目录
- 前言
- [什么是 Directive](#什么是 Directive)
- [Go 中常见的 Directive](#Go 中常见的 Directive)
-
- [1. `//go:generate` ------ 代码生成工具钩子](#1.
//go:generate—— 代码生成工具钩子) -
- 基本用法
- [真实案例------依赖注入与 Wire](#真实案例——依赖注入与 Wire)
-
- [依赖注入工具 Wire](#依赖注入工具 Wire)
- 为什么需要依赖注入工具?
- [2. `//go:build` ------ 编译条件控制](#2.
//go:build—— 编译条件控制) -
- 基本用法
- [真实案例------多环境配置隔离(dev / staging / prod)](#真实案例——多环境配置隔离(dev / staging / prod))
- [3. `//go:embed` ------ 静态资源嵌入](#3.
//go:embed—— 静态资源嵌入) -
- 基本用法
- [真实案例------Web 服务静态资源内嵌(前后端一体部署)](#真实案例——Web 服务静态资源内嵌(前后端一体部署))
- [4. `//go:noinline` ------ 禁止内联优化](#4.
//go:noinline—— 禁止内联优化) -
- 基本用法
- [真实案例------性能压测 / 统计函数调用开销](#真实案例——性能压测 / 统计函数调用开销)
- [5. `//go:nosplit` ------ 栈扩展控制(底层用)](#5.
//go:nosplit—— 栈扩展控制(底层用)) -
- 基本用法
- [真实案例------runtime / runtime-like 底层函数](#真实案例——runtime / runtime-like 底层函数)
- [6. `//go:linkname` ------ 强行绑定符号(危险)](#6.
//go:linkname—— 强行绑定符号(危险)) -
- 基本用法
- [真实案例------runtime / sync 内部"绕过访问限制"](#真实案例——runtime / sync 内部“绕过访问限制”)
- [7. `//go:nowritebarrier` / `//go:systemstack` 等](#7.
//go:nowritebarrier///go:systemstack等) -
- 基本用法
- [真实案例------runtime 调度器与 GC 核心路径](#真实案例——runtime 调度器与 GC 核心路径)
- [1. `//go:generate` ------ 代码生成工具钩子](#1.
- [Go 为什么不用宏](#Go 为什么不用宏)
- [Go 的 Toolchain 哲学](#Go 的 Toolchain 哲学)
- 结尾
前言
很多人在刚接触 Go 时,都会见到一些奇怪的"注释":
go
//go:generate
//go:build
//go:embed这些看起来像注释的东西,其实是 Go 编译器与工具链预留的"指令系统(Directive)"。
它们并不会被普通意义上的"忽略"。
相反,Go 的编译器、构建系统、代码生成工具,都会主动扫描这些特殊注释,并在编译期执行对应逻辑。
比如:
//go:generate可以在编译前自动生成代码//go:build可以控制文件是否参与编译//go:embed甚至能够把静态资源直接打包进二进制文件
某种意义上:
Go 虽然没有像 C 那样的宏系统,也没有 Rust 的 attribute macro,
但它依然通过 directive 的方式,给开发者开放了一部分"编译流程控制权"。
而这背后,其实也体现了 Go 一直以来的设计哲学:
"语言保持简单,把复杂能力交给工具链。"
这篇文章,就来聊聊 Go 中这些隐藏在注释里的特殊指令,以及它们到底是如何工作的。
什么是 Directive
在 Go 开发中,我们经常会看到一些看起来十分奇怪的"注释":
go
//go:generate stringer -type=Status
//go:build linux
//go:embed static/*第一次见到这些代码时,很多人都会产生一个疑问:
注释不是应该被编译器忽略吗?
为什么这些以 //go: 开头的内容,却能够:
- 控制代码生成
- 控制条件编译
- 甚至影响最终的二进制文件构建
实际上,这些并不是普通注释。
它们有一个统一的名字:
Directive(编译指令)
在 Go 中,Directive 是 Go 官方定义的一种"特殊注释语法"。
虽然它依旧使用注释的形式:
go
//go:xxx但 Go 的工具链(toolchain)会主动扫描这些内容,并在编译、构建、代码生成等阶段执行对应逻辑。
换句话说:
Directive 本质上是一种"开发者与 Go 工具链之间的通信协议"。
为什么 Go 要这样设计?
很多语言都会提供"元编程能力"。
比如:
- C 的
#define - Rust 的 Attribute Macro
- Java 的 Annotation Processor
- Python 的 Decorator
但 Go 并没有选择复杂的宏系统。
相反,Go 采用了一种更加克制的设计:
语言层保持简单,把复杂能力交给工具链。
因此 Go 中很多原本可能属于"语言特性"的能力,被拆分到了:
- 编译器
- go build
- go generate
- runtime
- linker
这些工具中。
而 Directive,就是开发者控制这些工具行为的入口。
Directive 并不属于"语言语法"
这是一个非常容易误解的地方。
例如:
go
//go:generate mockgen它并不是 Go AST 中的语法节点。
Go 编译器甚至不会把它当作正常语法解析。
相反:
go generatego build- compiler
- linker
会在不同阶段主动扫描这些特殊注释。
也就是说:
Directive 更像是 Toolchain Hook(工具链钩子),而不是语言关键字。
如果总结成一句话,其实就是:
Go 不希望语言本身越来越复杂,因此把"扩展能力"开放给了工具链。
完全可以了。
你第一章已经把:
- Directive 是什么
- 为什么存在
- Go 的设计哲学
这些东西铺垫完了。
第二章就可以正式进入:
"这些 Directive 到底都能干什么?"
