摘要
随着大语言模型(LLM)技术的快速发展,以AutoGPT、BabyAGI为代表的Agent智能体成为AI领域最受关注的技术方向之一。Agent智能体通过将大模型的推理能力与工具调用能力相结合,使AI系统能够自主规划、执行复杂多步骤任务,真正实现了从"被动回答"到"主动执行"的跨越。本文将深入剖析Agent智能体的核心架构,详细讲解自主任务编排的实现原理,并结合Java生态系统提供完整的实战指导。
一、Agent智能体概述
1.1 什么是Agent智能体
Agent智能体(Agent)是一种能够感知环境、进行自主规划、执行具体行动并从经验中学习的人工智能系统。与传统的AI模型只能被动响应用户输入不同,Agent具有以下核心特征:
自主性(Autonomy) :Agent能够独立进行决策,无需人类持续干预即可完成复杂任务。它能够根据目标自主规划执行路径,在执行过程中根据反馈动态调整策略。
反应性(Reactivity) :Agent能够感知环境变化并做出相应反应。这种反应不仅限于简单的刺激-响应模式,而是基于对上下文的深度理解做出的智能反馈。
主动性(Proactivity) :Agent不仅被动响应现有需求,还能主动预测未来可能发生的情况并提前做好准备。这种能力使其能够处理开放性的复杂问题。
从技术架构角度看,一个典型的Agent系统由四大核心组件构成:感知模块(Perception) 负责接收和处理来自外部环境的信息;规划模块(Planning) 负责任务分解和策略制定;执行模块(Action) 负责调用工具和API完成具体操作;记忆模块(Memory) 负责存储和检索知识、经验和中间结果。这四个模块相互协作形成闭环,使Agent具备持续学习和自我改进的能力。
1.2 Agent与传统AI助手的区别
传统的AI助手,如基于GPT-3.5/4的对话系统,本质上是一个强大的语言模型。它能够理解用户的问题并生成流畅的回答,但在处理需要多步骤操作的任务时存在明显局限性。用户需要精确地告诉AI助手每一步该做什么,AI本身无法自动规划执行路径。
举例来说,如果用户希望AI助手帮忙预订下周去上海的机票并安排行程,传统的AI助手只能生成一段行程建议文字,而无法实际执行机票查询、日程添加到日历、酒店预订等操作。用户仍需要手动完成这些任务。
而Agent智能体则不同,它可以将"预订机票"这个高层目标分解为多个子任务:查询航班信息、比较价格、选择最优选项、调用航空公司API完成预订、将行程添加到日历等。Agent能够自主完成整个流程,真正成为用户的"数字助理"。
这种差异的根本原因在于架构设计的不同。传统AI助手是"端到端"的单一模型架构,所有能力都压缩在一个模型中。而Agent则采用了"模块化"的架构设计,将不同的能力分配给不同的组件,LLM主要负责推理和规划,具体执行则交由专业的工具和API完成。
1.3 Agent技术的发展历程
Agent技术的发展经历了几个重要阶段。早期的人工智能代理主要基于强化学习算法,如DeepMind的AlphaGo通过强化学习在围棋领域取得了突破性进展。这一阶段的Agent能够完成特定领域的复杂任务,但缺乏通用性和灵活性。
2022年,随着大型语言模型的兴起,Prompt Engineering(提示工程)成为主流。研究者们发现,通过精心设计的提示词,可以激发LLM的潜在能力,使其表现得像个"初级Agent"。这一时期的代表性工作是WebGPT和PilotELIC,它们通过提示词引导LLM使用工具和浏览器。
2023年是Agent技术爆发的一年。AutoGPT的发布引发了广泛关注,它首次展示了如何让GPT-4自主完成复杂的多步骤任务。随后,OpenAI发布了ChatGPT Plugins和Code Interpreter,进一步完善了Agent的工具调用能力。BabyAGI、AgentGPT等开源项目也如雨后春笋般涌现。
