一.文件描述符 fd
通过对open函数的学习,我们知道了⽂件描述符就是⼀个⼩整数
1-1 0 & 1 & 2
• Linux进程默认情况下会有3个缺省打开的⽂件描述符,分别是标准输⼊0, 标准输出1, 标准错误2.
• 0,1,2对应的物理设备⼀般是:键盘,显⽰器,显⽰器
所以输⼊输出还可以采⽤如下⽅式:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main()
{
ssize_t s = read(0, buf, sizeof(buf)); // 从键盘读取最多1024字节
if(s > 0){ // 如果读到了内容
buf[s] = 0; // 添加字符串结束符
write(1, buf, strlen(buf)); // 输出到标准输出(屏幕)
write(2, buf, strlen(buf)); // 输出到标准错误(也是屏幕)
}
return 0;
}【补充】
唯一可能用
strlen的场景如果你不知道 数据长度,只知道它以
\0结尾(比如来自strcpy的字符串),这时才需要strlen。但这里你明明知道
s(read刚返回的),没必要扔掉这个信息再重新去数一遍。
【解释】
|------------------|------------------------------------|
| task_struct | Linux 内核中描述进程的核心结构体 |
| *files | 指向 files_struct 的指针 |
| files_struct | 管理进程打开的所有文件的结构 |
| fd_array[] | 文件描述符数组,下标 = 文件描述符值 |
| 0,1,2,3... | 文件描述符编号 |
| 标准输入/输出/错误 | 默认打开的 0(stdin)、1(stdout)、2(stderr) |
| myfile(新打开的文件) | 通过 open() 获得新描述符(如 3) |
| file 对象 | 内核中代表一次打开的文件实例 |
| inode 元信息 | 文件在磁盘上的元数据(大小、权限、时 |
【补充】
| 概念 | 说明 |
|---|---|
| 进程 → 文件 | 通过 fd → fd_array[fd] → file → inode |
| 多个 fd → 同一个 file | dup() / fork() 后父子进程共享 file(包括 f_pos) |
| 多个 file → 同一个 inode | 同一文件被多次打开 (如两个独立 open)→ 各有各的 f_pos |
| 磁盘 inode(唯一) | 一个文件只有一个磁盘 inode |
| 内存 inode | 可能多个 file 指向同一个内存 inode 对象 |
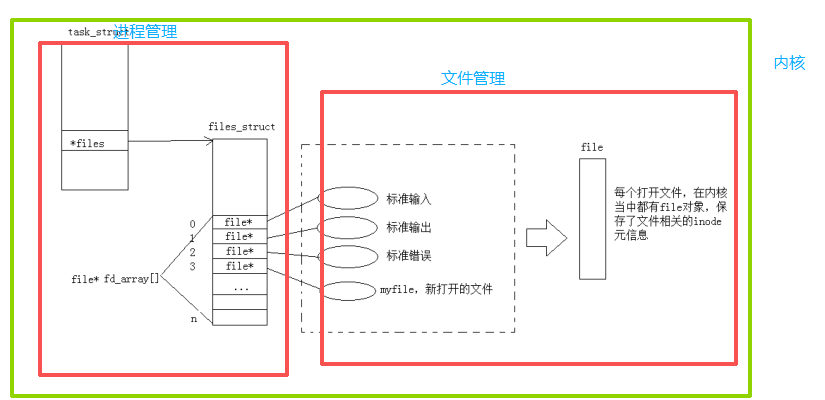
- ⽽现在知道,⽂件描述符就是从0开始的⼩整数。
- 一个程序启动成为进程后,内核会为该进程维护一个
task_struct结构体(包含进程状态、PID等信息),其中包含一个指向files_struct的指针。files_struct内部有一个fd_array[]数组,数组的下标就是用户态所见的文件描述符(如0、1、2、3...),数组元素则是指向内核file对象的指针。每个file对象代表一次打开的文件实例 (同一文件打开多次会产生多个独立的file对象),内部保存了当前读写位置f_pos、引用计数f_count(用于共享和延迟释放)、文件操作函数表f_op以及指向inode的指针。inode存储了文件的元信息(如大小i_size、权限i_mode、所有者i_uid/gid、时间戳等),一个磁盘文件唯一对应一个inode。用户态调用write(fd, ...)等系统调用时,内核会通过当前进程的task_struct找到files_struct,再用文件描述符作为索引从fd_array[]中取出对应的file对象,最终通过file对象访问inode并执行真正的设备或磁盘读写操作。图中还标注了默认打开的标准输入(fd 0)、标准输出(fd 1)、标准错误(fd 2)以及用户自己打开的新文件(如myfile,通常获得fd 3),并通过write()调用示例展示了从用户态FILE*或fd到内核file对象再到内存/磁盘数据的完整路径。
对于以上原理结论我们可通过内核源码验证:
⾸先要找到 task_struct 结构体在内核中为位置,地址为: /usr/src/kernels/3.10.0-
