Excel Python:飞速搞定数据分析与处理

第四部分 使用 xlwings 对 Excel 应用程序进行编程
第九章 Excel 自动化
作为第四部分的第一章,本章不再通过读写包操作 Excel 文件,而是开始利用 xlwings 自动化 Excel 应用程序。
xlwings 的主要用途是构建以 Excel 工作表为用户界面的交互式应用程序,你可以通过点击按钮调用 Python 代码或用户定义函数,而这类功能是读写包无法提供的。不过这并不是说 xlwings 无法用来读写文件------只要你在macOS 或者 Windows 中安装了 Excel 就行。 xlwings 的一个优势是它能够真正地编辑各种格式的 Excel文件,且不会修改或者丢失任何现有的内容或者格式;另一个优势是你可以从 Excel 工作簿中读取单元格的值而无须先保存这个工作簿。
在本章的开头,会向你介绍 Excel 对象模型和 xlwings:首先学习一些基础知识,比如连接工作簿或者读写单元格的值,然后深入学习如何利用转换器和各种选项来处理 pandas DataFrame 和 NumPy 数组。你也会看到如何与图表、图片和自定义名称进行互动。最后, 会解释 xlwings的工作原理,有了这些知识之后,你就知道如何才能让脚本更加好用以及如何处理一些缺少的功能。
9.2 转换器、选项和集合
本章在开头的代码示例中已经通过 xlwings range 对象的 value 属性从 Excel 中读取和写入了字符串和嵌套列表。本节首先会向你展示如何在 pandas Dataframe 中完成这些任务。然后我们会进一步了解 options 方法,它可以影响 xlwings 读写值的方式。随后我们再转向通过 sheet 对象访问的图表、图片、已定义名称和集合。学习了这些 xlwings 基础知识之 后,我们会再次回到第 7 章的报表案例研究。
9.2.1 处理 DataFrame
将 DataFrame 写入 Excel 与将标量或嵌套列表写入 Excel 并无二致:只需将 DataFrame 赋值给 Excel 区域的左上角单元格即可。
In [34]: data=[["Mark", 55, "Italy", 4.5, "Europe"],
["John", 33, "USA", 6.7, "America"]]
df = pd.DataFrame(data=data,
columns=["name", "age", "country",
"score", "continent"],
index=[1001, 1000])
df.index.name = "user_id"
df
Out[34]: name age country score continent
user_id
1001 Mark 55 Italy 4.5 Europe
1000 John 33 USA 6.7 America
In [35]: sheet1["A6"].value = df如果你想去掉列标题或索引(也可以同时去掉两者),那么可以像下面这样使用 options 方法:
In [36]: sheet1["B10"].options(header=False, index=False).value = df要将 Excel 区域以 DataFrame 的形式读取,需要将 DataFrame 类传递给 options 方法的 convert 参数。在默认情况下,你的数据必须同时具备标题和索引,但是你可以通过 index 参数和 header 参数来改变这种行为。除了使用转换器,还可以将这些值读取为嵌套列表, 然后手动构造 DataFrame。不过使用转换器可以更方便地处理索引和标题。
expand 方法:在下面的代码示例中,引入了 expand 方法,该方法可以方便地读取一块连续的单元格,这和你在Excel 中按下快捷键 Shift+Ctrl+下箭头+右箭头选中的区域是一样的,只不过 expand 会跳过左上角的空单元格。
In [37]: df2 = sheet1["A6"].expand().options(pd.DataFrame).value