当前,Agent技术正朝着多模态、自主协作、长时记忆等方向发展。多模态Agent能够处理图像、音频、视频等多种类型的信息;多Agent协作系统则通过多个Agent的分工合作解决更复杂的问题。
二、Agent核心架构详解
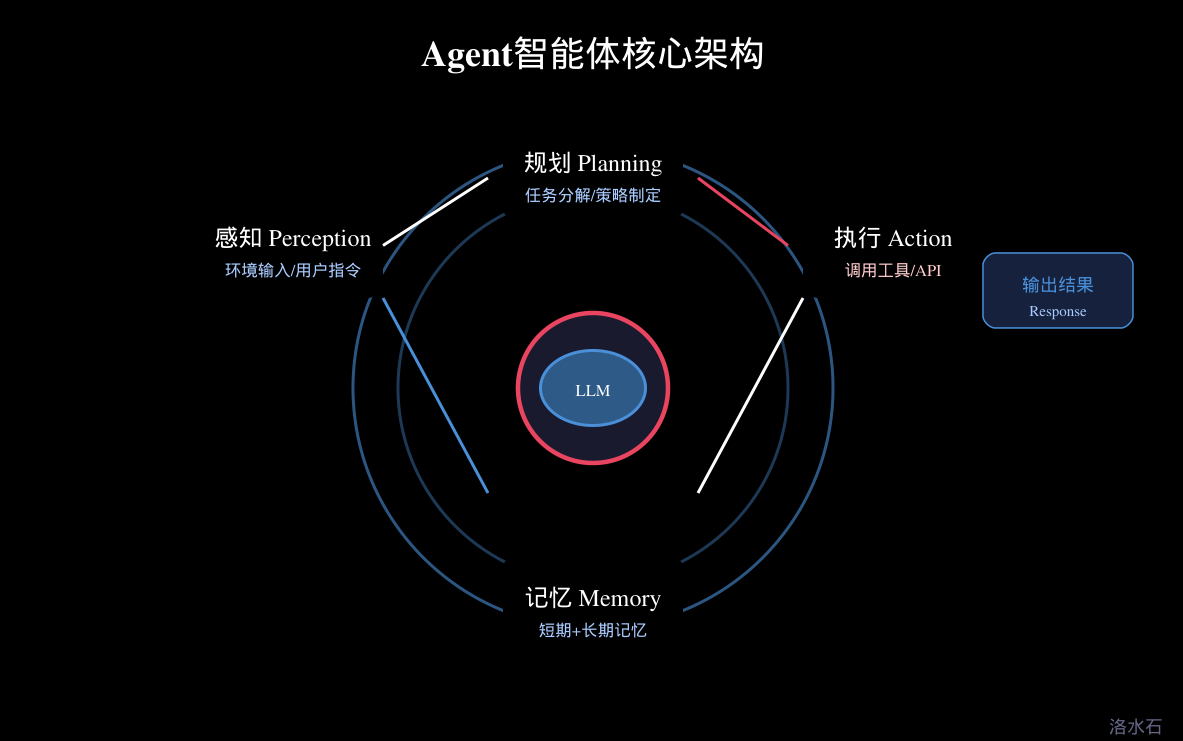
2.1 四大核心组件
Agent智能体的架构设计是其能力的基础。一个设计良好的Agent架构需要平衡多个关键要素:感知能力决定Agent能获取多少环境信息;规划能力决定Agent能否有效分解和执行复杂任务;执行能力决定Agent能否准确调用各种工具;记忆能力则决定Agent能否积累经验并持续改进。
感知模块(Perception) 是Agent与外部环境交互的窗口。在Java实现中,感知模块通常通过事件监听机制实现。当用户发送消息、API返回结果、或者定时器触发时,感知模块捕获这些事件并进行预处理。预处理可能包括文本清洗、格式转换、关键信息提取等操作。例如,当用户发送一条自然语言指令时,感知模块需要识别意图、提取实体、评估紧急程度等信息。
感知模块的设计需要考虑多种输入源。除了用户的直接输入,还可能包括:文件系统变化、网络请求响应、数据库查询结果、第三方服务回调等。一个完善的感知模块应该能够统一处理这些异构输入,将它们转换为Agent内部可处理的标准化格式。
规划模块(Planning) 是Agent的"大脑",负责将复杂任务分解为可执行的子任务序列。在Java后端实现中,规划模块通常基于LLM的推理能力实现。常用的技术包括Chain-of-Thought(思维链)、Tree of Thoughts(思维树)等。
Chain-of-Thought是一种让LLM显式展示推理过程的技术。在使用CoT时,我们不是直接让LLM给出答案,而是要求它分步骤思考:先分析问题的哪个方面,再考虑使用什么策略,最后得出什么结论。这种方法已被证明能够显著提升LLM在复杂推理任务上的表现。
对于更复杂的任务,Tree of Thoughts提供了更强大的规划能力。它允许LLM同时探索多条可能的推理路径,评估每条路径的可行性,最终选择最优策略。这种方法特别适合于需要深度搜索或战略规划的场景。
执行模块(Action) 负责将规划模块生成的行动计划转化为具体操作。在Java实现中,执行模块通常采用策略模式和命令模式设计。不同的工具有不同的执行策略,但都遵循统一的接口规范。
Tool接口是执行模块的核心抽象。一个标准的Tool接口应该定义工具名称、执行方法、参数模式、返回格式等属性。Java开发者可以利用反射机制和动态代理来实现更灵活的Tool注册和调用。
执行模块还需要处理执行失败的情况。当某个工具调用失败时,执行模块应该能够:记录错误信息、尝试替代方案、向规划模块反馈以便重新规划、或者请求人工介入。一个健壮的执行模块应该能够优雅地处理各种异常情况。
记忆模块(Memory) 使Agent能够存储和检索过去的经验。Agent的记忆系统通常分为三个层次:感官记忆、短期记忆和长期记忆。
感官记忆保存Agent在最近一次交互中感知到的原始信息,如完整的用户输入、API返回的原始数据等。这些信息容量大但衰退快,通常在对话结束后就被清除。
短期记忆保存当前任务执行过程中的中间结果和状态信息。例如,当Agent在执行一个复杂任务时,会产生多个中间步骤的结果,这些结果需要暂时保存以便后续步骤使用。Java中可以使用ConcurrentHashMap或专门的内存数据库实现短期记忆。
