量化问题 & 经验
- MapTR 出现全 int16 calib+qat 下,map angle dist 指标不达标
- Debug 工具查看量化敏感度,weight 和激活同时需要 int16 量化,在 OE 3.5.0 以及之后版本已支持
- MapTR 出现 qat map angle dist 指标差,同时存在车道线抖动问题
- 优先排查特殊算子,例如存在浮点 CU