df2
Out[37]: name age country score continent
user_id
1001.0 Mark 55.0 Italy 4.5 Europe
1000.0 John 33.0 USA 6.7 America
In [38]: # 如果你需要整数索引,
# 那么可以修改其数据类型
df2.index = df2.index.astype(int)
df2
Out[38]: name age country score continent
1001 Mark 55.0 Italy 4.5 Europe
1000 John 33.0 USA 6.7 America
In [39]: # 通过设置index=False,Excel文件中的所有值都会
# 被保存到DataFrame的数据部分且使用默认索引
sheet1["A6"].expand().options(pd.DataFrame, index=False).value
Out[39]: user_id name age country score continent
0 1001.0 Mark 55.0 Italy 4.5 Europe
1 1000.0 John 33.0 USA 6.7 America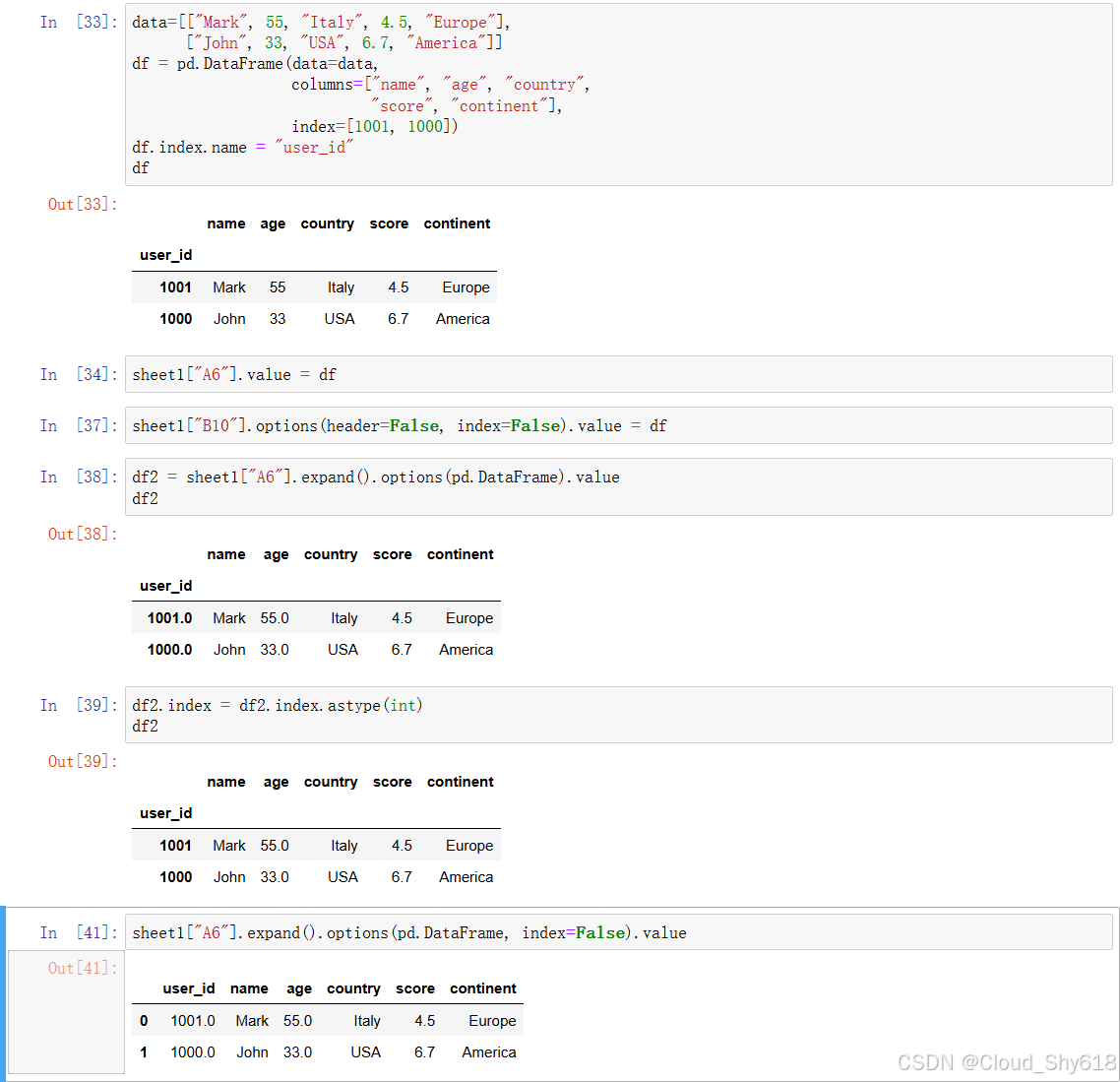
读写 DataFrame 只体现了转换器的一部分功能。下一节会介绍如何规范地定义转换器,以 及如何用转换器来处理其他数据结构。
9.2.2 转换器和选项
如前所述,xlwings range 对象的 options 方法修改的是读写 Excel 文件时处理值的方式。 也就是说,只有在你调用 range 对象的 value 属性时,options 才会进行求值。它的语法如下(其中 myrange 是一个 xlwings range 对象):
myrange.options(convert=None, option1=value1, option2=value2, ...).value表 9-4 展示了内置的转换器,即 convert 参数可以接受的值。这些转换器之所以被称为内置的,是因为 xlwings 还提供了编写自定义转化器的方法。如果你在写入值之前或读取值之后一次又一次地进行了额外的转换工作,那么能够自己编写转换器是不错的。要想了解如何编写自定义转换器,可以看一下 xlwings 的文档。

在 DataFrame 的示例中已经用过 index 选项和 header 选项,不过除此之外还有更多的选项,如表 9-5 所示。


来仔细看一下 ndim:在默认情况下,从 Excel 中读取单个单元格时,你会得到一个标量 (比如浮点数或字符串);当读取一行或一列时,你得到的是一个简单列表;当读取一个二维区域时,你得到的是一个嵌套(二维)列表。这样的行为是自洽的,并且和第 4 章中讲到的 NumPy 数组切片的行为也是一致的。但一维的情况很特殊:有时候一列可能只是二维区域的特殊情况,在这种情况下,可以用 ndim=2 来强制区域的维度为 2:
In [40]: # 水平区域(一维)
sheet1["A1:B1"].value
Out[40]: [1.0, 2.0]
In [41]: # 垂直区域(一维)
sheet1["A1:A2"].value
Out[41]: [1.0, 3.0]
In [42]: # 水平区域(二维)
sheet1["A1:B1"].options(ndim=2).value
Out[42]: [[1.0, 2.0]]
In [43]: # 垂直区域(二维)
sheet1["A1:A2"].options(ndim=2).value
Out[43]: [[1.0], [3.0]]
In [44]: # 使用NumPy数组转换器也是一样的效果:
# 垂直区域会产生一维数组
sheet1["A1:A2"].options(np.array).value
Out[44]: array([1., 3.])