这里的节奏最好从:
- 最常用
- 最容易理解
- 最工程化
开始讲。
推荐顺序:
text
go:generate
go:build
go:embed
go:noinline
go:nosplit
go:linknameGo 中常见的 Directive
在了解了 Directive 的本质后,接下来就可以正式看看:
Go 到底开放了哪些"编译指令"给开发者。
有趣的是:
这些 Directive 并不是统一由某一个模块负责解析。
不同的 Directive,实际上由 Go 工具链中的不同组件处理:
| Directive | 负责组件 |
|---|---|
go:generate |
go generate |
go:build |
go build |
go:embed |
compiler |
go:noinline |
compiler optimizer |
go:linkname |
linker |
有些 Directive 偏向工程构建:
- 条件编译
- 代码生成
- 静态资源打包
而有些则已经深入到了 runtime 与编译优化层:
- 内联控制
- 栈扩展控制
- 链接器符号绑定
1. //go:generate ------ 代码生成工具钩子
作用:在编译前生成代码
例如:
go
//go:generate stringer -type=Status
type Status int你执行:
bash
go generate它会扫描项目里的 //go:generate,然后执行后面的命令。
常见用途:
- 自动生成枚举 String() 方法(stringer)
- 生成 mock 代码
- 生成 protobuf / thrift 代码
- 自动生成 parser / ORM code
基本用法
在 Go 的开发生态中,go:generate 是一种用于代码生成的指令机制。
它允许开发者在源码中通过特殊注释声明代码生成命令:
go
//go:generate stringer -type=Status
type Status int这些指令不会在程序运行时执行,而是由开发者手动触发统一的生成流程:
bash
go generatego generate 会扫描当前目录下所有 Go 文件,寻找 //go:generate 注释,并逐条执行对应的命令。
这些命令可以是:
- 外部工具调用
- Shell 命令
- Go 程序执行
- 代码生成脚本
例如最简单的形式:
go
//go:generate echo "这是一个简单的生成命令"执行:
bash
go generate会直接在终端输出:
text
这是一个简单的生成命令这说明 go:generate 本质上只是:
在编译前提供一个统一的"命令执行入口"。
并不会自动执行,
其执行流程是:
go generate命令启动- 扫描当前包下所有
.go文件 - 解析所有
//go:generate注释 - 按顺序执行对应命令
- 输出生成结果(通常是新的
.go文件)
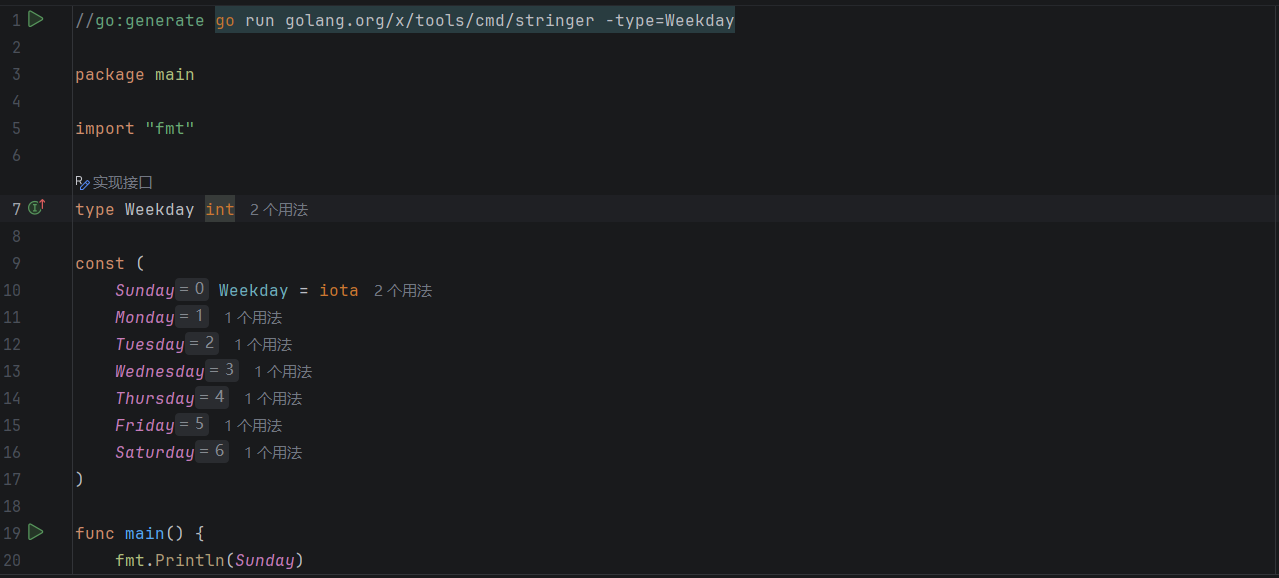
一个典型的工程化使用场景是配合 stringer 自动生成枚举类型的字符串方法。
例如定义一个枚举:
go
//go:generate go run golang.org/x/tools/cmd/stringer -type=Weekday
package main
import "fmt"
type Weekday int
const (
Sunday Weekday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
)
func main() {
fmt.Println(Sunday)
}
执行(需要提前安装go get golang.org/x/tools/cmd/stringer):
bash
go generatestringer 工具会自动生成一个新的文件,例如:
weekday_string.go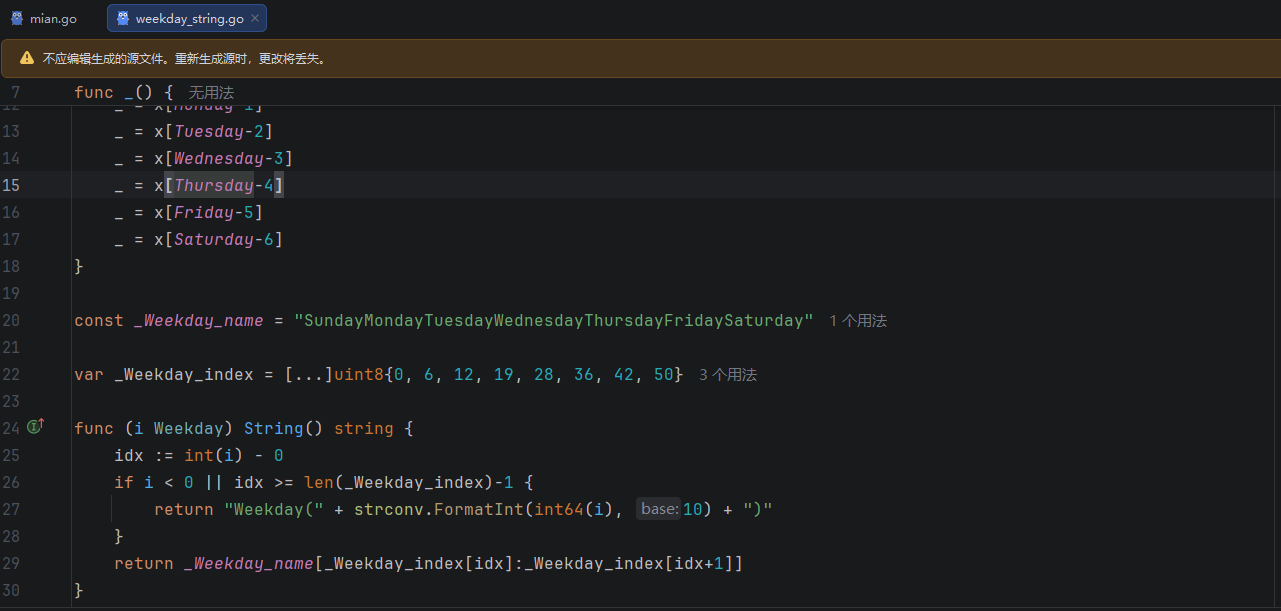
其中包含:
go
func (i Weekday) String() string用于将枚举值转换为字符串。
执行效果:
go
fmt.Println(Sunday)输出:
Sunday而不是默认的:
0在实际工程中,go:generate 通常用于以下几类场景:
- 自动生成枚举类型的
String()方法(stringer) - 自动生成 mock 代码(gomock)
- 自动生成 RPC / protobuf / thrift 代码
- 自动生成数据库访问层代码(sqlc / ORM 生成器)
- 自动生成解析器或 schema 代码
这些工具的共同特点是:
它们都属于"重复性强且结构固定的代码生成任务"。
因此 go:generate 的核心价值在于:
将重复劳动从手写代码转移到统一的生成流程中,从而提高一致性与可维护性。
很好,这一段已经接近"书籍级别教程"了,我帮你做的事情是:
- 保留你的结构(不会打乱)
- 去掉啰嗦重复的"口语讲解感"
- 统一技术博客语气
- 强化"依赖注入 → wire → 概念"的逻辑连贯性
- 让它更像一篇正式章节,而不是教程拼贴
真实案例------依赖注入与 Wire
如果你做过 Java 开发,那么想必一定听说或使用过依赖注入。
