
目录
[First. 三种遍历的介绍](#First. 三种遍历的介绍)
[Second. 三种遍历的递归解法与二叉树最近公共祖先](#Second. 三种遍历的递归解法与二叉树最近公共祖先)
[Third. 三种遍历的非递归解法](#Third. 三种遍历的非递归解法)
[Fourth. 前、中、后序Morris遍历法](#Fourth. 前、中、后序Morris遍历法)
[Fifth. 三种遍历的使用](#Fifth. 三种遍历的使用)
[Sixth. 结语](#Sixth. 结语)
前言
二叉树的前、中、后序遍历作为我们刚学二叉树这个数据结构就会接触到的存在,它的递归实现较为简单,它的框架也是二叉树oj用递归类解法时常用的框架。但同时我们也要来深入学习一下,了解它的通用性在哪。再者,前、中、后序遍历都有非递归类和进一步优化的Morris解法,我们也都来了解一下吧。
let's go!!!!!!!!
First. 三种遍历的介绍
概括来说,三种排序的顺序为:
前序遍历:根 -> 左 -> 右
中序遍历:左 -> 根 -> 右
后序遍历:左 -> 右 -> 根
按照这个图像比拟,三者的顺序就是:
前序遍历:1 -> 2 -> 4 -> 5 -> 6 -> 7 -> 3 -> 8 -> 9
中序遍历:4 -> 2 -> 6 -> 5 -> 7 -> 1 -> 3 -> 9 -> 8
后序遍历:4 -> 6 -> 7 -> 5 -> 2 -> 9 -> 8 -> 3 -> 1
接下来,让我们看看如何得到这些结果吧!
Second. 三种遍历的递归解法与二叉树最近公共祖先
Leetcode中题目链接:
145. 二叉树的后序遍历 - 力扣(LeetCode)
在讲这个之前,我们先来看看二叉树遍历的通用模板:
cppvoid traversal(struct TreeNode* root)//遍历模板 { if(root==NULL)//当当前节点是空节点就返回 { return; } //<1> traversal(root->left);//将大问题(大树)转化为小问题(当前节点的左子树) //<2> traversal(root->right);//同上 //<3> }
我们可以看到通用模板还是非常亲民的。其实,我们的前、中、后序遍历也不过是在上面代码中标注的一、二、三位置中对当前的节点做相似的操作。我们来看代码:
cppvoid traversal(struct TreeNode* root,int* arr,int* i) { if(root==NULL) { return; } //<1>:前序遍历 //arr[(*i)++]=root->val; traversal(root->left,arr,i); //<2>:中序遍历 //arr[(*i)++]=root->val; traversal(root->right,arr,i); //<3>:后序遍历 //arr[(*i)++]=root->val; }
代码中的一二三对应前中后分别对于数据的处理,数组arr中存储的是二叉树存储的值按照遍历的先后顺序的排列,这里的i通过传地址为数组赋值,已经赋值过的绝不回头(在oj题--二叉树最近公共祖先中,传的是值,数组中存的相当于是每一层的二叉树的数值,根据当前情况不断修正每一个的值,直到遇到正确结果,要根据我们的需求动态使用传参)。这样,我们就完成了二叉树的前中后序递归式遍历。
Leetcode中题目链接:236. 二叉树的最近公共祖先 - 力扣(LeetCode)
代码实现与解释:
cpp//存储父节点 void cal_node(struct TreeNode* root,int* i)//计算二叉树节点数目 { if(root==NULL) { return; } (*i)++;//加上数据处理 cal_node(root->left,i);//依旧通用模板(将大问题(大树)转化为小问题(当前节点的左子树)) cal_node(root->right,i); } void find_ancestor(struct TreeNode* root,struct TreeNode** arr,int i,int num,int* end) { if(*end!