In [45]: # 保持列的方向不变
sheet1["A1:A2"].options(np.array, ndim=2).value
Out[45]: array([[1.],
[3.]])
In [46]: # 如果需要垂直写入列表,
# 那么此时可以使用transpose选项
sheet1["D1"].options(transpose=True).value = [100, 200]ndim=1 会强制让读到的单个单元格的值生成列表而非标量。在使用 pandas 时无须使用 ndim 参数,因为 DataFrame 都是二维的,而 Series 都是一维的。下面还有一些示例,它们展示了 empty、date 和 number 是如何工作的:
In [47]: # 写入一些示例数据
sheet1["A13"].value = [dt.datetime(2020, 1, 1), None, 1.0]
In [48]: # 使用默认选项读取
sheet1["A13:C13"].value
Out[48]: [datetime.datetime(2020, 1, 1, 0, 0), None, 1.0]
In [49]: # 使用非默认选项读取
sheet1["A13:C13"].options(empty="NA",
dates=dt.date,
numbers=int).value
Out[49]: [datetime.date(2020, 1, 1), 'NA', 1]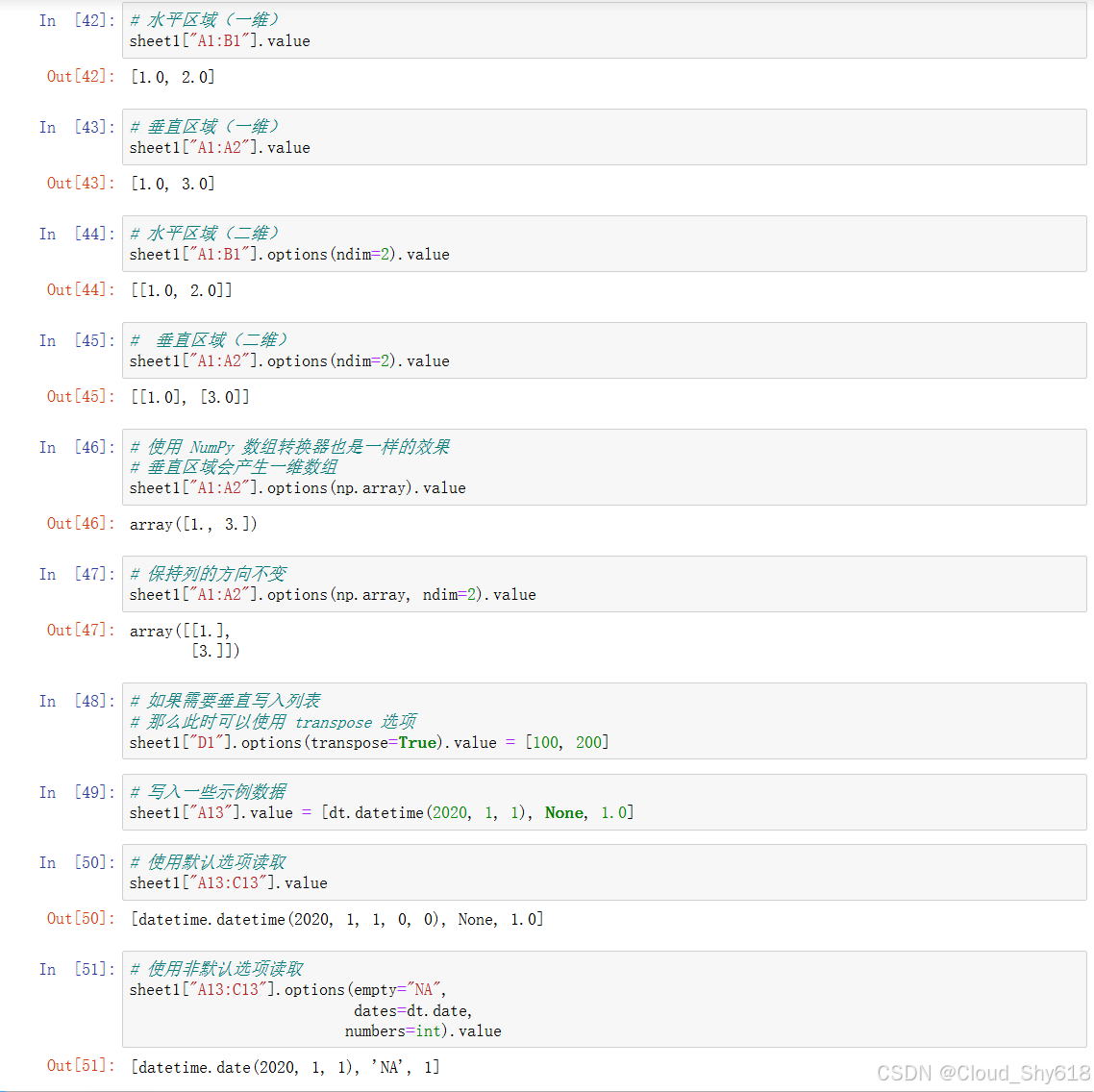
到目前为止,我们已经用过了 book、sheet 和 range 这 3 种对象。接下来学习如何通过 sheet 对象处理图表一类的集合。
9.2.3 图表、图片和已定义名称
本节会向你展示如何通过 sheet 对象或 book 对象来处理这 3 种集合,即图表、图片和已定义名称。xlwings 只支持最基本的图表功能,不过由于你可以操作模板,因此它提供的功能还是够用的。不过 xlwings 可以让你将 Matplotlib 的图表作为图片嵌入 Excel 文件。第 5 章讲过 Matplotlib 是 pandas 默认的绘图后端,这项功能一定程度上弥补了在图表操作方面的 不足。先来创建第一张 Excel 图表吧。
1、Excel 图表
使用 charts 集合的 add 方法来添加一张新的图表并为其设置图表类型和源数据:
In [50]: sheet1["A15"].value = [[None, "North", "South"],
["Last Year", 2, 5],
["This Year", 3, 6]]
In [51]: chart = sheet1.charts.add(top=sheet1["A19"].top,
left=sheet1["A19"].left)
chart.chart_type = "column_clustered"
chart.set_source_data(sheet1["A15"].expand())上面的代码会生成下图所示的图表。在 xlwings 的文档中可以查到所有可用的图表类型。如果比起 Excel 图表你更喜欢 pandas 的图表,或是想使用一种 Excel 中没有的图表类型,则 xlwings 也能帮到你。下面来看看怎么做。
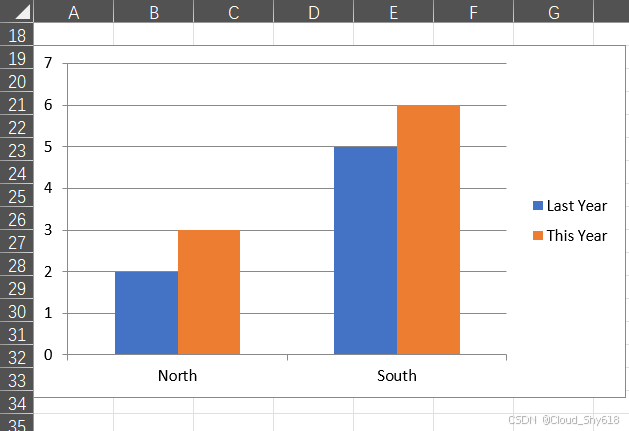
2、图片:Matplotlib 图像
当你使用 pandas 的默认绘图后端时,你创建的是一张 Matplotlib 的图像。要将这样的图像放进 Excel 中,首先要获取它的 figure 对象,然后将其作为参数传递给 pictures.add, pictures.add 会将 Matplotlib 图像转换为图片然后发送至 Excel:
In [52]: # 将图表数据读取为 DataFrame