长期记忆存储Agent的"经验",包括成功案例、失败教训、最佳实践等。这些信息会被持久化存储,以便Agent在未来的类似任务中复用。在Java生态中,可以使用Redis、MongoDB或专门的向量数据库存储长期记忆。
2.2 感知-规划-执行-记忆循环
Agent的工作模式可以用一个循环来描述:感知当前状态→规划下一步行动→执行行动→更新记忆→继续感知。这个循环持续运行,直到任务完成或达到终止条件。
在Java实现中,这个循环通常采用事件驱动或消息传递架构。感知模块捕获事件后,生成内部消息并发送到规划模块;规划模块处理消息并生成行动计划,将计划发送给执行模块;执行模块执行计划并生成结果消息,更新记忆后再次触发感知。这样形成了一个持续运行的反馈循环。
理解这个循环对于设计可靠的Agent系统至关重要。循环中的每个环节都可能成为瓶颈或故障点。感知模块可能遗漏重要信息,规划模块可能生成错误的计划,执行模块可能调用失败,记忆模块可能存储了过时的信息。因此,在设计时需要为每个环节添加适当的容错和恢复机制。
2.3 Java生态系统中的Agent框架
在Java生态系统中,有多个框架可以用于构建Agent应用。Spring AI是Spring生态系统针对AI应用推出的框架,提供了与各种LLM提供商(OpenAI、Azure OpenAI、HuggingFace等)集成的标准化接口。Spring AI的Agent模块基于Function Calling API实现,提供了简洁的Tool定义和调用机制。
LangChain4j是另一个流行的Java AI框架,它提供了与LangChain类似的能力,包括Prompt模板管理、Chain组合、Tool定义等。LangChain4j的设计理念是为Java开发者提供与Python版LangChain同等的能力,同时保持Java的类型安全和IDE友好特性。
对于需要在终端环境中运行的Agent应用,Lanterna是一个值得推荐的选择。Lanterna是一个Java库,专门用于创建基于文本的终端用户界面(类似Unix ncurses)。使用Lanterna,开发者可以轻松实现交互式的命令行Agent应用。
Apache Camel也可以用于构建复杂的Agent工作流。Camel的Enterprise Integration Patterns和丰富的组件库使其特别适合于需要集成多个外部系统的复杂Agent应用。
选择哪个框架取决于具体需求。如果追求快速开发和生产就绪,Spring AI是首选;如果需要深度定制和灵活性,LangChain4j提供更多底层控制;对于终端应用,Lanterna更为轻量。
三、ReAct模式:推理与执行协同
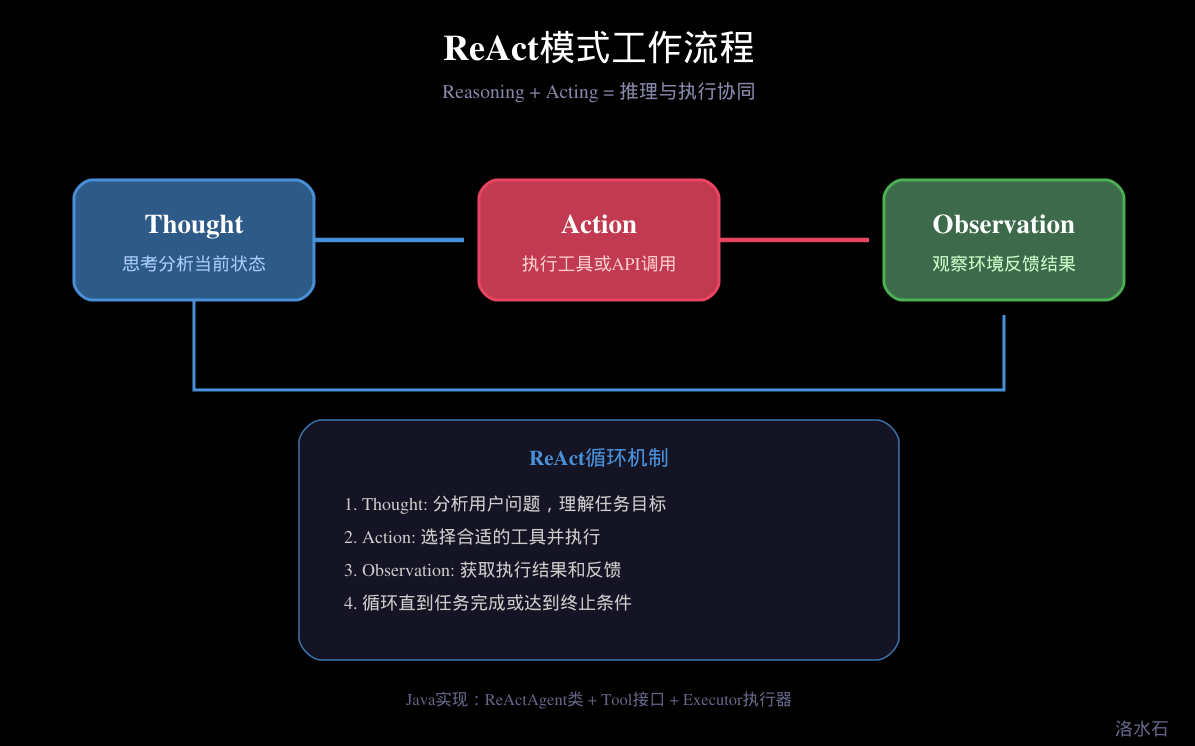
3.1 ReAct模式原理
ReAct(Reasoning and Acting)是一种让Agent在执行任务时同时进行推理的方法论,由Google Research在2022年提出。ReAct的核心思想是将推理过程外显化,使Agent能够在执行过程中不断"思考"当前状态,从而做出更好的决策。
传统的LLM应用通常采用"Thought→Action"的简单模式:给LLM一个Prompt,LLM生成一个Action,然后执行。这种模式的缺点是LLM缺乏对执行结果的感知能力,无法根据反馈调整策略。
ReAct模式引入了"Observation"环节,形成了"Thought→Action→Observation→Thought..."的循环。在这个循环中:
Thought(思考) 是LLM分析当前状态的过程。LLM需要思考:我当前的任务是什么?我已经完成了什么?接下来我应该做什么?有什么需要注意的?
