一句话总结
RL 训练 policy model 的同时让他写评分准则,效果比 GPT-4 还好
- 论文标题: EvoLM: Self-Evolving Language Models through Co-Evolved Discriminative Rubrics
- 论文地址 : https://arxiv.org/pdf/2605.03871
- 作者背景: 华盛顿大学、艾伦人工智能研究院、宾夕法尼亚大学
- 代码地址 : https://github.com/stellalisy/EvoLM
- 模型地址 : https://huggingface.co/stellalisy/EvoLM-8B
一、动机
1.1 从模仿者到探索者
强化学习已经成为大模型后训练的必修课------从 GPT 系列到 Claude、再到 DeepSeek,最后那一刀打磨基本都是 RL 干的。它不可替代的价值在于:SFT 只能"照葫芦画瓢",能力上限被标注数据死死锁住;RL 用奖励信号"指点"模型自己去探索,可以做出比标注更好的回答,从而突破训练数据的天花板,这是 SFT 永远做不到的
1.2 瓶颈是奖励信号
实际跑过 RL 训练的人都知道,这玩意比 SFT 难训得多 ------ 卡得最死的不是模型架构,而是奖励信号本身。RL 的灵魂是奖励,你给模型什么奖励,它就朝什么方向进化,奖励信号的质量直接决定 policy 能学到的上限
所有目前能用的奖励来源,都各自卡在一个绕不过去的天花板上:
| 奖励来源 | 问题 |
|---|---|
| 人类偏好标注 | 能力上限被标注员锁死,模型超过标注员就抓瞎;成本高昂 |
| 闭源 LLM-as-judge | API 涨价 / 改版 / 拒答直接影响训练 |
| 可验证奖励 | 信号最干净但只能用在有 ground truth 的任务,开放写作、共情对话完全失效 |
| Bradley-Terry RM | 评分标准被压缩进权重黑箱,不可解释,最容易被 reward hacking |
四种方法都默认了一个共同假设:奖励必须从模型外部拿,要有一个比模型自己更强的"外部裁判"。EvoLM 正是要打破这个假设
1.3 过往尝试
让模型自我评估这件事其实之前就有不少尝试,但效果都一般:
| 方法 | 自评估方式 | 致命缺陷 |
|---|---|---|
| Self-Rewarding | 模型当 judge,迭代 DPO | 评分 prompt 是固定的,跟不上 policy 的进化 |
| SPIN | 区分自己生成 vs 人类参考 | 本质上还是要外部参考数据 |
| Meta-Rewarding | 加 meta-judge 评估自己的判断 | 评分标准仍然是隐式、固定的 |
共同问题:评分标准本身没有跟着模型一起学。这个空白正是 EvoLM 抓住的,它把评分标准本身做成可学习对象、跟着 policy 一起进化
EvoLM 的底气来自一个被严重忽视的事实:预训练阶段模型已经读过海量论文、课本、code review,脑子里早就编码了大量 "什么算好、什么算差" 的判断知识。RL 不是在教模型评估,而是在把这部分隐含知识激活、结构化、并加以利用
二、实现方案