df = sheet1["A15"].expand().options(pd.DataFrame).value
df
Out[52]: North South
Last Year 2.0 5.0
This Year 3.0 6.0
In [53]: # 通过笔记本的魔法命令启用 Matplotlib
# 并切换至 "seaborn" 样式
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use("seaborn")
In [54]: # pandas 的 plot 方法会返回一个 axis 对象,
# 你可以从中获得图片。T会将 DataFrame 转置以调整图像方向
ax = df.T.plot.bar()
fig = ax.get_figure()
In [55]: # 将图像发送至 Excel
plot = sheet1.pictures.add(fig, name="SalesPlot",
top=sheet1["H19"].top,
left=sheet1["H19"].left)
# 将图像缩小为 70% 大小
plot.width, plot.height = plot.width * 0.7, plot.height * 0.7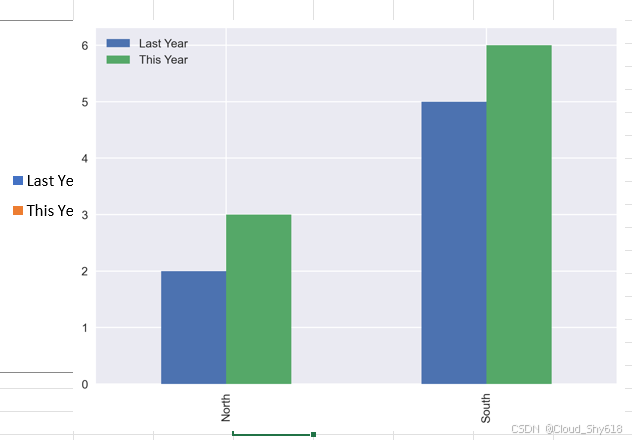
要想使用新的图像来更新图片,只需调用 update 方法并传递另一个 figure 对象即可。虽然这样做会替换 Excel 中的图片,但会保留位置、尺寸、名称等属性:
In [56]: ax = (df + 1).T.plot.bar()
plot = plot.update(ax.get_figure())注意:确保已安装 Pillow:在处理图片时,一定要确保安装了 Pillow,它是 Python 中常用的图片处理库。Pillow 能够保证图片在 Excel 中有正确的尺寸和比例。Anaconda 中包含了 Pillow,所以如果你用的是其他发行版,则需要通过 conda install pillow 或者 pip install pillow 进行安装。注意,除了接受 Matplotlib 图像, pictures.add 也可以接受磁盘上的图片路径。
图表集合和图片集合都可以通过 sheet 对象访问,而接下来要讲到的已定义名称集合除了通过 sheet 对象访问之外,还可以通过 book 对象访问。下面来看看两种访问方式有何区别。
3、已定义名称
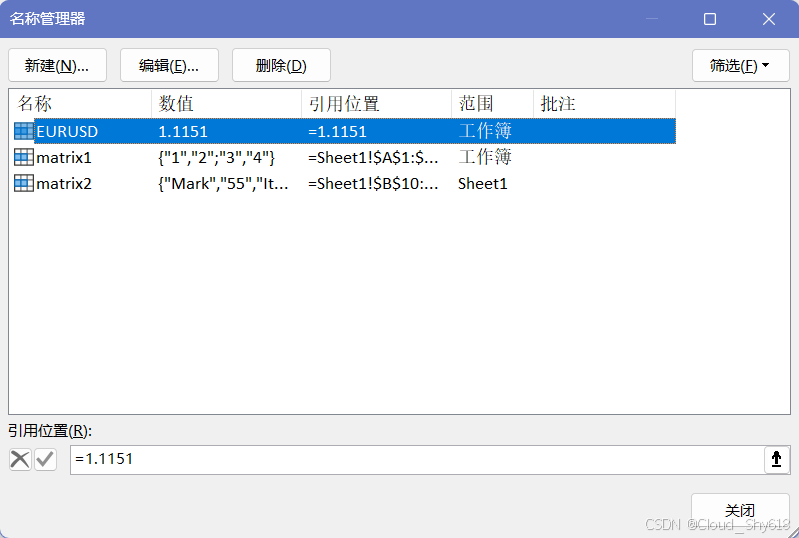
在 Excel 中,通过为区域、公式和常量赋予名称来创建已定义名称。为一个区域命名可能是最常见的情况,这种区域被称作具名区域 。利用具名区域,你可以在公式和代码中使用描述性名称 而不是抽象地址(A1:B2)来引用一个 Excel 区域。在 xlwings 中使用这些名称可以让你的代码更加灵活且更加稳定:利用具名区域读写值可以在不调整 Python 代码的情况下重新组织工作簿。这是极具灵活性的做法,比如,即使插入新行导致了单元格的移动,但对应的名称仍然引用的是原来的单元格。自定义名称可以在全局工作簿作用域或局部工作表作用域中设置。工作表作用域的优势是在复制工作表时不用担心重复的具名区域发生冲突。在 Excel 中,你可以在 "公式>定义名称" 菜单项中添加自定义名称。也可以选择一个区域,然后将想要的名称写到名称框(公式栏左边的文本框)中,你可以在这 里看到默认的单元格地址。下面的代码展示了使用 xlwings 管理自定义名称的方法:
In [57]: # 默认作用域是工作簿作用域
sheet1["A1:B2"].name = "matrix1"
In [58]: # 对于工作表作用域,需要在工作表名称前加上一个感叹号
sheet1["B10:E11"].name = "Sheet1!matrix2"