Action(行动) 是LLM决定执行的具体操作。这个操作可以是调用工具、查询知识库、或者生成文本响应。
Observation(观察) 是收集Action执行结果的过程。Agent需要客观地记录执行结果,不管结果是好是坏。
通过这个循环,Agent能够在执行过程中不断学习和调整。如果某个Action没有产生预期效果,Agent会在下一个Thought中分析原因并尝试不同策略。
3.2 ReAct的Java实现
在Java中实现ReAct模式,需要设计一个能够维护循环状态的管理器。以下是核心的ReActAgent类设计:
``__INLINE_java
public class ReActAgent {
private final LLM llm;
private final List<Tool> tools;
private final Memory memory;
public ReActAgent(LLM llm, List<Tool> tools, Memory memory) {
this.llm = llm;
this.tools = tools;
this.memory = memory;
}
public String run(String userInput) {
String context = memory.getRecentContext();
String prompt = buildReActPrompt(userInput, context);
int maxIterations = 10;
for (int i = 0; i < maxIterations; i++) {
ReActStep step = llm.generateReActStep(prompt);
if (step.isFinalAnswer()) {
memory.saveInteraction(userInput, step.getAnswer());
return step.getAnswer();
}
ToolResult result = executeTool(step.getToolName(), step.getToolInput());
memory.addObservation(step.getThought(), step.getAction(),
result.getOutput());
prompt = updatePromptWithObservation(prompt, step, result);
}
return "任务执行达到最大迭代次数";
}
private ToolResult executeTool(String toolName, String toolInput) {
Tool tool = findTool(toolName);
if (tool == null) {
return ToolResult.failure("未知工具: " + toolName);
}
try {
String output = tool.execute(toolInput);
return ToolResult.success(output);
} catch (Exception e) {
return ToolResult.failure(e.getMessage());
}
}
}
__`_INLINE
ReActAgent的核心是一个循环执行器。在每次迭代中,Agent首先根据当前上下文生成ReAct步骤;如果步骤标记为最终答案,则返回结果;否则执行相应的工具调用,并将执行结果添加到记忆中以便下一次迭代使用。
ReActPrompt是实现良好推理效果的关键。一个有效的ReAct Prompt通常包含以下几个部分:
角色定义 :明确Agent的身份和能力边界。例如:"你是一个专业的AI助手,能够使用各种工具来帮助用户解决问题。"
任务描述 :清晰说明当前要完成的任务。
工具描述 :列出所有可用工具的名称、功能和参数规范。
输出格式 :指定Thought、Action、Observation的格式要求。
示例 :提供1-2个完整的Thought-Action-Observation循环示例,帮助LLM理解期望的输出格式。
3.3 ReAct的优缺点分析
ReAct模式具有多项显著优势。首先,通过将推理过程外显化,ReAct大大增强了Agent的可解释性。用户可以看到Agent为什么做出某个决定,这对于构建可信的AI系统至关重要。其次,ReAct的循环反馈机制使Agent能够从错误中恢复。当某个Action失败时,Agent可以在下一个Thought中分析原因并尝试替代方案。此外,ReAct的结构化输出便于集成日志记录和监控功能,为系统优化提供了数据支持。
ReAct的主要缺点是循环执行带来的延迟。每次迭代都需要调用LLM生成Thought,对于复杂任务可能需要多次迭代才能完成。另外,如果LLM的推理能力不足,可能产生错误的Thought,导致整个执行路径偏离。还有就是需要精心设计Prompt,不同的LLM可能需要不同的Prompt优化。
四、自主任务编排原理
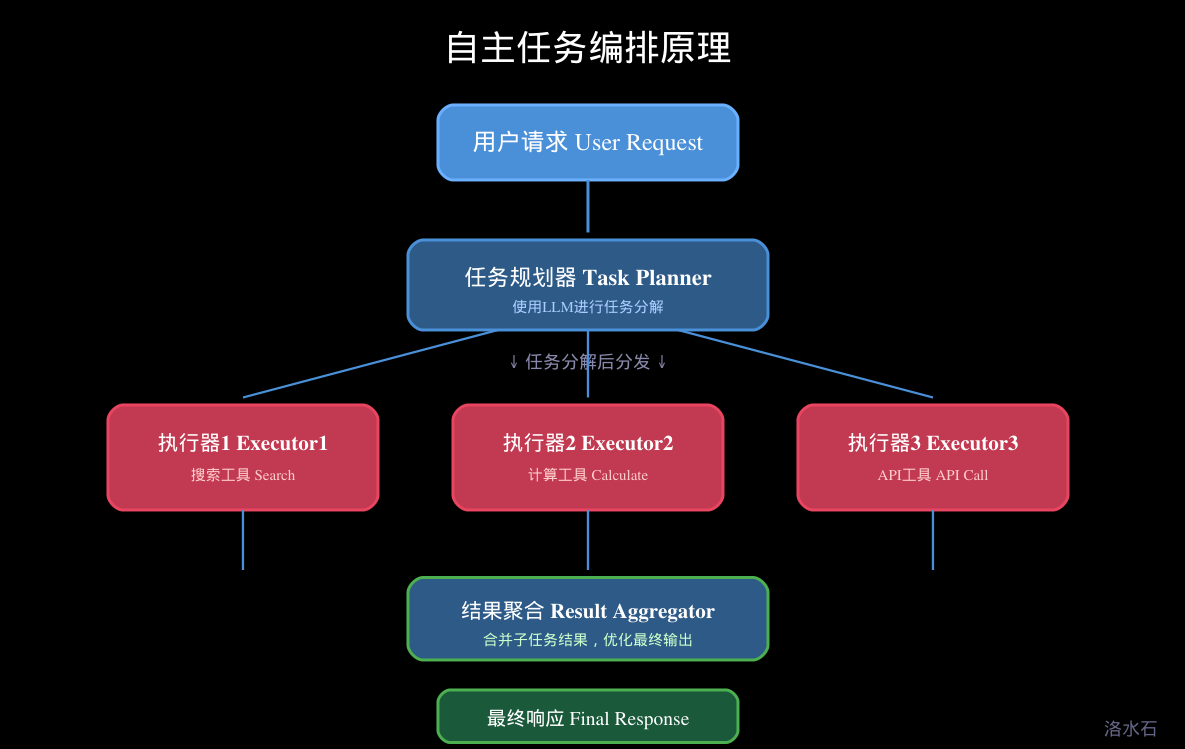
4.1 任务分解策略
自主任务编排是Agent系统中最具挑战性的部分之一。当用户给出一个模糊或复杂的目标时,Agent需要能够自主地将其分解为可执行的子任务。这个过程涉及多个层面的策略选择。
层次分解法 是最基本的任务分解策略。它将高层任务递归地分解为越来越具体的子任务,直到每个子任务都是可以直接执行的基本操作。这种方法类似于软件工程中的自顶向下设计。例如,"准备一场技术分享会"这个任务可以分解为:确定分享主题、邀请分享嘉宾、准备场地、发布通知、现场设备调试等子任务。每个子任务又可以继续分解。
基于工具的任务分解 根据可用工具的能力来组织任务分解过程。这种方法首先盘点所有可用工具,然后思考每个工具能解决什么问题,最后根据问题选择合适的工具组合。相比层次分解,这种方法更务实,特别适合工具集相对固定的场景。
LLM驱动的任务分解 利用大模型的推理能力自动进行任务分解。Agent可以分析用户目标,识别需要的技能和资源,生成任务列表,并确定执行顺序。这种方法灵活性最高,但也最不可预测。
在Java实现中,可以采用以下代码框架:
__`__INLINE_java
public class TaskPlanner {
private final LLM llm;
private final List<String> availableSkills;
public List<SubTask> decompose(String goal) {
String prompt = String.format("""
将以下目标分解为具体的子任务列表:
目标:%s
可用技能:%s
请以JSON格式返回子任务列表,每个子任务包含:
-
id: 任务ID
-
description: 任务描述
-
dependsOn: 依赖的其他任务ID列表
-
requiredSkills: 需要的技能列表
""", goal, String.join(", ", availableSkills));
String response = llm.generate(prompt);
return parseSubTasks(response);
}
public List<SubTask> reorder(List<SubTask> tasks) {
// 根据依赖关系进行拓扑排序
return topologicalSort(tasks);
}
}
__`_INLINE
4.2 子任务执行与协调
任务分解完成后,下一步是执行各个子任务。简单的顺序执行往往效率低下,理想的做法是根据子任务之间的依赖关系实现并行执行。
子任务之间通常存在几种依赖关系:顺序依赖 指任务B必须在任务A完成后才能开始,如写文件前需要先创建目录;数据依赖 指任务B需要使用任务A的输出作为输入;资源依赖 指多个任务需要共享同一资源,需要互斥访问。
并行执行的关键是识别可以同时运行的任务。在任务分解阶段,应该明确标注每个任务的依赖关系。然后通过拓扑排序确定执行顺序,同时识别出可以并行执行的任务组。
Java中的并行执行可以利用ExecutorService实现:
__`__INLINE_java
public class TaskExecutor {
private final ExecutorService executor;
private final Map<String, SubTaskResult> results;
public TaskExecutor(int parallelism) {
this.executor = Executors.newFixedThreadPool(parallelism);
this.results = new ConcurrentHashMap<>();
}
public Map<String, SubTaskResult> execute(List<SubTask> tasks) {
// 构建依赖图
DependencyGraph graph = buildGraph(tasks);
// 执行无依赖的任务
List<SubTask> readyTasks = graph.getNoDependencyTasks();
List<CompletableFuture<SubTaskResult>> futures = new ArrayList<>();
for (SubTask task : readyTasks) {