1160.71.1.el7.x86_64/include/linux/sched.h (3.10.0-1160.71.1.el7.x86_64是内核版本,可使⽤ uname -a ⾃⾏查看服务器配置, 因为这个⽂件夹只有⼀个,所以也不⽤刻意去分辨,
内核版本其实也随意)
- 要查看内容可直接⽤vscode在windows下打开内核源代码
- 相关结构体所在位置
◦ struct task_struct : /usr/src/kernels/3.10.0-
1160.71.1.el7.x86_64/include/linux/sched.h
◦ struct files_struct : /usr/src/kernels/3.10.0-
1160.71.1.el7.x86_64/include/linux/fdtable.h
◦ struct file : /usr/src/kernels/3.10.0-
1160.71.1.el7.x86_64/include/linux/fs.h
1-2⽂件描述符的分配规则
运行结果:

关闭0
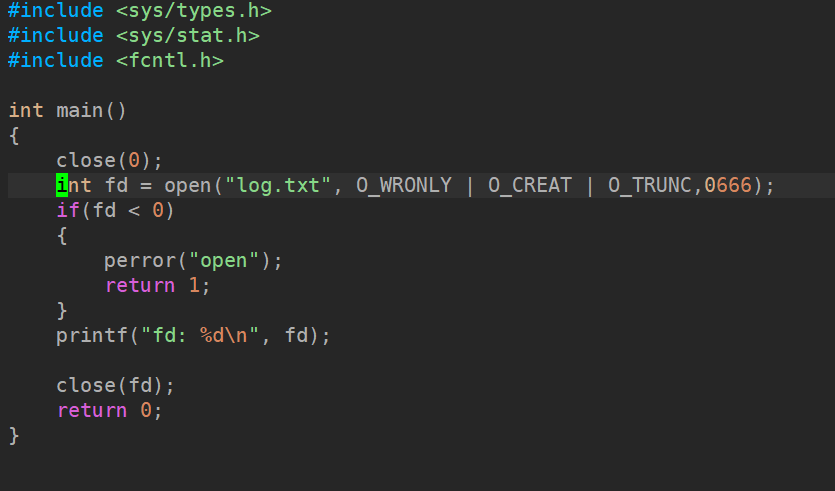
有 O_CREAT → 必须写权限参数(0666),不能省
无 O_CREAT → 可以不写,写了也没用
0666 只管新建文件权限,老文件权限不受影响
配合 umask(0) ,才能拿到 rw‑rw‑rw‑ 权限
关闭2
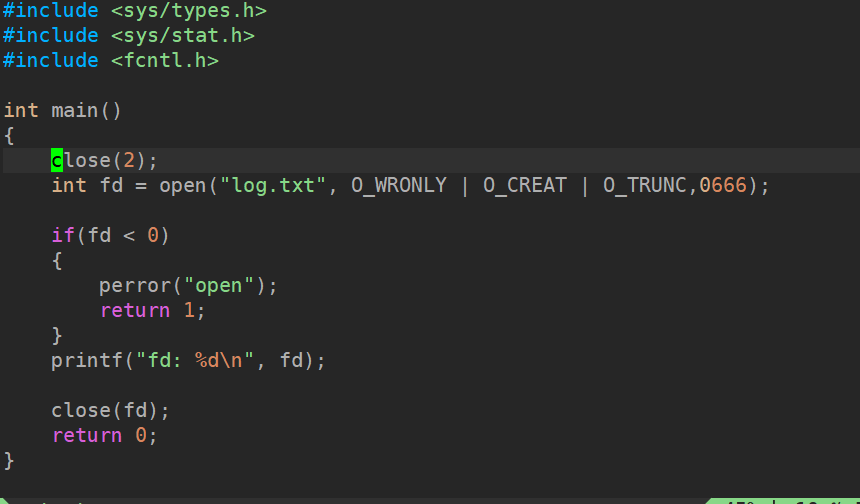

文件描述符分配规则:在 files_struct 数组中,找到当前没有被使用的最小且没有被占用的文件描述符"
-
files_struct中存放当前进程打开的文件指针。 -
关闭
2后,2这个位置就空了。 -
下次
open时,系统会从0开始扫描,找到第一个空闲位置2来用,即使2原先对应的是标准错误。
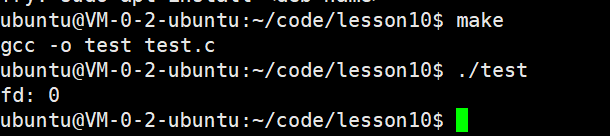
现是结果是: fd: 0 或者 fd 2 ,可⻅,⽂件描述符的分配规则:在files_struct数组当中,找到当前没有被使⽤的最⼩的⼀个下标,作为新的⽂件描述符。
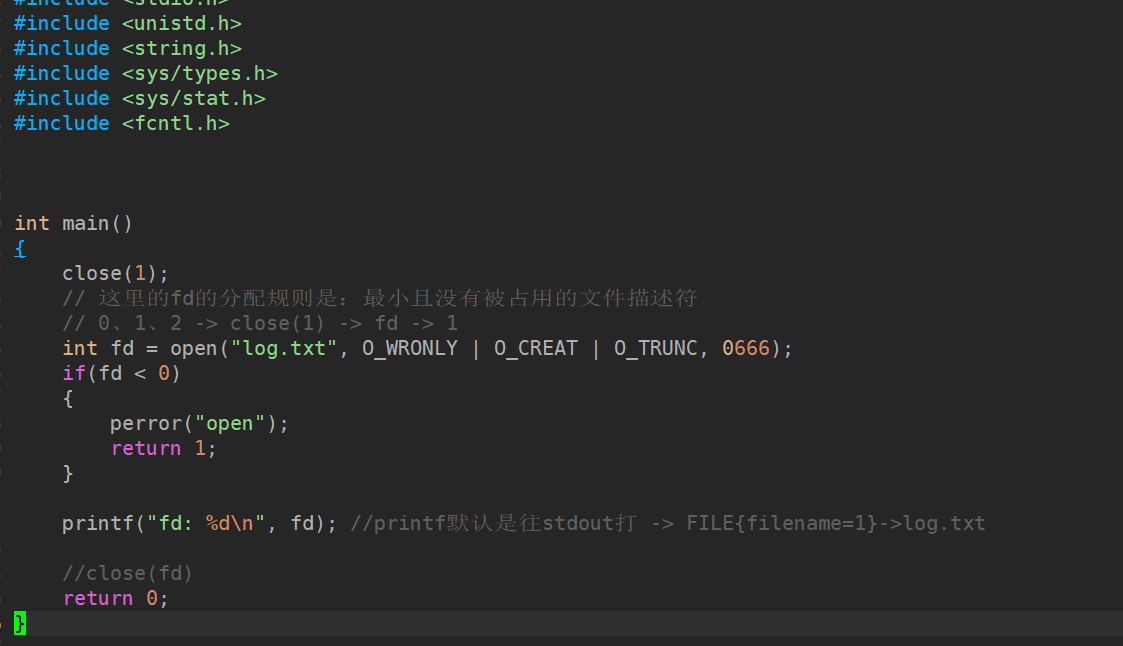

屏幕:无输出(因为标准输出已被关闭)close(fd)
log.txt文件中:有内容fd: 1
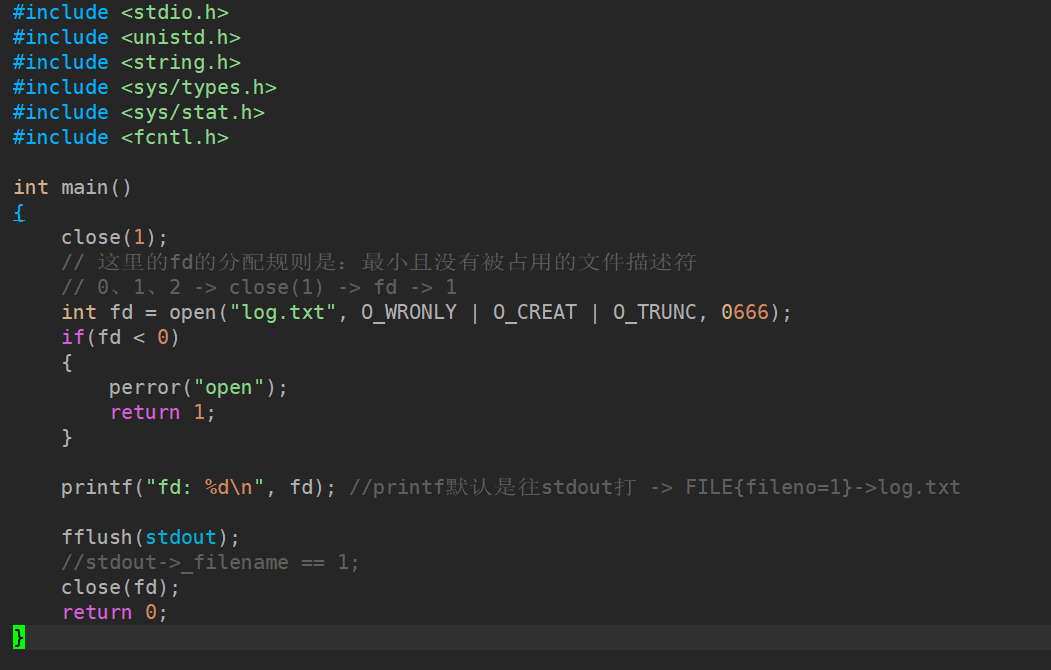

两段代码最终
log.txt都有内容,但本段代码通过fflush主动刷新缓冲区,更可靠。
1-3"文件描述符分配规则"的底层原理 &&fopen 和 open 之间耦合关系
fopen 和 open 之间耦合关系 的观点:
核心耦合关系:
| 用户层 | 内核层 |
|---|---|
FILE*(C库) |
struct file(内核) |
_fileno(fd编号) |
fd_array[fd] |
fopen() 调用 open() |
open() 分配 fd |
耦合关系详解
1. fopen 内部会调用 open
cpp
FILE *fopen(const char *path, const char *mode)
{
// 1. 分配 FILE 结构体
// 2. 调用 open() 系统调用获取 fd
int fd = open(path, flags, mode);
// 3. 将 fd 存入 FILE->_fileno
// 4. 返回 FILE*
}
2. 数据流动fread/fwrite → FILE* 缓冲区 → write/read 系统调用 → fd → 内核文件
3. 关键耦合点
FILE*中的_fileno字段就是内核fd_array的下标关闭
fd会影响对应的FILE*(因为_fileno变成无效)关闭
FILE*(fclose)也会关闭底层fd
补充
1. 缓冲区的独立性
FILE*有自己的用户态缓冲区 (_IO_read_ptr、_IO_write_ptr等)
open直接返回的fd没有用户态缓冲区这就是为什么
printf需要fflush,而write不需要
printf需要fflush才能保证落盘
write不需要刷新,直接进内核
2. 混合使用的风险
cpp
int fd = open("log.txt", O_WRONLY);
FILE* fp = fdopen(fd, "w"); // 将 fd 包装成 FILE*