In [59]: # 现在你可以通过名称访问区域了
sheet1["matrix1"]
Out[59]: <Range [Book2]Sheet1!$A$1:$B$2>
In [60]: # 如果通过 sheet1 对象访问名称集合,
# 则其中只包含工作表作用域的名称
sheet1.names
Out[60]: [<Name 'Sheet1!matrix2': =Sheet1!$B$10:$E$11>]
In [61]: # 如果通过 book 对象访问名称集合,
# 则其中包含了工作簿和工作表作用域的所有名称
book.names
Out[61]: [<Name 'matrix1': =Sheet1!$A$1:$B$2>, <Name 'Sheet1!matrix2':
=Sheet1!$B$10:$E$11>]
In [62]: # 名称有多种方法和属性,
# 例如,你可以获取对应的 range 对象
book.names["matrix1"].refers_to_range
Out[62]: <Range [Book2]Sheet1!$A$1:$B$2>
In [63]: # 如果你想为常量或公式取名,可以使用 add 方法
book.names.add("EURUSD", "=1.1151")
Out[63]: <Name 'EURUSD': =1.1151>可以通过 "公式>名称管理器"(参见下图)菜单项打开名称管理器来查看在 Excel 中生成的自定义名称。注意,macOS 中并没有名称管理器,但在 "公式>定义名称" 菜单项中,你可以看到既存的名称。
现在你知道了如何处理 Excel 工作簿中最常用的各种组件。这就意味着我们可以再一次回 到第 7 章的案例研究,来看看在使用 xlwings 时会发生哪些变化。
9.2.4 案例研究(再次回顾):Excel 报表
xlwings 能够真正地编辑 Excel 文件,无论这些模板有多复杂、无论它们以什么格式保存, 我们都可以在保证不修改模板文件的情况下使用模板。例如你可以轻松地编辑 xlsb 文件, 而第 8 章中的任何读写包目前都不支持这种格式。在配套代码库的 sales_report_openpyxl.py 中可以看到,在 summary 这个 DataFrame 准备完成后,如果使用 OpenPyXL,就必须编写近 40 行代码来创建图表并调整 DataFrame 的样式。但是,如果使用 xlwings,则只需要 6 行代码就可以达成同样的目标,如例 9-1 所示。能够在 Excel 模板中调整格式可以省去大量的工作,不过这也是有代价的:xlwings 需要启动已安装的 Excel 应用程序。也就是说, 如果你在自己的计算机上创建这些报表,那么一般来说这没什么问题,但如果你尝试在服务器上创建报表并将其作为 Web 应用程序的一部分,那么这种方案就不那么理想了。
例 9-1 sales_report_xlwings.py(仅列出第二部分)
# 打开模板,粘贴数据,自动调整列并调整
# 图表源。然后将其保存为不同名称的文件
template = xw.Book(this_dir / "xl" / "sales_report_template.xlsx")
sheet = template.sheets["Sheet1"]
sheet["B3"].value = summary
sheet["B3"].expand().columns.autofit()
sheet.charts["Chart 1"].set_source_data(sheet["B3"].expand()[:-1, :-1])