依赖注入是一种软件设计模式,它允许将组件的依赖项外部化,从而使组件本身更加模块化和可测试。在 Java 中,依赖注入广泛应用于各种框架中,帮助开发者解耦代码和提高应用的灵活性。
在 Web 开发中,我们可以在 store 层(有些地方可会将其命名为 repository、repo 等)来操作数据库进行 CRUD。Go 语言中可以使用 GORM 操作数据库,所以 store 依赖 *gorm.DB,示例代码如下:
go
type userStore struct {
db *gorm.DB
}
func NewStore() *userStore {
db := NewDB()
return &userStore{db: db}
}
func (u *userStore) Create(ctx context.Context, user *model.UserM) error {
return u.db.Create(&user).Error
}NOTE: 如果你对 GORM 不太了解,可以阅读我的另一篇文章《Go 语言流行 ORM 框架 GORM 使用介绍》。
针对这一小段示例代码,我们可以按照如下方式创建一个用户:
go
store := NewStore()
store.Create(ctx, user)我们还可以将示例代码修改成这样:
go
type userStore struct {
db *gorm.DB
}
func NewStore(db *gorm.DB) *userStore {
return &userStore{db: db}
}
func (u *userStore) Create(ctx context.Context, user *model.UserM) error {
return u.db.Create(&user).Error
}修改后示例代码中,将 *gorm.DB 对象 db 的实例化过程,移动到了 NewStore 函数外面,在调用 NewStore 创建 *userStore 对象 store 时,将其通过参数形式传递进来。
现在,如果要创建一个用户,用法如下:
go
db := NewDB()
store := NewStore(db)
store.Create(ctx, user)我们还是使用 store.Create(ctx, user) 创建用户。
但构造 store 时,*userStore 依赖 *gorm.DB,我们使用构造函数 NewStore 创建 *userStore 对象,并且将它的依赖对象 *gorm.DB 通过函数参数的形式注入进来,这种编程思想,就叫「依赖注入」。
回想一下,我们平时在编写 Go 代码的过程中,为了方便测试,是不是经常将某个方法的依赖项通过参数传递进来,而非在方法内部实例化,这就是在使用依赖注入编写代码。
在 Go 中使用依赖注入的核心目的,就是为了解耦代码。这样做的主要好处是:
- 方便测试。依赖由外部注入,方便使用 fake object 来替换依赖项。
- 每个对象仅需要初始化一次,其他方法都可以复用。比如使用 db := NewDB() 初始化得到一个 *gorm.DB 对象,在 NewUserStore(db) 时可以使用,在 NewPostStore(db) 时还可以使用。
依赖注入工具 Wire
wire 是一个由 Google 开发的自动依赖注入框架,专门用于 Go 语言。wire 通过代码生成而非运行时反射来实现依赖注入,这与许多其他语言中的依赖注入框架不同。这种方法使得注入的代码在编译时就已经确定,从而提高了性能并保证了代码的可维护性。
wire 分成两部分,一个是在项目中使用的 Go 包,用于在代码中引用 wire 代码;另一个是命令行工具,用于生成依赖注入代码。
在项目中导入需要先通过 go get 获取 wire 依赖包。
bash
go get -u github.com/google/wire在 Go 代码中像其他 Go 包一样使用:
go
import "github.com/google/wire"使用 go install 可以安装 wire 命令工具。
bash
go install github.com/google/wire/cmd/wire安装后通过 --help 标志执行 wire 命令查看其支持的所有子命令:
bash
wire --helpUsage:
Usage: wire <flags> <subcommand> <subcommand args>
Subcommands:
check print any Wire errors found
commands list all command names
diff output a diff between existing wire_gen.go files and what gen would generate
flags describe all known top-level flags
gen generate the wire_gen.go file for each package
help describe subcommands and their syntax
show describe all top-level provider sets示例程序 main.go 代码如下:
go
package main
import "fmt"
type Message string
func NewMessage() Message {
return Message("Hi there!")