CompletableFuture<SubTaskResult> future = CompletableFuture.supplyAsync(
() -> executeSingle(task), executor);
futures.add(future);
}
// 等待所有任务完成
CompletableFuture.allOf(futures.toArray(new CompletableFuture0)).join();
return results;
}
private SubTaskResult executeSingle(SubTask task) {
ToolResult toolResult = toolExecutor.execute(task);
SubTaskResult result = new SubTaskResult(task.getId(), toolResult);
results.put(task.getId(), result);
return result;
}
}
__`_INLINE
4.3 结果聚合与优化
多个子任务执行完成后,需要将结果聚合为最终输出。结果聚合不是简单的拼接,而是需要理解各部分之间的关系,进行语义整合和优化。
结果聚合面临几个挑战。首先是格式不统一问题:不同子任务可能返回不同格式的结果,需要统一化处理。其次是冲突解决:不同子任务的结果可能存在矛盾,需要智能裁决。还有信息冗余:多个子任务可能返回重复信息,需要去重。
一个简单的聚合策略是让LLM参与结果整合:
__`__INLINE_java
public class ResultAggregator {
public String aggregate(List<SubTaskResult> results) {
String combinedInput = buildCombinedInput(results);
String prompt = String.format("""
作为一个专业的AI助手,请整合以下子任务的结果:
%s
要求:
-
去除重复信息
-
解决可能的冲突,保留最可靠的信息
-
按照逻辑顺序组织内容
-
提供简洁明了的最终输出
""", combinedInput);
return llm.generate(prompt);
}
}
__`_INLINE
对于更复杂的多模态结果(如同时包含文本、表格、图片),聚合策略需要更加精细,可能需要使用专门的文档理解模型。
4.4 容错与恢复机制
在自主任务执行过程中,错误是不可避免的。可能发生的问题包括:网络请求超时、API调用失败、工具执行异常、LLM生成无效输出等。一个健壮的Agent系统需要具备完善的容错和恢复机制。
重试机制 是最基本的容错手段。对于临时性故障(如网络抖动、服务暂时不可用),重试往往能够成功。重试策略需要考虑:最大重试次数、重试间隔(指数退避)、是否针对特定错误类型重试等。
备选方案 是当某个工具或方法失败时,自动切换到替代方案。例如,当主要的搜索引擎不可用时,自动切换到备用的搜索引擎;当某个API超时时,尝试调用功能类似的替代API。
降级策略 在无法完成原定任务时,提供一个简化但可用的结果。例如,当无法获取实时数据时,返回历史数据和说明;当无法完成复杂分析时,提供简化版的分析结果。
人工介入 在自动化手段无法解决问题时的最后保障。当Agent连续多次执行失败,或者遇到无法理解的输入时,应该主动请求人工帮助,而不是盲目地继续尝试。
五、Java实现实战

5.1 项目环境准备
开始实现之前,需要准备好Java开发环境。以下是推荐的技术栈:
JDK版本 :建议使用JDK 17或更高版本,以支持最新的语言特性(如模式匹配、Records等)。
构建工具 :Maven或Gradle均可。推荐使用Maven,因为其pom.xml配置更直观。
核心依赖 :
-
Spring AI OpenAI Starter(如果使用OpenAI的模型)
-
LangChain4j(Java版LangChain)
-
Lanterna(终端UI)
-
Apache Commons Exec(执行外部命令)
-
Jackson(JSON处理)
创建一个Maven项目,pom.xml关键配置如下:
__`__INLINE_xml
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.35.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-openai</artifactId>
<version>0.35.0</version>
</dependency>
<dependency>
<groupId>com.googlecode.lanterna</groupId>
<artifactId>lanterna</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
</dependencies>
__`_INLINE
5.2 Tool接口设计
Tool接口是Agent执行能力的核心抽象。一个设计良好的Tool接口应该:
__`__INLINE_java
public interface Tool {
// 工具名称,用于Agent识别调用哪个工具
String getName();
// 工具描述,帮助LLM理解工具的用途和使用方法
String getDescription();
// 参数模式,使用JSON Schema格式定义
String getParameterSchema();
// 执行工具,input是经过解析的参数
ToolResult execute(String input);
// 执行结果封装
record ToolResult(boolean success, String output, String error) {
public static ToolResult success(String output) {
return new ToolResult(true, output, null);
}
public static ToolResult failure(String error) {
return new ToolResult(false, null, error);
}
}
}
__`_INLINE
接下来实现几个常用的Tool:
__`__INLINE_java
public class WebSearchTool implements Tool {
private final SearchApi searchApi;
public WebSearchTool(SearchApi searchApi) {
this.searchApi = searchApi;
}
@Override
public String getName() {
return "web_search";
}
@Override
public String getDescription() {
return "Search the web for information. " +
"Input: a search query string. " +
"Output: search results with titles and snippets.";
}
@Override
public String getParameterSchema() {
return """
{
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索查询词"}
},
"required": "query"
}""";
}
@Override
public ToolResult execute(String input) {
try {
String query = extractQuery(input);
SearchResult result = searchApi.search(query);
return ToolResult.success(formatResults(result));
} catch (Exception e) {
return ToolResult.failure("搜索失败: " + e.getMessage());
}
}
private String extractQuery(String input) {
// 解析输入,提取查询词
return input.replace("\"", "").trim();
}
}
__`_INLINE
5.3 基于Lanterna的终端Agent实现
Lanterna是一个纯Java的终端UI库,可以在命令行环境中创建类似GUI的界面。使用Lanterna可以实现一个交互式的Agent终端:
__`__INLINE_java
public class AgentTerminal {
private final Terminal terminal;
private final TerminalSize size;
private final ReActAgent agent;
private final Screen screen;
public AgentTerminal(ReActAgent agent) throws IOException {
this.agent = agent;
this.screen = new TerminalScreen(
TerminalBuilder.builder()
