nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
L07 已说明 schedule() 的整体结构:prefill 与 decode 互斥、两个预算上限分工、prefill 分支的八步解读。其中第 6.1 节读到关键一行 if remaining < num_tokens and scheduled_seqs: break 时,只给出了一个最小定义------"chunked prefill 只对队首生效",剩下的边界判定细节明确推迟到本节。
那一行的 if 后是 A and B 两个并列条件,语义却同时回答了三个问题:长 prompt 超过单步预算时,系统是拒绝、是让它无限期等待,还是切片分多步做?切的话,谁能切、谁不能切?切完之后,剩余 token 在下一 step 如何处理?
本节解读这一行,以及它衍生出的问题:被切了一刀的 seq,剩下的 token 在下一 step 怎么算完。
读完你能:
- 解释
max_num_batched_tokens这个 step 预算与单条 prompt 长度之间的矛盾,并指出 nano-vllm 用什么策略解决 - 拆解
if remaining < num_tokens and scheduled_seqs: break的 and 两边各对应什么物理含义 - 解释为什么 and 右边的
scheduled_seqs不可省------省掉会导致什么具体后果 - 在
max_num_batched_tokens=1024、prompt 长度 1500 的输入下,推导出 prefill 需要几个 step、每 step 处理多少 token - 在"队首长 prompt + 多条短 seq"并存的 waiting 队列里,预测每个 step 调度器选谁、为什么
1. 长 prompt 超预算的两难
L07 第 5 节讲过 max_num_batched_tokens 是单 step 内能计算的 token 数上限。这个上限有具体来源:prefill 一次 forward 中,attention 计算的是整个 batch 内 Q × K^T 的方阵,矩阵规模为 [batch_total_tokens, batch_total_tokens],显存与算力开销都随 batch_total_tokens 平方上升,所以必须卡一个单步上限。nano-vllm 默认值 32768,可在 Config 里调整,例如设为 1024。
此处 batch_total_tokens 指本 step 整批 token 总数,与后文代码里的局部变量 num_tokens(单条 seq 本 step 需要算的 token 数)不是同一记号,只是名字相近。
但 token 上限是按"批"算的,prompt 长度是按"条"给的------用户可以提交任意长的 prompt。这就引出一个矛盾:如果某条 prompt 比 max_num_batched_tokens 还长,这一 step 单条都超出预算,调度器如何处理?
只有三个可选答案:
| 答案 | 后果 |
|---|---|
| 拒绝该请求 | 用户行为不可控,等于把预算上限暴露给上层接口 |
| 让它在 waiting 队列里永远等 | 永远没有一个 step 能容纳它,系统陷入死锁 |
| 切片分多步做(chunked prefill) | 可行------但需要一套切片规则 |
前两种均不可行,nano-vllm 选第三种。这就引出本节要解释的一行代码:if remaining < num_tokens and scheduled_seqs: break。这一行定义了"谁能被切片、什么时候终止循环"------chunked prefill 的全部边界判定都体现在 and 两边的两个条件中。
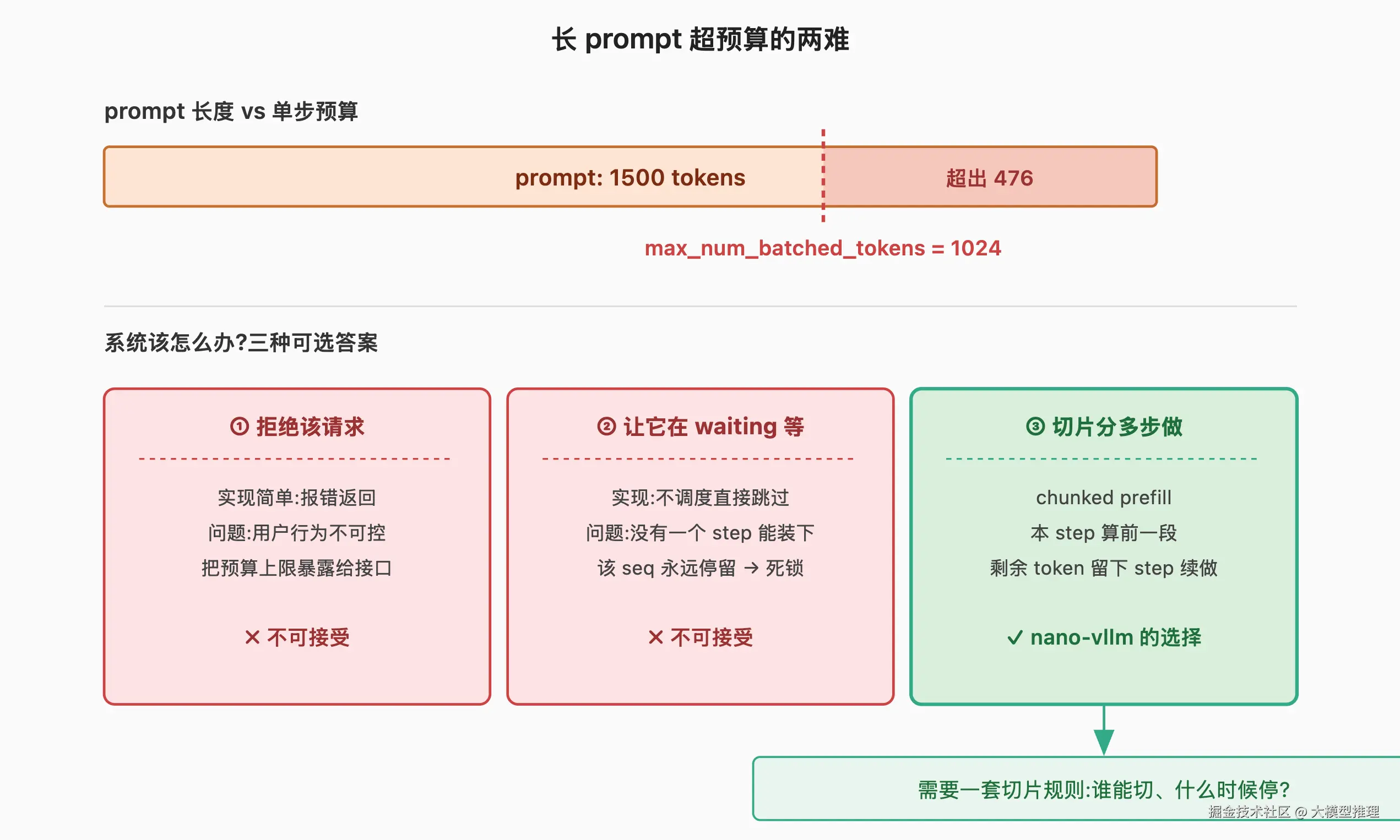