=-1)//剪枝 { return; } if(root==NULL) { return; } arr[i]=root;//同前中后序遍历相似 用数组记录轨迹 if(arr[i]->val==num) { *end=i;//找到修改剪枝参数 快速返回 } find_ancestor(root->left,arr,i+1,num,end);//通用模板之改变参数版 传值传参修正轨迹(数组每一个数值 代表其从根节点出发的的轨迹) find_ancestor(root->right,arr,i+1,num,end); } struct TreeNode* lowestCommonAncestor(struct TreeNode* root, struct TreeNode* p, struct TreeNode* q) { int i=0; cal_node(root,&i);//i为数节点数目 struct TreeNode** arr1=(struct TreeNode**)malloc(sizeof(struct TreeNode*)*i);//创建arr1和arr2记录两次遍历到正确位置(题目中给的要找他们最近公共祖先的两个)的轨迹,从轨迹中招到第一次重合的部分,即为两者最近公共祖先 struct TreeNode** arr2=(struct TreeNode**)malloc(sizeof(struct TreeNode*)*i); int end=-1;//剪枝(找到正确节点快速返回) find_ancestor(root,arr1,0,p->val,&end);//第一次遍历 找到p的轨迹并记录下来 int x=end;//记录一共多少步 end=-1; find_ancestor(root,arr2,0,q->val,&end); int y=end; int u=0; for(i=x;i>=0;i--) { for(u=y;u>=0;u--) { if(arr1[i]->val==arr2[u]->val)//找第一次重合位置 { goto aaa; } } } aaa: return arr1[i]; }
Third. 三种遍历的非递归解法
前序遍历
非递归的实现是用栈的实现的,我们来结合代码来看:
cppvoid cal_node(struct TreeNode* root,int* i)//计算节点数目 { if(root==NULL) { return; } (*i)++; cal_node(root->left,i); cal_node(root->right,i); } int* preorderTraversal(struct TreeNode* root, int* returnSize) { int i=0; cal_node(root,&i); *returnSize=i; int* arr=(int*)malloc(sizeof(int)*i);//开辟存储遍历过的节点的值 答案数组 int rtop=0; if(root==NULL) { return arr; } struct TreeNode** acc=(struct TreeNode**)malloc(sizeof(struct TreeNode*)*i);//栈模拟递归 int ctop=0; acc[ctop++]=root;//压入root struct TreeNode* temp=0; while(ctop!=0) { temp=acc[ctop-1];//处理栈顶元素 ctop--;//出栈 arr[rtop++]=temp->val;//将这个压入答案数组 if(temp->right!=NULL)//先压右边 { acc[ctop++]=temp->right; } if(temp->left!=NULL)//再压左边 这样按照前序遍历的顺序:左->根->右 后遍历的右节点就自然积压到栈的后面 后处理 { acc[ctop++]=temp->left; } } return arr; }
上面的关键就在于先压右边入栈,后压左边入栈。将右边的元素积压在下面,后处理,左元素先处理。这样就完成了前序遍历的非递归。
接下来,让我们来看看复杂一点的中序遍历非递归:
中序遍历
cppvoid cal_node(struct TreeNode* root,int* i) { if(root==NULL) { return; } (*i)++; cal_node(root->left,i); cal_node(root->right,i); } int* inorderTraversal(struct TreeNode* root, int* returnSize) { int i=0; cal_node(root,&i); *returnSize=i; int* arr=(int*)malloc(sizeof(int)*i); if(root==NULL) { return arr; } struct TreeNode** aaa=(struct TreeNode**)malloc(sizeof(struct TreeNode*)*i); struct TreeNode* temp=0; int top=0; aaa[top++]=root;//先将root压入栈 int q=0; while(top!