fprintf(fp, "hello"); // 通过 FILE* 写
write(fd, "world", 5); // 直接通过 fd 写 ------ 可能乱序!补充点 :混用 FILE* 和 fd 会导致缓冲区问题,因为 FILE* 有缓冲,fd 直接写穿透。
3. 关闭的层次
| 操作 | 效果 |
|---|---|
close(fd) |
只关内核 fd,FILE* 缓冲区还在,_fileno 变脏 |
fclose(fp) |
先刷新缓冲区,再 close(fd),再释放 FILE* |
fflush(fp) |
只刷新缓冲区,不关 fd |
总结:
fopen和open通过文件描述符 耦合,但FILE*多了一层用户态缓冲区这层缓冲区带来了便利(
printf格式化),也带来了陷阱(需要fflush)混用时记住:
close关 fd,fclose刷缓冲区再关,fflush只刷不关
从 close(1) 到 printf 失效:一次读懂文件描述符与用户态缓冲区
贴出你的第一段代码:
cpp
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("fd: %d\n", fd);现象:
屏幕无输出
log.txt里有没有内容,取决于是否手动close(fd)或fflush
为什么?
1.文件描述符分配规则
内核用
fd_array[]管理打开的文件分配规则:最小的未使用 fd
close(1)释放 1 →open返回 1 → fd 1 现在指向log.txt
2.stdout 与 FILE 结构体
printf写入的是stdout(类型FILE*)
FILE包含:
_fileno(底层 fd,初始为 1)用户态缓冲区指针(
_IO_write_ptr等)
关键点 :close(1) 关闭的是内核 fd,不影响 stdout 这个 FILE* 的存在,也不清空它的缓冲区。
3.缓冲区与 \n 的真相
| 底层 fd 指向 | 缓冲模式 | \n 是否刷新 |
|---|---|---|
| 终端(tty) | 行缓冲 | 是 |
| 普通文件 | 全缓冲 | 否 |
当 fd 1 从终端变成 log.txt,\n 不再触发系统调用,数据留在用户态缓冲区。
4.为什么 close(fd) 会丢数据?
cpp
printf(...); // 数据进 stdout 缓冲区
close(fd); // 只关内核 fd,不刷新用户态缓冲区
return 0; // 程序结束,但缓冲区已无机会刷新close 是系统调用,绕过了 FILE 层,不知道有缓冲区存在。
5.为什么"不关 fd"反而能写入?
cpp
printf(...); // 数据进缓冲区
return 0; // exit() 会遍历 _chain 链表,自动刷新所有 FILE*exit() 会调用 _IO_cleanup → 刷新所有未关闭的 FILE 缓冲区。
这就是你观察到的:
"关闭 fd 则不打印,不关则打印"
6.正确做法:fflush 或 fclose
cpp
printf(...);
fflush(stdout); // 手动刷新缓冲区
close(fd); // 安全关闭或者直接用
fclose(stdout)代替close(fd)。
二.重定向
那如果关闭1呢?看代码:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
close(1);
int fd = open("myfile", O_WRONLY|O_CREAT, 00644);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
fflush(stdout);
close(fd);
exit(0);
}运行结果:
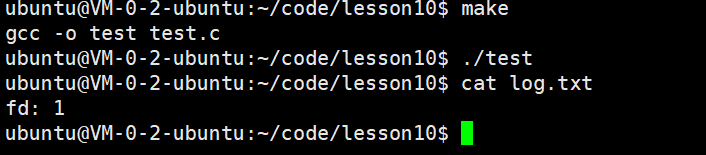
此时,我们发现,本来应该输出到显⽰器上的内容,输出到了⽂件 log.txt当中,其中,fd=1。这种现象叫做输出重定向。常⻅的重定向有: > , >> , <
| 类型 | 符号 | 作用 |
|---|---|---|
| 输出重定向 | > |
将命令输出写入文件(覆盖) |
| 追加重定向 | >> |
将命令输出追加到文件末尾 |
| 输入重定向 | < |
从文件读取输入,而不是键盘 |
那重定向的本质是什么呢?什么是"fd 对应的内容指向"?