图上半部分画出问题:max_num_batched_tokens = 1024,但 prompt 长度 1500,单 step 无法容纳整条。图下半部分对照三种应对------拒绝(用户不接受)、无限期等待(死锁)、切片(可行)。第三种是 nano-vllm 的选择,但选了之后必须回答两个问题:谁能切?剩余 token 在下一 step 如何处理?这正是后续章节的内容。
切片规则全部体现在那一行的两个条件中------下面将它置于完整代码上下文中,确认它在 prefill 循环的何处生效。
2. 关键一行:队首独享分片权
完整代码及关键一行所在的上下文如下:
python
# scheduler.py:schedule(), prefill 分支
while self.waiting and len(scheduled_seqs) < self.max_num_seqs:
seq = self.waiting[0]
remaining = self.max_num_batched_tokens - num_batched_tokens
if remaining == 0:
break
if not seq.block_table:
num_cached_blocks = self.block_manager.can_allocate(seq)
if num_cached_blocks == -1:
break
num_tokens = seq.num_tokens - num_cached_blocks * self.block_size
else:
num_tokens = seq.num_tokens - seq.num_cached_tokens
if remaining < num_tokens and scheduled_seqs: # ← 本节焦点
break
...
seq.num_scheduled_tokens = min(num_tokens, remaining)
num_batched_tokens += seq.num_scheduled_tokens
...代码上下文里有一个前置判断 if remaining == 0: break------它处理本 step 预算正好用完的情况:若继续迭代,下面的 min(num_tokens, remaining) 会退化为 0,既无意义又会让本 seq 错误地被加入 scheduled_seqs,所以直接退出循环。这一行精确处理 step 预算耗尽的情形,与"关键一行"的 and 表达式是两个独立的 break,各自处理不同情况。
L07 第 6.1 节已经解释过 and 两边的两个条件分别是什么,本节要回答为什么用 and 把这两个条件连在一起、而不是只看其中一个。先列出两个条件的物理含义:
- and 左边
remaining < num_tokens:remaining = max_num_batched_tokens - num_batched_tokens是本 step 还能再算多少个 token,num_tokens是当前这条 seq 还要算多少个 token。两个分支的num_tokens算法不同------新请求按seq.num_tokens - num_cached_blocks * block_size(整段 prompt 减去 prefix cache 已经覆盖的块对齐部分;按块对齐是因为 KV cache 以 block 为单位复用,L04 已讲过),续做的 seq 按seq.num_tokens - seq.num_cached_tokens(整段 prompt 减去之前 step 已算完、被postprocess累加进来的部分,精确到 token)。两个表达式来源不同,但表示的语义都是"本 seq 本 step 还需要计算的 token 数"。and 左边的判断就是:剩余预算小于本 seq 需算量,简单说就是"本 seq 这一步不够算"。 - and 右边
scheduled_seqs:这是一个列表,记录本 step 已经调度过的 seq。Python 里列表参与 and/or 时,空列表算 False、非空算 True,所以scheduled_seqs作为 and 右边的判断就是"本 step 之前是否已经调度过别的 seq"。