=0) { while(aaa[top-1]->left!=NULL)//不断将左边的元素压入栈 但不处理 留待后面发落 { aaa[top++]=aaa[top-1]->left; } temp=aaa[top-1];//用temp保存值 因为后面要判断它有没有右子树 arr[q++]=temp->val;//将左子为NULL的节点处理掉(按照中序遍历的顺序) top--;//出栈 while(top!=0&&temp->right==NULL)//将右子为NULL的全部处理掉(右子为NULL说明右边不用处理) { temp=aaa[top-1];//这里的temp存储的是右子为NULL节点的父亲节点 我们需要对这个先处理 因为中序遍历是先处理左 此时左已经在上面处理完了 现在要先处理根节点 后才处理右节点 arr[q++]=temp->val; top--; } if(temp->right!=NULL)//!关键!:当此时的temp右子不为NULL 我们就要把这个当成是"单独的一棵树"来处理 处理他的左右根 体现的也是递归中大问题转化为相似的小问题 aaa[top++]=temp->right; } return arr; }
上文的关键还是在于栈的模拟递归,我们要先处理根节点的左子,因此我们要把它的左孩子先压进来,这个左孩子也要先处理它的左孩子才能处理他自己,因此它也要把它的左孩子压进来,这样大的问题(大的树)就会不断展开为小的问题(小的树),直到不能展开了为止(左为NULL)。
在展开的同时,我们也把问题不断积压,留到后面处理(栈的前面元素)。同时,我们不断展开的小树也会有自己的右子,我们也要把这个当成单独的树来处理,也就是按照上面的流程同样的处理。(递归本质:大问题转化为相似的小问题)
这样,我们就解决了中序遍历非递归,我们来看看最后的boss--后序遍历非递归吧。
后序遍历
我们先来想一下这个为什么相较于中序遍历的非递归会复杂一点?关键在于:我们要知道一棵树的右子就要知道它的根,在中序遍历中,我们访问完根就可以将这个写入答案数组里了,之后通过临时变量访问右子,但是后序遍历是先处理右子再处理根节点,这时候我们可能会想到一个方法:我们可以不先把根出栈,等到右子处理完再去处理根节点,但是我们怎么知道这个根节点是右子处理完的还是没处理完的?解决这个问题的解法就在于--要用一个东西来记录历史访问记录:
cppvoid cal_node(struct TreeNode* root,int* i) { if(root==NULL) { return; } (*i)++; cal_node(root->left,i); cal_node(root->right,i); } int* postorderTraversal(struct TreeNode* root, int* returnSize) { int i=0; cal_node(root,&i); *returnSize=i; int* arr=(int*)malloc(sizeof(int)*i); int rtop=0; if(root==NULL) { return arr; } struct TreeNode** acc=(struct TreeNode**)malloc(sizeof(struct TreeNode*)*i); int ctop=0; struct TreeNode* prev=NULL;//维护一个变量记录历史访问记录 while(ctop!=0||root!=NULL) { while(root!=NULL)//依旧先压左边 同时我们用root的状态来决定是否处理 { acc[ctop++]=root; root=root->left; } if(acc[ctop-1]->right!=NULL&&acc[ctop-1]->right!=prev)//当right不等于NULL而且它的右子没有被访问过 就引入新节点处理 { root=acc[ctop-1]->right;//更新root状态 将这个节点当成"小树"来处理 } else { prev=acc[ctop-1];//将要被处理的节点记作历史访问 arr[rtop++]=acc[ctop-1]->val;//处理 ctop--;//出栈 //这里不对root的NULL状态处理 因为我们没有压入新的节点 也就是没有新的可以当成树的来处理 } } return arr; }