每个进程的 files_struct 中有一个 fd_array[],数组的每个元素是一个指针,指向内核中对应的 struct file(代表一个打开的文件/设备)。
cpp
fd_array[0] → 指向键盘的 struct file
fd_array[1] → 指向显示器的 struct file
fd_array[2] → 指向显示器的 struct file重定向就是修改这个指针的指向:
cpp
// 输出重定向 > output.txt 之后:
fd_array[1] → 指向 output.txt 的 struct file(不再指向显示器)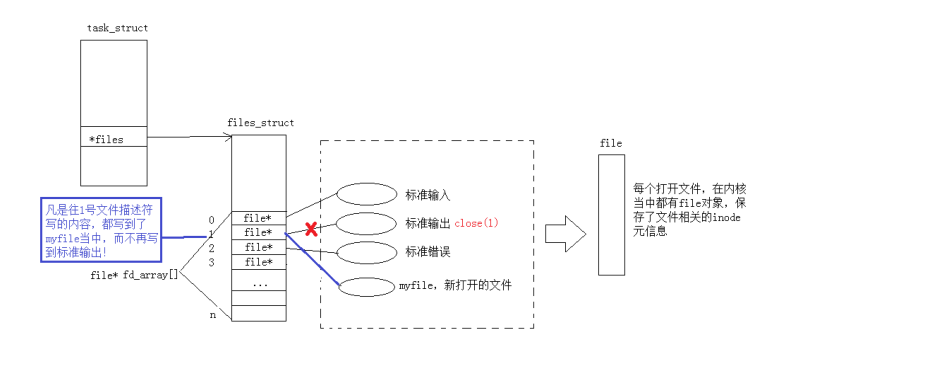
很多人学重定向只记住了 `>`、`>>`、`<` 这些符号,但不知道底层发生了什么。 直白来说:就是在 OS 内部更改 fd 对应的内容指向。 每个进程都有一个 fd_array[] 数组: fd_array[0]默认指向键盘 fd_array[1]默认指向显示器 fd_array[2]默认指向显示器 假设:执行 ./program > log.txt 时,shell 做的事情是: 1. close(1) ------ 断开与显示器的连接 2. open("log.txt") ------ 打开文件,返回的 fd 恰好是 1(最小未使用) 3. 此后 printf写入 fd 1,实际就写入了 log.txt 这就是重定向的全部秘密。
重定向的底层本质就是修改进程内核中
fd_array[]数组的指针指向:默认情况下fd_array[0]指向键盘的file对象,fd_array[1]和fd_array[2]指向显示器的file对象;当执行close(1)后再open("log.txt"),系统会分配最小未使用的 fd(即 1),使fd_array[1]转而指向log.txt的file对象,此后所有往 fd 1 写入的数据(如printf)都会进入文件而非屏幕;而dup2(fd, 1)则是直接让fd_array[1]复制fd_array[fd]的指针,同样实现重定向。一句话:重定向就是改fd_array[]指针,让标准 IO 的下标指向你指定的文件对象
2-1输出重定向 >
定义
将程序的标准输出(stdout,fd 1)从显示器改为写入文件。覆盖模式:如果文件已存在,先清空再写入。
cpp
# 创建一个测试程序
echo 'int main() { printf("Hello World\n"); return 0; }' > test.c
gcc test.c -o test
# 正常执行:输出到屏幕
./test
# 输出:Hello World
# 输出重定向:输出到文件
./test > output.txt
# 屏幕无输出,output.txt 内容为:Hello World
# 再次执行:文件被覆盖
./test > output.txt
# output.txt 仍只有一行 Hello World(旧内容被覆盖)代码模拟重定向底层原理
cpp
// 模拟输出重定向:将 stdout 指向文件
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
// 关闭标准输出(fd 1)
close(1);
// 打开文件,O_TRUNC 表示清空/覆盖
int fd = open("output.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
// 分配规则:最小未使用 fd = 1,所以 fd 得到 1
printf("fd = %d\n", fd); // 输出:fd = 1
// 此时 printf 写入 fd 1,实际写入 output.txt
printf("这是输出重定向的内容\n");
// 数据还在缓冲区,需要刷新
fflush(stdout);
close(fd);
return 0;
}执行结果:
cpp
屏幕:无输出(stdout 已被重定向)
output.txt 内容:fd = 1 + 这是输出重定向的内容使用 dup2 实现
cpp
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
int fd = open("output.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
// dup2(fd, 1):将 fd 复制到 1,让 1 也指向 output.txt
dup2(fd, 1);
close(fd); // 原 fd 可关闭,因为 1 已经指向它
printf("通过 dup2 实现输出重定向\n");
fflush(stdout);
return 0;
}> 的 open 标志解析
cpp
open("file", O_WRONLY | O_CREAT | O_TRUNC, 0666);| 标志 | 作用 |
|---|---|
O_WRONLY |
只写模式 |
O_CREAT |
文件不存在则创建 |
O_TRUNC |
文件存在则清空(覆盖) |
0666 |
创建时的权限(rw-rw-rw- 再被 umask 限制) |
2-2追加重定向 >>
定义
将程序的标准输出(stdout,fd 1)改为追加写入文件末尾,不覆盖原有内容。
cpp
# 准备初始文件
echo "第一行" > log.txt
cat log.txt
# 输出:第一行
# 追加重定向
echo "第二行" >> log.txt
cat log.txt
# 输出:
# 第一行
# 第二行
# 再次追加
echo "第三行" >> log.txt
cat log.txt
# 输出:
# 第一行
# 第二行
# 第三行代码模拟追加重定向底层原理
cpp
// 模拟追加重定向:追加写入文件末尾
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
close(1);
// 关键区别:使用 O_APPEND 而不是 O_TRUNC
int fd = open("log.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
printf("这是追加的内容\n");
printf("另一行追加内容\n");
fflush(stdout);
close(fd);
return 0;
}使用 dup2 实现追加重定向
cpp
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
int fd = open("log.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
dup2(fd, 1);
close(fd);
printf("通过 dup2 实现追加重定向\n");
fflush(stdout);
return 0;
}>> 的 open 标志解析
cpp
open("file", O_WRONLY | O_CREAT | O_APPEND, 0666);| 标志 | 作用 |
|---|---|
O_WRONLY |
只写模式 |
O_CREAT |
文件不存在则创建 |
O_APPEND |
每次写入自动定位到文件末尾(关键区别) |
0666 |
创建时的权限 |
O_APPEND 的内核保证
css
// 没有 O_APPEND 时(多进程问题)
// 进程 A:lseek 到末尾,准备写入
// 进程 B:lseek 到末尾,准备写入
// 进程 A:写入 → 覆盖了 B 的位置?
// 结果:数据互相覆盖
// 有 O_APPEND 时
// 内核保证每次 write 都是原子性地定位到末尾再写入
// 多进程追加写入不会互相覆盖2-3输入重定向 <
定义
将程序的标准输入(stdin,fd 0)从键盘改为从文件读取。
命令行示例
cpp
# 准备输入文件
echo "hello from file" > input.txt
# 编译读取程序
cat > read.c << 'EOF'
#include <stdio.h>
int main() {
char str[100];
scanf("%s", str);
printf("读取到: %s\n", str);
return 0;
}
EOF
gcc read.c -o read
# 输入重定向
./read < input.txt
# 输出:读取到: hello代码模拟输入重定向底层原理
cpp
// 模拟输入重定向:从文件读取输入
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
close(0); // 关闭标准输入
int fd = open("input.txt", O_RDONLY);
// fd 得到 0(最小未使用)
char str[100];
scanf("%s", str); // 实际从 input.txt 读取
printf("从文件读取到: %s\n", str);
close(fd);
return 0;
}使用 dup2 实现输入重定向
cpp
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
int fd = open("input.txt", O_RDONLY);
dup2(fd, 0); // 让 fd 0 指向 input.txt
close(fd);
char str[100];
fgets(str, sizeof(str), stdin); // 从 input.txt 读取
printf("读取: %s", str);
return 0;
}2-4三种重定向对比
| 类型 | 符号 | 文件描述符 | open 标志 | 作用 |
|---|---|---|---|---|
| 输入重定向 | < |
0 (stdin) | O_RDONLY |
从文件读输入 |
| 输出重定向 | > |
1 (stdout) | `O_WRONLY | O_CREAT |
| 追加重定向 | >> |
1 (stdout) | `O_WRONLY | O_CREAT |
O_TRUNCvsO_APPEND的内核区别:
O_TRUNC:打开文件时立即清空内容
O_APPEND:每次write系统调用前,内核自动把文件偏移量移到末尾
【补充】问题进程替换会影响重定向的结果?
进程替换(exec 族函数)不会影响重定向结果 ------ 重定向在 exec 之前设置,exec 后会保留。
核心原理
cpp
// fork 之后,exec 之前设置重定向
pid_t pid = fork();
if (pid == 0) {
// 子进程:先重定向
int fd = open("log.txt", O_WRONLY);
dup2(fd, 1); // 修改 fd_array[1] 指针
close(fd);
// 后执行进程替换
execvp("ls", args); // 新进程会继承 fd_array 的状态!