Python 里 A and B 的语义是"A 和 B 同时成立才算成立",所以这一行 if A and B: break 的语义是:只有 A 和 B 同时成立,才执行 break 。反过来推一下:A 成立、B 不成立------本 seq 这一步不够算,但本 step 还没调过任何别的 seq------这种情况不 break ,继续执行下面的 num_scheduled_tokens = min(num_tokens, remaining),对本 seq 执行切片(只计算 remaining 个 token)。这种"剩余预算不够却继续算"的特例,就是"队首独享分片权"。
所有可能的输入组合如下:
remaining < num_tokens |
scheduled_seqs 非空 |
是否 break | 含义 |
|---|---|---|---|
| 否 | --- | 否 | 剩余预算足够,正常调度整段 |
| 是 | 否 | 否 | 超预算,但本条是 step 的第一条 → 切片只算 remaining 个 token |
| 是 | 是 | 是 | 超预算,且前面已有 seq 被调度 → 留到下一 step |
第二行就是本节标题里那条"分片权":表中只有一种输入会触发切片,即"本 seq 超预算 + 本 step 还没调过任何 seq",而这只在循环第一次迭代时可能出现,即当前 seq 就是 self.waiting[0]。所以"分片权"只属于队首,且每个 step 最多触发一次切片。
到这里已能回答 L08 的核心反直觉点:chunked prefill 不是"把所有超预算的 seq 都切片",而是"只切队首"。如果队首未超预算、第二条超预算,第二条不会被切,而是整条推迟到下一 step;只有队首超预算时,队首本身才会被切片。这套规则把切片的复杂度限制在最小范围------任何一个 step 内最多只有一条 seq 处于"已被切片"的状态。
为什么必须设计成只有队首能切?如果两个条件都不可省、and 右边那个判断不是冗余,那就需要用反证给出动机------下一节用反证回答。
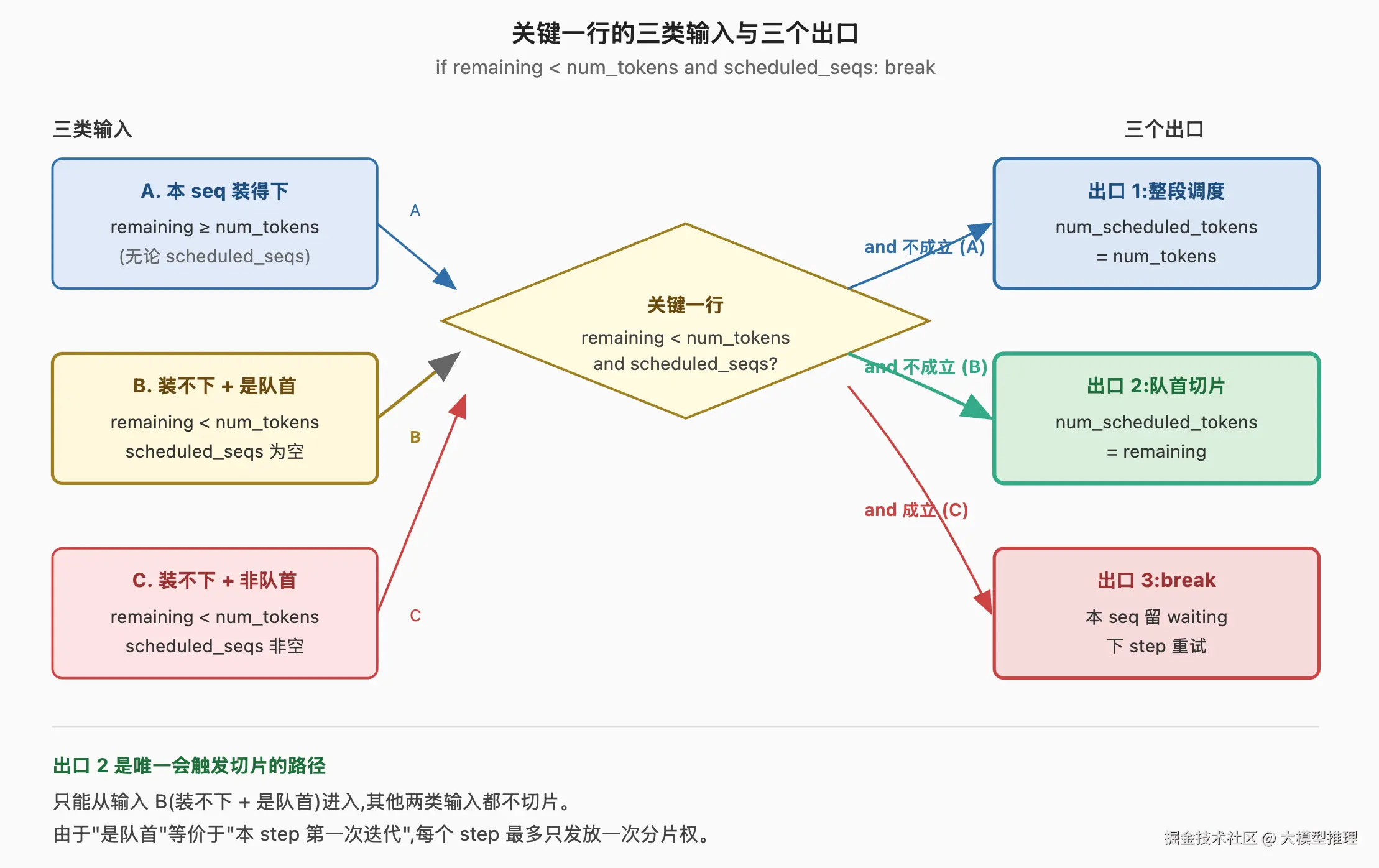
图把循环里的判断画成流程图。三个分支分别对应表中三行输入。绿色终点"切片只算 remaining 个 token"是唯一会触发切片的路径,只能由"队首超预算"分支进入。红色终点"break、推迟到下一 step"是非队首超预算时的处理。蓝色终点"整段调度"是正常路径,剩余预算足够时直接执行完整逻辑。
3. 为什么队首必须例外(死锁论证)
上一节解释了 and 两边的两个条件是什么 ,但没回答 and 右边那个为什么不能省 。这一节就从反证出发,考察省略 scheduled_seqs 之后的后果。
假设把代码改成只检查 and 左边那个条件:
python
# 反例:省掉 and 右边的 scheduled_seqs
if remaining < num_tokens:
break以下为具体场景:max_num_batched_tokens = 1024,waiting 队列只有一条 seq,prompt 长度 1500。schedule() 进入 prefill 分支,循环第一次迭代:
seq = self.waiting[0](那条长 prompt)remaining = 1024 - 0 = 1024num_tokens = 1500(假设没有 prefix cache 命中)- 检查
remaining < num_tokens→1024 < 1500→ 成立 →break