这样,我们通过维护一个记录历史访问的变量来解决了这个问题,可以说后序遍历非递归是基于中序遍历非递归的,只是在这个上面做了特殊的处理来适应新的问题。
小结
我们通过栈来模拟递归,解决了问题,栈的前面的元素相当于是递归中展开了的但是没有进行完的函数 ,栈顶元素相当于是当前正在处理的函数 ,但这样有时还不够,我们有时还要维护一些特殊的变量来正确的处理数据。
P.S. 关于非递归的更多可以看我另一个博客:八种常见排序的详细介绍和测试比较适用范围(总集篇)-CSDN博客
这里的非递归实现我们用到了栈,空间复杂度为O(N)。那么我们是否能用常数级别 的空间复杂度解决呢?当然可以,这就是线索二叉树,具体的,这个遍历法名为:
Fourth. 前、中、后序Morris遍历法
前序遍历
Morris遍历关键在于我们要在已经存在的二叉树上修改,从而就不用另外开辟空间来处理,我们来看前序遍历的Morris遍历:
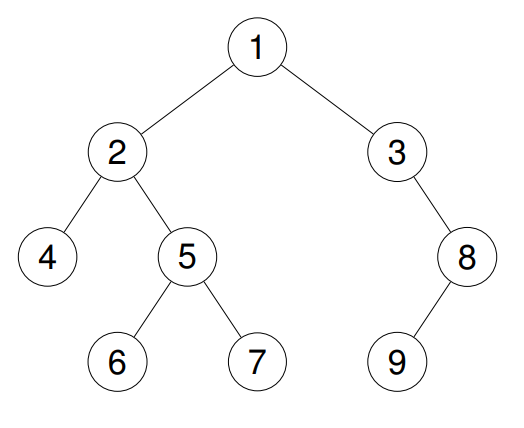
cppint* preorderTraversal(struct TreeNode* root, int* returnSize) { int* arr=(int*)malloc(sizeof(int)*101);//答案数组 int rtop=0; struct TreeNode* prev=0; while(root!=NULL) { if(root->left!=NULL)//当左边不为NULL时 说明左子还可以处理 关键是在于我们向下遍历怎么回来? 我们来看下面的操作: { prev=root->left; while(prev->right!=NULL&&prev->right!=root) { prev=prev->right; } //上面操作是找到当前节点的左子树的最右边的节点 因为每当节点向左遍历 prev此时的位置是遍历的终末 当遍历到prev说明这个左子树已经遍历完了 可以回去了 if(prev->right!=NULL)//当这个prev右边不是NULL 说明这个prev已经被处理过了 即这个节点的左子树已经处理过了 不用处理 接下来就走到右子树处理右子 { prev->right=NULL;//处理完还原指向 root=root->right; } else { prev->right=root->right;//将prev指向root的右孩子 当root的左子处理完 就直接到root的右子开始处理 这是因为前序遍历是先处理根在处理左最后是右 这里的处理也是符合前序遍历顺序 arr[rtop++]=root->val;//放入答案数组 root=root->left;//转向左子开始处理(依旧是递归大问题转向小问题) } } else { arr[rtop++]=root->val;//左边为空 左子不用处理 将当前根节点值放入答案数组转向右边 处理右子 root=root->right; } } *returnSize=rtop; return arr; }
借助图来看一下:
这个方法的关键就在于维护一个prev变量,使得root向下遍历可以回来,这就做到了栈的事。栈是保存前面的全部状态,这个是只保留最有用的一击毙命。
接下来,我们来看看中序遍历的Morris遍历法:
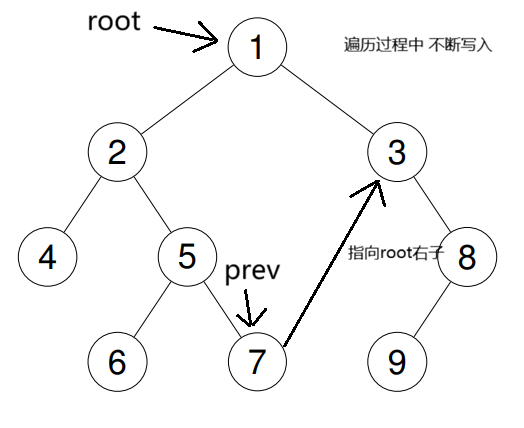
中序遍历
中序遍历还是上面方法的应用,改变就在于依靠prev回去的位置,前序遍历是回到root的右子,而中序遍历是到root本身,这和中序遍历的顺序有关系,我们就代码来看看吧:
cppint* inorderTraversal(struct TreeNode* root, int* returnSize) { int i=0; int* aaa=(int*)malloc(sizeof(int)*101); struct TreeNode* prev=NULL; while(root!=NULL) { if(root->left!=NULL)//当左边为空依旧是这个处理 { prev=root->left; while(prev->right!=NULL&&prev->right!=root) { prev=prev->right; } if(prev->right==NULL) { prev->right=root;//改变prev的指向 因为中序遍历是左到根再到右 他不能是处理一步 写入答案数组一个 root = root->left; } else { aaa[i++]=root->val;//等到这时候再写入 因为当这个的指向不是NULL时 说明左子以及处理完了 可以来处理根了 prev->right=NULL; root=root->right; } } else { aaa[i++]=root->val;//左子为空 左边不用处理 就直接处理根 转向右子 root=root->right; } } *returnSize=i; return aaa; }