template.save(this_dir / "sales_report_xlwings.xlsx")你可以在配套代码库的 sales_report_xlwings.py(前半部分和使用 OpenPyXL 以及 XlsxWriter 的版本是相同的)中看到完整的 xlwings 脚本。这也是读取包和 xlwings 搭配使用的绝佳例子:尽管 pandas(通过 OpenPyXL 和 xlrd)可以更快地从磁盘中读取大量文 件,但 xlwings 可以更加方便地填充预先格式化的模板。
利用已经格式化的 Excel 模板,你可以非常快速地构建精美的 Excel 报表。你还可以使用 autofit 之类的方法调整格式,不过,由于这类方法依赖于 Excel 应用程序完成的运算,因此用于写入文件的包并不能提供这些功能。autofit 可以根据内容对单元格宽度和高度 进行适当的调整。
9.3 高级 xlwings 主题
本节会展示如何让 xlwings 代码具有更高的效率以及如何弥补 xlwings 缺少的功能。不过要理解这些主题,首先需要谈一谈 xlwings 和 Excel 是如何通信的。
9.3.1 xlwings 的基础
xlwings 依赖于其他 Python 包来和各个操作系统中的自动化机制通信。
Windows :在 Windows 中,xlwings 依赖于 COM 技术。COM 是 Component Object Model(组件对象模型)的缩写。它是一个可以让两个进程相互通信的标准,而对于我们来说,这两个进程就是 Excel 和 Python。xlwings 使用 pywin32 包来处理 COM 调用。
macOS: 在 macOS 中,xlwings 依赖于 AppleScript。AppleScript 是 Apple 用于自动化支持脚本的应用程序的一种脚本语言,幸运的是,Excel 就是这样一种支持脚本的应用程序。为了执行 AppleScript 命令,xlwings 使用了 appscript 包。
拓展 :Windows 如何防止僵尸进程
当你在 Windows 中尝试 xlwings 时,有时候会注意到 Excel 看起来像是被完全关闭了, 但当你打开任务管理器(在 Windows 任务栏上单击右键,然后选择任务管理器)时, 会在进程标签页下的后台进程中发现 Microsoft Excel。如果你看不见标签页,则可以先点击 "更多细节"。另外,在 "详细标签页" 中,你也可以看见 Excel以 "EXCEL. EXE" 的名称列出。要终止僵尸进程,可以在对应的行上单击右键,然后选择 "结束任务" 强制关闭 Excel。 由于这些进程处于僵死状态而没有被正常终止,因此它们通常都被称为僵尸进程 (zombie process)。如果弃之不顾,则它们会持续消耗资源且可能导致意外的行为,比 如,文件可能会被阻塞,打开新的 Excel 实例时插件无法正常加载。之所以有时候 Excel 无法正常关闭,是因为只有不再存在 COM 引用(比如一个 xlwings 的 app 对象) 时进程才能被关闭。大部分时候,当你强制关闭 Python 解释器时会产生一个 Excel 僵尸进程,因为这样的做法会使得 COM 引用无法被正常清理。考虑下面这个 Anaconda Prompt 中的例子:
(base)> python
>>> import xlwings as xw
>>> app = xw.App()一旦新的 Excel 实例开始运行,立即通过 Excel 的用户界面将其关闭:虽然 Excel 关闭了,但任务管理器中的 Excel 进程会持续运行。如果你通过执行 quit() 或按快捷键 Ctrl+Z 正常关闭了 Python 会话,那么 Excel 进程最终也会被关闭。但如果直接点击窗口右上角的 "×" 关闭了 Anaconda Prompt,你会注意到这个 Excel 进程会继续作为一个僵尸进程存在。如果你在关闭 Excel 之前关闭了 Anaconda Prompt,或是在运行 Jupyter 服务器且在笔记本单元格中保留了 xlwings 的 app 对象时关闭了 Anaconda Prompt,则也会发生这种现象。为了尽可能地减少 Excel 僵尸进程的出现,这里有几条建议。