break 后退出 while 循环。这时 scheduled_seqs 是空列表。L07 第 4 节讲过 prefill 分支在 if scheduled_seqs: return scheduled_seqs, True 这一行做早返回------早返回的含义是:只要 prefill 调度过至少一条 seq,就在此行返回、不进入 decode 分支。空列表意味着此处不返回、控制流转入 decode 分支。但 running 队列也是空的(系统刚启动,所有 seq 都在 waiting),decode 分支的 while self.running 循环一次都不进入,最后那条 assert scheduled_seqs 会直接报错。
即使忽略 assert 的细节,考虑下一 step------这条长 prompt 还在 waiting 队首,num_batched_tokens 重新归零,remaining 重新是 1024,num_tokens 依然是 1500------条件依旧成立,依旧 break。这条 prompt 始终满足 break 条件,系统陷入死锁。
and 右边的 scheduled_seqs 的作用就是消除这种死锁:当本 step 没有其他 seq 作为备用调度对象时,即使当前队首超预算,也不能 break,必须执行下面的 num_scheduled_tokens = min(num_tokens, remaining)------这一行计算时,remaining < num_tokens 触发 min 取 remaining,本 step 只 prefill 队首的前 remaining 个 token。这就是切片的发生位置。
对照正常代码的行为(同样输入):
- 检查
remaining < num_tokens and scheduled_seqs→1024 < 1500成立,但scheduled_seqs是空列表 → 整个 and 表达式不成立 → 不 break - 继续执行
num_scheduled_tokens = min(1500, 1024) = 1024 num_batched_tokens累加到 1024- 检查不变式
num_cached_tokens + num_scheduled_tokens == num_tokens→0 + 1024 = 1024 ≠ 1500→ 不成立。该不变式的物理含义是:左边num_cached_tokens + num_scheduled_tokens是本 step 执行完后这条 seq 累计被算过 的 token 数(过去 step 已算的 + 本 step 即将算的),右边num_tokens是整条 prompt 的总 token 数;两者相等意味着 prefill 已经覆盖整段 prompt,seq 可以从 waiting 切到 running,不相等意味着还有 token 没算完,seq 留在 waiting。当前数值不成立 → seq 留在 waiting 队首,不切到 running - 循环下一次迭代:
remaining = 1024 - 1024 = 0→break - 退出循环,
scheduled_seqs = [seq]非空,return True
这一 step 处理了队首的前 1024 个 token,剩 476 个 token 留到下一 step。下一 step 如何续做?这就是下一节的内容。
综上,本节的论点是:and 右边的 scheduled_seqs 不是冗余,而是消除死锁的关键条件 。用 and 把"超预算"和"已经调过别的 seq"两个条件连起来,意味着"超预算"只在已经有其他 seq 备选时才触发 break;没有备选时,必须对队首执行切片------即使本 step 只能完成 remaining 个 token,也优于死锁。
这是 chunked prefill 整套机制里最反直觉的一点:按常规判断逻辑会得出"超预算就停",而这里的设计是"超预算就停,除非停下后本 step 未调度任何 seq"。
4. 剩余 token 在下一 step 怎么算完
上一节末尾遗留一个问题:队首在上一 step 被切片,剩 476 个 token 没算,下一 step 如何处理剩余 token?