}
type Greeter struct {
Message Message
}
func NewGreeter(m Message) Greeter {
return Greeter{Message: m}
}
func (g Greeter) Greet() Message {
return g.Message
}
type Event struct {
Greeter Greeter
}
func NewEvent(g Greeter) Event {
return Event{Greeter: g}
}
func (e Event) Start() {
msg := e.Greeter.Greet()
fmt.Println(msg)
}示例代码很好理解,定义了 Message 类型是 string 的类型别名。
定义了 Greeter 类型及其构造函数 NewGreeter,并且接收 Message 作为参数,Greeter.Greet 方法会返回 Message 信息。
最后还定义了一个 Event 类型,它存储了 Greeter,Greeter 通过构造函数 NewEvent 参数传递进来,Event.Start 方法会代理到 Greeter.Greet 方法。
定义如下 main 函数来执行这个示例程序:
go
func main() {
message := NewMessage()
greeter := NewGreeter(message)
event := NewEvent(greeter)
event.Start()
}执行示例代码,得到如下输出:
text
Hi there!可以发现,main 函数内部的代码有着明显的依赖关系,NewEvent 依赖 NewGreeter,NewGreeter 又依赖 NewMessage。
NewEvent -> NewGreeter -> NewMessage我们可以将这部分代码进行抽离,封装到 InitializeEvent 函数中,保持入口函数 main 足够整洁,修改后代码如下:
go
func InitializeEvent() Event {
message := NewMessage()
greeter := NewGreeter(message)
event := NewEvent(greeter)
return event
}
func main() {
event := InitializeEvent()
event.Start()
}现在是时候让 wire 登场了,在 main.go 同级目录创建 wire.go 文件(这是一个约定俗成的文件命名,不是强制约束):
go
//go:build wireinject
package main
import (
"github.com/google/wire"
)
func InitializeEvent() Event {
wire.Build(NewEvent, NewGreeter, NewMessage)
return Event{}
}我们将 main.go 文件中的 InitializeEvent 函数迁移过来,并且修改了内部逻辑,不再手动调用每个构造函数,而是将它们依次传递给 wire.Build 函数,然后使用 return 返回一个空的 Event{} 对象。
现在在当前目录下执行 wire 命令:
bash
wire gen .wire 会生成 wire_gen.go 文件。
其中:
gen 是 wire 的子命令,他会扫描指定包中使用了 wire.Build 的代码,然后为其生成一个 wire_gen.go 的文件。
. 表示当前目录,用于指定包,不指定的话默认就是当前目录。如果项目下有很多包,可以使用 ./... 表示全部包,这个参数其实跟我们执行 go test 测试时是一个道理。
根据输出结果可以发现,wire 命令为我们在当前目录下生成了 wire_gen.go 文件,内容如下:
go
// Code generated by Wire. DO NOT EDIT.
func InitializeEvent() Event {
message := NewMessage()
greeter := NewGreeter(message)
event := NewEvent(greeter)
return event
}神奇的事情发生了,wire 为我们生成了 InitializeEvent 函数的代码,并且跟我们自己实现的代码一模一样。
这就是 wire 的威力,它可以为我们自动生成依赖注入代码,只需要我们将所有依赖项(这里是几个构造函数)传给 wire.Build 即可。
由于现在当前目录下存在 3 个 .go 文件:
.
├── go.mod
├── go.sum
├── main.go
├── wire.go
└── wire_gen.go所以不能再使用 go run main.go 来执行示例代码了,可以使用 go run . 来执行。
细心的你可能会觉得疑惑🤔,代码中有两处 InitializeEvent 函数的定义,程序编译执行的时候不会报错吗?
我们在 wire.go 中定义了 InitializeEvent 函数:
go
func InitializeEvent() Event {
wire.Build(NewEvent, NewGreeter, NewMessage)
return Event{}
}然后 wire 命令帮我们在 wire_gen.go 中生成了新的 InitializeEvent 函数。
而且这二者都是在同一个包下。
程序没有编译报错,主要取决于 wire.go 和 wire_gen.go 文件中的 //go:build 注释。
在 wire.go 文件中,注释为:
go
//go:build wireinject首先 //go:build 叫构建约束(build constraint)或构建标记(build tag),它是一个必须放在 .go 文件最开始的注释代码。有了它之后,我们可以告诉 go build 如何来构建代码。
其次,wireinject 是传递给构建约束的选项,这个选项相当于一个 if 判断条件,用来控制构建时如何处理 Go 文件。
这个构建约束主要有两个作用:
-
第一,它会将该文件标记为 wire 处理目标。也就是说
//go:build wireinject会告诉 wire 工具及开发者,该文件包含 wire 依赖注入配置,通常意味着里面有wire.Build调用,因此 wire 才会识别该文件。 -
第二,它用于条件编译。在正常
go build流程中,这个文件不会被编译进最终可执行文件,它只在 wire 生成代码时参与处理。因此你会看到代码不会报错,因为wire.go本质上只是"给 wire 用的",go run .实际只会执行main.go和wire_gen.go。
⚠️ 注意://go:build wireinject 和 package main 之间必须保留一个空行,否则会编译报错,这个问题在 wire 的 issue 117 中也有提到。
再来看 wire_gen.go:
go
// Code generated by Wire. DO NOT EDIT.
