TL;DR:亚马逊图片 URL 藏在 JS 渲染后的 DOM 里,静态请求拿不到;自建爬虫反爬成本高。最稳方案是调 Pangolinfo Scrape API 直接拿结构化 JSON,或通过 MCP 协议让 Open Claw / Claude 直接驱动采集,不写一行 API 代码。
为什么「亚马逊图片批量下载」是个工程问题?
很多人第一次碰这个需求时,以为只是写个循环请求然后下载图片。现实是:
难点 1 --- 动态渲染:亚马逊商品详情页的图片节点由 React 注入,静态 HTTP 响应里根本没有图片 URL。
难点 2 --- 多层 Bot 检测:TLS 指纹(JA3/JA4)、HTTP/2 帧参数、行为熵(鼠标轨迹、滚动时序)、IP 信誉------亚马逊的检测体系非常完整。裸 IP 自动化脚本的平均稳定周期不超过 48 小时。
难点 3 --- URL 格式碎片化 :同一张图有多种分辨率 URL 格式(._SL1500_.jpg、._AC_SL1000_.jpg),且 CDN 链接带过期签名,采集后需要立即落库。
难点 4 --- 基础设施成本:维护一套可用的亚马逊采集系统,光是代理 IP 池 + 反指纹浏览器 + 调度系统,月均成本 $300--1000,还不算每次亚马逊升级反爬后的维护工时。
架构选型:三条路径
css
路径 A:直接调 Scrape API(有代码能力的团队)
ASIN List → Pangolinfo API → 结构化 JSON(含图片 URL) → 落库/下载
路径 B:MCP Skill + Open Claw(低代码/运营团队)
自然语言指令 → Open Claw Agent → Pangolinfo MCP Skill → 图片数据 → 多维表格
路径 C:MCP Skill + Claude(研究/分析场景)
对话输入 → Claude 调用 MCP Tool → 图片采集 → 结合视觉分析输出报告路径 A:API 直接调用实现
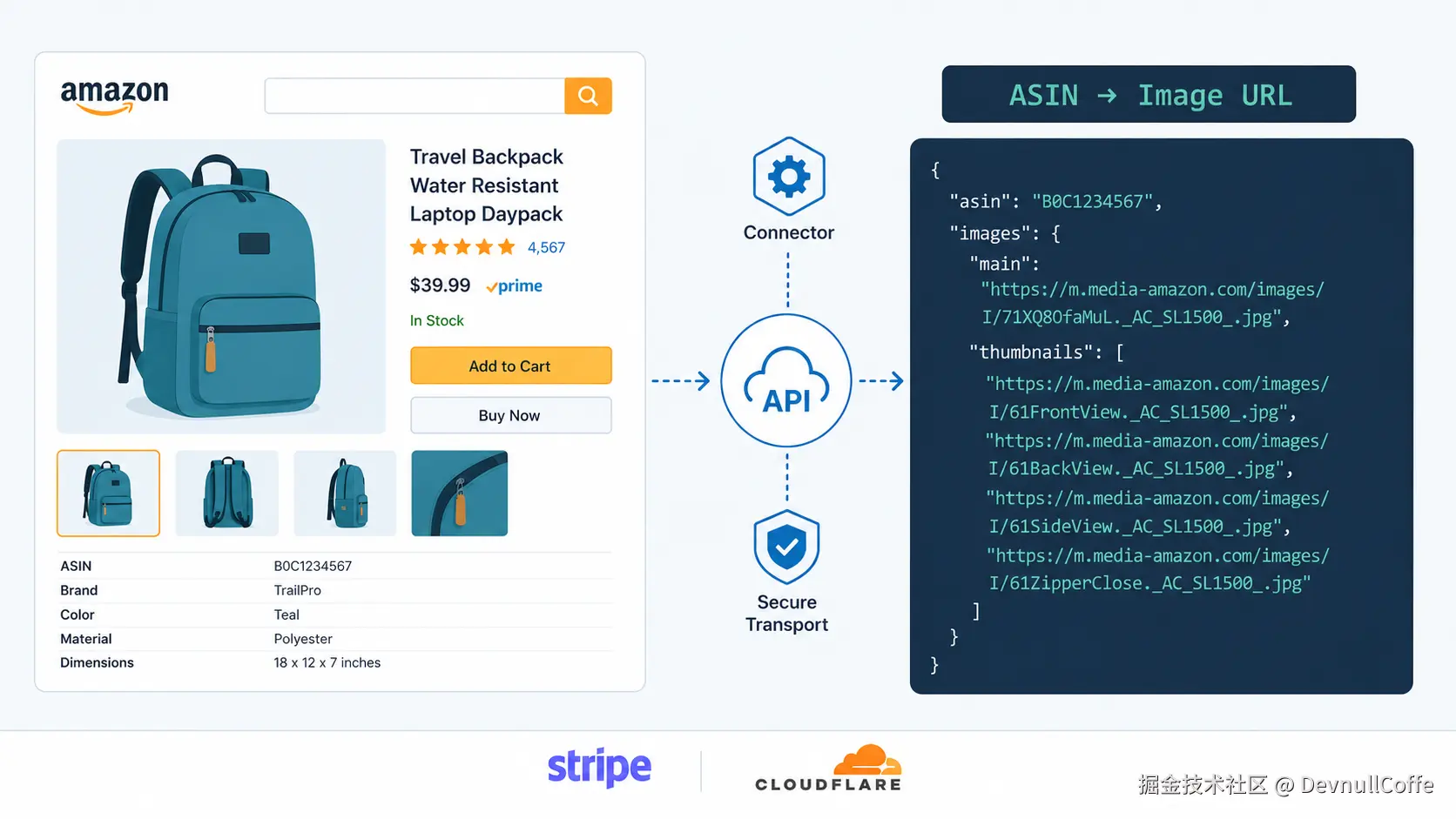
核心接口
调用 Pangolinfo Scrape API的商品详情端点,images 字段包含完整图片数据:
python
import asyncio
import aiohttp
API_KEY = "your_api_key"
async def get_asin_images(session, asin):
async with session.get(
"https://api.pangolinfo.com/v2/amazon/product",
params={"asin": asin, "marketplace": "US"},
headers={"Authorization": f"Bearer {API_KEY}"}
) as resp:
data = await resp.json()
return {
"asin": asin,
"main": data.get("main_image"), # 主图,2000×2000px
"gallery": data.get("images", []), # 副图,最多 9 张
"aplus": data.get("aplus_images", []), # A+ 内容图
"video_thumb": data.get("video_thumbnail")
}
async def bulk(asins):
sem = asyncio.Semaphore(20) # 控制并发
async def bounded(s, asin):
async with sem:
return await get_asin_images(s, asin)
async with aiohttp.ClientSession() as s:
return await asyncio.gather(*[bounded(s, a) for a in asins])
# 1000 个 ASIN 约 3--5 分钟
results = asyncio.run(bulk(["B09XYZ1234", "B08ABC5678"]))高分辨率 URL 规范化
拿到 URL 后,统一转换为最高分辨率版本:
python
import re
def normalize_to_hires(url: str) -> str:
"""将亚马逊图片 URL 规范化为 2000px 高清版本"""
# 移除已有的尺寸参数
url = re.sub(r'\._[^.]+_\.', '.', url)
# 插入高清参数
return url.replace('.jpg', '._SL2000_.jpg')
# 示例
raw = "https://images-amazon.com/images/I/71abc123XY._AC_SL1000_.jpg"
print(normalize_to_hires(raw))
# → https://images-amazon.com/images/I/71abc123XY._SL2000_.jpg路径 B:MCP Skill 接入 Open Claw
MCP(Model Context Protocol)是 Anthropic 推出的开放协议,定义了 AI 模型调用外部工具的标准化接口。Pangolinfo Amazon Scraper Skill 实现了这套协议,作为 MCP 工具服务器运行。
Open Claw 接入流程(5 分钟完成):
- 工具市场 → 搜索「Pangolinfo Amazon Scraper」→ 安装
- 填入 API Key
- 创建工作流,添加「获取商品图片」节点
- 输入节点:ASIN 列表(手动输入或从表格读取)
- 输出节点:写入多维表格或下载 CSV
触发示例:
获取以下 ASIN 的商品图片 URL,并整理成表格:
B09XYZ1234, B08ABC5678, B07DEF9012Agent 自动调用 MCP Tool,无需写任何代码。
路径 C:Claude Desktop + MCP 本地服务器
适合需要将图片采集嵌入 AI 分析链路的场景(如:采集图片 → 视觉分析 → 输出竞品报告)。
配置方式:
json
// claude_desktop_config.json
{
"mcpServers": {
"pangolinfo": {
"command": "npx",
"args": ["@pangolinfo/amazon-scraper-mcp", "--port", "3100"],
"env": {"PANGOLINFO_API_KEY": "your_key"}
}
}
}配置后,Claude 可在对话中直接调用 get_product_images 工具。实际工作流示例:
css
你:帮我分析家居类目 Top 20 商品的主图风格趋势
Claude:[调用 get_product_images(asins=[...])]
→ 获取 20 个 ASIN 的主图 URL
→ [调用视觉分析工具]
→ 输出:白底图占 65%,场景图占 30%,信息图占 5%;
近 3 个月新品主图中场景图占比提升 12pp,建议...最佳实践
图片 URL 持久化:采集完立即异步下载到对象存储(S3/OSS),不依赖亚马逊 CDN 链接长期有效。
增量更新策略:只重新采集上次采集时间超过 7 天、或有版本更新信号的 ASIN,减少不必要的 API 消耗。
错误分类处理:
429→ 降低并发,指数退避重试404→ ASIN 已下架,标记跳过5xx→ 临时错误,3 次重试后告警
A+ 图缺失处理 :部分 ASIN 无 A+ 内容,采集前用 has_aplus 字段过滤,避免无效请求。
总结
亚马逊商品图片批量下载在技术上的核心挑战是:动态渲染 + 多层反爬 + URL 碎片化。自建方案的隐性成本往往是预估的 3--5 倍。选择成熟的 API 方案,配合 MCP 协议接入 AI Agent 工作流,是目前工程性价比最高的路径------而且对运营团队友好,不需要每个人都懂爬虫。
有问题欢迎在评论区交流,或查看 Pangolinfo API文档获取完整接口说明。