答案分两部分:seq 所处队列、字段如何更新 。第一部分是 seq 的位置。第 3 节末尾的走查里已经讲过------cached + scheduled == num_tokens 不成立时,L07 第 6.1 节⑧标号对应的代码不执行,seq 不从 waiting 弹出,继续留在 waiting 队首。第二部分是字段:postprocess()(L07 第 1 节讲过的 step 收尾函数)会把 num_scheduled_tokens 累加到 num_cached_tokens 上,然后将 num_scheduled_tokens 重置为 0:
python
# scheduler.py:postprocess()
seq.num_cached_tokens += seq.num_scheduled_tokens
seq.num_scheduled_tokens = 0所以上一节 step 执行完后:这条 seq 仍在 waiting 队首,num_cached_tokens = 1024,num_scheduled_tokens = 0,num_tokens = 1500,block_table 已经在 allocate() 调用中完成填充。这里需要说明 allocate 的签名:allocate(seq, num_cached_blocks) 接收两个参数,第一个是 seq,第二个是 prefix cache 已经命中的 block 数(用于跳过这部分的物理块分配)。它按 seq 的整段 num_tokens 一次性完成剩余 block 的全部分配,所以 step 1 之后 block_table 长度直接等于 ⌈num_tokens / block_size⌉,下一 step 续做时无需再分配。
下一 step schedule() 再次进入 prefill 循环,关键差异在这一段:
python
if not seq.block_table:
num_cached_blocks = self.block_manager.can_allocate(seq)
if num_cached_blocks == -1:
break
num_tokens = seq.num_tokens - num_cached_blocks * self.block_size
else:
num_tokens = seq.num_tokens - seq.num_cached_tokens新请求(block_table 是空列表)走 if 分支:先调 can_allocate 检查显存,然后算 num_tokens = seq.num_tokens - num_cached_blocks * block_size------seq.num_tokens 是整段 prompt 长度,减去 prefix cache 已经覆盖的部分(按 block 对齐),得到"本 step 之前从未算过的 token 数"。
续做的 seq(block_table 非空)走 else 分支:num_tokens = seq.num_tokens - seq.num_cached_tokens。此时 num_cached_tokens = 1024 是上一 step 已经算完、postprocess 累加而得,所以本 step 还要算 1500 - 1024 = 476 个 token。
此处存在一个反直觉点,需显式标注:同一个局部变量 num_tokens,在 if 分支和 else 分支下含义不同。
| 分支 | num_tokens 局部变量含义 |
扣除对象 |
|---|---|---|
| if(新请求) | 整段 prompt 减去 prefix cache 命中的块对齐部分 | num_cached_blocks * block_size(按 block 对齐) |
| else(续做) | 整段 prompt 减去之前 step 已算完的部分 | seq.num_cached_tokens(token 级精确) |
两个分支扣除的对象不同------if 分支扣的是 block 对齐的 prefix 命中,else 分支扣的是 token 级精确累加的已算量------但下游使用方式完全一致。为什么同一变量名要表示两种语义?两个分支的下一行为 if remaining < num_tokens and scheduled_seqs: break------这一行只关心一件事:这条 seq 本 step 还要算多少 token,本 step 还剩多少预算 。两个分支算出的 num_tokens 都是"本 step 还要算多少 token"的具体数值,只是来源不同,下游使用方式完全一致。复用同一个变量名,是因为下游逻辑确实只需要这一个语义。
else 分支没有调用 allocate------block_table 在 seq 首次被调度时已经分配完成,下一 step 续做不需要再分配。这就解释了 L07 第 6.1 节⑥那一段为什么写 if not seq.block_table: allocate(...)------这是为续做场景设的必要条件:若不加 if not seq.block_table: 判断,下一 step 续做时会对同一条 seq 重复调用 allocate,造成 KV block 重复分配,既浪费显存也会破坏 block_table 的状态。
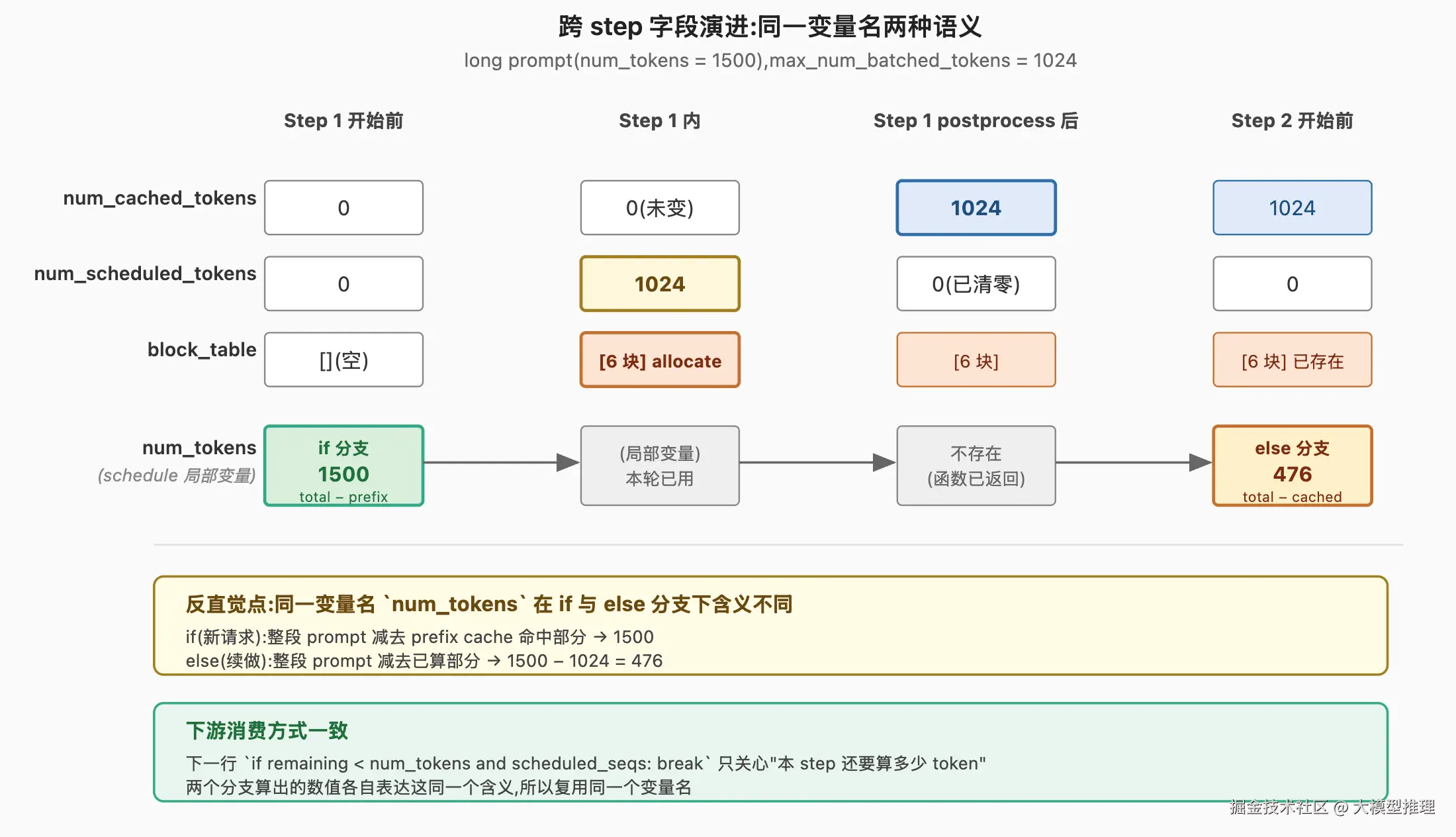
图横向画 2 个 step 的时间线,纵向逐 step 列出一条长 prompt 的关键字段。step 1 开始前:num_cached_tokens=0、block_table=[],走 if 分支,num_tokens 表示"整段 prompt 减 prefix"。step 1 内被切片,num_scheduled_tokens=1024。step 1 postprocess 之后:num_cached_tokens=1024、num_scheduled_tokens=0、block_table=[已分配]。step 2 开始前进入 else 分支,num_tokens 表示"剩余未算"。两个色块标记出"同一变量名两种语义"的对照。
5. 1500-token prompt 在 1024 预算下的走查
前四节给出了规则,本节用一组具体数值进行端到端验证,确认规则在多个 step 里如何衔接。
