目录
[exit() 与 _exit()的核心区别](#exit() 与 _exit()的核心区别)
[wait 与 waitpid 的对比表](#wait 与 waitpid 的对比表)
[系统调用函数 execve](#系统调用函数 execve)
进程创建
引入一个小知识
在Linux中fork函数是一个非常重要的函数,它从已经存在的进程中创建一个新进程来完成特定的事情。新进程被称为子进程,已经存在的进程被称为父进程。
由此可知,在 Linux 下我们自己写的可执行程序要想执行起来,就必定会成为一个子进程,那么我们执行的可执行程序的父进程是谁呢?
cpp
1 #include <stdio.h>
2 #include <unistd.h>
3
4 int main()
5 {
6 printf("我的父进程pid:%d,我的pid:%d\n", getppid(), getpid());
7 return 0;
8 }我的父进程pid:32747,我的pid:706
我的父进程pid:32747,我的pid:707
我的父进程pid:32747,我的pid:707
对上述代码的多次运行,可以看到一个现象,父进程pid永远不变,子进程pid不断变化
对于子进程pid不断变化,很好理解,因为操作系统会创建其他的进程占有了原来的pid,从而分配其他的pid,对于父进程pid永远不变,那么我们执行的可执行程序是由同一个父进程来管理的,那这个父进程是谁呢?

通过这张图,我们可以很好地看到,原来我们执行的可执行程序都是通过bash进程来创建子进程完成特定任务的,我们还可以看到,我们在Linux下使用的命令也都是一个进程,并且父进程也为bash进程。
fork函数的认识

返回值:对于子进程返回0,对于父进程返回子进程 id ,创建进程失败返回 -1
在 深度理解进程 ---- 进程状态 这篇文章中,我们简单理解了三个问题。
-
为什么要给⼦进程返回 0 ,⽗进程返回⼦进程 pid ?
-
为什么⼀个函数 fork 会有两个返回值?
-
为什么⼀个 id 即等于 0 ,⼜⼤于 0 ?
那让我们再深刻地重新理解一下这三个问题
对于问题1,因为一个父进程可以创建多个子进程,但一个子进程只能拥有一个父进程,可以得出父进程 : 子进程 = 1 : n ,且父进程要对子进程的退出信息做管理,那么父进程就必须知道它所创建的子进程,所以给父进程返回子进程 pid ,子进程返回0,是一个约定的标识,来表示我是子进程。
对于问题2和问题3一起说
进程调用fork,执行到fork函数内部中,内核做了什么?
分配新的内存块和内核数据结构给子进程
将父进程部分数据结构内容拷贝到子进程
添加子进程到系统进程列表中
fork返回,开始调度器调度
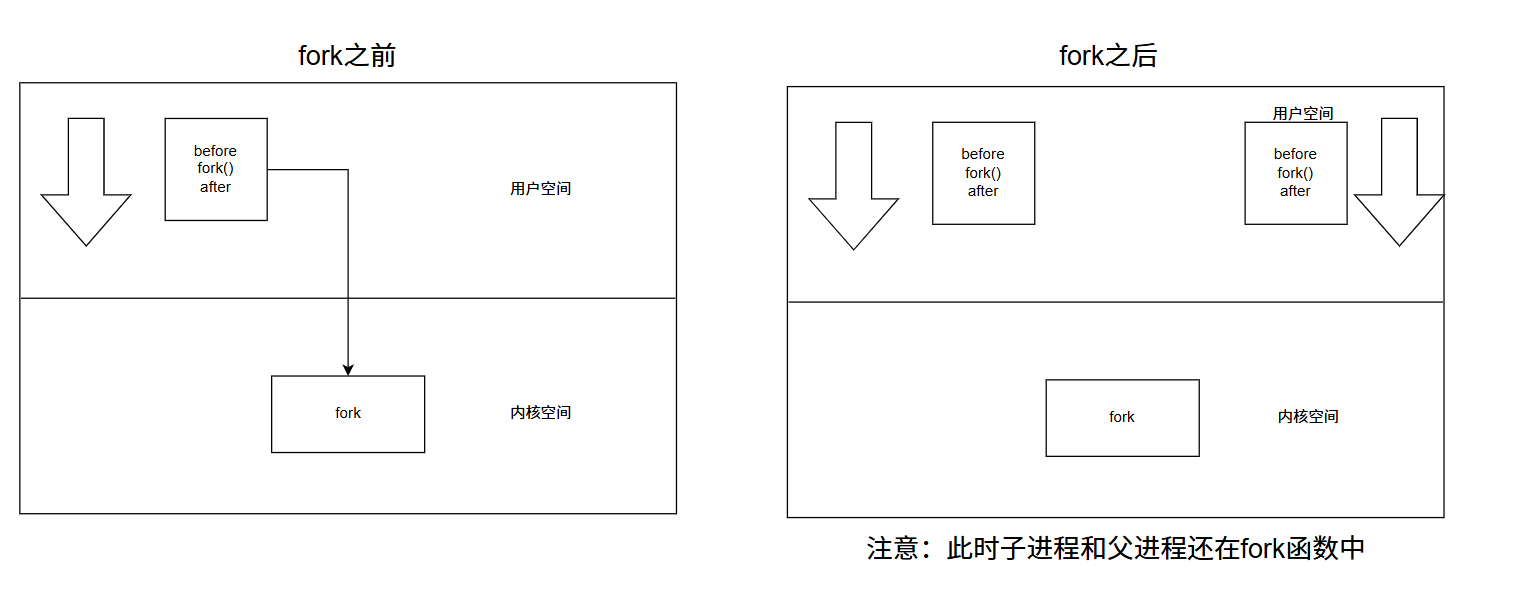
fork之前父进程独立执行,fork之后父子进程分别执行。
注意:fork之后,父子进程都处于就绪状态,有操作系统的调度器决定哪个进程先获得CPU时间片开始执行,没有任何机制保证父进程一定先运行,也没有办法强制让子进程先运行。
回答问题2和3
子进程刚创建时,子进程和父进程的代码和数据共享,但fork函数内部会进行判断,如果是父进程返回子进程pid,如果是子进程返回0,此时数据被修改,会发生写时拷贝。所以fork函数会有2个返回值,导致父子进程得到id的值也不同了。
写时拷贝
写时拷贝是一种延迟拷贝技术,目的是避免不必要的内存复制,提高效率。
通常,父子代码共享,父子不进行对数据的修改时侯,数据也是共享的,但是当任意一方准备写入数据时,便以写时拷贝的形式,使父子进程各有一份独立的数据。所以父子进程各自执行,互不影响,完成了进程的独立性。
fork函数常规用途
1.一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
2.一个进程要执行一个不同的程序。例如子进程通过exec系列函数进行进程替换,来完成独立于父进程的任务。
fork函数调用失败的原因
1.系统中进程数量太多,内存剩余空间很少。
2.实际用户的进程数超过了限制。
进程终止
进程终止:本质是释放系统资源,就是释放创建一个进程所申请的内核数据结构和对应的代码和数据。
进程退出:主动、正常结束,程序自己执行完、调用 exit() / return 等结束。
进程终止场景
1.代码运行完毕,结果正确
2.代码运行完毕,结果错误
3.代码异常终止
进程终止的常见方法
正常终止
注意:可以通过echo $? 查看最近一个进程的退出码
1.从main函数返回