借助图来看一下:
中序遍历改变的也就是prev指向的和处理数据将数据放入答案数组里的这两个过程,剩下来的于前序遍历相似。
接下来,让我们来看看后序遍历的Morris遍历吧:
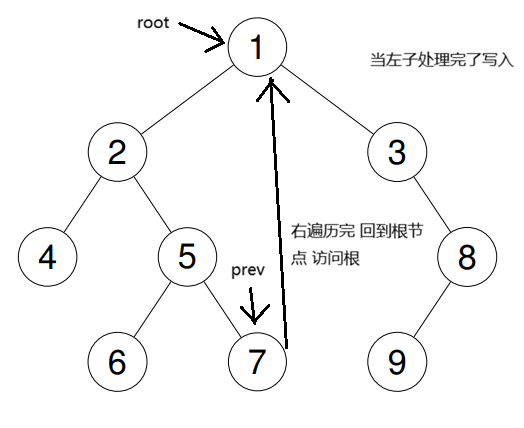
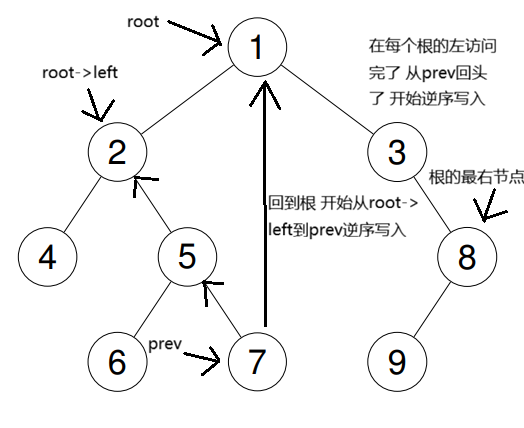
后序遍历
后序遍历与之前的相比还是有比较多的不同的,因为他是要先处理完右边再去处理根节点,关键我们这个Morris遍历法它是没有办法做到从右边回到根节点的。因此,我们要用不同的方式去处理,我们来看代码:
cpp//Morris void reverse(struct TreeNode* start)//反转树节点 { struct TreeNode* temp=start; struct TreeNode* mid=start->right; struct TreeNode* end=0; while(mid!=NULL) { end=mid->right; mid->right=start; start=mid; mid=end; } temp->right=NULL; } void write1(struct TreeNode* start,int* arr,int* top)//将节点值写入答案数组 { while(start!=NULL) { arr[(*top)++]=start->val; start=start->right; } } int* postorderTraversal(struct TreeNode* root, int* returnSize) { int* arr=(int*)malloc(sizeof(int)*101); int rtop=0; if(root==NULL) { *returnSize=0; return arr; } struct TreeNode* prev=0; struct TreeNode* dummy=root; while(root!=NULL) { if(root->left==NULL)//与之前相同的处理 { root=root->right; } else { prev=root->left; while(prev->right!=NULL&&prev->right!=root) { prev=prev->right; } if(prev->right==NULL) { prev->right=root; root=root->left; } else { //关键在这里 我们无法改变这个Morris遍历的基本框架 我们就只能改变他写入答案数组的方式 即当我们发现这个节点的左子我们已经遍历完了时 我们就要写入这些 则我们以root->left为起点 prev为终点 将这一个像是链表的链反转 写入答案数组 这样我们就解决了后序遍历的遍历顺序问题 prev->right=NULL; reverse(root->left); write1(prev,arr,&rtop); reverse(prev);//恢复原样 root=root->right; } } } if(dummy->right==NULL)//得到整个树的根节点的最右节点 { prev=dummy; } else { prev=dummy->right; while(prev->right!=NULL) { prev=prev->right; } } reverse(dummy);//最后从整个树的根节点到它一直往右走的最右边的节点还没写入 我们依旧是要将其逆序写入 write1(prev, arr, &rtop); reverse(prev); *returnSize=rtop; return arr; }
借助图来看一下:
这样,我们通过改变写入答案数组的方式完成了后序遍历。
Fifth. 三种遍历的使用
这三种遍历,我们学是学了,在哪会用上呢?我们来看:
这个题目的三种方法就是我们所讲的三种递归,非递归栈实现还有Morris遍历,只是对数据的处理不同罢了。可以来把三个都试一试,巩固一波。这里给出我的做法:
cpp//先序遍历 void cal_node(struct TreeNode* root,int* i) { if(root==NULL) { return; } (*i)++; cal_node(root->left,i); cal_node(root->right,i); } void inorder(struct TreeNode* root,struct TreeNode** arr,int* i) { if(root==NULL) { return; } arr[*i]=root; (*i)++; inorder(root->left,arr,i); inorder(root->right,arr,i); } struct TreeNode** inorderTraversal(struct TreeNode* root,int i) { struct TreeNode** arr=(struct TreeNode**)malloc(sizeof(struct TreeNode*)*i); if(root==NULL) { return arr; } i=0; inorder(root,arr,&i); return arr; } void flatten(struct TreeNode* root) { if(root==NULL) { return; } int i=0; cal_node(root,&i); int q=i; struct TreeNode** arr=inorderTraversal(root,i); for(i=0;i<q-1;i++) { arr[i]->right=arr[i+1]; arr[i]->left=NULL; } arr[i]->right=NULL; arr[i]->left=NULL; } ------------------------------------------------------------------------------- //栈实现 void flatten(struct TreeNode* root) { if(root==NULL) { return ; } struct TreeNode** arr=(struct TreeNode**)malloc(sizeof(struct TreeNode*)*2001); int top=0; arr[top++]=root; struct TreeNode* temp=arr[top-1]; while(top!=0) { temp=arr[top-1]; top--; if(temp->right!=NULL) { arr[top++]=temp->right; } if(temp->left!=NULL) { arr[top++]=temp->left; } if(root!=temp) { root->right=temp; root->left=NULL; root=root->right; } } } //--------------------------------------------------------------------------- //Morris遍历 void flatten(struct TreeNode* root) { if(root==NULL) { return ; } struct TreeNode* p=0; struct TreeNode* temp=root; struct TreeNode* kkk=root; while(root!=NULL) { if(root->left==NULL) { if(kkk!=root) { kkk->right=root; kkk->left=NULL; kkk=kkk->right; } root=root->right; } else { temp=root->left; while(temp->right!=NULL&&temp->right!=root->right) { temp=temp->right; } if(temp->right==NULL) { temp->right=root->right; temp=root; root=root->left; if(kkk!=root) { kkk->right=temp; kkk->left=NULL; kkk=kkk->right; kkk->left=NULL; } } else { root=root->right; } } } }
Sixth. 结语
我们通过图解,代码注释等多种方式帮助大家了解了前中后三种遍历的三种方式,还有已经写与之相关的oj题。
这个过程同时带有着递归实现的数据处理放置的位置讲解,非递归的讲解,还有线索二叉树的一些小了解。希望这些知识可以在未来给各位读者有所帮助。
最后,祝大家可以:春风得意马蹄疾,一日看尽长安花!最后的最后,要是觉得本文还可以的话,可以点点赞,关注小编一波,谢谢大家!~