.setInitialTerminalSize(new TerminalSize(100, 40))
.build()
);
this.terminal = screen.getTerminal();
this.size = screen.getTerminalSize();
}
public void run() throws IOException {
screen.startScreen();
try {
printWelcome();
mainLoop();
} finally {
screen.stopScreen();
}
}
private void printWelcome() {
printLine("=".repeat(80), Color.CYAN);
printLine(" Java Agent Terminal - 基于大模型的智能助手", Color.GREEN);
printLine("=".repeat(80), Color.CYAN);
printLine("");
printLine("可用命令:", Color.YELLOW);
printLine(" /search <query> - 使用网络搜索");
printLine(" /calculate <expr> - 数学计算");
printLine(" /remember <text> - 存储信息到记忆");
printLine(" /recall - 查询记忆");
printLine(" /exit - 退出程序");
printLine("");
printLine("也可以直接输入自然语言问题,我会尽力回答。", Color.WHITE);
printLine("-".repeat(80), Color.CYAN);
}
private void mainLoop() throws IOException {
while (true) {
print("> ", Color.GREEN);
String input = readLine();
if (input == null || input.equals("/exit")) {
break;
}
if (input.trim().isEmpty()) {
continue;
}
processCommand(input.trim());
}
}
private void processCommand(String input) {
if (input.startsWith("/")) {
handleSlashCommand(input);
} else {
handleNaturalLanguage(input);
}
}
private void handleNaturalLanguage(String input) {
printLine("思考中...", Color.YELLOW);
try {
String response = agent.run(input);
printLine(response, Color.WHITE);
} catch (Exception e) {
printLine("执行出错: " + e.getMessage(), Color.RED);
}
printLine("");
}
private void printLine(String text, Color color) {
// 实际实现在终端上打印一行
}
private void print(String text, Color color) {
// 实际实现打印不换行
}
private String readLine() {
// 实现从终端读取一行输入
}
}
__`_INLINE
5.4 Spring Boot集成
在Spring Boot应用中集成Agent能力,可以提供HTTP API或Web界面。以下是一个简单的REST控制器实现:
__`__INLINE_java
@RestController
@RequestMapping("/api/agent")
public class AgentController {
private final ReActAgent agent;
private final ConversationHistory history;
public AgentController(ReActAgent agent, ConversationHistory history) {
this.agent = agent;
this.history = history;
}
@PostMapping("/chat")
public ResponseEntity<AgentResponse> chat(@RequestBody ChatRequest request) {
try {
String userInput = request.getMessage();
// 保存用户消息
history.addUserMessage(userInput);
// 执行Agent
String response = agent.run(userInput);
// 保存Agent回复
history.addAssistantMessage(response);
return ResponseEntity.ok(AgentResponse.success(response));
} catch (Exception e) {
return ResponseEntity.internalServerError()
.body(AgentResponse.error(e.getMessage()));
}
}
@GetMapping("/history")
public ResponseEntity<List<ChatMessage>> history() {
return ResponseEntity.ok(history.getMessages());
}
@DeleteMapping("/history")
public ResponseEntity<Void> clearHistory() {
history.clear();
return ResponseEntity.noContent().build();
}
}
__`_INLINE
对应的请求和响应类:
__`__INLINE_java
public record ChatRequest(String message, Map<String, Object> context) {}
public record AgentResponse(boolean success, String data, String error) {
public static AgentResponse success(String data) {
return new AgentResponse(true, data, null);
}
public static AgentResponse error(String error) {
return new AgentResponse(false, null, error);
}
}
public record ChatMessage(String role, String content, Instant timestamp) {}
__`_INLINE
六、实战案例:构建一个代码审查Agent
6.1 需求分析
让我们通过一个实际案例来综合运用Agent开发知识。本节将构建一个代码审查Agent,它能够接收Git仓库URL,自动拉取代码,进行静态分析,并生成审查报告。
核心功能需求 :
-
接收代码仓库地址(GitHub、GitLab等)
-
克隆并解析代码仓库结构
-
识别主要编程语言
-
执行静态代码分析
-
识别潜在的代码异味和安全问题
-
生成结构化的审查报告
技术挑战 :
-
需要集成多个外部工具(Git、静态分析工具)
-
需要处理不同类型的代码问题
-
需要生成可读性强的报告
6.2 架构设计
代码审查Agent的整体架构如下:
感知层 :接收用户请求,解析仓库URL,验证输入格式。
规划层 :制定代码审查策略,确定需要执行的检查项。
执行层 :调用Git克隆仓库,运行静态分析工具,处理分析结果。
记忆层 :存储审查历史,支持查询历史审查记录。
__`__INLINE_java
public class CodeReviewAgent {
private final LLM llm;
private final List<Tool> tools;
private final Memory memory;
private final ReviewHistoryRepository historyRepo;
public CodeReviewAgent(LLM llm, List<Tool> tools,
Memory memory, ReviewHistoryRepository historyRepo) {
this.llm = llm;
this.tools = tools;
this.memory = memory;
this.historyRepo = historyRepo;
}
public ReviewReport review(CodeReviewRequest request) {
// 1. 克隆仓库
String repoPath = gitClone(request.getRepoUrl());
// 2. 分析仓库结构