2.调用exit()函数(库函数,底层会调用 _exit()函数)
3.调用_exit()函数(系统调用)
exit() 与 _exit()的核心区别
| 特性 | exit()(库函数) |
_exit()(系统调用) |
|---|---|---|
| 缓存区处理 | 关闭所有打开的文件描述符,会刷新用户级缓存区 | 同样关闭文件描述符,不会刷新用户级缓存区 |
| 适用场景 | 正常程序退出,需要保证数据写入磁盘 | 异常终止,或需要立刻结束进程的场景 |
异常终止
-
ctrl + c
-
信号终止
退出码
退出码:对于一个进程,进程执行结束后,用来记录最后一次执行命令的状态的数值就叫做退出码(退出状态),进程退出时,会把退出码保存到自身 task_struct 中,然后父进程通过系统调用来获取子进程的退出信息,从而判断子进程是否正常完成任务。
约定规则:
退出码0:执行成功、正常结束
非0任意值:执行失败、异常退出
退出码取值范围:0, 255
在Linux系统中,每一个退出码都被规定为对应一个错误,可以采用下列方式来获取退出码对应的描述。
cpp
1 #include <stdio.h>
2 #include <string.h>
3
4 int main()
5 {
6 for(int i = 0; i <= 255; ++i)
7 {
8 printf("error[%d]->%s\n", i, strerror(i));
9 }
10 return 0;
11 }进程等待
进程等待必要性
1.子进程退出,父进程如果对子进程的退出信息不处理,待父进程退出后,子进程的task_struct没有回收,此时子进程就变成了僵尸进程,从而造成内存泄漏。
2.对于僵尸进程,除了重启操作系统,没有任何办法对僵尸进程的task_struct进行回收,kill -9 也不起作用。
3.对于父进程,父进程分配给子进程任务,父进程肯定要知道子进程是否正常完成任务。
4.父进程通过进程等待,获取子进程退出信息,释放子进程资源
进程等待的方法
1.wait方法
功能:等待任意一个子进程退出
头文件和系统调用
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
参数:
输出型,获取子进程的退出码,如果父进程不关心子进程的退出码,则可以设置为NULL
函数返回值:
等待子进程退出成功,返回子进程的pid,失败返回-1
2.waitpid方法
功能:等待子进程退出
头文件和系统调用
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *status, int options);
参数:
pid:
pid = -1 等待任意一个子进程,与wait一样。
pid = 指定子进程pid 等待指定子进程
status:输出型参数
WIFEXITED(status):判断子进程是不是正常退出(退出码不一定为0)
WEXITSTATUS(status):获取子进程的退出码
WIFSIGNALED(status):判断子进程是否被信号杀死
WTERMSIG(status):获取杀死子进程的信号编号
cpp// 宏的主要使用方法 if (WIFEXITED(status)) { // 进程正常退出,获取退出码 printf("子进程正常退出,退出码:%d\n", WEXITSTATUS(status)); } else { // 非正常退出(被信号杀死),获取终止信号 printf("子进程被信号杀死,信号编号:%d\n", WTERMSIG(status)); }options:
options = 0 表示阻塞等待(父进程会一直卡在wait这里,直到对应子进程退出才会继续执行,适合父进程没有其他任务,只需等待子进程结束的场景)
options = WNOHANG 表示非阻塞等待(父进程扫描一下子进程列表,如果子进程退出,则回收子进程,如果没有子进程退出,则父进程继续向下执行代码),常用于父进程需要一边处理自己的任务,一边定期回收子进程的长期,避免父进程阻塞在waitpid上
返回值
>0 : 成功回收的子进程PID
= 0:有子进程还在运行,没有退出(一般用于非阻塞等待)
-1:出错(比如没有子进程可以等待或者等待的子进程PID不存在)
wait 与 waitpid 的对比表
| 特性 | wait() |
waitpid() |
|---|---|---|
| 等待对象 | 任意一个子进程 | 可指定 PID ,或任意子进程 |