- 从 Python 代码中执行 app.quit() 而不是手动关闭 Excel。这样可以确保 COM 引用被正确清理。
- 不要在使用 xlwings 时关闭交互式 Python 会话,如果你在 Anaconda Prompt 中运行 Python REPL,那么通过执行 quit() 或按快捷键 Ctrl+Z 来正确关闭 Python 解释器。 在使用 Jupyter 笔记本时,在 Web 界面上点击退出按钮关闭服务器。
- 使用交互式 Python 会话时,应该避免直接使用 app 对象,比如使用 xw.Book() 而不是 myapp.books.add()。当 Python 进程被终止时,Excel 也应该被正常终止。
9.3.2 提升性能
要想让 xlwings 脚本有良好的性能,有以下几种策略:最重要的一种是尽可能减少跨应用程序调用;使用原始值是另一种策略;正确设置 app 的属性也可能有一定的帮助。下面来逐个了解这些选项。
1、尽可能减少跨应用程序调用
要知道 Python 到 Excel 的跨应用程序调用是十分"昂贵"的,也就是说非常慢。因此应该尽可能地减少这种调用。最简单的办法是读取和写入整个 Excel 区域而不是遍历各个单元格。在下面的例子中,我们读写了 150 个单元格,第一种方法是遍历单元格,第二种方法是在一次调用中处理整个区域。
In [64]: # 添加新的工作表,写入150个值以便有事可做
sheet2 = book.sheets.add()
sheet2["A1"].value = np.arange(150).reshape(30, 5)
In [65]: %%time
# 这段代码进行了150次跨应用程序调用
for cell in sheet2["A1:E30"]:
cell.value += 1
Wall time: 909 ms
In [66]: %%time
# 这里只进行了两次跨应用程序调用
values = sheet2["A1:E30"].options(np.array).value
sheet2["A1:E30"].value = values + 1
Wall time: 97.2 ms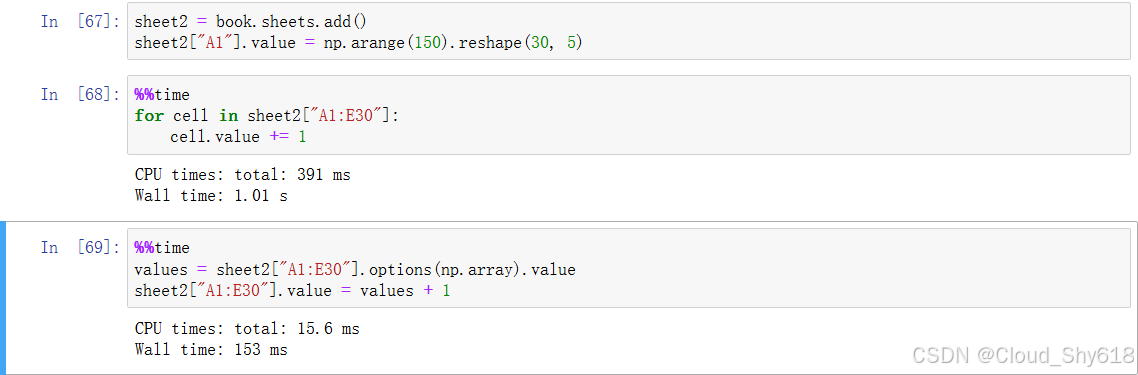
2、原始值
xlwings 的主要设计目标是更方便 而不是更快。然而,如果你要处理庞大的单元格区域, 那么在这种情况下可能需要跳过 xlwings 的数据清理阶段来节省时间:在续写数据时, xlwings 会遍历每个值,比如为了将 Windows 和 macOS 的数据类型进行统一时它就会这样做。在 options 方法中使用字符串 raw 作为转换器可以跳过这一阶段。虽然这样可以让各种操作更快一些,但如果不是在 Windows 中写入大型数组,则速度上的差距并不明显。然 而,使用原始值就意味着你不能再直接使用 DataFrame ,此时需要以嵌套列表或元组的形式提供值。另外,你也必须提供 想要写入的区域的完整地址,因为只提供左上角的单元格地址是不够的。
In [67]: # 使用原始值时必须提供完整的目标区域,
# sheet["A35"]就不再可用了
sheet1["A35:B36"].options("raw").value = [[1, 2], [3, 4]]3、app 对象的属性
根据工作簿内容的不同,修改 app 对象的某些属性可能会让代码运行得更快。一般来说, 你会对如下属性(myapp 指的是一个 xlwings app 对象)感兴趣。
- myapp.screen_updating = False
- myapp.calculation = "manual"
- myapp.display_alerts = False