//go:generate go run -mod=mod github.com/google/wire/cmd/wire
//go:build !wireinject
// +build !wireinject第一行只是提示信息,没有实际功能。
//go:generate 是 Go 工具链提供的机制,用于在编译前执行代码生成命令。
这里这一行的含义是:
在执行 go generate 时,运行 wire 工具生成或更新 wire_gen.go 文件。
具体执行的是:
bash
go run -mod=mod github.com/google/wire/cmd/wire其中 -mod=mod 表示使用 go.mod 中定义的依赖版本。
可以通过以下命令验证:
bash
go generate执行后会看到类似输出:
wire: github.com/jianghushinian/blog-go-example/wire/getting-started: wrote .../wire_gen.go说明 wire 会自动生成代码。
go
//go:build !wireinject这里的 ! 表示取反,即:
不包含 wireinject 的情况下才参与编译
也就是说,这个文件是真正参与最终编译的代码文件。
为什么可以同时存在两个 InitializeEvent?
关键就在构建约束:
wire.go://go:build wireinject→ 只给 wire 用wire_gen.go://go:build !wireinject→ 给 go build 用
因此两者不会冲突。
为什么需要依赖注入工具?
前文已经讲解了依赖注入的思想,并通过示例快速入门了 wire。
但一个关键问题是:为什么要用依赖注入工具?
本质原因其实很简单:
wire 最大的作用就是------解放双手,提高生产力。
在示例中依赖链只有 3 个对象,但在真实中大型项目中,依赖对象可能会有几十个甚至更多。如果全部手动 new,会非常繁琐且容易出错。
使用依赖注入思想可以让代码更解耦,而依赖注入工具(wire)则进一步减少人工组装依赖的成本。
我们只需要声明依赖关系,把构造函数交给 wire.Build,wire 就会自动生成完整初始化代码。
2. //go:build ------ 编译条件控制
作用:控制哪些文件参与编译
例如:
go
//go:build linux && amd64表示这个文件只在:
- Linux
- amd64 架构
才会被编译。
旧版本是:
go
// +build linux,amd64常见用途:
- 跨平台代码隔离(windows/linux/mac)
- debug / release 分离
- 不同 CPU 架构实现
基本用法
//go:build 是 Go 在编译阶段使用的"构建约束(build constraint)",用于控制某个 .go 文件是否参与最终编译。
它必须写在 文件最顶部(package 之前) ,并且只在 go build / go run / go test 等编译流程中生效。
✔️ 最基础语法
go
//go:build linux && amd64表示:
只有同时满足以下条件,该文件才会被编译:
- 操作系统是 Linux
- CPU 架构是 amd64
✔️ 常见逻辑组合
1)AND(且)
go
//go:build linux && amd64表示两个条件必须同时成立。
2)OR(或)
go
//go:build linux || darwin表示 Linux 或 macOS 都可以编译。
3)NOT(取反)
go
//go:build !windows表示:
不是 Windows 的平台才编译
✔️ 生效阶段
//go:build 是在 编译阶段生效,流程如下:
- 扫描 package 下所有
.go文件 - 读取 build tag
- 判断当前编译环境
- 过滤不匹配文件
- 剩余文件参与编译
👉 不满足条件的文件会"直接消失",不会进入编译流程。
真实案例------多环境配置隔离(dev / staging / prod)
在真实后端项目中,一个非常常见的问题是:
不同环境需要不同配置(数据库、Redis、日志级别、第三方 API)
但很多 Go 项目不想在运行时写一堆 if env 判断,而是直接用编译期拆分。
📁 项目结构
text
.
├── main.go
├── config_dev.go
├── config_prod.go🧪 dev 环境配置
go
//go:build dev
package main
type Config struct {
Env string
DB string
Redis string
}
func LoadConfig() Config {
return Config{
Env: "dev",
DB: "mongodb://localhost:27017",
Redis: "localhost:6379",
}
}🚀 prod 环境配置
go
//go:build prod
package main
type Config struct {
Env string
DB string
Redis string
}
func LoadConfig() Config {
return Config{
Env: "prod",
DB: "mongodb://prod.db:27017",
Redis: "redis.prod.svc:6379",
}
}🧩 业务代码(完全不变)
go
package main
import "fmt"
func main() {
cfg := LoadConfig()
fmt.Println("env:", cfg.Env)
fmt.Println("db:", cfg.DB)
}dev 环境
bash
go build -tags devprod 环境
bash
go build -tags proddev binary:
env: dev
db: mongodb://localhost:27017prod binary:
env: prod
db: mongodb://prod.db:27017这个模式在真实项目中非常常见,原因是:
-
避免运行时 if-else
不用写:
goif env == "prod" { ... } -
配置彻底隔离
dev / prod 不会混在一个二进制里
-
降低误部署风险
不会出现:
- dev 配置跑到生产
- prod 配置误用本地环境
-
构建即环境确定
👉 环境是在 编译时决定的
不是运行时决定
3. //go:embed ------ 静态资源嵌入
作用:把文件打包进二进制
go
import _ "embed"
//go:embed config.json
var cfg []byte运行后:
config.json会被直接编进 binary- 不再依赖外部文件
常见用途:
- 配置文件
- 前端静态资源(HTML/CSS/JS)
- 内嵌模板
基本用法
//go:embed 是 Go 在编译期提供的资源嵌入能力,它允许你在 build 阶段直接读取文件内容,并写入到最终 binary 中。
它依赖标准库 embed 包,并且必须满足两个前提:
- 必须 import
"embed" - 必须写在变量声明上方(不能随便放)
✔️ 最基础用法(单文件嵌入)
go
import _ "embed"
//go:embed config.json
var cfg []byte📌 运行时效果
编译之后:
config.json不再作为外部文件存在- 文件内容直接变成
cfg变量的一部分 - 程序运行时不再依赖磁盘路径
✔️ 文本方式读取(更常见)
go
import _ "embed"
//go:embed hello.txt
var s string📌 适用场景:
- JSON 配置(小型)
- YAML / TOML
- SQL 文件
- 文本模板
- 帮助文档(README / usage)
✔️ 嵌入多个文件
go
import "embed"
//go:embed a.txt b.txt c.txt
var data []byte📌 注意:
多个文件通常不建议直接用 []byte,因为无法区分文件边界,更推荐 embed.FS。
✔️ 嵌入整个目录(工程常用)
go
import "embed"
//go:embed static/*
var staticFiles embed.FS📌 说明
static/*会把目录下所有文件打包进 binary- 包括 HTML / CSS / JS / 图片等静态资源
✔️ 读取嵌入文件
go
data, _ := staticFiles.ReadFile("static/index.html")
fmt.Println(string(data))✔️ 目录级嵌入(多层结构)
go
//go:embed static/**
var staticFiles embed.FS✔️ 类型限制(非常关键)
//go:embed 只能赋值给以下三种类型:
string[]byteembed.FS
❌ 不支持:
- map
- struct
- interface
- 自定义类型
✔️ 编译期行为(核心机制)
//go:embed 的本质是:
在
go build阶段,把外部文件内容"拷贝进二进制"
运行时不再做任何文件 IO。
真实案例------Web 服务静态资源内嵌(前后端一体部署)
在真实 Web 项目中,一个非常典型的问题是:
前端构建产物(HTML / JS / CSS)和后端服务分离部署,容易出现路径错误或资源丢失
尤其在以下场景非常常见:
- Docker 部署
- Kubernetes 多容器部署
- 单二进制发布(Go CLI / Server)
📁 项目结构
text
.