| 阻塞方式 | 只能阻塞等待 | 支持阻塞 / 非阻塞(WNOHANG) |
| 灵活性 | 低 | 高,可自定义等待策略 |
| 底层实现 | 封装了 waitpid(-1, &status, 0) |
系统调用,更底层 |
进程替换
进程替换的诞生原因
fork()创建子进程之后,子进程完全拷贝父进程的代码、数据、堆栈等,子进程只能执行父进程的代码片段,无法直接执行一个全新的程序。
假如我用fork()创建了一个子进程,我不想让子进程执行父进程的代码,我想让它执行一个全新的程序,那必须用进程替换来解决,使子进程抛弃自己原来的代码和数据,加载一个全新的程序到内存中。
进程替换:通过特定的接口,用一个新程序,替换当前进程的代码段、数据段、堆栈段,进程的PID不变,PPID、文件描述符等属性保持不变。
注意:
1.PID不改变
2.程序完全替换
3.没有创建新进程,只是换程序执行
进程替换函数
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char * const envp\[\]);
int execv(const char *path, char *const argv\[\]);
int execvp(const char *file, char *const argv\[\]);
int execvpe(const char *file, char *const argv\[\], char *const envp\[\]);
注意,argv数组必须以NULL为结尾,否则会导致越界访问
理解进程替换函数的返回值
1.这些函数如果调用新程序成功,则加载新的程序从新的程序的启动代码开始执行,不再返回,exec后面的代码不会被执行
2.如果调用出错,则返回-1,继续执行后面的代码
3.exec系列函数只有出错的返回值,没有成功的返回值
cpp
// 正确写法:必须处理 exec 失败的情况
execl("/bin/ls", "ls", "-al", NULL);
// 只有 exec 失败,才会执行下面两行
perror("execl 调用失败");
// 必须主动退出,否则会继续执行原程序代码
exit(1); 快速记忆进程替换函数
l(list):表示参数采用列表
v(vector):参数采用数组
p(path):表示自动搜索环境变量PATH(也支持全路径的写法)
e(env):表示自己维护环境变量
cpp
#include <unistd.h>
int main()
{
char *const argv[] = {"ls", "-al", NULL};
char *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};
// 列表形式传参
execl("/bin/ls", "ls", "-al", NULL);
// 带p的,可以使用环境变量PATH,无需写全路径
execlp("ls", "ls", "-al", NULL);
// 带e的,需要自己手动传递环境变量
execle("/bin/ls", "ls", "-al", NULL, envp);
// 数组形式传参
execv("/bin/ls", argv);
execvp("ls", argv);
execvpe("/bin/ls", argv, envp);
return 0;
}你可能会好奇:为什么会有6个exec系列函数呢?
实际上,只有execve()是Linux内核提供的真正系统调用,上述6个函数均为C库提供的封装,它们的底层都会调用execve()。
系统调用函数 execve
NAME
execve - execute program
SYNOPSIS
#include <unistd.h>
int execve(const char *filename, char *const argv\[\], char *const envp\[\]);
Shell的底层原理
Shell 本质是一个死循环程序,它会一直重复以下流程。
读入用户输入的命令 -> 对读入的命令进行解析 -> 判断是否为内建命令(如果是内建命令则执行) ->
创建子进程执行外部命令 -> 子进程发生进程替换 -> 等待子进程 -> 回到循环开头,等待下一条命令输入
内建命令(如 cd、exit、echo等):这类命令直接在Shell进程内执行,不需要创建新进程。
外部命令(如 ls、ps、gcc等):这些命令是独立的可执行文件,Shell会通过创建子进程,再用exec系列函数实现进程替换。