List<String> files = analyzeStructure(repoPath);
Map<String, String> fileTypes = identifyLanguages(files);
// 3. 提取关键代码文件
List<CodeFile> codeFiles = extractCodeFiles(repoPath, files);
// 4. 执行各项检查
List<Issue> issues = new ArrayList<>();
for (CodeFile file : codeFiles) {
issues.addAll(checkSecurity(file));
issues.addAll(checkCodeSmell(file));
issues.addAll(checkPerformance(file));
}
// 5. 生成报告
ReviewReport report = generateReport(request, issues);
// 6. 保存历史
historyRepo.save(report);
return report;
}
}
__`_INLINE
6.3 关键Tool实现
GitCloneTool :用于克隆代码仓库
__`__INLINE_java
public class GitCloneTool implements Tool {
private final String workDir;
public GitCloneTool(String workDir) {
this.workDir = workDir;
}
@Override
public String getName() {
return "git_clone";
}
@Override
public String getDescription() {
return "Clone a git repository. " +
"Input: repository URL. " +
"Output: local path to cloned repository.";
}
@Override
public String getParameterSchema() {
return """
{
"type": "object",
"properties": {
"url": {"type": "string", "description": "Git仓库URL"},
"branch": {"type": "string", "description": "分支名称,默认main"}
},
"required": "url"
}""";
}
@Override
public ToolResult execute(String input) {
try {
JsonNode config = new ObjectMapper().readTree(input);
String url = config.get("url").asText();
String branch = config.has("branch") ?
config.get("branch").asText() : "main";
String repoName = extractRepoName(url);
Path targetPath = Paths.get(workDir, repoName);
ProcessBuilder pb = new ProcessBuilder(
"git", "clone", "--branch", branch, "--depth", "1", url,
targetPath.toString()
);
pb.redirectErrorStream(true);
Process process = pb.start();
int exitCode = process.waitFor();
if (exitCode == 0) {
return ToolResult.success(targetPath.toString());
} else {
String error = new String(process.getInputStream().readAllBytes());
return ToolResult.failure("克隆失败: " + error);
}
} catch (Exception e) {
return ToolResult.failure("克隆异常: " + e.getMessage());
}
}
private String extractRepoName(String url) {
String name = url.substring(url.lastIndexOf('/') + 1);
return name.replace(".git", "");
}
}
__`_INLINE
StaticAnalysisTool :使用PMD进行静态分析
__`__INLINE_java
public class StaticAnalysisTool implements Tool {
private final String pmdHome;
public StaticAnalysisTool(String pmdHome) {
this.pmdHome = pmdHome;
}
@Override
public String getName() {
return "static_analysis";
}
@Override
public String getDescription() {
return "Run static code analysis on Java files. " +
"Input: path to source code directory. " +
"Output: analysis report in JSON format.";
}
@Override
public ToolResult execute(String input) {
try {
Path sourceDir = Paths.get(input.trim());
ProcessBuilder pb = new ProcessBuilder(
"bash", "-c",
String.format("cd %s && %s/bin/run.sh pmd -d . -R rulesets/java/quickstart.xml -f json",
sourceDir.getParent(), pmdHome)
);
pb.redirectErrorStream(true);
Process process = pb.start();
String output = new String(process.getInputStream().readAllBytes());
int exitCode = process.waitFor();
if (exitCode == 0) {
return ToolResult.success(output);
} else {
return ToolResult.failure("分析失败: " + output);
}
} catch (Exception e) {
return ToolResult.failure("分析异常: " + e.getMessage());
}
}
}
__`_INLINE
6.4 报告生成
报告生成是代码审查的最后一环,需要将分析结果整合为易读的格式:
__`__INLINE_java
public class ReviewReportGenerator {
public ReviewReport generate(CodeReviewRequest request,
List<Issue> issues) {
// 按严重程度分组
Map<Severity, List<Issue>> bySeverity = issues.stream()
.collect(groupingBy(Issue::getSeverity));
// 按文件分组
Map<String, List<Issue>> byFile = issues.stream()
.collect(groupingBy(Issue::getFile));
// 生成摘要
String summary = generateSummary(bySeverity);
// 生成详细建议
String recommendations = generateRecommendations(byFile);
// 使用LLM生成整体评价
String overallComment = generateOverallComment(issues);
return ReviewReport.builder()
.request(request)
.summary(summary)
.issuesBySeverity(bySeverity)
.issuesByFile(byFile)
.recommendations(recommendations)
.overallComment(overallComment)
.generatedAt(Instant.now())
.build();
}
private String generateSummary(Map<Severity, List<Issue>> bySeverity) {
return String.format("""
代码审查摘要:
-
总问题数:%d