在脚本的最后,一定要将 app 对象的属性还原。如果在 Windows 中,则通过 xw.App (visible=False) 在隐藏 Excel 实例中运行脚本也可以获得轻微的性能提升。 现在你已经知道如何控制代码的性能,下面来研究一下如何扩展 xlwings 的功能。
9.3.3 如何弥补缺失的功能
xlwings 为大部分常用的 Excel 命令提供了十分符合 Python 风格的接口,并且可以同时在 Windows 和 macOS 中工作。不过仍然有很多 Excel 对象模型的方法和属性没有在 xlwings 中得到原生的实现。不要灰心!通过在所有的对象上提供 api 属性,xlwings 在 Windows 中提供了访问底层 pywin32 对象的接口,在 macOS 中提供了访问 appscript 对象的接口。 这样你就可以访问整个 Excel 对象模型了,但相应的,你会失去跨平台兼容性。如果你想 清除单元格的格式,那么可以遵循如下步骤来完成。
- 检查 xlwings 的 range 对象上是否有对应的方法可用,比如,在 Jupyter 笔记本中,在输入 range 对象后面的点之后按下 Tab 键,或是执行 dir(sheet"A1"),或者搜索 xlwings 的 API 参考文档。在 VS Code 上,可用方法会自动显示在提示信息中。
- 如果找不到所需功能,则可以使用 api 属性获得底层对象:在 Windows 中,sheet"A1". api 会返回一个 pywin32 对象;在 macOS 中返回的是 appscript 对象。
- 在 Excel VBA 参考文档中查看 Excel 对象模型。要清除区域的格式,可以使用 Range. ClearFormats。
- 在 Windows 中,大部分时候可以直接在 api 对象上使用 VBA 方法或属性。如果要使用方法,那么一定要在Python 代码中加上圆括号:sheet"A1".api.ClearFormats()。如 果在 macOS中 操作,则事情会变得复杂一些,因为 appscript 的语法难以捉摸。最好的办法是查看作为 xlwings 源代码一部分的开发者指南。不过,清除单元格格式的做法还是很简单的:只需将 Python 的语法规则套用到方法名上,使用带下划线的小写字符即可, 即 sheet"A1".api.clear_formats()。
如果需要确认 ClearFormats 是否能在这两个平台上工作,那么可以像下面这样做(darwin 是 macOS 的内核, sys.platform 中使用的就是这个名称):
import sys
if sys.platform.startswith("darwin"):
sheet["A10"].api.clear_formats()
elif sys.platform.startswith("win"):
sheet["A10"].api.ClearFormats()9.4 小结
本章介绍了 Excel 自动化的相关概念:通过 xlwings 可以使用 Python 来完成那些通常用 VBA 完成的任务。学习了有关 Excel 对象模型的知识,了解了 xlwings 如何让你和 Excel 对象模型的组件(比如 sheet 对象和 range 对象)进行交互。还研究了 xlwings 在底层使用的库,进而知道了如何去优化性能以及弥补缺失的功能。作者最喜欢的 xlwings 特性是它在 macOS 和 Windows 中都能工作。更令人激动的一点在于 macOS 中的 Power Query 尚未实现 Windows 版的所有功能,但无论少了什么功能,你都应该能够使用 pandas 和 xlwings 直接替代它。
现在你已经具备了 xlwings 的基础知识,接下来就可以进入第 10 章了。第 10 章会从 Excel 中调用 xlwings 脚本,从而构建由 Python 驱动的 Excel 工具。