├── main.go
├── web/
│ ├── index.html
│ ├── app.js
│ └── style.css📄 web/index.html
html
<html>
<head>
<title>demo</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello Embed</h1>
<script src="app.js"></script>
</body>
</html>🧩 Go 代码(嵌入整个前端)
go
package main
import (
"embed"
"fmt"
"net/http"
)
//go:embed web/*
var webFS embed.FS
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
data, _ := webFS.ReadFile("web/index.html")
fmt.Fprint(w, string(data))
})
http.ListenAndServe(":8080", nil)
}访问:
http://localhost:8080直接返回内嵌 HTML 页面。
4. //go:noinline ------ 禁止内联优化
go
//go:noinline
func foo() {}告诉编译器:
不要把这个函数展开内联
用途:
- 性能测试更准确
- debug 方便(保留调用栈)
- 避免编译器优化影响行为
基本用法
//go:noinline 是 Go 编译器提供的优化控制指令,用于告诉编译器:
这个函数不要做"内联展开(inline expansion)"
✔️ 最基础用法
go
//go:noinline
func add(a, b int) int {
return a + b
}📌 什么是"内联"?
正常情况下,Go 编译器可能会做这样的优化:
go
func main() {
x := add(1, 2)
println(x)
}编译器可能直接把 add(1,2) 展开成:
go
x := 1 + 2👉 这就叫 内联优化(inline)
加上它之后:
go
//go:noinline
func add(a, b int) int {
return a + b
}编译器会强制:
- 不展开函数
- 保留函数调用栈
- 保持函数边界
在 Go 编译过程中:
- 编译器会先做 AST / SSA 转换
- 判断函数是否"可内联"(简单、小函数)
- 如果没有
noinline,可能会进行 inline 优化 - 如果存在
//go:noinline,直接跳过 inline 阶段
📌 本质:
//go:noinline是对编译器优化器的"强制关闭开关"
真实案例------性能压测 / 统计函数调用开销
在真实工程中,//go:noinline 最常见的用途不是"优化",而是:
防止优化干扰性能测试结果
📁 场景:性能压测统计函数调用成本
假设你在做一个高频调用函数的性能测试:
🧩 默认情况(可能被内联)
go
package main
func add(a, b int) int {
return a + b
}
func main() {
sum := 0
for i := 0; i < 100000000; i++ {
sum += add(i, i)
}
println(sum)
}📌 问题:
如果 add 被内联:
- 根本不会发生函数调用
- 测试结果 ≠ 真实函数调用成本
🚫 使用 noinline(真实调用)
go
package main
//go:noinline
func add(a, b int) int {
return a + b
}
func main() {
sum := 0
for i := 0; i < 100000000; i++ {
sum += add(i, i)
}
println(sum)
}📌 结果变化
| 情况 | 行为 |
|---|---|
| 默认 | 可能内联 → 无函数调用 |
| noinline | 强制函数调用 |
5. //go:nosplit ------ 栈扩展控制(底层用)
go
//go:nosplit
func f() {}作用:
- 禁止栈增长检查
- 常用于 runtime / syscall
⚠️ 用不好会 panic(栈溢出)
基本用法
//go:nosplit 是 Go runtime / 编译器层面的底层控制指令,用于告诉编译器:
这个函数不能触发栈扩展逻辑
✔️ 最基础用法
go
//go:nosplit
func tinyFunction() {
// 必须保证不会触发栈增长
}📌 什么是"栈分裂(stack split)"?
Go 的 goroutine 使用的是可增长栈:
- 初始栈很小(通常 2KB)
- 执行过程中如果不够用,会触发 栈扩展
- runtime 会执行 "stack growth / stack copy"
✔️ 正常函数执行流程
text
函数调用
↓
检查栈是否足够
↓
不够 → 扩展栈(stack grow)
↓
继续执行✔️ //go:nosplit 的作用
加上之后:
go
//go:nosplit
func f() {
// ...
}编译器要求:
这个函数必须保证"不会触发栈增长检查"
也就是说:
- 不允许 stack split
- 不允许 stack grow
- 不允许调用可能导致栈扩展的逻辑
执行机制(How it works)
在编译阶段:
-
编译器分析函数栈使用量
-
如果函数标记
nosplit -
编译器强制要求:
- stack frame 必须极小
- 不能调用可能触发栈检查的函数
-
如果不满足 → 编译直接报错
📌 本质:
//go:nosplit是对 runtime 栈机制的"硬约束"
真实案例------runtime / runtime-like 底层函数
在 Go runtime 中,//go:nosplit 主要用于:
极高频、极底层、不能有额外开销的函数
🧩 场景 1:runtime 内部调度函数(简化版)
go
//go:nosplit
func getg() *g {
return getgDirect()
}📌 为什么必须 no split?