设定 :max_num_batched_tokens = 1024,max_num_seqs = 16,prefix cache 全空(num_cached_blocks = 0),block_size = 256。waiting 队列初始 [r1],r1 的 num_tokens = 1500。
下面表格里"整段完成检查"即第 3 节给出的不变式 num_cached_tokens + num_scheduled_tokens == num_tokens------左边累计已算 token 数、右边整条 prompt 总长,成立则 seq 转入 running,不成立则留 waiting。
Step 1
进入 prefill 分支,循环第一次迭代:
| 字段 | 值 | 来源 |
|---|---|---|
seq |
r1 | self.waiting[0] |
remaining |
1024 | max_num_batched_tokens - 0 |
seq.block_table |
[] |
新请求 |
num_cached_blocks |
0 | can_allocate 返回 |
num_tokens(局部) |
1500 | seq.num_tokens - num_cached_blocks * block_size = 1500 - 0 * 256,即整段 1500 减 prefix 命中 0 块 |
| 第 2 节关键一行 | 1024 < 1500 = True,scheduled_seqs = [] = False → and 不成立 → 不 break |
队首例外 |
num_scheduled_tokens |
1024 | min(1500, 1024) |
num_batched_tokens |
1024 | 累加 |
| 整段完成检查 | 0 + 1024 = 1024 ≠ 1500 → 不成立 |
r1 留 waiting 队首 |
调用 allocate(r1, 0) 给 r1 分配整段所需的物理块(共 ⌈1500/256⌉=6 块)。
循环第二次迭代:remaining = 1024 - 1024 = 0,触发 if remaining == 0: break,退出循环。返回 ([r1], True)。
step 1 结束后 postprocess:r1.num_cached_tokens = 0 + 1024 = 1024、r1.num_scheduled_tokens = 0。r1 仍在 waiting 队首,block_table 长度 6。
Step 2
进入 prefill 分支:
| 字段 | 值 | 来源 |
|---|---|---|
seq |
r1 | 仍在队首 |
remaining |
1024 | 新 step,累加器归零 |
seq.block_table |
[6 块已分配] |
上一 step allocate 调用完成的分配结果 |
| 分支 | else | block_table 非空 |
num_tokens(局部) |
476 | seq.num_tokens - seq.num_cached_tokens = 1500 - 1024 |
| 关键一行 | 1024 < 476 = False → and 不成立 → 不 break |
剩余预算足够 |
num_scheduled_tokens |
476 | min(476, 1024) |
num_batched_tokens |
476 | 累加 |
| 整段完成检查 | 1024 + 476 = 1500 = 1500 → 成立 |
r1 转入 running |
r1 从 waiting 弹出、append 到 running,状态切到 RUNNING。
循环第二次迭代:waiting 已空 → 退出循环。返回 ([r1], True)。
step 2 结束后 postprocess:r1.num_cached_tokens = 1024 + 476 = 1500 = num_tokens,prefill 整段完成,下一 step 起进入 decode 稳态。
整体回看
| step | num_scheduled_tokens |
num_cached_tokens (postprocess 后) |
num_batched_tokens |
remaining 起点 |
状态 |
|---|---|---|---|---|---|
| 1 | 1024 | 1024 | 1024 | 1024 | 留 waiting |
| 2 | 476 | 1500 | 476 | 1024 | 转入 running |
1500 token 的 prompt 在 1024 预算下被分为 2 段:第一段达到预算上限 1024,第二段 476 完成剩余 token。两个 step 都没浪费预算(step 1 用满,step 2 使用 476/1024,但 r1 是 waiting 唯一一条,后续无 seq 可继续填充本 step 剩余预算)。
这套机制的代价由此显现:首 token 延迟从 1 个 step 变为 2 个 step。若 prompt 更长(例如 3000),延迟将增至 3 个 step。chunked prefill 以更长的首 token 延迟为代价,换取系统不死锁------只要 prompt 单步预算容纳不下,延迟必然要分布到多个 step,这是机制本身决定的,无法规避。
6. 队首独享在多条请求并存时的表现
第 5 节走查中 waiting 队列只有一条 seq,"队首独享"对其他 seq 的影响无从体现。本节增加若干短 seq,考察一条排在队首的长 prompt(下文记为"长队首")在阻塞其他 seq 的同时,它们何时才会被调度。
设定 :max_num_batched_tokens = 1024,waiting 队列初始 [long_1500, short_200, short_300](按到达顺序),其他参数与第 5 节相同。
Step 1
第一次迭代:seq = long_1500、remaining = 1024、num_tokens = 1500、scheduled_seqs = [] → 队首例外、切片、num_scheduled_tokens = 1024、num_batched_tokens = 1024、整段完成检查不成立 → long_1500 留 waiting 队首。
第二次迭代:remaining = 1024 - 1024 = 0 → if remaining == 0: break → 退出。