-
严重问题:%d
-
中等问题:%d
-
轻微问题:%d
""",
bySeverity.values().stream().mapToInt(List::size).sum(),
bySeverity.getOrDefault(Severity.CRITICAL, List.of()).size(),
bySeverity.getOrDefault(Severity.MAJOR, List.of()).size(),
bySeverity.getOrDefault(Severity.MINOR, List.of()).size()
);
}
private String generateRecommendations(Map<String, List<Issue>> byFile) {
StringBuilder sb = new StringBuilder("改进建议:\n");
byFile.entrySet().stream()
.sorted((a, b) -> Integer.compare(b.getValue().size(), a.getValue().size()))
.limit(5)
.forEach(entry -> {
sb.append(String.format("\n文件:%s(%d个问题)\n", entry.getKey(), entry.getValue().size()));
entry.getValue().stream()
.limit(3)
.forEach(issue -> sb.append(" - ").append(issue.getMessage()).append("\n"));
});
return sb.toString();
}
}
__`_INLINE
七、Agent进阶话题
7.1 多Agent协作
多Agent系统是当前Agent研究的前沿方向。在多Agent架构中,多个具有不同专业能力的Agent协同工作,共同完成复杂任务。
多Agent协作的主要模式包括:层级模式 下,一个主Agent负责任务分解和分配,子Agent各自执行分配到的子任务,结果汇总给主Agent进行整合。这种模式适合任务可以自然分解的场景。
对等模式 下,多个Agent地位平等,通过协商和讨论达成共识。这种模式适合需要多角度分析的问题。
竞争模式 下,多个Agent尝试解决同一个问题,最终选择最佳解决方案。这种模式适合需要多方案比较的场景。
实现多Agent协作的关键是设计有效的通信协议。Agent之间需要能够交换消息、分享状态、协调行动。以下是一个简单的Agent通信接口:
__`__INLINE_java
public interface AgentMessage {
String getSenderId();
String getReceiverId();
MessageType getType();
Object getContent();
Instant getTimestamp();
enum MessageType {
REQUEST, // 请求某个Agent执行任务
RESPONSE, // 返回任务结果
QUERY, // 查询某个Agent的状态
NOTIFY, // 通知某个事件
BROADCAST // 广播消息给所有Agent
}
}
__`_INLINE
7.2 长期记忆与个性化
让Agent具备长期记忆能力是实现真正智能助理的关键。短期对话中,Agent只能访问当前对话的历史;而长期记忆使Agent能够跨会话积累知识和偏好。
实现长期记忆的一种方法是使用向量数据库存储记忆片段,并通过语义检索召回相关记忆。步骤如下:
-
当Agent完成一次交互后,将重要的信息片段提取并存储到向量数据库
-
在新的交互中,根据当前上下文从向量数据库检索相关记忆
-
将召回的记忆注入到Prompt中,使Agent能够利用历史信息
这种架构的优点是存储容量大、检索速度快、语义理解准确。缺点是需要额外的向量数据库支持,增加了系统复杂度。
__`__INLINE_java
public class VectorMemory {
private final VectorStore store;
private final EmbeddingModel embeddingModel;
public VectorMemory(VectorStore store, EmbeddingModel embeddingModel) {
this.store = store;
this.embeddingModel = embeddingModel;
}
public void add(String content, MemoryMetadata metadata) {
Embedding embedding = embeddingModel.embed(content);
store.add(embedding, content, metadata);
}
public List<MemoryEntry> retrieve(String query, int topK) {
Embedding queryEmbedding = embeddingModel.embed(query);
return store.similaritySearch(queryEmbedding, topK);
}
public void clear() {
store.deleteAll();
}
}
__`_INLINE
7.3 安全性与权限控制
Agent系统的安全性是一个容易被忽视但至关重要的问题。Agent拥有执行工具的能力,如果被恶意利用,可能造成严重后果。
输入验证 :对用户输入进行严格验证,防止Prompt注入攻击。攻击者可能通过精心构造的输入让Agent执行非预期的操作。
权限控制 :Agent应该只在授权范围内操作。例如,一个代码审查Agent不应该被允许删除代码文件或修改生产环境配置。
操作审计 :所有Agent操作都应该记录日志,便于事后追溯和分析。审计日志应该包括:操作时间、执行者、操作内容、执行结果等信息。
确认机制 :对于高风险操作(如删除文件、发送外部请求),Agent应该先请求用户确认,再执行实际的操作。
7.4 性能优化
Agent系统的性能优化涉及多个层面。在LLM调用层面,可以采用:缓存重复的请求、使用更小的模型处理简单任务、批量处理多个请求等技术。
在任务执行层面,可以采用:并行执行独立子任务、异步执行耗时操作、增量处理而非全量重算等策略。
在系统架构层面,可以采用:负载均衡、请求队列、限流熔断等机制保证系统稳定性。
__`__INLINE_java
public class AgentPerformanceOptimizer {
private final LoadingCache<String, String> responseCache;
private final ExecutorService asyncExecutor;
public AgentPerformanceOptimizer() {
this.responseCache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(Duration.ofMinutes(10))
.build(CacheLoader.from(this::generateResponse));
this.asyncExecutor = Executors.newFixedThreadPool(10);
}
public CompletableFuture<String> runAsync(String input) {
return CompletableFuture.supplyAsync(
() -> responseCache.get(input), asyncExecutor);
}
}
__``
八、总结与展望
Agent智能体代表着人工智能发展的重要方向,它将大模型的推理能力与专业工具的执行能力相结合,使AI系统能够真正参与到复杂任务的执行中。从本文的讲解可以看到,Agent系统的核心在于:感知-规划-执行-记忆的闭环架构、基于ReAct模式的推理执行协同、以及灵活可扩展的工具系统。
对于Java开发者而言,当前的生态系统已经提供了足够丰富的工具和框架来构建Agent应用。Spring AI、LangChain4j等框架大大降低了开发门槛,Lanterna则提供了独特的终端应用开发能力。未来随着技术的发展,我们可以期待更多专业化的Agent框架和更强大的LLM支持。
Agent技术的发展也带来了新的挑战,包括安全性、可靠性、可解释性等问题都需要认真对待。作为开发者,我们应该在追求能力提升的同时,始终将安全性和可靠性放在首位。
展望未来,多Agent协作、长期记忆、具身智能等方向都可能取得突破性进展。Agent有望成为继GUI、触屏之后的新一代人机交互范式,深刻改变我们与计算机交互的方式。Java开发者应该密切关注这些发展,及时更新知识体系,在这个变革浪潮中保持竞争力。
参考资源
-
Yao et al. "ReAct: Synergizing Reasoning and Acting in Language Models" (2022)
-
Brown et al. "Language Models are Few-Shot Learners" (GPT-3论文)
-
AutoGPT项目官方文档
-
LangChain4j官方文档
-
Spring AI参考文档
-
Lanterna库文档
作者:洛水石