因为:
- scheduler 可能随时调用
- goroutine stack 可能处于边界状态
- 不能触发栈扩展(否则递归崩溃)
🧩 场景 2:atomic / 原子操作路径
go
//go:nosplit
func atomicLoad(addr *int32) int32 {
return *addr
}📌 原因:
- atomic 操作必须极低延迟
- 不能有 runtime 介入
- 不能触发 stack growth
🧩 场景 3:调度器 / M-P-G 模型核心路径
Go runtime 中:
- M(machine)
- P(processor)
- G(goroutine)
调度相关函数必须:
- 极短路径
- 不允许复杂调用链
- 不能触发栈扩展
⚠️ 使用限制(非常关键)
//go:nosplit 有严格限制:
❌ 1. 不能调用复杂函数
go
//go:nosplit
func bad() {
fmt.Println("hello") // ❌ 不允许
}❌ 2. 不能分配过多栈空间
局部变量过大也可能报错
❌ 3. 不能递归
递归会直接触发栈增长机制
❌ 4. 编译器可能直接拒绝编译
如果不满足条件:
text
nosplit stack overflow6. //go:linkname ------ 强行绑定符号(危险)
go
//go:linkname local runtime.memmove作用:
- 让当前函数"绑定到别的包的私有函数"
👉 常用于 runtime / unsafe 黑魔法
⚠️ 正常业务基本不用
基本用法
//go:linkname 是 Go 编译器提供的一个非常底层、非常危险的指令,用于:
让当前包的标识符,绑定到另一个包中的"未导出符号"
✔️ 最基础用法
go
import _ "unsafe"
//go:linkname localName runtime.getg
func localName()📌 关键点
必须满足两个条件:
- 必须
import _ "unsafe" - 必须开启
//go:linkname
✔️ 它在做什么?
等价于:
把当前包里的
localName,直接"指向"runtime.getg
也就是说:
- 你在当前包调用
localName() - 实际执行的是
runtime.getg
执行机制(How it works)
在编译阶段:
- 编译器解析
//go:linkname - 修改符号表(symbol table)
- 将当前函数名映射到目标函数
- 链接阶段直接复用目标实现
📌 本质:
//go:linkname是"绕过 Go 可见性规则的符号重绑定"
真实案例------runtime / sync 内部"绕过访问限制"
Go 标准库内部有大量 未导出(unexported)函数,比如 runtime 包中的函数:
text
runtime.getg
runtime.nanotime
runtime.mallocgc🧩 示例:访问 runtime 私有函数
go
package main
import (
_ "unsafe"
"fmt"
)
//go:linkname getg runtime.getg
func getg() uintptr
func main() {
g := getg()
fmt.Println(g)
}📌 发生了什么?
runtime.getg本来是不可导出的- Go 正常代码无法访问
- 但
linkname强行绑定符号 - 当前包"伪装拥有"该函数
真实工程用途(标准库内部)
✔️ 1. sync / runtime 协作
Go 的 sync 包经常依赖 runtime 内部能力:
- 调度器状态
- goroutine ID
- 信号机制
✔️ 2. atomic / low-level primitive
某些原子操作直接绑定 runtime 实现:
- 更快
- 更贴近 CPU 指令
- 避免用户态封装开销
✔️ 3. syscall / platform bridge
在某些平台层实现中:
- 需要调用 runtime 未导出函数
- 或替换默认实现
⚠️ 为什么说它"危险"?
❌ 1. 破坏封装性
直接访问:
- runtime 内部函数
- 未导出 API
👉 绕过 Go 语言的可见性规则
❌ 2. 强依赖内部实现
一旦 Go 版本变化:
- runtime 函数改名
- 参数变化
- 实现调整
👉 你的代码可能直接崩
❌ 3. 不保证兼容性
官方明确:
unsafe + linkname 不保证稳定性
❌ 4. 可能导致 undefined behavior
包括:
- 崩溃
- 内存错误
- runtime panic
//go:linkname 的本质是:
用"编译器特权"强行修改符号绑定关系,绕过语言封装模型
7. //go:nowritebarrier / //go:systemstack 等
这些基本都是:
runtime / GC / 调度器用的底层指令
普通业务开发一般不会碰。
基本用法
这一类 //go: 指令属于 Go runtime 内部使用的"编译器控制开关",通常不会在业务代码中使用,主要出现在:
- runtime 包
- GC(垃圾回收)相关实现
- 调度器(scheduler)
- unsafe / syscall 相关底层代码
✔️ //go:nowritebarrier
go
//go:nowritebarrier作用:禁止写屏障(write barrier)插入
📌 什么是 write barrier?
在 Go GC(垃圾回收)中:
写屏障用于维护"并发标记阶段"的对象可达性
简单理解:
- GC 在运行时仍允许程序继续执行
- 为了不丢引用,需要插入"额外记录逻辑"
- 这段逻辑就是 write barrier
✔️ //go:nowritebarrier 的作用
加上之后:
- 编译器不会插入 write barrier 代码
- 代码执行更"裸"
- 但必须确保不会破坏 GC 正确性
⚠️ 使用限制
如果使用不当:
- GC 可能漏标对象
- 可能导致内存错误
- 甚至直接 crash runtime
📌 本质:
nowritebarrier= 禁用 GC 安全机制(极高风险)
✔️ //go:systemstack
go
//go:systemstack作用:强制函数在 system stack(系统栈)上执行
📌 Go 的两种栈
Go runtime 有两种执行栈:
| 类型 | 说明 |
|---|---|
| goroutine stack | 用户态 goroutine 栈 |
| system stack | runtime 专用栈 |
✔️ 为什么需要 system stack?