}关键 :exec 族函数会替换进程的代码段、数据段、堆栈 ,但保留文件描述符表 (除非设置了 FD_CLOEXEC 标志)。
2-5dup2 系统调用详解------重定向的核心
1.函数原型与核心理解
cpp
#include <unistd.h>
int dup2(int oldfd, int newfd);核心理解:dup2(oldfd, newfd) 让 newfd 成为 oldfd 的拷贝,最终 newfd 和 oldfd 指向同一个文件。
2.重定向时参数怎么传?
场景 :输出重定向 ./program > log.txt,让标准输出(fd 1)指向文件(fd 3)
| 错误写法 | 正确写法 |
|---|---|
dup2(1, fd) |
dup2(fd, 1) |
为什么? 你想让 1(标准输出) 变成 fd(文件) 的样子,所以 oldfd = fd(源),newfd = 1(目标)。
cpp
执行 dup2(fd, 1) 前: 执行后:
fd(3) → log.txt fd(3) → log.txt
1 → 显示器 1 → log.txt ← 变成和 fd 一样3.代码示例
输出重定向(>)
cpp
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
dup2(fd, 1); // 让 stdout 指向文件
close(fd); // 原 fd 可关闭,因为 1 已经指向它
printf("写入文件\n");
fflush(stdout);输入重定向(<)
cpp
int fd = open("input.txt", O_RDONLY);
dup2(fd, 0); // 让 stdin 指向文件
close(fd);
scanf("%s", str); // 从文件读取追加重定向(>>)
cpp
int fd = open("log.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
dup2(fd, 1); // 和输出重定向写法一样,区别只在 open 的 O_APPEND
close(fd);4.边界情况
| 情况 | 行为 |
|---|---|
oldfd 无效 |
调用失败,返回 -1,newfd 不被关闭 |
oldfd == newfd |
不做任何操作,直接返回 newfd |
newfd 原本是打开的 |
dup2 会自动关闭 newfd,再让它指向 oldfd |
5.dup2 与close+open比较
| 方式 | 代码 | 特点 |
|---|---|---|
| close+open | close(1); open("file", ...); |
依赖"最小未使用"分配规则,不够直观 |
| dup2 | dup2(fd, 1); |
意图明确:直接说"让 1 指向 fd 指向的文件" |
推荐使用 dup2,因为它不依赖分配规则,代码意图更清晰。
简单总结
dup2(fd, 1)让标准输出重定向到文件:关闭 1 原来的指向,然后让 1 指向fd指向的文件。
2-6在minishell中添加重定向功能
重定向的底层本质
核心一句话:重定向就是修改进程的
fd_array[]指针,让标准输入/输出不再指向默认设备,而是指向目标文件。
每个进程在内核中维护一个 files_struct 结构,里面有个 fd_array[] 数组:
cpp
默认状态:
fd_array[0] → 键盘设备文件
fd_array[1] → 显示器设备文件
fd_array[2] → 显示器设备文件
执行 ls -l > list.txt 后:
fd_array[0] → 键盘设备文件
fd_array[1] → list.txt 文件 ← 指针被修改了
fd_array[2] → 显示器设备文件Shell 实现重定向的三步走:
open()打开目标文件,获得一个文件描述符(比如 3)
dup2(3, 1)------ 让 fd_array1 指向和 fd 3 一样的文件
close(3)------ 关闭多余的 fd
dup2 系统调用的底层行为
cpp
#include <unistd.h>
int dup2(int oldfd, int newfd);
dup2(oldfd, newfd) 的底层逻辑:
执行前:
fd_array[oldfd] → 文件A
fd_array[newfd] → 文件B
执行 dup2(oldfd, newfd) 时内核做的事:
1. if (fd_array[newfd] 正在使用) 关闭它
2. fd_array[newfd] = fd_array[oldfd] // 指针复制
3. 文件A 的引用计数 +1
执行后:
fd_array[oldfd] → 文件A
fd_array[newfd] → 文件A ← 现在指向同一个文件为什么重定向要用 dup2(fd, 1) 而不是 dup2(1, fd)?
cpp
// 假设 fd = open("list.txt") 返回 3
// 目标:让 stdout(1) 指向 list.txt
dup2(3, 1) // 正确:把 fd_array[1] 改成指向 list.txt
dup2(1, 3) // 错误:把 fd_array[3] 改成指向显示器,1 没变口诀 :
dup2(oldfd, newfd)让 newfd 变成 oldfd 的样子。你想让 1 变成文件的样子,所以oldfd=文件fd, newfd=1。
代码逐段解析
1 .数据结构
cpp
typedef struct {
char *input_file; // 输入重定向的文件名,NULL 表示无
char *output_file; // 输出重定向的文件名,NULL 表示无
int append; // 0=覆盖(>),1=追加(>>)
} Redir;2. 解析函数:从命令行提取重定向信息
cpp
void parse(char *cmd, char **args, Redir *redir) {
redir->input_file = NULL;
redir->output_file = NULL;
redir->append = 0;
int i = 0;
char *token = strtok(cmd, " \t\n");
while (token && i < MAX_ARGS - 1) {
if (strcmp(token, "<") == 0) {
// 输入重定向:下一个 token 是文件名
token = strtok(NULL, " \t\n");
redir->input_file = token;
}
else if (strcmp(token, ">") == 0) {
// 输出重定向(覆盖)
token = strtok(NULL, " \t\n");
redir->output_file = token;
redir->append = 0;
}
else if (strcmp(token, ">>") == 0) {
// 输出重定向(追加)
token = strtok(NULL, " \t\n");
redir->output_file = token;
redir->append = 1;
}
else {
// 普通参数,存入 args 数组
args[i++] = token;
}
token = strtok(NULL, " \t\n");
}
args[i] = NULL; // execvp 需要 NULL 结尾
}解析过程:
cpp
输入: ls -l > list.txt
token="ls" → args[0]="ls"
token="-l" → args[1]="-l"
token=">" → 识别为输出重定向,下一个 token="list.txt" → output_file="list.txt"
token=NULL → 结束
结果: args[0]="ls", args[1]="-l", args[2]=NULL
redir->output_file="list.txt", redir->append=03. 执行函数:fork + 重定向 + exec
cpp
void execute(char **args, Redir *redir) {
pid_t pid = fork();
if (pid == 0) {
// ========== 子进程 ==========
// 子进程会复制父进程的 fd_array,但修改只影响自己
// 【输入重定向】让 stdin(0) 从文件读取
if (redir->input_file) {
int fd = open(redir->input_file, O_RDONLY);
if (fd < 0) { perror("open input"); exit(1); }
dup2(fd, 0); // fd_array[0] 指向文件
close(fd); // 关闭原 fd,因为 0 已经指向它了
}
// 【输出重定向】让 stdout(1) 写入文件
if (redir->output_file) {
int flags = O_WRONLY | O_CREAT;
// 追加模式用 O_APPEND,覆盖模式用 O_TRUNC
flags |= redir->append ? O_APPEND : O_TRUNC;
int fd = open(redir->output_file, flags, 0666);
if (fd < 0) { perror("open output"); exit(1); }
dup2(fd, 1); // fd_array[1] 指向文件
close(fd);
}
// 执行命令(此时 printf/write 都会写入文件)
execvp(args[0], args);
// exec 失败才会走到这里
perror("execvp");
exit(1);
}
else if (pid > 0) {
// ========== 父进程 ==========
// 父进程的 fd 没有被修改,等待子进程结束
wait(NULL);
}
else {
perror("fork");
}
}为什么重定向代码要放在 fork 之后的子进程?