short_200 和 short_300 在本 step 完全未进入调度迭代,因为 long_1500 占满预算。step 1 末态:long_1500 已通过 allocate 完成 6 块 KV cache 的分配,short_200 / short_300 在整个 step 中未进入调度,block_table 仍是空列表,等到 step 2 才被处理。返回 ([long_1500], True)。
Step 2
第一次迭代:seq = long_1500(仍在队首)、remaining = 1024、走 else 分支、num_tokens = 476、scheduled_seqs = [] → and 不成立(右边空)、剩余预算足够、num_scheduled_tokens = 476、num_batched_tokens = 476、整段完成检查成立 → long_1500 转入 running。
第二次迭代:seq = short_200(原来的第二个,前一个已弹出)、remaining = 1024 - 476 = 548、走 if 分支(新请求)、num_tokens = 200、scheduled_seqs = [long_1500](非空)→ 检查关键一行:548 < 200 = False → and 不成立 → 不 break。short_200 的整段 200 token < 剩余预算 548 → 整段调度、num_scheduled_tokens = min(200, 548) = 200、num_batched_tokens = 676、整段完成检查成立 → short_200 转入 running。
第三次迭代:seq = short_300、remaining = 1024 - 676 = 348、走 if 分支、num_tokens = 300、检查关键一行:348 < 300 = False → 不 break、num_scheduled_tokens = 300、num_batched_tokens = 976、整段完成检查成立 → short_300 转入 running。
第四次迭代:waiting 空 → 退出。返回 ([long_1500, short_200, short_300], True)。
整体回看
| step | 调度结果 | long_1500 状态 | 注 |
|---|---|---|---|
| 1 | [long_1500] 切 1024 |
留 waiting | 预算被长队首独占 |
| 2 | [long_1500, short_200, short_300] |
全部转入 running | 长队首整段完成、剩余预算供其他 seq 整段调度 |
观察两点:
第一,短 seq 在 step 1 完全未被调度 ------即使它们的 num_tokens 都远小于 step 1 剩余的"假想预算"(1024 - 1024 = 0,实际剩 0),也只能在长队首整段完成后才会被调度。这是"队首独享"的代价:长队首整段未完成前,后续 seq 一律延后到下一 step。
第二,step 2 反而调度了 3 条 seq------长队首在 step 2 仅消耗 476 个 token,剩余 548 个预算可容纳后两条短 seq 的整段调度。从单 step 角度看,step 2 比 step 1 调度数量增加 2 条 seq,但整体首 token 延迟仍受长队首制约。
若短 seq 排在长队首之前(waiting = [short_200, short_300, long_1500]),情形完全不同:step 1 会先调度 short_200(200 token)、short_300(300 token),num_batched_tokens = 500,然后 long_1500 作为第三个候选------remaining = 524、num_tokens = 1500、scheduled_seqs = [short_200, short_300](非空)→ 关键一行触发 break(524 < 1500 = True 且 and 右边非空),long_1500 留 waiting。也就是说,顺序决定调度结果 :长 prompt 排第一则独占 step 1 的预算;短 prompt 排第一则使 long_1500 延后到下一 step。顺序之所以决定结果,根本原因是分片机会仅在循环第一次迭代成立------此时 scheduled_seqs 必然为空,and 右边的条件不成立,左条件即使为真也不 break------后续迭代一律走 break 留下一 step;谁排队首,谁就获得本 step 的切片机会。

图横向是 step 时间线,纵向 3 条 seq 各占一行。Step 1 只有 long_1500 的黄色块(占满 1024 预算),short_200 和 short_300 行空白(未调度)。Step 2 三条 seq 都有黄色块,块的长度反映各自的 num_scheduled_tokens(long_1500 整段完成 476、short_200 整段 200、short_300 整段 300)。Step 3 起三条都进入 decode 稳态(蓝色 d 块)。图中底部黄色注释块标记"队首独享"机制让短 seq 延后一个 step、绿色注释块标记 step 2 的调度数量增加。
7. 思考题
合上教程先自己答,再看下面的提示。
-
把第 5 节设定改成
max_num_batched_tokens = 2000、prompt 长度仍是 1500。chunked prefill 分支还会被触发吗?step 1 与原来相比,r1 在 waiting 还是 running?为什么? -
修改第 6 节设定,把 waiting 改成
[long_1500, long_1200, short_200],max_num_batched_tokens = 1024。step 1、step 2、step 3 各调度了哪些 seq?各 seq 的num_scheduled_tokens是多少?给出推导过程。 -
如果把关键一行改成
if remaining < num_tokens: break(只保留 and 左边的条件、删掉 and 右边的scheduled_seqs),并把 prefill 分支结尾的早返回行if scheduled_seqs: return scheduled_seqs, True也删掉,让控制流自然转入 decode 循环。在 waiting 只有一条 long_1500 prompt 的初始场景下,程序是会正常工作、死锁、还是 assert 崩溃?给出执行轨迹推导。