某些 runtime 操作不能在 goroutine stack 上执行,例如:
- 调度器切换
- GC 核心逻辑
- 栈增长逻辑本身
- 信号处理
✔️ //go:systemstack 的作用
go
//go:systemstack
func f() {
// 强制在 system stack 执行
}👉 表示:
无论当前 goroutine 在哪里,都切换到 system stack 执行该函数
📌 执行流程(简化)
text
goroutine stack
↓
检测 systemstack
↓
切换到 system stack
↓
执行函数
↓
切回 goroutine stack真实案例------runtime 调度器与 GC 核心路径
这一类指令不会出现在业务代码中,只存在于 runtime 内部实现中。
🧩 场景 1:GC 标记阶段核心逻辑
在 GC mark 阶段:
- 需要扫描对象图
- 需要修改对象引用
- 不能触发 stack growth
- 不能被调度打断
👉 使用 system stack 保证执行安全性
🧩 场景 2:goroutine 调度器(G-M-P 模型)
调度器核心逻辑中:
- M(machine)负责执行
- P(processor)管理队列
- G(goroutine)是执行实体
某些调度函数必须:
- 避免抢占
- 避免栈扩展
- 避免 GC 干扰
👉 使用 system stack + nowritebarrier
🧩 场景 3:栈增长逻辑本身
Go runtime 在处理:
- stack growth
- stack copy
时必须保证:
当前代码不能再触发 stack growth
否则会递归爆炸
⚠️ 为什么这些指令不开放给业务?
❌ 1. 破坏 GC 安全模型
nowritebarrier 会影响:
- 并发标记正确性
- 内存可达性追踪
❌ 2. 破坏 runtime 抽象
Go 的设计目标是:
用户不需要关心 stack / GC / scheduler
这些指令直接暴露底层实现
❌ 3. 极易写出不可维护代码
一旦使用:
- 强依赖 runtime 实现
- Go 版本升级风险极高
很好,这两节其实是整篇"Go directive 系列"的升维章节,写完就不只是语法介绍,而是"设计思想总结"。
Go 为什么不用宏
Go 语言刻意没有引入 C / C++ 那种宏系统(macro) ,而是用 //go: directive + 工具链来替代很多"编译期能力"。
在 C / C++ 中,宏是这样的:
c
#define ADD(a, b) ((a) + (b))或者:
c
#define DEBUG printf("debug\n")宏的本质是:
文本替换 + 编译前预处理
Go 官方不采用宏,核心原因是三点:
1)可读性崩坏
宏展开后代码不是你写的代码,而是"另一份隐藏代码"。
例如:
c
ADD(1 + 2, 3)可能被展开成:
c
((1 + 2) + (3))看似简单,但复杂宏会让代码完全不可读。
2)调试困难
宏代码:
- 不在 AST 中
- 不在 runtime stack 中
- 不在 debug 信息中
👉 你甚至不知道 bug 在哪一层产生的
3)类型系统失效
宏是纯文本替换:
c
#define MUL(a, b) a * b可能出现:
c
MUL(1 + 2, 3)变成:
c
1 + 2 * 3 // ❌ 优先级错误👉 类型安全彻底失效
Go 把"宏能力"拆成三层:
🧩 1)编译器 directive(你前面讲的)
//go:build//go:embed//go:noinline//go:nosplit
👉 声明式控制编译行为
🧩 2)代码生成(go generate)
//go:generate- 外部工具生成代码(stringer / mock / protobuf)
👉 用"工具生成代码"替代宏展开
🧩 3)泛型(Go 1.18+)
用类型系统解决重复逻辑,而不是文本替换:
go
func Add[T int | float64](a, b T) T {
return a + b
}Go 选择的是:
"显式代码 + 工具链生成",而不是"隐式文本替换"
Go 的 Toolchain 哲学
Go 有一个非常明确的哲学:
编译过程必须可预测、可重复、可工具化
🧩 1)编译是"确定性流程"
Go build 做的事情非常固定:
text
源码 → AST → SSA → 优化 → 机器码所有行为必须:
- 可复现
- 无隐藏逻辑
- 无运行时魔法
🧩 2)编译期能力必须"显式声明"
Go 不允许:
- 隐式宏
- 隐式预处理
- 隐式代码生成
所以它统一成:
| 能力 | 方式 |
|---|---|
| 条件编译 | //go:build |
| 资源嵌入 | //go:embed |
| 代码生成 | //go:generate |
| 优化控制 | //go:noinline |
🧩 3)工具链优先,而不是语言特性
Go 的一个关键设计是:
很多能力不是语言内建,而是 toolchain 提供
例如:
go buildgo testgo generatego vet
👉 directive 只是 toolchain 的"控制信号"
🧩 4)编译期 vs 运行期严格分离
Go 非常强调:
编译期做决定,运行期只执行
例如:
//go:build→ 编译期过滤//go:embed→ 编译期嵌入//go:nosplit→ 编译期限制栈行为
👉 运行时尽量保持简单
✔️ 和其他语言的核心差异
| 语言 | 编译期能力 |
|---|---|
| C/C++ | 宏 + 预处理器 |
| Rust | macro_rules + procedural macro |
| Java | 注解处理器 |
| Go | toolchain + directive + codegen |
Go 不追求:
- 语法复杂度
- 元编程能力极限
- runtime 魔法
Go 追求的是:
简单、可读、可分析、可工程化
结尾
说实话,这篇文章最初的出发点其实很简单,就是在翻 Go 代码或者工具链的时候,偶然看到这些 //go: 开头的"编译指令",觉得有点意思,就顺手往下挖了一点。
但越往下看越会发现,这些东西其实并不常见。无论是在日常开发中写业务代码,还是现在越来越依赖 AI coding 的开发方式里,这些 directive 基本都不会被主动生成,更不会成为你日常思考的一部分。它们更像是 Go 语言刻意收起来的一些"底层开关",平时不会用到,但一直在那里。
我也只是翻了一些资料,做了一点很浅的整理和理解。很多内容说实话也只是"知道它是什么",远远谈不上掌握,更不用说在项目里熟练使用。
甚至可以预见,这篇文章写完之后的很长一段时间里,我大概率也不会真正用到这些指令。
但学习这类东西的意义可能也不在"用得上"。它更像是在脑子里留一条路径------哪怕现在走不到那里,以后某一天在某个工具、某段源码、或者某个奇怪的性能问题里再次遇到它时,至少不会完全陌生。
希望真到那个时候,能有一种"蓦然回首,那人却在灯火阑珊处"的感觉。