2.1 把评估拆成 rubric + judge
EvoLM 第一个关键设计是把 "评估" 这件事拆成两个独立步骤:
- Rubric 生成器 ρ_φ:给定问题 q,生成自然语言评分标准 r。例如 "答案应该等于 144"、"段落数恰好为 3"、"必须列出至少 3 个反例"
- 评分器 J:给定 (q, r, a),输出 s = J(q, r, a) ∈ 0, 1,这个分数即奖励
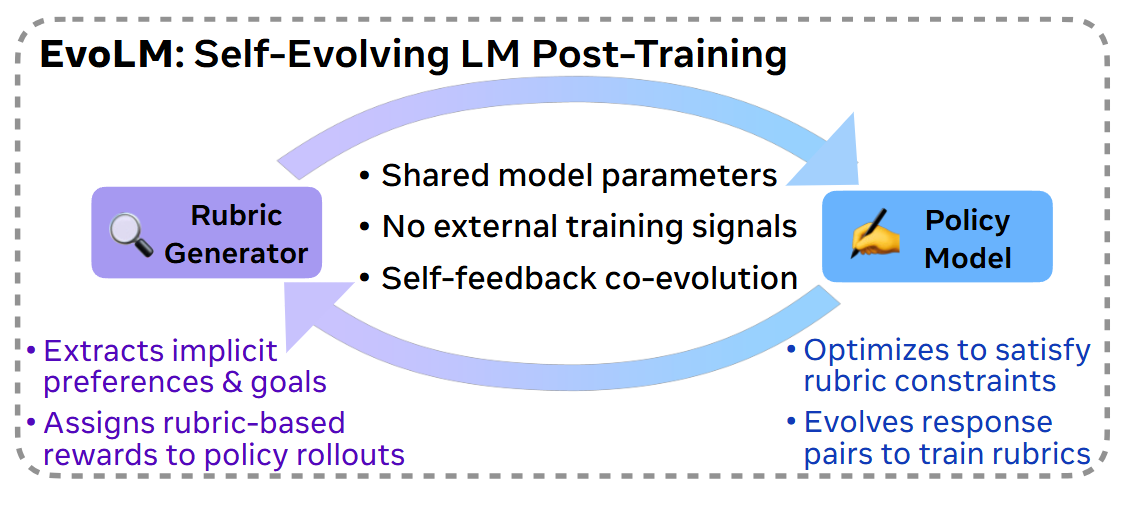
这套拆解的好处是显而易见的,rubric 是自然语言,人能直接看懂模型在考核什么(可解释);rubric 生成器与评分器解耦,更换评分器不用重训(模块化);而且只要 rubric 写得足够具体,哪怕请一个能力很弱的评分器也能完成任务(评估能力外包)
2.2 rubric 质量量化
拆完之后核心问题就来了:什么算 "好的 rubric" ?以前评 rubric 必须有 ground truth,主观且难以量化。EvoLM 给出一个直接可测量的定义:
一份 rubric 是好的,当且仅当 judge 用这份 rubric 打分时,能把好回答 a+ 打高分、差回答 a- 打低分,二者的判分差距越大,rubric 就越好
形式化为 rubric 的奖励函数:
R ( r ; q , a + , a − ) = J ( q , r , a + ) − J ( q , r , a − ) R(r;\, q, a^+, a^-) = J(q, r, a^+) - J(q, r, a^-) R(r;q,a+,a−)=J(q,r,a+)−J(q,r,a−)
整个 rubric generator 训练就转化为一个标准 RL 问题:用 policy gradient 优化 φ,让 rubric 最大化判分边际
这套奖励设计的思路其实跟 DPO 是一脉相承的:给定 "A 比 B 好" 这种偏好对,本质上是在做一件事:反向工程出那个能解释偏好的"评分标准"。DPO 的洞察是 "从偏好里反推出一个隐含的标量奖励",而 EvoLM 则是反推出一段自然语言写的 rubric
一个标量 0.85 只能告诉你 "这回答还行",但一段 rubric "答案应等于 144、必须列出 3 个反例、不能出现 obsolete 这个词" 能告诉你好在哪、差在哪、怎么改。表达力完全不在一个层面
此外,光优化上述 "判分差距" 还不够。RL 时模型会想尽办法钻奖励的空子,比如尝试无意义规则、把权重故意写得很怪等,所以还需要格式奖励:
- rubric 是不是合法 JSON
- 至少包含 2 条 criterion
- 权重和约等于 1
最终奖励为两项加权:R = 0.7 × 判分差距 + 0.3 × 格式合规
2.3 交替训练
policy 和 rubric 生成器需要协同进化,而不是顺序训练:
把 judge 冻结是作者故意的对照设计:锁死 judge 后,所有训练信号的改善都只能归因于 rubric generator 在变好,严格隔离了变量
评分器全程冻结(确保所有改善都只归因于policy 和 rubric 生成器的进化),每 50 步切换一次:
- 冻结 ρ_φ,policy 用当前 rubric 给的奖励做优化
- 冻结新的 π_θ,从 policy 最新输出构造偏好对,ρ_φ 学着写更具区分度的 rubric
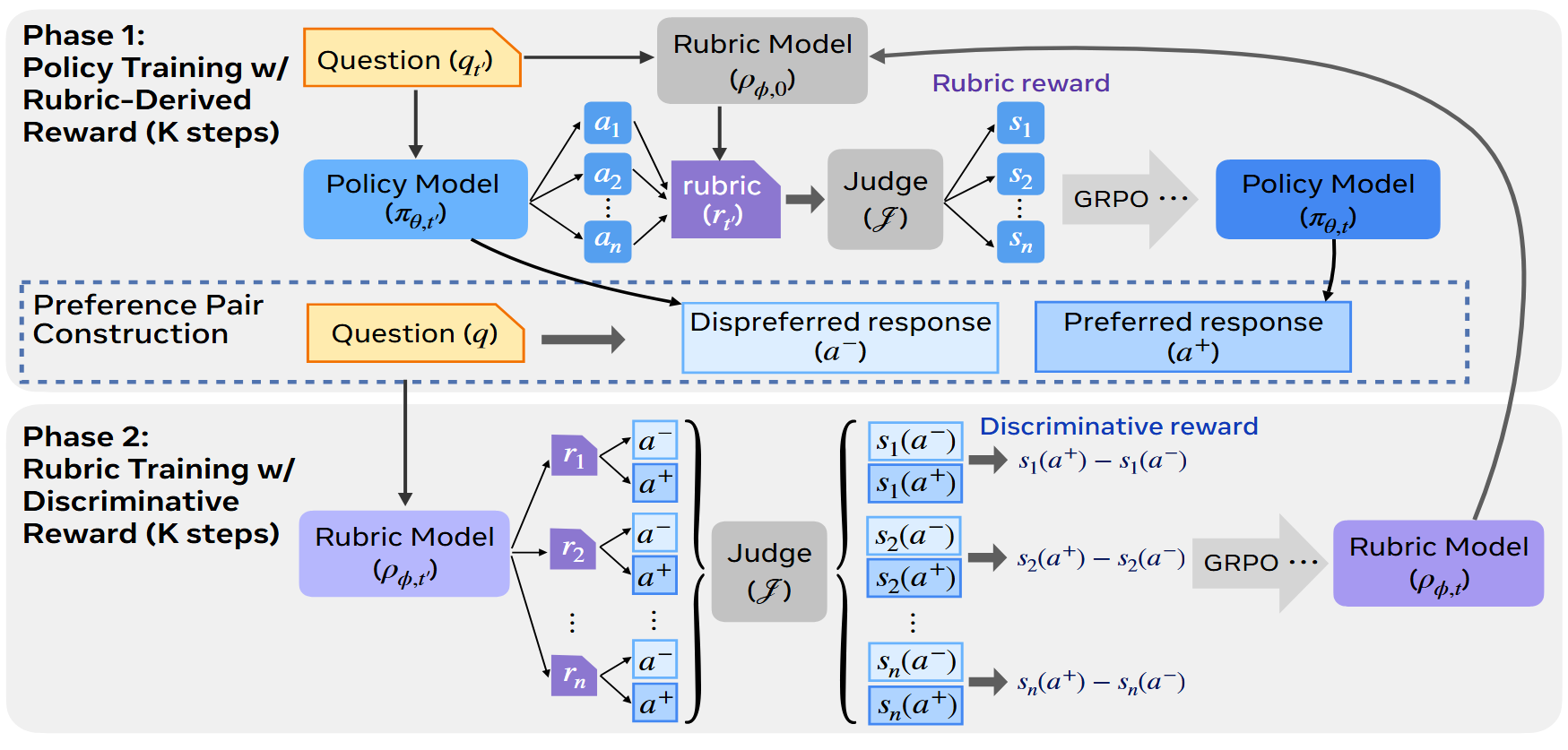
policy 进步后,旧 rubric 就开始打不出差距,迫使 rubric 变得更精细才能继续区分 "好里面更好" 和 "差里面较差";更精细的 rubric 又给 policy 更锐利的训练信号,形成正反馈飞轮
2.4 偏好构造
Rubric 训练需要 (a+, a-) 对作为监督。EvoLM 完全从 policy 自身输出构造,具体提出了三种方法:
-
Temporal Contrast(时序对比)
思路 :在当前训练步 t 与更早的步 t' 上分别从 policy 采样一次,用 "较新的一步" 产出的回答作 a+、"较早一步"的作 a-
目的:若训练整体有效,通常应有 "新的好于旧的",期望 rubric 能否把这种进步判出来 -
Inferred Question(IQ,推断问题)
思路 :先固定一条偏好的回答 a+,让 policy 倒推它像是在回答哪个问题,再对这个问题采样一条回答作为a-,制造 "答案没错但题不对" 的错配
目的:看 rubric 能否识别答非所问 -
Rubric-Conditioned(RC,条件于 rubric)
思路 :a+ 在问题 + rubric 条件下由 policy 生成,a- 只在问题 条件下生成,对照 rubric 是否真的提供了有用的生成条件。
测什么:看 rubric 的内容是否有指导价值,是否真能让回答编号
三、实验结果
3.1 主结果
主战场 OLMo3-Adapt 12 个 benchmark,涵盖数学、代码、推理、知识、指令跟随、开放生成。所有对照组其实都在做同一件事:RL 训练 policy,差别只在 "奖励信号从哪来",总共有以下三类对照组:
-
提示型 rubric:不训练 rubric 生成器,直接用 prompt 让 GPT-4(闭源 LLM)或 Qwen3-8B(开源 SLM) 在每条 query 上写一段 rubric,再交给固定 judge 打分作 reward,整个流程中只有 policy 在更新
-
标量奖励模型:跳过 rubric 这一环,沿用传统 RLHF 路子 ------ 奖励信号直接来自一个在海量人类偏好数据上预训练好的标量打分器,每个回答输出一个数字当 reward
-
基于评分标准的 RL:作者还对比了近期发表的四个同主题工作(RaR、RRD、RLCER、Rubric-ARM),都是用 rubric 当 reward 训 policy,是真正的同行对手
RaR、RRD 走 "蒸馏 / 在线调用 GPT-4 写 rubric" 路线,把上游问题甩给了闭源 API;RLCER 不调 API,但需要外部 verifier 帮忙校对答案;Rubric-ARM 需要现成的人工偏好标注数据。
测试结果如下,可见除了 EvoLM 以外,其他方法或多或少都得借外部信号:要么调 GPT-4 API、要么用预训练好的 RM、要么靠外部 verifier、要么吃人工标注
| 方法 | 是否依赖外部强模型 | OLMo3-Adapt 平均分 |
|---|---|---|
| GPT-4 prompted rubric | ✓ | 66.7 |
| Qwen3-8B prompted rubric | ✗ | 67.5 |
| SkyWork-RM-V2(scalar) | ✗ 但需预训练 | 59.7 |
| RaR | ✓ 依赖 GPT-4 | 67.5 |
| RRD | ✓ 依赖 GPT-4 | 67.6 |
| RLCER | ✗ 但需 verifier | 66.7 |
| Rubric-ARM | ✗ 但需 preference labels | 67.5 |
| Sequential(IQ + RC,先训 rubric 再训 policy) | ✗ | 68.3 |
| EvoLM(co-evolving) | ✗ 完全自举 | 69.3 |
而 EvoLM 在零外部 API、零外部标注、零外部 verifier 的条件下做到第一,比直接 prompt GPT-4 的方案高 2.6%
代码任务尤其惊艳:HumanEval+ 86.2%,超过次优方法 5.7%,这是因为细粒度 rubric 在代码任务上提供的判分信号最锐利
倒数第二行是 EvoLM 不做交替训练的版本,结果次优,证实了交替训练的价值
3.2 反直觉发现:评分更准的 RM 训出更弱的 policy
最值得细品的一个对比:
| 方法 | RewardBench-2 | JudgeBench | OLMo3-Adapt 平均 |
|---|---|---|---|
| SkyWork-RM-V2 | 86.4(榜首) | 80.8(榜首) | 59.7(垫底) |
| EvoLM | 46.0 | 44.4 | 69.3(榜首) |
| 两者差距 | SkyWork +40.4 | SkyWork +36.4 | EvoLM +9.6 |
SkyWork 在 reward 准确度上是绝对霸主,但训出来的 policy 反而最差。这是经典的 reward overoptimization:静态打分器一旦锁死,policy 就会找漏洞批量生产"看似拿高分实则跑偏"的回答。
EvoLM 的 co-evolving 之所以不会陷入这个陷阱,正是因为 rubric 每 50 步都重新看一遍 policy 当前的输出分布:policy 一旦开始走偏,rubric 立刻能更新评分细则把那种刷分回答堵死------把 reward 变成一个"看着 policy 走的活物",policy 钻空子的边际成本被推到无穷大
这个发现对生产环境的 reward 系统设计有强启发 ------ 任何静态的奖励信号,只要时间够长 policy 一定能找到漏洞钻进去;让 reward 跟着 policy 协同进化,是反 reward hacking 的钥匙
3.3 机制分析
最精彩的定性发现来自一道初中题:矩形周长 48,求最大可能面积(答案是正方形,144)
- Prompted Qwen3-8B:
| 权重 | 准则 |
|---|---|
| 0.20 | 正确应用周长公式关联长宽 |
| 0.20 | 正确把面积表达为单变量函数 |