思考题参考答案
-
不会被触发 。step 1 第一次迭代:
remaining = 2000、num_tokens = 1500、关键一行的左条件2000 < 1500 = False→ 不 break(无论右项)、num_scheduled_tokens = min(1500, 2000) = 1500、num_batched_tokens = 1500、整段完成检查0 + 1500 = 1500 = 1500成立 → r1 直接转入 running。chunked prefill 这条分支只在"单条 prompt 超过单步预算"时才会被触发;预算大于最长 prompt 时,prefill 永远是一次性算完整段,等价于"chunked prefill 被关闭"。换言之,max_num_batched_tokens是一个条件触发开关------大于等于最长 prompt 时该机制失效,小于时才生效。 -
推导(
block_size = 256不影响此题,假设 prefix cache 全空):- Step 1 :迭代 1 处理 long_1500,
remaining = 1024、num_tokens = 1500、队首例外 → 切片 1024 token、留 waiting;迭代 2remaining = 0→ break。调度结果[long_1500],num_scheduled_tokens = {long_1500: 1024}。 - Step 2 :迭代 1 处理 long_1500(仍在队首,else 分支),
remaining = 1024、num_tokens = 476、剩余预算足够 → 整段调度、转入 running;迭代 2 处理 long_1200,remaining = 548、num_tokens = 1200、scheduled_seqs = [long_1500]非空 → 关键一行触发 break(548 < 1200 ∧ 非空),long_1200 留 waiting。调度结果[long_1500],num_scheduled_tokens = {long_1500: 476}。 - Step 3 :迭代 1 处理 long_1200(新请求,if 分支),
remaining = 1024、num_tokens = 1200、scheduled_seqs = []→ 队首例外、切片 1024、留 waiting;迭代 2remaining = 0→ break。调度结果[long_1200],num_scheduled_tokens = {long_1200: 1024}。 - 关键观察:long_1200 必须在 long_1500 整段完成后才能进入调度;short_200 必须在 long_1200 整段完成后才能进入调度。每个 step 最多有一条 seq 被切片,这就是"队首独享"在多条长 prompt 场景下的累积效应------长 prompt 之间的首 token 延迟会被串行化。
- Step 1 :迭代 1 处理 long_1500,
-
assert 崩溃 。执行轨迹:
schedule()进 prefill 循环、seq = long_1500、remaining = 1024 < num_tokens = 1500→ break。退出 while 循环时scheduled_seqs = []。早返回行已被删除,控制流转入 decode 分支的while self.running循环,但 running 也是空(系统刚启动),循环一次都不进入。代码末尾assert scheduled_seqs检查到空列表,触发 AssertionError,程序崩溃。结论:and 右边的scheduled_seqs与早返回行if scheduled_seqs: return是同一套"防止本 step 空转"的设计,删除其中任一行都会使长 prompt 在第一个 step 即触发程序崩溃------这两行不是冗余,而是协同保证 prefill 分支至少调度一条 seq 的最小机制。
本节总结
-
chunked prefill 解决的问题 :单条 prompt 超过
max_num_batched_tokens时,既不能拒绝也不能让它无限期等待,只能把 prompt 切片分多 step 完成 prefill。这一机制把"无法调度"转化为"分多步调度"。 -
关键一行
if remaining < num_tokens and scheduled_seqs: break的合取语义 :把"剩余预算不够"与"本 step 已调过其他 seq"两个条件用 and 连起来,只有同时成立才 break。and 右边的条件不可省------省掉会让单条长 prompt 在 prefill 后让scheduled_seqs空,触发末尾assert崩溃。 -
分片机会只属于队首:and 右边的条件只在循环第一次迭代时为空,所以只有队首能在超预算时继续被切片调度。任何 step 内最多一条 seq 处于"已被切片"的状态------这是反直觉点。
-
下一 step 续做的机制 :被切片的 seq 留在 waiting 队首,
postprocess把num_scheduled_tokens累加到num_cached_tokens上;下一 step 走 else 分支,按seq.num_tokens - seq.num_cached_tokens算剩余量。block_table已在首次入场时分配完整段,续做时不再分配。 -
代价 :首 token 延迟由 1 个 step 变为
⌈num_tokens / max_num_batched_tokens⌉个 step------chunked prefill 以更长的首 token 延迟为代价,换取系统不死锁。
下面这段视频把第 6 节的多请求并存场景跑了一遍------waiting 队列 = [long_1500, short_200, short_300],max_num_batched_tokens = 1024,演示 step 1 → step 2 → step 3+ 的调度全过程。状态面板(scheduled_seqs / num_batched_tokens / num_cached / num_scheduled / block_table)和判定面板(关键一行 and 真值)随每步同步变化: