PyTorch强化学习实战(8)------Q学习详解与实现
0. 前言
我们已经学习了贝尔曼方程 (Bellman equation) 及其实际应用方法,价值迭代法(value iteration)。通过这种方法,我们显著提高了在 FrozenLake 环境中的训练速度和收敛性。在本节中,我们将使用相同的方法来处理复杂度更高的任务:来自 Atari 2600 平台的街机游戏,这些游戏已成为强化学习研究领域事实上的基准测试。
1. 价值迭代的局限性
从交叉熵方法转向价值迭代法为 FrozenLake 环境带来了显著的性能提升,接下来我们将价值迭代法应用于更具挑战性的问题。但在实现之前,我们必须了解该方法的前提假设与局限性。
因此将值迭代方法应用于更具挑战性的问题似乎很有吸引力。然而,重要的是要审视我们值迭代方法的假设和限制。我们先快速回顾其原理:价值迭代法在每个步骤中遍历所有状态,并通过贝尔曼近似更新各状态价值。其Q值(动作价值)版本原理相似,只是改为存储和更新每个状态-动作对的价值。
首要问题在于环境状态数量及其遍历可行性。价值迭代要求我们预先知晓所有可能状态、能够遍历这些状态,并能存储其价值估计。对于 FrozenLake 这样的简单网格世界尚可实现,接下来,考虑面对更复杂任务的表现。
我们需要评估价值迭代方法的可扩展性------即单次循环中能高效处理的状态数量上限。现代计算机的内存已能轻松存储数十亿浮点数值,因此价值表的内存占用并非主要瓶颈。遍历数十亿个状态和动作虽然会对中央处理单元 (CPU) 造成较大需求,但这并不是不可克服的问题。
多核系统大多数时间处于空闲状态,因此通过并行化,我们可以在合理的时间内遍历数十亿个值。真正的问题是,为了获得好的状态转移动态近似,我们需要大量的样本。假设有一个环境包含大约十亿个状态(这大致相当于一个 31600 × 31600 大小的 FrozenLake)。即便只是为这个环境的每个状态计算一个粗略的近似值,我们也需要数千亿次的状态转移,而且还必须均匀分布在所有状态上,这在现实中是不可行的。
举一个更极端的例子, Atari 2600 游戏机,提供了许多街机风格的游戏。按照今天的游戏标准,Atari 游戏机显得十分落后,但它的游戏却为强化学习提供了极佳的测试环境:人类玩家能很快上手,但对计算机来说仍具有挑战性,这个平台在强化学习研究中是非常受欢迎的基准测试。
计算 Atari 平台的状态空间。屏幕分辨率为 210 × 160 像素,每个像素有 128 种颜色。因此,每一帧画面有 210 × 160 = 33600 个像素,不同屏幕画面的总数量为 12833600,如果我们尝试枚举 Atari 的所有可能状态,即使是最快的超级计算机,也需要数以亿年计的时间才能完成。且 99.9% 的状态在实际游戏中根本不会出现,因此我们也不可能采集到这些状态的样本。然而,价值迭代 (value iteration) 法为了"以防万一"仍会遍历它们。
价值迭代方法的第二个主要问题是,该方法仅适用于离散动作空间。无论是 Q ( s , a ) Q(s,a) Q(s,a) 还是 V ( s ) V(s) V(s) 估计,都要求动作是互斥的离散集合,这对于连续控制问题来说并不适用。在连续控制问题中,动作可以表示连续变量,如方向盘转角、加热器温度等连续控制问题。该问题比状态空间问题更具挑战性,我们将在后续学习中专门探讨连续动作空间的问题。目前,假设我们有一个离散的动作数量,且动作数量级在数十个以内,接下来,我们介绍如何处理在此前提下的状态空间规模问题。
2. 表格Q学习
在应对状态空间问题时,关键问题是,我们是否真的需要遍历状态空间中的每个状态?环境本身就能为我们提供真实的状态样本。如果某个状态从未在环境中出现,我们何必关注其价值?只需利用从环境中获取的状态来更新状态价值,就能大幅减少工作量。
这种对价值迭代法的改进就是Q学习,对于那些有明确状态到价值映射的情况,它包括以下步骤:
- 创建空表,建立状态到动作价值的映射
- 通过与环境交互获取四元组 ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′)------即状态、动作、奖励和新状态。在这一步中,需要决定采取哪个动作
- 使用贝尔曼近似更新 Q ( s , a ) Q(s,a) Q(s,a) 值:
Q ( s , a ) ← r + γ max a ′ ∈ A Q ( s ′ , a ′ ) Q(s, a) \leftarrow r + \gamma \max_{a'\in A} Q(s', a') Q(s,a)←r+γa′∈AmaxQ(s′,a′) - 从步骤
2开始重复
与价值迭代类似,终止条件可以是更新阈值,也可以通过测试回合评估策略的预期奖励。需特别注意Q值的更新方式:直接从环境样本覆盖旧值会导致训练不稳定。实践中通常采用"混合"技术进行渐进式更新,即通过 0 到 1 之间的学习率 α α α 对新旧Q值取加权平均:
Q ( s , a ) ← ( 1 − α ) Q ( s , a ) + α ( r + γ max a ′ Q ( s ′ , a ′ ) ) Q(s, a) \leftarrow (1 - \alpha) Q(s, a) + \alpha \left( r + \gamma \max_{a'} Q(s', a') \right) Q(s,a)←(1−α)Q(s,a)+α(r+γa′maxQ(s′,a′))
这样即使环境存在噪声,Q值也能够平稳收敛。算法的最终版本如下:
- 初始化空 Q ( s , a ) Q(s,a) Q(s,a) 表
- 从环境中获取 ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′)
- 执行贝尔曼更新:
Q ( s , a ) ← ( 1 − α ) Q ( s , a ) + α ( r + γ max a ′ ∈ A Q ( s ′ , a ′ ) ) Q(s, a) \leftarrow (1 - \alpha) Q(s, a) + \alpha (r + \gamma \max_{a'\in A} Q(s', a')) Q(s,a)←(1−α)Q(s,a)+α(r+γa′∈AmaxQ(s′,a′)) - 检查收敛条件,未满足从步骤
2开始重复
该方法被称为表格Q学习,因为需要维护状态及其Q值的表格。接下来,在 FrozenLake 环境中进行测试。
3. 实现表格Q学习
(1) 首先,导入所需库,并定义常量及类型:
python
import typing as tt
import gymnasium as gym
from collections import defaultdict
from torch.utils.tensorboard.writer import SummaryWriter
ENV_NAME = "FrozenLake-v1"
GAMMA = 0.9
ALPHA = 0.2
TEST_EPISODES = 20
State = int
Action = int
ValuesKey = tt.Tuple[State, Action]
class Agent:
def __init__(self):
self.env = gym.make(ENV_NAME)
self.state, _ = self.env.reset()
self.values: tt.Dict[ValuesKey] = defaultdict(float)α α α 值将作为学习率用于价值更新。我们的 Agent 类初始化现在更简单,因为不再需要追踪奖励历史和状态转移计数器,只需维护价值表。这将减少内存占用------虽然对 FrozenLake 环境影响不大,但在更大规模的环境中可能至关重要。
(2) sample_env() 方法用于从环境中获取下一个状态转移样本:
python
def sample_env(self) -> tt.Tuple[State, Action, float, State]:
action = self.env.action_space.sample()
old_state = self.state
new_state, reward, is_done, is_tr, _ = self.env.step(action)
if is_done or is_tr:
self.state, _ = self.env.reset()
else:
self.state = new_state
return old_state, action, float(reward), new_state我们从动作空间中随机采样一个动作,并返回包含旧状态、采取的动作、获得的奖励以及新状态的元组。该元组将在后续训练循环中使用。
(3) best_value_and_action() 方法接收环境的状态:
python
def best_value_and_action(self, state: State) -> tt.Tuple[float, Action]:
best_value, best_action = None, None
for action in range(self.env.action_space.n):
action_value = self.values[(state, action)]
if best_value is None or best_value < action_value:
best_value = action_value
best_action = action
return best_value, best_action该方法通过选择价值表中对应动作的最大值,来确定当前环境状态下应采取的最佳动作。若状态-动作对尚未存储对应价值,则默认取零值。该方法将应用于两个场景:其一是在测试方法中(基于当前价值表运行完整回合以评估策略质量),其二是在执行价值更新的方法中(用于获取下一状态的价值)。
(4) 接下来,利用环境交互的单步数据来更新价值表:
python
def value_update(self, state: State, action: Action, reward: float, next_state: State):
best_val, _ = self.best_value_and_action(next_state)
new_val = reward + GAMMA * best_val
old_val = self.values[(state, action)]
key = (state, action)
self.values[key] = old_val * (1-ALPHA) + new_val * ALPHA这里我们首先通过即时奖励与下一状态折现价值之和,计算出当前状态 s s s 与动作 a a a 的贝尔曼近似值。随后获取该状态-动作对的原有价值,并通过学习率混合新旧价值。最终得到的更新值将作为状态 s s s 与动作 a a a 的新价值存入表格。
(5) Agent 类的 play_episode() 方法使用测试环境运行完整回合:
python
def play_episode(self, env: gym.Env) -> float:
total_reward = 0.0
state, _ = env.reset()
while True:
_, action = self.best_value_and_action(state)
new_state, reward, is_done, is_tr, _ = env.step(action)
total_reward += reward
if is_done or is_tr:
break
state = new_state
return total_reward每一步的动作都基于当前的Q值表进行选择。该方法用于评估当前策略,以检验学习进度。需要注意的是,此方法不会修改Q值表,仅根据现有表格选择最优动作。
(6) 实现训练循环。创建测试环境、智能体和记录器,然后在循环中执行环境交互步骤,并利用获得的数据更新Q值。随后通过运行多个测试回合来评估当前策略。若获得满意奖励,则终止训练:
python
if __name__ == "__main__":
test_env = gym.make(ENV_NAME)
agent = Agent()
writer = SummaryWriter(comment="-q-learning")
iter_no = 0
best_reward = 0.0
while True:
iter_no += 1
state, action, reward, next_state = agent.sample_env()
agent.value_update(state, action, reward, next_state)
test_reward = 0.0
for _ in range(TEST_EPISODES):
test_reward += agent.play_episode(test_env)
test_reward /= TEST_EPISODES
writer.add_scalar("reward", test_reward, iter_no)
if test_reward > best_reward:
print("%d: Best test reward updated %.3f -> %.3f" % (iter_no, best_reward, test_reward))
best_reward = test_reward
if test_reward > 0.80:
print("Solved in %d iterations!" % iter_no)
break
writer.close()输出结果如下所示:

可以看到,相较于价值迭代法,Q学习需要更多迭代次数来解决问题。这是因为我们不再利用测试阶段获得的经验,定期测试会触发Q表统计数据的更新;而当前版本在测试期间不修改Q值,导致环境求解需要更多的迭代。
从整体来看,两种方法所需的环境样本总量基本相当。TensorBoard 中的奖励曲线也显示了良好的训练动态,这与价值迭代法的表现高度相似:
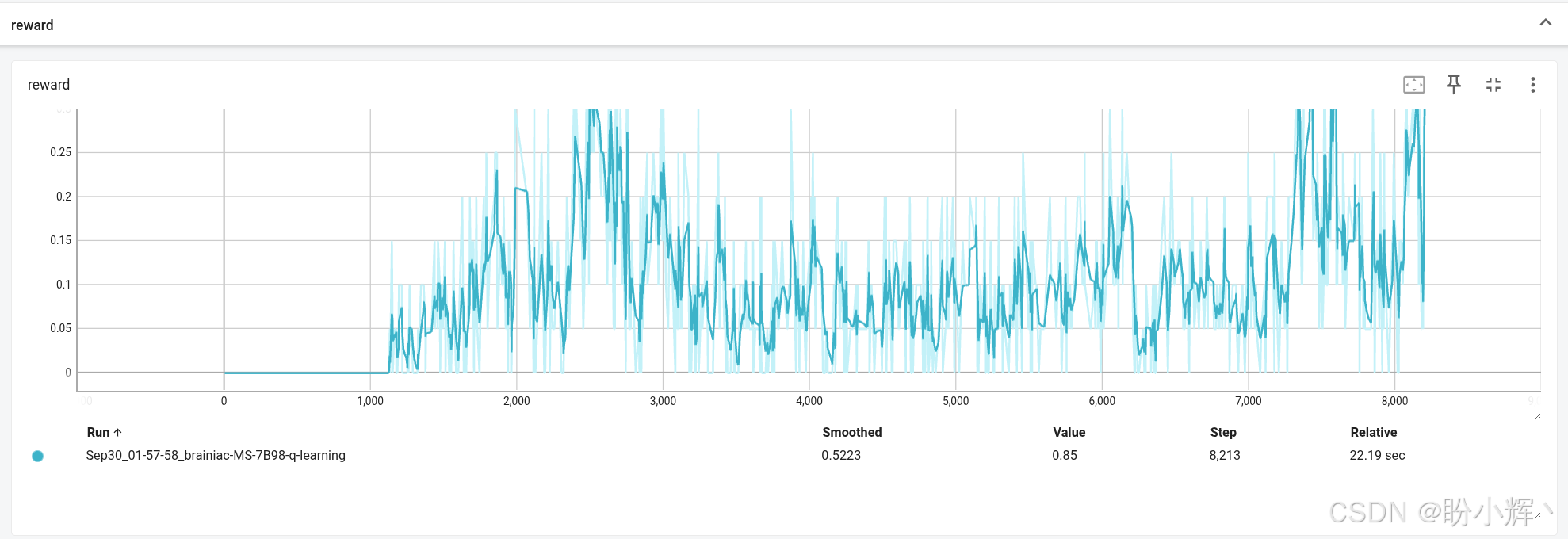
小结
在本节中,我们了解了价值迭代算法在具有庞大观测空间的复杂环境中的局限性,并学习了如何通过Q学习算法来克服这些限制。通过在 FrozenLake 环境中的实践验证了Q学习算法,同时深入讨论了如何利用神经网络近似Q值,以及这种近似方法带来的额外复杂性。
系列链接
PyTorch强化学习实战(1)------强化学习(Reinforcement Learning,RL)详解
PyTorch强化学习实战(2)------强化学习环境库Gymnasium
PyTorch强化学习实战(3)------Gymnasium API扩展功能
PyTorch强化学习实战(4)------PyTorch基础
PyTorch强化学习实战(5)------PyTorch Ignite 事件驱动机制与实践
PyTorch强化学习实战(6)------交叉熵方法详解与实现
PyTorch强化学习实战(7)------表格学习与贝尔曼方程