| 0.20 | 正确使用方法求最大面积(配方/求导) |
| 0.20 | 正确算出最大面积 |
| 0.20 | 解释为什么正方形面积最大 |
- EvoLM:
| 权重 | 准则 |
|---|---|
| 0.80 | 答案是正确的最大面积 144,由给定的周长 48 推导得出 |
| 0.15 | 正确使用周长和面积公式 |
| 0.05 | 提供合理的解题步骤 |
二者存在质的差异:
- 原始 rubric 要求 judge 必须自己懂数学才能判断 "求最大值方法是否正确",这对一个 1.7B 的小 judge 几乎不可能
- 训练后的 rubric 把 "评估证明严谨性" 这个高难度判断,降维成"答案是不是包含 144" 这个低难度模式匹配
aggregate 统计 (100 道评估题) 证实这是普遍趋势:
| 指标 | 训练前(prompted) | 训练后(EvoLM) | 变化 |
|---|---|---|---|
| 纯标签型 criteria(空泛标准如"清晰") | 21.9% | 0.3% | 几乎根除 |
| 嵌入具体期望值的 criteria | 6.9% | 19.3% | ↑ 2.8× |
| 平均单条 criterion 长度 | 59 字符 | 112 字符 | ↑ 90% |
高质量的评估,往往就是把所需要的领域知识,提前内化进评分细则,让低质量评判者也能可靠操作
3.4 泛化性
冻结 EvoLM 训出来的 rubric generator,换不同的 judge 测 RewardBench-2:
| Inference Judge | Prompted rubric | EvoLM rubric | 提升 |
|---|---|---|---|
| Qwen3-1.7B(训练用) | 26.2 | 46.0 | +19.8 |
| Qwen3-8B | 39.7 | 62.4 | +22.7 |
| OLMo-3-7B-Instruct | 40.5 | 43.9 | +3.4 |
| Mistral-7B(JudgeBench) | 22.2 | 35.8 | +13.6 |
用更大的 Qwen3-8B 当 judge,RB2 直接从 39.7% 暴涨到 62.4%,说明训练好的 rubric 把评估结构编码进去了,更强的 judge 能挖出更多价值
冻结 rubric generator 训不同 policy,各方案在 OLMo3-Adapt 上的平均分:
| Policy | GPT-4 rubric | EvoLM rubric | 提升 |
|---|---|---|---|
| Qwen3-4B | 64.4 | 65.2 | +0.8 |
| Llama-3.1-8B | 45.7 | 46.9 | +1.2 |
最让人惊艳的部分是领域泛化能力。在通用数据 Tulu-3 上训练的 rubric generator,扔到完全没见过的医疗与深度研究领域:
| Benchmark | EvoLM rubric | GPT-4 rubric | 差距 |
|---|---|---|---|