因为重定向只应该影响当前命令,不应该影响 Shell 本身。如果直接在 Shell 进程里修改 fd,那么执行完命令后 Shell 的标准输出就永久指向文件了,后续命令的输出都会写到文件里。fork 后子进程是 Shell 的副本,子进程修改自己的 fd 不影响父进程。
常见问题与坑
1.为什么重定向后 printf 不输出?
printf有用户态缓冲区,重定向到文件后变为全缓冲,需要fflush或程序正常退出才会写入。但 Shell 中执行的是外部命令(如ls),它们内部会用fflush或直接write,所以一般没问题。
2.为什么先 dup2 再 close(fd)?
dup2后,fd 和 1 都指向同一个文件。close(fd)只是减少引用计数,文件不会真正关闭因为 1 还在指向它。不关也可以,但会浪费一个 fd 条目。
3.同时有输入和输出重定向怎么办?
代码中已经支持,分别执行两个
if块即可,顺序无关紧要。
4.文件打开失败怎么办?
必须检查
open返回值,失败时打印错误并exit(1),否则会继续执行危险操作。
三.理解"⼀切皆⽂件"
⾸先,在windows中是⽂件的东西,它们在linux中也是⽂件;其次⼀些在windows中不是⽂件的东西,⽐如进程、磁盘、显⽰器、键盘这样硬件设备也被抽象成了⽂件,你可以使⽤访问⽂件的⽅法访问它们获得信息;甚⾄管道,也是⽂件;将来我们要学习⽹络编程中socket(套接字)这样的东西,使⽤的接⼝跟⽂件接⼝也是⼀致的。这样做最明显的好处是,开发者仅需要使⽤⼀套 API 和开发⼯具,即可调取 Linux 系统中绝⼤部分的资源。举个简单的例⼦,Linux 中⼏乎所有读(读⽂件,读系统状态,读PIPE)的操作都可以⽤read 函数来进⾏;⼏乎所有更改(更改⽂件,更改系统参数,写 PIPE)的操作都可以⽤ write 函数来进⾏。之前我们讲过,当打开⼀个⽂件时,操作系统为了管理所打开的⽂件,都会为这个⽂件创建⼀个file结构体,该结构体定义在 /usr/src/kernels/3.10.0-
1160.71.1.el7.x86_64/include/linux/fs.h 下,以下展⽰了该结构部分我们关系的内容:
cpp
struct file {
struct inode
*f_inode;
/* cached value */
const struct file_operations
*f_op;
...
atomic_long_t
f_count;
// 表⽰打开⽂件的引⽤计数,如果有多个⽂件指针指
向它,就会增加f_count的值。
unsigned int
f_flags;
// 表⽰打开⽂件的权限
fmode_t
f_mode;
// 设置对⽂件的访问模式,例如:只读,只写等。所
有的标志在头⽂件<fcntl.h> 中定义
loff_t
f_pos;
// 表⽰当前读写⽂件的位置
...
} __attribute__((aligned(4))); /* lest something weird decides that 2 is OK
*/- struct file 中的 f_op 指针指向了⼀个 file_operations 结构体,这个结构体中的成员除了struct module* owner 其余都是函数指针。该结构和 struct file 都在fs.h下。
cpp
struct file_operations {
struct module *owner;
//指向拥有该模块的指针;
loff_t (*llseek) (struct file *, loff_t, int);
//llseek ⽅法⽤作改变⽂件中的当前读/写位置, 并且新位置作为(正的)返回值.
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
//⽤来从设备中获取数据. 在这个位置的⼀个空指针导致 read 系统调⽤以 -
EINVAL("Invalid argument") 失败. ⼀个⾮负返回值代表了成功读取的字节数( 返回值是⼀个
"signed size" 类型, 常常是⽬标平台本地的整数类型).
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
//发送数据给设备. 如果 NULL, -EINVAL 返回给调⽤ write 系统调⽤的程序. 如果⾮负,
返回值代表成功写的字节数.
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long,loff_t);
//初始化⼀个异步读 -- 可能在函数返回前不结束的读操作.
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
//初始化设备上的⼀个异步写.
int (*readdir) (struct file *, void *, filldir_t);
//对于设备⽂件这个成员应当为 NULL; 它⽤来读取⽬录, 并且仅对**⽂件系统**有⽤.
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
//mmap ⽤来请求将设备内存映射到进程的地址空间. 如果这个⽅法是 NULL, mmap 系统调⽤
返回 -ENODEV.
int (*open) (struct inode *, struct file *);
//打开⼀个⽂件
int (*flush) (struct file *, fl_owner_t id);
//flush 操作在进程关闭它的设备⽂件描述符的拷⻉时调⽤;
int (*release) (struct inode *, struct file *);
//在⽂件结构被释放时引⽤这个操作. 如同 open, release 可以为 NULL.
int (*fsync) (struct file *, struct dentry *, int datasync);
//⽤⼾调⽤来刷新任何挂着的数据.
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
//lock ⽅法⽤来实现⽂件加锁; 加锁对常规⽂件是必不可少的特性, 但是设备驱动⼏乎从不实现它.
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *,int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned lonunsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_ *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *,
size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **);
};file_operation 就是把系统调⽤和驱动程序关联起来的关键数据结构,这个结构的每⼀个成员都对应着⼀个系统调⽤。读取 file_operation 中相应的函数指针,接着把控制权转交给函数,从⽽完成了Linux设备驱动程序的⼯作。
图解:
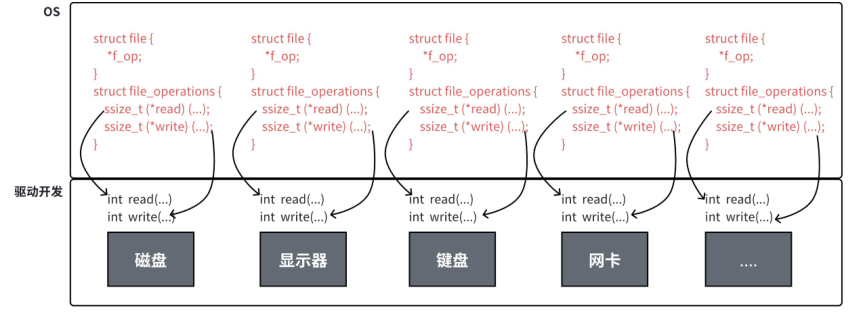
上图中的外设,每个设备都可以有⾃⼰的read、write,但⼀定是对应着不同的操作⽅法!!但通过struct file 下 file_operation 中的各种函数回调,让我们开发者只⽤file便可调取 Linux 系统中绝⼤部分的资源!!这便是"linux下⼀切皆⽂件"的核⼼理解。
四.FILE
- 因为IO相关函数与系统调⽤接⼝对应,并且库函数封装系统调⽤,所以本质上,访问⽂件都是通过fd访问的。
- 所以C库当中的FILE结构体内部,必定封装了fd。
运行结果:
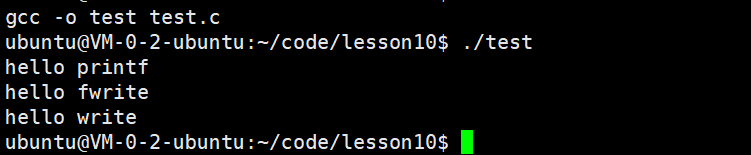
但如果对进程实现输出重定向呢? ./test > file , 我们发现结果变成了:
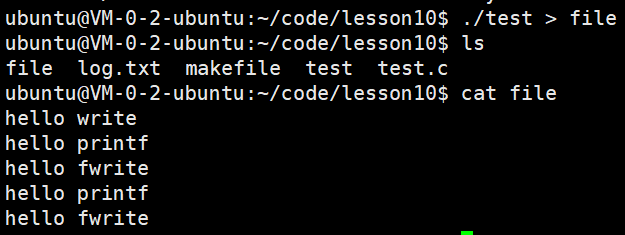
我们发现 printf 和 fwrite (库函数)都输出了2次,⽽ write 只输出了⼀次(系统调⽤)。为
什么呢?肯定和fork有关!