| HealthBench Acc | 58.4 | 52.5 | +5.9 |
| HealthBench Acc@0.1 | 59.0 | 53.6 | +5.4 |
| ResearchQA Acc | 59.3 | 51.0 | +8.3 |
| ResearchQA Acc@0.05 | 68.7 | 65.3 | +3.4 |
一个在通用数据上训的 8B 模型产出的评分标准,比 GPT-4 prompt 出来的更贴近医疗专家与深度研究专家的判断。这条结论如果稳得住,LLM-as-judge 那一套基本可以重新洗牌:评估的本质不是"裁判模型必须最强",而是"评分标准必须最具体可执行"。
3.5 多 judge 训练
作者还尝试了一个进阶设置:同时让 5 个模型当裁判,包括 Qwen3-1.7B、Llama-3.2-1B-Instruct、OLMo-2-0425-1B-Instruct、Gemma-3-1B-IT、Qwen3-4B,刻意挑了不同公司、不同架构的小模型。目的是逼迫 rubric 学 "5 家裁判都买账的评分原则",而不是悄悄学到 "只投 Qwen3-1.7B 所好" 的捷径
训练时,5 个裁判各自独立读 rubric,对 (a+,a-) 打分。原本的 "判分差距 × 0.7 + 格式合规 × 0.3" 变成了 "MAF",即 Margin + Agreement + Format:
- Margin:平均差距 (权重 0.5):衡量 "rubric 让多少裁判整体上觉得 a+ 比 a-好"。均值越大,说明这条 rubric 的区分能力是普遍管用的,而不是只有某一个裁判才认
- Agreement:一致性(权重 0.2):用 Fleiss kappa 统计指标度量 5 个裁判的打分 "是不是齐刷刷投同一边",κ 值越大说明大家意见越统一。这一项避免了 rubric 偷懒只讨好单一或者部分裁判
- Format:格式合规 (权重 0.3):rubric 必须是合法 JSON、至少 2 条 criterion、权重和约等于 1,防止训练时模型为了刷判分差把 rubric 结构写坏
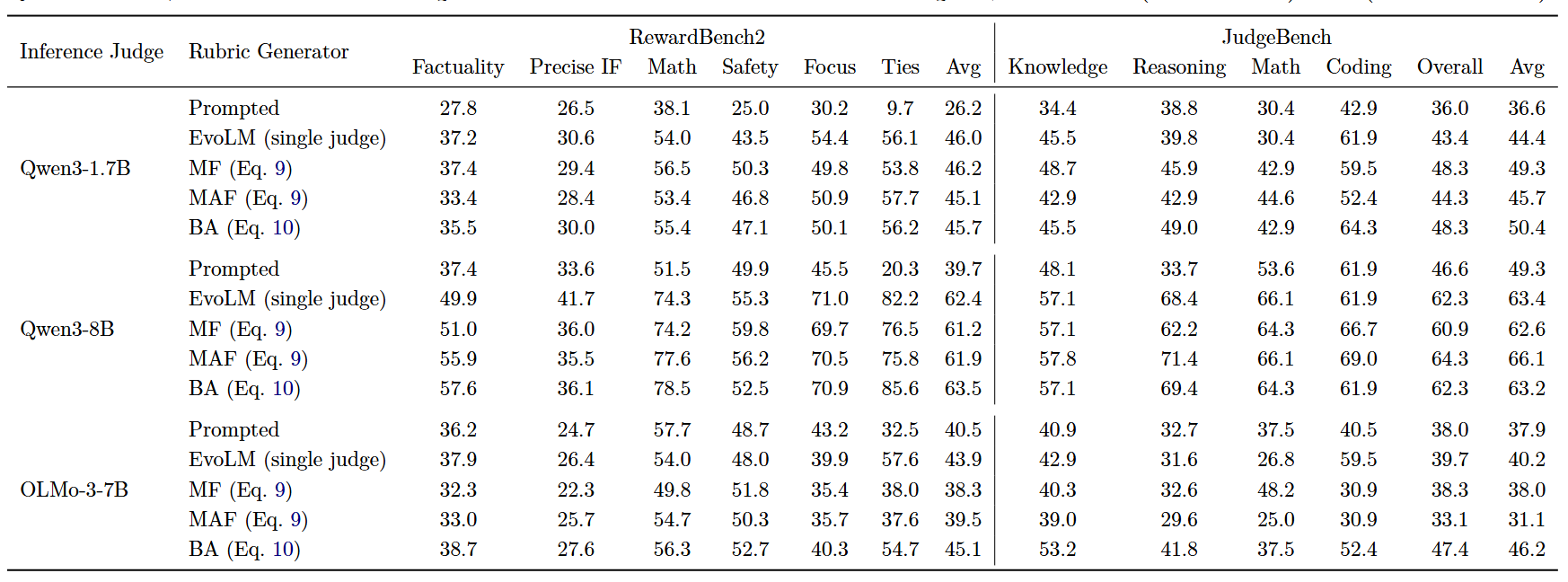
测试结果如上图所示,可见 rubric 学到的已经不是某一个 judge 的打分偏好,而是一套换裁判照样能稳定运作的 "通用评分语言"
四、关键消融
| 消融维度 | 推荐取值 | 结论 |
|---|---|---|
| 格式奖励 | 必须含(0.3 权重) | 不可或缺,一去掉就崩 |
| 交替间隔 | K=50 | K=2 (过紧) 和 K=100 (过松) 都只差 1pt 左右 |
| 参数共享 vs 双模型 | 参数共享(省显存) | policy 模型和 rubic 生成器共享权重得分一样 |
| 偏好对构造 (TC / IQ / RC) | TC 单用 | 混合构造方案 RB2 高但 policy 反而更弱,再次说明榜单高 ≠ policy 强 |
| judge 大小 | 1.7B 即可 | 0.6B 直接训崩;1.7B 以上边际收益≈0 |
| TC 偏好对构造时的 step 间隔 | 20, 100 步 | 偏近 5,20、偏远 100,300 都略差 |