- ⼀般C库函数写⼊⽂件时是全缓冲的,⽽写⼊显⽰器是⾏缓冲。
- printf fwrite 库函数+会⾃带缓冲区(进度条例⼦就可以说明),当发⽣重定向到普通⽂件时,数据的缓冲⽅式由⾏缓冲变成了全缓冲。
- ⽽我们放在缓冲区中的数据,就不会被⽴即刷新,甚⾄fork之后
- 但是进程退出之后,会统⼀刷新,写⼊⽂件当中。
- 但是fork的时候,⽗⼦数据会发⽣写时拷⻉,所以当你⽗进程准备刷新的时候,⼦进程也就有了同样的⼀份数据,随即产⽣两份数据。
- write 没有变化,说明没有所谓的缓冲。
综上:
printf fwrite 库函数会⾃带缓冲区,⽽ write 系统调⽤没有带缓冲区。另外,我们这⾥所说的缓冲区,都是⽤⼾级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区。
那这个缓冲区谁提供呢?
printf fwrite 是库函数, write 是系统调⽤,库函数在系统调⽤的"上层", 是对系统调⽤的"封装",但是 write 没有缓冲区,⽽ printf fwrite 有,⾜以说明,该缓冲区是⼆次加上的,⼜因为是C,所以由C标准库提供。
五.缓冲区
5-1 什么是缓冲区
缓冲区是内存空间的⼀部分。也就是说,在内存空间中预留了⼀定的存储空间,这些存储空间⽤来缓冲输⼊或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输⼊设备还是输出设备,分为输⼊缓冲区和输出缓冲区。
5-2 为什么要引⼊缓冲区机制
- 读写⽂件时,如果不会开辟对⽂件操作的缓冲区,直接通过系统调⽤对磁盘进⾏操作(读、写等),那么每次对⽂件进⾏⼀次读写操作时,都需要使⽤读写系统调⽤来处理此操作,即需要执⾏⼀次系统调⽤,执⾏⼀次系统调⽤将涉及到CPU状态的切换,即从⽤⼾空间切换到内核空间,实现进程上下⽂的切换,这将损耗⼀定的CPU时间,频繁的磁盘访问对程序的执⾏效率造成很⼤的影响。为了减少使⽤系统调⽤的次数,提⾼效率,我们就可以采⽤缓冲机制。⽐如我们从磁盘⾥取信息,可以在磁盘⽂件进⾏操作时,可以⼀次从⽂件中读出⼤量的数据到缓冲区中,以后对这部分的访问就不需要再使⽤系统调⽤了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作⼤⼤快于对磁盘的操作,故应⽤缓冲区可⼤⼤提⾼计算机的运⾏速度。
- ⼜⽐如,我们使⽤打印机打印⽂档,由于打印机的打印速度相对较慢,我们先把⽂档输出到打印机相应的缓冲区,打印机再⾃⾏逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区就是⼀块内存区,它⽤在输⼊输出设备和CPU之间,⽤来缓存数据。它使得低速的输⼊输出设备和⾼速的CPU能够协调⼯作,避免低速的输⼊输出设备占⽤CPU,解放出CPU,使其能够⾼效率⼯作。
缓冲区的刷新策略
1.核心概念
刷新策略 = 一般策略 + 特殊策略
一般策略:系统自动触发的刷新机制
特殊策略:用户或进程状态变化触发的刷新
2.一般策略(三种刷新模式)
| 刷新方式 | 触发条件 | 典型场景 | 示例 |
|---|---|---|---|
| 立即刷新(无缓冲) | 数据立刻写入 | stderr | fprintf(stderr, "error") |
| 行刷新(行缓冲) | 遇到 \n |
终端交互 | printf("hello\n") |
| 满刷新(全缓冲) | 缓冲区满了 | 普通文件 | printf 重定向到文件 |
2.1 行缓冲(Line Buffered)
cpp
#include <stdio.h>
#include <unistd.h>
int main() {
printf("hello"); // 没有 \n,数据留在缓冲区
sleep(2); // 等待2秒,屏幕上没有输出
printf(" world\n"); // 遇到 \n,缓冲区刷新,输出 "hello world"
return 0;
}2.2 全缓冲(Full Buffered)
cpp
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
// 重定向到文件后,stdout 变成全缓冲
close(1);
open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("hello\n"); // \n 不会触发刷新!数据留在缓冲区
printf("world\n"); // 还是留在缓冲区
// 程序退出时才会刷新,log.txt 里才能看到内容
return 0;
}2.3 立即刷新(No Buffered)
cpp
#include <stdio.h>
int main() {
fprintf(stderr, "error message\n"); // stderr 无缓冲,立即输出
// 即使没有 \n,也会立刻显示
return 0;
}3.特殊策略(四种触发方式)
| 触发方式 | 代码示例 | 说明 |
|---|---|---|
| 用户强制刷新 | fflush(stdout) |
手动刷新指定缓冲区 |
| 进程正常退出 | return 0 或 exit(0) |
自动刷新所有缓冲区 |
| 进程异常退出 | _exit() 或 abort() |
不刷新缓冲区 |
| 关闭文件 | fclose(fp) |
先刷新再关闭 |
3.1 用户强制刷新:fflush
cpp
#include <stdio.h>
#include <unistd.h>
int main() {
printf("hello"); // 没有 \n,数据在缓冲区
fflush(stdout); // 强制刷新,立刻输出 "hello"
printf("world"); // 数据在缓冲区
// 不加 fflush,程序退出时会自动刷新
return 0;
}3.2 进程退出:exit 和 _exit
cpp
#include <stdio.h>
#include <unistd.h>
int main() {
printf("hello"); // 数据在缓冲区
// exit(0) → 刷新缓冲区,输出 "hello"
// _exit(0) → 不刷新缓冲区,什么也不输出
return 0;
}| 退出方式 | 是否刷新缓冲区 | 使用场景 |
|---|---|---|
return 0 |
是 | 正常退出 |
exit(0) |
是 | 正常退出 |
_exit(0) |
否 | 异常退出、子进程专用 |
abort() |
否 | 异常终止 |
3.3 fclose 自动刷新
cpp
#include <stdio.h>
int main() {
FILE *fp = fopen("log.txt", "w");
fprintf(fp, "hello");
// 没有 fflush,数据在缓冲区
fclose(fp); // fclose 内部会先刷新缓冲区,再关闭文件
return 0;
}4.经典问题:fork + 缓冲区
cpp
#include <stdio.h>
#include <unistd.h>
int main() {
printf("hello");
fork();
return 0;
}直接运行 :输出 1 次 hello(行缓冲,遇到 \n 才刷新?这里没有 \n!)