| 基础模型 | Qwen3-8B | OLMo-3-7B 上可用 (64.0%);Llama-3.1-8B 明显下降(43.8%) |
核心结论:最终训出来的 policy 能在 12 个 benchmark 上拿多少分,对绝大多数超参数都异常不敏感 ------ 交替频率、偏好对从哪种方法构造、新旧 policy 之间隔多少步、用哪种参数共享方式,这些细节调来调去,平均分都只在 1~2 个百分点内浮动。唯一的关键是维持自我进化运行的条件:
- 格式奖励:若去掉,rubric 会被 RL 训成 "乱码 JSON",合法率从 99% 崩到 23%,judge 根本没法解析,policy 跟着退化
- judge 不能太小:至少要 Qwen3-1.7B 这个量级,0.6B 的小模型直接训崩,因为它连最基本的 "按 rubric 对答案" 都做不可靠
五、局限与未来方向
1. Judge 是冻结的
这是作者刻意为隔离变量做的对照设计,但同时意味着 rubric 能学到的复杂度被 judge 能力卡死。如果 judge 也能进化呢?这是个有意思的开放问题(类似 PPO → IPO 的演化)
2. 专业化领域未充分验证
论文主要在通用 Tulu-3 上验证,医学 / 法律 / 金融这种高度专业化的 mixture 上的表现仍待考察(虽然 OOD 测试在 HealthBench / ResearchQA 上是积极的)
3. 纯主观任务上的边界
rubric 进化机制最显著的现象是 "把评估降维成可验证的检查" ------ 这在数学、代码、约束写作上很自然,但在"哪首诗意境更高"、"哪段文字更感人" 这种纯主观任务上 rubric 还能不能持续进化,论文坦承没充分验证
六、核心启发
1. 评估和判断解耦
LLM-as-judge 天然把 "出题" 和 "阅卷" 绑在一起。把 rubric 显式分离,做成自然语言、可学习对象、可解释模块 ------ 立刻打开了 "换 judge 不重训"、"跨领域泛化"、"小 judge 也能可靠打分" 的口子
2. 任何静态 reward 都会被 policy 钻空子
SkyWork 在静态 RB2 上 86.4% 但训出 59.7% 的 policy,EvoLM 在静态 RB2 上仅 46.0% 却训出 69.3% 的 policy ------ 这个对比有强烈的工业意义,reward 准 ≠ policy 强,生产环境中长期使用的 reward 系统,都值得借鉴这种 "协同进化" 思路
3. 评估的本质是把抽象判断降维成具体检查
EvoLM 训练后的 rubric 不是变得更聪明,而是变得更具体 ------ 把 "评估证明的严谨性" 压缩成 "答案是不是 144"。这其实揭示了所有评估任务的共同结构:高质量评估往往就是把高质量判断需要的领域知识,提前内化到评分细则里,让低质量评判者也能可靠操作
4. 自我进化不是空中楼阁
EvoLM 用 8B 模型 + 1.7B judge 就跑出了 SOTA,完全没依赖 GPT-4 类的强外部模型。这个范式打开了一种可能:未来的模型迭代可以越来越少依赖人工标注和专有模型,把训练成本和数据隐私问题一并解决