区分:
终端运行 :行缓冲,但程序退出时
return会刷新 → 输出 1 次重定向文件 :全缓冲,
fork复制缓冲区 → 父进程退出刷新一次,子进程退出刷新一次 → 输出 2 次
例子说明:理解缓冲区刷新策略,才能解释 fork 后的输出次数问题。
5-3缓冲区内型
标准I/O提供了3种类型的缓冲区。
- 全缓冲区:这种缓冲⽅式要求填满整个缓冲区后才进⾏I/O系统调⽤操作。对于磁盘⽂件的操作通常使⽤全缓冲的⽅式访问。
- ⾏缓冲区:在⾏缓冲情况下,当在输⼊和输出中遇到换⾏符时,标准I/O库函数将会执⾏系统调⽤操作。当所操作的流涉及⼀个终端时(例如标准输⼊和标准输出),使⽤⾏缓冲⽅式。因为标准I/O库每⾏的缓冲区⻓度是固定的,所以只要填满了缓冲区,即使还没有遇到换⾏符,也会执⾏I/O系统调⽤操作,默认⾏缓冲区的⼤⼩为1024。
- ⽆缓冲区:⽆缓冲区是指标准I/O库不对字符进⾏缓存,直接调⽤系统调⽤。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显⽰出来
- 除了上述列举的默认刷新⽅式,下列特殊情况也会引发缓冲区的刷新:
缓冲区满时;
执⾏flush语句;
进程结束
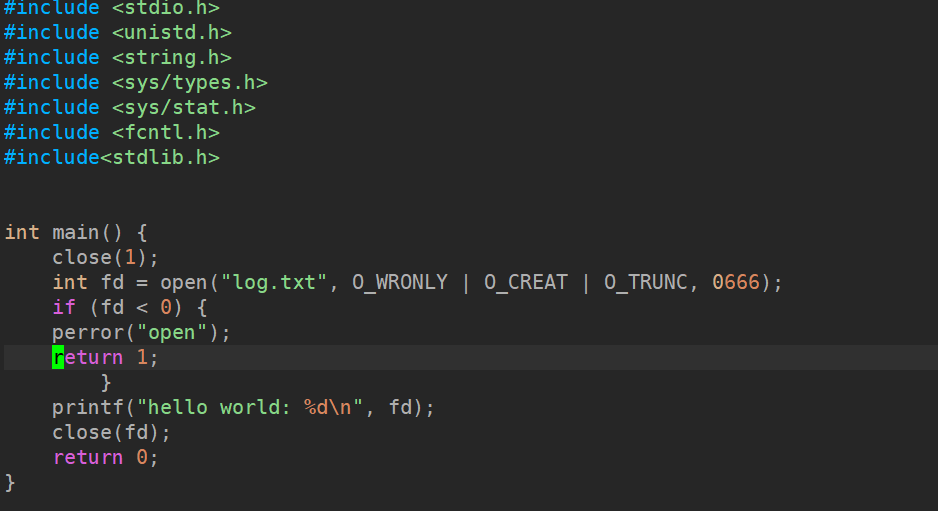

- 这是由于我们将1号描述符重定向到磁盘⽂件后,缓冲区的刷新⽅式成为了全缓冲。⽽我们写⼊的内容并没有填满整个缓冲区,导致并不会将缓冲区的内容刷新到磁盘⽂件中。怎么办呢?可以使⽤fflush强制刷新下缓冲区。
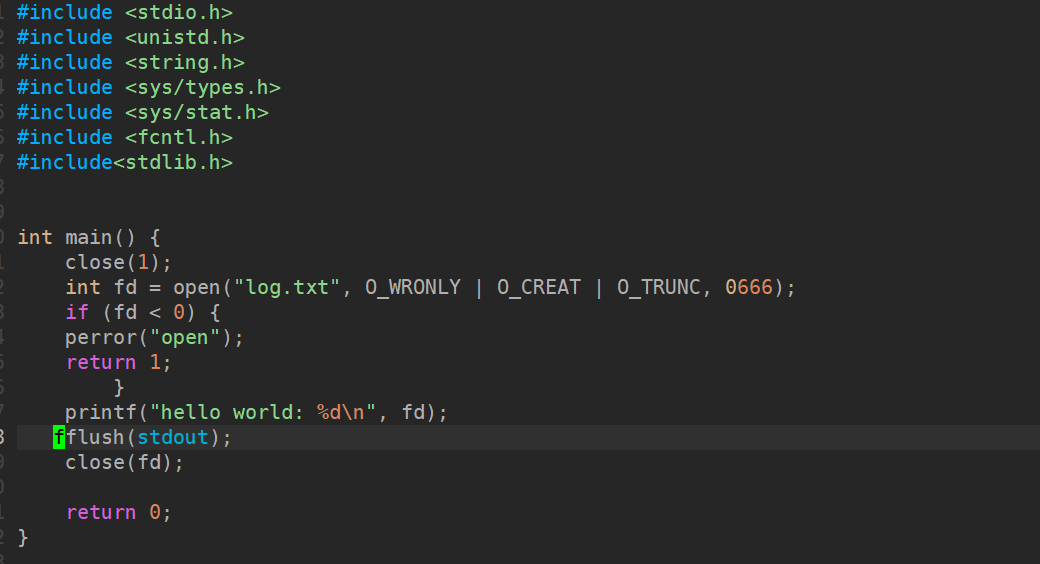

还有⼀种解决⽅法,刚好可以验证⼀下stderr是不带缓冲区的,代码如下:
cpp
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
close(2);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 0;
}
perror("hello world");
close(fd);
return 0;
}
底层原理分析
1 .文件描述符重定向过程
| 步骤 | 代码 | fd 状态 |
|---|---|---|
| 初始 | 程序启动 | fd 0→键盘,fd 1→显示器,fd 2→显示器 |
| 1 | close(2) |
fd 2 变为空闲 |
| 2 | open("log.txt") |
分配最小未使用 fd = 2,fd 2 指向 log.txt |
| 3 | perror("hello world") |
往 stderr(fd 2)写入,实际写入 log.txt |
2 .为什么不需要 fflush?
核心原因 :stderr 是**无缓冲(立即刷新)**模式。
| 标准流 | 缓冲模式 | 刷新条件 | 是否需要 fflush |
|---|---|---|---|
stdout(终端) |
行缓冲 | 遇到 \n 或退出 |
通常不需要 |
stdout(文件) |
全缓冲 | 缓冲区满或退出 | 需要 |
stderr |
无缓冲 | 立即写入 | 不需要 |
perror 内部操作的是 stderr,而 stderr 默认是无缓冲的,所以数据立即通过 write 系统调用进入内核,不经过用户态缓冲区。
3验证对比
用 stdout 做同样的事(需要 fflush)
cpp
close(1); // 关闭 stdout
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("hello world\n"); // 数据进缓冲区
// 没有 fflush,数据丢失!
close(fd);用 stderr 做同样的事(不需要 fflush)
cpp
close(2); // 关闭 stderr
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
perror("hello world"); // 数据直接 write,无需刷新
close(fd); // 数据已经在文件里总结:
stderr是无缓冲模式,所以重定向stderr到文件后,perror的内容会立即写入文件,无需fflush。这正好验证了stderr不带缓冲区的特性。